目錄
引言
1 Hive小文件問題概述
1.1 什么是小文件問題
1.2 小文件產生的原因
2 Hive小文件合并機制
2.1 hive.merge.smallfiles參數詳解
2.2 小文件合并流程
2.3 合并策略選擇
3 動態分區與小文件問題
3.1 動態分區原理
3.2 動態分區合并策略
3.3 動態分區合并流程
4 高級調優技巧
4.1 基于存儲格式的優化
4.2 定時合并策略
4.3 寫入時優化
5 案例分析
5.1 日志分析案例
5.2 數據倉庫ETL案例
6 監控與評估
6.1 小文件檢測方法
6.2 性能評估指標
7 總結
7.1 Hive小文件處理
7.2 參數推薦配置
引言
在大數據領域,Apache Hive作為構建在Hadoop之上的數據倉庫工具,被廣泛應用于數據ETL、分析和報表生成等場景。然而,隨著數據量的增長和業務復雜度的提升,Hive性能問題逐漸顯現,其中小文件問題尤為突出。本文將深入探討Hive中的小文件問題及其解決方案,特別是通過參數hive.merge.smallfiles進行小文件合并和動態分區合并的技術細節。
1 Hive小文件問題概述
1.1 什么是小文件問題
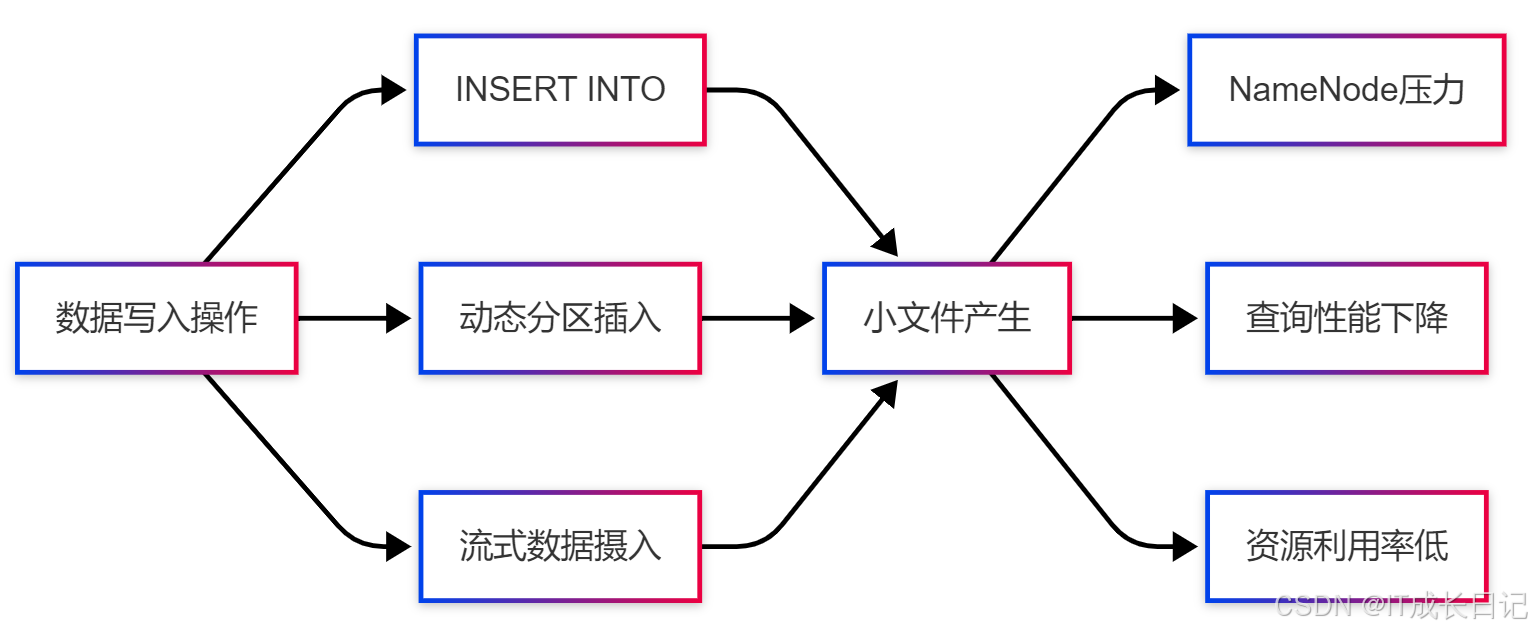
小文件問題指的是在Hadoop分布式文件系統(HDFS)中存儲了大量遠小于HDFS塊大小(通常為128MB或256MB)的文件。這些小文件會導致:
- NameNode內存壓力:HDFS中每個文件、目錄和塊都會在NameNode內存中占用約150字節的空間
- MapReduce效率低下:每個小文件都會啟動一個Map任務,造成任務調度開銷遠大于實際數據處理時間
- 查詢性能下降:Hive查詢需要打開和處理大量文件,增加了I/O開銷
1.2 小文件產生的原因
在Hive中,小文件通常由以下操作產生:
- 頻繁執行INSERT語句:特別是INSERT INTO和動態分區插入
- 動態分區:當分區字段基數(cardinality)很高時,會產生大量小文件
- 流式數據攝入:如Flume、Kafka等實時寫入小批量數據
- 過度分區:分區粒度過細導致每個分區數據量很小
2 Hive小文件合并機制
2.1 hive.merge.smallfiles參數詳解
Hive提供了hive.merge.smallfiles參數來控制小文件合并行為:
-- 開啟小文件合并
SET hive.merge.mapfiles = true; -- 合并Map-only作業輸出的小文件
SET hive.merge.mapredfiles = true; -- 合并MapReduce作業輸出的小文件
SET hive.merge.smallfiles.avgsize = 16000000; -- 平均文件大小小于該值會觸發合并
SET hive.merge.size.per.task = 256000000; -- 合并后每個文件的目標大小參數解釋:
- hive.merge.mapfiles:控制是否合并Map-only任務輸出的文件,默認false
- hive.merge.mapredfiles:控制是否合并MapReduce任務輸出的文件,默認false
- hive.merge.smallfiles.avgsize:當輸出文件的平均大小小于此值時,啟動合并流程,默認16MB
- hive.merge.size.per.task:合并操作后每個文件的目標大小,默認256MB
2.2 小文件合并流程

合并過程詳細說明:
- 評估階段:作業完成后,Hive計算輸出文件的平均大小
- 決策階段:如果平均大小小于閾值,則觸發合并流程
- 執行階段:啟動一個額外的MapReduce任務讀取所有小文件
- 寫入階段:按照目標大小將數據重新寫入新文件
- 清理階段:合并完成后刪除原始小文件
2.3 合并策略選擇
Hive支持兩種合并策略:
- 合并為更大的文件:
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
SET hive.merge.size.per.task=256000000;
SET hive.merge.smallfiles.avgsize=16000000;- 合并為ORC/Parquet的塊(針對列式存儲):
SET hive.exec.orc.default.block.size=256000000;
SET parquet.block.size=256000000;3 動態分區與小文件問題
3.1 動態分區原理
動態分區允許Hive根據查詢結果自動創建分區
- 語法
INSERT INTO TABLE employee_partitioned
PARTITION(dept, country)
SELECT name, salary, dept, country
FROM employee;動態分區優勢:
- 簡化了多分區寫入操作
- 避免了手動指定每個分區
動態分區問題:
- 容易產生大量小文件
- 當分區字段基數高時問題更嚴重
3.2 動態分區合并策略
針對動態分區的小文件問題,Hive提供了專門的優化參數:
-- 開啟動態分區
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;-- 動態分區優化
SET hive.merge.tezfiles=true; -- 在Tez引擎上合并文件
SET hive.merge.sparkfiles=true; -- 在Spark引擎上合并文件
SET hive.exec.insert.into.multilevel.dirs=true; -- 支持多級目錄插入3.3 動態分區合并流程

優化技巧:
- 限制最大動態分區數:
SET hive.exec.max.dynamic.partitions=1000;
SET hive.exec.max.dynamic.partitions.pernode=100;- 分區裁剪:在查詢前過濾不必要分區
SET hive.optimize.dynamic.partition.prune=true;- 合并層級控制:對于多級分區,可以控制合并粒度
SET hive.merge.level=partition; -- 按分區合并4 高級調優技巧
4.1 基于存儲格式的優化
不同存儲格式對小文件處理有不同影響:
| 存儲格式 | 小文件處理能力 | 合并效率 | 適用場景 |
| TEXT | 差 | 高 | 原始數據 |
| ORC | 中 | 中 | 分析查詢 |
| Parquet | 中 | 中 | 分析查詢 |
| AVRO | 好 | 低 | 序列化 |
- ORC格式優化示例:
CREATE TABLE optimized_table (...
) STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY","orc.create.index"="true","orc.stripe.size"="268435456", -- 256MB"orc.block.size"="268435456" -- 256MB
);4.2 定時合并策略
對于無法避免小文件產生的場景,可以設置定時合并任務:
- 使用Hive合并命令:
ALTER TABLE table_name CONCATENATE;- 使用Hadoop Archive(HAR):
hadoop archive -archiveName data.har -p /user/hive/warehouse/table /user/hive/archive- 自定義合并腳本:
# 示例
for partition in partitions:if avg_file_size(partition) < threshold:merge_files(partition, target_size)4.3 寫入時優化
在數據寫入階段預防小文件產生:
- 批量插入:減少INSERT操作頻率
- 合理設置Reduce數量:
SET mapred.reduce.tasks=適當數量;- 使用CTAS代替INSERT:
CREATE TABLE new_table AS SELECT * FROM source_table;5 案例分析
5.1 日志分析案例
- 場景:每日用戶行為日志,按dt(日期)、hour(小時)兩級分區
- 問題:每小時一個約5MB的小文件
- 解決方案:
-- 建表時指定合并參數
CREATE TABLE user_behavior (user_id string,action string,...
) PARTITIONED BY (dt string, hour string)
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY","hive.merge.mapfiles"="true","hive.merge.smallfiles.avgsize"="64000000", -- 64MB"hive.merge.size.per.task"="256000000" -- 256MB
);-- 插入數據時控制動態分區
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions.pernode=100;INSERT INTO TABLE user_behavior
PARTITION(dt, hour)
SELECT user_id, action, ..., dt, hour
FROM raw_log;5.2 數據倉庫ETL案例
- 場景:每日全量同步上游數據庫表
- 問題:全表掃描產生大量小文件
- 解決方案:
-- 使用CTAS創建中間表
CREATE TABLE temp_table STORED AS ORC AS
SELECT * FROM source_table;-- 使用DISTRIBUTE BY控制文件分布
SET hive.exec.reducers.bytes.per.reducer=256000000;INSERT OVERWRITE TABLE target_table
SELECT * FROM temp_table
DISTRIBUTE BY FLOOR(RAND()*10); -- 隨機分布到10個Reducer-- 定期合并歷史分區
ALTER TABLE target_table PARTITION(dt='20230101') CONCATENATE;6 監控與評估
6.1 小文件檢測方法
- HDFS命令檢查:
hdfs dfs -count -q /user/hive/warehouse/db/table- Hive元數據查詢:
SELECT partition_name, file_count, total_size
FROM metastore.PARTITIONS p
JOIN metastore.TBLS t ON p.TBL_ID = t.TBL_ID
WHERE t.TBL_NAME = 'table_name';- 自定義監控腳本:
# 檢查分區文件數量和大小分布
for part in partitions:files = list_files(part)if len(files) > threshold:alert_small_files(part)6.2 性能評估指標
| 指標 | 優化前 | 優化后 | 測量方法 |
| 文件數量 | 1000 | 10 | hdfs dfs -count |
| NameNode內存使用 | 高 | 低 | NameNode UI |
| 查詢響應時間 | 慢 | 快 | EXPLAIN ANALYZE |
| 任務執行時間 | 長 | 短 | JobHistory |
7 總結
7.1 Hive小文件處理
預防為主:
- 合理設計分區策略
- 控制動態分區數量
- 使用適當Reduce數量
合并為輔:
- 啟用hive.merge.smallfiles
- 定期執行合并操作
- 根據存儲格式調整參數
監控持續:
- 建立小文件監控告警
- 定期評估合并效果
- 根據業務變化調整策略
7.2 參數推薦配置
-- 通用小文件合并配置
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
SET hive.merge.smallfiles.avgsize=64000000; -- 64MB
SET hive.merge.size.per.task=256000000; -- 256MB-- 動態分區優化配置
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions=2000;
SET hive.exec.max.dynamic.partitions.pernode=100;-- 存儲格式優化
SET hive.exec.orc.default.block.size=268435456; -- 256MB
SET parquet.block.size=268435456; -- 256MB通過合理配置這些參數可以顯著改善Hive中的小文件問題,提升集群整體性能和查詢效率。





)


)


)

:股票價格模型、利率模型的構建)
:MCP多服務器協作架構)

![[算法學習]——通過RMQ與dfs序實現O(1)求LCA(含封裝板子)](http://pic.xiahunao.cn/[算法學習]——通過RMQ與dfs序實現O(1)求LCA(含封裝板子))

)
