InfiniBand協議總結
- InfiniBand協議是什么?
- Infiniband產生的原因
- Mellanox公司介紹及其新聞
- 基于TCP/IP的網絡與IB網絡的比較
- IB標準的優勢
- 什么是InfiniBand網絡
- 什么是InfiniBand架構
- Mellanox IB卡介紹
- InfiniBand速率發展介紹
- InfiniBand網絡主要上層協議
- InfiniBand管理軟件
- Infiniband的協議層次與網絡結構
- 如何使用IB verbs傳送數據
- 常見錯誤
- IB專業術語
- 報文基本知識
- 報文傳輸類型
- 交換器和路由器規則
- 屬性與管理器
- IB核心傳輸引擎Queue Pair
InfiniBand協議是什么?
NVIDIA 于2020年4月份完成了對 Mellanox 的收購,將高性能網絡技術與自身高性能計算技術相結合,提供更高的性能、更高的計算資源利用率,其中最重要的一點是通過 InfiniBand 實現互連。
InfiniBand 即“無限帶寬”技術,通常縮寫為IB,是一個用于高性能計算的計算機網絡通信標準,它最重要的一個特點就是高帶寬、低延遲,應用于計算機與計算機之間的數據互連。InfiniBand 也用作服務器與存儲系統之間的直接或交換互連,以及存儲系統之間的互連,這也是 NVIDIA 收購 Mellanox 的一個重要原因。
由于IB網絡具備低延遲、高帶寬的網絡特性,因此在高性能計算項目中有比較廣泛的應用,通常在集群中作為高速計算網絡,IB 網絡采用了 mallenox 的IB網卡(目前最新帶寬已經達到400Gb/s),通過專用 IB 交換機和控制器軟件 UFM 實現網絡通信和管理。
InfiniBand 作為一個統一的互聯技術,可以用來處理存儲 I/O、網絡 I/O,也能夠去處理進程間的互相通信。它可以將服務器集群中的管理節點、計算節點、存儲服務器(分布式存儲、磁盤陣列)等進行互聯,實現高速通信,也可以連接外部網絡(例如互聯網、VPN、WAN)。設計及使用InfiniBand 技術的目的主要是應用于企業級的數據中心進行高速通信。其目標主要是實現高的可靠性、可用性、可擴展性和高的性能。InfiniBand 可以提供高帶寬、低延遲的傳輸在相對短的距離內,而且在單個或多個互聯網絡中支持冗余的 I/O 通道,所以在數據中心發生一些故障的情況下仍然能夠保持高速運行。
在應用場景方面,以太網可以實現全球通信的互聯,InfiniBand 則沒有那么大的通信距離和范圍,主要用于企業、校園內部或者城市局域部分的數據中心,通常只有幾間機房,而他的最大距離很大程度上取決于纜線類型(銅纜或光纖)、連接的質量、數據速率和收發器等。如果在使用光纜、單模的收發器以及基本數據速率的情況下,InfiniBand 的最大距離在10公里左右。
理論上來說,InfiniBand 能夠想以太網一樣通過交換機、路由器實現超遠距離的通信,但是在實際使用過程中,傳輸距離會受到多方面的限制。為了確保數據分組的可靠傳輸,InfiniBand 具備諸如反應超時、流控等特點,用來防止阻塞造成的分組丟失。延長 InfiniBand 的距離將降低這些特征的有效性,因為延遲超過了合理的范圍。
為了擴大InfiniBand的應用范圍,滿足用戶更大的使用需求,需要解決長距離傳輸問題,Mellanox 廠商想到了利用以太網、光纖網絡的方式來解決這一困擾;即通過一橋接設備連接到以太網和光纖網絡,同時能夠實現InfiniBand網絡與現有的光纖通道連接的各類局域網、城域網等分布式數據中心相兼容,通過這一方法,將傳輸距離提升至10公里左右。
除了上文中介紹到的高速網絡傳輸性能之外,Infiniband 技術發展的另一個重要的方向在于將服務器中的總線進行網絡化,因此它直接繼承了總線低時延、高帶寬的特性。Infiniband 中的 RDMA(Remote Direct Memory Access) 技術直接繼承的總線技術中使用的 DMA Direct Memory Access) 技術。得益于這一技術的應用,我們能夠通過 RDMA 提供的基于 IO 通道直接對遠程的虛擬內存進行直接讀寫,而不是像傳統的讀寫方式,需要通過 CPU 的干預,應用程序能夠直接訪問遠程主機內存或者硬盤而不必消耗遠程主機中的任何 CPU 資源,釋放服務器 CPU 性能。因此相對萬兆以太網來說,Infiniband 在服務器中對 CPU、內存、硬盤等的交流方面具備天然的優勢。
Infiniband產生的原因
隨著CPU性能的飛速發展,I/O系統的性能成為制約服務器性能的瓶頸。于是人們開始重新審視使用了十幾年的PCI總線架構。雖然PCI總線結構把數據的傳輸從8位/16位一舉提升到32位,甚至當前的64位,但是它的一些先天劣勢限制了其繼續發展的勢頭。PCI總線有如下缺陷:
-
由于采用了基于總線的共享傳輸模式,在PCI總線上不可能同時傳送兩組以上的數據,當一個PCI設備占用總線時,其他設備只能等待;
-
隨著總線頻率從33MHz提高到66MHz,甚至133MHz(PCI-X),信號線之間的相互干擾變得越來越嚴重,在一塊主板上布設多條總線的難度也就越來越大;
-
由于PCI設備采用了內存映射I/O地址的方式建立與內存的聯系,熱添加PCI設備變成了一件非常困難的工作。目前的做法是在內存中為每一個PCI設備劃出一塊50M到100M的區域,這段空間用戶是不能使用的,因此如果一塊主板上支持的熱插拔PCI接口越多,用戶損失的內存就越多;
4. PCI的總線上雖然有buffer作為數據的緩沖區,但是它不具備糾錯的功能,如果在傳輸的過程中發生了數據丟失或損壞的情況,控制器只能觸發一個NMI中斷通知操作系統在PCI總線上發生了錯誤因此,Intel、 Cisco、 Compaq、 EMC、 富士通等公司共同發起了infiniband架構,其目的是為了取代PCI成為系統互連的新技術標準,其核心就是將I/O系統從服務器主機中分離出來。
InfiniBand 采用雙隊列程序提取技術,使應用程序直接將數據從適配器 送入到應用內存(稱為遠程直接存儲器存取或RDMA), 反之依然。在TCP/IP協議中,來自網卡的數據先拷貝到 核心內存,然后再拷貝到應用存儲空間,或從應用空間 將數據拷貝到核心內存,再經由網卡發送到Internet。這 種I/O操作方式,始終需要經過核心內存的轉換,它不 僅增加了數據流傳輸路徑的長度,而且大大降低了I/O 的訪問速度,增加了CPU的負擔。而SDP則是將來自網 卡的數據直接拷貝到用戶的應用空間,從而避免了核心 內存參入。這種方式就稱為零拷貝,它可以在進行大量 數據處理時,達到該協議所能達到的最大的吞吐量
Mellanox公司介紹及其新聞
InfiniBand技術一直以來都是Mellanox公司在推動發展,下面是Mellanox的簡要介紹;

Mellanox合并完成:NVIDIA網卡名正言順!
Mellanox為何讓多家巨頭公司“趨之若鶩”
N卡網速快!Mellanox 100GbE 交換機 SN2700 開箱簡測
一文掌握InfiniBand技術和架構
infiniband學習總結
基于TCP/IP的網絡與IB網絡的比較
IP網絡協議如TCP/IP,具有轉發丟失數據包的特性,網絡不良時要不斷地確認與重發,基于這些協議的通信也會因此變慢,極大地影響了性能。與之相比,IB使用基于信任的、流控制的機制來確保連接的完整性,數據包極少丟失。
使用IB協議,除非確認接收緩存具備足夠的空間,否則不會傳送數據。接受方在數據傳輸完畢之后,返回信號來標示緩存空間的可用性。通過這種辦法,IB協議***消除了由于原數據包丟失而帶來的重發延遲,從而提升了效率和整體性能***。
IB標準的優勢
IB(InfiniBand)協議是用于高性能計算的網絡通訊標準,其主要優勢是:
- 支持大量協議:包括通過IB光纖的非IB協議的隧道包,例如IPv6、Ethertype包;
- 高帶寬,吞吐量可實現2.5Gb/s,10Gb/s,30Gb/s;
- 低延時,應用程序時延 <3us; 高可擴展性的拓撲結構;
- 非特權應用發送接收信息時,內核不用進行特權模式的切換;
- 每個信息都由CA(通道適配器)的硬件DMA直接傳輸,而不用處理器的參與,也就是RDMA;
大部分協議都可以在芯片上實現,減少軟件和處理器的負荷。
什么是InfiniBand網絡
InfiniBand是一種網絡通信協議,它提供了一種基于交換的架構,由處理器節點之間、處理器節點和輸入/輸出節點(如磁盤或存儲)之間的點對點雙向串行鏈路構成。每個鏈路都有一個連接到鏈路兩端的設備,這樣在每個鏈路兩端控制傳輸(發送和接收)的特性就被很好地定義和控制了。
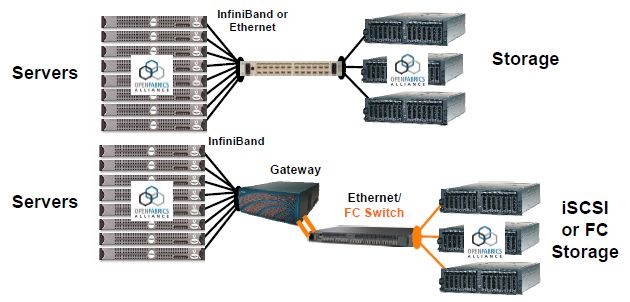
InfiniBand通過交換機在節點之間直接創建一個私有的、受保護的通道,進行數據和消息的傳輸,無需CPU參與遠程直接內存訪問(RDMA)和發送/接收由InfiniBand適配器管理和執行的負載。
適配器通過PCI Express接口一端連接到CPU,另一端通過InfiniBand網絡端口連接到InfiniBand子網。與其他網絡通信協議相比,這提供了明顯的優勢,包括更高的帶寬、更低的延遲和增強的可伸縮性。
什么是InfiniBand架構
InfiniBand Architecture(IBA) 是為硬件實現而設計的,而TCP則是為軟件實現而設計的。因此,InfiniBand是比TCP更輕的傳輸服務,因為它不需要重新排序數據包,因為較低的鏈路層提供有序的數據包交付。傳輸層只需要檢查包序列并按順序發送包。
進一步,因為InfiniBand提供以信用為基礎的流控制(發送方節點不給接收方發送超出廣播 “信用“大小的數據包),傳輸層不需要像TCP窗口算法那樣的包機制確定最優飛行包的數量。這使得高效的產品能夠以非常低的延遲和可忽略的CPU利用率向應用程序交付56、100Gb/s的數據速率。
IB是以通道(Channel)為基礎的雙向、串行式傳輸,在連接拓樸中是采用交換、切換式結構(Switched Fabric),所以會有所謂的IBA交換器(Switch),此外在線路不夠長時可用IBA中繼器(Repeater)進行延伸。
而每一個IBA網絡稱為子網(Subnet),每個子網內最高可有65,536個節點(Node),IBASwitch、IBA Repeater僅適用于Subnet范疇,若要通跨多個IBA Subnet就需要用到IBA路由器(Router)或IBA網關器(Gateway)。
至于節點部分,Node想與IBA Subnet接軌必須透過配接器(Adapter),若是CPU、內存部分要透過HCA (Host Channel Adapter),若為硬盤、I/O部分則要透過TCA (Target Channel Adapter),之后各部分的銜接稱為聯機(Link)。上述種種構成了一個完整的IBA。
Mellanox IB卡介紹
1、它長什么樣子???


2、為什么 Infiniband 協議需要使用 ib卡?
首先,這里介紹兩種概念:
(1)、傳統的網絡通信協議 —— tcp、udp、ip、icmp 等…
(2)、新一代網絡通信協議 —— InfiniBand … 等
傳統的通信協議通過內核傳遞,這很難去支持 新的網絡協議 及 發送/接收 端口。而 Infiniband 作為一種新一代的網絡協議 ,從一開始就支持 RDMA 技術,由于 infiniband是 一種新的網絡協議,因此需要支持該技術的網卡和交換機。
3、如何查看本機有沒有ib卡?
user@ubuntu:~$ lspci | grep Mell
0b:00.0 Network controller: Mellanox Technologies MT27500 Family [ConnectX-3]
# 記得是大寫的 M,千萬要注意格式
4、如何簡單使用:
1、在服務器上,插上ib卡,然后連接到服務器上
2、下載相應的ib驅動(點我下載)
3、啟動驅動,然后查看ib口(iconfig -a)
4、配置ip,重啟服務,進行 RDMA 連通性測試。
推薦:下載ib驅動包 以 基于ubuntu16.04安裝ib驅動(步驟詳細)
RDMA 連通性測試
4、如何簡單使用:
1、在服務器上,插上ib卡,然后連接到服務器上
2、下載相應的ib驅動(點我下載)
3、啟動驅動,然后查看ib口(iconfig -a)
4、配置ip,重啟服務,進行 RDMA 連通性測試。
推薦:下載ib驅動包 以 基于ubuntu16.04安裝ib驅動(步驟詳細)
RDMA 連通性測試
版權聲明:本文為CSDN博主「鄭澤林」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/ljlfather/article/details/102892052
InfiniBand速率發展介紹
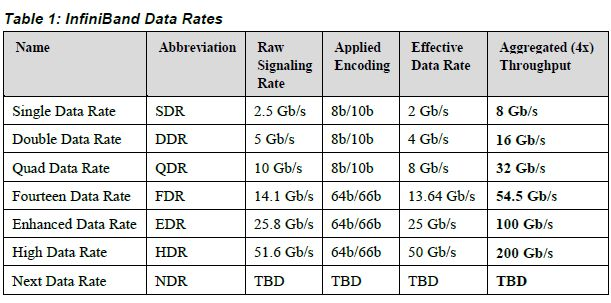
InfiniBand串行鏈路可以在不同的信令速率下運行,然后可以捆綁在一起實現更高的吞吐量。原始信令速率與編碼方案耦合,產生有效的傳輸速率。編碼將通過銅線或光纖發送的數據的錯誤率降至最低,但也增加了一些開銷(例如,每8位數據傳輸10位)。
典型的實現是聚合四個鏈接單元(4X)。目前,InfiniBand系統提供以下吞吐量速率:
InfiniBand網絡主要上層協議
InfiniBand為不同類型的用戶提供了不同的上層協議,并為某些管理功能定義了消息和協議。InfiniBand主要支持SDP、SRP、iSER、RDS、IPoIB和uDAPL等上層協議。
SDP (Sockets Direct Protocol)是InfiniBand Trade Association (IBTA)制定的基于infiniband的一種協議,它允許用戶已有的使用TCP/IP協議的程序運行在高速的infiniband之上。
SRP(SCSIRDMA Protocol)是InfiniBand中的一種通信協議,在InfiniBand中將SCSI命令進行打包,允許SCSI命令通過RDMA(遠程直接內存訪問)在不同的系統之間進行通信,實現存儲設備共享和RDMA通信服務。
iSER(iSCSI RDMA Protocol)類似于SRP(SCSI RDMA protocol)協議,是IB SAN的一種協議 ,其主要作用是把iSCSI協議的命令和數據通過RDMA的方式跑到例如Infiniband這種網絡上,作為iSCSI RDMA的存儲協議iSER已被IETF所標準化。
RDS(Reliable Datagram Sockets)協議與UDP 類似,設計用于在Infiniband 上使用套接字來發送和接收數據。實際是由Oracle公司研發的運行在infiniband之上,直接基于IPC的協議。
IPoIB(IP-over-IB)是為了實現INFINIBAND網絡與TCP/IP網絡兼容而制定的協議,基于TCP/IP協議,對于用戶應用程序是透明的,并且可以提供更大的帶寬,也就是原先使用TCP/IP協議棧的應用不需要任何修改就能使用IPoIB。
uDAPL(User Direct Access Programming Library)用戶直接訪問編程庫是標準的API,通過遠程直接內存訪問 RDMA功能的互連(如InfiniBand)來提高數據中心應用程序數據消息傳送性能、伸縮性和可靠性。
iSER (iSCSI Extensions for RDMA)和NFSoRDMA (NFS over RDMA),SRP (SCSI RDMA Protocol) 等是InfiniBand中的一種通信協議,在InfiniBand中將SCSI命令進行打包,允許SCSI命令通過RDMA在不同的系統之間進行通信,實現存儲設備共享和RDMA通信服務。
InfiniBand管理軟件
***OpenSM***軟件是符合InfiniBand的子網管理器(SM),運行在Mellanox OFED軟件堆棧進行IB 網絡管理,管理控制流走業務通道,屬于帶內管理方式。
OpenSM包括子網管理器、背板管理器和性能管理器三個組件,綁定在交換機內部的必備部件。提供非常完備的管理和監控能力,如設備自動發現、設備管理、Fabric可視化、智能分析、健康監測等等。
Infiniband的協議層次與網絡結構
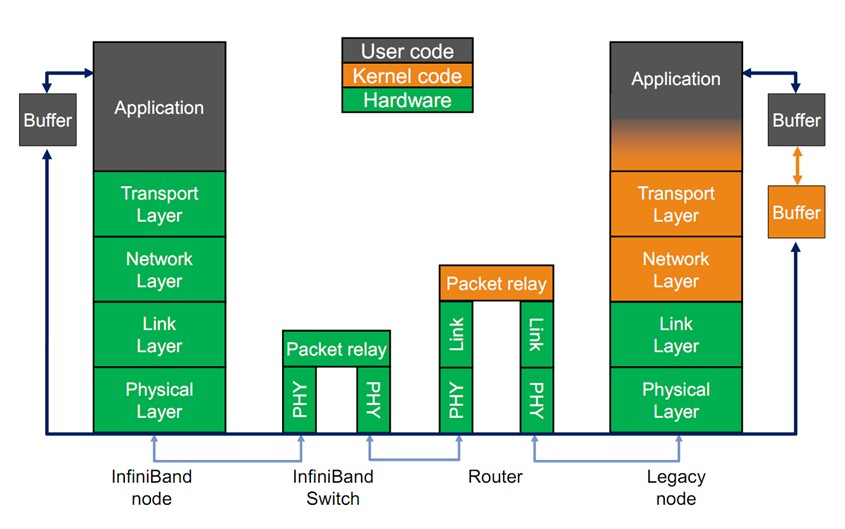
Infiniband的協議采用分層結構,如下圖所示,各個層次之間相互獨立,下層為上層提供服務。
其中,物理層定義了在線路上如何將比特信號組 成符號,然后再組成幀、 數據符號以及包之間的數據填 充等,詳細說明了構建有效包的信令協議等;
鏈路層定義了數據包的格式以及數據包操作的協議,如流控、 路由選擇、 編碼、解碼等;
網絡層通過在數據包上添加一個40字節的全局的路由報頭(Global Route Header,GRH)來進行路由的選擇,對數據進行轉發。在轉發的過程中,路由器僅僅進行可變的CRC校驗,這樣就保證了端到端的數據傳輸的完整性;
傳輸層再將數據包傳送到某個指定 的隊列偶(QueuePair,QP)中,并指示QP如何處理該數據 包以及當信息的數據凈核部分大于通道的最大傳輸單 元MTU時,對數據進行分段和重組。
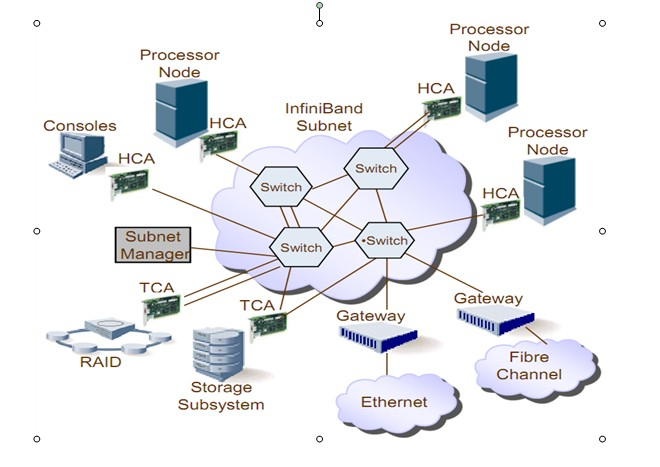
Infiniband的網絡拓撲結構如下圖,其組成單元主要分為四類:
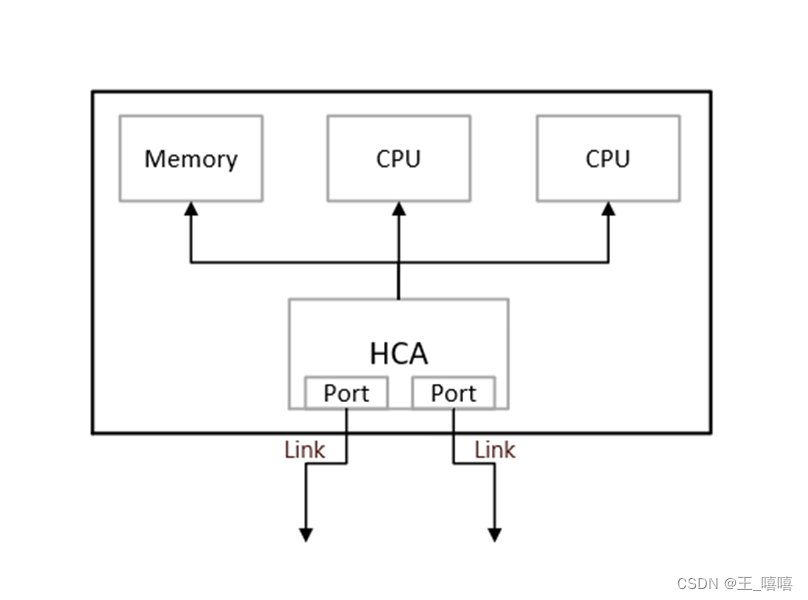
(1)HCA(Host Channel Adapter),它是連接內存控制器和TCA的橋梁;
(2)TCA(Target Channel Adapter),它將I/O設備(例如網卡、SCSI控制器)的數字信號打包發送給HCA;
(3)Infiniband link,它是連接HCA和TCA的光纖,InfiniBand架構允許硬件廠家以1條、4條、12條光纖3種方式連結TCA和HCA;
(4)交換機和路由器;
無論是HCA還是TCA,其實質都是一個主機適配器,它是一個具備一定保護功能的可編程DMA(Direct Memory Access,直接內存存取 )引擎。
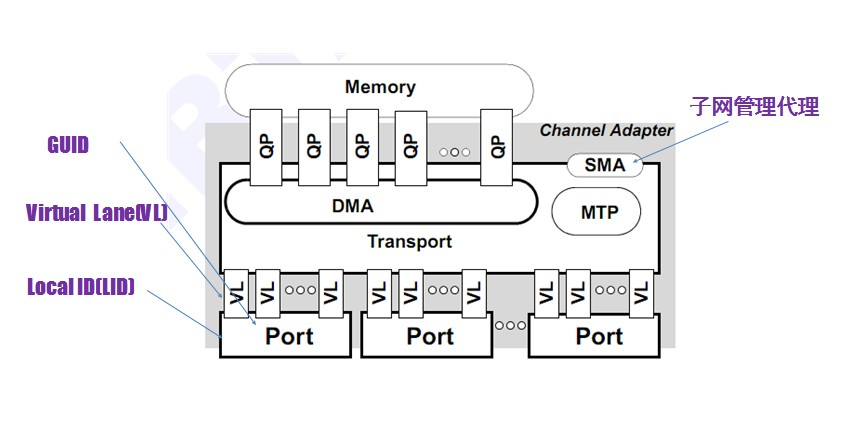
如下圖所示,每個端口具有一個GUID(Globally Unique Identifier),GUID是全局唯一的,類似于以太網MAC地址。運行過程中,子網管理代理(SMA)會給端口分配一個本地標識(LID),LID僅在子網內部有用。QP是infiniband的一個重要概念,它是指發送隊列和接收隊列的組合,用戶調用API發送接收數據的時候,實際上是將數據放入QP當中,然后以輪詢的方式將QP中的請求一條條的處理,其模式類似于生產者-消費者模式。
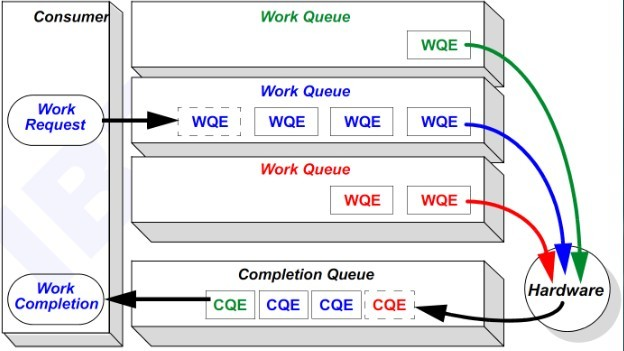
如下圖所示,圖中Work queue即是QP中的send Queue或者receive Queue,WQ中的請求被處理完成之后,就被放到Work Completion中。
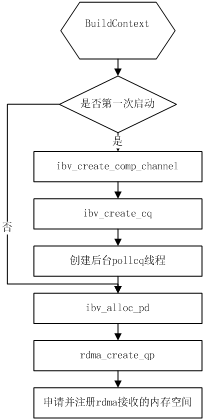
如何使用IB verbs傳送數據
Infiniband提供了VPI verbs API和RDMA_CM verbs API 這兩個API集合,用戶使用其中的庫函數,就能很方便的在不同的機器之間傳輸數據。Infiniband建立連接的流程如下圖所示:

其中buildcontext的流程如下:
連接建立完成之后,就可以調用ibv_post_recv和ibv_post_send收發數據了,發送和接收請求都被放在QP中,后臺需要調用ibv_poll_cq來逐條處理請求,由于infiniband連接中,一旦有一條數據發送或者接收失敗,其后所有的數據發送或者接收都會失敗,因此一旦檢測到WC的狀態不是成功,需要立即處理此錯誤(此時最好斷開連接)。
常見錯誤
ibv_poll_cq處理完隊列中的數據后,WC會包含此次處理的全部信息,包括wr_id、操作狀態、錯誤碼等等,錯誤碼包含的信息對于我們解決錯誤非常有用,這里我就列舉一下我在編寫代碼中遇到的錯誤。
(1)錯誤碼為4(IBV_WC_LOC_PROT_ERR ),這種錯誤通常意味著用戶對內存的操作權限不夠,需要檢測在ibv_post_recv和ibv_post_send時scatter/gather list 中傳入的內存地址與長度是否正確,或者ibv_reg_mr操作是否成功。
(2)錯誤碼為5,(IBV_WC_WR_FLUSH_ERR ),在flush的時候出現錯誤,通常是因為前一個操作出現了錯誤,接下來的一系列操作都會出現
IBV_WC_WR_FLUSH_ERR的錯誤。
(3)錯誤碼為13(IBV_WC_RNR_RETRY_EXC_ERR ),這種錯誤一般是因為本地post數據過快。在infiniband傳輸數據過程中,接收端首選需要注冊內存并ibv_post_recv將此內存放入receive queue中然后發送端才能發送數據,如果接受端來不及完成這些操作發送端就發送數據,就會出現上述錯誤。
IB專業術語
-
處理器節點(processor Node):一組或多組處理器以及其內存,并通過主機通道適配器(HCA)與IBA光纖連接,每個HCA都有一個或多個端口;
-
端口(port):IBA設備與IBA鏈路連接的雙向接口;
-
鏈路(link):用于兩臺IBA設備的兩個端口間的雙向高速連接。具體應用中以serdes實現,單條鏈路的傳輸速率可達2.5Gb/s,250MB/s的吞吐率(由于serdes中8b/10b的原因)。此外,還可以用4條或12條鏈路,達到1GB/s和3GB/s的吞吐率;
-
通道適配器Channel Adapter(CA):書中沒有具體介紹,本人認為CA類似于網卡類設備。
每個CA port在配置時就具有唯一地址,當一個CA必須發送信息或者讀取信息時,首先需要發送一個請求報文,該報文帶有destination port ID,通過交換機和路由器的幫助,CA最終抵達目標CA。所以說終端必然是CA而不是交換機或路由器,CA是真正的操控者,交換機和路由器只是維護流量通道的。
- IO單元與IO控制器(IOU and IOC):IOU的組成包括,連接到IBA的目標通道適配器;一個或多個IO控制器提供的IO接口,其實現形式會是一個大量的存儲矩陣;
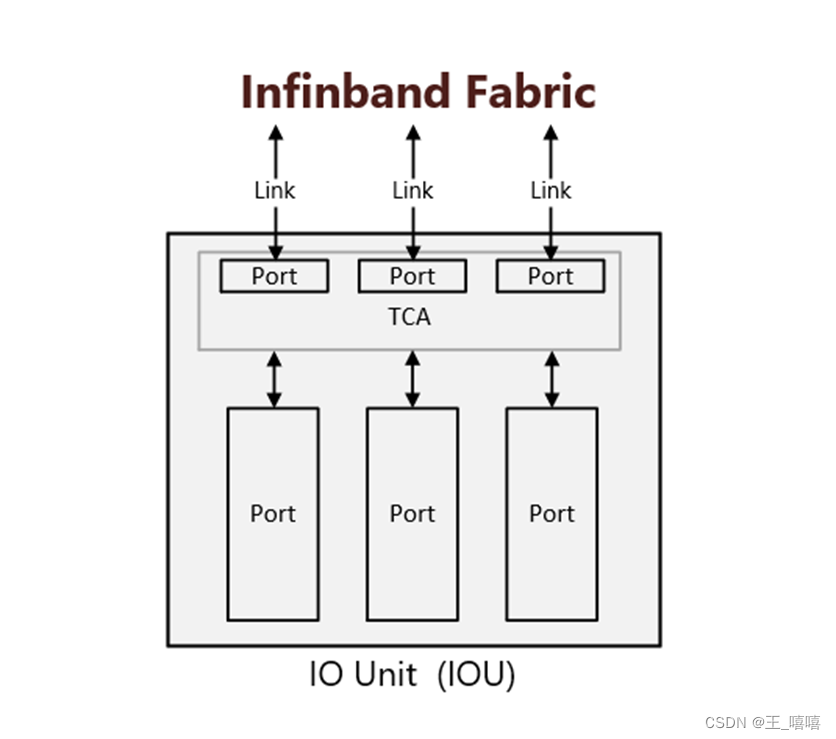
- 子網(subnet)一些有相同子網ID和相同的子網管理器的端口和鏈路的集合。
(1)子網管理器(SM)會在子網啟動時發現所有設備,配置它們,并在后續周期性檢查子網的拓撲結構是否被修改;
(2)在配置過程中,子網管理器會為每個端口配置一個獨有的本地ID和一個相同的子網ID,用以標識子網和端口位置;
(3)能交換數據包的所有的CA、路由器端口以及交換機端口都可以被叫做在同一個子網下;
(4)子網間可以通過路由器進行相互連接。
報文基本知識
報文是用來在兩個CA之間發送請求(request)或者響應(response)信號,一個報文的有效荷載(payload)部分最大可以包含4KB數據。CA如果需要發送的報文大于此長度,需要對此進行切分,分為多個包傳輸。每個報文分為payload、路由報文頭(header)、CRC校驗等,其中header包含以下內容:
本地路由頭部(LRH):包括目標端口本地ID(DLID)和源端口本地ID(SLID)。
兩者都占據16-bits,前者用來表示報文通過交換機需要到達的子網目的地端口;后者用來表示報文源頭的子網ID。
全局路由頭部(GRH):包括目標端口全局ID(DGID)和源端口全局ID(SGID)。
兩者都占據128-bits,高64-bits表示CA端口的子網ID,低64-bits表示端口的全局唯一ID(GUID)。
注意:GRH和LRH的區別主要在于,LRH是本地ID,報文在通過交換機進行傳輸時使用LRH,源端口和目標端口在同一子網下;而GRH是全局ID,報文通過IB光纖傳輸時需要GRH,源端口和目標端口在不同子網下。
基礎傳輸頭部(BTH):包括Opcode、DestQP和PSN;
Opcode表示報文操作類型;DestQP表示對端CA的目標QP(Queue Pair,是IB協議中信息傳輸的重要機制,在后續篇章中會介紹);PSN(Packet Sequence Number)占24-bits ,表示報文序列號,可以用于報文順序檢查和報文重傳。

報文傳輸類型
IB協議中的消息傳遞是建立在CA間的,其本質是CA間的內存空間進行數據交換。
三類消息傳輸:
- 從本地CA的內存傳輸信息到目標CA的內存;
- 從目標CA的內存讀取信息,并存儲在本地CA的內存中;
- 對目標CA的內存執行原子操作(讀/改/寫),并將返回的數據存儲在本地CA的內存。
1.向對端CA內存寫信息,分為兩種情況:
信息發送操作:請求信息不會通知CA數據該寫到哪塊內存中,而是對端CA自行決定數據的存放地址;
RDMA寫操作:請求報文會指定數據需要寫到對端CA的哪塊內存中,報文包括了有效荷載,請求報文的內存起始地址、報文長度和允許該RDMA寫操作的一個密鑰。
2.從對端CA內存中讀取信息:
CA向對端CA發出讀指定內存中數據的請求,對端CA接收該請求后,會返回一個或多個響應報文,請求端將返回報文中的數據存儲到指定內存中。
3.原子操作:IBA中分為以下兩種原子操作
原子讀取和加法操作:收到請求后,目標CA從其本地的指定內存中讀取數據,將Add值與讀取數據相加,并將結果寫回本地內存。目標CA將讀回的初始值以原子響應包的形式返回給請求端CA。收到響應數據包后,請求端CA將讀數據寫入自己的本地內存;
原子比較和交換操作:收到請求后,目標CA從其本地的指定內存中讀取數據,將讀取的數據與Compare值比較,若相等,將值寫入指定位置,返回的響應操作與上述加法原子操作一致。
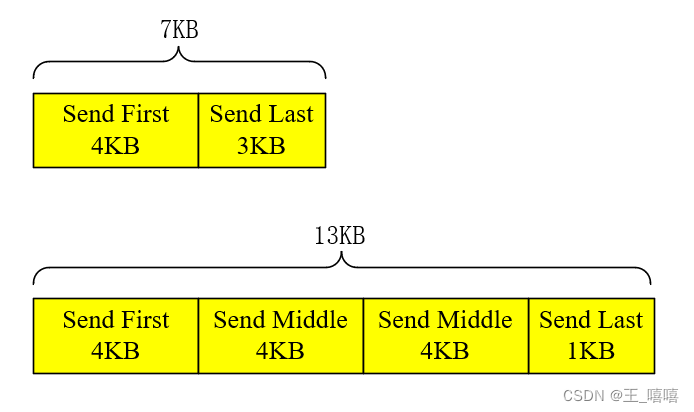
Single packet & Multiple packet
? ?IBA標準中最大包的長度限制為4KB,大約4KB的信息并非不能傳輸,而是需要拆分為***多包傳輸(multiple packet)***。
如果信息總長在4KB~8KB,multiple packet將分為***Send First操作***與***Send Last操作***;
如果信息總長大于8KB,將分為***Send First***、Send Middle***和***Send Last操作,其中,非第一包和最后一包的數據都為Send Middle操作。
? ?具體如下示意圖:
交換器和路由器規則
當一個請求報文由CA發送后,會有以下兩種情況:
- 源CA和目標CA直接連接:這種情況下,報文通過唯一鏈路,對頭部中的DLID信息解碼后直接找到目標CA port,目標CA接受請求后,并作出對應處理;
- 源CA和目標CA非直接連接:請求報文不能直接抵達目標CA,所以其需要先前往交換機或者路由器的port。
交換機規則:負責在同一子網內報文的路由,根據DLID查找交換機內部的轉發表(由軟件在啟動階段配置),確定報文需要從交換機的哪個端口輸出。(一個報文在抵擋目標CA前可能需要經過多個交換機)
路由器規則:當源CA和目標CA不在同一子網下,請求報文會帶有GRH。交換機會在子網下不斷路由報文,直到抵擋路由器的一個port,然后路由器根據GRH:DGID確定目標CA在哪個子網下,與交換機類似,路由器內部存在路由表。(一個報文在抵擋目標CA前可能需要經過多個交換機)
屬性與管理器
設備屬性
?? 所有IBA設備都有一系列屬性(中繼器因為在軟件上不可見,所以不存在屬性),這些屬性由于各類原因可以被讀寫操作,具體屬性如下:
- 查詢是否有IBA設備存在;
- 查詢IBA設備類型(CA、交換機、路由器);
- 確定設備的當前狀態;
- 確定設備上的端口數;
- 控制設備的運行屬性;
誰訪問這些屬性?
IBA中定義了一系列管理器,每個管理器都負責IBA設備中操作的各方面:
- 子網管理器 Subnet Manager(SM);
- 性能管理器 Performance Manager(PM);
- 設備管理器 Device Manager(DM);
- 交互管理器 Communications Manager(CM);
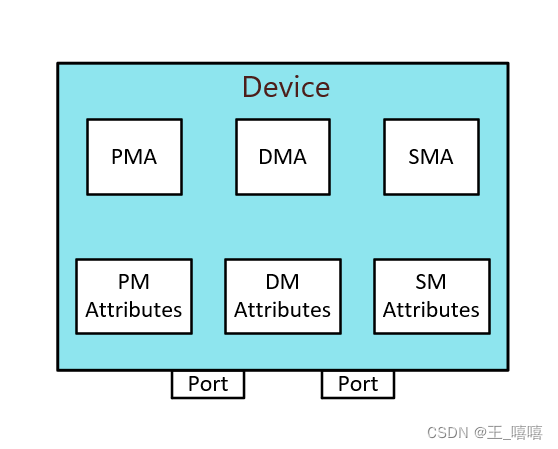
管理代理
每個IBA設備包含了一系列管理代理,每個管理代理處理各自的管理器發出的屬性訪問請求。
當設備中的MA收到來自其各自管理器的屬性訪問請求報文時,它會對指定的屬性執行所請求的操作,并在大多數情況下以響應報文的形式返回結果。
管理器使用特殊的數據包(MAD)
?? 各種管理器使用管理數據報(MAD)的特殊數據包來請求對設備屬性執行操作(即方法)。請求MAD具有以下基本特征:
- MAD消息完全包含在單個數據包的數據有效載荷字段中,數據有效載荷字段總是包含精確的256字節。
- 管理類:標識發出數據包的管理器,標識處理請求MAD的設備中的管理代理。
- 方法:指定目標管理代理要對指定屬性執行的操作類型。例如,Get方法執行屬性讀取操作,而Set方法執行屬性寫入操作。
- 屬性ID:指定要執行的屬性(例如,讀或寫)。
- 屬性修改器:對于許多屬性/方法組合并不需要,指定有關目標屬性的附加信息。例如,如果管理員的目標是CA、路由器或交換機上的portinfo屬性,則修改器指定目標端口號。
- 數據區域:內容取決于方法和屬性。
- 如果“方法”是“Set”操作,則數據區域包含要寫入指定屬性的數據;
- 如果"方法"是"Get"操作,數據區內容在請求MAD中是未定義的,但是在設備返回的相應響應MAD中包含被請求屬性的內容。
IBA中的屬性不一定是單一數據格式的,可以是一個選項,可以是一張表,也可以是多種元素組成的數據結構。
IB核心傳輸引擎Queue Pair
雙向信息傳輸引擎QP
?? 在每個CA中會實現若干QP,數量最多可達16M(2^24)QPs,之所以叫Queue pair,是因為每個QP由兩個隊列組成,發送隊列(Send Queue)和接收隊列(Receive Queue)。
-
發送隊列:軟件將消息傳輸請求(WQE)發送到SQ,執行時,SQ將出站消息傳輸請求發送到對端QP的RQ;
-
接收隊列:軟件將工作請求(WQE)發送到此隊列,以處理通過對端QP的SQ傳輸到RQ的不同類型的入站消息傳輸請求。
-
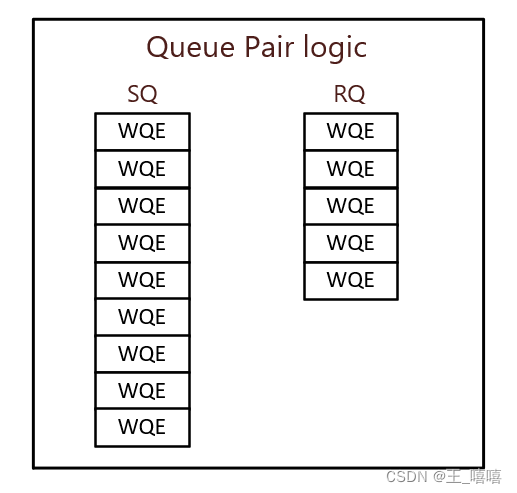
請求包與響應包:
QP的SQ會以一系列的一個或多個請求包的形式向遠端QP的RQ傳輸消息傳輸請求;
根據QP類型,遠端QP的RQ可以通過向對應的SQ發送一系列的一個或多個響應數據包來響應接收到的消息傳輸請求。
報文序列號PSN:
?? SQ生成的每個請求包都包含一個PSN,收到請求數據包后,RQ將驗證數據包是否與期望的PSN (ePSN)一致。
?? 與之對應的,RQ生成的每個響應包都包含一個PSN,該PSN將它與從遠端SQ接收到的請求包關聯,SQ收到每個響應包時, 將驗證包的PSN是否與之前發出的請求相關聯。
QP服務類型
?? 在IBA中,主要根據信息的傳播需求、場景不同,以及對信息重要性的不同,分為以下幾種類型:
- 可靠連接 RC(Reliable Connected)QP;
- 非可靠連接 UC(UnReliable Connected)QP;
- 可靠數據報 RD (Reliable Datagram) QP;
- 非可靠數據報 UD (Unreliable Datagram) QP;
- 類似與隧道包,對非IBA協議的包進行封裝的 RAW QP。
每種服務類型的具體區別與特點將在后續專題中進行介紹:占位符。
獨立于OS的動作層verb API
??軟件接口與HCA接口是非直接關聯的,軟件應用的調用稱為verb layer。可以將verb layer想象成松散的API (可以看作函數調用),并由每個操作系統供應商以特定方式實現。對于每個verb,規范定義了:
- 輸入的參數
- 返回結果,輸出的參數
- verb的操作類型
verb layer可以通過訪問HCA的硬件接口(例如寄存器組)來完成期望的動作,verb layer還有以下特性:
- 需要時會調用OS。例如它可以調用OS的內存管理器,為verb或者HCA的使用分配物理內存;
- 必須通過verb調用請求的操作,才能訪問主存。例如,在特定的操作系統環境中,軟件應用可以在主存中構建一個消息傳輸工作請求(WR),然后執行Post Send Request verb調用,將WR發布到QP的SQ中進行處理。它將在主存中提供WR的起始地址作為Post Send Request verb的輸入參數之一,然后verb將訪問主存以讀取WR,將WR發送到目標QP的SQ。
裝載QP操作特征的QP Context
在使用QP進行發送或接收信息前,軟件會先創建一個QP,并提供一些其在發送、接收過程中需要用到的特征。QP Context大致會包含以下內容(每個內容的具體含義暫不展開介紹):
- 本地端口號(在QP創建時確定);
- QP類型;
- SQ開始PSN(SQ發送的第一包插入開始PSN,后續實時更新current PSN);
- RQ期望PSN;
- 最大payload尺寸(0.25KB、0.5KB、1KB、2KB、4KB,也被稱作path maximum transfer unit,PMTU);
- 目標端的本地ID;
- 期望的本地QoS;
- 報文注入延遲(因為鏈路的寬度不同,內部報文延遲也不同,防止快速鏈路的流量超過較慢鏈路的流量,定義了強制觀測延遲);
- 本地應答超時(指定時間內沒收到ack報文,即為應答超時,需要重發對應報文);
- Ack timeout/丟包重傳計數;
- RNR重傳計數;
- 源端口本地ID;
- 全局的源端/目標端地址;
QP傳輸示例
本文以RC服務類型的QP舉例,詳細描述了QP是如何傳輸一個數據包的;
??
假設QP已創建,且:
- SQ PSN起始地址在CA X為100,CA Y為2000;
- QP都為剛創建完成狀態;
- RQ 期望PSN CA X為2000,CA Y為100;
- 需要發送的信息為5KB,報文payload最大尺寸限制為2KB;
- Ack重傳計數為7,RNR重傳計數為7;
- Source CA與destination CA在同一子網下;
注意:這里只舉例了報文第一包發送與響應過程,后續包的過程稍有不同,但整體類似。
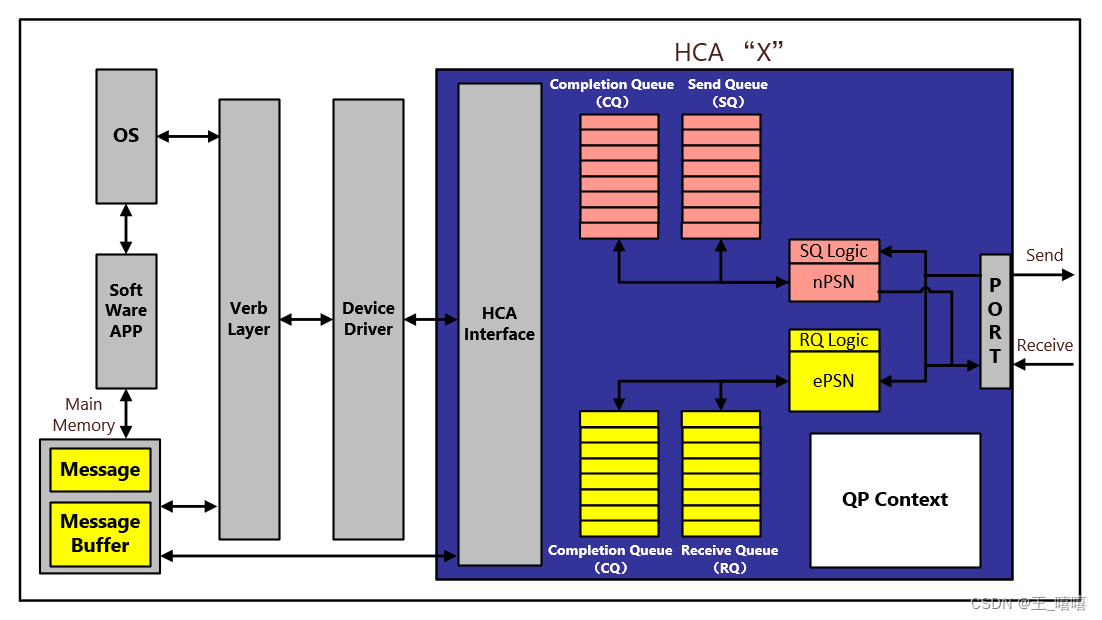
發送第一個請求報文
-
SQ開始處理頂層條目,WQE指定一個多包發送操作,將5KB消息從HCA本地內存發送到對端CA的QP;
-
SQ檢查QP Context中的PMTU來決定請求報文的最大數據大小,在本例中,SQ會選擇前2KB數據作為第一個請求報文發送;
-
SQ在第一包的Opcode內容中填入Send first,向對端RQ表示,該包是第一發送包,并填入PSN=100,同時根據QP context內容設置目標QP;
注:RQ在接收到send last的報文前,都不知道報文的真實長度; -
SQ將請求包轉發到端口X進行傳輸時,向端口提供基本LID地址的偏移量,以替代包的SLID;
-
SQ將第一個請求包內的DLID設置為目標CA端口的QP的DLID,DLID來自QP Context;
-
SQ根據QP context內容設置服務等級(Service Level);
-
如果請求操作中存在全局ID,SQ需要在第一包中插入GRH(但在本例中不需要);
-
Send操作的第一個請求包被發送到網絡層,然后轉發到HCA端口(X)的鏈路層。此外,SQ還做以下工作:
a) 將nPSN從100更新到101,這是將在發送的下一個請求包中插入的PSN。
b) 等待收到“Send First”請求包的對應Ack包。
c) 形成下一個請求包發送到鏈路層進行傳輸。 -
當從網絡層接收到第一個報文后,端口的鏈路層將:
a) 在端口的base LID上加入偏移,并將此LID插入在請求報文中的SLID中;
b) 如果目標CA和源CA不在同一子網下,會生成一個128-bits的SGID;
c) 在配置過程中,SM設置了端口的SLtoVLMappingTable屬性表,將16個可能的SL值映射到特定的鏈路層傳輸緩沖區。SM還建立了一個仲裁方案,為每個傳輸緩沖區分配一個重要級別。定義了傳輸緩沖區以什么順序將數據包傳輸到端口的物理層;
d) 請求包被發布到鏈路層選擇的傳輸緩沖上;
e) 當該VL傳輸緩沖區進行報文傳輸時,端口的鏈路層將請求報文轉發給端口的物理層進行傳輸。數據包的VL字段標識了各自的VL接收緩沖區,該緩沖區將在與該端口連接的物理鏈路的另一端接收數據包。 -
從X鏈路層端口流出的請求報文將根據serdes的規范,編碼為10-bits的串行流;
-
請求包經過一個或多個鏈路,最后到達目標端口。每個交換機查找內部轉發表,并根據包內的DLID確認向何處轉發;
-
目標QP端口對從物理層收到的數據解串行化,恢復8-bits數據流,并傳遞給鏈路層;
-
鏈路層解析包內的DLID項,確定數據前往哪個端口,并將數據傳輸到數據包指示的VL接收緩沖區,緊接著,請求包轉發至網絡層,網絡層根據DestQP項將數據傳遞到對應RQ;
-
RQ將請求包的PSN與ePSN比較,確定是否出現丟包(如果PSN為之前請求包范圍內的PSN,代表是一個重復包,不需要響應其動作,但要回復ack);
-
RQ將檢查包的opcode,確認是否需要WQE將報文寫入CA Y的本地內存中。如果opcode是send或RDMA write,WQE則需要完成此動作。如果RQ當前沒有發布WQE,則需要返回對端SQ一個RNR NAK包;
-
進一步確認opcode,本例中為send first,不能是send middle,send last;
-
RQ返回一個ack包,并使用頂端的WQE確認將payload寫入本地內存何處;
-
Payload使用散列緩沖鏈表寫入CA本地內存中,同時RQ向WQE更新下一包需要寫入的內存地址;
-
最后,RQ更新期望PSN(ePSN=101);
第一個ack包返回
當RQ成功接收send first包,返回ack包的過程如下:
- RQ將ack包發送到網絡層,然后轉發至端口的鏈路層;
- Ack包不包含payload,但是包含opcode和確認擴展傳輸頭(AETH)字段,opcode表示這是一個Ack報文,AETH表示Ack報文的類型:positive Ack或negative Ack (Nak)。如果是Nak包,Nak的原因也會被指出;
- Ack的目標QP會被寫入QPN;
- Ack包中的SL和請求包中的SL一致,SLID和DLID與請求包中相反;
- CA Y的端口根據SL查表確定,Ack包需要發布到哪個VL傳輸緩存;
- 當該VL緩存區傳輸時,將Ack包從鏈路層傳給對應的物理層;
- 和之前物理層的處理一樣,數據將被串行化,通過傳輸介質后,由另一端的物理層解串;
- 對端鏈路層解析包中的DLID,確定該傳輸到哪個端口;
- 鏈路層將接收到的ack包放至對應的VL接收緩存區,進一步轉發至網絡層;
- 網絡層將ack包發送給對應SQ,QP與上一步發送請求報文的QP一致;
- SQ驗證是否是ack包,檢查PSN是否和send first包的PSN一致;
字體
滾滾滾color=#0099ff size=6 face="黑體"灌灌灌灌
滾滾滾color=#0099ff size=6 face="黑體"灌灌灌灌
滾滾滾color=#0099ff size=6 face="黑體"灌灌灌灌
滾滾滾color=#0099ff size=6 face="黑體"灌灌灌灌
滾滾滾滾滾滾熱熱熱太陽眼鏡
紅:255,0,0 #FF0000
橙: 255,125,0 #FF7D00
黃:255,255,0 #FFFF00
綠:0,255,0 #00FF00
藍:0,0,255 #0000FF
靛: 0,255,255 #00FFFF
紫: 255,0,255 #FF00FF加粗樣式
??:基于隨機采樣的數值計算與模擬技術)
工業核心板硬件說明書)


原理與使用細節)














