一、引言:數據庫開發的 “效率革命” 正在發生
在某互聯網金融公司的凌晨故障現場,資深 DBA 正滿頭大汗地排查一條執行超時的 SQL—— 該語句涉及 7 張核心業務表的復雜關聯,因索引缺失導致全表掃描,最終引發交易系統阻塞。這類場景在傳統數據庫開發中屢見不鮮:據 Gartner 調研,開發人員 43% 的時間消耗在 SQL 編寫與調優,32% 的生產故障源于 SQL 性能問題,而跨數據庫方言適配更讓開發效率降低 40% 以上。
隨著 AIGC 技術的成熟,數據庫 AI 助手應運而生。阿里 Chat2DB、微軟 SQLFlow、開源項目 DB-GPT 等工具的出現,正在重塑數據庫開發范式:某中型電商實測顯示,AI 助手使 SQL 編寫效率提升 68%,跨庫遷移成本下降 75%,慢 SQL 優化周期從 4 小時縮短至 15 分鐘。本文將從技術原理、工具測評、實戰案例、生態構建四個維度,深度解析數據庫 AI 助手如何重構開發生產力。
二、傳統數據庫開發的 “不可能三角” 困境
2.1 技術壁壘:從語法差異到復雜邏輯的層層關卡
(1)跨庫方言的 “翻譯鴻溝”
| 數據庫 | 分頁語法 | 字符串模糊匹配 | 序列生成方式 | ||||
|---|---|---|---|---|---|---|---|
| MySQL | LIMIT OFFSET | LIKE %?% | AUTO_INCREMENT | ||||
| PostgreSQL | LIMIT OFFSET | ILIKE %?% | SERIAL8 | ||||
| Oracle | ROWNUM <= ? | LIKE '%' | ? | '%' | CREATE SEQUENCE | ||
| SQL Server | OFFSET ? ROWS FETCH NEXT | LIKE '%' + ? + '%' | IDENTITY(1,1) |
某跨境電商需同時維護 MySQL(主庫)、PostgreSQL(日志庫)、Oracle(舊系統),開發團隊需為同一查詢編寫 3 套 SQL,僅語法適配就消耗 20% 的開發時間。
(2)復雜查詢的 “知識壁壘”
- 多表關聯:超過 5 張表的 JOIN 操作,開發人員平均需要查閱 3 次文檔,出錯率達 28%
- 窗口函數:
ROW_NUMBER()/RANK()/DENSE_RANK()的適用場景混淆,導致排序邏輯錯誤 - CTE 遞歸:在物料清單(BOM)查詢等場景中,遞歸 CTE 的語法誤用可能引發性能災難
2.2 經驗依賴:性能調優的 “黑箱” 困境
(1)索引優化的 “試錯迷宮”
傳統索引優化流程:
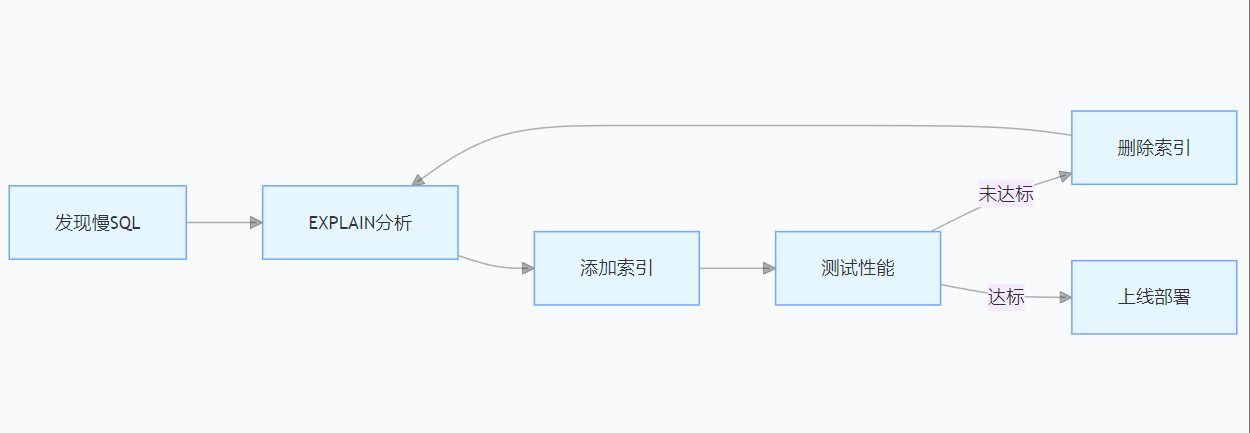
某零售企業曾為訂單查詢語句嘗試 5 次索引組合,耗時 2 天,最終通過 AI 助手一次生成最優索引。
(2)執行計劃的 “經驗門檻”
解讀 EXPLAIN 輸出需要掌握:
- 訪問類型(ALL/INDEX/Range/Ref)的性能差異
- 關聯算法(Nested Loop/Hash Join/Merge Join)的適用場景
- 成本計算(cost 值的構成與優化方向)
初級工程師誤判率超過 60%,導致優化方向南轅北轍。
2.3 協作割裂:數據需求的 “失真傳遞”
業務人員與開發人員的需求溝通存在三層損耗:
- 語義轉換:“統計各地區復購率” 需轉化為 “識別 90 天內重復購買的用戶 ID”
- 字段映射:業務術語 “客戶編號” 對應數據庫字段 “cust_id”
- 邏輯細化:“復購” 需明確 “同一用戶購買同一商品” 或 “任意商品”
某教育平臺因需求理解偏差,報表開發返工率高達 45%,平均每個需求需 3.2 輪溝通。
三、主流數據庫 AI 助手技術解析與橫向測評
3.1 全鏈路智能工具:阿里 Chat2DB(企業級首選)
(1)技術架構:三層智能引擎驅動
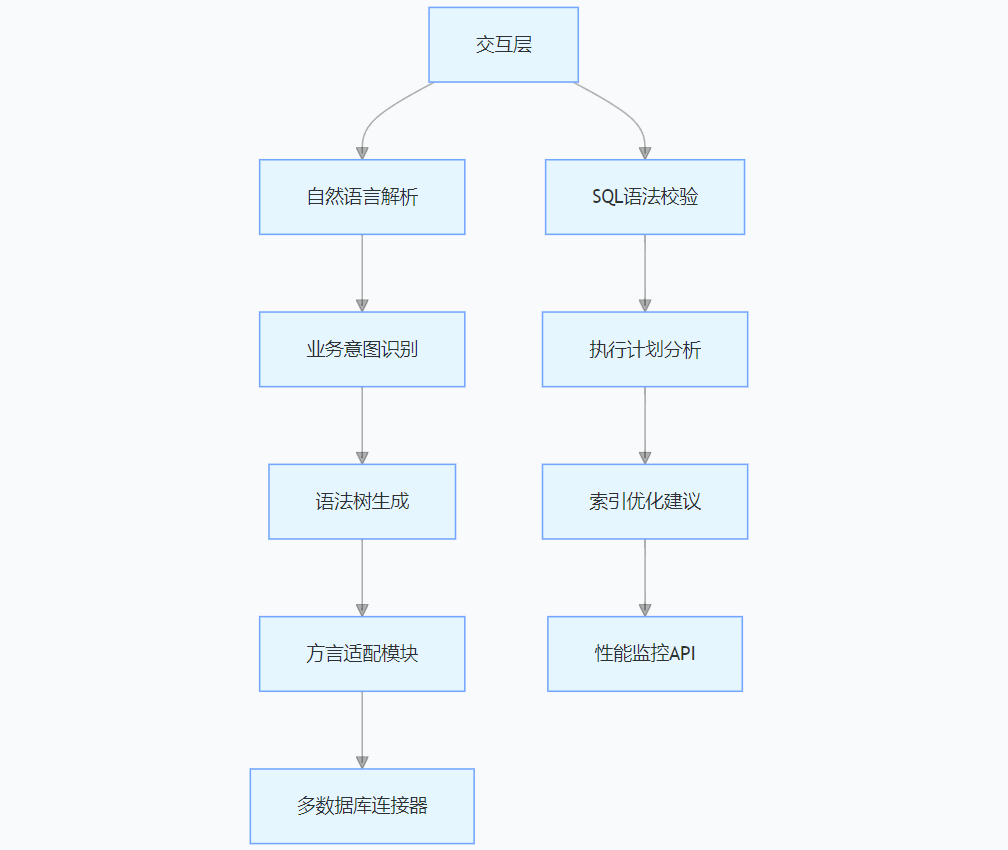
- NL2SQL 引擎:基于 T5 模型微調,支持 20 + 數據庫方言,復雜查詢生成準確率達 92%
python
# 自然語言轉SQL示例(含窗口函數) input:


)


)

???????????2025最新(六))
![[藍橋杯 2023 國 Python B] 劃分 Java](http://pic.xiahunao.cn/[藍橋杯 2023 國 Python B] 劃分 Java)








技術解析:3D重建與虛擬世界的未來)

