傳輸層協議UDP和TCP
- 1、UDP
- 2、TCP
- 2.1、TCP協議段格式
- 2.2、確認應答(ACK)機制
- 2.3、超時重傳機制
- 2.4、連接管理機制
- 2.5、理解CLOSE_WAIT狀態
- 2.6、理解TIME_WAIT狀態
- 2.7、流量控制
- 2.8、滑動窗口
- 2.9、擁塞控制
- 2.10、延遲應答
- 2.11、捎帶應答
- 2.12、面向字節流
- 2.13、粘包問題
- 2.14、TCP異常情況
- 2.15、用UDP實現可靠傳輸
- 3、TCP全連接隊列和tcpdump抓包
1、UDP
傳輸層:負責數據能夠從發送端傳輸接收端。
再談端口號:端口號(Port)標識了一個主機上進行通信的不同的應用程序。
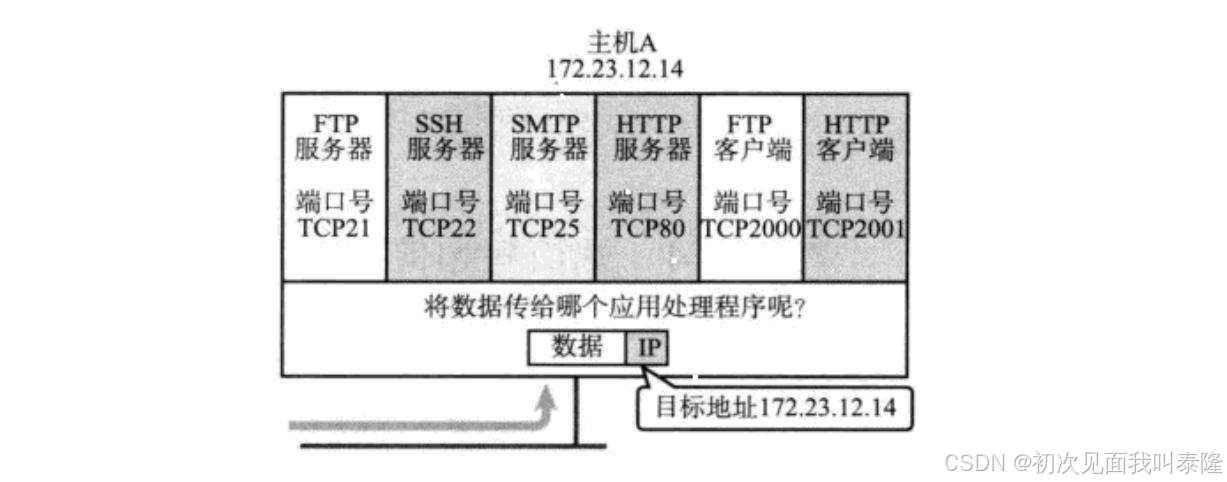
如圖,主機A上有許多服務,那么當傳輸層接收到數據,如何得知要將數據交給上層的哪個進程呢?網絡通信本質就是進程間通信。所以就需要端口號來標識要將數據交給上層的哪個進程。一個端口號只能被一個進程綁定,而一個進程可以綁定多個端口號。
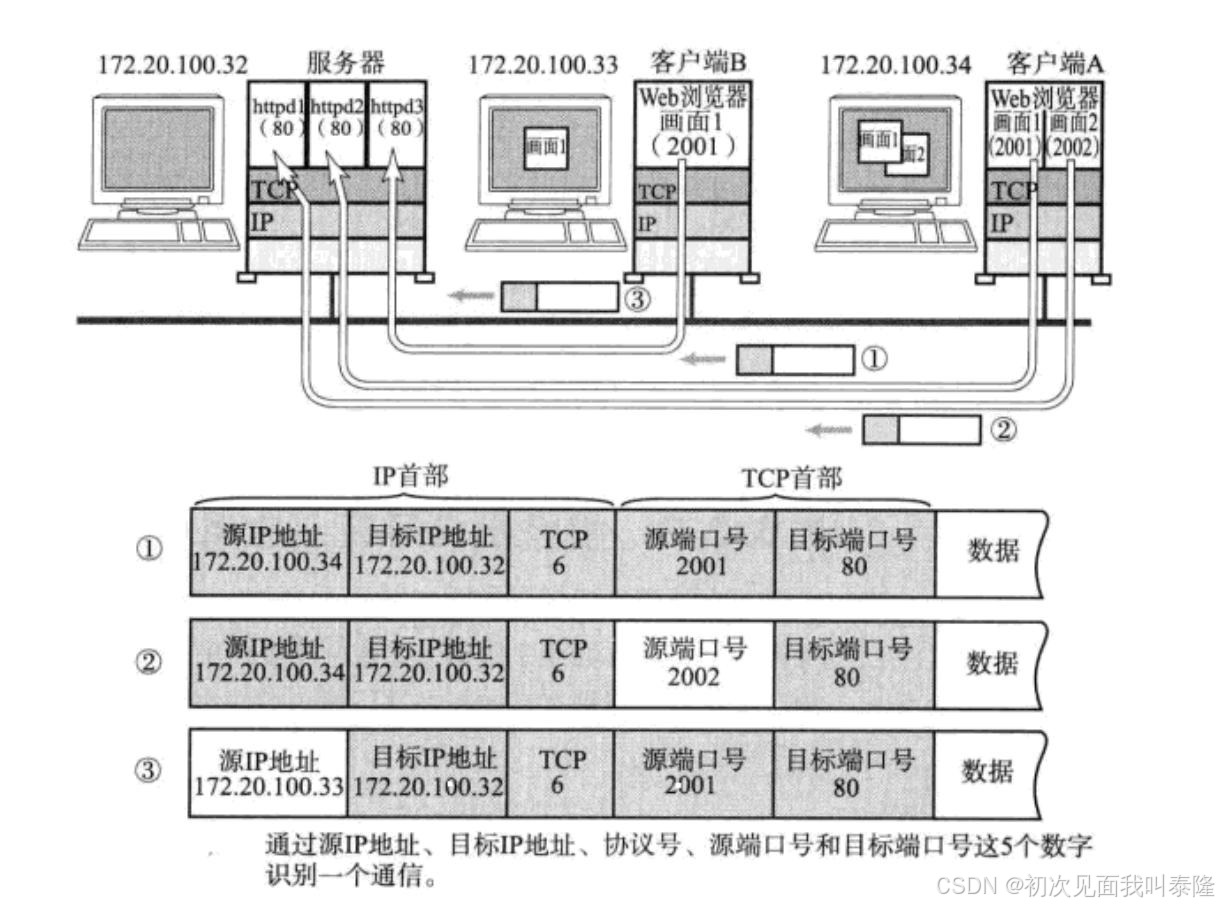
如圖:客戶端B向服務器發起請求,客戶端A的web瀏覽器有兩個頁面向服務器發起請求。服務器要將響應的資源返回,而請求的時候會攜帶自己的源IP地址和源端口號,因此服務器將來返回的時候就可以根據IP地址找到主機,但是對于客戶端A的瀏覽器請求了兩個不同的頁面,所以還需要端口號來區分要交給誰,而不會給反了或給錯了。
所以之前我們是通過源IP+源端口+目的IP+目的端口四元組來標識一個網絡通信的。那么實際上源IP和目的IP是添加在IP報頭中的,然后源端口和目的端口是添加在TCP首部的,并且還需有一個協議號來標識傳輸層用的是什么協議。所以現在就通過上面的四元組+協議號來標識一個通信。
0 - 1023:知名端口號, HTTP, FTP, SSH 等這些廣為使用的應用層協議,他們的端口號都是固定的。
1024 - 65535:操作系統動態分配的端口號. 客戶端程序的端口號,就是由操作系統從這個范圍分配的。
cat /etc/services:可以查看一些知名端口。
UDP協議:
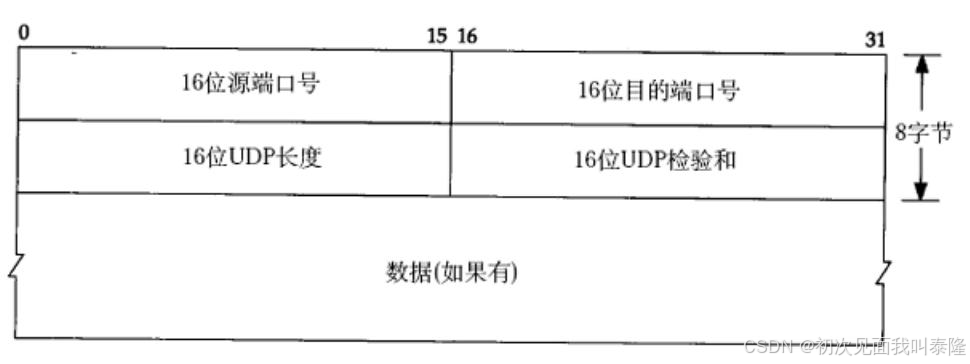
UDP協議報文如圖:第一行32位,4個字節,前十六位表示源端口號,后十六位表示目的端口號。第二個四字節表示16位UDP長度和16位校驗和。16位UDP長度是整個報文的長度,也就是報頭8個字節加上數據的長度。如果校驗和出錯,就會直接將報文丟棄。
1、UDP如何做到解包的?
在讀取UDP報文的時候,直接讀取前八個字節,就是UDP報文的報頭,剩下的就是有效載荷了。
2、UDP如何做到分用?
UDP報頭里面就有16位目的端口號,根據16位目的端口號就可以找到進程。
3、接收方收到的UDP報文可能有多個黏在一起,這就是粘包問題。那么操作系統是如何準確的把一個UDP報文讀上來呢?
UDP報文的前八個字節就是固定的報頭,讀取前八個字節將16位UDP長度提取出來,然后將長度減8算出來的就是有效載荷的長度,就可以根據這個長度去讀取數據了。
16位UDP長度,這種自己報頭里會描述有效載荷的特性我們稱為自描述字段。
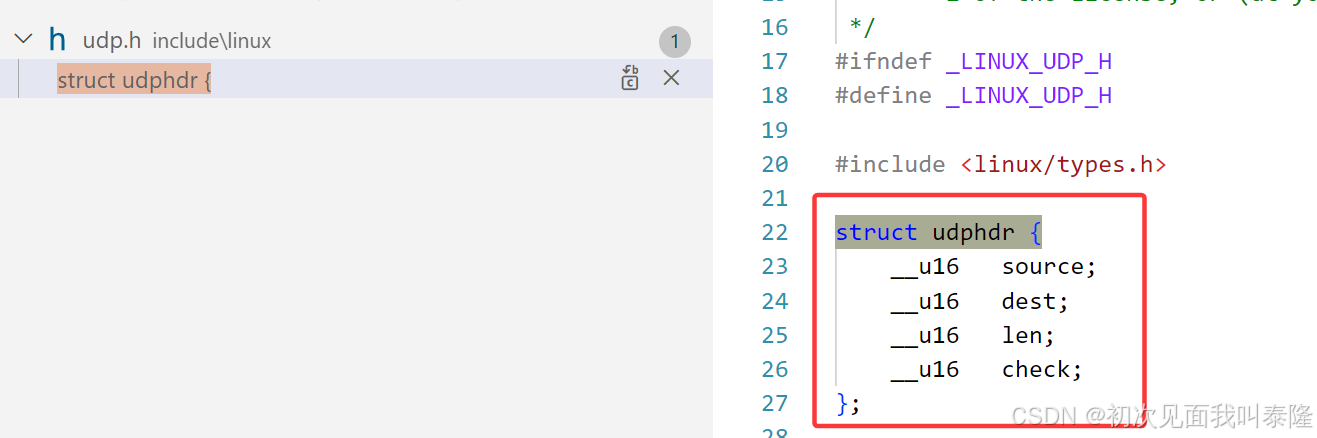
上圖就是Linux內核中UDP報頭的結構體信息。
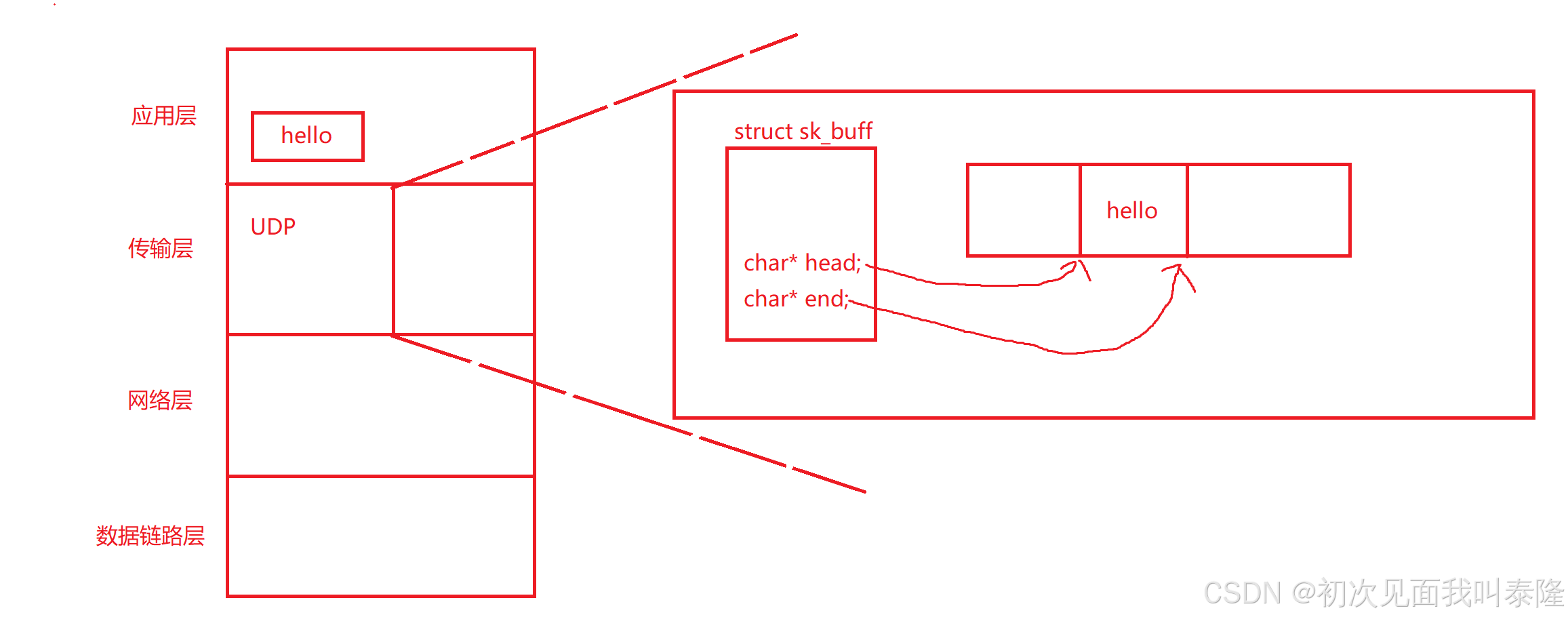
應用層發送數據hello,交給下層,我們知道操作系統要對報文進行管理,所以struct sk_buff就是一個一個的報文。head指針指向數據頭部,end指向尾部。并且之前也說了TCP全雙工是存在兩個隊列的,一個接收隊列一個寫隊列。
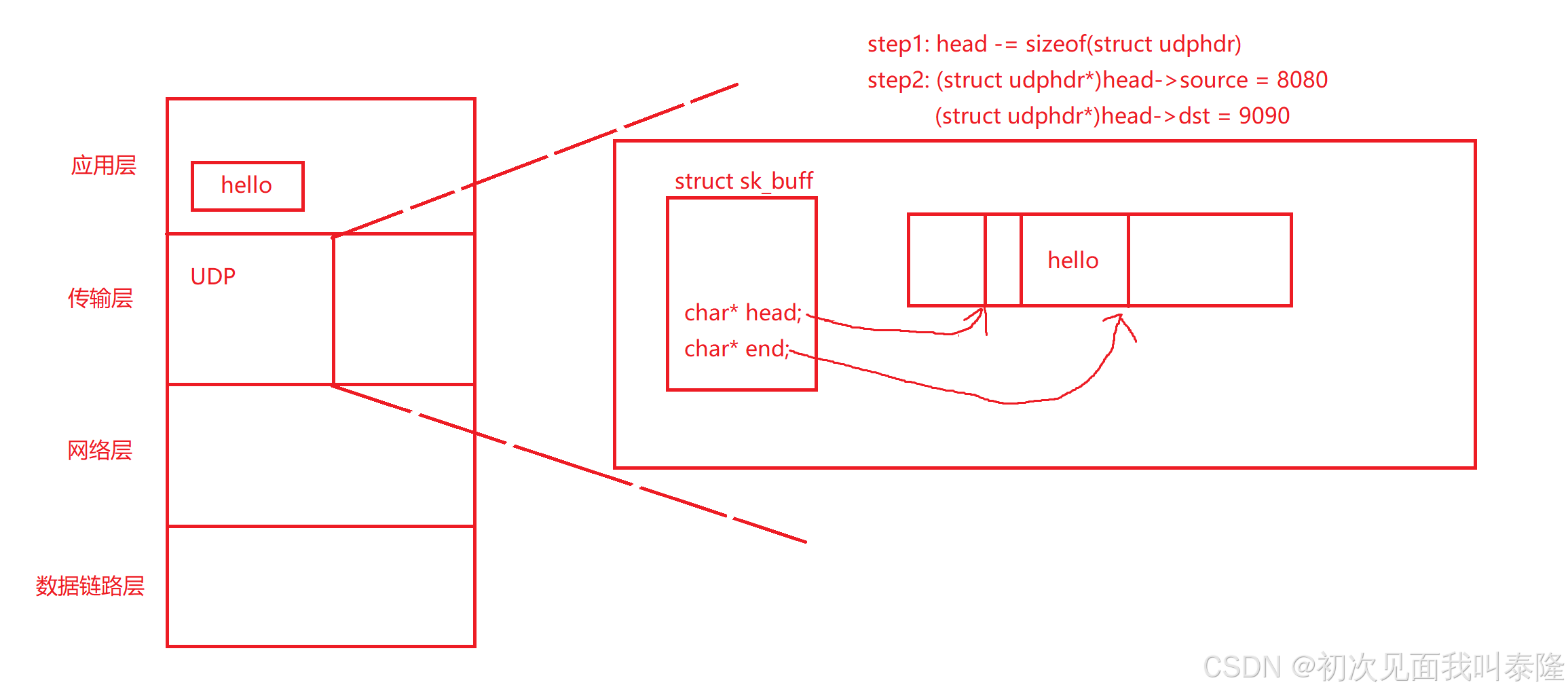
那么現在報頭無非就是兩步,第一步:將head指針往前移動udphdr大小個字節。第二步:接著將指針強轉成struct udphdr*然后就可以訪問里面的成員,對里面的成員進行賦值。
UDP的特點:
無連接:知道對端的IP和端口號就直接進行傳輸,不需要建立連接。
不可靠:沒有確認機制,沒有重傳機制。如果因為網絡故障該段無法發到對方,UDP 協議層也不會給應用層返回任何錯誤信息。
面向數據報:不能夠靈活的控制讀寫數據的次數和數量。應用層交給 UDP 多長的報文,UDP原樣發送,既不會拆分,也不會合并。
UDP的緩沖區:
UDP沒有真正意義上的發送緩沖區。調用 sendto 會直接交給內核,由內核將數據傳給網絡層協議進行后續的傳輸動作。
UDP具有接收緩沖區。但是這個接收緩沖區不能保證收到的UDP報文的順序和發送UDP報文的順序一致。如果緩沖區滿了,再到達的 UDP 數據就會被丟棄。
比如主機A給主機B發送的順序是ABC,而主機B接收到的順序可能就是BCA,這也是屬于不可靠傳輸的一種。
我們注意到,UDP協議首部中有一個16位的最大長度。也就是說一個UDP能傳輸的數據最大長度是64K(包含 UDP首部)。然而64K在當今的互聯網環境下,是一個非常小的數字。如果我們需要傳輸的數據超過 64K,就需要在應用層手動的分包,多次發送,并在接收端手動拼裝。
基于UDP的應用層協議:
NFS:網絡文件系統
TFTP:簡單文件傳輸協議
DHCP:動態主機配置協議
BOOTP:啟動協議(用于無盤設備啟動)
DNS:域名解析協議
2、TCP
TCP全稱為"傳輸控制協議(Transmission Control Protocol)"。人如其名,要對數據的傳輸進行一個詳細的控制。
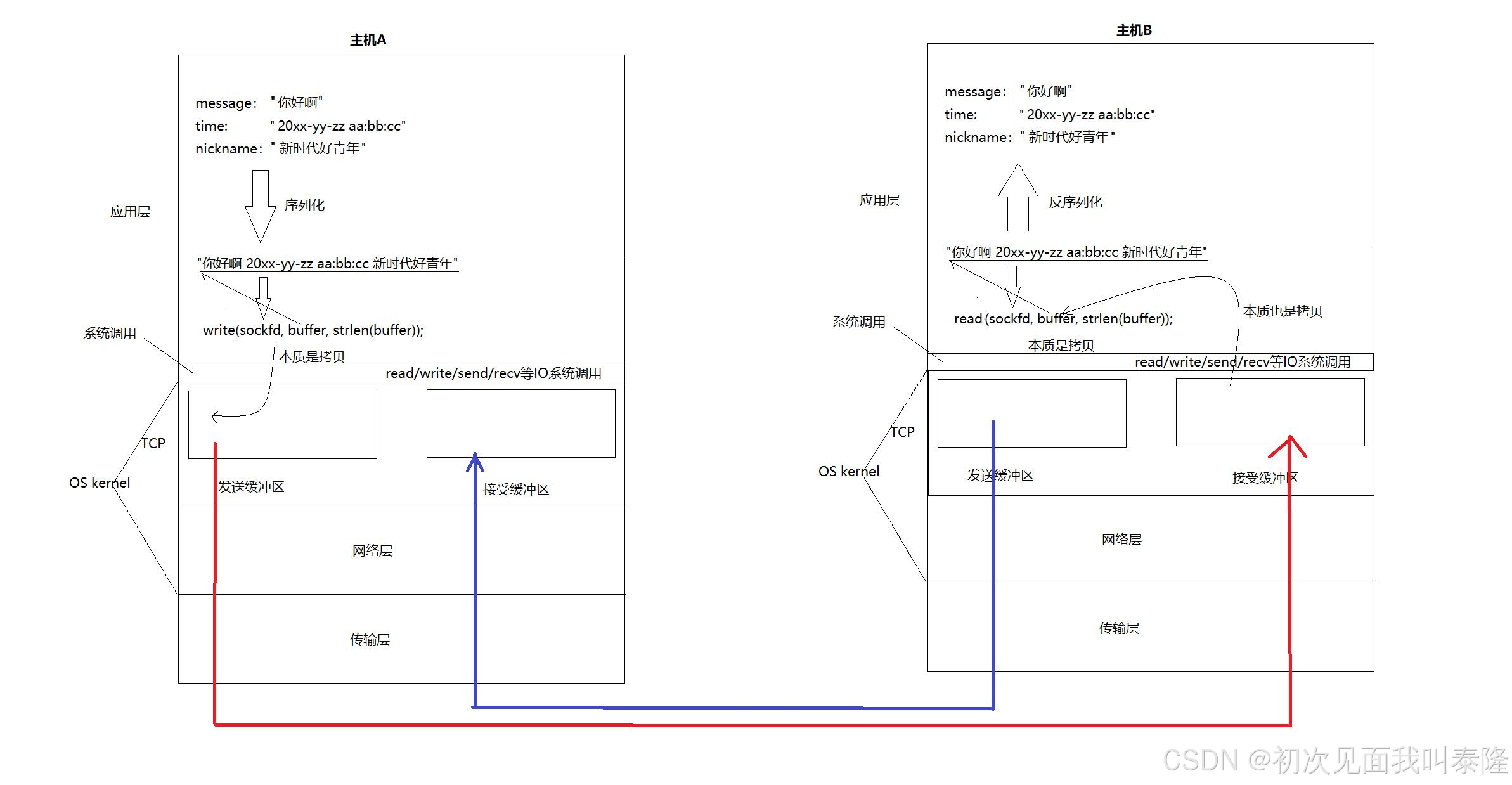
TCP有兩個緩沖區,一個發送緩沖區一個接收緩沖區,當我們調用write函數時,本質是將數據拷貝到發送緩沖區中,對方調用read獲取數據時,本質上是從接收緩沖區中拷貝數據。而發送數據本質就是將主機A的發送緩沖區的數據拷貝到主機B的接收緩沖區中,所以網絡通信的本質就是拷貝。
上層將數據拷貝到發送緩沖區,本質就是拷貝給操作系統,未來數據發送的相關問題:什么時候發、發多少、出錯了怎么辦等,都是由操作系統自主決定的,所以TCP叫做傳輸控制協議。而UDP不存在發送緩沖區,write之后將數據交給下層,UDP做不到傳輸控制。
2.1、TCP協議段格式
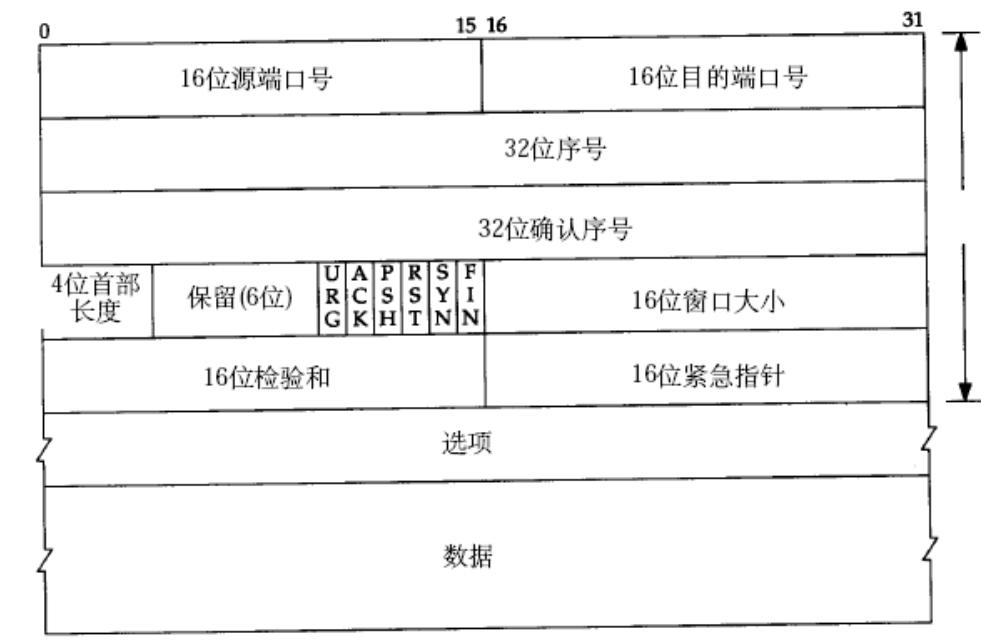
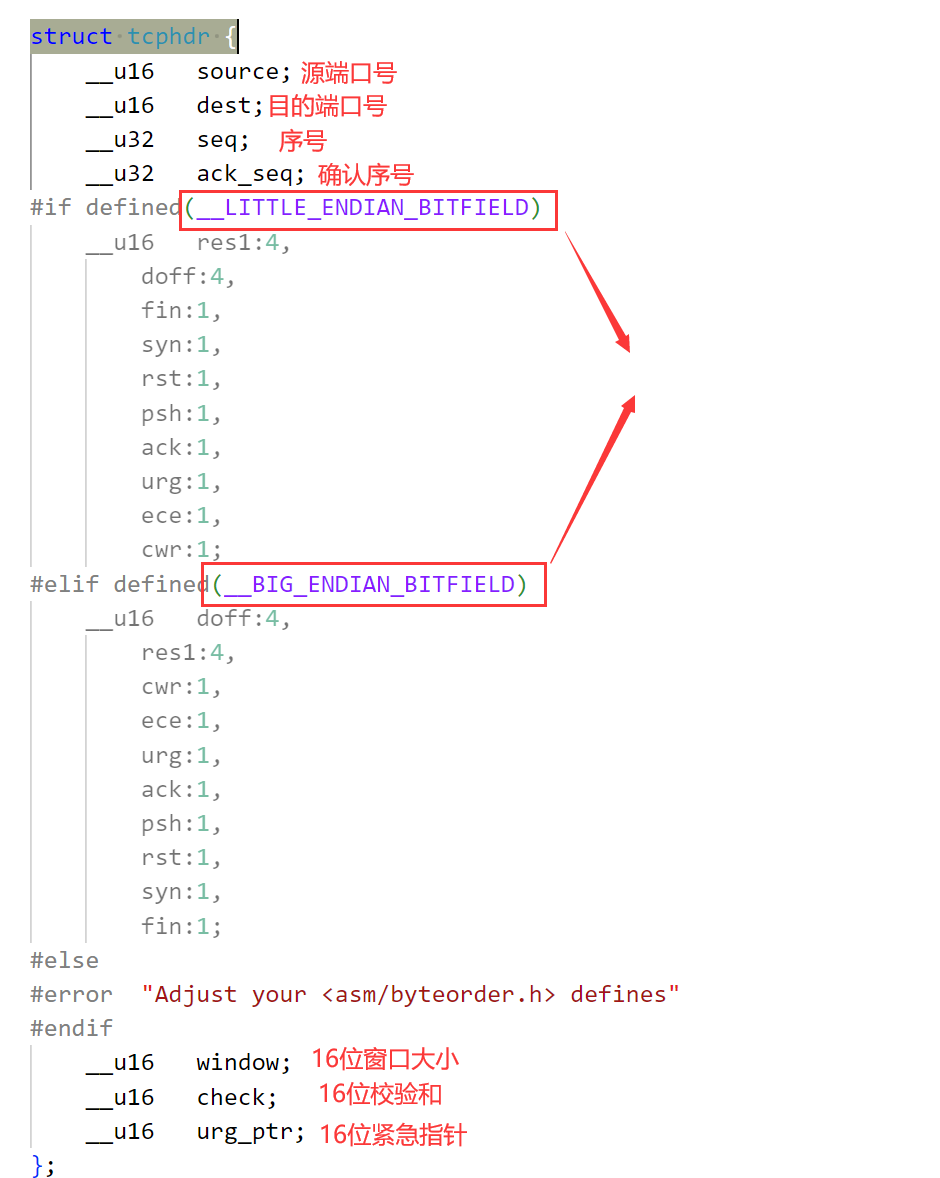
如圖,TCP報文包含報頭和數據,其中前20個字節是固定的,圖中就是五行,每一行四個字節,總共20字節。第一行為16位源端口、16位目的端口。第二行32位序號。第三行32位確認序號。第四行,4位首部長度,保留六位,還有六個標志位,16位窗口大小。第四行有16位校驗和與16位緊急指針。
另外TCP還可以攜帶選項,如果不帶選項就是20字節的報頭+數據。
1、TCP是如何解包的?
首先讀取前20個字節的固定長度,然后提取4位首部長度,根據4位首部長度的大小就可以獲取完整的TCP報頭,這個4位首部長度是包含固定的20字節+選項的長度的。那有人就會說了,4位首部長度最大就是1111,轉換成十進制就是15,連前二十個字節都表示不了?
4位首部長度是有基本計算單位的,它的基本單位是4字節。
4位首部長度的取值范圍為0000->1111,也就是[0,15],還需要再乘以4,所以最后4位首部長度可以表示的范圍就是[0,60]。但是TCP前面20字節是固定的,因此實際取值返回就是[20,60]。
比如提取出來的4位首部長度是8,乘以基本單位4字節就是32字節,32字節減去固定的20字節還剩下12字節,說明剩下的12字節就是選項的長度。這樣就可以讀取整個TCP報頭,那么剩下的就是數據了。那么如果今天TCP報頭沒有選項,TCP報頭就只有20字節,那么對應的首部長度就是20/4=5。
2、TCP是如何分用的?
讀取固定長度的前20個字節,報頭中含有16位目的端口號,提取出16位目的端口號,就可以知道要將數據交付給上層的哪個進程。
下面來看一下Linux內核中的TCP報頭結構體:
2.2、確認應答(ACK)機制
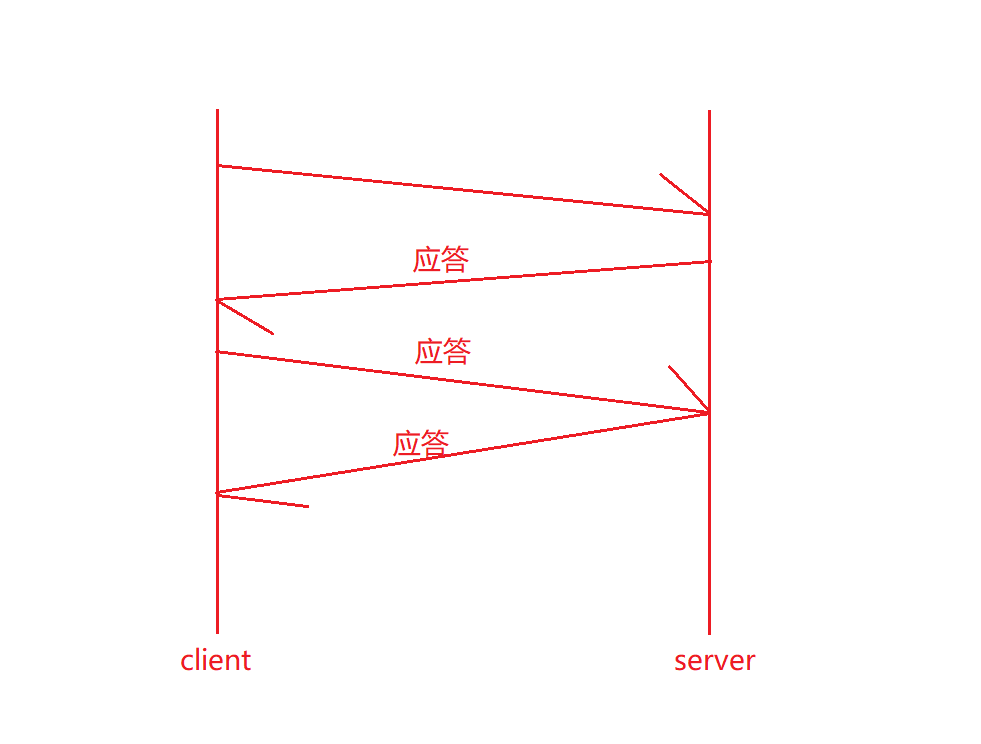
客戶端給服務器發送數據,這個報文在網絡上跑也是需要花時間的。那么客戶端怎么知道我發出去的報文是否被服務端收到了呢?我發出去的報文是否因為某些原因丟失了呢?客戶端是無法得知的。因此就需要服務端對客戶應答,當服務端接收到客戶端發送的報文后,需要對客戶端做應答。
同樣的,服務端給客戶端發數據,客戶端也需要應答,這種策略就是確認應答機制。
那么服務端給客戶端作應答,表示我收到你發給我的報文了,那么服務端如何得知客戶端是否收到我的應答呢?所以就需要客戶端對服務端的應答繼續做應答,然后客戶端又需要知道服務端是否接收到我的應答,所以又需要服務端繼續做應答。那么如果這樣就會陷入了死循環。我們發現長距離通信的時候,其實沒有100%的可靠性!因為總有一條最新的消息是沒有應答的!
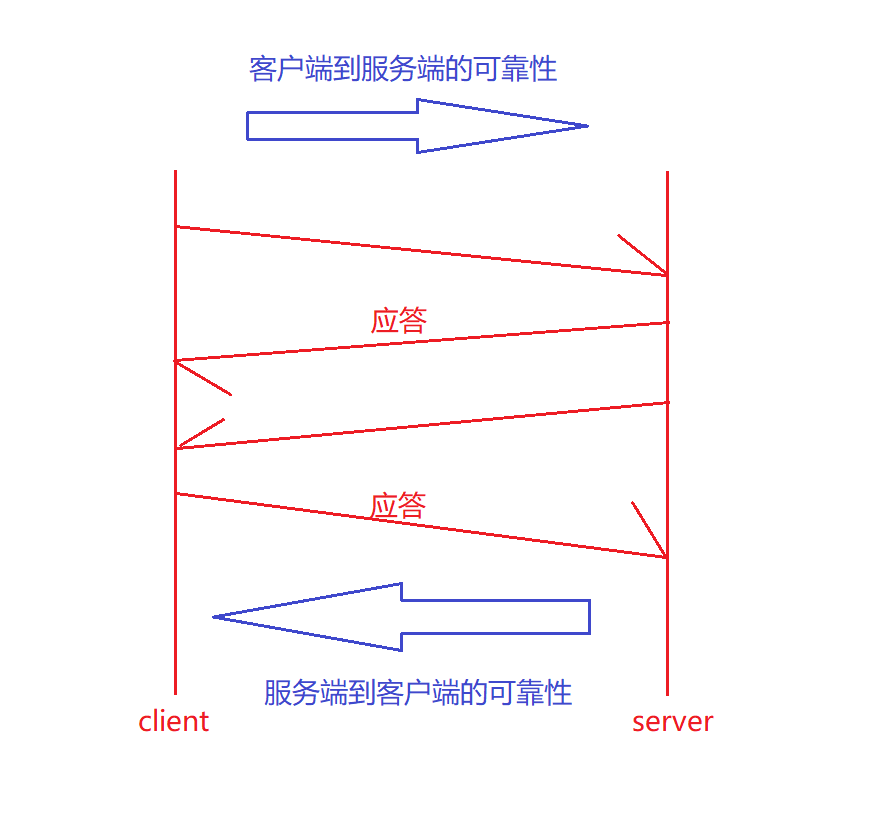
當客戶端給服務端發送數據后,服務端接收到數據需要對客戶端做應答,那么此時服務端就不再關心我的應答是否被客戶端接收到了,因為是客戶端要操心我的數據服務端有沒有接收到。當客戶端接收到應答就說明我之前發送的數據服務端接收到了,保證了老的消息是可靠的,保證了客戶端到服務器的可靠性,不需要再對服務端的應答做應答了。如果客戶端沒有接收到應答,那么可能是服務端沒有接收到數據,也可能是服務端的應答丟失了,這時候客戶端會再去問服務端的。
所以老消息是有應答的,保證100%可靠。
那么此時從客戶端到服務端就是可靠的。同樣的,服務端給客戶端發送數據,客戶端也需要做應答,如此一來,也保證了服務端到客戶端的可靠性。
所以TCP是可靠的,它的核心協議就是確認應答。
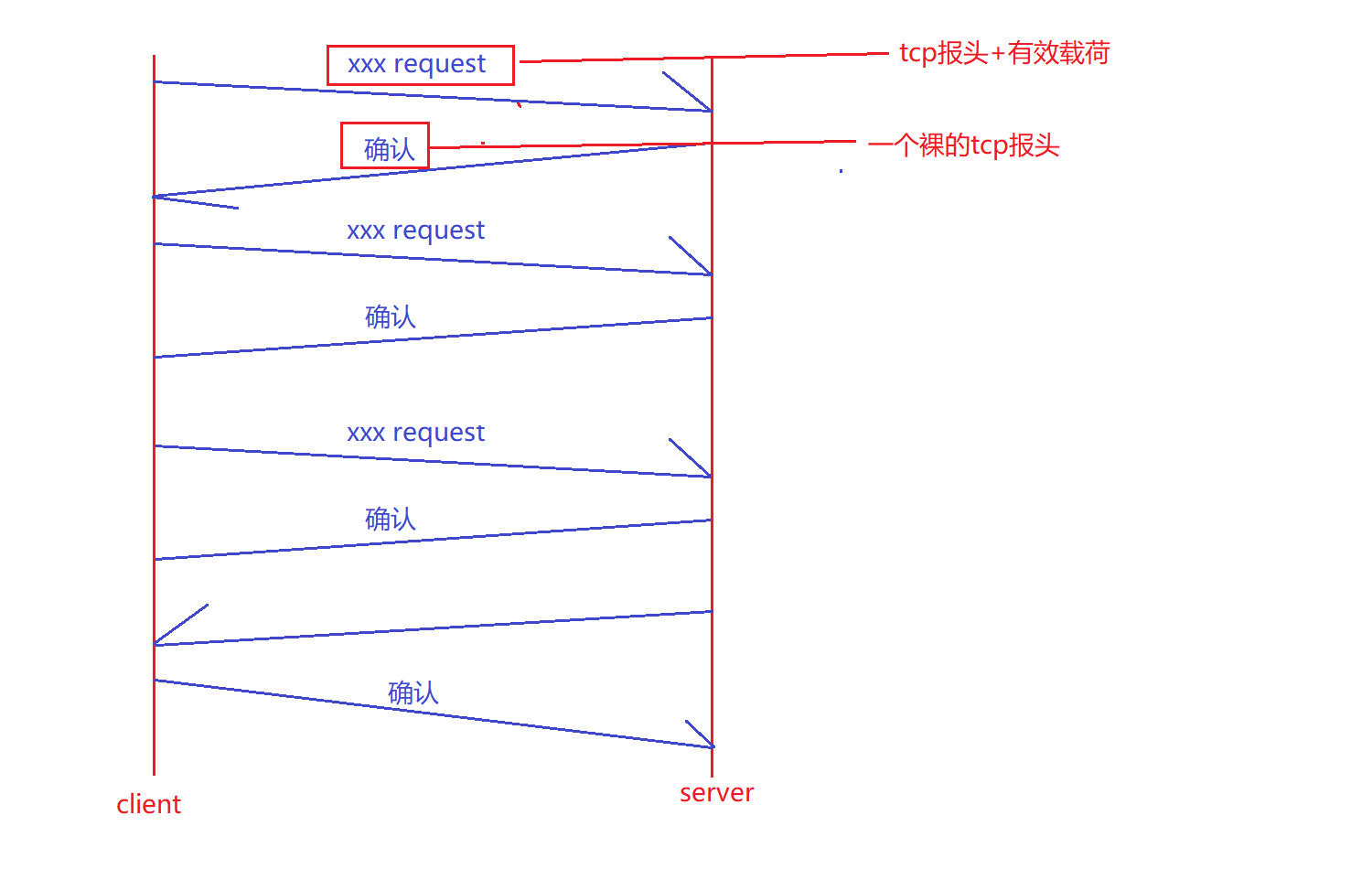
所以現在客戶端發送request,服務端就需要確認應答。同樣的,服務端給客戶端發送數據,客戶端也需要對服務端做應答。
此時客戶端給服務端發送的request是TCP報頭+有效載荷,也就是一個完整的報文。而服務端給客戶端的確認應答是一個裸的TCP報頭。所以雙方在發送數據的時候,至少都要有一個報頭。
再談序號和確認序號:
上面我們的通信方式是:客戶端給服務端發送消息,然后服務端做應答,客戶端接收到確認應答后然后再給服務端發送數據。這種通信方式是串行的,這是我們第一階段的認識,那么這種通信方式效率就很低。
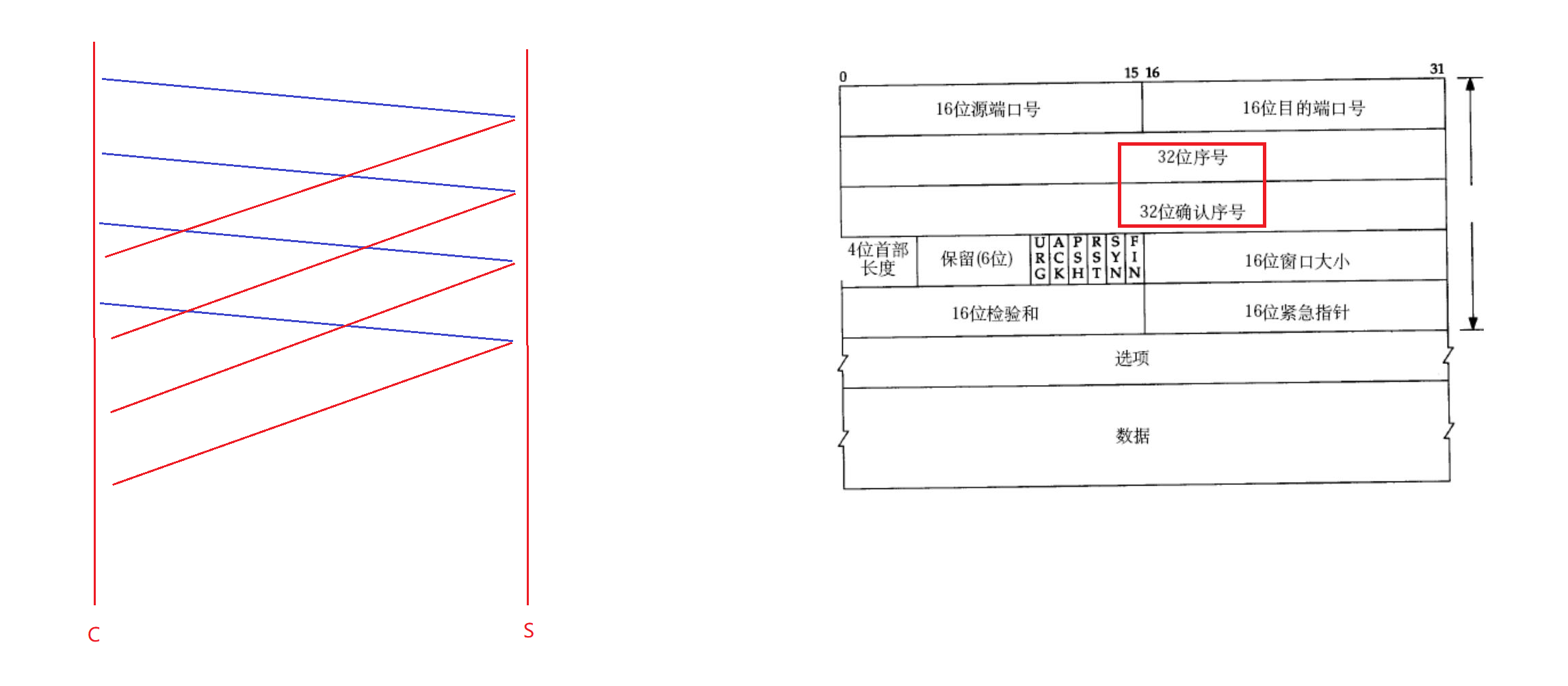
實際上,客戶端會給服務端發送一批報文,比如上圖客戶端C給服務端S發送了四個報文,而每個報文都需要做應答,因此服務端在接收到報文后再給客戶端做應答,每一個報文都要有應答。通過這種方式,既可以保證可靠性同時又提高了效率。但是問題是,服務端給客戶端應答,如果客戶端只收到了三個應答,那么客戶端如何得知這三個應答針對的是哪三個報文呢?
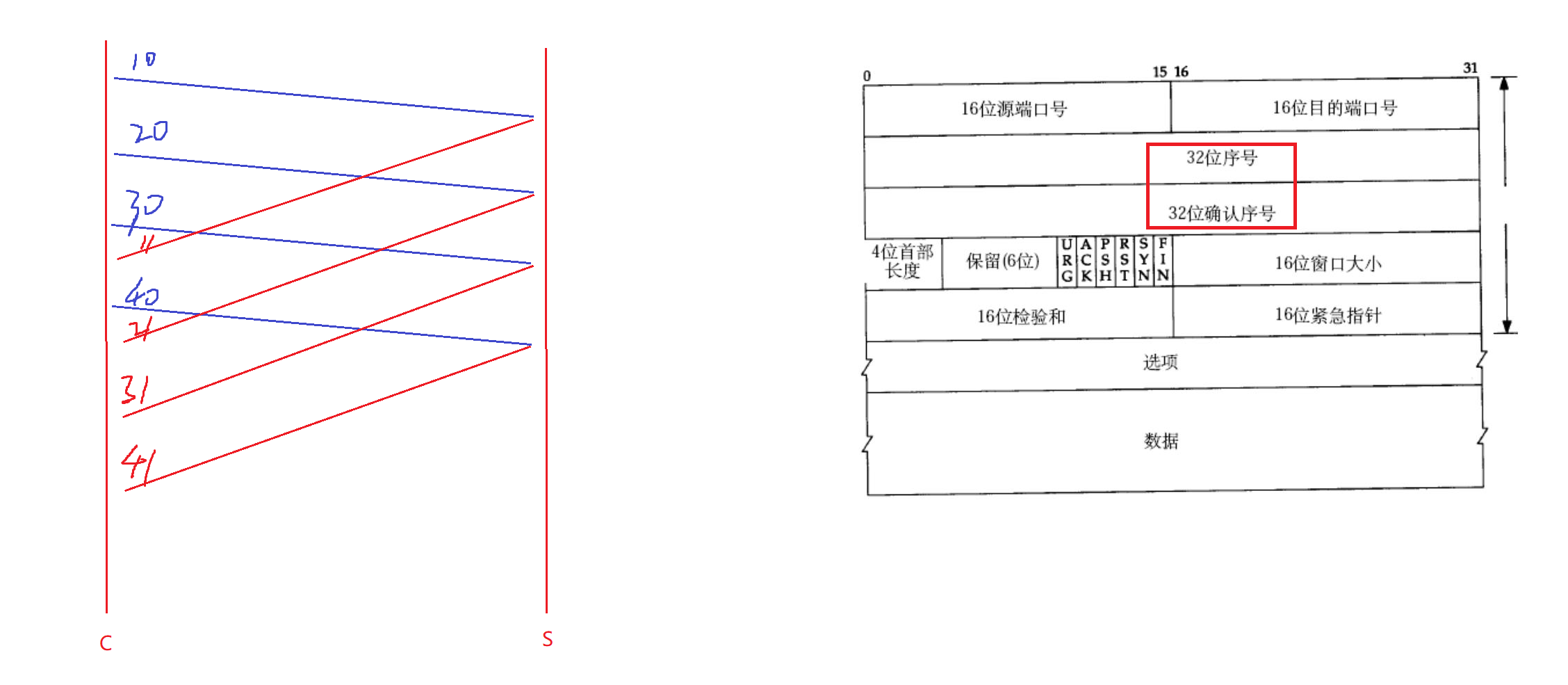
因此客戶端給服務端發送數據的時候,需要給每個報文帶上編號,這個編號就是序號。比如客戶端給服務端發送的四個報文編號分別為10、20、30、40。將來服務端給客戶端確認應答的時候,應答往往是收到的報文序號的值再加1,比如服務端收到客戶端發送的編號位10的報文,將來應答的就是11,收到20,應答就是21。所以給報文帶上序號,就可以對報文進行區分了。
服務端給客戶端返回的序號稱為確認序號,確認序號=序號+1。表示序號之前的內容已經全部收到了。
比如客戶端給服務端發送的報文序號為10,服務端收到后給客戶端作應答,確認序號為11。客戶端再收到服務端的應答后就知道,11號之前的內容對方已經全部收到了。
報文攜帶序號還有另外一個意義。當客戶端給服務端發送報文,比如按照10、20、30、40的順序進行發送的,但是服務端在接受的時候并不一定是按照10、20、30、40的順序接收的。因為網絡可能存在各種各樣的情況,所以可能后發送的先到了,先發送的反而后到。而報文如果是亂序的,也是不可靠的表現。因此就需要根據序號來對接收到的報文進行排序。
服務端在接收到報文后可以根據報文的序號進行升序排序,這樣就保證了服務端緩沖區的報文是有序的。
為什么要有兩個序號?
服務端接收到客戶端發送的數據,比如對應的報文序號為10,那么服務端直接設置序號11給客戶端返回做確認應答就好了,也就是說它們使用一個序號不就可以了嗎,為什么要有序號和確認序號呢?
服務端在給客戶端做應答的時候,如果只是單純的應答,那就是裸的TCP報頭,但是有沒有可能服務端也要給客戶端發送數據呢?當然是有可能的,那么這時候服務端給客戶端發送的就是一個報文,這個報文既是對客戶端之前發送數據的應答,同時也給客戶端發送數據。這種情況稱之為捎帶應答機制。TCP報文在很大的概率上,既是應答,又是數據。
所以這時候就需要序號和確認序號了,確認序號用來表示之前客戶端給我發送的數據我服務端接收到了,同時我也要給客戶端發送數據,所以也要給報文設置序號,方便將來客戶端做應答。那么將來客戶端如果還要發送數據,那發送的報文就是既是應答也是數據,如果沒有數據要發送了,那就是單純的應答。
因此,在TCP通信中,大部分情況下報文既是應答,又攜帶了數據。這才是真實的TCP通信。
再談16位窗口大小:
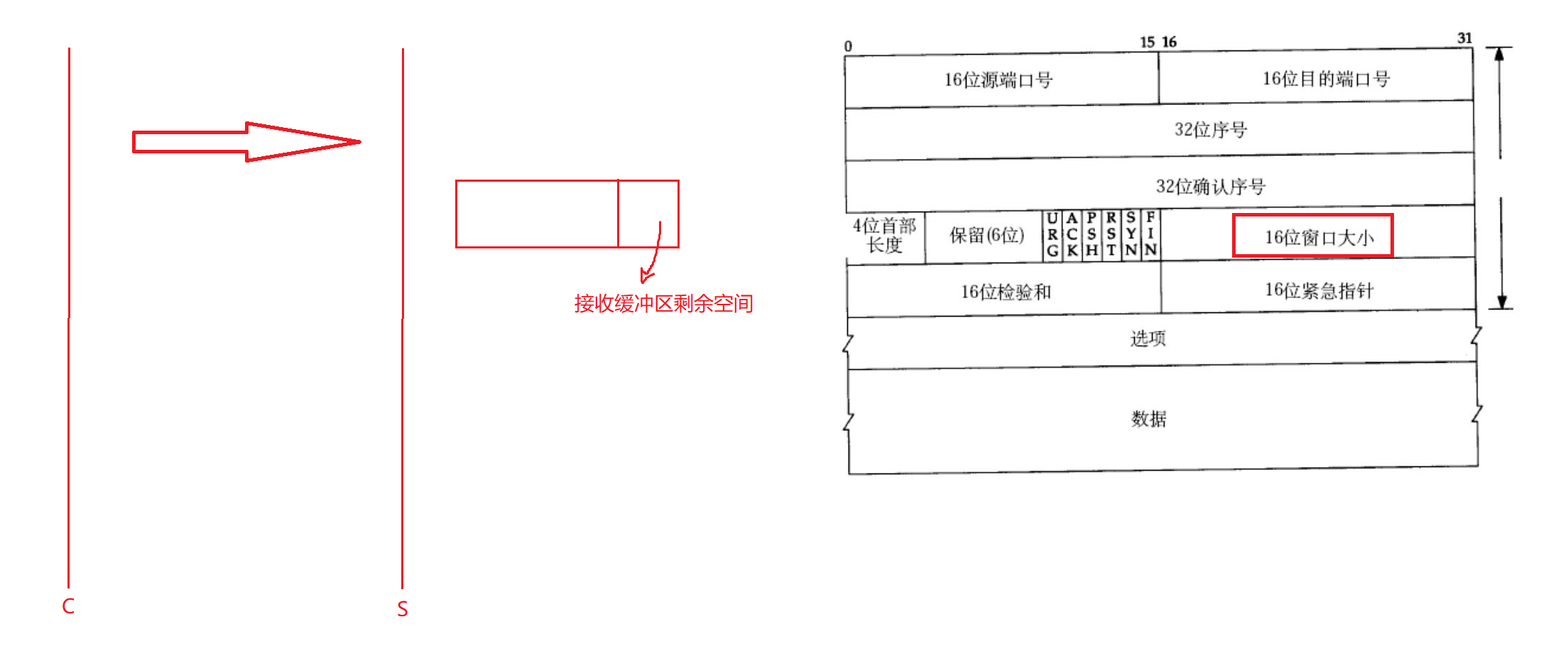
如果對方來不及接收數據呢?
客戶端給服務端發送數據,假設服務端接收緩沖區有100字節,現在已經有80字節的數據了,還剩下20字節的數據。服務端上層還在進行數據的處理,來不及將這80個字節的數據取走,如果這時候客戶端再給服務端發送一大批數據的話,那么接收緩沖區就會滿,滿了服務端就接收不了數據了,因此服務端就會將報文直接丟棄。那么這種做法當然是可以解決的,如果服務端直接將報文丟棄,就不會給客戶端做確認應答,因此客戶端沒有接收到確認應答就會重新給服務端發送報文。
但是操作系統不做浪費時間,浪費空間的事情。
客戶端今天發送了一個報文,這個報文經過網絡千里迢迢到達了服務端,占用了各種網絡資源,結果服務端直接就丟棄了,那不就

詳細教程)

系統軟件部署全攻略:Redis、RabbitMQ、MySQL 等集群搭建指南)






與持續檢測鍵盤按鍵(Input.GetKey))



)




)