1. Linux操作系統CPU平均負載
以前我們總認為CPU使用率和CPU平均負載是一樣的,負載高了就是CPU使用率提高。但是到底是什么情況呢?
1.1. CPU的平均負載
單位時間內 系統處于 可運行狀態 和不可中斷狀態 的平均進程數,就是平均活躍進程數,和CPU使用率并沒有直接關系
- 可運行狀態:
-
- 正在使用CPU或者等待CPU的進程
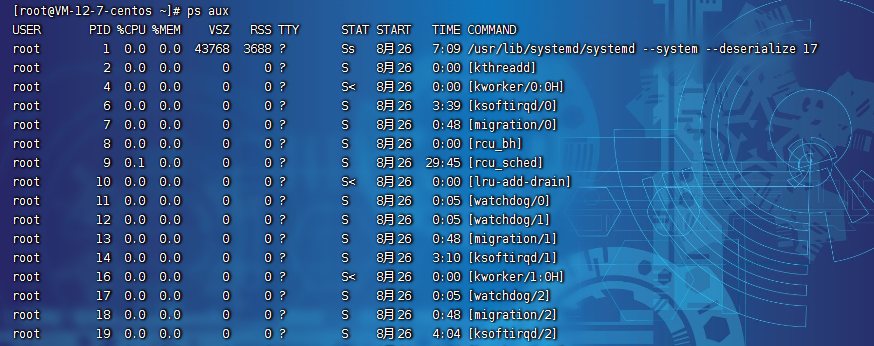
- 用ps aux命令看到的, 處于R狀態(Running或Runnable)的進程
- 不可中斷狀態:
-
- 正處于內核態關鍵流程中的進程,且流程不可被打斷。
- 比如 等待硬件設備的IO響應,為了保證數據一致性,進程向磁盤讀寫數據時,在得到磁盤響應前是不能被其他進程中斷打斷的
- ps aux 命令中D狀態的進程
| PS 中常見 STAT 狀態 | 描述 |
| D | 無法中斷的休眠狀態(通常 IO 的進程) |
| R | 正在運行,或在隊列中的進程 |
| S | 處于休眠狀態 |
| T | 停止或被追蹤 |
| Z | 僵尸進程 |
| < | 優先級高的進程 |
| n | 優先級較低的進程 |
| L | 有些頁被鎖進內存 |
| s | 進程的領導者(在它之下有子進程) |
| l | 多進程的(使用 CLONE_THREAD,類似 NPTL pthreads) |
| + | 位于后臺的進程組 |
1.2. 如何查看平均負載?
我們可以使用uptime查詢CPU的平均負載。
![]()
load average后的3個數字分別代表1分鐘,5分鐘,15分鐘的CPU平均負載。
查看服務器總的邏輯cpu個數:cat /proc/cpuinfo | grep "processor" | wc -l
![]()
分析:
- 如果我們的平均負載為2,則邏輯cpu為2時剛剛好可以利用。但是如果邏輯cpu為4,則表示有50%空閑
- 如果1,5,15分鐘差值不大,說明負載穩定。
- 如果1分鐘值遠小于15分鐘,說明系統最近1分鐘在降低,前15分鐘壓力大;如果1分鐘值遠大于15分鐘,則表示最近1分鐘的負載在增加,平均負載接近或超越CPU個數,意味著系統正在發生過載問題,持續的時間長說明問題需要優化。
平均負載的合理分布范圍:常規推薦等于CPU核數即可,同時也要看業務場景和歷史趨勢。
2. CPU的使用率和平均負載區別
2.1. CPU使用率
CPU非空閑狀態運行的時間占比,反映CPU的繁忙程度,和平均負載不一定完全一致。
比如當我們在進行軟件開發的時候,我們項目前期每個人都有比較多的事情去做,這時候平均負載很高,CPU使用率也很高。當項目進入測試階段,開發人員都在等待測試結果,十分空閑卻不可以離開現在的崗位,這時候的CPU利用率很低但是負載很高。
在生產中系統的CPU使用總量不建議超過70%~80%。
Linux中我們使用top命令來查看CPU的使用率
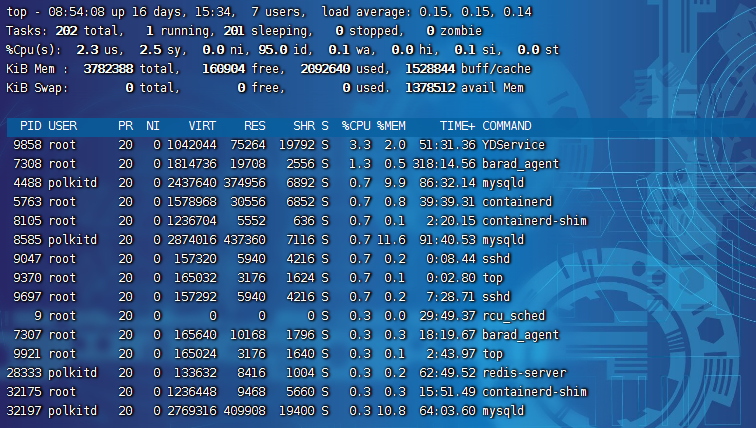
- us(user):CPU 在用戶態運行的時間百分比,通常用戶態 CPU 高表示有應用程序比較繁忙,值高則 CPU 使用率高。
- sy(sys):CPU 在內核態運行的時間百分比(不包括中斷),內核態 CPU 越低越不值,值高則 CPU 使用率高。
- id(idle):CPU 處于空閑態的時間占比,CPU 會執行一個特定的虛擬進程,名為 System Idle Process,值高的話,說明 CPU 比較空閑。
- wa(iowait):CPU 在等待 I/O 操作完成所消耗的時間,該指標越低越好,否則表示 I/O 存在瓶頸,用 iostat 命令進一步分析。
- hi(hardirq):CPU 處理硬中斷所花費的時間,由外設硬件(如鍵盤控制器、硬件傳感器等)發出的中斷信號,快速執行。
- si(softirq):CPU 處理軟中斷所花費的時間,由軟件程序(如網絡收發、定時調度等)發出的中斷信號,延遲執行。
- st(steal):CPU 被其他虛擬機占用的時間,僅出現在多虛擬機場景,指標過高的話,檢查下宿主機或其他虛擬機是否異常。
2.2. CPU使用率和平均負載的區別
CPU平均負載 指單位時間內活躍進程數,包括正在使用CPU的進程,還包括可等待CPU和等待IO的進程(不可中斷狀態)。
CPU使用率 是指單位時間內CPU繁忙情況的統計。
- CPU密集型:也叫做計算機密集型,表示該任務需要大量的運算,沒有阻塞CPU一直會全速運行。
- IO密集型: 程序需要大量IO操作,大部分時間是CPU在等待IO(硬盤/內存)的讀寫操作。CPU使用率低,但等待IO也會導致平均負載升高。當線程進行IO操作CPU空閑時,啟動其他線程繼續使用CPU,提高CPU的使用率。
區別說明:
- CPU密集型進程,使用大量CPU運算 會導致平均負載升高,這個場景兩者是一致的
- IO密集型進程,等待IO也會導致平均負載升高,但CPU使用率不一定高
-
- CPU的效率要遠高于磁盤,磁盤讀寫請求過多會導致大量IO等待
- 進程在CPU上訪問磁盤文件,CPU會像內核發起調用文件請求,讓內核去取磁盤文件,這個時候CPU會切換到其他進程或者空閑
- 任務會轉換為 不可中斷的睡眠狀態,當這種讀寫請求過多會導致不可中斷睡眠狀態的進程過多,導致CPU負載高,利用率低的情況。
- 大量等待CPU的進程調度也會導致平均負載升高,此時CPU使用率也會比較高
3. 生成環境Linux操作系統CPU壓測環境準備
我們知道線上Linux會存在多個瓶頸問題,CPU、內存、IO、帶寬等,所以這時候我們就需要去準備相應的工具,模擬生成環境出現的多種問題,這時候我們選擇的壓測程序,讓CPU產生瓶頸,如何再進行分析。
目標:分析Linux相關性能指標,找出CPU平均負載升高的進程和原因,原因一般為多個進程搶占CPU、等待IO、CPU上下文切換
思路:先看全局,找到系統的哪個資源問題,是CPU還是IO還是啥瓶頸,。知道具體后,再看啥哪個進程導致的這個資源問題。
核心命令+應用場景:
- sysstat 工具包的命令
-
- mpstat(全局) 多核CPU性能分析程序,實時查看每個CPU的性能指標和全局CPU的平均性能指標
- pidstat(局部) 實時查看進程的CPU、內存、IO、上下文切換等指標
- vastart(全局)實時查看系統的上下文切換(跨進程間,同個進程里多個子進程)、系統中斷次數
下載地址:https://mirrors.aliyun.com/blfs/conglomeration/sysstat/ 版本號為:12.7.2
在 /user/local/software/arch文件夾下傳入sysstat壓縮包,編寫以下指令
# 安裝環境
yum install unzip -y# 進入目錄
cd /user/local/software/arch# 解壓縮文件
tar -xvJf sysstat-12.7.2.tar.xz# 配置編譯參數
./configure# 編譯并安裝
make
sudo make install# 查看版本
pidstat -V模擬壓測工具:
- stress多進程工具,模擬IO密集型應用,CPU密集型應用,多進程等待CPU調度場景,對CPU,內存,IO等情況進程壓測
yum install -y epel-release
yum install stress -y- sysbench多線程基準測試工具,模擬上下文切換過多場景等
sudo yum install -y epel-release
sudo yum install -y sysbench
sysbench --version基準測試:
- 通過設計科學的測試方法、測試工具和測試系統,實現對一類測試對象的某項性能指標進行定量的和看對比的測試
- 技術人員為了確定當前環境、系統、服務器等的性能情況而進行的測試,為了在同一環境條件下進行性能優而進行的測試
- 場景:數據庫sql語句、索引、應用代碼、網絡、機器硬件配置等
- 核心點
-
- 測試過程是看重復執行的
- 每次的基準測試都應該在相同環境下進行,除了某項測試變動,其他的軟件和硬件組成等各種保持一致
- 除了被測試系統是處于運行和可調整狀態外,要避免其他程序或者調整,以免影響基準測試結果
4. Linux性能優化診斷pidstat+mpstat
4.1. mpstat
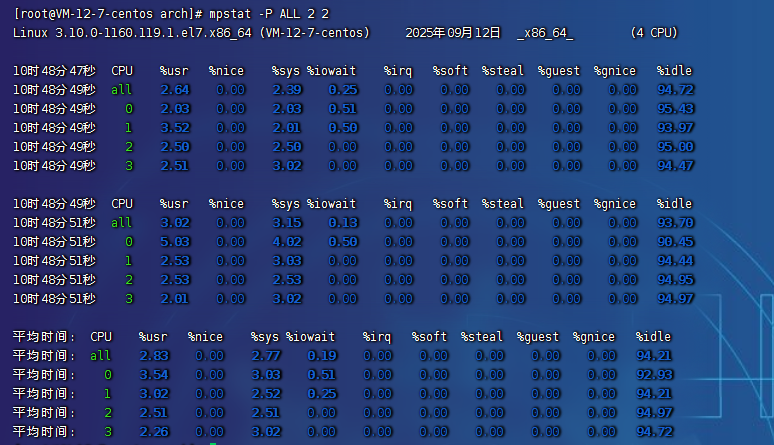
多核CPU性能分析程序,實時查看每個CPU的性能指標和全部CPU的平均性能指標。
- 使用場景:當系統變慢,CPU平均負載增大,判斷是CPU的使用率增大,還是IO壓力增大的情況導致
- 格式:
mpstat [-P {ALL|n}] [ <時間間隔> ] [ <次數> ]列如:mpstat -P ALL 2 3,表示每隔2秒出一個報告數據,共出3次
| 參數 | 說明 |
| -P | 指定監控哪個 CPU,范圍是 [0 - (N-1)],ALL 表示監控所有 CPU 都監控 |
| internal | 兩次采樣的間隔時間 |
| count | 總采樣次數 |
| 字段 | 說明 |
| CPU | 全部 CPU 和某個 CPU,從 0 開始 |
| %usr | 用戶態所使用 CPU 時間的百分比,CPU 使用率 |
| %nice | nice 值為負進程的 CPU 時間,即使用 nice 命令對進程進行降級時 CPU 的百分比 |
| %sys | 內核態所使用 CPU 時間的百分比,CPU 使用率 |
| %iowait | CPU 在等待 I/O 操作完成所消耗的時間,高表示可能 I/O 存在瓶頸 |
| %irq | 用于硬中斷的 CPU 百分比 |
| %soft | 用于軟中斷的 CPU 百分比 |
| %steal | 虛擬機強制 CPU 等待的時間百分比(基本很少關注) |
| %guest | 虛擬機占用 CPU 時間的百分比(基本很少關注) |
| %gnice | CPU 運行帶 nice guest 虛擬機所花費的時間百分比(基本很少關注) |
| %idle | CPU 空閑且系統沒有未完成的磁盤 I/O 請求的時間百分比;CPU 使用率低,iowait 高,idle 低的話可能是等待 I/O |
4.2. pidstat
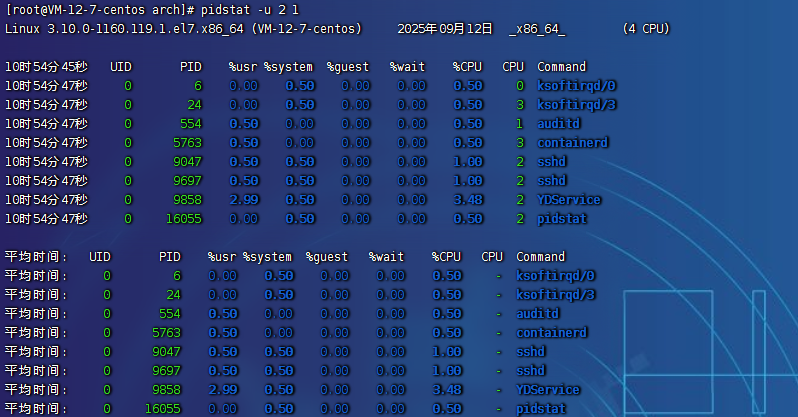
實時查看進程的CPU、內存、IO、上下文切換等指標
- 格式:
pidstat [ 選項 ] [ <時間間隔> ] [ <次數> ],比如pidstat -u 2 3表示每隔 2 秒出一個報告數據,一共出具 3 次。 - 輸出排序:
pidstat -u | sort -k 8 -r
-
sort排序:指定排序用哪一列,示例中是第 8 列%CPU。-r:倒序。
| 參數 | 說明 |
| -u | 默認的參數,顯示各個進程的 cpu 使用統計,監控 cpu, 和 是等效的 |
| -r | 顯示各個進程的內存使用統計,監控內存 |
| -d | 顯示各個進程的 I/O 使用情況,監控硬盤 |
| -p | 指定進程號,比如 |
| -w | 顯示每個進程的上下文切換情況 |
| -t | 顯示選擇任務的線程的統計信息外的額外信息 |
| 字段 | 說明 |
| PID | 進程 ID |
| %usr | 進程在用戶態所使用 CPU 時間的百分比,CPU 使用率 |
| %system | 進程在內核態所使用 CPU 時間的百分比,CPU 使用率 |
| %guest | 進程在虛擬機占用 cpu 的百分比(基本很少關注) |
| %wait | 進程等待 cpu 的時間百分比,進程處于就緒隊列中的狀態等待 CPU 調度運行的百分比【新版才有】 |
| %CPU | 進程占用 cpu 的百分比,和 top 命令一樣等于用戶態 CPU + 內核態 CPU,如果要區分 cpu 哪個多則用 pidstat |
| CPU | 處理進程的 cpu 編號 |
| Command | 當前進程對應的命令 |
pidstat -d
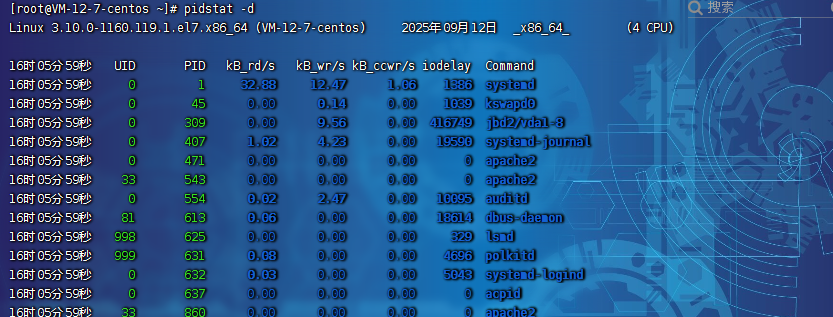
| 字段 | 說明 |
| PID | 進程 ID |
| kB_rd/s | 每秒從磁盤讀取的 KB |
| kB_wr/s | 每秒寫入磁盤 KB |
| kB_ccwr/s | 每秒進程被取消向磁盤寫的數據量 (以 kB 為單位) |
| iodelay | 塊 I/O 延遲(iodelay),包括等待同步塊 I/O 和換入塊 I/O 結束的時間 |
| Command | 當前進程對應的命令 |
4.3. 壓測工具stress
多線程工具,模擬IO密集型應用,CPU密集型應用,多線程等待CPU調度場景,對CPU,內存,IO等情況進行壓測
| 參數 | 說明 |
| --timeout | 指定運行多少秒 |
| --cpu N | 產生多個處理 函數的 CPU 進程,每個進程高頻的計算隨機數的平方根,模擬 CPU 計算密集型場景 |
| --io N | 產生多個處理 函數的磁盤 I/O 進程,每個進程高頻調用 ,刷內存緩沖區到磁盤,模擬 I/O 密集型場景 |
| --vm N | 每個進程高頻調用內存分配 和內存釋放 函數 |
| --vm-bytes | 指定 時申請內存的字節數,默認 256MB |
| --hdd N | 產生 N 個高頻執行 和 函數的進程(創建 / 寫入 / 刪除文件),屬于磁盤 I/O 進程 |
| --hdd-bytes | 每個 hdd worker 進程讀寫的 byte 數,默認 1G |
5. 綜合實戰
5.1. 模擬 CPU 密集型應用,系統是 4 核
- 終端一:模擬兩個 CPU 核的使用率 100%,對 2 個 CPU 進行壓力測試,持續 600s,命令為
stress --cpu 2 --timeout 600 - 終端二:
-d參數表示高亮顯示變化的區域,命令為watch -d uptime - 終端三:
mpstat查看 CPU 使用率情況,每 5 秒監控所有 CPU 情況,命令為mpstat -P ALL 5 - 終端四:查看運行中的進程和任務,每 5 秒刷新一次,命令為
pidstat -u 5
宏觀思路
- 先看全局,找系統哪個資源有問題,是 CPU、I/O 還是磁盤瓶頸
- 知道具體問題后,再看是哪個進程導致的這個資源問題
詳細分析思路
- 全局
-
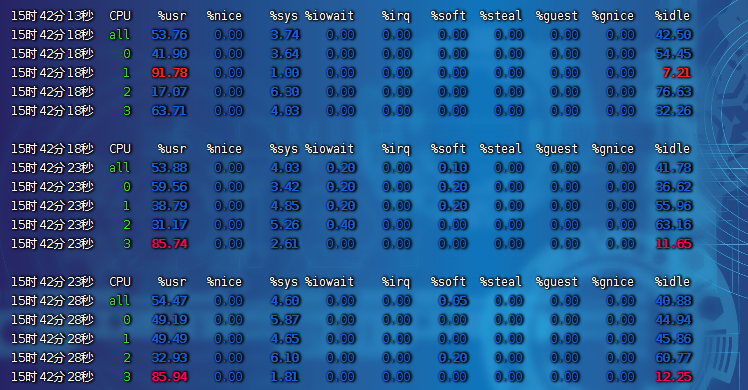
uptime:運行 1 分鐘后,4 個核的 CPU 負載是 2,高負載可以到 4mpstat:
-
-
- 應用場景:當系統變慢,CPU 平均負載增大時,判斷是 CPU 的使用率增大,還是 I/O 壓力增大的情況導致
- CPU 的兩個核在用戶態使用率是 100%,兩個核數空閑的,總的 CPU 使用率是 50%,% iowait 為 0,不存在 I/O 瓶頸
sqrt()函數的 CPU 進程是在用戶態,所以是 % usr 升高,而 % sys 沒啥變化
-
- 局部
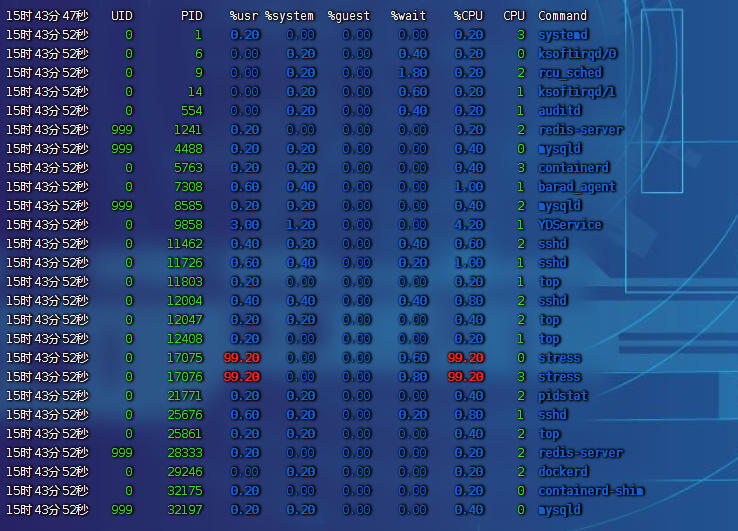
-
pidstat:對進程和任務的使用情況進行查看,發現stress進程對 2 塊 CPU 使用率過高,導致 CPU 平均負載增加。- 舉一反三:如果不是
stress,其他進程造成這類影響的,靠這個思路也能排查出是哪個進程,包括壓測 4 個核。 - CPU 使用率高,CPU 平均負載也高;CPU 平均負載高,CPU 使用率不一定高。
線程1
![]()
線程2

線程3
線程4
5.2. 模擬 I/O 密集型應用,系統是 4 核
- 終端一:模擬四個 I/O 進程,持續 600s,命令為
stress --io 4 --timeout 600 - 終端二:
-d參數表示高亮顯示變化的區域,命令為watch -d uptime - 終端三:
mpstat查看 CPU 使用率情況,每 5 秒監控所有 CPU 情況,命令為mpstat -P ALL 5 - 終端四:查看運行中的進程和任務,每 5 秒刷新一次,命令為
pidstat -u 5
- 宏觀思路
-
- 先看全局,找系統哪個資源有問題,是 CPU、I/O 還是磁盤瓶頸
- 知道具體問題后,再看是哪個進程導致的這個資源問題
- 局部
-
pidstat:對進程和任務的使用情況進行查看,發現stress進程對 CPU 使用率比較高,導致 CPU 平均負載增加- % iowait 有一定數值,但不高,使用
pidstat -d查看,沒太多磁盤讀寫,但有 iodelay
線程一
![]()
線程二

線程三
線程四
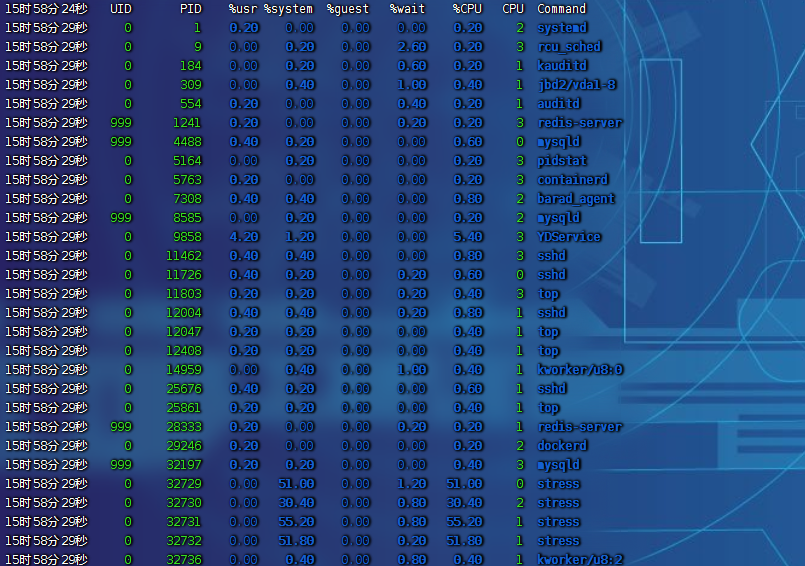
5.3. IO密集型案例
- 終端一:模擬兩個磁盤 I/O 進程,持續 600s,命令為
stress --hdd 2 --hdd-bytes 6G --timeout 600 - 終端二:
-d參數表示高亮顯示變化的區域,命令為watch -d uptime - 終端三:
mpstat查看 CPU 使用率情況,每 5 秒監控所有 CPU 情況,命令為mpstat -P ALL 2 3(每隔 2 秒出一個報告數據,一共出具 3 次) - 終端四:查看運行中的進程和任務,每 5 秒刷新一次,命令為
pidstat -u 2 3(每隔 2 秒出一個報告數據,一共出具 3 次)
宏觀思路
- 先看全局,找系統哪個資源有問題,是 CPU、I/O 還是磁盤瓶頸。
- 知道具體問題后,再看是哪個進程導致的這個資源問題。
詳細分析思路
- 全局
-
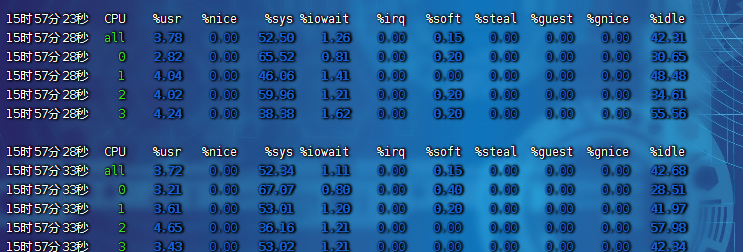
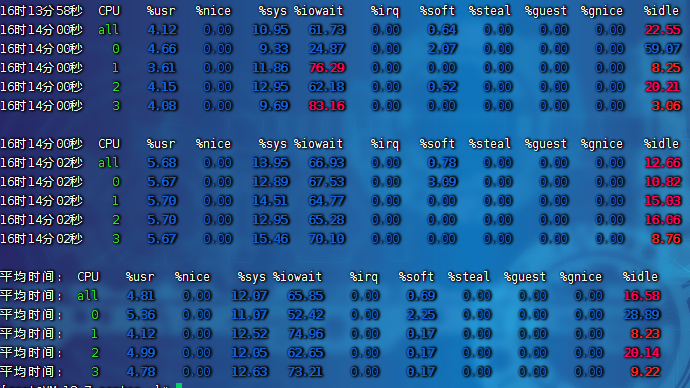
uptime:運行 1 分鐘后,4 個核的 CPU 負載比較高。mpstat:
-
-
- 應用場景:當系統變慢,CPU 平均負載增大時,判斷是 CPU 的使用率增大,還是 I/O 壓力增大的情況導致
- 多次調用
mpstat,持續觀察,平均負載升高,但 CPU 使用率沒啥變化,% iowait 大于 50% 且比較高 - 一直在等待 I/O 處理,說明進程是 I/O 密集型,進程頻繁進行 I/O 操作,導致系統平均負載很高,而 CPU 使用率不高
-
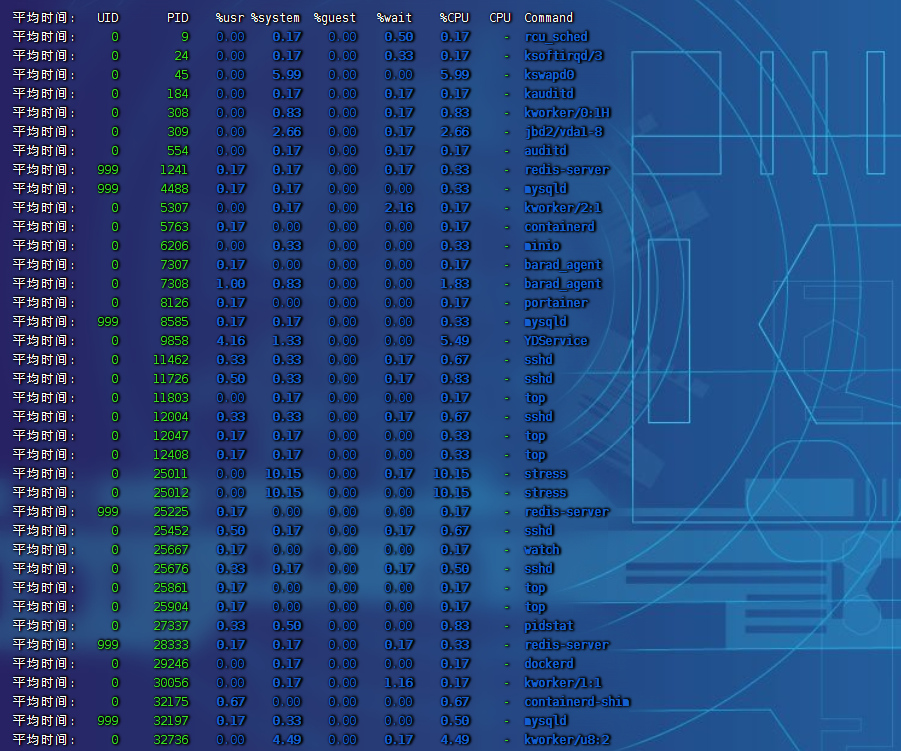
- 局部
-
ps aux里stat字段 D 的狀態一般是 I/O 出現了問題,說明進程在等待 I/O,比如磁盤 I/O、網絡 I/O 或者其他pidstat:對進程和任務的使用情況進行查看,發現stress進程對 CPU 使用率不高,但 CPU 平均負載高- 舉一反三:如果不是
stress,其他進程造成這類影響的,靠這個思路也能排查出是哪個進程。 - CPU 使用率高,CPU 平均負載也高;CPU 平均負載高,CPU 使用率不一定高,則可能 I/O 瓶頸
線程一
![]()
線程二

線程三
線程三
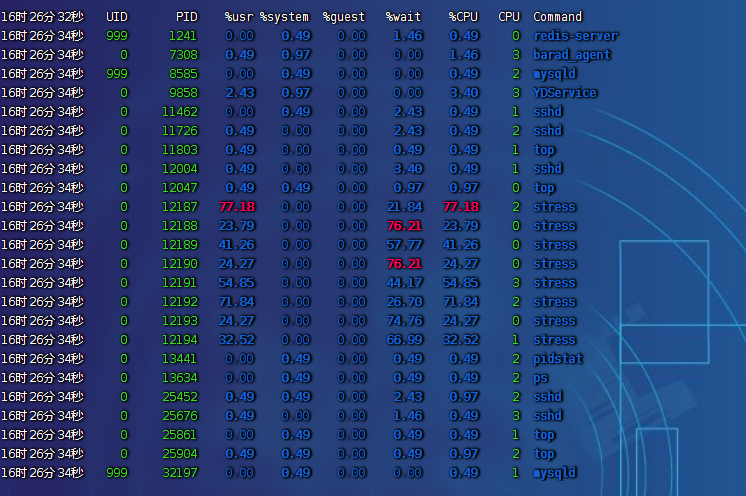
5.4. 大量等待 CPU 的進程調度,導致平均負載升高,CPU 使用率也會比較高,系統是 4 核
- 終端一:模擬 8 個進程(也可更多),持續 600s,命令為
stress --cpu 8 --timeout 600 - 終端二:
-d參數表示高亮顯示變化的區域,命令為watch -d uptime - 終端三:
mpstat查看 CPU 使用率情況,每隔 2 秒出一個報告數據,一共出具 3 次,命令為mpstat -P ALL 2 3 - 終端四:查看運行中的進程和任務,每隔 2 秒出一個報告數據,一共出具 3 次,命令為
pidstat -u 2 3
宏觀思路
- 先看全局,找系統哪個資源有問題,是 CPU、I/O 還是磁盤瓶頸。
- 知道具體問題后,再看是哪個進程導致的這個資源問題。
詳細分析思路
- 全局
-
uptime:運行 1 分鐘后,4 個核的 CPU 負載比較高。mpstat:
-
-
- 應用場景:當系統變慢,CPU 平均負載增大時,判斷是 CPU 的使用率增大,還是 I/O 壓力增大的情況導致
- 多次調用
mpstat,持續觀察,平均負載升高,每個 CPU 利用率都高,使用率接近 100%,% iowait 很低接近 0,I/O 不是瓶頸 - 再進一步分析,CPU 利用率高,主要是哪部分操作占據了 CPU
-
- 局部
-
pidstat:對進程和任務的使用情況進行查看,發現%wait高,說明 CPU 不夠用,在等待 CPU 調度上花費了不少時間- 結論:8 個進程在競爭 4 個 CPU,每個進程等待 CPU 的時間達到 50%(
%wait),超出 CPU 計算能力的進程,導致了負載變高
-
-
pidstat -u:CPU 情況,默認pidstat -d:磁盤 I/O 情況,基本很低
-
-
- 舉一反三:如果不是
stress,其他進程造成這類影響的,靠這個思路也能排查出是哪個進程
- 舉一反三:如果不是
線程一
![]()
線程二

線程三

線程四
)









)




)



