SpringAI–RAG知識庫
RAG概念
什么是RAG?
RAG(Retrieval-Augmented Genreation,檢索增強生成)是一種結合信息檢索技術和AI內容生成的混合架構,可以解決大模型的知識時效性限制和幻覺問題。
RAG在大語言模型生成回答之前,會先從外部知識庫中檢索相關信息,然后將這些檢索到的內容作為額外上下文提供給模型,引導其生成更準確、更相關的回答。
簡單了解傳統AI模型和RAG增強模型區別:
| 特性 | 傳統AI | RAG增強模型 |
|---|---|---|
| 知識失效性 | 受訓練數據截止日期限制 | 可接入最新知識庫 |
| 領域專業性 | 泛華知識,專業深度有限 | 可接入專業領域知識庫 |
| 響應準確性 | 可能產生幻覺 | 基于檢索的事實依據 |
| 可控性 | 依賴原始訓練 | 可通過知識庫定制輸出 |
| 資源消耗 | 較高(需要大模型參數) | 模型可更小,結合外部知識 |
RAG工作流程
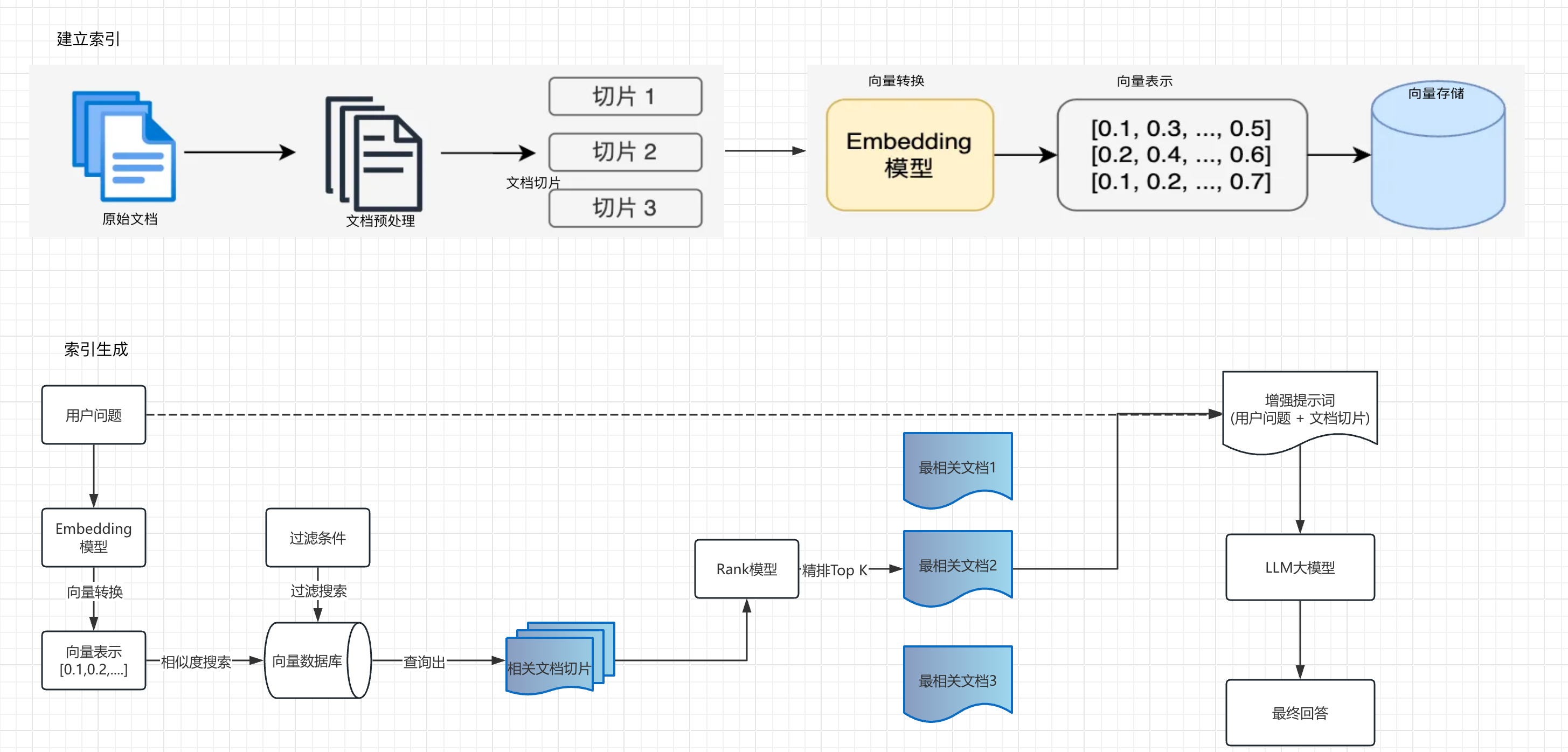
RAG技術實現主要包含以下4個核心步驟:
- 文檔收集和切割
- 向量轉換和存儲
- 文檔過濾和檢索
- 查詢增強和關聯
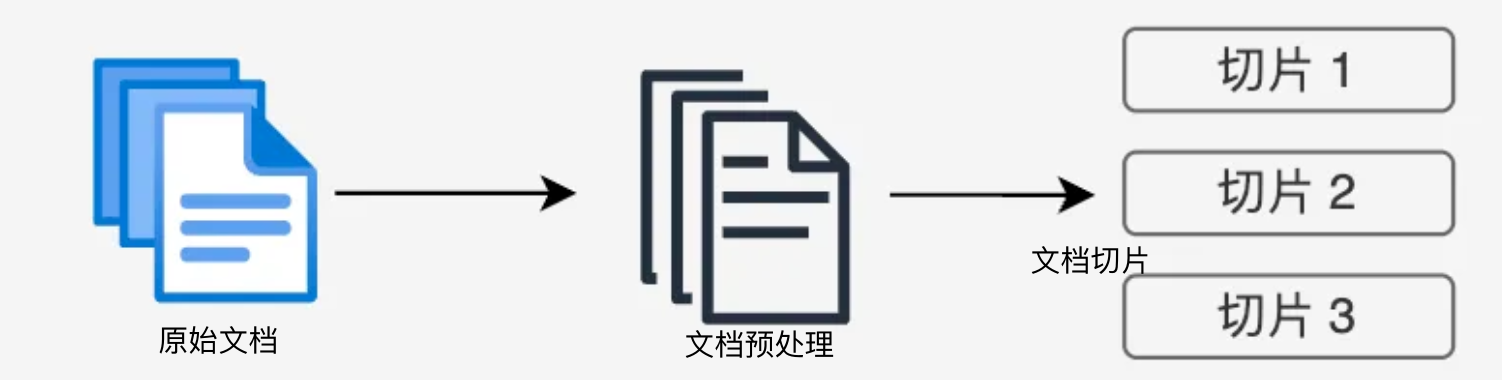
文檔收集和切割
- 文檔收集:從各種來源(網頁、PDF、數據庫等)收集原始文檔。
- 文檔預處理:清洗、標準化文檔格式(markdown格式、docx格式等)。
- 文檔切割:將長文檔分割成適當大小的片段(俗稱chunks)。
- 基于固定大小(如512個token)
- 基于語義邊界(如段落、章節)
- 基于遞歸分割策略(如遞歸字符n-gram切割)
向量轉換和存儲
- 向量轉換:使用Embedding模型將文本塊轉換為高維向量表示,可以捕獲到文檔的語義特征。
- 向量存儲:將生成的向量和對應文本存儲向量數據庫,支持高效的相似性搜索。

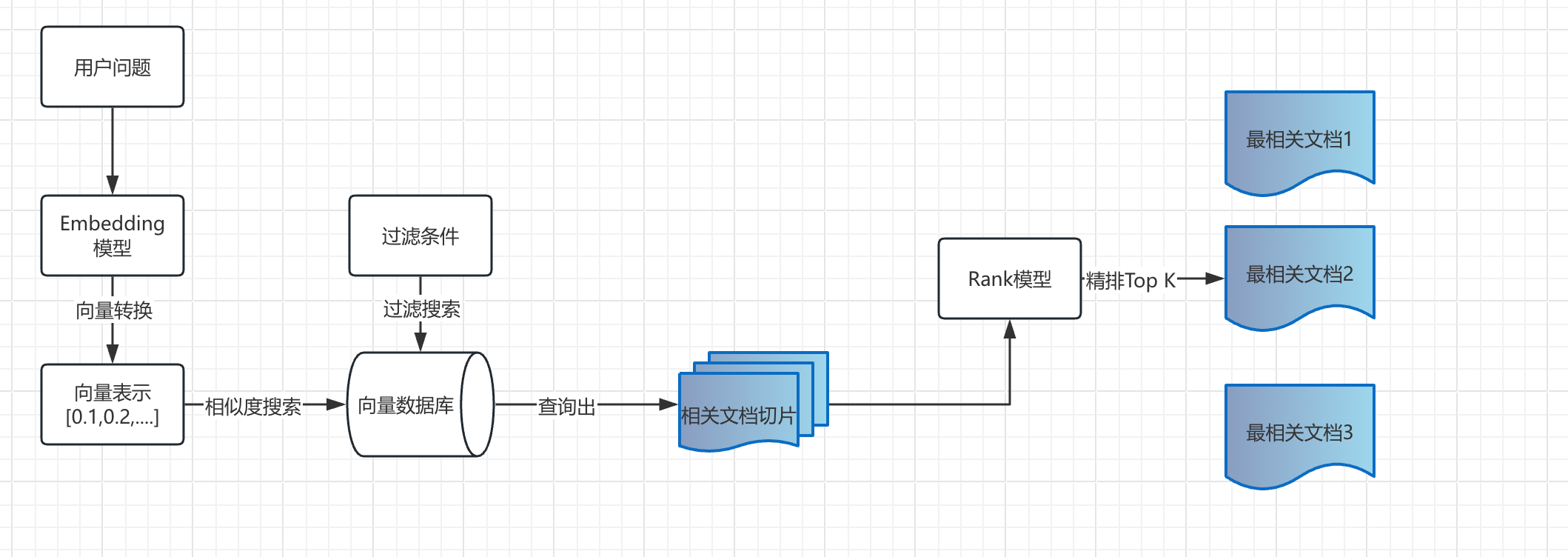
文檔過濾和檢索
- 查詢處理:將用戶問題也轉換為向量表示。
- 過濾機制:基于元數據、關鍵詞或自定義規則進行過濾。
- 相似度搜索:在向量數據庫中查找與問題向量最相似的文檔塊,常用的相似度搜索算法有余弦相似度、歐氏距離等。
- 上下文組裝:將檢索到的多個文檔塊組裝成連貫的上下文。
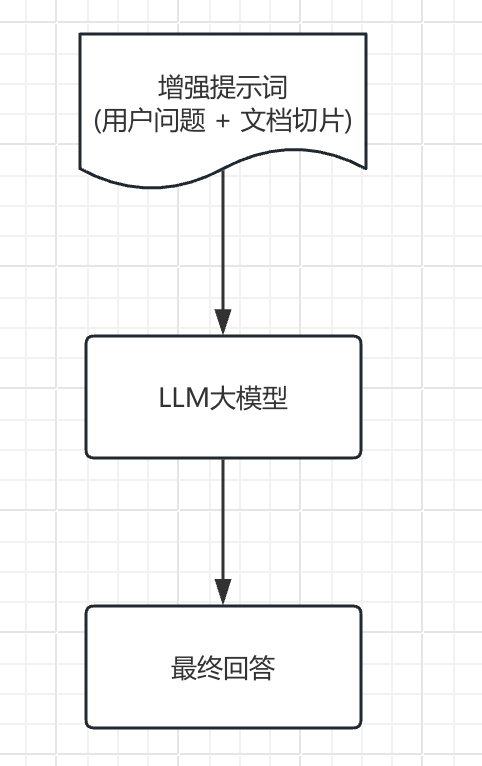
查詢增強和關聯
- 提示詞組裝:將檢索到的相關文檔與用戶問題組合成增強提示。
- 上下文融合:大模型基于增強提示生成回答。
- 源引用:在回答中添加信息來源引用。
- 后處理:格式化、摘要或其他處理以優化最終輸出。
完整工作流程
RAG相關技術
Embedding和Embedding模型
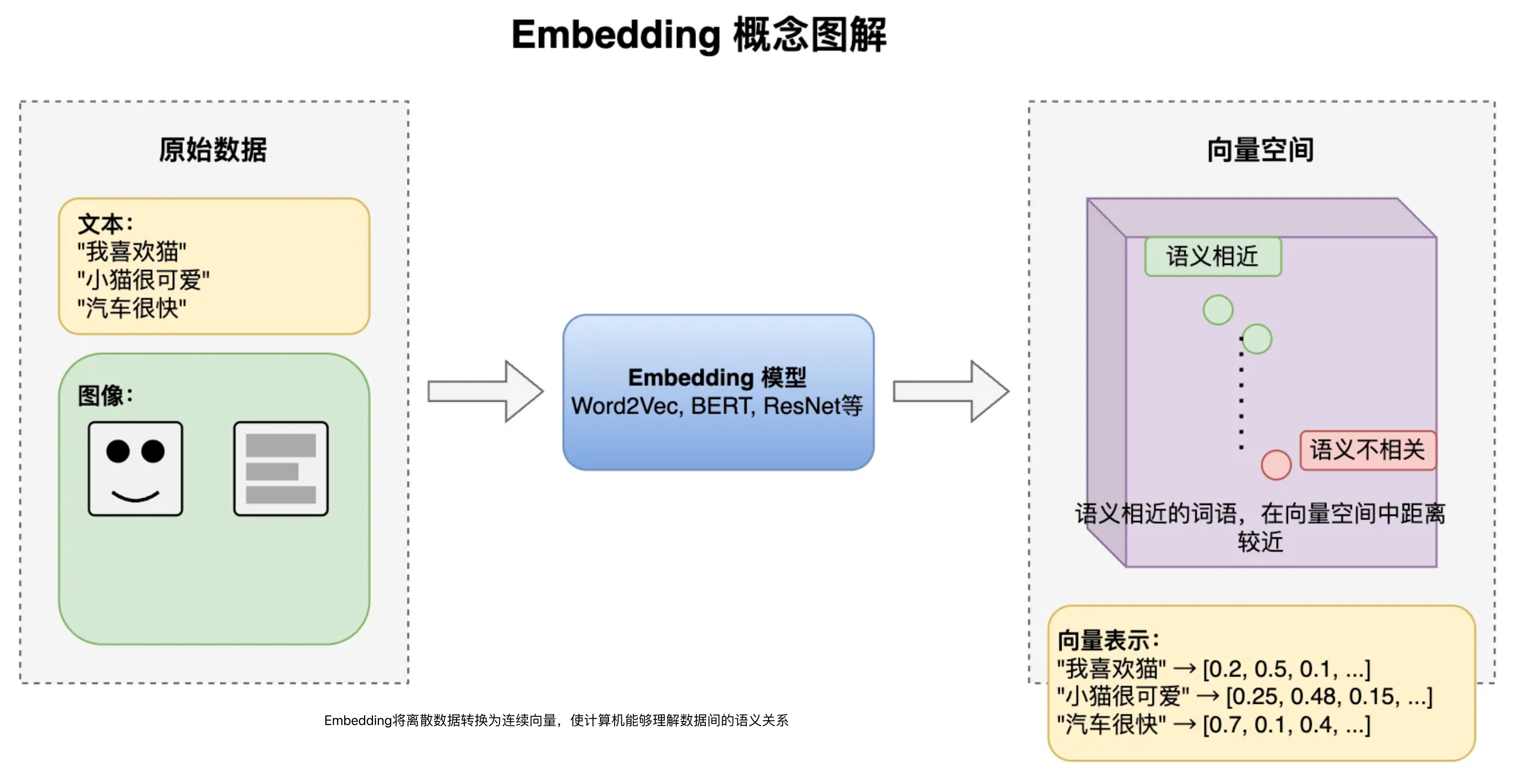
Embedding嵌入是將高維離散數據(如文字、圖片)轉換為低維連續向量的過程。這些向量能在數學空間中表示原始數據的語義特征,使計算機能夠理解數據間的相似性。
Embedding模型是執行這種轉換算法的機器學習模型,如Word2Vec(文本)、ResNet(圖像)等。不同的Embedding模型產生的向量表示和維度數不同,一般維度越高表達能力越強,可以捕獲更豐富的語義信息和更細微的差別,但同樣占用更多存儲空間。
向量數據庫
向量數據庫是專門存儲和檢索向量數據的數據庫系統。通過高效索引算法實現快速相似性搜索,支持K近鄰查詢等操作。
注意,并不是只有向量數據庫才能存儲向量數據,只不過與傳統數據庫不同,向量數據庫優化了高維向量的存儲和檢索。
AI的流行帶火了一波向量數據庫和向量存儲,比如Milvus、Pinecone等,此外,一些傳統數據庫也可以通過安裝插件實現向量存儲和檢索,比如PGVector、Redis Stack的RediSearch等。
召回
召回是信息檢索中的第一階段,目標是從大規模數據集中快速篩選出可能相關的候選項子集。強調速度和廣度,而非精確度。
精排和Rank模型
精排(精確排序)是搜索/推薦系統的最后階段,使用計算復雜度更高的算法,考慮更多特征和業務規則,對少量候選項進行更復雜、精細的排序。
Rank模型(排序模型)負責對召回階段篩選出的候選集進行精確排序,考慮多種特征評估相關性。
現代Rank模型通常基于深度學習,如BERT、LambdaMART等,綜合考慮查詢與候選項的相關性、 用戶歷史行為等因素。
混合檢索策略
混合檢索策略結合多種檢索方法的優勢,提高搜索效果。常見組合包括關鍵詞檢索、語義檢索、知識圖譜等。
比如在AI大模型開發平臺Dify中,就為用戶提供了“基于全文檢索的關鍵詞搜索+基于向量檢索的語義檢索”的混合檢索策略,用戶還可以自己設置不同檢索方式的權重。
RAG實戰:SpringAI + 本地知識庫
我們要對自己準備好的知識庫文檔進行處理,然后保存到向量數據庫中。這個過程俗稱ETL(抽取、轉換、加載),SpringAI提供了對ETL的支持。
ETL的3大核心組件,按照順序執行:
- DocumentReader:讀取文檔,得到文檔列表。
- DocumentTransformer:轉換文檔,得到處理后的文檔列表。
- DocumentWriter:將文檔列表保存到存儲中(可以是向量數據庫,也可以是其他存儲)。
文檔準備
demo文檔
文檔讀取
讀取markdown文檔
demo文檔讀取
向量存儲和轉換
為了實現方便,先使用SpringAI內置的基于內存讀寫的向量數據庫SimpleVectorStore來保存文檔。
SimpleVectorStore實現了VectorStore接口,而VectorStore接口集成了DocumentWriter,所以具備文檔寫入能力。
通過下面SimpleVectorStore的源碼可以了解到,在將文檔寫入到數據庫前,會先調用Embedding大模型將文檔轉換為向量,實際保存到數據庫中的是向量類型的數據。
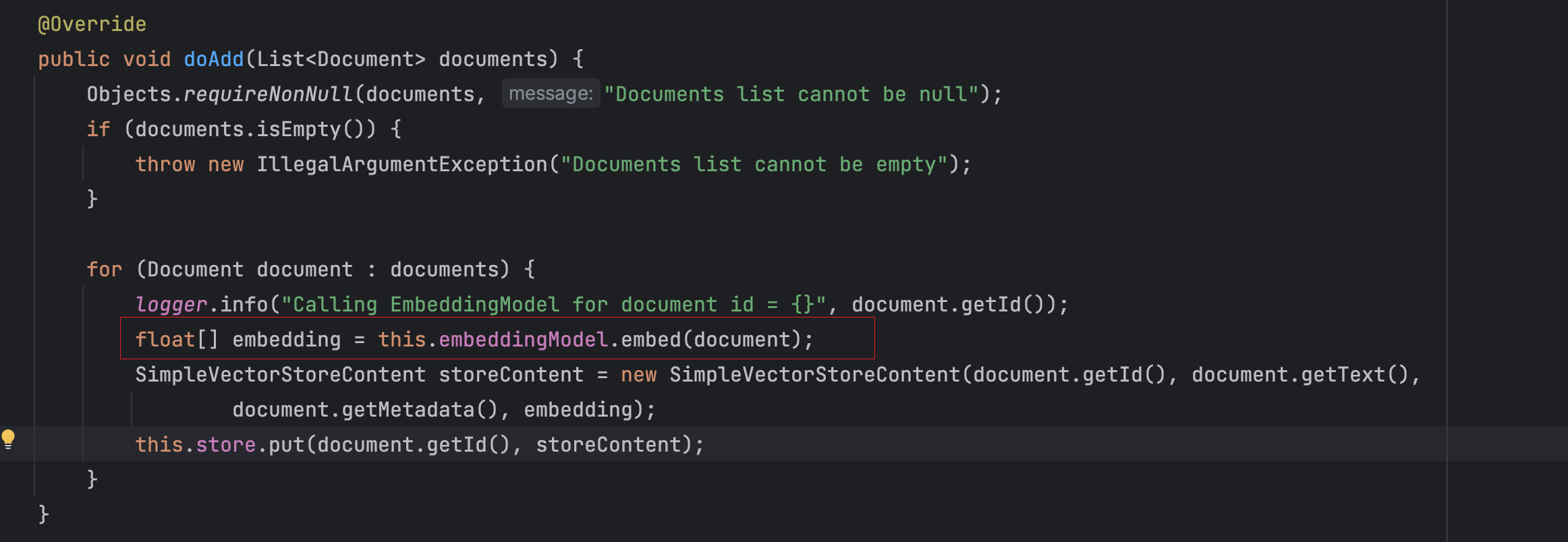
實現初始化向量數據庫并保存文檔的方法:
文檔存入向量數據庫(內存實現)
查詢增強
SpringAI通過Advisor特性提供了開箱即用的RAG功能。主要是QuestionAnswerAdvisor問答攔截器和RetrievalAugmentationAdvisor檢索增強攔截器,前者更簡單易用,后者更靈活強大。
查詢增強
測試
測試本地知識庫
基于PGVector實現向量存儲
多數據源整合
PgVectorStoreConfig.java
/*** 向量檢索* 查詢增強原理:* 向量數據庫存儲著AI模型本身不知道的數據,當用戶問題發送給AI模型時,* QuestionAnswerAdvisor會查詢向量數據庫,獲取與用戶問題相關的文檔。* 然后從向量數據庫返回的響應會被附加到用戶文本中,為AI模型提供上下文,幫助AI模型生成回答* 存儲在pgVector向量數據庫中*/
public String doChat4RagPgVector(String message, String chatId) {ChatResponse chatResponse = chatClient.prompt().user(message).advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId).param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 5))// QuestionAnswerAdvisor 查詢增強,在調用大模型前會檢索pgVectorStore中的數據,拼接到用戶的Prompt中.advisors(new QuestionAnswerAdvisor(pgVectorStore))// MySQL存儲對話記憶.advisors(new MessageChatMemoryAdvisor(chatMemory)).call().chatResponse();return chatResponse.getResult().getOutput().getText();
}
)

)






課堂 1--5,這五節主要講解 mysql 的概念,定義,下載安裝與卸載)






)
)

