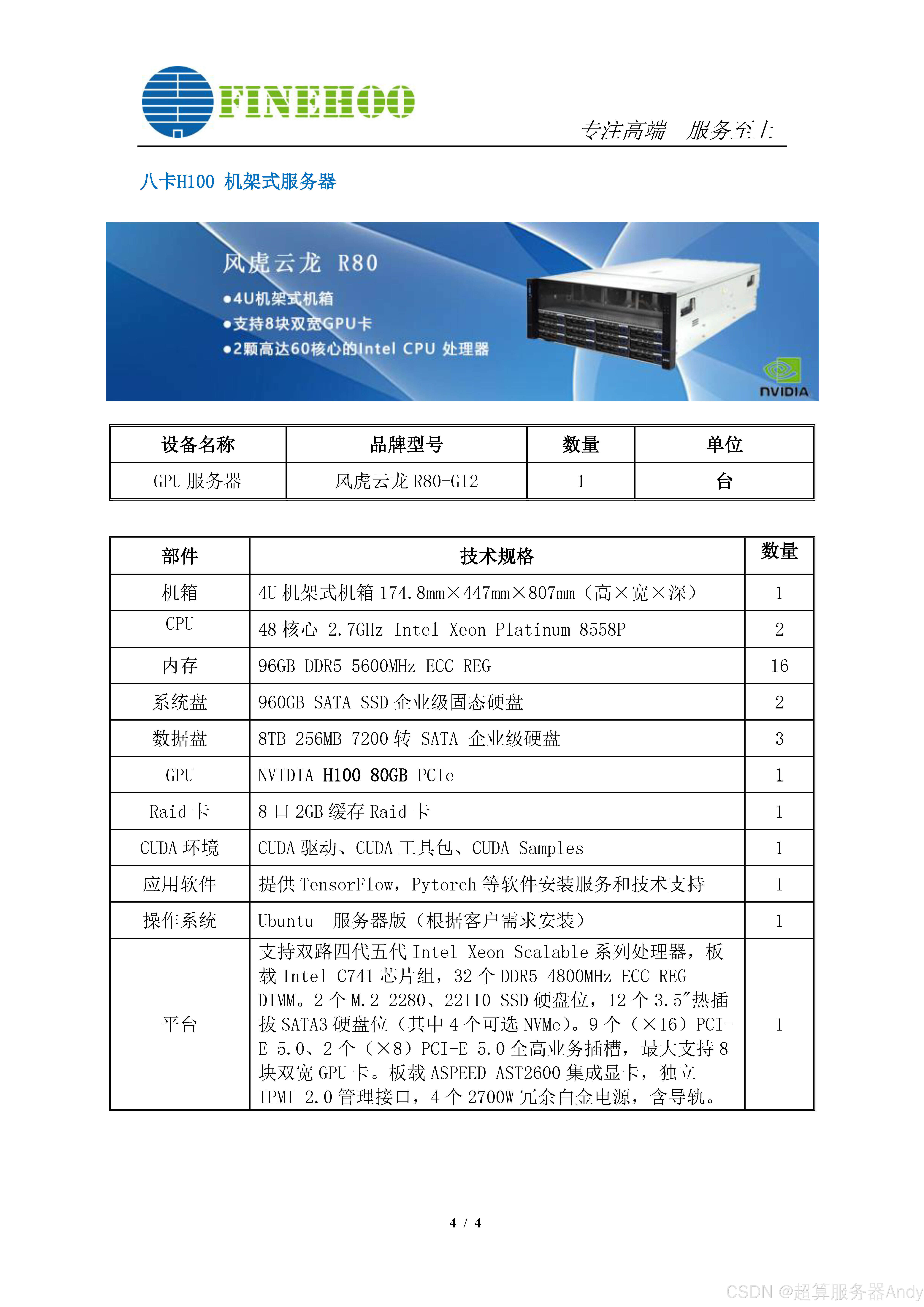
當AI開始操控方向盤和機械臂,人類正在見證一場靜默的產業革命。
2023年7月,谷歌DeepMind拋出一枚技術核彈——全球首個視覺語言動作模型(VLA)RT-2橫空出世。這個能將“把咖啡遞給穿紅衣服的阿姨”這類自然語言指令直接轉化為機器人動作的AI系統,不僅讓機器人行業沸騰,更讓自動駕駛領域嗅到了顛覆性變革的氣息。今天,我們深度拆解VLA模型的技術密碼,看它如何架起虛擬世界與物理世界的智能橋梁。
一、VLA:從“看圖說話”到“動手動腦”的進化革命
傳統AI模型像被割裂的“腦區”:視覺模型負責認路,語言模型負責聊天,規劃模型負責算路線。而VLA模型打破了這種“各司其職”的局限,它像人類一樣用統一的大腦處理視覺、語言和動作。
- 端到端架構:?傳統自動駕駛需要感知→定位→規劃→控制四大模塊,VLA直接將攝像頭畫面、語音指令和車輛動作塞進一個“黑箱”訓練,輸出結果就是方向盤轉角和油門深度。這種簡化讓系統反應速度提升40%,硬件成本降低60%。
- 泛化能力炸裂:?RT-2在測試中展現了“開掛級”推理:當被要求“用石頭當錘子砸開堅果”,它能識別石頭物理特性;當指令是“給累癱的工人送能量飲料”,它能關聯“疲憊→需要提神”的語義邏輯。這種跨場景理解能力,讓AI從“執行預設程序”進化為“現場即興創作”。
- 通用性顛覆:?同一套VLA算法,裝在機器人手臂上能組裝家具,裝在汽車上能自動駕駛,裝在無人機上能自主避障。這種“算法即平臺”的特性,正在催生AI時代的“智能操作系統”。

二、VLA如何煉成?揭秘三模態融合的黑科技
要理解VLA的魔力,得先看它如何“煉金”三種數據:
- 視覺編碼器:?用DinoV2或SigLIP等模型將攝像頭畫面轉化為“空間語義地圖”,比如識別出“斑馬線”“紅綠燈”“行人手勢”等關鍵要素。
- 語言編碼器:?基于Llama-2等萬億參數模型,把“靠邊停車”“繞過障礙物”等指令拆解為向量化的“動作意圖”。
- 動作編碼器:?將歷史駕駛數據(如方向盤轉動記錄)或機器人操作軌跡轉化為“動作基因序列”。
這些數據在跨模態融合層通過Transformer的注意力機制“對話”:視覺告訴語言“前方有兒童”,語言告訴動作“減速至10km/h”,動作反饋給視覺“已執行制動”。最終,動作解碼器像賽車手的大腦,在0.1秒內輸出最優操作指令。
三、產業巨震:VLA正在改寫哪些游戲規則?
- 自動駕駛2.0時代:?特斯拉FSD還在用“感知-規劃-控制”分立架構時,VLA已實現“眼到心到手到”的直覺駕駛。測試顯示,搭載VLA的車輛在重慶黃桷灣立交這種“8D魔幻道路”上,決策延遲從200ms降至80ms。
- 機器人行業質變:?波士頓動力還在教機器狗“小步快跑”,VLA賦能的機器人已能理解“把工具箱遞給穿工裝的師傅”這類模糊指令,并在工廠中自主導航完成70%的裝配任務。
- 硬件產業鏈洗牌:?傳統芯片算力需求暴增。英偉達Thor芯片原定2025年量產的1000Tops算力,在VLA訓練需求下可能推遲。國內廠商如地平線、寒武紀正加速研發“專為多模態優化”的AI芯片,試圖打破算力壟斷。
四、黎明前的挑戰:數據、算力與安全的“不可能三角”
盡管VLA前景誘人,但產業落地仍需跨越三道天塹:
- 數據饑荒:?訓練一個城市級VLA模型需要10萬小時的駕駛數據+100萬條語言指令+1億幀環境畫面,相當于1000輛測試車不眠不休跑3年。
- 算力詛咒:?RT-2訓練耗資超2億美元,相當于燒掉4000顆A100顯卡。國內車企若自研,單次訓練成本可能突破15億元。
- 安全困局:?當AI同時掌控視覺、決策和執行,任何環節的漏洞都可能引發“多米諾失效”。某自動駕駛團隊測試發現,VLA在遇到“前方假人+語音干擾”時,誤判率比傳統模型高3倍。
VLA不是下一個風口,而是正在到來的新時代
從谷歌實驗室到特斯拉工廠,從波士頓動力到華為車BU,全球科技巨頭正在All in VLA。這場革命不僅關乎技術路線之爭,更將重塑制造業、物流業、服務業的底層邏輯。當AI開始像人類一樣“眼觀六路、耳聽八方、手腦并用”,我們或許正在見證智能體從“工具”到“伙伴”的質變臨界點。
未來已來,只是尚未均勻分布。?而VLA,正是那把打開未來之門的鑰匙。
Java/python/JavaScript/C/C++/GO最佳實現)





![[特殊字符] UI-Trans:字節跳動發布的多模態 UI 轉換大模型工具,重塑界面智能化未來](http://pic.xiahunao.cn/[特殊字符] UI-Trans:字節跳動發布的多模態 UI 轉換大模型工具,重塑界面智能化未來)







)



)
