目錄
1. 搜索引擎的相關宏觀原理
2. 正排索引 vs 倒排索引 - 搜索引擎具體原理
3. 編寫數據去標簽與數據清洗的模塊 Parser
去標簽
編寫parser
用boost枚舉文件名
解析html
提取title
?編輯?去標簽
構建URL
將解析內容寫入文件中
4. 編寫建立索引的模塊 Index
建立正排的基本代碼
建立倒排的基本代碼
?5.? 編寫索引模塊 Searcher
安裝jsoncpp
獲取摘要
代碼
去重后的代碼
測試
編寫http_server 模塊
基本使用測試
簡單編寫日志
編寫前端模塊
成品
搜索展示
項目源碼:https://gitee.com/uyeonashi/boost
1. 搜索引擎的相關宏觀原理
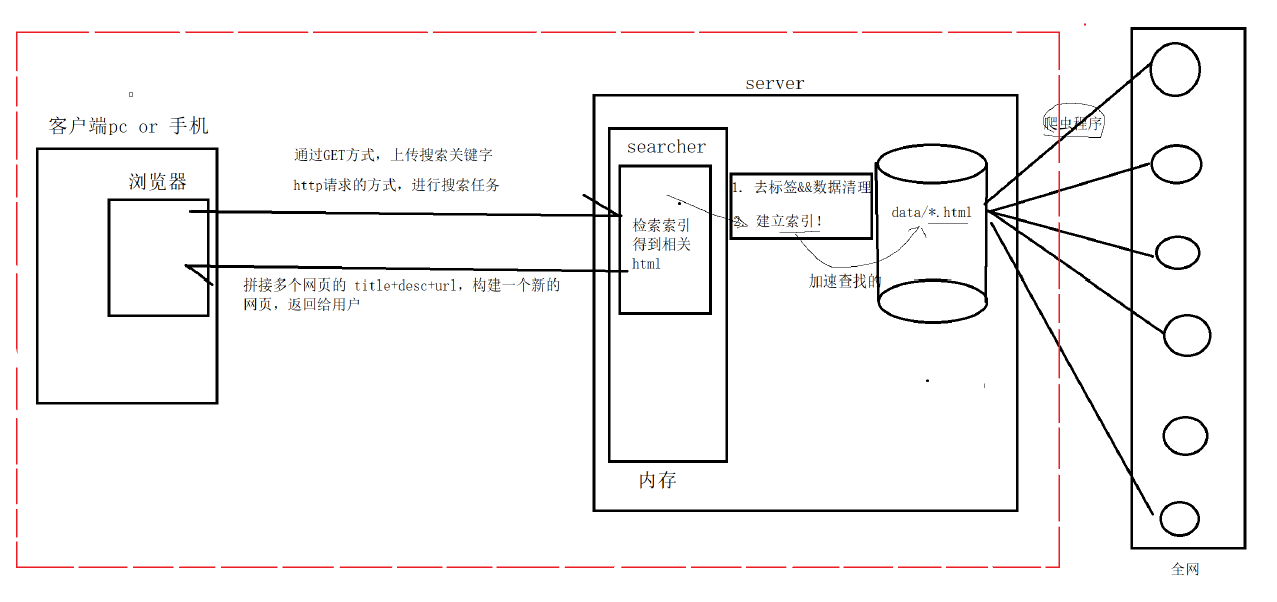
搜索引擎技術棧和項目環境?
? 技術棧: C/C++ C++11, STL, 準標準庫Boost,Jsoncpp,cppjieba,cpp-httplib ,
? 項目環境: Ubuntu22.04,vim/gcc(g++)/Makefile ,?vs code
2. 正排索引 vs 倒排索引 - 搜索引擎具體原理
? 文檔1: 雷軍買了四斤小米
? 文檔2: 雷軍發布了小米手機
| 文檔ID | 文檔內容 |
| 1 | 雷軍買了四斤小米 |
| 2 | 雷軍發布了小米手機 |
目標文檔進行分詞(目的:方便建立倒排索引和查找):
????????? 文檔1[雷軍買了四斤小米 ]: 雷軍/買/四斤/小米/四斤小米
????????? 文檔2[雷軍發布了小米手機]:雷軍/發布/小米/小米手機
停止詞:了,的,嗎,a,the,一般我們在分詞的時候可以不考慮
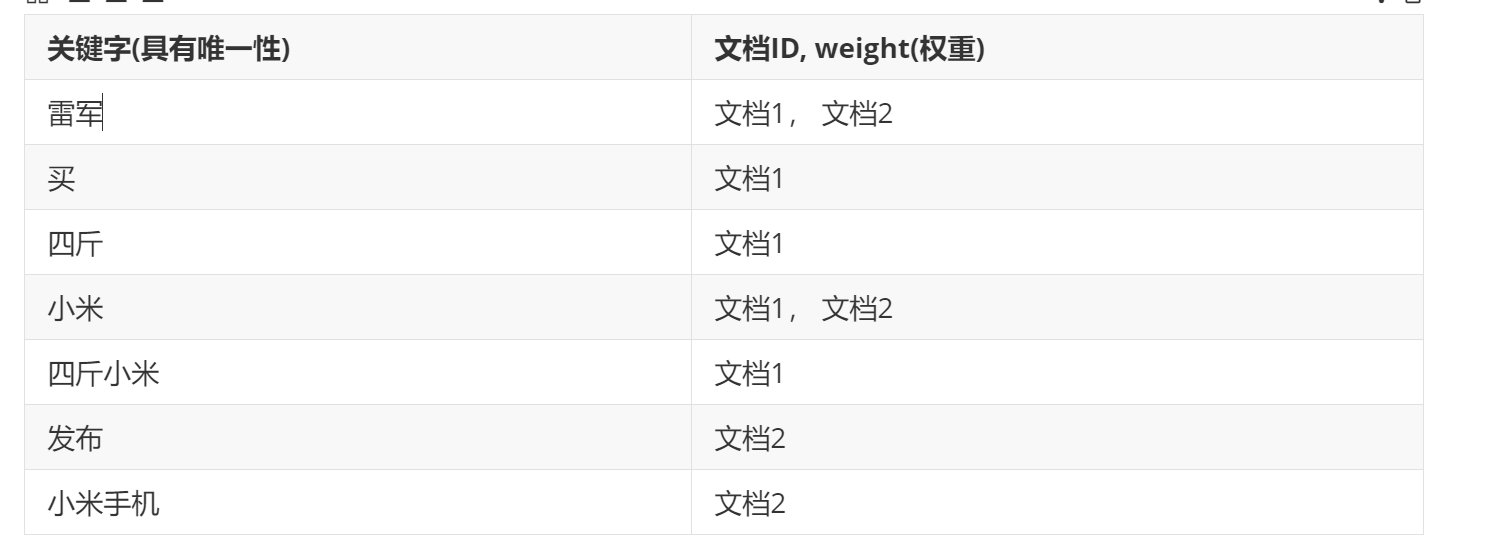
?倒排索引:根據文檔內容,分詞,整理不重復的各個關鍵字,對應聯系到文檔ID的方案
| 關鍵字(具有唯一性) | 文檔id,weight權重 |
| 雷軍 | 文檔1, 文檔2 |
| 買 | 文檔1 |
| 四斤 | 文檔1 |
| 小米 | 文檔1, 文檔2 |
| 四斤小米???????? | 文檔1 |
| 小米手機 | 文檔2 |
模擬一次查找的過程:
用戶輸入:小米 -> 倒排索引中查找 -> 提取出文檔ID(1,2) -> 根據正排索引 -> 找到文檔的內容 -> title+conent(desc)+url 文檔結果進行摘要 -> 構建響應結果
3. 編寫數據去標簽與數據清洗的模塊 Parser
boost 官網:https://www.boost.org/
下載一個最新版的即可
//目前只需要boost_1_88_0/doc/html目錄下的html文件,用它來進行建立索引
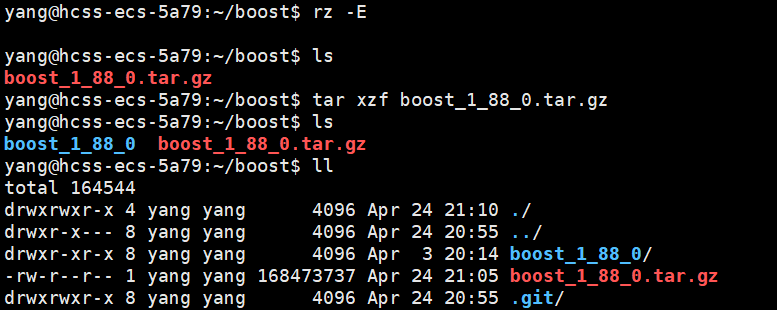

![]()
現在搜索源就在data中了,我們拼接一下即可
去標簽
? touch parser.cc
//原始數據 -> 去標簽之后的數據 (隨便截取一段舉個例子)
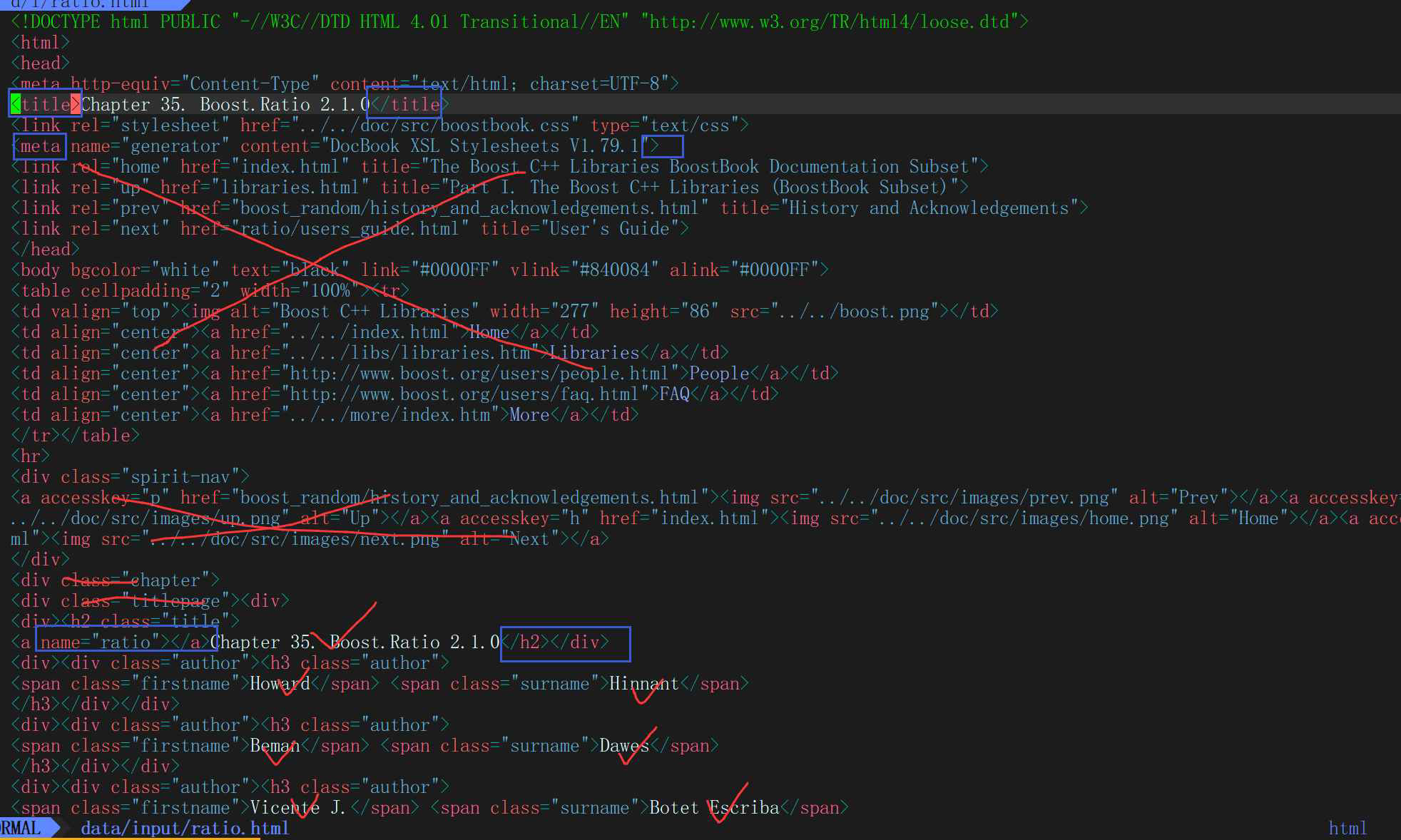
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html> <!--這是一個標簽-->
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Chapter 30. Boost.Process</title>
<link rel="stylesheet" href="../../doc/src/boostbook.css" type="text/css">
<meta name="generator" content="DocBook XSL Stylesheets V1.79.1">
<link rel="home" href="index.html" title="The Boost C++ Libraries BoostBook
Documentation Subset">
<link rel="up" href="libraries.html" title="Part I. The Boost C++ Libraries
(BoostBook Subset)">
<link rel="prev" href="poly_collection/acknowledgments.html"
title="Acknowledgments">
<link rel="next" href="boost_process/concepts.html" title="Concepts">
</head>
<body bgcolor="white" text="black" link="#0000FF" vlink="#840084"
alink="#0000FF">
<table cellpadding="2" width="100%"><tr>
<td valign="top"><img alt="Boost C++ Libraries" width="277" height="86"
src="../../boost.png"></td>
<td align="center"><a href="../../index.html">Home</a></td>
<td align="center"><a href="../../libs/libraries.htm">Libraries</a></td>
<td align="center"><a href="http://www.boost.org/users/people.html">People</a>
</td>
<td align="center"><a href="http://www.boost.org/users/faq.html">FAQ</a></td>
<td align="center"><a href="../../more/index.htm">More</a></td>
</tr></table>
.........
// <> : html的標簽,這個標簽對我們進行搜索是沒有價值的,需要去掉這些標簽,一般標簽都是成對出現的!yang@hcss-ecs-5a79:~/boost$ cd data
yang@hcss-ecs-5a79:~/boost/data$ mkdir raw_html
yang@hcss-ecs-5a79:~/boost/data$ ll
drwxrwxr-x 56 yang yang 12288 Apr 24 21:27 input/ //這里放的是原始的html文檔
drwxrwxr-x 2 yang yang 4096 Apr 24 21:37 raw_html/ //這是放的是去標簽之后的干凈文檔yang@hcss-ecs-5a79:~/boost/data$ ls -Rl | grep -E '*.html' | wc -l
8637目標:把每個文檔都去標簽,然后寫入到同一個文件中!每個文檔內容不需要任何\n!文檔和文檔之間用 \3 區分
version1:
類似:XXXXXXXXXXXXXXXXX\3YYYYYYYYYYYYYYYYYYYYY\3ZZZZZZZZZZZZZZZZZZZZZZZZZ\3采用下面的方案:
version2: 寫入文件中,一定要考慮下一次在讀取的時候,也要方便操作!
類似:title\3content\3url \n title\3content\3url \n title\3content\3url \n ...方便我們getline(ifsream, line),直接獲取文檔的全部內容:title\3content\3url編寫parser
先將代碼結構羅列出來
#include <iostream>
#include <string>
#include <vector>//是一個目錄,下面放的就是所以的html網頁
const std::string src_path = "data/intput/";
const std::string output = "data/raw_html/raw.txt";typedef struct DocInfo
{std::string title; //文檔的標題std::string content; //文檔的內容std::string url; //該文檔在官網中的url
}DocInfo_t;bool EnumFile(const std::string &stc_path,std::vector<std::string> *file_lists);
bool ParseHtml(const std::vector<std::string> &file_lists,std::vector<DocInfo_t> *result);
bool SaveHtml(const std::vector<DocInfo_t> &result,const std::string &output);int main()
{std::vector<std::string> files_list;//第一步:遞歸式的吧每個html文件名帶路徑,保存到files_list中,方便后期進行一個一個的文件進行讀取if(!EnumFile(src_path,&files_list)){std::cerr << "enum file name error!" << std::endl;return 1;}//第二步:按照files_list讀取每個文件的內容,并進行解析std::vector<DocInfo_t> result;if(!ParseHtml(files_list,&result)){std::cout << "parse html error" << std::endl;return 2;}//第三步:把解析完畢的各個文件內容,寫入到output,按照/3最為文檔的分割符if(!SaveHtml(result,output)){std::cerr << "save html error" << std::endl;return 3;}
}boost 開發庫的安裝
因為這里我們需要用到boost庫中的功能
sudo apt-get install libboost-all-dev用boost枚舉文件名
//枚舉文件名
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list)
{namespace fs = boost::filesystem;fs::path root_path(src_path);//判斷路徑是否存在,不存在,就沒有必要再往后走了if(!fs::exists(root_path)){std::cerr << src_path << " not exists" << std::endl;return false;}//定義一個空的迭代器,用來進行判斷遞歸結束fs::recursive_directory_iterator end;for(fs::recursive_directory_iterator iter(root_path); iter != end; iter++){//判斷文件是否是普通文件,html都是普通文件if(!fs::is_regular_file(*iter))continue;if(iter->path().extension() != ".html")//判斷文件路徑名的后綴是否符合要求continue;std::cout << "debug: " << iter->path().string() << std::endl;//當前的路徑一定是一個合法的,以.html結束的普通網頁文件files_list->push_back(iter->path().string()); //將所有帶路徑的html保存在files_list,方便后續進行文本分析}return true;
}解析html
先把結構列出
//枚舉文件名
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list)
{namespace fs = boost::filesystem;fs::path root_path(src_path);//判斷路徑是否存在,不存在,就沒有必要再往后走了if(!fs::exists(root_path)){std::cerr << src_path << " not exists" << std::endl;return false;}//定義一個空的迭代器,用來進行判斷遞歸結束fs::recursive_directory_iterator end;for(fs::recursive_directory_iterator iter(root_path); iter != end; iter++){//判斷文件是否是普通文件,html都是普通文件if(!fs::is_regular_file(*iter))continue;if(iter->path().extension() != ".html")//判斷文件路徑名的后綴是否符合要求continue;std::cout << "debug: " << iter->path().string() << std::endl;//當前的路徑一定是一個合法的,以.html結束的普通網頁文件files_list->push_back(iter->path().string()); //將所有帶路徑的html保存在files_list,方便后續進行文本分析}return true;
}提取title
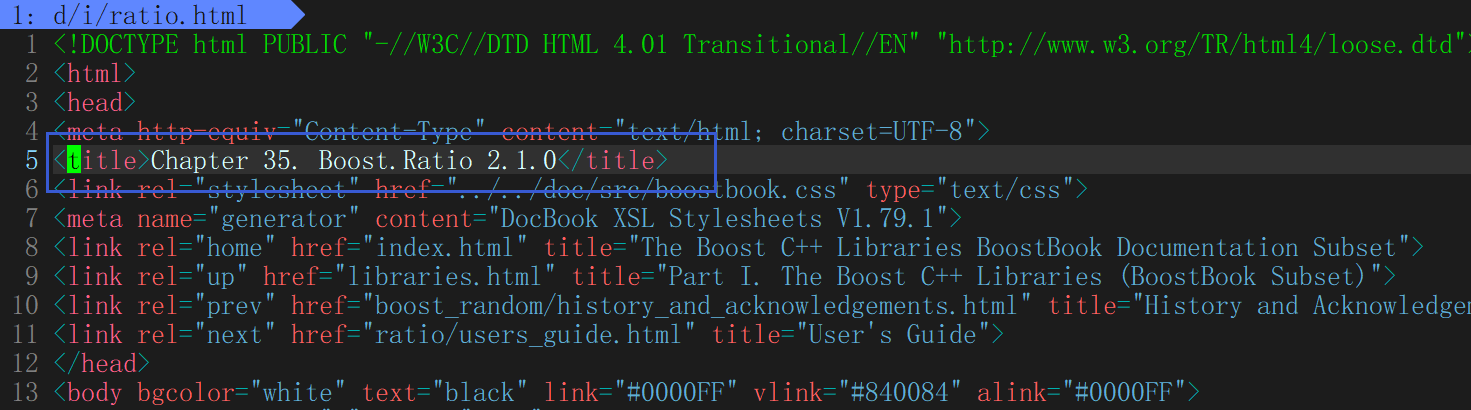
用string 找?< >,?找到title的起始位置,前閉后開,找到的是中間的位置
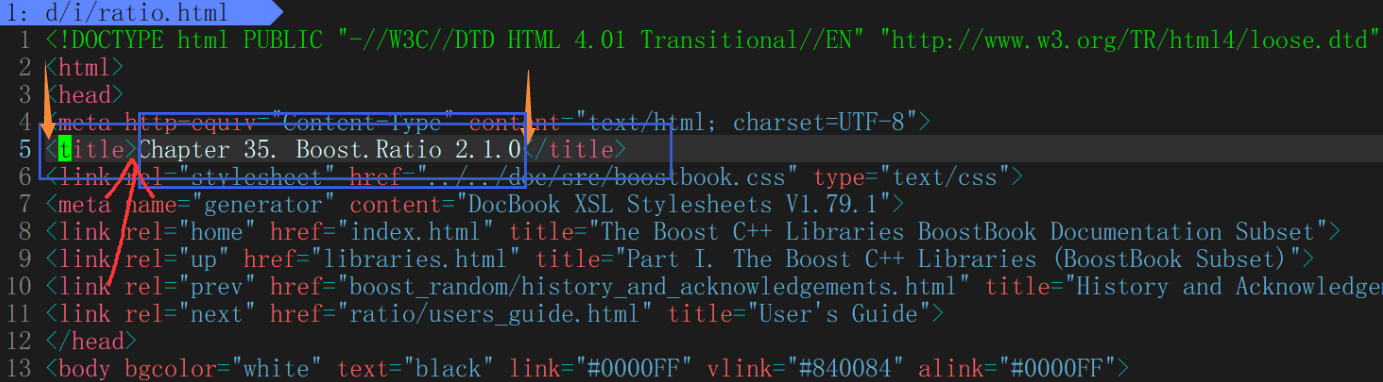 ?去標簽
?去標簽
提取content,本質是進行去標簽,只保留有效字段
?在進行遍歷的時候,只要碰到了 > ,就意味著,當前的標簽被處理完畢.;只要碰到了< 意味著新的標簽開始了
構建URL
boost庫的官方文檔,和我們下載下來的文檔,是有路徑的對應關系的
官網URL樣例:
https://www.boost.org/doc/libs/1_78_0/doc/html/accumulators.html我們下載下來的url樣例:boost_1_78_0/doc/html/accumulators.html我們拷貝到我們項目中的樣例:data/input/accumulators.html //我們把下載下來的boost庫doc/html/* copy data/input/url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html";
url_tail = [data/input](刪除) /accumulators.html -> url_tail = /accumulators.htmlurl = url_head + url_tail ; 相當于形成了一個官網鏈接static bool ParseUrl(const std::string &file_path,std::string *url)
{std::string url_head = "https://www.boost.org/doc/libs/1_88_0/doc/html";std::string url_tail = file_path.substr(src_path.size());*url = url_head + url_tail;return true;
}將解析內容寫入文件中
//見代碼
采用下面的方案:
version2: 寫入文件中,一定要考慮下一次在讀取的時候,也要方便操作!
類似:title\3content\3url \n title\3content\3url \n title\3content\3url \n ...
方便我們getline(ifsream, line),直接獲取文檔的全部內容:title\3content\3urlbool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{
#define SEP '\3'//按照二進制方式寫入std::ofstream out(output,std::ios::out | std::ios::binary);if(!out.is_open()){std::cerr << "open " << output << std::endl;return false;}//就可以進行文件內容的攜入了for(auto &item : results){std::string out_string;out_string = item.title;out_string += SEP;out_string += item.content;out_string += SEP;out_string += item.url;out_string += '\n';out.write(out_string.c_str(),out_string.size());}out.close();return true;
}4. 編寫建立索引的模塊 Index
先把基本結構搭建出
#pragma once
#include <iostream>
#include<vector>
#include<string>
#include<unordered_map>namespace ns_index
{struct DocInfo{std::string title; //標題std::string content; //文檔去標簽后的內容std::string url;uint64_t doc_id; //文檔的ID};struct InvertedElem{uint64_t doc_id;std::string word;int weight;};//倒排拉鏈typedef std::vector<InvertedElem> InvertedList;class Index{public:Index(){}~Index(){}public:DocInfo *GetForwardIndex(uint64_t doc_id){return nullptr;}//根據關鍵字string,獲得倒排拉鏈InvertedList * GetForwardIndex(const std::string &word){return nullptr;}//根據去標簽,格式化之后的文檔,構建正排和倒排索引//data/raw_html/raw.txtbool BuildIndex(const std::string &input) //parse處理完的數據交給我{}private://正排索引的數據結構用數組,數組下標天然石文檔的IDstd::vector<DocInfo> forward_index; //正排索引//倒排索引一定是一個關鍵字和一組InvertedElem對應(關鍵字和倒排拉鏈的映射關系)std::unordered_map<std::string,InvertedList> inverted_index;};
}建立正排的基本代碼
DocInfo *BuildForwardIndex(const std::string &line)
{//1. 解析line,字符串切分//line -> 3 string, title, content, urlstd::vector<std::string> results;const std::string sep = "\3"; //行內分隔符ns_util::StringUtil::CutString(line, &results, sep);//ns_util::StringUtil::CutString(line, &results, sep);if(results.size() != 3)return nullptr;//2. 字符串進行填充到DocIinfoDocInfo doc;doc.title = results[0]; //titledoc.content = results[1]; //contentdoc.url = results[2]; ///url//先進行保存id,在插入,對應的id就是當前doc在vector中的下標!doc.doc_id = forward_index.size();//3. 插入到正排索引的vectorforward_index.push_back(std::move(doc)); //doc,html文件內容return &forward_index.back();
}建立倒排的基本代碼
//原理:
struct InvertedElem
{uint64_t doc_id;std::string word;int weight;
};//倒排拉鏈
typedef std::vector<InvertedElem> InvertedList;
//倒排索引一定是一個關鍵字和一組(個)InvertedElem對應[關鍵字和倒排拉鏈的映射關系]
std::unordered_map<std::string, InvertedList> inverted_index;//我們拿到的文檔內容
struct DocInfo
{std::string title; //文檔的標題std::string content; //文檔對應的去標簽之后的內容std::string url; //官網文檔urluint64_t doc_id; //文檔的ID,暫時先不做過多理解
};
//文檔:
title : 吃葡萄
content: 吃葡萄不吐葡萄皮
url: http://XXXX
doc_id: 123根據文檔內容,形成一個或者多個InvertedElem(倒排拉鏈)
因為當前我們是一個一個文檔進行處理的,一個文檔會包含多個”詞“, 都應當對應到當前的doc_id1. 需要對 title && content都要先分詞 --使用jieba分詞
title: 吃/葡萄/吃葡萄(title_word)
content:吃/葡萄/不吐/葡萄皮(content_word)詞和文檔的相關性(詞頻:在標題中出現的詞,可以認為相關性更高一些,在內容中出現相關性低一些
2. 詞頻統計
struct word_cnt
{title_cnt;content_cnt;
}
unordered_map<std::string, word_cnt> word_cnt;
for &word : title_word
{word_cnt[word].title_cnt++; //吃(1)/葡萄(1)/吃葡萄(1)
}
for &word : content_word
{word_cnt[word].content_cnt++; //吃(1)/葡萄(1)/不吐(1)/葡萄皮(1)
}知道了在文檔中,標題和內容每個詞出現的次數
3. 自定義相關性
for &word : word_cnt
{
//具體一個詞和123文檔的對應關系,當有多個不同的詞,指向同一個文檔的時候,此時該優先顯示誰??相關性!struct InvertedElem elem;elem.doc_id = 123;elem.word = word.first;elem.weight = 10*word.second.title_cnt + word.second.content_cnt ; //相關性inverted_index[word.first].push_back(elem);
}//jieba的使用--cppjieba
獲取鏈接:https://gitcode.com/gh_mirrors/cp/cppjieba
如何使用:源代碼都寫進頭文件include/cppjieba/*.hpp里,include即可使用
?如何使用:注意細節,我們需要自己執行: cp -rf deps/limonp include/cppjieba/
也就是說要將limonp移到cppjieba目錄下,不然會報錯
//使用 demo.cpp
#include "inc/cppjieba/Jieba.hpp"
#include <iostream>
#include <string>
#include <vector>
using namespace std;const char* const DICT_PATH = "./dict/jieba.dict.utf8";
const char* const HMM_PATH = "./dict/hmm_model.utf8";
const char* const USER_DICT_PATH = "./dict/user.dict.utf8";
const char* const IDF_PATH = "./dict/idf.utf8";
const char* const STOP_WORD_PATH = "./dict/stop_words.utf8";int main(int argc, char** argv)
{cppjieba::Jieba jieba(DICT_PATH,HMM_PATH,USER_DICT_PATH,IDF_PATH,STOP_WORD_PATH);vector<string> words;string s;s = "小明碩士畢業于中國科學院計算所,后在日本京都大學深造";cout << s << endl;cout << "[demo] CutForSearch" << endl;jieba.CutForSearch(s, words);cout << limonp::Join(words.begin(), words.end(), "/") << endl;return EXIT_SUCCESS;
} bool BuildForwardIndex(const DocInfo &doc){//DoInfo(title,content,url,doc_id)//word->倒排拉鏈struct word_cnt{int title_cnt;int content_cnt;word_cnt():title_cnt(0),content_cnt(0){}};std::unordered_map<std::string,word_cnt> word_map; //用來暫存詞頻的映射表//對標題進行分詞std::vector<std::string> title_words;ns_util::JiebaUtil::CutString(doc.title,&title_words);//對標題詞頻進行統計for(auto &s : title_words){word_map[s].title_cnt++;//如果存在就獲取,不存在就新建}//對文檔內容進行分詞std::vector<std::string> content_words;ns_util::JiebaUtil::CutString(doc.content,&content_words);//對內容進行詞頻統計std::unordered_map<std::string,word_cnt> concent_map;for(auto &c : content_words){word_map[c].content_cnt++;}#define X 10#define Y 1for(auto &word_pair : word_map){InvertedElem item;item.doc_id = doc.doc_id;item.word = word_pair.first;item.weight = X*word_pair.second.title_cnt + Y*word_pair.second.content_cnt;InvertedList &inverted_list = inverted_index[word_pair.first];inverted_list.push_back(item);}return true;}?5.? 編寫索引模塊 Searcher
先把基本代碼結構搭建出來
namespace ns_seracher
{class Searcher{public:Searcher() {} ~Searcher() {}public:void InitSercher(const std::string &input){//1. 獲取或者創建Index對象//2. 根據index對象建立索引}void Search(const std::string &queue, std::string *ison String){//1. [分詞]:對我們的query進行按照searcher的要求進行分詞//2. [觸發]:就是根據分詞的各個“詞”,進行index查找//3. [合并]:匯總查找結果,按照相關性(weight)降序排序//4. [構建]: 根據查找出來的結果,構建json串 -- jsoncpp}private:ns_index::Index *index; //索引};
}
搜索:雷軍小米 -> 雷軍、小米->查倒排->兩個倒排拉鏈(文檔1,文檔2,文檔1、文檔2)
安裝jsoncpp
sudo apt-get install libjsoncpp-dev具體實現代碼?
https://gitee.com/uyeonashi/boost
獲取摘要
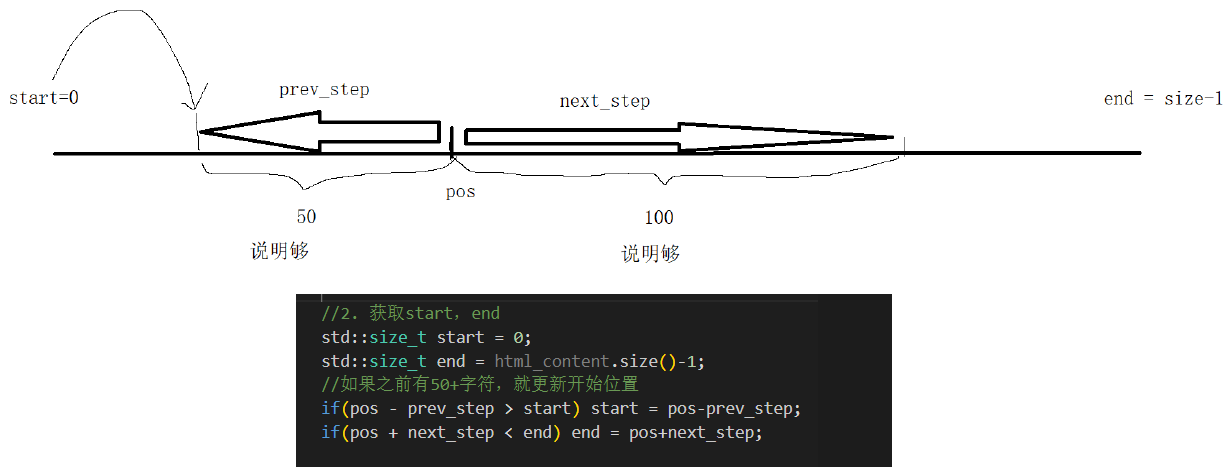
注意定義start和end雙指針的時候,要注意size_t類型與int類型的符號比較,很容易出錯!
- 由于size_t是無符號類型,如果使用不當(比如使用負數做運算),可能會導致意想不到的結果。例如,將負數賦值給size_t會導致它變成一個很大的正數。
代碼
std::string GetDesc(const std::string &html_content, const std::string &word)
{// 找到word在html_content中的首次出現,然后往前找50字節(如果沒有,從begin開始),往后找100字節(如果沒有,到end就可以的)// 截取出這部分內容const int prev_step = 50;const int next_step = 100;// 1. 找到首次出現// 不能使用find查找,可能因為大小寫不匹配而報錯auto iter = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y){ return (std::tolower(x) == std::tolower(y)); });if (iter == html_content.end()){return "None1";}int pos = std::distance(html_content.begin(), iter);// 2. 獲取start,end , std::size_t 無符號整數int start = 0;int end = html_content.size() - 1;// 如果之前有50+字符,就更新開始位置if (pos > start + prev_step)start = pos - prev_step;if (pos < end - next_step)end = pos + next_step;// 3. 截取子串,returnif (start >= end)return "None2";std::string desc = html_content.substr(start, end - start);desc += "...";return desc;
}比如我們在搜索“你是一個好人”時,jieba會將該語句分解為你/一個/好人/一個好人,在建立圖的時候,可能會指向同一個文檔,導致我們在搜索的時候會出現重復的結果。
所以我們要做去重操作,如何判斷相同呢?直接看文檔id即可。并且要將權值修改,我們應該將搜索到的相同內容進行權值的累加,作為該文檔的真正權值!
去重后的代碼
#pragma once#include "index.hpp"
#include "util.hpp"
#include "log.hpp"
#include <algorithm>
#include <unordered_map>
#include <jsoncpp/json/json.h>namespace ns_searcher
{struct InvertedElemPrint{uint64_t doc_id;int weight;std::vector<std::string> words;InvertedElemPrint() : doc_id(0), weight(0) {}};class Searcher{private:ns_index::Index *index; // 供系統進行查找的索引public:Searcher() {}~Searcher() {}public:void InitSearcher(const std::string &input){// 1. 獲取或者創建index對象index = ns_index::Index::GetInstance();std::cout << "獲取index單例成功..." << std::endl;// LOG(NORMAL, "獲取index單例成功...");// 2. 根據index對象建立索引index->BuildIndex(input);std::cout << "建立正排和倒排索引成功..." << std::endl;// LOG(NORMAL, "建立正排和倒排索引成功...");}// query: 搜索關鍵字// json_string: 返回給用戶瀏覽器的搜索結果void Search(const std::string &query, std::string *json_string){// 1.[分詞]:對我們的query進行按照searcher的要求進行分詞std::vector<std::string> words;ns_util::JiebaUtil::CutString(query, &words);// 2.[觸發]:就是根據分詞的各個"詞",進行index查找,建立index是忽略大小寫,所以搜索,關鍵字也需要// ns_index::InvertedList inverted_list_all; //內部InvertedElemstd::vector<InvertedElemPrint> inverted_list_all;std::unordered_map<uint64_t, InvertedElemPrint> tokens_map;for (std::string word : words){boost::to_lower(word);ns_index::InvertedList *inverted_list = index->GetInvertedList(word);if (nullptr == inverted_list){continue;}// 不完美的地方: 你/是/一個/好人 100// inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());for (const auto &elem : *inverted_list){auto &item = tokens_map[elem.doc_id]; //[]:如果存在直接獲取,如果不存在新建// item一定是doc_id相同的print節點item.doc_id = elem.doc_id;item.weight += elem.weight;item.words.push_back(elem.word);}}for (const auto &item : tokens_map){inverted_list_all.push_back(std::move(item.second));}// 3.[合并排序]:匯總查找結果,按照相關性(weight)降序排序// std::s ort(inverted_list_all.begin(), inverted_list_all.end(),\// [](const ns_index::InvertedElem &e1, const ns_index::InvertedElem &e2){// return e1.weight > e2.weight;// });std::sort(inverted_list_all.begin(), inverted_list_all.end(),[](const InvertedElemPrint &e1, const InvertedElemPrint &e2){return e1.weight > e2.weight;});// 4.[構建]:根據查找出來的結果,構建json串 -- jsoncpp --通過jsoncpp完成序列化&&反序列化Json::Value root;for (auto &item : inverted_list_all){ns_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);if (nullptr == doc){continue;}Json::Value elem;elem["title"] = doc->title;elem["desc"] = GetDesc(doc->content, item.words[0]); // content是文檔的去標簽的結果,但是不是我們想要的,我們要的是一部分 TODOelem["url"] = doc->url;// for deubg, for deleteelem["id"] = (int)item.doc_id;elem["weight"] = item.weight; // int->stringroot.append(elem);}Json::StyledWriter writer;// Json::FastWriter writer;*json_string = writer.write(root);}std::string GetDesc(const std::string &html_content, const std::string &word){// 找到word在html_content中的首次出現,然后往前找50字節(如果沒有,從begin開始),往后找100字節(如果沒有,到end就可以的)// 截取出這部分內容const int prev_step = 50;const int next_step = 100;// 1. 找到首次出現// 不能使用find查找,可能因為大小寫不匹配而報錯auto iter = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y){ return (std::tolower(x) == std::tolower(y)); });if (iter == html_content.end()){return "None1";}int pos = std::distance(html_content.begin(), iter);// 2. 獲取start,end , std::size_t 無符號整數int start = 0;int end = html_content.size() - 1;// 如果之前有50+字符,就更新開始位置if (pos > start + prev_step)start = pos - prev_step;if (pos < end - next_step)end = pos + next_step;// 3. 截取子串,returnif (start >= end)return "None2";std::string desc = html_content.substr(start, end - start);desc += "...";return desc;}};
}測試
每寫一個模塊,最好都要測試一下不然最后bug成群
測試代碼
#include "seracher.hpp"
#include <cstdio>
#include <cstring>
#include <iostream>
#include <string>const std::string input = "data/raw_html/raw.txt";int main()
{ns_seracher::Searcher *search = new ns_seracher::Searcher();search->InitSercher(input);std::string query;std::string json_string;char buffer[1024];while (true){std::cout << "Plase Enter Your Search Query# ";fgets(buffer,sizeof(buffer)-1,stdin);buffer[strlen(buffer)-1] = 0;query = buffer;search->Search(query,&json_string);std::cout << json_string << std::endl;}return 0;
}編譯然后運行,查看
編寫http_server 模塊
我們這里不用自己去搭建輪子,直接用網上的cpp-httplib庫即可搭建網絡通信。
所以我們只要會使用基本的接口即可
cpp-httplib庫:https://gitee.com/royzou/cpp-httplib
注意:cpp-httplib在使用的時候需要使用較新版本的gcc
基本使用測試
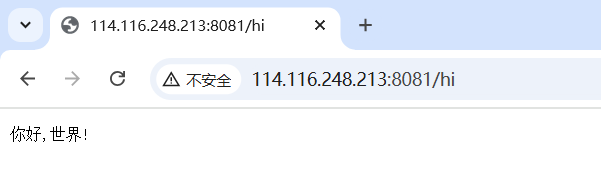
#include"httplib.h"int main()
{httplib::Server svr;svr.Get("/hi", [](const httplib::Request &req, httplib::Response &rsp){rsp.set_content("你好,世界!", "text/plain; charset=utf-8");});svr.listen("0.0.0.0",8081);return 0;
}
編寫一個簡單的前端做測試
#include"httplib.h"const std::string root_path = "./wwwroot";int main()
{httplib::Server svr;svr.set_base_dir(root_path.c_str());svr.Get("/hi", [](const httplib::Request &req, httplib::Response &rsp){rsp.set_content("你好,世界!", "text/plain; charset=utf-8");});svr.listen("0.0.0.0",8081);return 0;
}<!DOCTYPE html><html>
<head><meta charset="UTF-8"><title>for test</title>
</head>
<body><h1>你好,世界</h1><p>這是一個測試網頁</p>
</body>
</html>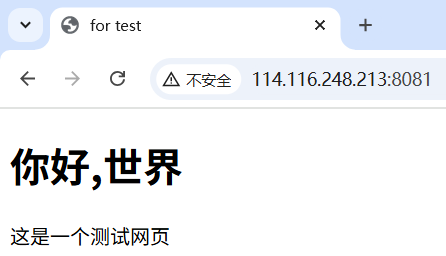
#include"httplib.h"
#include "seracher.hpp"const std::string input = "data/raw_html/raw.txt";
const std::string root_path = "./wwwroot";int main()
{ns_seracher::Searcher search;search.InitSercher(input);httplib::Server svr;svr.set_base_dir(root_path.c_str());svr.Get("/s", [&search](const httplib::Request &req, httplib::Response &rsp){if(!req.has_param("word")){rsp.set_content("要有搜索關鍵詞!","text/plain: charset=utf-8");return;}std::string word = req.get_param_value("word");std::cout << "用戶在搜索:" << word << std::endl;std::string json_string;search.Search(word,&json_string);rsp.set_content(json_string,"application/json"); // rsp.set_content("你好,世界!", "text/plain; charset=utf-8");});svr.listen("0.0.0.0",8081);return 0;
}簡單編寫日志
#pragma once#include <iostream>
#include <string>
#include <ctime>#define NORMAL 1
#define WARNING 2
#define DEBUG 3
#define FATAL 4#define LOG(LEVEL, MESSAGE) log(#LEVEL, MESSAGE, __FILE__, __LINE__)void log(std::string level, std::string message, std::string file, int line)
{std::cout << "[" << level << "]" << "[" << time(nullptr) << "]" << "[" << message << "]" << "[" << file << " : " << line << "]" << std::endl;
}
編寫前端模塊
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><script src="http://code.jquery.com/jquery-2.1.1.min.js"></script><title>boost 搜索引擎</title><style>/* 去掉網頁中的所有的默認內外邊距,html的盒子模型 */* {/* 設置外邊距 */margin: 0;/* 設置內邊距 */padding: 0;}/* 將我們的body內的內容100%和html的呈現吻合 */html,body {height: 100%;}/* 類選擇器.container */.container {/* 設置div的寬度 */width: 800px;/* 通過設置外邊距達到居中對齊的目的 */margin: 0px auto;/* 設置外邊距的上邊距,保持元素和網頁的上部距離 */margin-top: 15px;}/* 復合選擇器,選中container 下的 search */.container .search {/* 寬度與父標簽保持一致 */width: 100%;/* 高度設置為52px */height: 52px;}/* 先選中input標簽, 直接設置標簽的屬性,先要選中, input:標簽選擇器*//* input在進行高度設置的時候,沒有考慮邊框的問題 */.container .search input {/* 設置left浮動 */float: left;width: 600px;height: 50px;/* 設置邊框屬性:邊框的寬度,樣式,顏色 */border: 1px solid black;/* 去掉input輸入框的有邊框 */border-right: none;/* 設置內邊距,默認文字不要和左側邊框緊挨著 */padding-left: 10px;/* 設置input內部的字體的顏色和樣式 */color: #000be2;font-size: 14px;}/* 先選中button標簽, 直接設置標簽的屬性,先要選中, button:標簽選擇器*/.container .search button {/* 設置left浮動 */float: left;width: 150px;height: 52px;/* 設置button的背景顏色,#4e6ef2 */background-color: #4e6ef2;/* 設置button中的字體顏色 */color: #FFF;/* 設置字體的大小 */font-size: 19px;font-family: Georgia, 'Times New Roman', Times, serif;}.container .result {width: 100%;}.container .result .item {margin-top: 15px;}.container .result .item a {/* 設置為塊級元素,單獨站一行 */display: block;/* a標簽的下劃線去掉 */text-decoration: none;/* 設置a標簽中的文字的字體大小 */font-size: 20px;/* 設置字體的顏色 */color: #4e6ef2;}.container .result .item a:hover {text-decoration: underline;}.container .result .item p {margin-top: 5px;font-size: 16px;font-family: 'Lucida Sans', 'Lucida Sans Regular', 'Lucida Grande', 'Lucida Sans Unicode', Geneva, Verdana, sans-serif;}.container .result .item i {/* 設置為塊級元素,單獨站一行 */display: block;/* 取消斜體風格 */font-style: normal;color: rgba(103, 6, 193, 0.838);}</style>
</head><body><div class="container"><div class="search"><input type="text" value="請輸入搜索關鍵字"><button onclick="Search()">搜索一下</button></div><div class="result"><!-- 動態生成網頁內容 --></div></div><script>function Search() {// 是瀏覽器的一個彈出框// alert("hello js!");// 1. 提取數據, $可以理解成就是JQuery的別稱let query = $(".container .search input").val();console.log("query = " + query); //console是瀏覽器的對話框,可以用來進行查看js數據//2. 發起http請求,ajax: 屬于一個和后端進行數據交互的函數,JQuery中的$.ajax({type: "GET",url: "/s?word=" + query,success: function (data) {console.log(data);BuildHtml(data);}});}function BuildHtml(data) {// 獲取html中的result標簽let result_lable = $(".container .result");// 清空歷史搜索結果result_lable.empty();for (let elem of data) {// console.log(elem.title);// console.log(elem.url);let a_lable = $("<a>", {text: elem.title,href: elem.url,// 跳轉到新的頁面target: "_blank"});let p_lable = $("<p>", {text: elem.desc});let i_lable = $("<i>", {text: elem.url});let div_lable = $("<div>", {class: "item"});a_lable.appendTo(div_lable);p_lable.appendTo(div_lable);i_lable.appendTo(div_lable);div_lable.appendTo(result_lable);}}</script>
</body></html>成品
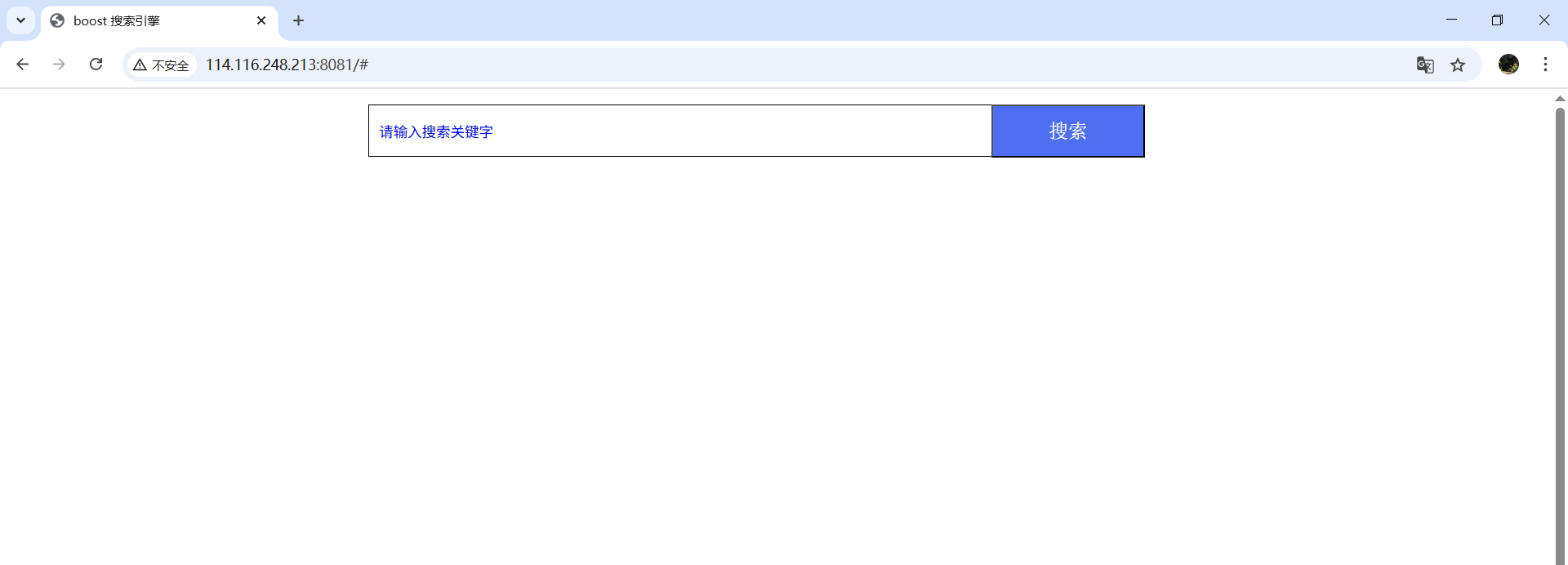
搜索展示
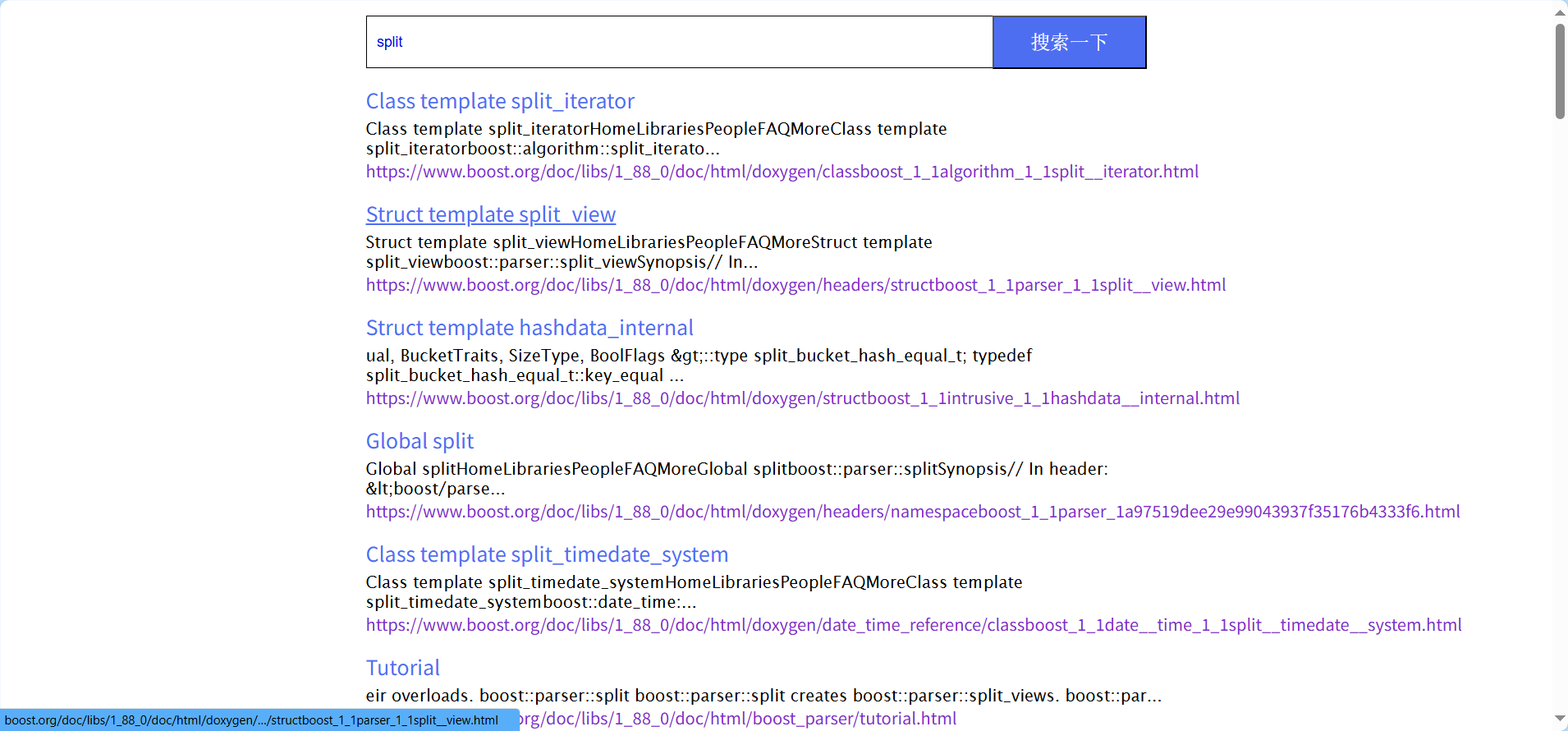
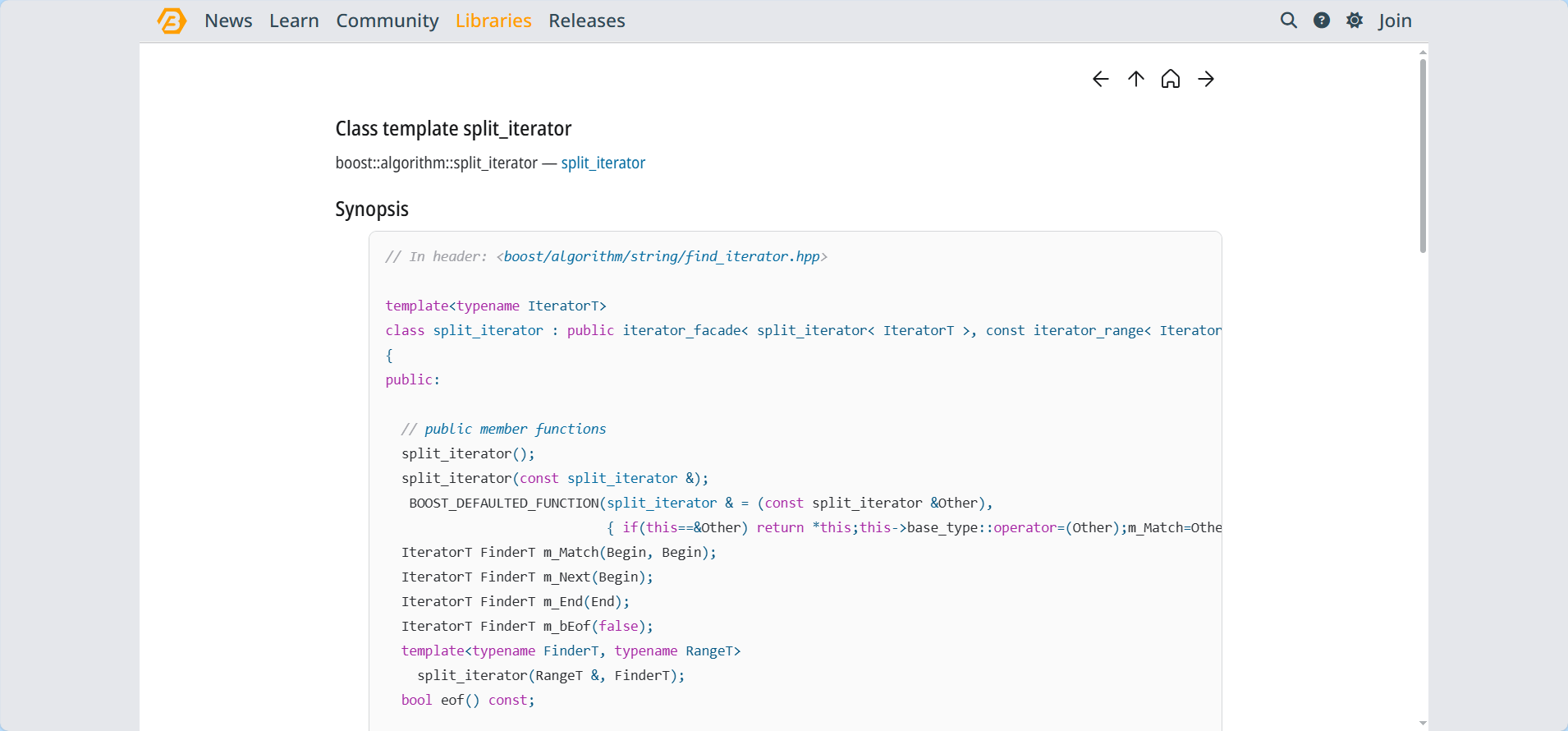
OK,還是很不錯的,本篇完!














: 標準庫 <deque>)
考點分析——求三連)
)



