爬蟲本質:通過編寫程序來獲取到互聯網上的資源。
我們的程序本質上就是模擬瀏覽器
一個簡單的小爬蟲:
只需要三步:
from urllib.request import urlopen
#url是網址,request意思是請求
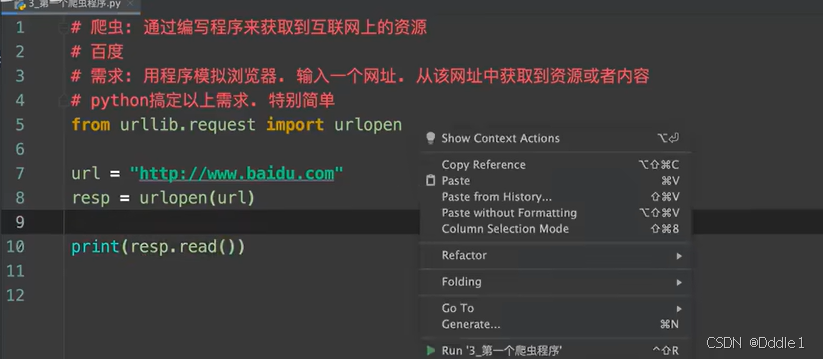
這里跑出來的中文是這樣的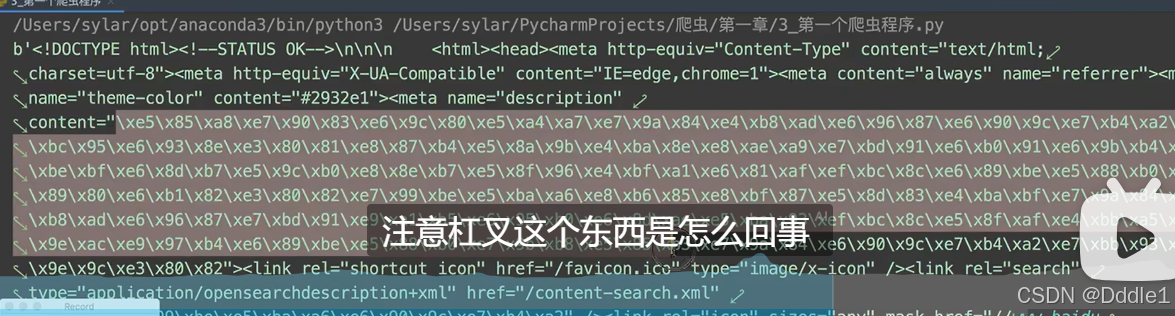 注意看:前面有一個b',這代表后面的是字節,也就是說我們需要自己把它這個還原成我們想要看到的字符串,我們可以這樣還原:
注意看:前面有一個b',這代表后面的是字節,也就是說我們需要自己把它這個還原成我們想要看到的字符串,我們可以這樣還原:
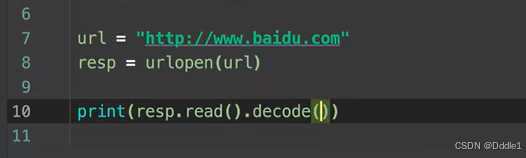
不過這里面的問題就來了,我們解碼是按照utf-8還是jdk呢?其實源代碼里有寫的: 所以這個地方是:
所以這個地方是:
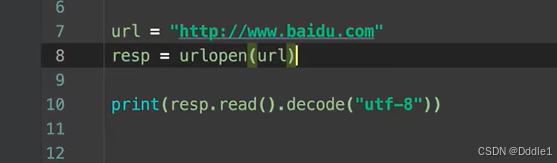
現在就變成中文的了:
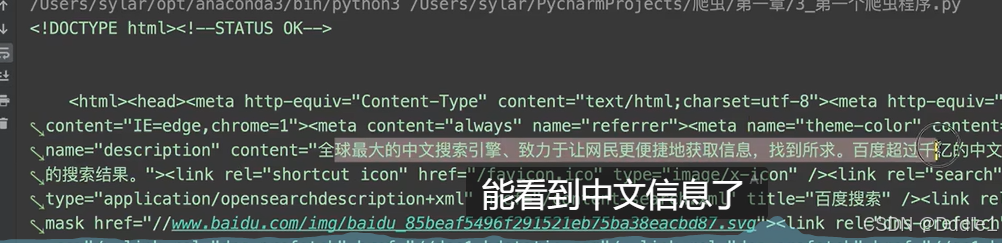
不過現在還是有個問題,我們得到的源碼里面一大堆看不懂的東西。我們先把它們保存到一個文件里去。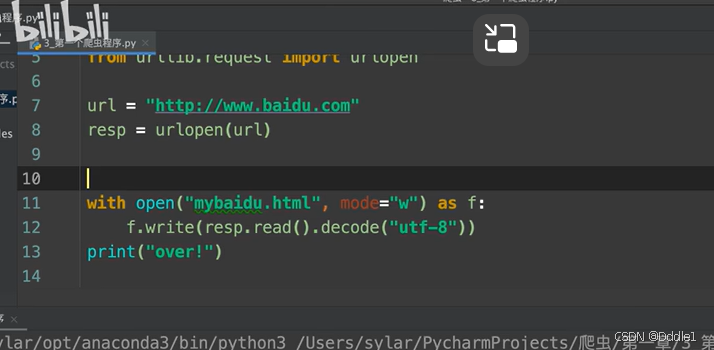 如果文件里出現亂碼,就:
如果文件里出現亂碼,就:


我們拿到了這些東西: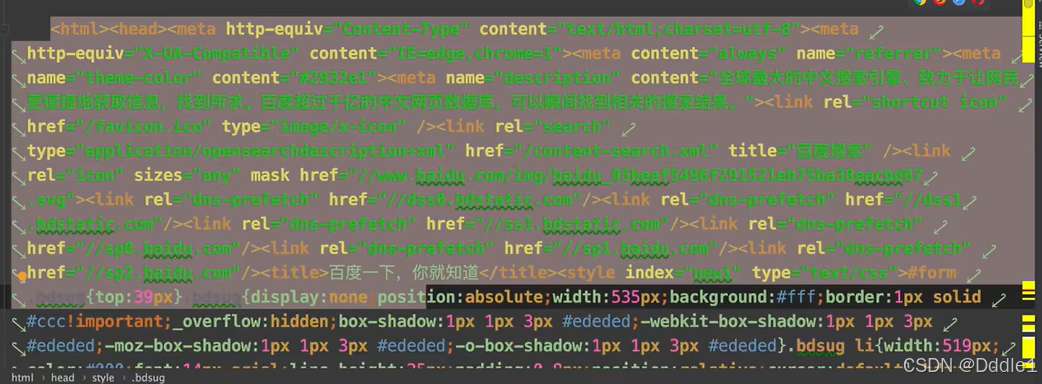 其實我們的瀏覽器拿到的也是這些東西,只是瀏覽器把它運行成這個樣子:
其實我們的瀏覽器拿到的也是這些東西,只是瀏覽器把它運行成這個樣子:
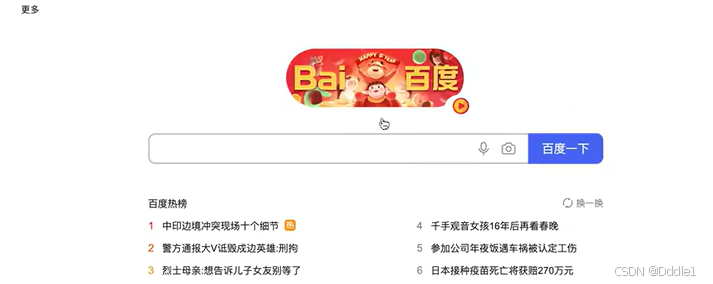 瀏覽器里我們只要輸入網址,按下回車,就相當于發送了一個請求。
瀏覽器里我們只要輸入網址,按下回車,就相當于發送了一個請求。
web請求過程剖析:
響應分為兩種,一種是服務器渲染,另一種是客戶端渲染。服務器渲染就是在服務器端把數據和html源碼結合在一起,我們要的數據在html源碼里,客戶端渲染是第一次請求的時候只返回html框架,第二次請求的時候把關鍵字發給服務器,服務器再把數據返回,也就是說html源碼和數據是分開的

動態API)

)
)














)