目錄
- 1. 引入
- 2. 現有漏洞識別方案的不足
- 2.1 數據集中label不準
- 2.2 數據重復
- 2.3 測評標準不夠好
- 3. 現有漏洞識別數據集分析
- 3.1 關于現有數據集中label的準確率分析
- 3.2 關于現有數據集中數據泄露( Data Leakage)情況分析
- 4. 漏洞識別測評
- 5. PrimeVul數據集構建過程
- 5.1 數據合并
- 5.2 數據去重
- 5.3 數據打標
- 5.4 數據切分
- 6. 模型測評情況
- 6.1 對開源代碼大模型進行微調后的測評
- 6.2 對GPT4和GPT3.5進行測評
- 7. 總結
- 8. 參考
1. 引入
參考1是2024年5月份發表在ICSE(47th IEEE/ACM International Conference on Software Engineering (ICSE 2025))上的一篇文章,文章題目是"Vulnerability Detection with Code Language Models: How Far Are We?"。它對現階段的漏洞數據集進行了分析,指出了現有數據集label不準和數據重復的問題,現有根據ACC/F1來做漏洞識別模型評測的不足,并給出了作者構建的另一個高質量數據集PrimeVul,還用這個數據測評了現有的SOTA的一些模型,并得出了現有模型做漏洞識別能力都不足的結論。
下面詳細解讀其核心思想。
2. 現有漏洞識別方案的不足
2.1 數據集中label不準
- 大部分數據集,都是自動打標,比如根據漏洞修復的commit來對函數打標。但真實世界中,修復漏洞的同時,也會對其他代碼做調整,這樣打標就導致誤標。
2.2 數據重復
- 數據重復:發現18.9%的樣本在測試集和訓練集中同時存在
2.3 測評標準不夠好
- 漏洞檢測任務不適合用accuracy來做評價,因為真實世界中漏洞很少,一直輸出0就能得到很高的acc
- 真實世界中漏洞檢測,防止誤報很重要
3. 現有漏洞識別數據集分析
3.1 關于現有數據集中label的準確率分析
現有數據集分析:
(1)Juliet和SARD這種老數據集不能表示真實世界漏洞的復雜性;
(2)真實開源軟件的漏洞:自動label的不準,手動label成本高。
手動label,成本高。比如SVEN數據集,雖然量少(1606個函數,半數都有洞),但質量高。
自動label的方法,一般是這樣做的:收集漏洞修復commit,把修復前的作為有洞數據,修復后的作為無洞數據。隨機取樣分析,每個數據集隨機抽樣50個函數,3個人工檢查,最終按投票決策,發現現有數據集label本身準確率較低,見表1。
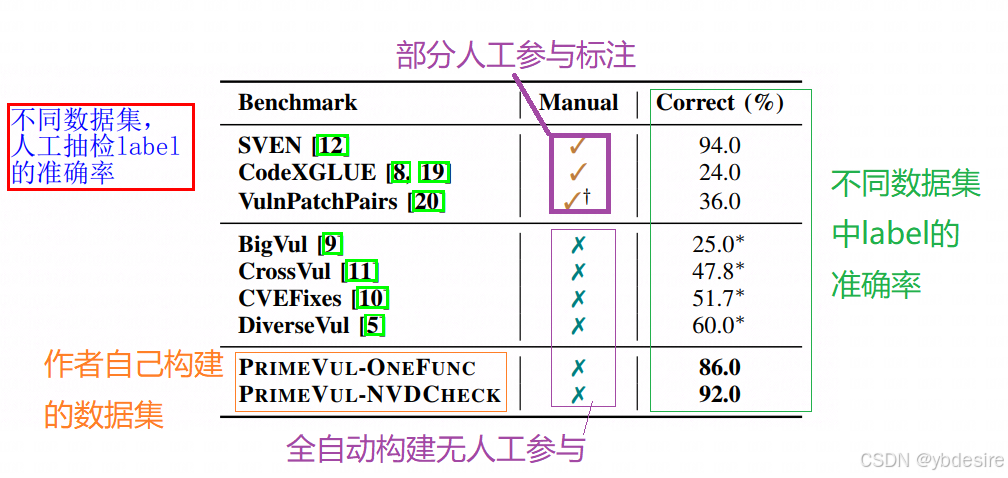
BigVul,CrossVul,CVEFixes,DiverseVul這四個都是比較知名的數據集,從表格中的數據看,準確率也都不行。
3.2 關于現有數據集中數據泄露( Data Leakage)情況分析
文中的 Data Leakage,指的是:測試集中含有訓練集中的數據。作者認為,目前大部分已經存在的漏洞數據集中,造成數據泄露的兩種情況是(1)數據復制(2)時間順序錯亂。
(1)數據復制
作者按照現有數據集來分析其訓練集和測試集中函數的重復性,得到的結果如下圖:
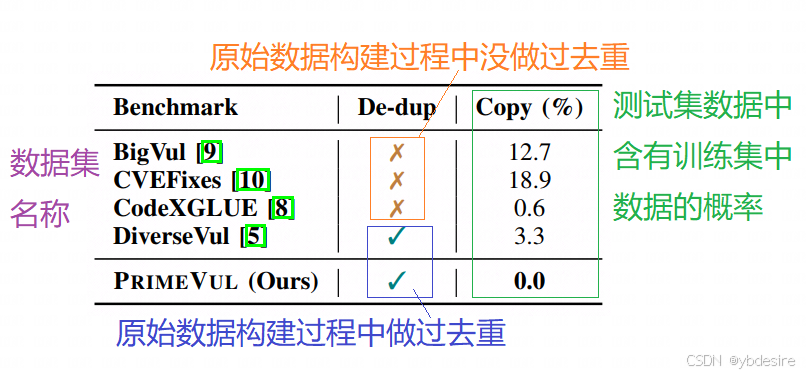
對于DiverseVul,它雖然做過hash去重,但還是有3.3%的重復率,因為它沒有對格式化字符做歸一化(比如空格的數量不同)。
(2)時間順序錯亂
大部分數據集構建時,采用隨機切分數據集為訓練集、測試集,這帶來的問題:
隨機劃分函數到不同集合中,會導致訓練和測試數據在時間順序上不合理,出現數據時間順序錯亂的 “時間穿越” 現象,這種現象會使得模型訓練和測試的結果不能真實反映模型在實際應用(用過去數據訓練預測未來數據)中的性能 。
4. 漏洞識別測評
真實世界中的漏洞檢測,開發者不關注F1和ACC,而是關注
(1)減少漏洞和誤報;
(2)對于文本上相似的代碼樣本(包括有漏洞的樣本和已修復補丁的樣本)的區分能力,也就是模型能否準確地區分有漏洞的代碼和已經修復了漏洞的代碼,即使它們在文本內容上很相似。
漏報太多,會導致安全問題;誤報太多,看不過來。所以漏報和誤報要平衡折中。作者認為:
(1)漏報率FNR要越低越好;
(2)有一些誤報FPR是可以接受的
作者提出的測評標準是Vulnerability Detection Score (VD-S)。公式為:FNR@(FPR≤r) ,其中 r∈[0%, 100%] 是可配置參數,文中選擇 r = 0.5% 進行評估。如果一個漏洞檢測模型的 VD-S 為 10%,意味著在誤報率被控制在 0.5% 的情況下,仍有 10% 的真實漏洞可能被漏檢。所以VD-S越低越好。
5. PrimeVul數據集構建過程
高質量數據集PrimeVul的構建過程:
5.1 數據合并
首先,對真實世界的數據集進行合并。作者將BigVul、CrossVul、CVEfixes和DiverseVul這些數據集中函數進行合并。作者沒有使用Devign和CodeXGLUE數據,因為作者發現這兩數據集中的內容的很大一部分與安全問題無關。
5.2 數據去重
去除空格、制表符(“\t”)、換行符(“\n”)和回車符(“\r”)等字符,對提交前后已更改的函數進行規范化處理。然后,我們計算已更改函數在提交前版本和提交后版本的 MD5 哈希值。如果一個函數的提交前版本和提交后版本產生相同的哈希值,我們就認為這個函數沒有發生變化,并且將其舍棄。
5.3 數據打標
作者構建了兩種數據打標策略,進一步提高label的正確率:
(1)PRIMEVUL-ONEFUNC
標注規則:如果某個函數是與安全相關的提交中唯一被更改的函數,那么就將這個函數視為存在漏洞的函數。
也就是說,在之前的標注方法中,當一個提交commit修改了多個函數時,可能會在判斷哪個函數真正存在漏洞。而 PRIMEVUL-ONEFUNC 方法通過限定只有當某個函數是安全相關提交中唯一被改動的函數時才認定它有漏洞,避免了在多函數修改提交情況下標注的模糊性和錯誤,提供了一種更明確、更準確的標注方式來確定函數是否存在漏洞 ,從而提高了數據標注的質量,有助于后續漏洞檢測模型的訓練和評估。
(2)PRIMEVUL-NVDCHECK
**關聯數據:**首先,我們將與安全相關的代碼提交(commits)與其對應的 CVE 編號以及 NVD 數據庫中的漏洞描述進行關聯。
數據標注:
- NVD 的描述中明確指出了該函數存在漏洞。這意味著在 NVD 對某個 CVE 的詳細描述中,直接提到了這個函數是有問題的,那么根據這個權威信息,我們就可以將該函數標記為存在漏洞。
- 當 NVD 的描述提到了某個函數所在的文件名,并且在這個文件中,這個函數是唯一因與安全相關的提交而被更改的函數時,該函數也會被認定為存在漏洞的函數。
5.4 數據切分
不是隨機切分訓練集、測試集。而是根據時間切分,老數據做訓練集,新數據做測試集。
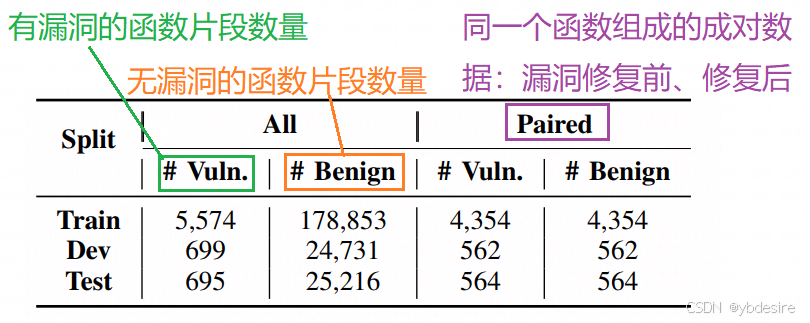
最終,得到的數據集PrimeVul如下:
6. 模型測評情況
作者對如下模型進行了測評
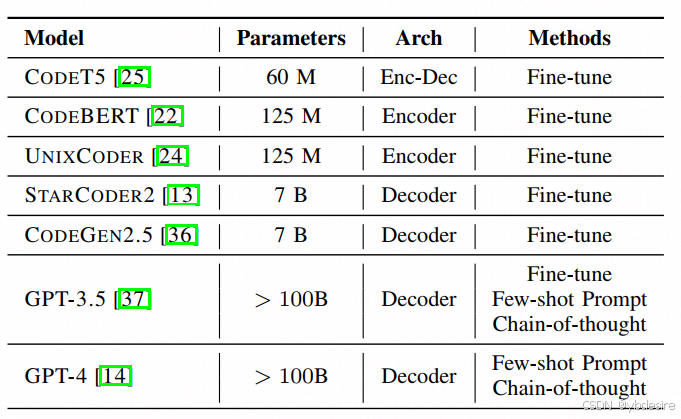
對CodeT5等開源代碼大模型,用PrimeVul微調后做了測評。
6.1 對開源代碼大模型進行微調后的測評
微調時,對StarCoder2和CodeGen2.5,epoch=4;對CodeT5和CodeBERT,epoch=10。微調后的模型測評結果如下:
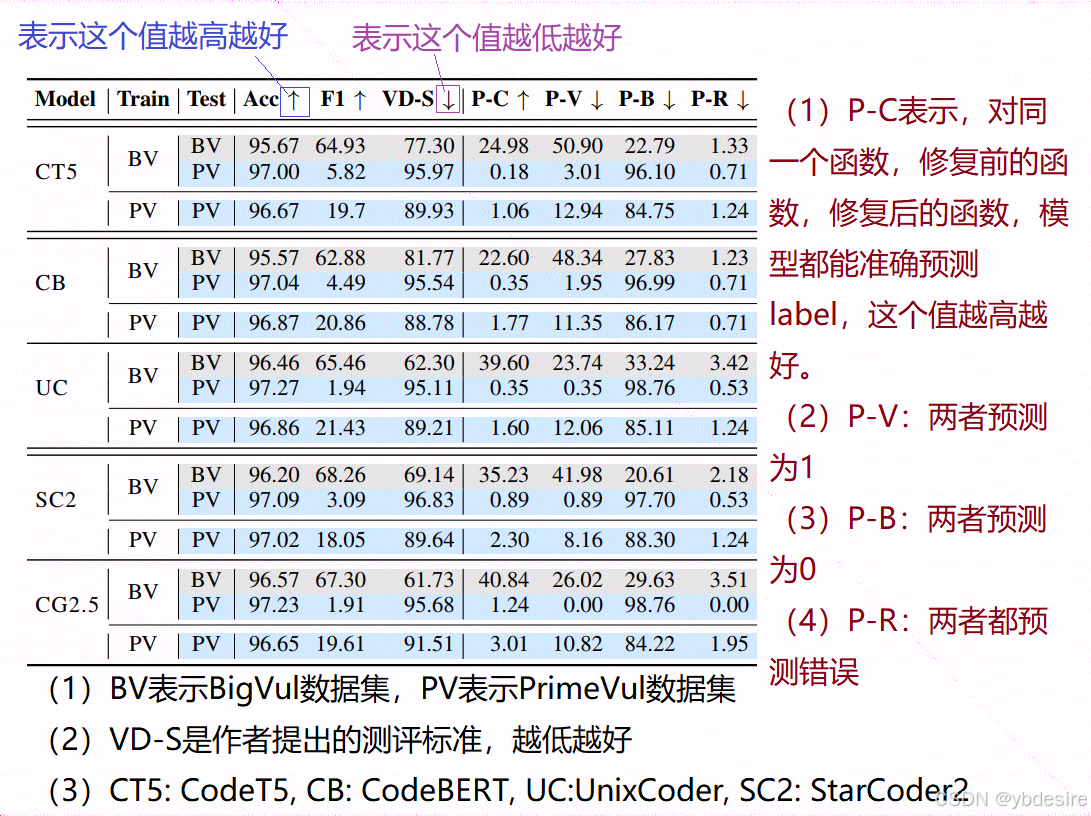
雖然 StarCoder2 模型在 BigVul 基準測試上表現出了值得稱贊的 F1 分數(達到 68.26%),但在 PrimeVul 基準測試上,它的 F1 分數卻急劇下降到了微不足道的 3.09%。這種大幅下降并非個例,而是在所有模型中都能觀察到的一種趨勢,這從觀察到的漏報率中就可以得到例證。也就是說,之前基于 BigVul 等基準測試所認為的模型具有較好的漏洞檢測能力,其實是不準確的,當使用更能反映現實漏洞復雜性的 PrimeVul 基準測試時,這些模型的真實表現很差,漏報率較高,無法有效地檢測出漏洞。這表明之前的基準測試存在局限性,不能真實反映代碼語言模型在實際漏洞檢測任務中的性能。
作者還做了更復雜的訓練,結果表明,用于二分類的先進訓練技術,例如對比學習和類別權重,并不能顯著提升代碼語言模型在 PrimeVul 數據集上的性能,這突顯了該任務在現實中的難度。
6.2 對GPT4和GPT3.5進行測評
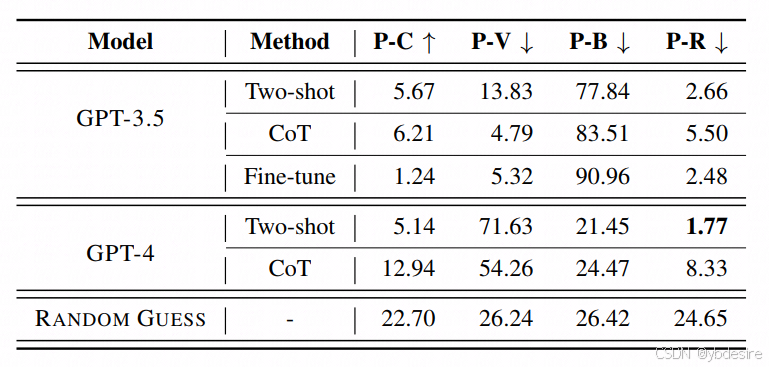
我們對 GPT-3.5 進行微調時,我們注意到該模型受到了漏洞樣本與良性樣本 1:3 比例的強烈影響,其表現甚至比使用提示方法時還要差。這是一個危險信號,表明即使是這樣一個大型的語言模型(LLM),仍然無法捕捉到漏洞模式,而是選擇了從數據中走捷徑(即依賴數據中的表面特征而非真正理解漏洞模式)。
所以,作者認為,即使是最先進的 OpenAI 模型,在 PrimeVul 數據集上也無法取得可靠的性能表現,這就需要從根本上采用全新的方法來改進這項任務。
7. 總結
PrimeVul作者對現有漏洞數據集進行分析,指出了現有數據集label不準和數據重復的問題,現有根據ACC/F1來做漏洞識別模型評測的不足,并給出了作者構建的另一個高質量數據集PrimeVul,還用這個數據測評了現有的SOTA的一些模型,并得出了現有模型做漏洞識別能力都不足的結論。作者的分析方法和高質量數據集構建的思路非常值得借鑒。
8. 參考
- https://arxiv.org/abs/2403.18624

)


動態API)

)
)











