目錄
一、什么是向量?
二、為什么需要向量數據庫?
三、向量數據庫的特點
四、常見的向量數據庫產品
FAISS 支持的索引類型 vs 相似度
五、常見向量相似度方法對比
六、應該用哪種
七、向量數據庫的核心邏輯
🔍 示例任務:查找與這句話最相似的一句話
八、圖示:向量空間中的相似度搜索
九、實際案例:文本語義檢索
十、實際案例:圖像搜索
十一、總結圖:向量數據庫流程
十二、 faiss向量數據代碼用例
說明
文件結構
?documents.txt
main.py(簡化版)
運行結果

向量數據庫(Vector Database)是一種專門用于存儲、管理和檢索高維向量數據的數據庫系統。它的核心作用是實現相似度搜索(Similarity Search),即在海量數據中快速找到“最相似”的數據項。
一、什么是向量?
在機器學習和人工智能中,向量是一種用來表示數據的數學結構。比如:
-
一張圖片可以被編碼成一個128維的向量。
-
一段文本可以通過模型(如BERT)轉換成768維的向量。
-
用戶的興趣或商品的特征也可以表示為向量。
這些向量通常來源于神經網絡模型,稱為“嵌入向量(embedding)”。
二、為什么需要向量數據庫?
傳統數據庫適合處理結構化數據(如數字、字符串等),而不適合處理向量的“相似性檢索”。向量數據庫的優勢在于可以支持如下需求:
-
檢索與某段文本語義相似的內容(如ChatGPT的知識搜索)
-
找到與用戶行為相似的商品或視頻(推薦系統)
-
查找長相相似的人臉圖像(圖像識別)
-
在安全監控中匹配相似的車牌或目標(目標識別)
三、向量數據庫的特點
| 特點 | 描述 |
|---|---|
| 高維向量支持 | 支持數十到上千維的向量存儲與計算 |
| 相似度檢索 | 支持基于余弦相似度、歐氏距離、點積等方式的Top-K搜索 |
| 近似最近鄰搜索(ANN) | 使用高效算法(如 HNSW、IVF、PQ)實現“近似而快速”的搜索 |
| 可擴展性 | 能夠處理上億甚至上百億條向量數據 |
| 多模態支持 | 支持圖像、文本、音頻等多種模態的向量嵌入 |
四、常見的向量數據庫產品
| 名稱 | 特點 |
|---|---|
| FAISS(Meta) | 高性能向量搜索庫,適合本地使用 |
| Milvus | 開源,分布式,支持億級向量,適合工業部署 |
| Weaviate | 支持文本搜索和語義索引,內置向量生成 |
| Pinecone | 云原生,面向生產級應用 |
| Qdrant | 支持高效過濾器和payload數據的檢索 |
FAISS 支持的索引類型 vs 相似度
| FAISS 索引類型 | 支持相似度方式 | 是否需歸一化 |
|---|---|---|
IndexFlatL2 | 歐氏距離 | ? 否 |
IndexFlatIP | 內積(近似余弦) | ? 是(手動) |
IndexFlatCosine | ? 余弦相似度 | ? 自動歸一化(新版本才支持) |
- FAISS: Meta 開源的向量檢索引擎?https://github.com/facebookresearch/faiss
- Pinecone: 商用向量數據庫,只有云服務?The vector database to build knowledgeable AI | Pinecone
- Milvus: 開源向量數據庫,同時有云服務?Milvus | High-Performance Vector Database Built for Scale
- Weaviate: 開源向量數據庫,同時有云服務?The AI-native database developers love | Weaviate
- Qdrant: 開源向量數據庫,同時有云服務?Qdrant - Vector Database - Qdrant
- PGVector: Postgres 的開源向量檢索引擎?https://github.com/pgvector/pgvector
- RediSearch: Redis 的開源向量檢索引擎?https://github.com/RediSearch/RediSearch
- ElasticSearch 也支持向量檢索?Elasticsearch vector search - highly relevant, lightning fast search | Elastic
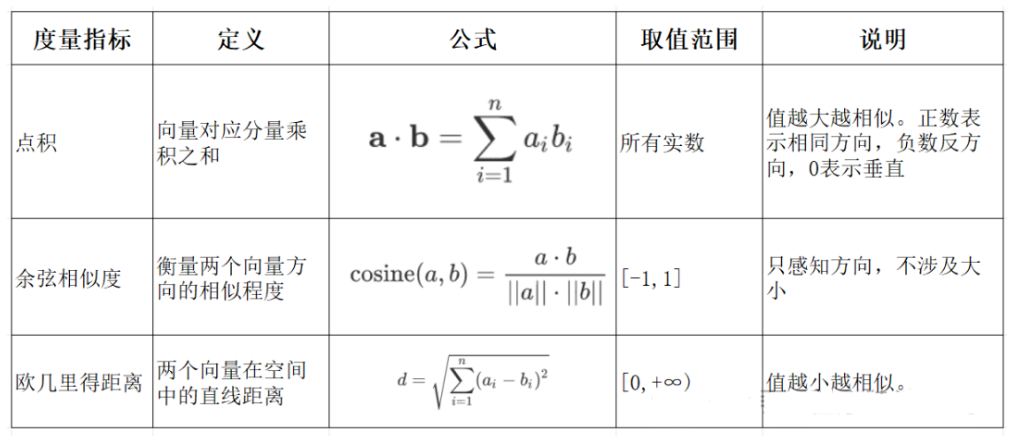
五、常見向量相似度方法對比
| 方法名稱 | 公式(向量 A 和 B) | 取值范圍 | 越小越相似? | 特點說明 |
|---|---|---|---|---|
| 歐氏距離 (L2) | [0, +∞) | ? 是 | 距離越小越相似。對向量長度敏感。 | |
| 余弦相似度 | [-1, 1] | ? 否 | 越接近 1 越相似。方向相近即可,不管長度。 | |
| 內積 (dot product) | 任意實數 | ? 否 | 通常需要歸一化后使用,變成余弦相似度。 |
六、應該用哪種
| 場景 | 推薦相似度類型 | 理由 |
|---|---|---|
| 文本檢索 / 語義搜索 | 余弦相似度 or 內積(需歸一化) | 語義相似的句子方向一致,即便長度不同也應視為相似。 |
| 數值空間距離計算 | 歐氏距離(L2) | 更注重“幾何距離”本身。 |
| 圖像、傳感器數據 | L2 / 內積 | 嵌入空間常是連續向量域,L2 更合適。 |
代碼示例
import numpy as np# 假設有兩個向量
vec1 = np.array([0.1, 0.3, 0.5])
vec2 = np.array([0.2, 0.1, 0.7])# 歐氏距離
euclidean = np.linalg.norm(vec1 - vec2)# 曼哈頓距離
manhattan = np.sum(np.abs(vec1 - vec2))# 余弦相似度
cosine = np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))print(f"歐氏距離: {euclidean:.4f}")
print(f"曼哈頓距離: {manhattan:.4f}")
print(f"余弦相似度: {cosine:.4f}")
運行結果
歐氏距離: 0.3000
曼哈頓距離: 0.5000
余弦相似度: 0.9201
七、向量數據庫的核心邏輯
🔍 示例任務:查找與這句話最相似的一句話
🟢 查詢語句:
“我今天想去看電影。”
被模型(如 BERT)轉換成一個 768 維向量:
[0.12, -0.34, 0.56, ..., 0.87]
🗂 向量數據庫中預存了大量句子的向量,比如:
| 原始句子 | 向量表示(768維) |
|---|---|
| “晚上看個電影放松一下吧。” | [0.13, -0.33, 0.57, ..., 0.88] |
| “我今天不太想出門。” | [0.01, -0.55, 0.24, ..., 0.39] |
| “今天天氣很好。” | [0.45, 0.22, 0.18, ..., 0.72] |
📌 向量數據庫通過余弦相似度等算法,找出最相似的向量(Top-K),再返回對應的句子。
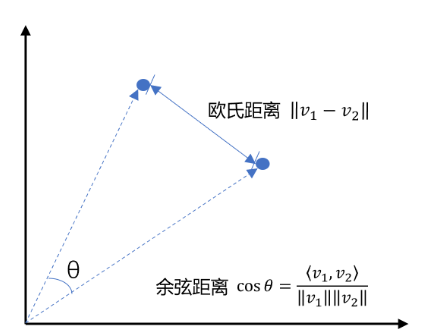
八、圖示:向量空間中的相似度搜索
想象每個句子被映射到一個三維空間中的點(實際是高維空間):

🧲 目標是:找到距離查詢點最近的幾個點 —— 這就是向量數據庫做的事!
九、實際案例:文本語義檢索
你構建了一個問答系統,用戶輸入:
“怎么注冊公司的營業執照?”
系統會將這個問題轉為向量,然后在知識庫中查找語義最接近的答案,比如:
-
“如何辦理工商注冊?”
-
“注冊公司需要準備哪些資料?”
-
“去哪個地方辦營業執照?”
向量數據庫會返回這些“語義相似”的文本,而不只是關鍵詞匹配。
🧠 這就是語義搜索 vs 關鍵詞搜索的區別。
十、實際案例:圖像搜索
你上傳一張貓的照片,系統會在數據庫中返回類似的圖片:
-
🐱 顏色相近的貓
-
🐈 姿勢相似的貓
-
🐾 背景相近的貓圖
原因是:圖像也可以轉成向量,向量數據庫進行相似度查找。
十一、總結圖:向量數據庫流程
?? 原始數據(文本/圖片/音頻)↓向量模型生成 embedding↓向量入庫(Milvus, FAISS, Pinecone等)↓用戶輸入查詢 → 同樣轉換成向量↓在向量空間中找最近的K個鄰居(ANN)↓返回原始內容(文本、圖片、視頻等)
十二、 faiss向量數據代碼用例
說明
1、選用向量模型:阿里百煉的文本向量模型(text-embedding-v1);
2、運行條件:需要有百煉控制臺的APIkey;
3、查看(選擇)其它向量模型:百煉控制臺;
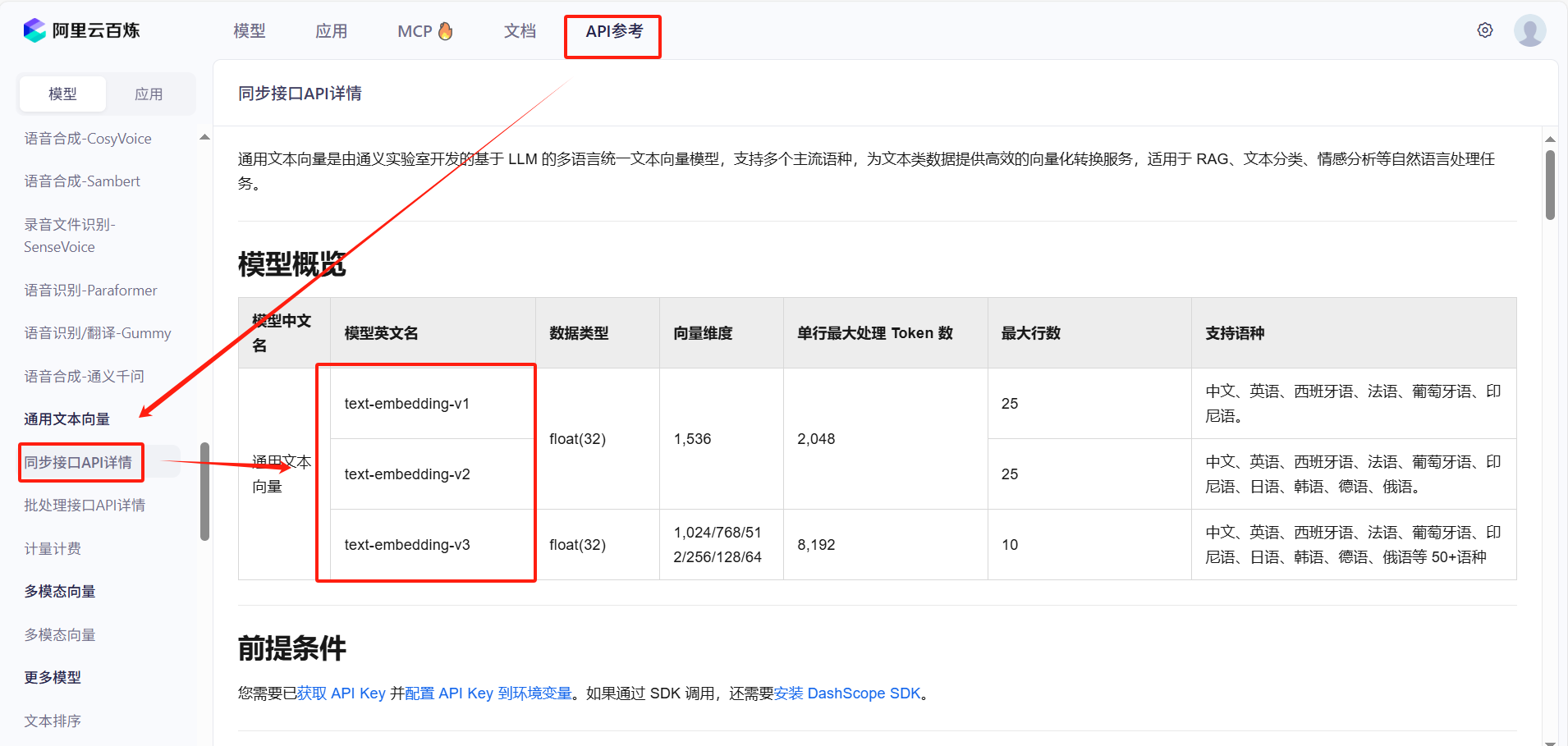
該圖是百煉提供的3種文本向量模型?
文件結構
semantic_search_demo/
├── main.py ? ? ? ? ? ? ?# 主程序
├── documents.txt ? ? ? ?# 示例語料庫(你要搜索的內容)
├── requirements.txt ? ? # 依賴庫
?documents.txt
這個作為知識庫示例
注冊公司需要準備身份證、注冊地址、公司章程等材料。
營業執照由工商局頒發,需要填寫申請表。
稅務登記是注冊公司的后續步驟。
開公司銀行賬戶需要營業執照和法人身份證。
你可以在線申請營業執照。
main.py(簡化版)
import faiss
import dashscope
import os
import numpy as np
from tqdm import tqdm# 設置 API KEY(你也可以改為用環境變量)
dashscope.api_key = os.getenv("DASHSCOPE_API_KEY")# 獲取當前腳本所在目錄的絕對路徑
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
DOC_PATH = os.path.join(BASE_DIR, "documents.txt")# 載入文檔
if not os.path.exists(DOC_PATH):raise FileNotFoundError(f"未找到文件:{DOC_PATH}")with open(DOC_PATH, "r", encoding="utf-8") as f:docs = [line.strip() for line in f.readlines() if line.strip()]# 使用阿里百煉嵌入模型
def get_embedding(text):rsp = dashscope.TextEmbedding.call(model="text-embedding-v1",input=text)if rsp.status_code == 200:return rsp.output['embeddings'][0]['embedding']else:raise ValueError(f"? 嵌入失敗: {rsp.message}")# 生成文檔向量
print("🔍 正在生成文檔向量...")
doc_embeddings = [get_embedding(doc) for doc in tqdm(docs)]# 建立 FAISS 索引
dim = len(doc_embeddings[0])
index = faiss.IndexFlatL2(dim)
index.add(np.array(doc_embeddings).astype("float32"))# 查詢函數
def search(query, top_k=3):q_embedding = get_embedding(query)D, I = index.search(np.array([q_embedding]).astype("float32"), top_k)return [(docs[i], D[0][j]) for j, i in enumerate(I[0])]# 主循環
if __name__ == "__main__":while True:q = input("\n請輸入查詢(輸入 'exit' 退出):\n> ")if q.lower() == "exit":breakresults = search(q)print("\n🔍 最相似的段落:")for i, (text, score) in enumerate(results):print(f"{i+1}. {text} (距離:{score:.4f})")
運行結果
🔍 正在生成文檔向量...
100%|█████████████████████████████████████| 5/5 [00:09<00:00, ?1.90s/it]請輸入查詢(輸入 'exit' 退出):
> 一個公司的創建需要具備什么條件🔍 最相似的段落:
1. 注冊公司需要準備身份證、注冊地址、公司章程等材料。 ?(距離:6633.3623)
2. 開公司銀行賬戶需要營業執照和法人身份證。 ?(距離:8122.5732)
3. 營業執照由工商局頒發,需要填寫申請表。 ?(距離:9337.1758)請輸入查詢(輸入 'exit' 退出):
> 三里屯怎么走🔍 最相似的段落:
1. 注冊公司需要準備身份證、注冊地址、公司章程等材料。 ?(距離:15391.9512)
2. 稅務登記是注冊公司的后續步驟。 ?(距離:15656.2275)
3. 你可以在線申請營業執照。 ?(距離:16183.6201)請輸入查詢(輸入 'exit' 退出):
> 注冊公司需要準備什么材料🔍 最相似的段落:
1. 注冊公司需要準備身份證、注冊地址、公司章程等材料。 ?(距離:1627.7302)
2. 營業執照由工商局頒發,需要填寫申請表。 ?(距離:5437.8076)
3. 開公司銀行賬戶需要營業執照和法人身份證。 ?(距離:5667.3779)
main.py(優化版)
import faiss
import os
import numpy as np
from tqdm import tqdm
import dashscope
from dotenv import load_dotenv# 加載 .env 文件中的 API Key
load_dotenv()
dashscope.api_key = os.getenv("DASHSCOPE_API_KEY")# 獲取當前腳本所在目錄的路徑
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
DOC_PATH = os.path.join(BASE_DIR, "documents.txt")# 載入文檔
if not os.path.exists(DOC_PATH):raise FileNotFoundError(f"未找到文件:{DOC_PATH}")with open(DOC_PATH, "r", encoding="utf-8") as f:docs = [line.strip() for line in f.readlines() if line.strip()]# 獲取阿里百煉的向量
def get_embedding(text):rsp = dashscope.TextEmbedding.call(model="text-embedding-v1", # 阿里模型名input=text,)return rsp.output["embeddings"][0]["embedding"]# 向量歸一化函數
def normalize(vec):norm = np.linalg.norm(vec)return vec / norm if norm > 0 else vec# 生成文檔向量
print("🔍 正在生成文檔向量...")
doc_embeddings = [normalize(get_embedding(doc)) for doc in tqdm(docs)]# 建立 FAISS 余弦相似度索引(內積模式)
dim = len(doc_embeddings[0])
index = faiss.IndexFlatIP(dim)
index.add(np.array(doc_embeddings).astype("float32"))# 計算歐幾里得距離(歐式距離)
def euclidean_distance(vec1, vec2):return float(np.linalg.norm(np.array(vec1) - np.array(vec2)))# 查詢函數:使用余弦相似度
def search(query, top_k=3):q_embedding = normalize(get_embedding(query))similarities = []for doc, doc_emb in zip(docs, doc_embeddings):# 計算余弦相似度cosine_sim = float(np.dot(q_embedding, doc_emb))# 計算歐幾里得距離dist = euclidean_distance(q_embedding, doc_emb)similarities.append((doc, cosine_sim, dist, doc_emb))# 按余弦相似度排序similarities.sort(key=lambda x: x[1], reverse=True)top_results = similarities[:top_k]print("\n🔍 查詢向量:")print(np.round(q_embedding, 4).tolist())print("\n📊 相似文檔向量、余弦相似度 & 歐式距離:")for i, (doc, sim, dist, vec) in enumerate(top_results):print(f"\n{i+1}. 文本內容:{doc}")print(f" 文檔向量:{np.round(vec, 4).tolist()}")print(f" 余弦相似度:{sim:.4f}")print(f" 歐式距離:{dist:.4f}")return [(doc, sim, dist) for doc, sim, dist, _ in top_results]# 主循環
if __name__ == "__main__":while True:q = input("\n請輸入查詢(輸入 'exit' 退出):\n> ")if q.lower() == "exit":breakresults = search(q)print("\n🔍 最相似的段落(按余弦相似度降序):")for i, (text, sim, dist) in enumerate(results):print(f"{i+1}. {text} (余弦相似度:{sim:.4f},歐式距離:{dist:.4f})")運行結果
🔍 正在生成文檔向量...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:12<00:00, ?2.59s/it]請輸入查詢(輸入 'exit' 退出):
> 你好🔍 查詢向量:
[0.0026, -0.0312, 0.0114, 0.0236, -0.0029, 0.0034, 0.0251, -0.0333, -0.0135, 0.0028, -0.0288, 0.0582, 0.0263, -0.0033, 0.0137, -0.0047, -0.0317, 0.016, -0.0047, 0.0211, -0.0313, -0.0203, 0.0066, -0.0228, 0.0292, -0.0183, 0.0028, 0.0084, -0.0164, 0.0071...?]📊 相似文檔向量、余弦相似度 & 歐式距離:
1. 文本內容:你可以在線申請營業執照。
? ?文檔向量:[0.0312, 0.0475, 0.0324, 0.0472, -0.0346, 0.0171, -0.0325, 0.028, -0.0763, -0.0216, -0.0158, 0.0121, -0.0084, -0.0194, 0.0368, -0.0105, 0.0095, -0.0155, 0.0385, 0.013, -0.0147, 0.001, 0.0547, 0.0259, 0.0132, 0.0262, -0.0585, 0.0146, -0.0198, 0.016, ...?]
? ?余弦相似度:0.1997
? ?歐式距離:1.26522. 文本內容:注冊公司需要準備身份證、注冊地址、公司章程等材料。
? ?文檔向量:[0.0006, 0.0363, 0.0236, 0.0462, -0.0021, 0.0076, -0.0199, 0.027, -0.0587, -0.0176, -0.0289, -0.0134, 0.0296, -0.0566, 0.0102, -0.006, 0.0052, -0.0242, 0.0255, -0.046, -0.0065, 0.0107, 0.0173, 0.0214, -0.0075, 0.0027, -0.0233, -0.014, -0.0467, 0.0144, ] ????余弦相似度:0.1473
? ?歐式距離:1.30593. 文本內容:開公司銀行賬戶需要營業執照和法人身份證。
? ?文檔向量:[0.0007, 0.0148, 0.107, 0.009, -0.0025, 0.0103, -0.0273, 0.0553, -0.0794, -0.0432, -0.0285, -0.0105, 0.0291, -0.0292, 0.0212, -0.0296, 0.0196, -0.0294, 0.0092, -0.0325, 0.0117, -0.0071, -0.0013, 0.0267, -0.0065, 0.0112, -0.044, 0.0127, -0.0102...]
? ?余弦相似度:0.1357
? ?歐式距離:1.3148🔍 最相似的段落(按余弦相似度降序):
1. 你可以在線申請營業執照。 ?(余弦相似度:0.1997,歐式距離:1.2652)
2. 注冊公司需要準備身份證、注冊地址、公司章程等材料。 ?(余弦相似度:0.1473,歐式距離:1.3059)
3. 開公司銀行賬戶需要營業執照和法人身份證。 ?(余弦相似度:0.1357,歐式距離:1.3148)




_基于線程的并發(二):線程api和基于線程的并發服務器)


)


)



Day19)

)


