YOLOv2講解
一、YOLOv2 整體架構與核心特性
YOLOv2(You Only Look Once v2)于2016年發布,全稱為 YOLO9000(因支持9000類目標檢測),在YOLOv1基礎上進行了多項關鍵改進,顯著提升了檢測精度和速度,同時首次實現了目標檢測與分類的聯合訓練。
二、YOLOv2 網絡結構詳解
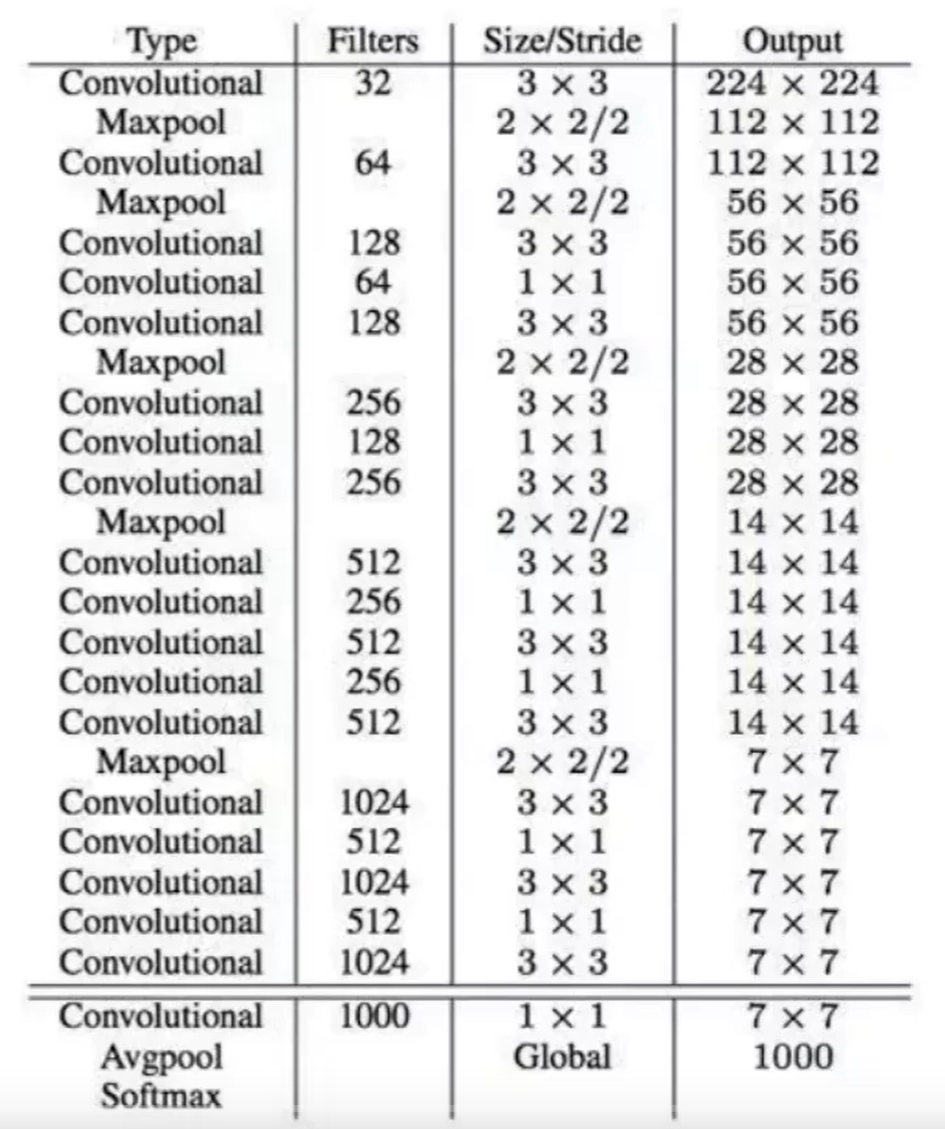
1. 主干網絡:Darknet-19
- 設計目標:相比YOLOv1的Darknet-20,減少計算量并保持精度。
- 結構特點:
- 由19個卷積層和5個最大池化層組成,最終通過全局平均池化輸出特征。
- 卷積層采用 1×1 和 3×3 交替堆疊,降低參數量(YOLOv1為24個卷積層)。
- 引入 批量歸一化(Batch Normalization, BN):所有卷積層后均添加BN,提升收斂速度,減少過擬合。
- 輸出特征:輸入圖像經Darknet-19后,生成 13×13×1024 的特征圖(輸入尺寸為416×416時)。
2. 檢測頭與錨框機制(錨框常也被稱作先驗框)
-
錨框(Anchor Boxes)的引入:
-
YOLOv1問題:直接預測邊界框坐標,缺乏先驗信息,定位精度低。
-
YOLOv2改進:借鑒Faster R-CNN的錨框機制,通過 K-Means聚類 從訓練數據中自動學習錨框尺寸,共生成 5種錨框(YOLOv1無錨框)。
-
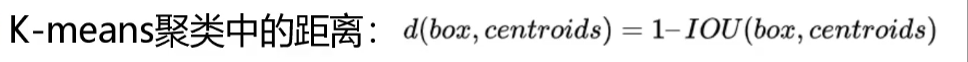
-
優勢:
- 召回率從YOLOv1的81%提升至88%,允許模型預測更多邊界框。
- 簡化網絡學習任務(僅需預測錨框的偏移量和尺度,而非絕對坐標)。
-
-
邊界框預測:
-
放棄YOLOv1的直接坐標預測,采用 邏輯斯蒂回歸 預測錨框的中心坐標偏移量 ( t x , t y ) (t_x, t_y) (tx?,ty?)、尺度 ( t w , t h ) (t_w, t_h) (tw?,th?) 和置信度 t o t_o to?。
-
坐標公式:

-
優勢:通過 σ \sigma σ 函數將中心坐標約束在網格內,避免YOLOv1的坐標預測發散問題。
-
3. 多尺度訓練(Multi-Scale Training)
- YOLOv1問題:固定輸入尺寸為448×448,部署時缺乏靈活性。
- YOLOv2策略:
- 訓練過程中每10 batches隨機選擇輸入尺寸(320×320, 352×352, …, 608×608),步長為32(因下采樣5次,32=2^5)。
- 網絡自動適應不同尺寸,小尺寸下速度更快(如320×320時幀率更高),大尺寸下精度更高。
- 優勢:提升模型泛化能力,無需重新訓練即可適應不同硬件環境。
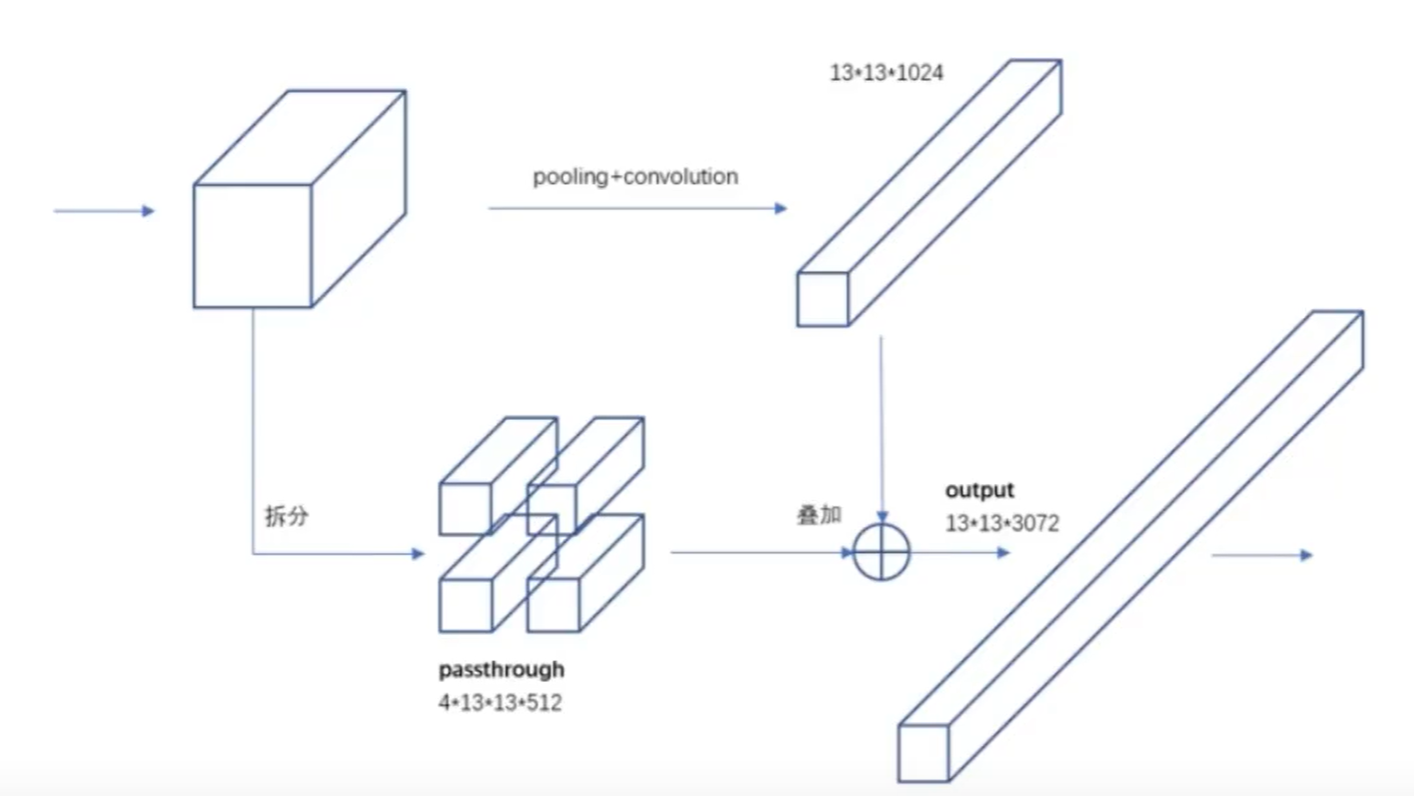
4. 細粒度特征(Fine-Grained Features)與Passthrough層
- YOLOv1問題:僅使用最后一層特征圖(13×13),缺乏細粒度信息,小目標檢測能力弱。
- YOLOv2改進:
- 在Darknet-19后添加 Passthrough層(類似特征金字塔網絡FPN),將前一層26×26×512的特征圖通過 通道疊加(Channel Concatenation)與13×13×1024的特征圖融合。
- 具體操作:將26×26×512的特征圖進行 像素重排列(Pixel Shuffle),轉化為13×13×2048的特征圖,與深層特征結合,增強小目標檢測能力。
5. 更高分辨率的預訓練
- YOLOv1預訓練:在ImageNet上使用224×224分辨率預訓練,檢測時提升至448×448,分辨率跳躍大,導致訓練初期不穩定。
- YOLOv2預訓練:
- 先在ImageNet上用448×448分辨率預訓練10 epochs,再微調檢測任務。
- 優勢:縮小預訓練與檢測階段的分辨率差距,提升特征提取能力。
6. 聯合訓練(Joint Training)與YOLO9000
- 目標:同時訓練檢測數據(如VOC)和分類數據(如ImageNet),擴展檢測類別至9000類。
- 技術實現:
- 分類數據僅含標簽無邊界框,需設計統一輸出格式。
- WordTree結構:將分類標簽構建為樹狀結構(如“狗”包含多個品種),檢測時通過樹結構合并概率分布。
- 損失函數中,檢測樣本計算全部損失,分類樣本僅計算分類損失。
- 效果:成功檢測ImageNet中未標注邊界框的類別(如“蝴蝶”),驗證了聯合訓練的有效性。
三、YOLOv2 對比 YOLOv1 的核心改進
| 改進點 | YOLOv1 | YOLOv2 | 效果/原因 |
|---|---|---|---|
| 主干網絡 | Darknet-20(24卷積層) | Darknet-19(19卷積層+BN) | 減少計算量,BN提升收斂速度,降低過擬合。 |
| 錨框機制 | 無 | 引入5種K-Means聚類錨框 | 召回率從81%→88%,定位精度提升,模型更易優化。 |
| 邊界框預測 | 直接預測絕對坐標 | 預測錨框偏移量+邏輯斯蒂回歸 | 坐標約束在網格內,避免發散,提升穩定性。 |
| 多尺度訓練 | 固定448×448 | 動態調整輸入尺寸(320×320~608×608) | 提升泛化能力,適應不同硬件,兼顧速度與精度。 |
| 細粒度特征融合 | 無 | Passthrough層融合26×26與13×13特征圖 | 增強小目標檢測能力(小目標在淺層特征中更清晰)。 |
| 預訓練分辨率 | 224×224→448×448(跳躍大) | 448×448預訓練+微調 | 減少分辨率差距,特征更貼近檢測任務。 |
| 批量歸一化 | 僅部分層使用 | 所有卷積層后添加BN | 消除Internal Covariate Shift,提升訓練穩定性。 |
| 損失函數 | 定位損失權重固定(λ_coord=5) | 可能調整權重或引入錨框置信度損失 | 未明確文檔,但錨框機制間接優化了損失函數設計。 |
| 數據增強與正則化 | 隨機裁剪、翻轉等 | 增強數據增強(如HSV顏色擾動) | 提升模型對顏色、光照變化的魯棒性。 |
| 檢測類別與訓練策略 | 僅支持VOC等小數據集 | 聯合訓練檢測與分類數據(YOLO9000) | 擴展至9000類,利用海量分類數據提升泛化能力。 |
| 速度與精度平衡 | mAP@VOC2007約63.4%,FPS≈45(GPU) | mAP@VOC2007提升至78.6%,FPS≈67(GPU) | 精度顯著提升,速度因優化結構未下降反升,實現更好的trade-off。 |
四、YOLOv2 性能總結
- 精度:在VOC2007數據集上,mAP從YOLOv1的63.4%提升至78.6%,接近當時領先的Faster R-CNN(78.8%)和SSD(77.2%),但速度更快。
- 速度:在Titan X上,輸入416×416時FPS約67,輸入608×608時FPS約40,兼顧實時性與高精度。
- 創新意義:
- 首次將錨框機制與YOLO結合,奠定后續YOLO系列基礎。
- 多尺度訓練、特征融合等策略成為目標檢測的通用技術。
- YOLO9000開創“弱監督檢測”思路,為大數據場景提供新方向。
五、YOLOv2 的局限性
- 小目標檢測:雖引入Passthrough層,但僅融合一層淺層特征,效果有限(后續YOLOv3通過多尺度特征金字塔進一步優化)。
- 錨框數量:僅使用5種錨框,對復雜場景覆蓋不足(YOLOv3增加至9種)。
- 正負樣本分配:沿用YOLOv1的啟發式分配策略,可能導致訓練低效(后續版本通過IOU閾值或標簽分配算法改進)。
總結
YOLOv2通過錨框機制、多尺度訓練、特征融合、BN等一系列改進,在保持實時性的同時顯著提升了檢測精度,并首次實現了跨數據集的聯合訓練,為YOLO系列的后續發展(如YOLOv3、v4、v5)奠定了關鍵基礎。其設計思路(如平衡速度與精度、數據增強、特征融合)至今仍被廣泛借鑒。
YOLO中的錨框機制(Anchor Boxes)
一、錨框機制的起源與核心思想
錨框(Anchor Boxes) 最早由 Faster R-CNN 提出,用于解決目標檢測中邊界框預測的多樣性問題。YOLO 在 v2版本 中引入錨框機制,顯著提升了檢測精度(尤其是定位精度)。其核心思想是:
- 在特征圖的每個網格(Grid Cell)中預設多個具有不同尺度和比例的邊界框(即錨框),作為目標檢測的“先驗框”。
- 模型通過學習對這些錨框的位置、尺寸進行調整,從而更靈活地預測不同形狀的目標。
二、YOLOv2引入錨框的背景與動機
在 YOLOv1 中,每個網格直接預測邊界框的絕對坐標(x, y, w, h),存在兩大缺陷:
- 定位精度低:直接預測坐標難度大,尤其是對不同尺度的目標泛化能力不足。
- 邊界框多樣性不足:每個網格僅預測2個邊界框,難以覆蓋數據集中目標的多種形狀(如高瘦、寬扁物體)。
YOLOv2引入錨框的目標:
- 通過預設錨框提供邊界框的“先驗信息”,降低模型學習難度。
- 增加邊界框的多樣性,提升召回率(Recall)和定位精度。
三、錨框的生成:K-Means聚類算法
YOLOv2采用 無監督聚類算法 自動確定錨框的尺寸和比例,而非手動設計(如Faster R-CNN),步驟如下:
- 數據準備:使用訓練集中所有真實框(Ground Truth Boxes)的寬高作為輸入。
- 距離度量:定義聚類的距離函數為 1 - IOU(box, centroid),即錨框與真實框的交并比(IOU)越大,距離越近(傳統K-Means使用歐氏距離,不適合邊界框尺寸聚類)。
- 聚類過程:
- 預設聚類中心數量
k(YOLOv2默認k=5,YOLOv3擴展為k=9)。 - 通過迭代更新聚類中心,使所有真實框與最近錨框的IOU均值最大化。
- 預設聚類中心數量
- 優勢:生成的錨框更貼合數據集的目標分布,提升檢測效率。
四、錨框在特征圖上的應用
以 YOLOv2 為例(輸入圖像尺寸為 416×416,輸出特征圖尺寸為 13×13):
-
網格與錨框的對應關系:
- 每個網格負責預測
k個錨框(YOLOv2中k=5)。 - 每個錨框對應一組預測參數:
(t_x, t_y, t_w, t_h, t_o),分別表示:t_x, t_y:錨框中心坐標的偏移量(相對于網格左上角)。t_w, t_h:錨框寬高的縮放因子。t_o:置信度(Confidence),表示錨框內存在目標的概率。
- 每個網格負責預測
-
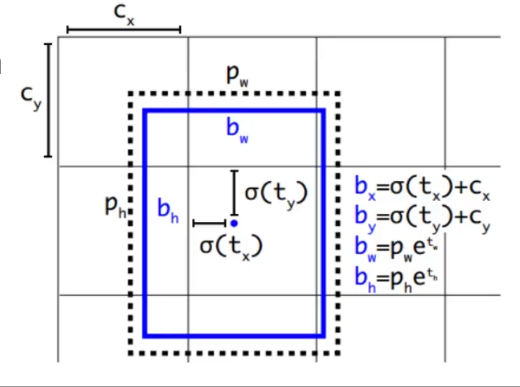
從預測值到真實坐標的轉換:
設某網格的左上角坐標為(c_x, c_y),錨框的先驗寬高為(p_w, p_h),則預測的邊界框坐標計算如下:-
中心坐標:
b x = σ ( t x ) + c x , b y = σ ( t y ) + c y b_x = \sigma(t_x) + c_x, \quad b_y = \sigma(t_y) + c_y bx?=σ(tx?)+cx?,by?=σ(ty?)+cy?
其中,σ為Sigmoid函數,確保b_x, b_y位于當前網格內。 -
寬高:
b w = p w ? e t w , b h = p h ? e t h b_w = p_w \cdot e^{t_w}, \quad b_h = p_h \cdot e^{t_h} bw?=pw??etw?,bh?=ph??eth?通過指數函數允許寬高縮放至任意大小。
-
置信度:
C o n f i d e n c e = σ ( t o ) Confidence = \sigma(t_o) Confidence=σ(to?)
表示預測框與真實框的IOU值(訓練時)或目標存在的概率(推理時)。
-
五、YOLOv2對比YOLOv1:錨框帶來的改進
| 改進點 | YOLOv1 | YOLOv2(引入錨框) |
|---|---|---|
| 邊界框預測方式 | 直接預測絕對坐標 (x, y, w, h) | 基于錨框的偏移量預測 (t_x, t_y, t_w, t_h) |
| 每個網格的邊界框數量 | 2個 | k=5個(通過聚類生成) |
| 召回率(Recall) | 較低(約81%) | 顯著提升(約88%) |
| 定位精度(IOU) | 較低 | 更高(錨框先驗提供更優初始值) |
| 全連接層 | 存在(用于預測坐標) | 移除(全卷積結構,支持任意輸入尺寸) |
| 輸入尺寸 | 固定 448×448 | 調整為 416×416(奇數倍32,確保特征圖有單一中心網格,利于檢測大目標) |
六、YOLOv3中的錨框機制:多尺度預測
YOLOv3進一步擴展錨框機制,引入 多尺度特征圖預測,解決不同尺寸目標的檢測問題:
-
三尺度特征圖:
- 輸入圖像尺寸:
608×608,輸出特征圖尺寸分別為76×76(小目標)、38×38(中目標)、19×19(大目標)。 - 每個尺度對應 3個錨框,共9個錨框(通過聚類生成),分配方式:
- 小目標(
76×76):(10×13), (16×30), (33×23) - 中目標(
38×38):(30×61), (62×45), (59×119) - 大目標(
19×19):(116×90), (156×198), (373×326)
- 小目標(
- 輸入圖像尺寸:
-
多尺度的優勢:
- 小尺度特征圖(如
19×19)感受野大,適合檢測大目標;大尺度特征圖(如76×76)保留更多細節,適合檢測小目標。 - 每個尺度的錨框尺寸與目標尺寸匹配,提升各尺度目標的檢測精度。
- 小尺度特征圖(如
七、錨框機制的訓練與損失函數
-
正負樣本分配:
- 正樣本:與真實框IOU最大的錨框,或IOU超過閾值(如0.5)的錨框(不同實現可能不同)。
- 負樣本:與真實框IOU低于閾值且未被選為正樣本的錨框。
- 忽略樣本:部分實現中,對IOU高但非匹配真實框的錨框不計算損失(如YOLOv3)。
-
損失函數設計:
YOLOv2/v3的損失函數分為三部分:- 坐標損失:預測框與真實框的坐標誤差,通常對小目標賦予更高權重(如使用平方根或對數變換)。
- 置信度損失:正樣本的置信度接近真實IOU,負樣本的置信度接近0,采用二元交叉熵(BCE)損失。
- 類別損失:僅對正樣本計算類別概率損失,同樣使用BCE或交叉熵損失。
八、錨框機制的優缺點與爭議
-
優點:
- 提供邊界框先驗,降低模型學習難度,提升定位精度。
- 通過聚類適應不同數據集,增強泛化能力。
- 多尺度錨框結合特征金字塔,提升對不同尺寸目標的檢測能力。
-
缺點:
- 錨框數量和尺寸需手動或自動確定,對小目標檢測仍需優化(如增加小錨框數量)。
- 計算量隨錨框數量增加而上升(但YOLO通過輕量級主干網絡緩解)。
-
爭議與后續發展:
部分無錨框(Anchor-Free)檢測器(如CenterNet、YOLOv8-NAS)嘗試摒棄錨框,直接預測目標中心點和尺寸,避免錨框設計的復雜性,但錨框機制在YOLO系列中仍為核心技術之一。
九、總結:錨框機制的技術價值
錨框機制是YOLO從v1到v2/v3進化的關鍵創新,其核心貢獻包括:
- 引入先驗知識:通過聚類生成的錨框貼合數據分布,提升邊界框初始化質量。
- 提升多樣性與召回率:每個網格預測多個錨框,覆蓋更多目標形狀,避免YOLOv1的邊界框匱乏問題。
- 多尺度擴展基礎:為YOLOv3的多尺度檢測提供了框架,結合特征金字塔網絡(FPN),成為現代目標檢測的標配技術。
通過錨框機制,YOLO在保持速度優勢的同時,顯著提升了檢測精度,奠定了其在實時檢測領域的地位。
我們大部分時間都在害怕失敗與拒絕,但后悔或許才是最該害怕的事。 —特雷弗·諾亞




)



)










