Learning with Less: Knowledge Distillation from Large Language Models via Unlabeled Data
發表:NNACL-Findings 2025
機構:密歇根州立大學
Abstract
在實際的自然語言處理(NLP)應用中,大型語言模型(LLMs)由于在海量數據上進行過廣泛訓練,展現出極具前景的解決方案。然而,LLMs龐大的模型規模和高計算需求限制了它們在許多實際應用中的可行性,尤其是在需要進一步微調的場景下。為了解決這些限制,實際部署時通常更傾向于使用較小的模型。但這些小模型的訓練常受到標注數據稀缺的制約。相比之下,無標簽數據通常較為豐富,可以通過利用LLMs生成偽標簽(pseudo-labels),用于訓練小模型,從而使得這些小模型(學生模型)能夠從LLMs(教師模型)中學習知識,同時降低計算成本。
這一過程也帶來了一些挑戰,例如偽標簽可能存在噪聲。因此,選擇高質量且信息豐富的數據對于提升模型性能和提高數據利用效率至關重要。為了解決這一問題,我們提出了 LLKD(Learning with Less for Knowledge Distillation),一種能夠以更少計算資源和更少數據完成從LLMs進行知識蒸餾的方法。
LLKD 是一種自適應樣本選擇方法,融合了來自教師模型和學生模型的信號。具體來說,它優先選擇那些教師模型在標注上表現出高度置信度的樣本(意味著標簽更可靠),以及學生模型在這些樣本上表現出高信息需求的樣本(表明這些樣本具有挑戰性,需要進一步學習)。
我們的大量實驗證明,LLKD 在多個數據集上都實現了更高的數據效率和更優的性能表現。
1 Introduction
大型語言模型(LLMs),如 LLaMA(Touvron 等,2023)和 GPT-4(Achiam 等,2023),由于在大規模語料上進行了預訓練,獲得了廣泛的知識,因此在許多實際的自然語言處理(NLP)應用中展現出卓越的語言理解能力(Schopf 等,2022;Thirunavukarasu 等,2023;Zhao 等,2023)。然而,LLMs 的部署需要大量資源,包括高內存需求、較高的計算成本以及推理時更高的延遲,尤其是在需要為特定任務進一步微調時(Shoeybi 等,2019)。為了應對這些限制,研究者和開發者往往更傾向于使用資源需求更低的小型模型(Liu,2019;Devlin,2018;Wang 等,2024)。然而,小模型在能力上不如LLMs(Kaplan 等,2020),通常需要使用帶標簽的數據進行進一步訓練,因為它們通常缺乏捕捉廣泛知識的能力。
在缺乏標注數據的指導下,對小模型進行自監督訓練可能導致性能欠佳,因為這類模型在泛化到多樣化任務方面存在困難,且常常無法有效地學習特定任務所需的特征(Goyal 等,2019)。這一挑戰因獲取任務相關的標注數據代價高昂而進一步加劇。盡管無標簽數據通常更加豐富,但若缺乏適當的標注,便無法直接用于訓練模型,從而成為模型訓練中的一大挑戰。
一種有前景的解決方案是利用LLMs為無標簽數據生成偽標簽(pseudo-labels),進而用于訓練小模型。這種策略使得小模型能夠從LLMs中蘊含的廣泛知識中獲益,同時降低了計算成本。該過程可以被視為一種知識蒸餾方法(Mishra 與 Sundaram,2021;Zhou 等,2023;Kontonis 等,2024;Iliopoulos 等,2022)。然而,這一方法也存在挑戰——由LLMs生成的偽標簽可能存在噪聲或不可靠性,從而可能削弱學生模型的性能。
因此,提高數據效率至關重要——這不僅有助于減輕噪聲偽標簽的影響,還能確保選取具有代表性的數據樣本以實現最優訓練效果。一種潛在的解決思路是選擇那些不僅偽標簽質量高,而且對學生模型而言具有信息價值的數據樣本。然而,由于學生模型在訓練過程中會不斷更新,持續識別對其具有學習價值的知識仍然是一項挑戰。
已有一些研究提出了在知識蒸餾過程中進行數據選擇的方法(Mishra 與 Sundaram,2021;Zhou 等,2023;Li 等,2021)。但多數方法(如 Zhou 等,2023;Li 等,2021)依賴于真實標簽的數據集,并未考慮偽標簽樣本可能存在噪聲的問題,從而導致訓練效果不佳。而部分方法雖然針對無標簽數據(如 Kontonis 等,2024;Iliopoulos 等,2022),卻往往忽視了學生模型的學習進度,或者未能兼顧數據利用效率。
因此,我們提出一種方法,旨在讓學生模型從最有價值的數據中學習,并通過減少所需訓練數據量來提升數據效率。為了解決上述挑戰,我們提出了 LLKD,即“以更少計算資源和更少數據從LLMs進行知識蒸餾的學習方法”(Learning with Less for Knowledge Distillation)。這是一種在每個訓練步驟中根據學生模型動態學習狀態進行自適應樣本選擇的方法。
具體而言,我們優先選擇以下兩類樣本:(1)教師模型在標注時表現出高度置信度的樣本,代表偽標簽具有較高可靠性(Mishra 與 Sundaram,2021);(2)學生模型在這些樣本上表現出高度不確定性的樣本,表明這些是其仍需進一步學習的難點樣本(Zhou 等,2023)。我們在每個訓練步驟中基于教師模型置信度和學生模型不確定性設計了兩種閾值,并從兩種視角出發選取符合標準的重疊樣本。該樣本選擇策略促進了從LLM向小模型的高效知識轉移,確保用于訓練的都是最具信息量的樣本,同時減少所需數據量,從而提升數據利用效率。
我們將 LLKD 應用于一個基礎的NLP任務——文本分類,并在多個數據集上進行了全面評估。實驗結果表明,LLKD 顯著提升了模型性能,在數據利用效率方面也取得了更優表現。
我們的貢獻總結如下:
1)我們提出了一種基于無標簽數據的知識蒸餾方法,該方法所需計算資源更少;
2)我們提出了一個動態的數據選擇方法 LLKD,能夠識別高質量樣本,從而提高數據利用效率;
3)大量實驗證明,LLKD 在文本分類任務中能實現更優性能和更高數據效率。
2 Related Work
Knowledge Distillation(知識蒸餾)
知識蒸餾(Mishra 和 Sundaram, 2021;Zhou 等, 2023;Xu 等, 2023;Li 等, 2021;Kontonis 等, 2024)被廣泛用于將知識從一個龐大的教師模型傳遞給一個輕量級的學生模型。大多數傳統方法集中于帶有真實標簽的數據集,并且一些方法在此過程中探索了數據選擇策略。例如,Mishra 和 Sundaram(2021)提出了一種基于訓練輪次的閾值方法,用于為學生模型選擇困難樣本。類似地,Li 等(2021)和 Xu 等(2023)通過設置固定的采樣比例,選擇那些學生模型不確定性較高的樣本。Zhou 等(2023)引入了一種基于強化學習的選擇器,以不同方式衡量學生模型的不確定性。然而,這些方法大多依賴真實標簽,且未能解決教師模型所生成的偽標簽可能存在噪聲的問題。雖然部分方法關注于無標簽數據(Lang 等, 2022;Dehghani 等, 2018),但它們通常忽視了數據效率,或未考慮學生模型的動態變化以識別對學生有價值的樣本。例如,Kontonis 等(2024)通過將學生模型的軟標簽與去噪后的教師標簽結合來生成新的軟標簽;而 Iliopoulos 等(2022)則通過對學生模型的損失函數重新加權來模擬無噪聲偽標簽下的訓練損失。
Thresholding Methods(閾值方法)
在面對大量無標簽和噪聲數據的分類任務中,已有多種基于置信度的閾值方法被提出(Zhang 等, 2021;Sohn 等, 2020;Wang 等, 2023;Chen 等, 2023),以優先選擇置信度高的樣本。例如,FlexMatch(Zhang 等, 2021)采用課程學習策略,依據已學習樣本的數量為每個類別靈活調整閾值;FreeMatch(Wang 等, 2023)和 SoftMatch(Chen 等, 2023)使用基于置信度的閾值,其中 FreeMatch 同時考慮全局和類別層面的學習狀態,而 SoftMatch 則使用高斯函數對損失函數進行加權。然而,這些方法通常依賴于有限的有標簽數據,因此在自訓練場景下可能表現不佳。
Unsupervised Text Classification(無監督文本分類)
無監督文本分類的目標是在沒有標簽數據的情況下對文本進行分類。一種常見的方法是基于相似度的技術(Abdullahi 等, 2024;Schopf 等, 2022;Yin 等, 2019),這些方法為輸入文本和標簽生成嵌入向量,然后基于相似度將文本與標簽進行匹配。這類方法無需訓練數據或訓練過程。例如,Abdullahi 等(2024)建議用 Wikipedia 數據增強輸入文本;而 Schopf 等(2022)使用 lbl2TransformerVec 來生成嵌入表示。然而,如果缺乏特定任務的領域知識,這些方法通常表現較差。雖然一些方法(如 Gretz 等, 2023)提出先在其他領域的數據集上進行預訓練,再將模型應用于當前任務進行預測,但這些預訓練模型通常因法律或隱私問題而無法公開獲取。
3 Method
3.1 Notations
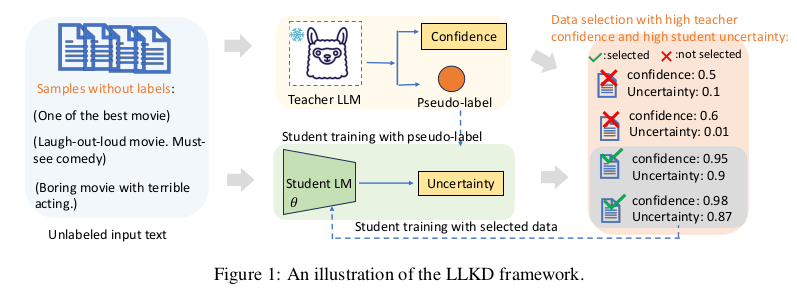

3.2 Teacher Model

3.3 Student Model

3.4 Data Selection


4 Experiment
在本節中,我們將進行全面的實驗以驗證 LLKD 的性能。我們首先介紹實驗設置,隨后呈現結果及其分析。
4.1 experimental settings
數據集。我們使用了來自不同領域的五個數據集:
-
PubMed-RCT-20k(Dernoncourt 和 Lee,2017),提取自醫學論文;
-
Yahoo! Answers(Zhang 等,2015),來自 Yahoo! Answers 平臺的問題與回答對集合;
-
Emotions(Saravia 等,2018),包含被分類為六種基本情感的推特消息;
-
Arxiv-10(Farhangi 等,2022),由 ArXiv 論文構建;
-
BiosBias(De-Arteaga 等,2019),一個文本傳記數據集,旨在預測職業身份。
更多細節見附錄 A.3 節。
基線方法。我們將方法與四組基線方法進行比較:
-
閾值方法,如 FreeMatch(Wang 等,2023),使用自適應閾值選擇學生模型高置信度樣本;SoftMatch(Chen 等,2023),對學生置信度更高的樣本賦予更大權重。
-
知識蒸餾方法,重點在于基于教師模型過濾噪聲偽標簽,或基于學生模型選擇信息量大的樣本。第一類中,我們評估 CCKD_L(Mishra 和 Sundaram,2021),根據教師概率加權樣本;Entropy Score(Lang 等,2022),選擇教師熵最低(即教師置信度最高)的樣本。第二類中,包含 CCKD_T+Reg(Mishra 和 Sundaram,2021),使用閾值選擇對學生具有挑戰性的樣本;UNIXKD(Xu 等,2023),選擇學生不確定性最高的樣本。
-
無監督文本分類方法:Lbl2TransformerVec(Schopf 等,2022),基于輸入文本與標簽詞的嵌入相似度進行標簽預測。
-
基礎基線方法:Random,從每個批次隨機選擇樣本子集;Teacher,使用教師模型結合少量示例直接生成預測;Teacher-ZS,使用教師模型不帶示例(零樣本)生成預測;No_DS,學生模型在無數據選擇的情況下訓練。
實現細節。教師模型采用 LLaMA(Touvron 等,2023),一款在多種應用中表現出色的開源大語言模型。學生模型采用 RoBERTa(Liu,2019)。為確保公平比較,所有基線模型均使用與我們模型相同的偽標簽,且除 Lbl2TransformerVec 外,基線模型均以 RoBERTa 作為骨干模型。文本分類任務的模型性能使用準確率(ACC)和宏觀 F1 分數進行評估,數據效率則根據總訓練樣本數進行衡量。參數分析見第 4.7 節。更多細節請參見附錄 A.1 和 A.4 節。
4.2?Classification Performance Comparison
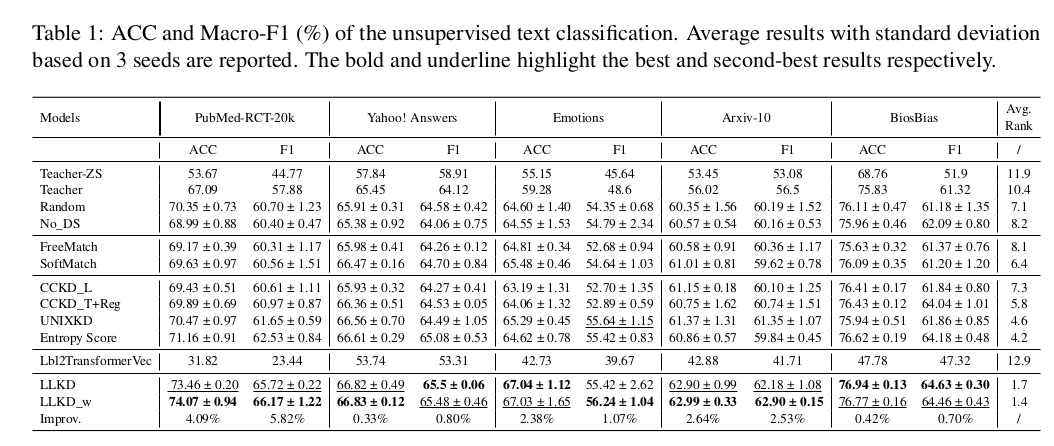
我們在表1中展示了分類性能對比結果,其中"LLKD_w"表示采用公式(9)加權損失函數的版本。同時,我們計算了各方法在所有數據集和評估指標上的平均排名,并以"Improv."標注最優方法相對于最佳基線的相對提升幅度。由于Lbl2TransformerVec是基于相似度的無訓練方法,其性能無標準差。
主要發現如下:
-
如表1所示,我們的模型在所有基線方法中表現最優,在PubMed-RCT-20k數據集上的F1分數相對提升達5.82%。加權版本普遍表現更優,說明通過教師置信度和學生不確定性對選定樣本進行加權能進一步提升模型性能。
-
直接使用教師模型(Teacher)的表現通常遜于我們的方法及其他基于偽標簽微調學生模型的基線(Lbl2TransformerVec除外)。這表明學生模型不僅能有效從教師處學習,還能取得更優結果。這些發現證明:經過適當調整,學生模型可以在保持更低計算成本的同時實現更優性能。
-
采用少樣本示例的教師模型(Teacher)普遍優于零樣本版本(Teacher-ZS),驗證了融入少樣本示例的有效性。
-
基于相似度的方法Lbl2TransformerVec表現最弱,說明僅依賴文本-標簽相似度難以實現有效的分類。
4.3 Ablation Study
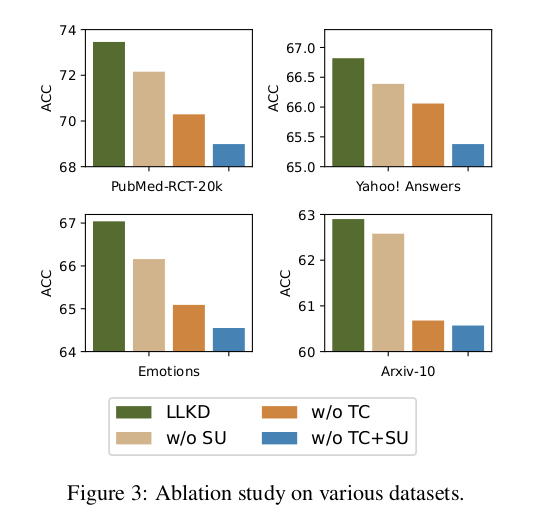
在本小節中,我們進行了消融實驗,以評估我們方法中各個組件的有效性,包括數據選擇、教師置信度和學生不確定性。結果如圖 3 所示。我們使用 “w/o TC” 表示未使用教師置信度進行樣本選擇的模型,此時僅依賴學生不確定性閾值進行篩選;類似地,“w/o SU” 表示未使用學生不確定性閾值的模型;“w/o TC+SU” 表示完全不進行數據選擇的模型。需要注意的是,“w/o TC+SU” 與表 1 中的 No_DS 模型是相同的。圖中清晰地表明,我們的模型在所有數據集上均明顯優于各個去除組件的版本,突顯了各個組件的重要性。尤其值得注意的是,在完全不進行數據選擇的情況下,模型表現最差,進一步驗證了我們數據選擇策略在提升模型性能方面的關鍵作用。
此外,為評估在標注數據有限的情況下使用未標注數據的必要性,我們進行了進一步分析,詳見附錄 A.5。表 6 的結果表明,僅使用少量真實標簽訓練的模型,其性能遠不如使用未標注數據訓練的 LLKD 模型。這一發現強調了在標注數據有限時,利用未標注數據的重要性。
4.4 Data Efficiency
在本小節中,我們通過展示每輪訓練中模型所看到的樣本總數及其占原始總樣本數的百分比,來評估數據效率。例如,Arxiv-10 的原始訓練集大小為 79,790,我們將訓練輪數設置為 6,因此在不進行任何數據選擇的情況下,學生模型總共會看到 79,790 × 6 = 479,820 個樣本。所有方法在原始樣本總數上是一致的。
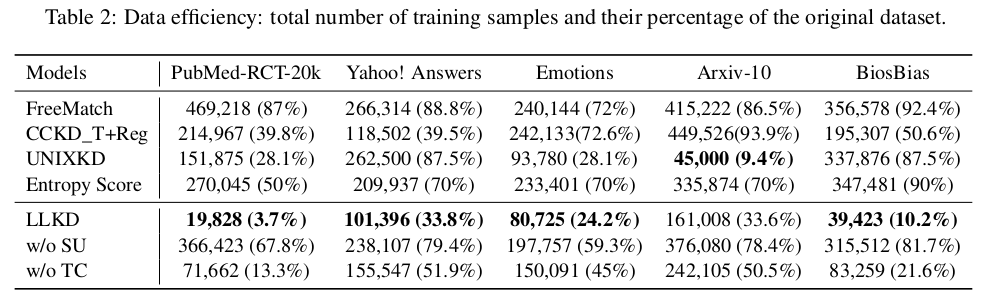
各種數據選擇方法的結果如表 2 所示。我們還包含了各個消融版本的結果,以更深入地分析我們的方法。對于采用固定選擇比例的 UNIXKD 和 Entropy Score,我們在比例 {10%, 30%, 50%, 70%, 90%} 上進行了實驗,并選擇驗證集性能最好的比例。由于 SoftMatch 和 CCKD_L 是對樣本進行加權而非篩選,它們使用了全部的原始樣本集合。
總體而言,結果表明我們的方法在效果和數據效率上始終優于其他方法。在大多數情況下,我們的方法只需要選擇不到 25% 的訓練樣本。值得注意的是,在 PubMed-RCT-20k 數據集上,我們僅使用了 3.7% 的訓練樣本,便實現了相對提升 5.82% 的顯著性能改進,如表 1 所示。盡管在 Arxiv-10 數據集上,UNIXKD 使用了更少的數據進行訓練,但我們的方法在性能上仍有較大提升,說明 UNIXKD 未能選擇到足夠有信息量的樣本。


)







)








