摘要
????????近期,視覺語言基礎模型領域取得的進展彰顯了其在理解多模態數據以及解決復雜視覺語言任務(包括機器人操作任務)方面的能力。我們致力于探尋一種簡便的方法,利用現有的視覺語言模型(VLMs),僅通過對機器人數據進行簡單微調,即可投入使用。為此,我們基于開源的視覺語言模型 OpenFlamingo,推導出了一個簡單且新穎的視覺語言操作框架,并將其命名為 RoboFlamingo。與以往的研究工作不同,RoboFlamingo 利用預訓練的視覺語言模型進行單步視覺語言理解,通過顯式的策略頭對序列歷史信息進行建模,并且僅在語言條件下的操作數據集上,通過模仿學習進行輕微微調。這種分解方式為 RoboFlamingo 提供了在開環控制以及在低性能平臺上部署的靈活性。在測試基準上的實驗結果顯示,RoboFlamingo 的性能大幅超越了當前最先進的技術水平,這表明 RoboFlamingo 可以作為一種有效且具有競爭力的替代方案,用于將視覺語言模型適配到機器人控制領域。我們廣泛的實驗結果還揭示了關于不同預訓練視覺語言模型在操作任務上行為表現的若干有趣結論。RoboFlamingo 可以在單個 GPU 服務器上進行訓練或評估,我們相信它有望成為一種成本效益高且易于使用的機器人操作解決方案,賦予每個人微調自身機器人策略的能力。代碼和模型將公開共享。
1 引言
近期,視覺語言基礎模型(VLM)在建模與對齊圖像和文字表征方面展現出了令人振奮的能力,并且具備利用多模態數據解決各類下游任務的無限潛力,例如視覺問答(Li 等人,2023;Zhou 等人,2022)、圖像描述生成(Zeng 等人,2022;Wang 等人,2022;Li 等人,2021)以及人機交互(Liu 等人,2022b;Oertel 等人,2020;Seaborn 等人,2021)等任務。
這些成果無疑激發了人們的想象,讓人們憧憬一種具備這種視覺語言理解能力的通用型機器人,能夠與人類自然交互,并執行復雜的操作任務。
因此,我們致力于探索將視覺語言基礎模型集成到機器人系統中,作為機器人操作策略。盡管此前已有一些研究將大型語言模型(LLMs)和視覺語言模型(VLMs)納入機器人系統,作為高層規劃器(Ahn 等人,2022;Driess 等人,2023),但直接利用它們進行底層控制仍面臨挑戰。大多數視覺語言模型是在靜態的圖像 - 語言對上進行訓練的,而機器人任務需要視頻理解能力來實現閉環控制。此外,視覺語言模型的輸出主要是語言符號,與機器人動作在表征形式上存在顯著差異。近期的一項工作(Brohan 等人,2023),即機器人轉換器 2(RT - 2),展示了一種將視覺語言模型適配到機器人底層控制的可能解決方案。然而,要使這種成本高昂的框架在所有機器人從業者中普及開來卻十分困難,因為它使用了私有模型,并且需要在大量視覺語言數據上進行協同微調,才能充分展現其有效性。因此,機器人領域迫切需要一種低成本的替代方案,能夠有效地利用視覺語言模型實現機器人操作策略。
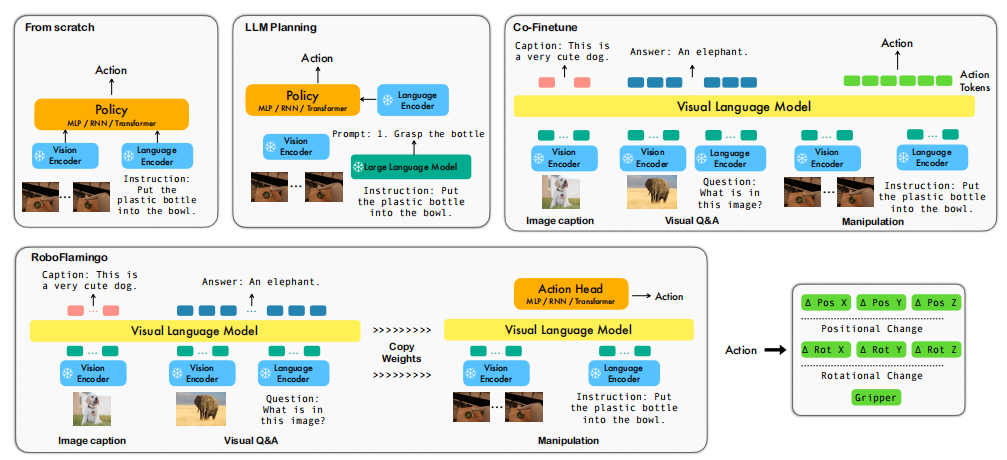
圖 1:RoboFlamingo 與現有視覺語言操作解決方案的對比
為此,我們引入了 RoboFlamingo,這是一種新穎的視覺語言操作框架,它利用可公開獲取的預訓練視覺語言模型,為機器人有效地構建操作策略。具體而言,RoboFlamingo 基于開源的視覺語言模型 OpenFlamingo(Awadalla 等人,2023),通過將視覺語言理解與決策過程解耦,解決了相關挑戰。與以往的研究不同,RoboFlamingo 主要利用預訓練的視覺語言模型在每個決策步驟中理解視覺觀測和語言指令,通過顯式的策略頭對歷史特征進行建模,并且僅在語言條件下的操作數據集上,利用模仿學習進行微調。通過這種解耦方式,我們僅需結合少量機器人演示,就能將模型適配到下游操作任務。同時,RoboFlamingo 還為開環控制以及在低性能平臺上的部署提供了靈活性。此外,得益于在大量視覺語言任務上的預訓練,RoboFlamingo 的性能大幅超越以往研究,達到了當前最先進水平,并且在零樣本設置和環境中也具有良好的泛化能力。值得注意的是,RoboFlamingo 可以在單個 GPU 服務器上進行訓練或評估。因此,我們認為 RoboFlamingo 是一種成本效益高且性能卓越的機器人操作解決方案,賦予每個人利用視覺語言模型微調自身機器人的能力。
通過廣泛的實驗,我們證明 RoboFlamingo 的性能明顯優于現有方法。具體而言,我們使用“語言與視覺動作組合基準”(CALVIN)(Mees 等人,2022b)來評估其性能,該基準是廣泛應用于長周期語言條件任務的模擬基準。我們的研究結果表明,RoboFlamingo 是將視覺語言模型適配到機器人控制領域的一種有效且具有競爭力的替代方案,與之前的最先進方法相比,性能提升了 2 倍。我們的綜合結果還為在機器人操作任務中使用預訓練視覺語言模型提供了寶貴見解,為進一步的研究和發展指明了潛在方向。
2 相關工作
語言是人類與機器人交互中最直觀且關鍵的接口,它使非專業人員能夠無縫地將指令傳達給機器人,以完成各種任務。因此,近年來,語言條件下的多任務操作領域受到了廣泛關注。直觀而言,這類任務要求機器人不僅要對外部世界的視覺捕捉信息有良好的理解,還要理解以文字形式呈現的指令。得益于預訓練視覺和語言模型強大的表征能力,許多先前的研究已將預訓練模型納入學習框架之中。在此,我們大致將這些研究分為以下三類,圖 1 也對其進行了直觀對比。
微調(Fine-tuning)
一些早期研究,如 Jang 等人(2022 年)以及 Lynch & Sermanet(2020 年),訓練了視覺編碼器和語言編碼器,以學習來自操作任務的輸入語言和視覺數據的表征。而近期的一些研究則直接采用預訓練模型來獲取優質的表征,隨后在這些預訓練模型的基礎上,從頭開始訓練策略模型,或者對整個模型進行微調。例如,Jiang 等人(2023 年)利用預訓練的 T5(Raffel 等人,2020 年)模型對多模態提示進行編碼,并通過微調 T5 模型以及額外訓練一個目標編碼器和注意力層來學習動作。HULC(Mees 等人,2022a)采用了在 CALVIN 數據集(Mees 等人,2022b)上訓練的 Lynch & Sermanet(2020 年)的視覺編碼器,以及一些預訓練的語言編碼器模型,如句子轉換器(Reimers & Gurevych,2019 年),其后續改進版本 HULC++(Mees 等人,2023 年)也對這些編碼器進行了微調。此外,Brohan 等人(2022 年)提出了 RT-1,即機器人轉換器,這是一個 3500 萬參數的視覺 - 語言 - 動作模型(VLA)。該模型將動作進行標記化處理,并在標記空間中對視覺、語言和動作進行對齊,利用大量真實世界操作數據集進行訓練。其中,語言嵌入通過通用句子編碼器(Cer 等人,2018 年)獲取,視覺標記器則采用預訓練的 EfficientNet-B3(Tan & Le,2019 年)。
大語言模型規劃(LLM Planning)
一些方法利用大型語言模型(LLMs)作為強大的零樣本規劃器,例如 SayCan(Ahn 等人,2022 年)。這類方法針對給定任務,借助人機交互提示生成分步的預定義計劃,隨后指示不同的預訓練底層技能策略執行這些計劃,以完成多項任務。與其他研究相比,這種控制策略無需具備理解指令的能力,而是依賴預訓練的、固定的大語言模型來選擇必要的技能。
協同微調(Co-Fine-Tuning)
Driess 等人(2023 年)提出了 5400 億參數的 PaLM-E 模型,展示了利用預訓練視覺和語言模型的另一種方式。具體而言,他們選擇不同的預訓練模型對輸入場景進行編碼,并以 PaLM(Chowdhery 等人,2022 年)模型作為基礎模型。通過協同微調整個視覺語言模型(VLM),利用移動操作問答數據以及從網絡上收集的輔助視覺語言訓練數據(如圖像描述生成數據和視覺問答數據),對模型進行端到端訓練,使其能夠生成以語言描述的預定義多步計劃。與 SayCan(Ahn 等人,2022 年)類似,他們需要底層控制策略來執行生成的計劃。受到 PaLM-E 的啟發,Brohan 等人(2023 年)進一步推出了 RT-2。RT-2 基于 RT-1,但進行了適應性改進,采用了大型視覺語言骨干網絡,如 PaLI-X(Chen 等人,2023 年)和 PaLM-E(Driess 等人,2023 年),并利用機器人操作數據和網絡數據對策略進行訓練。他們的方法表明,視覺語言模型(VLMs)具有被適配到機器人操作領域的潛力。然而,其關鍵的協同微調訓練策略需要大量的網絡級視覺語言數據以及底層機器人動作數據。此外,他們所使用的視覺語言模型和數據均為私有,這使得每個機器人從業者都難以在自己的項目中采用這種解決方案。
盡管上述先前的研究在一定程度上彌合了機器人操作任務中視覺和語言之間的差距,但它們要么依賴底層技能策略,如 SayCan 和 PaLM-E;要么訓練一個大型的完整模型,如 RT-1;要么需要大量的視覺語言數據和計算資源,以確保模型在學會操作策略的同時,不會遺忘視覺和語言之間出色的對齊關系。與這些研究相比,我們提出的 RoboFlamingo 是一種簡單直觀的解決方案,能夠輕松適配現有的視覺語言模型(本文中使用的是 OpenFlamingo(Alayrac 等人,2022 年;Awadalla 等人,2023 年)),僅需對少量操作演示數據進行微調。我們希望 RoboFlamingo 為充分利用視覺語言模型的能力提供一種不同的視角,同時降低數據收集成本和計算資源消耗,使其成為一種開放且易于使用的解決方案,讓每個人都能從中受益。
3 背景
機器人操作
在本文中,我們主要聚焦于機器人操作任務。在此類任務中,智能體(即機器人)無法直接獲取環境的真實狀態信息,但能夠從不同攝像頭獲取視覺觀測數據,以及獲取自身的本體感知狀態信息。就動作空間而言,它通常涵蓋機械臂末端執行器的相對目標位姿以及夾爪的開合狀態。例如,在 CALVIN(Mees 等人,2022b)測試平臺上,觀測數據由來自兩個不同視角的模擬攝像頭采集的圖像組成,動作是對配備平行夾爪的 Franka Emika Panda 機器人手臂進行 7 自由度(7-DoF)的控制,而指令則是目標描述,即事后給出的描述信息。
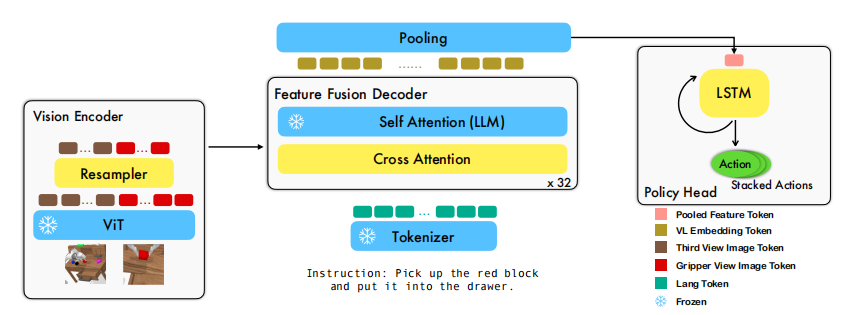
圖 2:所提出的 RoboFlamingo 框架示意圖。Flamingo 骨干網絡對單步觀測數據進行建模,而策略頭(policy head)則對時序特征進行建模。
模仿學習
模仿學習(Pomerleau,1988 年;Zhang 等人,2018 年;Liu 等人,2020 年;Jang 等人,2022 年)使智能體能夠模仿帶有指令標簽的專家演示數據中的操作計劃。這些專家演示數據集可表示為?D={(τ,l)i?}i=0D?,其中?D?為軌跡的數量,l?為語言指令,τ={(ot?,at?)}?包含為達成給定指令所描述的目標而經歷的前序狀態和動作。
模仿學習的目標可簡單概括為一個最大似然目標條件下的模仿學習目標,即學習策略?πθ?:
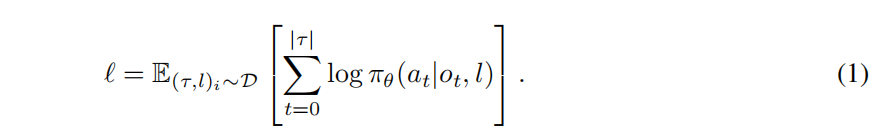
4 ROBOFLAMINGO
RoboFlamingo 是一個通用型機器人智能體,在解決語言條件下的操作任務方面表現出色。其核心思路是借助預訓練的視覺語言模型(VLMs),并將這些模型適配到操作策略中,從而使機器人獲得目標定位、語言理解、視覺語言對齊以及長時段規劃的能力。具體而言,RoboFlamingo 關注到當下熱門的 VLMs 之一——Flamingo(Alayrac 等人,2022 年),并采用其開源模型 OpenFlamingo(Awadalla 等人,2023 年)作為骨干網絡。RoboFlamingo 的整體架構如圖 2 所示。
為了將大規模視覺語言模型適配到機器人操作任務中,RoboFlamingo 僅需添加一個策略頭(policy head),即可進行端到端的微調。它解決了以下三個主要挑戰:1)將原本針對靜態圖像輸入的視覺語言模型適配到視頻觀測數據上;2)生成機器人控制信號,而非僅輸出文本;3)在擁有數十億可訓練參數的情況下,僅需有限數量的下游機器人操作數據,就能實現高性能和泛化性。本節將詳細闡述 RoboFlamingo 的設計。
4.1 語言條件下的機器人控制

4.2 Flamingo 主干網絡
我們采用 Flamingo 主干網絡?fθ??來在每個決策步驟理解視覺和語言輸入。總體而言,Flamingo 通過視覺編碼器將視覺觀測編碼為潛在標記;然后通過特征融合解碼器將它們與語言目標進行融合。下面我們將詳細解釋這些部分。
4.2.1 視覺編碼器
視覺編碼器由一個視覺變換器(ViT)(Yuan 等人,2021 年)和一個感知重采樣器(Alayrac 等人,2022 年)組成。在每個時間步?t,來自兩個視角的相機圖像?It?、Gt??通過 ViT 模塊被編碼為?X^t?,它由一個視覺標記序列組成:
![]()

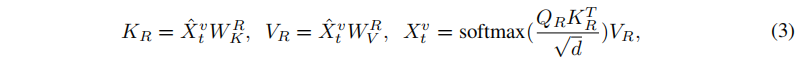

4.2.2 特征融合解碼器

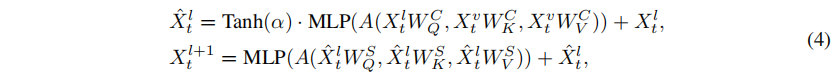

4.3 策略頭(Policy Head)

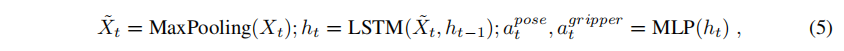

4.4 訓練目標

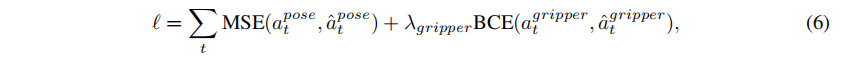

5 實驗

5.1 基準測試集與基線方法

表 1:不同設置下的模仿學習性能,所有結果均基于表現最佳的模型檢查點(model checkpoints)進行報告。“Full”(全量數據)和 “Lang”(僅語言相關數據)表示模型是否使用未配對的視覺數據(即沒有對應語言描述的視覺數據)進行訓練;“Freeze-emb” 表示凍結融合解碼器(fusion decoder)的嵌入層;“Enriched”(增強)表示使用 GPT-4 增強的指令。灰色行表示由我們重新訓練的模型評估得出的數值結果。我們重新實現了 RT-1,并采用了 Mees 等人(2022a)提供的 HULC 原始代碼。其他所有結果均由 Mees 等人(2022a)報告。
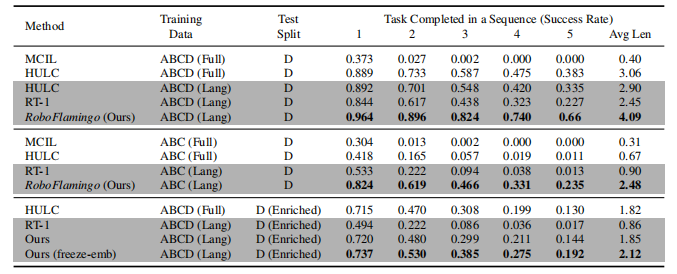
我們在 CALVIN 基準測試集中對一系列表現良好的基線方法進行了比較:(1)MCIL(Lynch & Sermanet, 2020):這是一個可擴展的框架,它將多任務模仿學習與自由形式文本條件相結合,能夠學習語言條件下的視覺運動策略,并且可以在動態精準的 3D 桌面環境中,在較長時間跨度內遵循多條人類指令。(2)HULC(Mees 等人,2022a):這是一種分層方法,它融合了不同的觀測空間和動作空間、輔助損失函數以及潛在表征,在 CALVIN 基準測試集上取得了當前最優(State-of-the-Art, SoTA)的性能表現。(3)RT-1(Brohan 等人,2022):這是一種機器人 Transformer 模型,它直接通過動作標記(action tokens),以及視覺和語言輸入來預測控制動作。由于我們無法獲取 RT-2(Brohan 等人,2023)的代碼、數據和模型權重,因此未對其進行實驗對比。
5.2 模仿學習性能
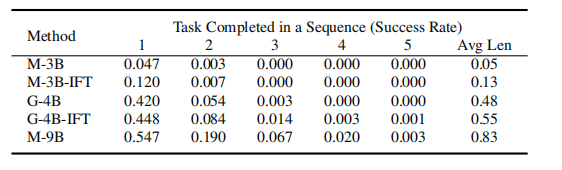
我們僅使用來自四個數據劃分(A、B、C 和 D)中均帶有語言標注的演示數據,對 RoboFlamingo(采用 M-3B-IFT 骨干網絡)進行訓練,并在從數據劃分 D 中采樣的任務片段(episodes)上評估其模仿學習性能。性能對比結果如表 1 所示。RoboFlamingo 在所有評估指標上均大幅超越所有基線方法,即便對于那些使用完整數據集進行訓練的方法亦是如此。這充分證明了 RoboFlamingo 作為機器人操作解決方案的有效性,它能夠讓視覺語言模型(VLMs)成為高效的機器人模仿者。
此外,后續任務的成功率可被視為衡量操作策略泛化能力的一個指標,因為后續任務的初始狀態高度依賴于其前序任務的結束狀態。在任務序列中,任務安排得越靠后,其初始狀態就越多樣化,這就需要更強大的視覺 - 語言對齊能力才能成功完成任務。在所有方法中,RoboFlamingo 在后續任務上取得了最高的成功率。這表明 RoboFlamingo 能夠利用預訓練 VLMs 的視覺 - 語言基礎(grounding)能力。在附錄中,我們還進一步給出了 RoboFlamingo 與 COCO 和 VQA 數據聯合訓練的結果(附錄 B.1),并將其與近期的一些機器人表征研究工作進行了對比(附錄 B.2)。附錄 B.1 還揭示了微調后原始視覺語言模型(VL)能力的變化情況。
5.3 零樣本泛化能力
為了評估 RoboFlamingo 的零樣本泛化能力,我們從視覺和語言兩個方面對其進行評價。在視覺泛化方面,我們在數據劃分 A、B 和 C 上訓練模型,并在具有不同視覺場景的數據劃分 D 上進行測試。如表 1 所示,在這種視覺泛化場景(ABC → D)下,我們的方法顯著優于基線方法。在語言泛化方面,我們通過使用 GPT-4(OpenAI,2023)為每個任務生成 50 條同義指令來豐富語言設置。在評估過程中,我們隨機采樣指令。在這種語言泛化設置下,與所有基線方法相比,我們的方法展現出了更優的性能。
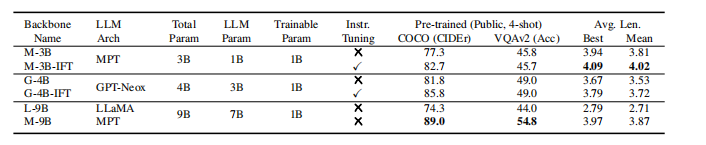
表 2:所測試的視覺語言模型(VLMs)的變體情況。“Pre-train”(預訓練表現)表示 VLM 在預訓練用的視覺語言(VL)數據集上的原始性能表現;“Best Avg. Len.”(最佳平均成功長度)表示在 5 個訓練周期(epochs)內,VLMs 平均成功長度所能達到的最佳性能;“Mean Avg. Len.”(最后 3 個周期平均成功長度的均值表現)表示在 CALVIN 基準測試集上,VLMs 在最后 3 個訓練周期的平均成功長度性能的均值。
需要注意的是,RoboFlamingo 在后續任務上的成功率下降幅度比 HULC 更大。這可能是由于我們的方法在訓練過程中直接使用詞元(word tokens)作為輸入,相較于使用凍結的句子模型來嵌入指令的 HULC,對于同義句子,我們的方法可能會產生更大的變化。為解決這一問題,我們在方法中凍結了特征融合解碼器的嵌入層,這有助于提升模型的泛化能力,并減少性能下降的幅度。
5.4 消融實驗研究
在本節中,我們針對 RoboFlamingo 開展消融實驗,以回答以下問題:
1)RoboFlamingo 在使用不同的策略頭(policy heads)/策略形式(formulations)時表現如何?
2)視覺語言(VL)預訓練是否能提升下游機器人任務的性能?
3)VL 預訓練中的關鍵因素如何影響機器人任務?
5.4.1 ROBOFLAMINGO 在不同策略形式下的表現如何?
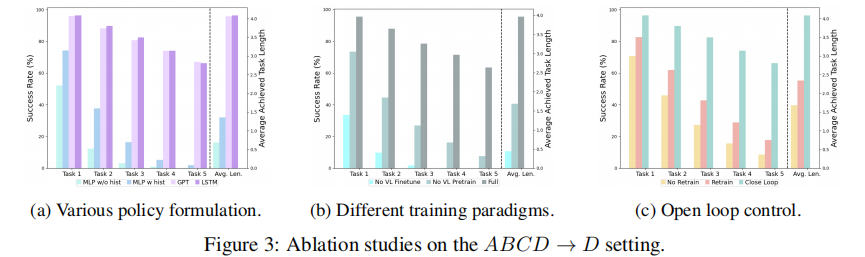
我們使用不同的策略頭/策略形式對 RoboFlamingo 進行測試。具體而言,我們比較了 4 種不同的實現方式:(a)MLP w/o hist(無歷史信息的多層感知機)僅將當前觀測作為輸入來預測動作,忽略了觀測歷史信息。(b)MLP w hist(帶歷史信息的多層感知機)將歷史幀與位置嵌入信息一同輸入視覺編碼器,并通過特征融合解碼器中的交叉注意力層對歷史信息進行編碼。(c)GPT 和(d)LSTM 均利用 VLM 骨干網絡處理單幀觀測,并通過策略頭整合歷史信息。GPT 明確地將視覺歷史作為輸入來預測下一個動作,而 LSTM 則隱式地維護一個隱藏狀態來編碼記憶并預測動作。詳細說明可參見附錄 C.1。我們在圖 3(a)所示的 ABCD → D 設置下比較了它們的最佳性能。MLP w/o hist 的表現最差,這表明歷史信息在操作任務中的重要性。MLP w hist 的表現優于 MLP w/o hist,但仍遠不及 GPT 和 LSTM。我們推測,這可能是因為 VLM(OpenFlamingo)在預訓練階段僅見過圖像 - 文本對,無法有效處理連續幀。此外,GPT 和 LSTM 的性能相近,鑒于 LSTM 的簡潔性,我們選擇其作為默認策略頭。
表 3:在 ABCD → D 設置下,使用 10% 帶有語言標注的數據所得到的性能表現。所有變體模型均在相同的訓練周期數(training epochs)下進行訓練與評估。
5.4.2 VL 預訓練是否能提升下游機器人任務的性能?
為驗證 VL 預訓練的必要性,我們在不加載由 OpenFlamingo 模型訓練得到的交叉注意力層和重采樣器(resampler)的預訓練參數的情況下,對同一模型進行訓練(表示為 No VL Pre-train,即無 VL 預訓練)。此外,我們還開展了一項消融實驗,凍結預訓練的 VLM,僅訓練策略頭(表示為 No VL Finetune,即不對 VL 進行微調)。如圖 3(b)所示,我們可以看到,視覺語言預訓練能夠顯著提升下游機器人操作任務的性能。此外,由于策略頭的容量有限,在機器人任務上對 VL 模型本身進行微調是必不可少的。
5.4.3 VL 預訓練中的關鍵因素如何影響機器人任務?
模型規模:一般來說,規模更大的模型往往能帶來更好的視覺語言(VL)性能。然而,在 CALVIN 數據集使用完整訓練數據的情況下,我們發現較小規模的模型與較大規模的模型性能相當(具體對比可參見表 2 和附錄 B.4)。為了進一步驗證模型規模對下游機器人任務的影響,我們在 CALVIN 數據集上僅使用 10% 的帶有語言標注的數據(這僅占完整數據的 0.1%)來訓練不同變體模型。從表 3 中我們可以觀察到,在訓練數據有限的情況下,視覺語言模型(VLMs)的性能與模型規模高度相關。較大規模的模型取得了顯著更高的性能,這表明較大規模的 VLM 在數據利用效率上更具優勢。
指令微調(Instruction Fine-tuning):指令微調是一種專門的技術,它利用指令微調數據集(IFT dataset)對大型語言模型(LLM)進行進一步的預訓練增強(Conover 等人,2023;Peng 等人,2023)。這種技術為模型提供了豐富的遵循指令行為示例,從而提升了模型在語言條件任務中的能力。我們發現,經過這種訓練階段的大型語言模型能夠提升策略在已見場景和未見場景下的性能。這一點從表 2 中 M-3B-IFT 相較于 M-3B,以及 G-4B-IFT 相較于 G-4B 的性能提升中可以得到體現。
5.5 部署的靈活性
由于我們的 RoboFlamingo 采用了將感知模塊和策略模塊分離的結構,并將主要計算任務交給感知模塊處理,因此我們可以通過開環控制(open loop control)來加速 RoboFlamingo 的推理過程。開環控制無需每次僅執行下一個動作,并在面對新觀測時為預測未來動作而每次都進行 VLM 推理。相反,在給定當前觀測的情況下,開環控制僅通過一次推理即可預測一個動作序列(堆疊動作),從而減輕了延遲和測試時的計算需求。然而,如圖 3(c)所示,直接在不重新訓練的情況下實施開環控制可能會導致性能下降。而通過跳躍步演示(jump step demonstration)對模型進行重新訓練,則可以緩解這種性能下降的問題。
6 結論與未來工作
本文探討了預訓練視覺語言模型在推動語言條件下的機器人操作任務(language-conditioned robotic manipulation)方面的潛力。我們提出的基于預訓練 OpenFlamingo 模型的 RoboFlamingo,在基準數據集上展現出了最先進的性能表現。此外,我們的實驗結果表明,預訓練模型在數據效率和零樣本泛化能力方面具有顯著優勢。本研究為開發能夠無縫理解并響應人類語言指令的智能機器人系統做出了貢獻,為更直觀、高效的人機協作鋪平了道路。
由于缺乏真實機器人數據,本文并未在真實機器人平臺上進行部署。不過,令我們欣喜的是,近期在大規模真實機器人數據領域取得的進展(Padalkar 等人,2023)表明,利用大量真實機器人數據對大型視覺語言模型(VLMs)進行微調具有可行性。最令人期待的未來工作,是觀察 RoboFlamingo 在結合此類大規模數據后,在真實任務中的實際表現。
)



Day19)

)






源碼分析(二、append實現))



)

