文章目錄
- 一、實驗目的
- 實驗內容
- 設計思路
- 三、實驗代碼實現
- 四、總結
一、實驗目的
理解linux文件系統的內部技術,掌握linux與文件有關的系統調用命令,并在此基礎上建立面向隨機檢索的散列結構文件;## 二、實驗內容與設計思想
實驗內容
1.設計一組散列文件函數,包括散列文件的創建,打開,關閉,讀,寫等;
2.編寫一個測試程序,通過記錄保存,查找,刪除等操作,檢查上述散列文件是否實現相關功能;
設計思路
- 設計散列文件函數
我設計了一組散列文件函數,涵蓋了散列文件的創建、打開、關閉、讀和寫等操作。這些函數是構建散列結構文件的基礎,通過合理的設計和實現,確保了文件操作的高效性和正確性。 - 編寫測試程序
為了驗證散列文件的功能,我編寫了一個測試程序,通過記錄的保存、查找和刪除等操作,檢查散列文件是否能正常工作。這個測試程序就像是一個 “質檢員”,幫助我發現并解決代碼中可能存在的問題。
三、實驗代碼實現
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#define HASH_TABLE_SIZE 10 // 散列表大小
#define MAX_RECORD_LENGTH 100 // 記錄最大長度typedef struct Record {char key[20]; // 記錄的關鍵字char data[MAX_RECORD_LENGTH]; // 記錄的數據struct Record* next; // 鏈接到下一個記錄(用于處理沖突)
} Record;typedef struct HashTable {Record* table[HASH_TABLE_SIZE]; // 散列表
} HashTable;// 哈希函數
unsigned int hash(const char* key) {unsigned int hashValue = 0;while (*key) {hashValue = (hashValue << 5) + *key; // 左移 5 位并加上當前字符的 ASCII 值key++;}return hashValue % HASH_TABLE_SIZE;
}// 創建散列文件
HashTable* createHashTable() {HashTable* ht = (HashTable*)malloc(sizeof(HashTable));memset(ht, 0, sizeof(HashTable)); // 初始化散列表return ht;
}// 插入記錄
void insertRecord(HashTable* ht, const char* key, const char* data) {unsigned int index = hash(key);Record* newRecord = (Record*)malloc(sizeof(Record));strcpy(newRecord->key, key);strncpy(newRecord->data, data, MAX_RECORD_LENGTH);newRecord->next = ht->table[index]; // 插入鏈表的頭部ht->table[index] = newRecord;
}// 查找記錄
Record* findRecord(HashTable* ht, const char* key) {unsigned int index = hash(key);Record* record = ht->table[index];while (record != NULL) {if (strcmp(record->key, key) == 0) {return record; // 找到記錄}record = record->next;}return NULL; // 未找到記錄
}// 刪除記錄
void deleteRecord(HashTable* ht, const char* key) {unsigned int index = hash(key);Record* record = ht->table[index];Record* prev = NULL;while (record != NULL) {if (strcmp(record->key, key) == 0) {if (prev == NULL) {ht->table[index] = record->next; // 刪除鏈表頭部元素} else {prev->next = record->next; // 刪除中間或尾部元素}free(record); // 釋放內存return;}prev = record;record = record->next;}
}// 關閉散列文件(釋放內存)
void closeHashTable(HashTable* ht) {for (int i = 0; i < HASH_TABLE_SIZE; i++) {Record* record = ht->table[i];while (record != NULL) {Record* temp = record;record = record->next;free(temp); // 釋放每個記錄}}free(ht); // 釋放哈希表
}// 測試程序
int main() {HashTable* ht = createHashTable();// 插入記錄insertRecord(ht, "key1", "data1");insertRecord(ht, "key2", "data2");insertRecord(ht, "key3", "data3");// 查找記錄Record* found = findRecord(ht, "key2");if (found) {printf("找到記錄: %s -> %s\n", found->key, found->data);} else {printf("未找到記錄\n");}// 刪除記錄deleteRecord(ht, "key2");found = findRecord(ht, "key2");if (found) {printf("找到記錄: %s -> %s\n", found->key, found->data);} else {printf("未找到記錄\n");}// 關閉哈希表closeHashTable(ht);return 0;
}
結果:
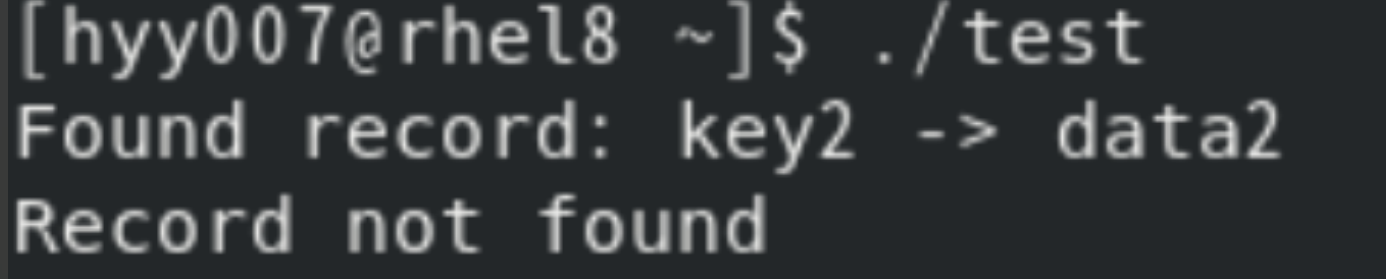
結果分析:
程序首先插入三條記錄:
key1 -> data1
key2 -> data2
key3 -> data3
當程序嘗試查找key2時,程序找到了該記錄,因此輸出:Found record: key2 -> data2
接下來,程序刪除了key2記錄。
再次查key2 時,記錄已經被刪除,因此輸出:Record not found
四、總結
- 遇到的問題
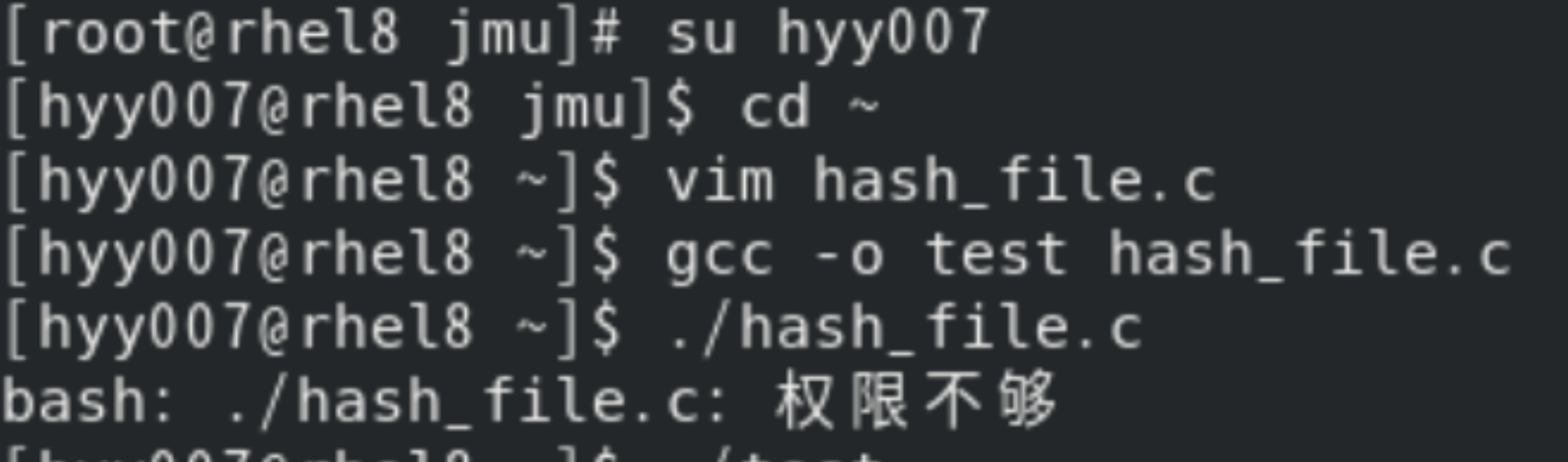
第一次運行時,我輸錯了編譯文件的名字,結果提示權限不夠。這讓我意識到在操作過程中一定要細心,一個小小的失誤都可能導致程序無法正常運行。經過修正后,程序的運行結果符合預期。程序先插入了三條記錄,然后成功查找到了 key2 對應的記錄,接著刪除了該記錄,再次查找時就顯示未找到記錄,這表明散列文件的基本功能已經實現。
為了處理哈希沖突,我使用了鏈式法。通過鏈表存儲多個記錄,保證了散列表的完整性。這讓我認識到在設計數據結構時,不僅要考慮基本功能的實現,還要考慮可能出現的異常情況,并采取有效的處理方法。
在實現散列表的過程中,我更加深入地理解了指針和內存管理的重要性。正確地分配和釋放內存是保證程序穩定運行的關鍵,稍有不慎就可能導致內存泄漏或懸空指針等問題。這也提醒我在今后的編程中要養成良好的內存管理習慣。
這次實驗讓我對 Linux 文件系統和散列結構文件有了更深入的理解,也提升了我的編程能力和問題解決能力。在今后的學習和工作中,我將繼續探索數據結構和算法的奧秘,不斷提升自己的技術水平。同時,我也會更加注重細節,避免因為粗心而導致的錯誤。我相信,通過不斷的實踐和學習,我能夠更好地應對各種編程挑戰。



)

結構體、共用體、枚舉、typedef關鍵字與位運算)


——visualize_dataset_html.py/visualize_dataset.py)





、包(Package)和模塊(Module)解析】)

)
)

