
大語言模型(LLM)的浪潮正席卷全球,其強大的自然語言理解、生成和推理能力,為各行各業帶來了前所未有的機遇。然而,正如我們在之前的探討中多次提及,LLM并非萬能。它們受限于訓練數據的時效性和范圍,也無法直接與瞬息萬變的外部世界進行實時交互或執行需要特定技能的操作。
為了彌補這些不足,賦予LLM調用外部工具(如搜索引擎、數據庫、計算器、各類API服務)的能力,成為了學術界和工業界共同關注的焦點。模型上下文協議(Model Context Protocol, MCP)等標準的出現,為LLM與外部工具的交互提供了一定程度的規范,旨在讓LLM能夠像人類一樣,在需要時“借用”外部工具來完成任務。
然而,當LLM可調用的工具數量從個位數、十位數激增到成百上千,甚至更多時,新的、嚴峻的挑戰便浮出水面。這正是我們今天要深入探討的核心問題,也是論文《RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation》所致力于解決的痛點。本文將帶您詳細解讀RAG-MCP如何通過引入檢索增強生成(RAG)的思想,巧妙化解大模型在規模化工具調用場景下的困境。
一、背景與痛點

1.1 大型語言模型的能力與局限
LLM無疑是強大的。它們能夠進行流暢的自然對話,理解復雜的指令,甚至協助我們進行代碼編寫和復雜推理。但其強大能力的背后,也存在著固有的局限性:
-
知識的靜態性:LLM的知識主要來源于其訓練數據,這些數據一旦訓練完成,就相對固定了。對于訓練截止日期之后的新信息、新知識,LLM是無從知曉的。
-
上下文窗口限制:LLM在處理信息時,依賴于一個固定大小的上下文窗口。這意味著它們一次能夠“看到”和“記住”的信息量是有限的。
-
缺乏直接行動能力:LLM本身無法直接訪問最新的數據庫、執行網絡搜索或與外部服務進行交互。
1.2 LLM工具擴展趨勢:打破壁壘的必然選擇

為了克服上述局限,讓LLM能夠獲取實時信息、執行特定領域的計算、與外部系統聯動,研究人員和開發者們積極探索外部工具集成技術。通過定義清晰的接口(如API),LLM可以“調用”這些外部工具,從而極大地擴展其能力邊界。無論是通過搜索引擎獲取最新資訊,通過計算工具進行精確數學運算,還是通過數據庫查詢結構化數據,工具的引入為LLM打開了通往更廣闊應用場景的大門。
1.3 Prompt膨脹問題:難以承受之重

然而,隨著LLM可調用工具數量的急劇增加,一個棘手的問題——Prompt膨脹(Prompt Bloat)——日益凸顯。
想象一下,為了讓LLM知道有哪些工具可用以及如何使用它們,我們需要在Prompt中提供每個工具的描述、功能、參數列表、使用示例等信息。當只有少數幾個工具時,這或許還能勉強應付。但當工具數量達到幾十、幾百甚至更多時,情況就完全不同了:
-
上下文窗口不堪重負:所有工具的描述信息堆積起來,會迅速填滿甚至超出LLM的上下文窗口限制。這就像給一個人一本厚厚的工具說明書,卻要求他在幾秒鐘內全部看完并記住。
-
模型選擇混亂與效率低下:即使上下文窗口能夠容納,過多的工具信息也會讓LLM在選擇時感到“困惑”。功能相似的工具、描述冗余的信息,都會增加LLM的決策難度,導致其選擇錯誤工具或花費過長時間進行選擇。
-
Token消耗劇增:更長的Prompt意味著更高的API調用成本(對于商業LLM而言)和更長的處理時間。
二、核心研究問題

基于上述背景,我們可以將LLM在規模化工具調用場景下遇到的核心問題歸納為以下兩點:
2.1 Prompt膨脹 (Prompt Bloat)
正如前文所述,將所有可用工具的完整定義和使用說明一次性注入到LLM的上下文中,是導致Prompt極度冗長、Token消耗巨大、甚至超出模型最大上下文窗口限制的直接原因。這種“填鴨式”的信息供給方式,使得LLM在工具數量較多時,難以有效地進行信息篩選和聚焦,反而容易被大量無關信息所干擾,導致模型混淆。
2.2 決策過載 (Decision Overhead)
面對一個長長的、可能包含許多功能相似工具的列表,LLM需要做出更復雜的決策:是否需要調用工具?如果需要,應該調用哪個工具?如何正確地填充參數?選擇的范圍越大,LLM出錯的概率就越高。這包括選擇了次優的工具、混淆了不同工具的功能,甚至“幻覺”出不存在的API或錯誤地調用了API。
三、RAG-MCP解決方案

為了應對上述挑戰,論文提出了RAG-MCP框架。其核心思想是將廣泛應用于問答系統等領域的檢索增強生成(Retrieval-Augmented Generation, RAG)范式,創新性地引入到LLM的工具選擇過程中。
3.1 傳統方法 vs. RAG-MCP方法
為了更清晰地理解RAG-MCP的創新之處,我們不妨將其與傳統工具調用方法進行一個直觀的對比:
-
傳統方法 (Traditional Method):
-
信息注入方式:將所有可用工具的定義和描述信息,在LLM處理用戶請求之前,一次性、全量地注入到模型的上下文中。
-
上下文狀態:隨著工具數量的增加,上下文窗口被迅速填滿,充斥著大量可能與當前任務無關的工具信息。
-
模型選擇機制:LLM需要自行在龐雜的工具列表中進行搜索、理解和篩選,從中選出合適的工具。
-
性能表現:隨著工具庫規模的擴大,工具選擇的準確率顯著下降,Token消耗急劇上升,響應延遲增加。
-
-
RAG-MCP方法 (RAG-MCP Method):
-
信息注入方式:基于用戶當前的查詢意圖,通過一個外部的檢索系統,動態地、按需地從一個大規模的工具知識庫中檢索出少數幾個最相關的工具。
-
上下文狀態:只將這少數幾個經過篩選的高度相關的工具描述注入到模型的上下文中,使得Prompt保持簡潔、聚焦。
-
模型選擇機制:LLM的決策范圍被大幅縮小,只需在少數幾個候選工具中進行選擇,決策難度和復雜度顯著降低。
-
性能表現:即使工具庫規模龐大,工具選擇的準確率依然能保持在較高水平,Prompt長度和Token消耗得到有效控制。
-

3.2 RAG-MCP的核心思路
RAG-MCP的核心理念是:不再將所有工具的詳細信息一次性提供給LLM,而是通過一個外部的、可動態檢索的工具知識庫,在LLM需要調用工具時,根據當前用戶查詢的語義,智能地檢索出最相關的一小部分候選工具,再將這些精選的工具信息注入到LLM的Prompt中。
這就像我們人類在解決一個復雜問題時,不會把所有可能的工具都擺在面前,而是會先根據問題的性質,從工具箱里挑選出幾種最可能用得上的,然后再仔細研究這幾種工具的用法,最終做出選擇。RAG-MCP正是為LLM模擬了這樣一個“按需取用”、“聚焦選擇”的智能工具選擇過程。
具體來講,RAG-MCP的解決方案主要包含以下幾個關鍵環節:
-
外部化工具知識庫與檢索層:將所有MCP工具的詳細描述信息(功能、參數、示例等)存儲在一個外部的、可高效檢索的知識庫中(例如向量數據庫)。當用戶請求到達時,首先由檢索層負責理解用戶意圖,并從該知識庫中匹配和召回最相關的工具。
-
智能化工具篩選:檢索層不僅僅是簡單地返回一批工具,還可能包含進一步的篩選和排序邏輯,以確保提供給LLM的是最優的候選工具集(例如Top-K個最相關的工具)。
-
精簡化的上下文與高效執行:只有經過檢索和篩選后的、與當前任務高度相關的少數工具描述,才會被注入到主LLM的上下文中。LLM得以在更為清爽、聚焦的上下文中進行后續的任務規劃和工具調用執行。
3.3 RAG-MCP的實現步驟

RAG-MCP的解決方案主要包含以下幾個關鍵環節:
-
檢索層 (Retrieval):
-
外部工具索引:首先,將所有可用的MCP工具(包括其功能描述、API schema、使用示例等元數據)進行編碼(例如,使用文本嵌入模型),構建一個外部的向量化索引庫。這個索引庫就像一個專門為工具建立的“語義圖書館”。
-
查詢編碼與檢索:當用戶發起一個查詢時,RAG-MCP首先使用相同的編碼模型將用戶查詢也轉換為向量。然后,在這個工具索引庫中進行語義相似度搜索,找出與用戶查詢意圖最匹配的Top-k個候選MCP工具。
-
-
工具篩選 (Selection & Validation):
-
Top-k工具選擇:從檢索結果中選出語義相似度最高的k個工具。
-
(可選) 驗證:論文中提到,對于每個檢索到的MCP,RAG-MCP可以生成一個few-shot示例查詢并測試其響應,以確保基本兼容性,這可以看作是一種“健全性檢查”。(論文第6頁)
-
-
精簡執行 (Invocation):
-
注入精選工具:只有這k個(或經過驗證后最優的)被檢索出來的工具的描述信息會被傳遞給LLM。
-
LLM決策與調用:LLM此時面對的是一個大大縮減的、高度相關的工具列表,其決策復雜度和Prompt長度都得到了顯著降低。LLM在此基礎上進行最終的工具選擇和參數填充,并執行調用。
-
通過這種方式,RAG-MCP巧妙地將“工具發現”這一復雜任務從LLM的核心推理過程中剝離出來,交由高效的檢索系統處理,從而實現了對LLM的“減負增效”。
四、RAG-MCP框架設計
4.1 框架概覽
RAG-MCP將檢索增強生成技術與Model Context Protocol標準相結合,通過外部語義索引與動態注入,高效解決大型工具庫的選擇與調用問題。其核心在于解耦工具發現與生成執行。
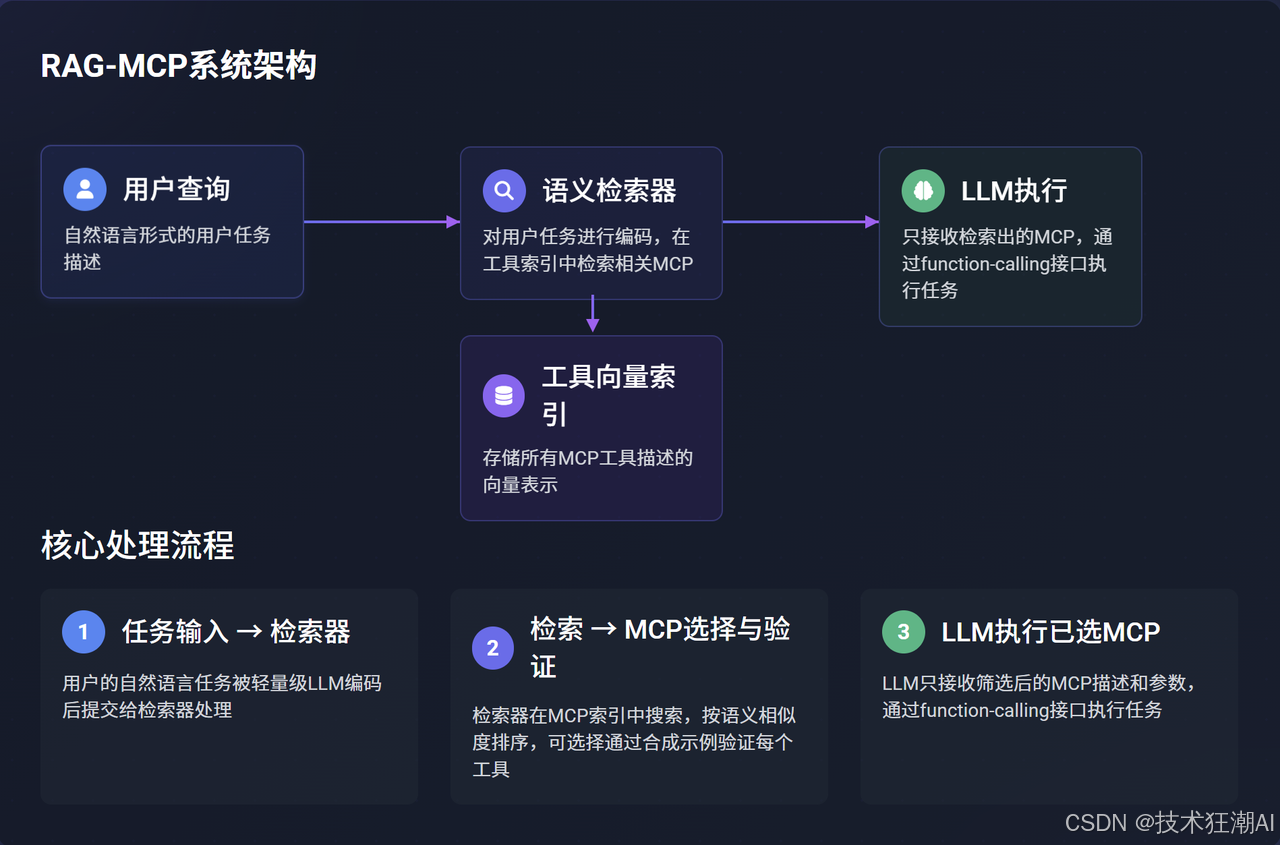
4.2 RAG-MCP系統架構組件
一個典型的RAG-MCP系統主要由以下幾個協同工作的核心組件構成:
-
語文檢索器 (Retriever):負責對用戶的自然語言任務進行編碼,并在工具向量索引中檢索相關的MCP。論文中提及可以使用輕量級的LLM(如Qwen)作為編碼器。(論文第6頁)
-
工具向量索引 (Tool Vector Index):存儲所有MCP工具描述的向量化表示,支持高效的語義相似度搜索。
-
LLM執行器 (LLM Executor):接收檢索器篩選出的MCP工具信息,并基于此進行任務規劃和函數調用。
4.3 核心處理流程:三步曲
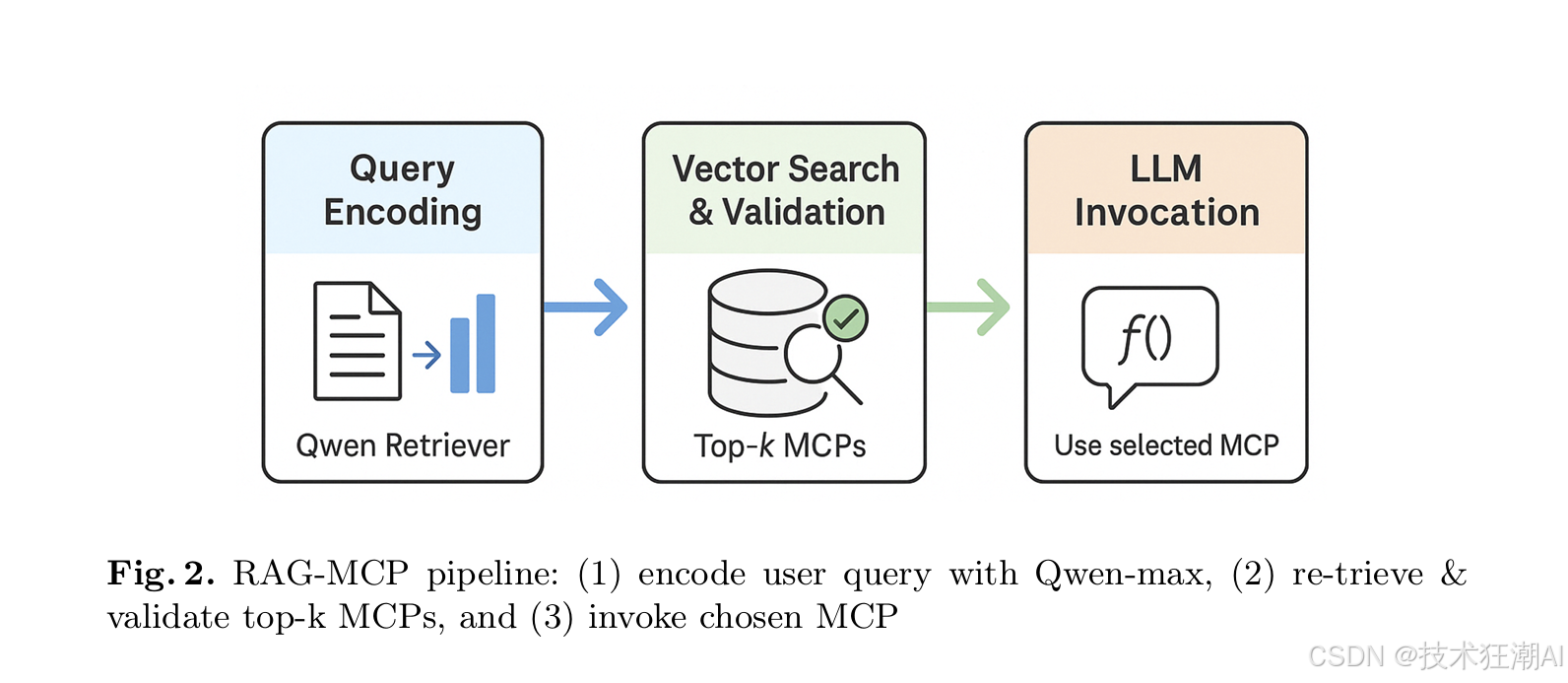
論文中將RAG-MCP的操作總結為三個核心步驟(如圖2所示):
步驟一:任務輸入與智能編碼 (Task Input → Retriever)
-
當用戶的自然語言任務請求被輸入到RAG-MCP系統后,首先由一個輕量級的LLM(例如Qwen模型,作為檢索器的一部分)對該任務描述進行深度的語義分析和編碼。
-
這個編碼過程旨在將用戶的意圖轉化為一個固定維度的、能夠精準捕捉其核心需求的向量表示(Query Embedding)。這個向量將作為后續在工具庫中進行檢索的“鑰匙”。
步驟二:高效檢索、MCP選擇與可選驗證 (Retriever → MCP Selection & Validation)
-
攜帶用戶任務意圖的查詢向量被提交給檢索器。檢索器會在預先構建好的、包含所有可用MCP工具描述及其向量表示的“工具向量索引”中執行高效的語義相似度搜索(例如,使用余弦相似度或內積作為度量)。
-
檢索器會根據語義相似度得分對所有工具進行排序,并返回得分最高(即與用戶任務最相關)的Top-K個候選MCP工具。
-
(可選但推薦的步驟)為了進一步提升選擇的準確性,系統還可以對這K個檢索到的候選MCP工具進行一個快速的“驗證(Validation)”環節。例如,可以為每個候選工具動態生成一些簡單的、與用戶原始查詢相關的“Few-Shot”示例查詢,并模擬調用該工具,觀察其響應是否符合預期。這個驗證過程可以幫助過濾掉那些雖然在文本描述上相似但實際可能不適用的工具。
步驟三:精簡上下文、LLM決策與執行已選MCP (LLM Execution with Selected MCP)
-
只有經過上述檢索(以及可選的驗證)環節后篩選出的、被認為是與當前用戶任務最匹配的一個或少數幾個MCP工具的詳細描述信息(包括其功能Schema、參數定義等),才會被注入到主大型語言模型(Main LLM)的上下文中。
-
此時,主LLM接收到的Prompt是高度精煉和聚焦的,它不再需要面對成百上千的工具選項。LLM基于這個清爽的上下文,可以更輕松、更準確地做出最終的工具選擇決策(如果候選工具多于一個),規劃具體的執行步驟,并通過標準的函數調用(Function-Calling)接口與選定的MCP工具進行實際的交互,完成用戶指定的任務。
4.4 核心組件詳解
-
語義檢索模塊:
-
使用輕量級LLM(如Qwen)進行任務編碼。
-
在向量空間中表示和匹配工具描述。
-
返回語義相似度最高的Top-k候選工具。
-
-
MCP驗證與執行:
-
對每個檢索到的MCP生成few-shot示例進行測試。
-
篩選出最佳工具注入主LLM的Prompt。
-
通過function-calling API執行計劃與調用。
-
4.5 設計優勢
RAG-MCP框架的核心設計思想在于“解耦工具發現與生成執行”。通過將工具的發現、篩選和初步驗證等復雜工作“外包”給一個獨立的、高效的檢索模塊,主LLM得以從繁重的工具管理和選擇任務中解脫出來,更專注于其核心的理解、推理和生成能力。這種設計帶來了諸多顯著優勢:
-
高度可擴展性 (Scalability):由于工具信息存儲在外部索引中,并且只有相關的工具才會被動態加載到LLM的上下文中,RAG-MCP系統能夠輕松擴展至支持包含數百甚至數千個MCP工具的龐大工具生態,而不會像傳統方法那樣迅速遭遇性能瓶頸。
-
顯著降低Prompt膨脹 (Reduced Prompt Bloat):這是RAG-MCP最直接的優勢。通過按需檢索,極大地減少了注入到LLM上下文中的工具描述信息量,有效避免了Prompt長度超出限制或因信息過載導致模型性能下降的問題。
-
減輕LLM決策疲勞 (Lowered Cognitive Load for LLM):LLM不再需要在海量的工具選項中進行大海撈針式的搜尋和比對,其決策范圍被大幅縮小,從而降低了認知負擔,提高了決策的準確性和效率,并減少了“幻覺調用”的風險。
-
類比RAG系統:RAG-MCP的設計理念與通用的檢索增強生成(RAG)系統有異曲同工之妙。正如RAG系統通過從大型語料庫中檢索相關段落來輔助LLM回答問題,避免讓LLM處理整個語料庫一樣,RAG-MCP也是通過從大型工具庫中檢索相關工具來輔助LLM完成任務,避免讓LLM被所有工具的描述所淹沒。
-
動態適應與靈活性:新的工具可以方便地添加到外部索引中,或對現有工具的描述進行更新,而無需重新訓練主LLM,這使得系統能夠快速適應工具生態的變化。
通過將工具發現與生成執行解耦,RAG-MCP確保LLM可以擴展到處理數百或數千個MCP,而不會遭受Prompt膨脹或決策疲勞的困擾。這與RAG系統通過僅檢索相關段落來避免LLM被整個語料庫淹沒的原理類似。
五、技術實現細節
5.1 RAG-MCP詳細工作流程

整個RAG-MCP的工作流程可以細化為以下幾個緊密銜接的步驟,每一步都為最終的高效工具調用貢獻力量:
-
步驟一:用戶查詢的深度語義編碼 (Query Encoding)
-
當用戶以自然語言形式輸入其任務或查詢時,RAG-MCP系統首先會調用一個輕量級但語義理解能力強的大型語言模型(例如,PPT中提及的Qwen系列模型或類似的嵌入模型)對該輸入進行深度語義編碼。
-
此編碼過程的目標是將用戶的原始文本查詢轉化為一個固定維度的高維向量表示(我們稱之為“查詢嵌入”或
query_embedding)。這個向量被設計為能夠精準地捕捉和濃縮用戶查詢的核心意圖和語義信息。
-
-
步驟二:基于向量的工具高效檢索 (Vector Retrieval)
-
攜帶著用戶查詢意圖的
query_embedding,系統會進入預先構建好的、存儲了所有可用MCP工具描述及其對應向量表示的“工具向量索引庫”(vector_db)。 -
在此索引庫中,系統會執行高效的語義相似度搜索。這通常涉及到計算
query_embedding與索引庫中每一個工具描述向量之間的相似度得分(例如,通過余弦相似度、內積或其他向量空間距離度量)。 -
根據計算出的相似度得分,系統能夠快速定位到與用戶查詢在語義上最為接近(即最可能相關)的一批MCP工具,并按照相似度從高到低進行排序,返回Top-K個候選工具(
tools)。
-
-
步驟三:智能化的工具選擇與驗證 (Tool Selection & Optional Validation)
-
從檢索器返回的Top-K個候選工具列表中,系統需要進一步篩選出最適合當前用戶任務的那個(或那幾個)MCP工具(
best_tool)。 -
這一步是可選的,但對于提升最終選擇的準確性至關重要。RAG-MCP框架支持引入一個“Few-Shot驗證”機制。具體而言,可以針對每個檢索到的候選MCP工具,基于用戶原始查詢的上下文,動態地生成一些簡單的、小批量的測試樣例(Synthetic Test Queries)。然后,模擬使用該候選工具來處理這些測試樣例,并評估其返回結果的質量、相關性以及與預期輸出的匹配程度。通過這種方式,可以更可靠地判斷哪個工具是當前場景下的最優選。
-
-
步驟四:精準上下文注入 (Inject Prompt with Selected Tool(s))
-
一旦通過檢索和可選的驗證環節確定了最優的MCP工具(
best_tool),系統便會將該工具的Schema(包含其詳細的功能描述、輸入參數定義、輸出格式等)以及必要的參數信息,精準地、有選擇性地注入到主大型語言模型(Main LLM)的上下文(Context)中。 -
此時,構建出的Prompt (
prompt) 內容是高度聚焦且信息量適中的,它只包含了用戶原始查詢 (user_query) 和與該查詢最相關的工具信息 (best_tool.schema),避免了大量無關工具描述的干擾。
-
-
步驟五:LLM規劃與執行任務 (LLM Planning & Execution)
-
主LLM在接收到這個經過精心構建的、包含用戶原始查詢及最優工具信息的精簡Prompt后,便可以利用其強大的理解、推理和規劃能力。
-
LLM會通過其內置的函數調用(Function-Calling)接口,規劃具體的執行步驟,并與選定的外部MCP工具進行實際的交互,發送請求、處理響應,最終完成用戶指定的任務,并返回結果 (
result)。
-
5.2 檢索器技術實現

一個高效且精準的檢索器是RAG-MCP系統成功的核心。其技術實現涉及以下幾個關鍵方面:
-
高質量的工具向量表示:
-
每一個MCP工具都需要通過結構化的數據進行詳盡的預處理,并最終轉化為一個能夠準確反映其語義和功能特性的高維度向量表示。這些結構化數據通常應包括:
-
工具名稱與核心用途描述:清晰、簡潔地闡述工具的主要功能和最典型的適用場景。
-
詳細的參數定義與返回值結構:明確定義工具調用時所需的各個輸入參數的名稱、數據類型、是否必需、取值范圍或格式要求,以及工具執行成功或失敗后返回結果的數據結構和含義。
-
具體的使用樣例與調用場景說明:提供1到多個具體的、具有代表性的調用示例代碼或自然語言描述的調用場景,這有助于嵌入模型更好地學習和理解工具的實際用法和上下文。
-
-
例如,一個天氣查詢API的向量化輸入可能包含:
-
tool_embedding = encoder({ "name": "weather_api", "description": "Get current weather conditions and forecast for a specified location.", "parameters": { "location": "string", "days": "integer" }, "examples": ["What's the weather like in Paris tomorrow?", "Get a 3-day forecast for London."]})-
高效的向量索引與存儲技術:
-
選擇一個能夠支持大規模向量數據高效存儲和快速相似性搜索的向量索引技術至關重要。業界常用的選項包括基于圖的索引(如HNSW)、基于量化的索引(如Product Quantization)或它們的組合。Facebook的FAISS庫、Milvus、Pinecone、Qdrant等都是流行的開源或商業向量數據庫解決方案。
-
構建的向量索引庫需要支持動態更新,以便能夠方便地添加新的工具、刪除過時的工具或更新現有工具的描述信息及其向量表示,而無需對整個索引庫進行重建或重新訓練主LLM。
-
在執行檢索時,除了基礎的語義相似度排序外,還可以結合一些高級策略,如基于工具元數據(例如工具類別、使用頻率、用戶評分等)的語義過濾(Semantic Filtering)或混合排序(Hybrid Ranking),以進一步提升檢索結果的精準度和相關性。
-
例如,典型的操作可能包括:
index.add(tool_id, tool_embedding)用于向索引中添加工具向量,以及results = index.search(query_embedding, top_k=5, filter_conditions={"category": "weather"})用于執行帶條件的Top-K檢索。
-
5.3 Few-Shot驗證技術
當檢索器根據語義相似度返回多個候選MCP工具時(即Top-K中的K>1),為了從這些看似都相關的選項中進一步優中選優,提高最終工具選擇的準確率和魯棒性,RAG-MCP框架引入了可選的Few-Shot驗證技術。其核心思想是:
-
動態合成驗證樣例:針對每一個檢索到的候選MCP工具,系統可以根據用戶原始查詢的上下文和意圖,自動地、動態地生成一些簡單的、小批量的、專門用于測試該工具適用性的“微型”任務樣例。這些樣例應盡可能地模擬用戶可能如何使用該工具。
-
模擬調用與響應質量評估:系統會模擬使用當前的候選工具來執行這些合成的驗證樣例,并捕獲其返回的響應。然后,通過預設的評估標準(例如,檢查響應是否包含預期信息、格式是否正確、與用戶原始查詢的相關性等)來對每個工具在這些驗證樣例上的表現進行打分。
-
基于綜合評分的最終工具篩選:最終的工具選擇決策將綜合考慮兩個方面的因素:一是該工具在初始語義檢索階段獲得的相似度得分;二是其在Few-Shot驗證環節的表現得分。通過一個加權或其他融合策略,計算出一個綜合評分,并選擇綜合評分最高的那個工具作為最終的“勝出者”。

這種驗證機制相當于在正式“上場”前對候選工具進行了一輪“試用”,有助于排除那些看似相關但實際效果不佳的工具。
通過上述這些精心設計的技術實現細節,RAG-MCP框架得以確保在面對日益龐大和復雜的外部工具生態時,依然能夠為大型語言模型精準、高效地“導航”,幫助其找到最合適的“左膀右臂”,從而更好地完成用戶賦予的各項任務。
六、實驗設計與評估方法
6.1 MCP壓力測試設計
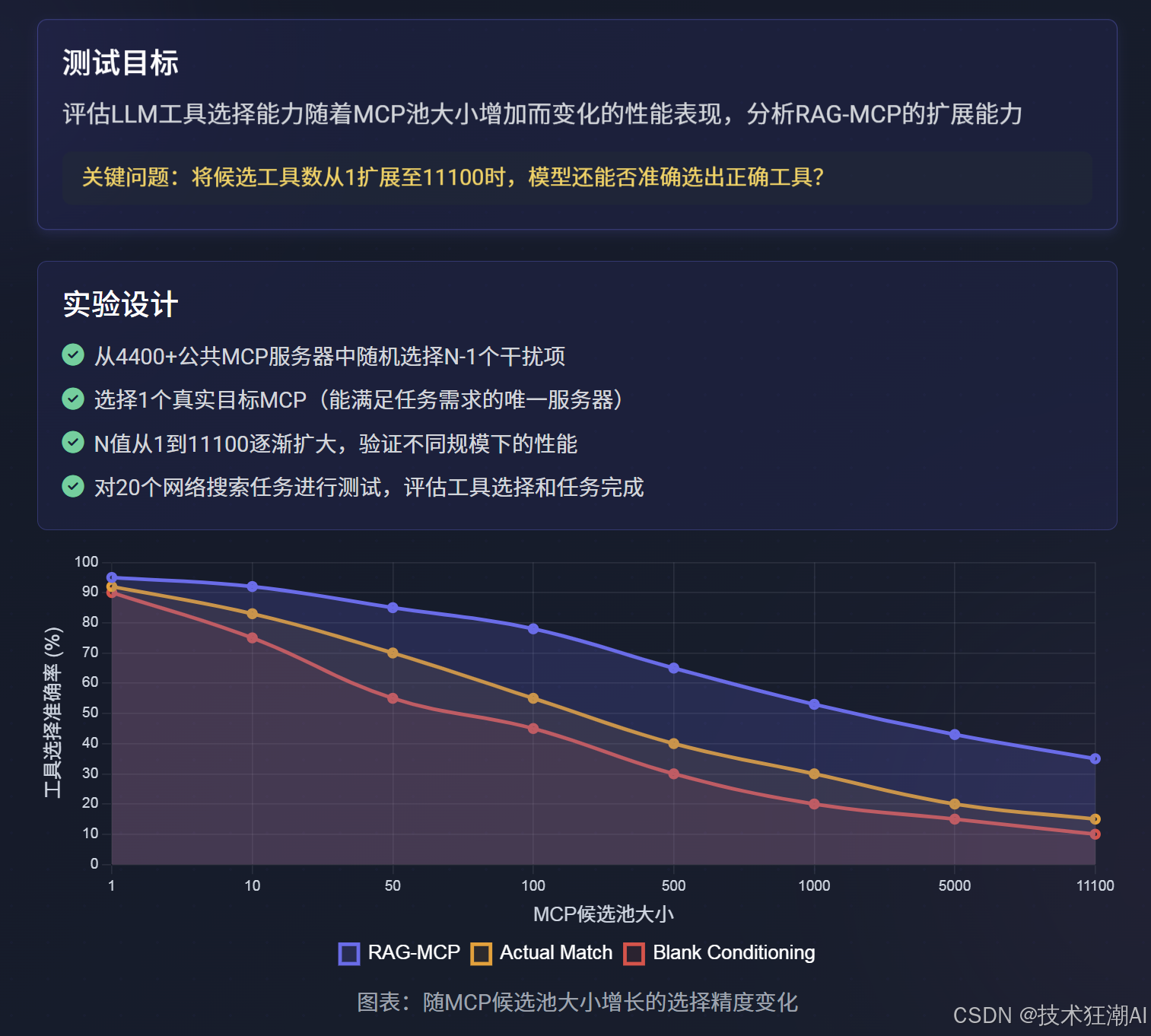
為了量化評估LLM的工具選擇能力如何隨著MCP池大小的增加而變化,并分析RAG-MCP的擴展能力,論文設計了MCP壓力測試。
-
關鍵問題:當候選工具數量從1擴展至11100時,模型還能否準確選出正確的工具?
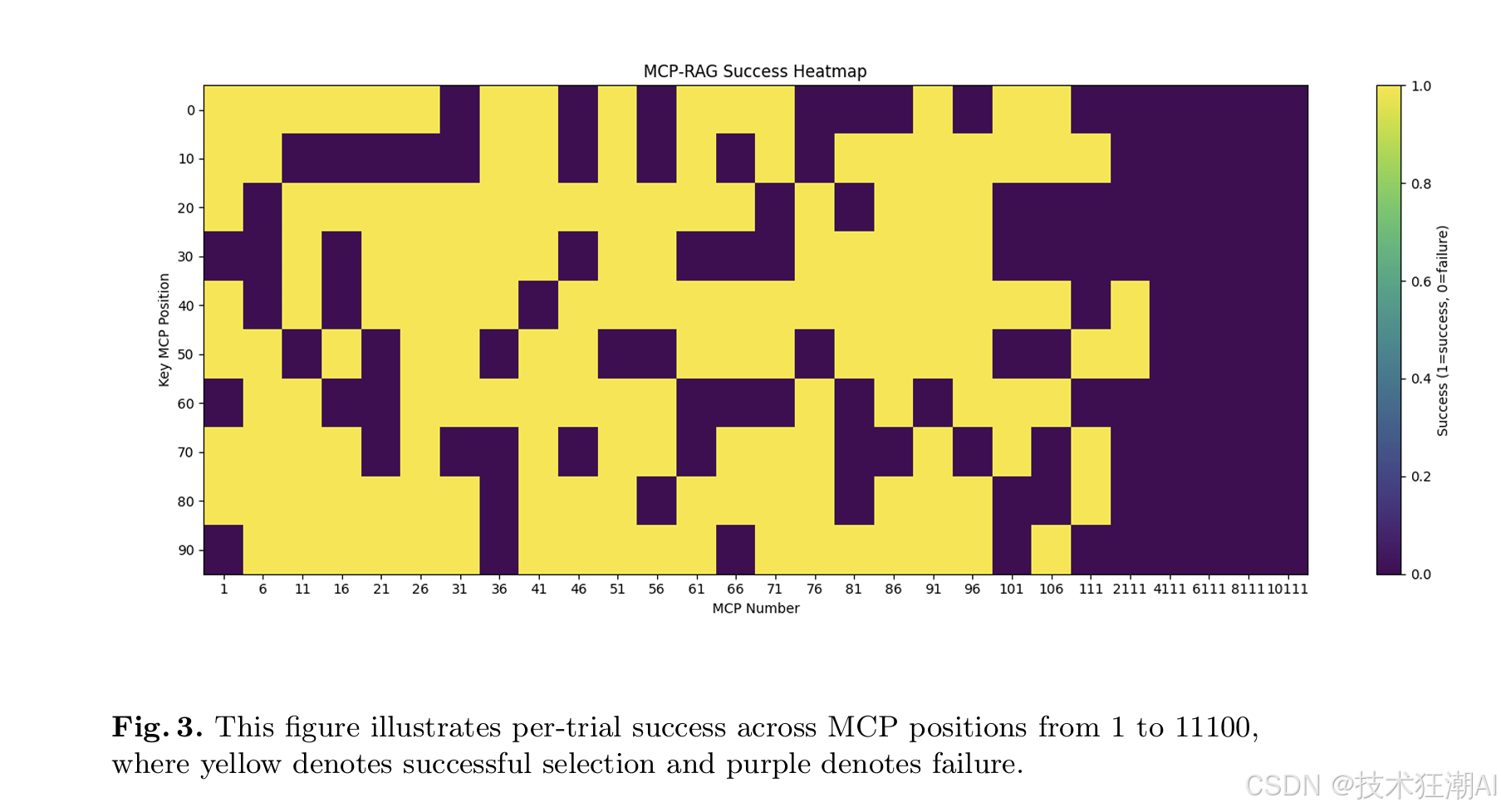
圖3展示了MCP壓力測試的部分結果,直觀地顯示了在不同工具數量和目標工具位置下,RAG-MCP的成功率(黃色表示成功,紫色表示失敗)。
6.2 MCPBench評估框架
為了確保實驗評估的客觀性、標準化和可復現性,研究團隊采用了領域內公認的MCPBench評估框架,并特別選取了其中的Web搜索任務子集(Web Search Subset)作為固定的、與訓練數據無關的留出測試平臺(Heldout Testbed)

-
評估設置:
-
每種方法進行20次獨立試驗。
-
允許模型與MCP服務器進行最多10輪交互以達成最終響應。
-
使用Deepseek-v3作為評估器來判斷答案的正確性。
-
使用qwen-max-0125作為基礎LLM。
-
-
評估指標:
-
準確率 (%): 模型選擇到真實目標MCP的試驗比例。
-
平均Prompt Token: 包含注入的MCP元數據在內的Prompt平均Token消耗。
-
平均完成Token: 模型最終輸出的生成內容的平均Token長度。
-
-
基礎模型:
-
使用qwen-max-0125作為基礎LLM。
-
確保實驗環境的網絡連通性。
-
使用Llama-based驗證器自動判斷輸出正確性。
-
6.3 對比基線方法
為了凸顯RAG-MCP的優勢,論文將其與以下基線方法進行了對比:

-
Blank Conditioning (BC):將所有N個MCP的描述一次性注入LLM的Prompt,讓模型自行選擇正確的工具。這是最直接但也最低效的方法。
-
Actual Match (AM):使用簡單的關鍵詞匹配對任務描述和MCP元數據進行預篩選,縮小候選范圍后,再將篩選后的工具集提供給LLM。這是一種加入了初步過濾的優化方法。
-
RAG-MCP: 即本文提出的方法,使用向量索引檢索器語義化地排序所有N個MCP,并僅將排名最高的候選工具的schema注入LLM的Prompt進行執行。
七、實驗結果與數據分析

7.1 性能對比分析
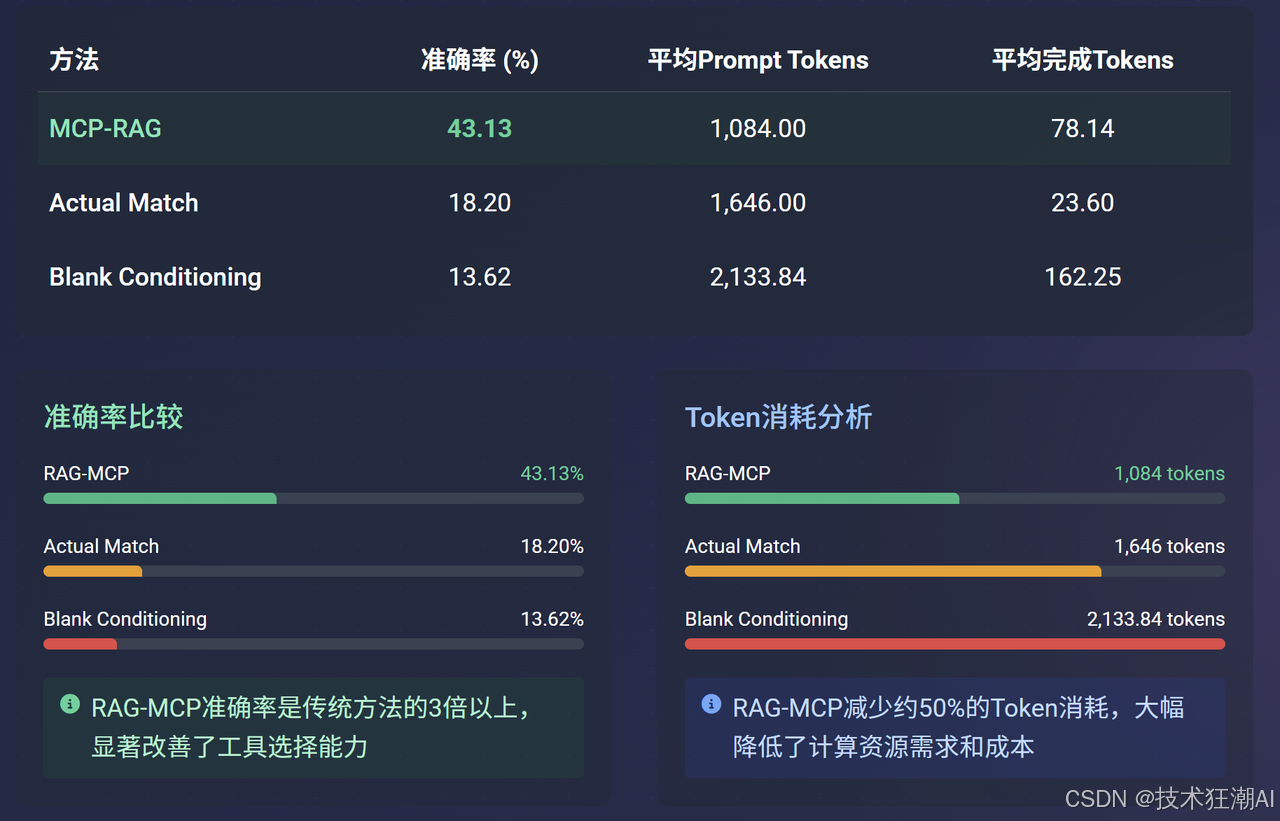
從表格中可以直觀地看到:
-
準確率大幅提升:RAG-MCP的工具選擇準確率(43.13%)遠超Actual Match(18.20%)和Blank Conditioning(13.62%),提升了約3倍。
-
Prompt Token顯著減少:RAG-MCP的平均Prompt Token消耗(1084.00)相比Blank Conditioning(2133.84)減少了近一半(約49%),也明顯低于Actual Match(1646.00)。
-
完成Token的權衡:雖然RAG-MCP的平均完成Token(78.14)略高于Actual Match(23.60),但這通常與更復雜的推理和更成功的任務完成相關聯,是一種值得的“開銷”。
7.2 擴展性與容量分析 (基于MCP壓力測試結果)
MCP壓力測試的結果(如圖3所示)揭示了RAG-MCP在不同工具庫規模下的性能表現:
-
小規模工具庫 (<30個MCP):成功率非常高,通常在90%以上。
-
中等規模工具庫 (30-100個MCP):成功率保持穩定,但隨著工具描述間語義重疊的增加,可能會出現間歇性的性能波動。
-
大規模工具庫 (>100個MCP):雖然檢索精度有所下降,但RAG-MCP的整體性能仍然顯著優于傳統方法。
-
“成功孤島”現象:即使在非常大的工具庫中,對于某些與用戶查詢高度對齊的特定MCP,系統仍然能夠保持較高的檢索和選擇成功率,顯示了其在特定語義領域的魯棒性。
這些結果證實,RAG-MCP能夠有效抑制Prompt膨脹,并在中小型工具池中保持高準確率。盡管在超大規模工具庫中檢索精度面臨挑戰,但其整體表現仍遠超基線。
八、創新點與應用優勢
8.1 核心創新點

-
RAG + MCP融合架構:首創性地將檢索增強生成(RAG)機制與模型上下文協議(MCP)的函數調用標準相結合。
-
可擴展的工具檢索機制:設計了高效的語義索引機制,使得系統可以在不重新訓練LLM的情況下,即時添加新的工具。這賦予了系統極高的靈活性和可擴展性。
-
顯著的性能突破:在處理大規模工具庫時,RAG-MCP顯著提高了工具選擇的準確率,同時大幅減少了錯誤調用和參數“幻覺”的風險。
8.2 技術優勢對比

-
傳統MCP調用:
-
將全部工具描述注入LLM上下文。
-
隨著工具數量增加,Token消耗線性增長。
-
工具選擇準確率隨規模增大而急劇下降。
-
-
RAG-MCP方法:
-
只注入最相關的工具,降低上下文負擔。
-
Token消耗幾乎恒定,與總工具數量解耦。
-
語義檢索提供更精準的工具選擇。
-
8.3 實用價值與優勢
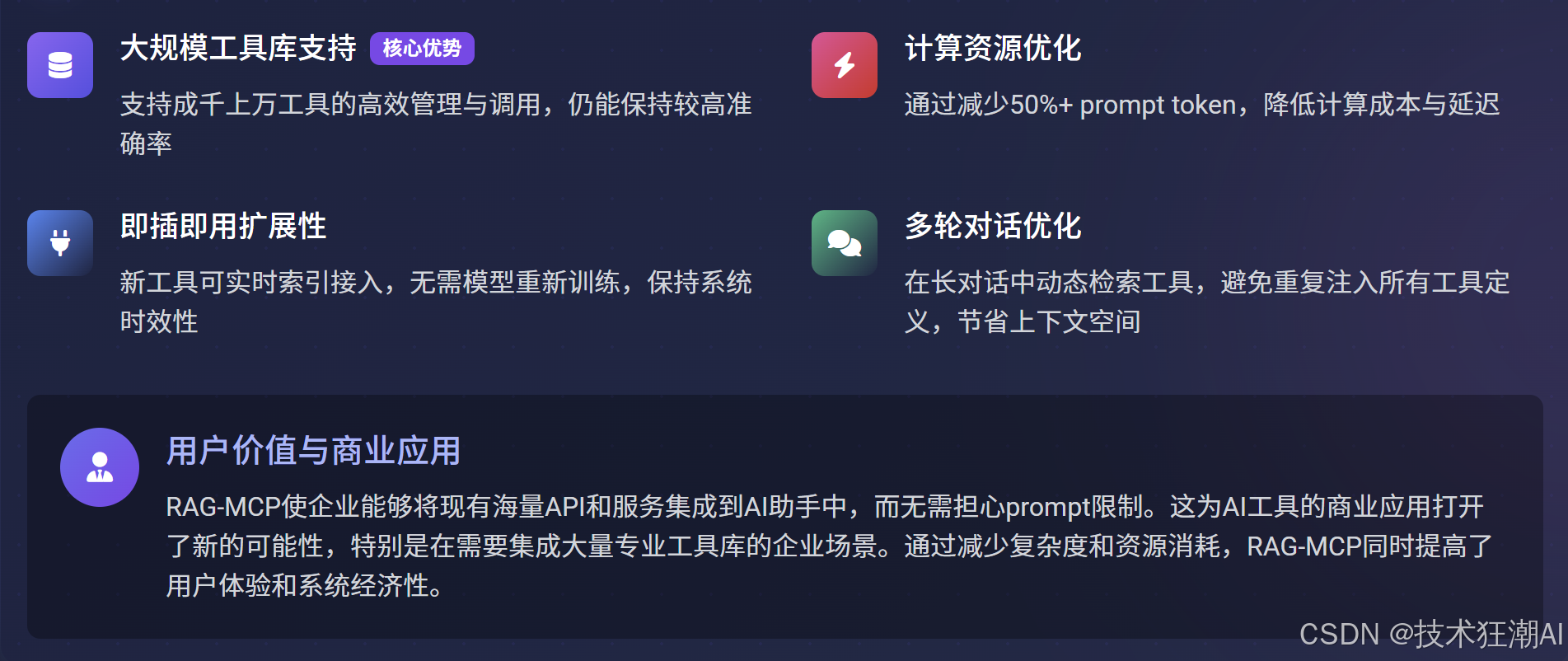
-
支持大規模工具庫:即使面對成千上萬的工具,RAG-MCP也能保持較高的管理和調用效率與準確性。
-
即插即用的擴展性:新的工具可以實時索引并接入系統,無需對核心LLM進行重新訓練,保持了系統的時效性。
-
計算資源優化:通過減少超過50%的Prompt Token,顯著降低了計算成本和API調用延遲。
-
優化多輪對話中的工具調用:在持續的多輪對話中,RAG-MCP可以動態檢索工具,避免在每一輪都重復注入所有工具的定義,從而節省了寶貴的上下文空間。
-
提升用戶價值與商業應用潛力:RAG-MCP使得企業能夠將現有的大量API和服務集成到AI助手中,而無需擔心Prompt限制。這為AI工具的商業應用開辟了新的可能性,特別是在需要集成大量專業工具庫的企業場景中。通過減少復雜度和資源消耗,RAG-MCP同時提高了用戶體驗和系統經濟性。
九、應用場景與未來展望
9.1 實際應用場景
RAG-MCP的框架思想和技術實現,使其在多種需要LLM與大量外部工具交互的場景中具有廣闊的應用前景:

-
AI客服系統:企業級客服系統往往需要接入數百種內部工具和API來處理各類用戶請求。RAG-MCP可以幫助AI客服精準選擇工具,降低運營成本,提升響應速度和問題解決率。
-
開發者助手:整合數千個代碼庫文檔、API參考和代碼示例,開發助手可以基于上下文檢索最相關的資源,而非一次性加載所有文檔,從而為開發者提供更精準、高效的輔助。
-
企業智能體:企業內部的自動化助手需要連接ERP、CRM、HR等多種復雜系統。RAG-MCP可以根據具體任務按需調用合適的系統接口,實現更智能、更高效的企業流程自動化。
9.2 局限性與挑戰
盡管RAG-MCP取得了顯著進展,但仍存在一些局限性和待解決的挑戰:

-
超大規模工具庫下的檢索精度瓶頸:當工具庫規模達到數千甚至上萬級別,且工具描述之間語義相似度較高時,檢索模塊的精度仍可能面臨挑戰,導致次優工具被選中的風險增加。
-
復雜工具鏈的處理:當前框架主要關注單個工具的選擇。當一個任務需要連續調用多個工具形成復雜工具鏈時,RAG-MCP在多步驟規劃與組合方面的原生支持尚有不足。
9.3 未來研究方向
為了進一步提升RAG-MCP的性能和適用性,未來的研究可以從以下幾個方面展開:

-
分層檢索架構:針對超大規模工具庫,可以發展多層次、層級化的工具檢索機制,例如先進行粗粒度的大類檢索,再進行細粒度的精確匹配,以適應不同規模的工具庫。
-
對話語境感知:增強檢索模塊對多輪對話歷史的理解能力,將上下文信息(如用戶之前的提問、偏好等)納入檢索考量,以提高在復雜對話場景下工具匹配的準確性。
-
自我優化與學習:開發系統從用戶交互歷史中學習的能力,例如,自動調整檢索算法的參數、排序權重,甚至動態更新工具的向量表示,以持續提升工具匹配的準確率。
-
多Agent協作:將RAG-MCP的思想擴展到多智能體(Multi-Agent)系統。不同的Agent可以負責管理和調用一部分工具子集,通過協同合作來完成更復雜的任務。
-
安全性與隱私增強:研究如何在工具檢索階段引入安全過濾和權限控制機制,防止未授權的工具被訪問或濫用,確保系統的安全性和用戶隱私。
十、實施指南與最佳實踐
10.1 RAG-MCP實施路線圖

-
工具庫梳理與標準化:整理并標準化所有需要集成的外部工具的API定義或MCP描述。確保每個工具的描述清晰、結構化,并包含必要的元數據。
-
向量索引構建:選擇合適的嵌入模型(Embedding Model),對工具描述進行向量化,并構建高效的向量索引庫(如使用FAISS、Milvus、Pinecone等)。
-
檢索器調優:優化檢索參數(如Top-k值的選擇)和語義匹配算法。針對特定領域的工具庫,可以考慮微調嵌入模型以提升檢索效果。
-
系統集成與測試:將檢索模塊與主LLM系統集成,并進行全流程的端到端測試,確保各組件協同工作順暢。
10.2 最佳實踐建議

-
優化工具描述:
-
使用結構化、一致的格式來描述工具功能。
-
在描述中包含明確的用例和適用場景。
-
為工具添加相關的關鍵詞標簽,以增強語義匹配的魯棒性。
-
為每個工具提供2-3個典型的使用示例。
-
-
提升檢索性能:
-
針對特定的工具領域或任務類型,考慮微調嵌入模型。
-
實驗不同的Top-k值(通常建議從3-5開始嘗試)。
-
可以探索結合語義檢索與關鍵詞匹配的混合策略。
-
定期更新和優化向量索引,以納入新增或變更的工具。
-
-
考量系統架構:
-
將檢索服務與主LLM服務解耦,以確保各自的獨立可擴展性。
-
引入緩存機制,減少對高頻工具的重復檢索開銷。
-
可以為高頻或關鍵工具設置更高的檢索優先級權重。
-
建立檢索結果的監控機制和失敗時的回退策略。
-
-
持續評估與優化:
-
跟蹤關鍵指標,如工具選擇準確率、誤用率等。
-
收集用戶交互反饋,用于改進檢索算法和工具描述。
-
建立標準化的測試集,定期評估系統性能。
-
定期重新訓練或更新工具的向量表示,以適應工具本身的變化和用戶使用模式的演變。
-
十一、關鍵結論與行業影響
11.1 核心結論與突破

-
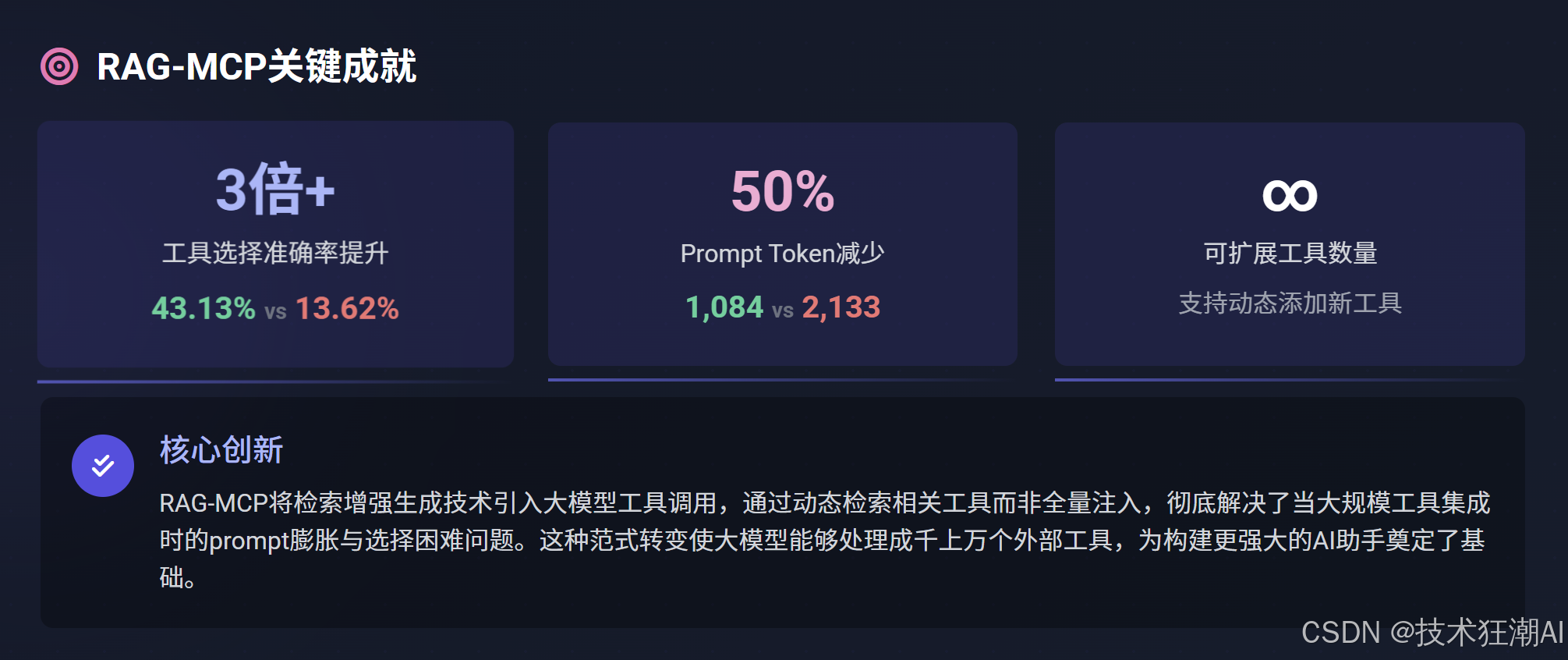
性能與效率雙提升:RAG-MCP通過動態檢索相關工具,成功將Prompt Token數量減少了50%以上,同時使工具選擇準確率提升了3倍以上(從基線的13.62%提升至43.13%)。這極大地降低了模型在處理大量工具時的上下文理解負擔,使得大規模工具庫的應用成為可能。
-
可擴展性的重大突破:通過解耦工具發現與LLM調用,RAG-MCP實現了無需重新訓練核心LLM即可動態添加新工具的能力,徹底打破了傳統方法在工具數量上的限制。這為LLM接入數千甚至數萬種外部工具提供了基礎架構。
11.2 突破性意義
RAG-MCP框架代表了LLM工具利用范式的一次重要轉變——從過去“一次性注入全部工具信息”的粗放模式,轉向了“按需動態檢索相關工具”的精細化、智能化模式。這種轉變,與RAG技術本身改變知識密集型任務中信息獲取方式的理念一脈相承。它不僅有效解決了當前LLM在規模化工具調用中面臨的Prompt膨脹和決策過載問題,更為未來構建具備數千種外部能力的、高度可擴展的AI系統鋪平了道路。
11.3 行業影響與應用前景

-
賦能AI助手生態擴展:使得AI助手能夠無縫連接并使用成千上萬的第三方服務和API,而無需擔心上下文窗口的限制,從而推動功能更強大、更通用的“超級應用”型AI助手的發展。
-
降低企業AI集成門檻:企業可以將現有的大量內部API和外部服務生態,以較低的成本、更便捷的方式集成到其AI系統中,避免了復雜的技術重構,加速了企業AI自動化轉型的進程。
-
革新開發者工具體驗:為開發者提供了更高效、更標準的API接入框架,有望催生更繁榮的AI功能市場和新型AI原生服務。
十二、總結與展望
RAG-MCP通過將檢索增強生成技術巧妙地引入大模型的工具調用流程,成功地解決了在面對大規模工具集時普遍存在的Prompt膨脹和選擇困難問題。它通過動態、按需地向LLM提供最相關的工具信息,而不是一次性加載所有工具,從而在大幅提升工具選擇準確率的同時,顯著降低了Prompt的長度和LLM的認知負擔。

這一創新范式不僅使得LLM能夠更有效地利用日益豐富的外部工具和服務,也為構建更強大、更靈活、更具擴展性的AI智能體奠定了堅實的基礎。RAG-MCP的出現,標志著我們向著能夠自如駕馭海量外部能力的通用人工智能又邁出了堅實的一步。
未來,我們期待看到更多基于RAG-MCP思想的演進和創新,例如更智能的分層檢索策略、更強大的多Agent協作機制,以及能夠從交互中持續學習和自我優化的自適應工具鏈等。這些技術的進步,將共同推動LLM工具調用能力的持續飛躍,最終構建出真正可靠、高效的大規模工具增強型AI系統。
對于所有致力于推動大模型應用落地、提升AI系統實用性和智能水平的研究者和開發者而言,RAG-MCP無疑提供了一個極具啟發性和實踐價值的優秀框架。
論文引用信息: Gan, T., & Sun, Q. (2025). RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation. arXiv preprint arXiv:2505.03275.





: 標準庫 <deque>)
考點分析——求三連)
)





)




)
