GET /categories/1/10?name=手機 // 按名稱過濾
GET /categories/1/10?type=電子產品 // 按類型過濾
GET /categories/1/10?name=手機&type=電子產品 // 組合過濾
- 查詢參數
@ApiOperation(value = "獲取商品分類分頁列表")@GetMapping("{page}/{limit}")public Result index(@ApiParam(name = "page", value = "當前頁碼", required = true)@PathVariable Long page,@ApiParam(name = "limit", value = "每頁記錄數", required = true)@PathVariable Long limit,@ApiParam(name = "categoryQueryVo", value = "查詢對象", required = false)CategoryQueryVo categoryQueryVo) {Page<Category> pageParam = new Page<>(page, limit);IPage<Category> pageModel = categoryService.selectPage(pageParam, categoryQueryVo);return Result.ok(pageModel);}
- CategoryQueryVo categoryQueryVo存儲查詢參數。
在基于Nacos的服務注冊與發現機制中,服務之間通過以下步驟完成數據發送:
一、服務注冊與發現階段
1. 服務提供者(service-provider)注冊到Nacos
- 動作:
服務提供者(端口8070)啟動時,向Nacos Server(端口8848)發送注冊請求,攜帶自身信息:{"serviceName": "service-provider","ip": "192.168.1.100","port": 8070,"metadata": {"version": "2018"} // 圖中標注的"2018"可能是版本號或其他元數據 } - 目的:
告知Nacos自己的存在,成為可被調用的服務實例。
2. 服務消費者(service-consumer)發現服務提供者
- 動作:
服務消費者(端口8080)向Nacos查詢服務名為service-provider的可用實例列表。
Nacos返回服務提供者的地址信息:http://192.168.1.100:8070/。
二、服務間數據發送階段
3. 消費者發起HTTP請求
- 動作:
服務消費者根據Nacos返回的地址,構造HTTP請求并發送:
或通過POST請求傳遞數據(具體方法由接口定義決定)。GET http://192.168.1.100:8070/echo?param=hello,2018
4. 提供者處理請求并返回響應
- 動作:
服務提供者接收到請求后,執行echo(string)方法處理參數:public String echo(String input) {return input.split(",")[1]; // 示例中返回"2018" } - 響應:
返回HTTP響應體:2018(即從輸入中提取的元數據)。
三、關鍵技術細節
1. HTTP協議通信
- 通信方式:
服務消費者通過HTTP協議(RESTful API)調用服務提供者。
示例:- 請求路徑:
/echo - 參數傳遞:通過URL參數(
param=hello,2018)或請求體(JSON/XML)。
- 請求路徑:
2. 服務標識解耦
- 服務名代替硬編碼IP:
消費者通過服務名(service-provider)調用服務,而非直接依賴IP地址。
優勢:- 動態擴縮容:提供者實例變化時,Nacos自動更新可用地址列表。
- 負載均衡:Nacos支持返回多個實例,消費者可輪詢或隨機選擇(需集成Ribbon等組件)。
3. 元數據(Metadata)傳遞
- 用途:
注冊時攜帶的元數據(如version=2018)可用于:- 灰度發布:根據版本號路由請求。
- 環境隔離:區分測試/生產環境實例。
調用示例:
消費者可通過元數據篩選特定實例(如請求version=2018的提供者)。
四、完整流程示例
1. 服務提供者啟動 → 注冊到Nacos(IP:8070,元數據version=2018)
2. 消費者啟動 → 向Nacos查詢service-provider地址 → 獲得http://192.168.1.100:8070/
3. 消費者發送HTTP請求 → GET http://192.168.1.100:8070/echo?param=hello,2018
4. 提供者處理請求 → 提取"2018" → 返回HTTP響應"2018"
5. 消費者收到響應 → 完成數據交互
五、擴展場景
1. 負載均衡
- 多實例場景:
若存在多個service-provider實例(如8070、8071、8072),Nacos返回所有實例地址。
消費者行為:
可結合Ribbon實現負載均衡(如輪詢、隨機選擇實例)。
2. 健康檢查
- 自動剔除故障節點:
Nacos定期檢查提供者心跳,若8070端口服務宕機,自動從列表中移除,確保消費者不會調用失效實例。
3. 動態配置
- 配置中心集成:
Nacos可管理服務配置(如超時時間、路由規則),服務重啟時自動同步最新配置。
總結
服務間數據發送的核心流程為:
注冊(Provider → Nacos)→ 發現(Consumer ← Nacos)→ 調用(HTTP請求)→ 響應。
通過Nacos解耦服務依賴,結合HTTP協議實現靈活通信,是微服務架構中高效協作的基礎。
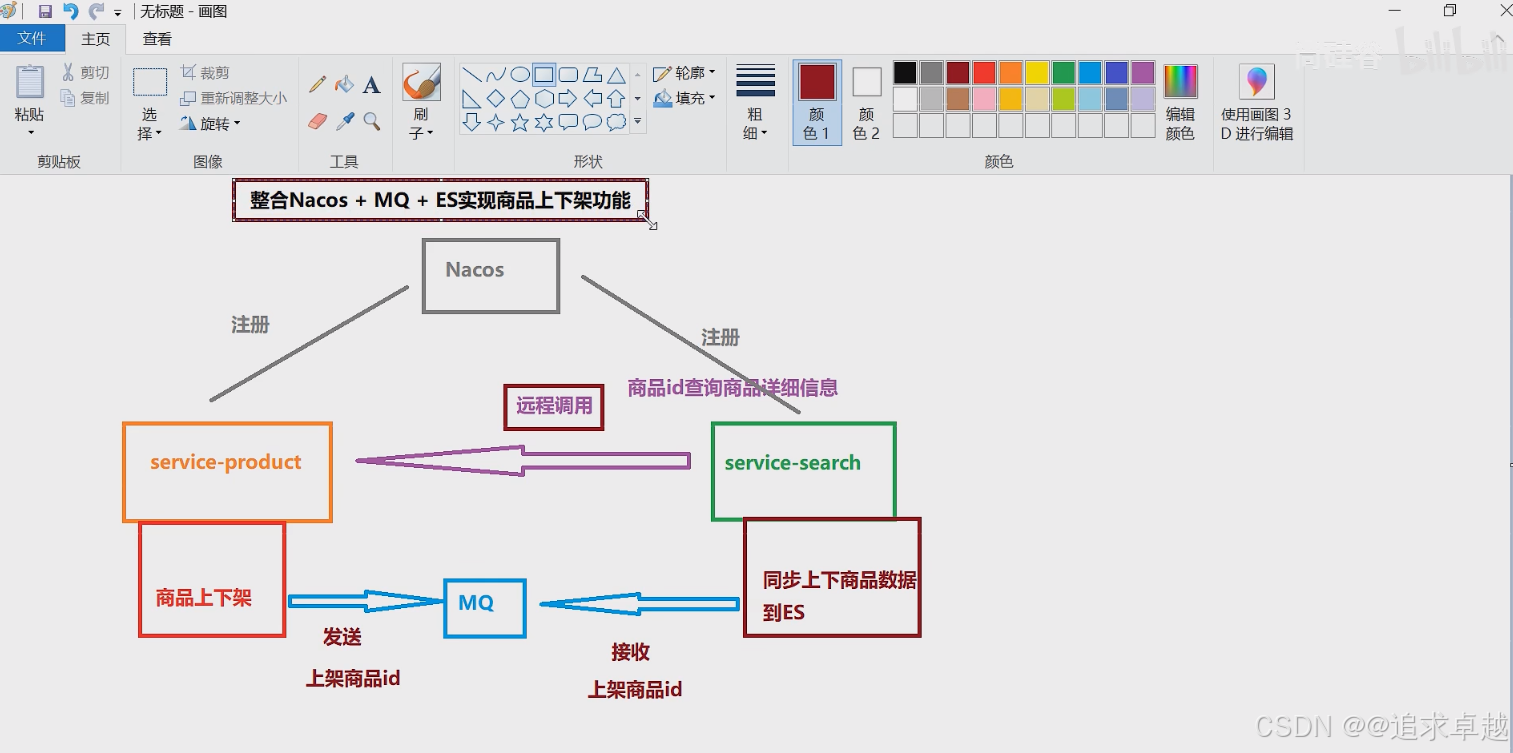
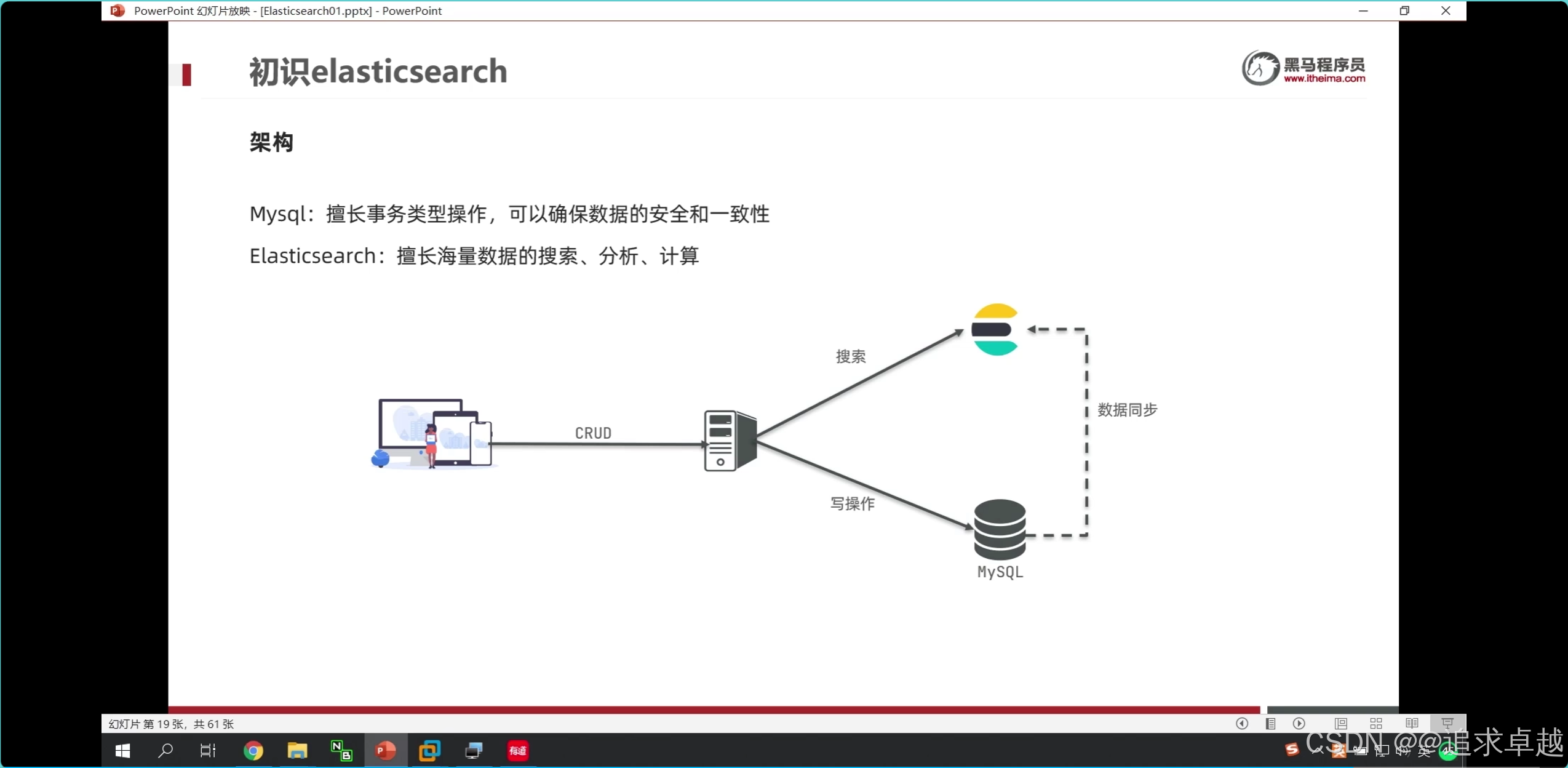
- 商品上下架過程中,修改數據庫表上下架狀態,之后通過RabbitMQ發送消息,最終實現ES中數據同步。
- ?Binding Key?:隊列綁定到交換機時設定的 ??“路由規則”??(收件規則)。
Routing Key?:生產者發送消息時指定的 ??“消息標簽”??(快遞單號)。
?匹配結果?:交換機根據兩者的匹配關系,決定消息投遞到哪些隊列。
話題交換機
- bindingkey和routingkey是可以(多個 routingKey 之間以.分割)。廣播和定向是只能一個。
- 交換機是具體的名字。routingkey是固定的名字,bingkey是可以有#。
bindkey相當于信箱的收件規則;routeingkey是消息的快遞號。
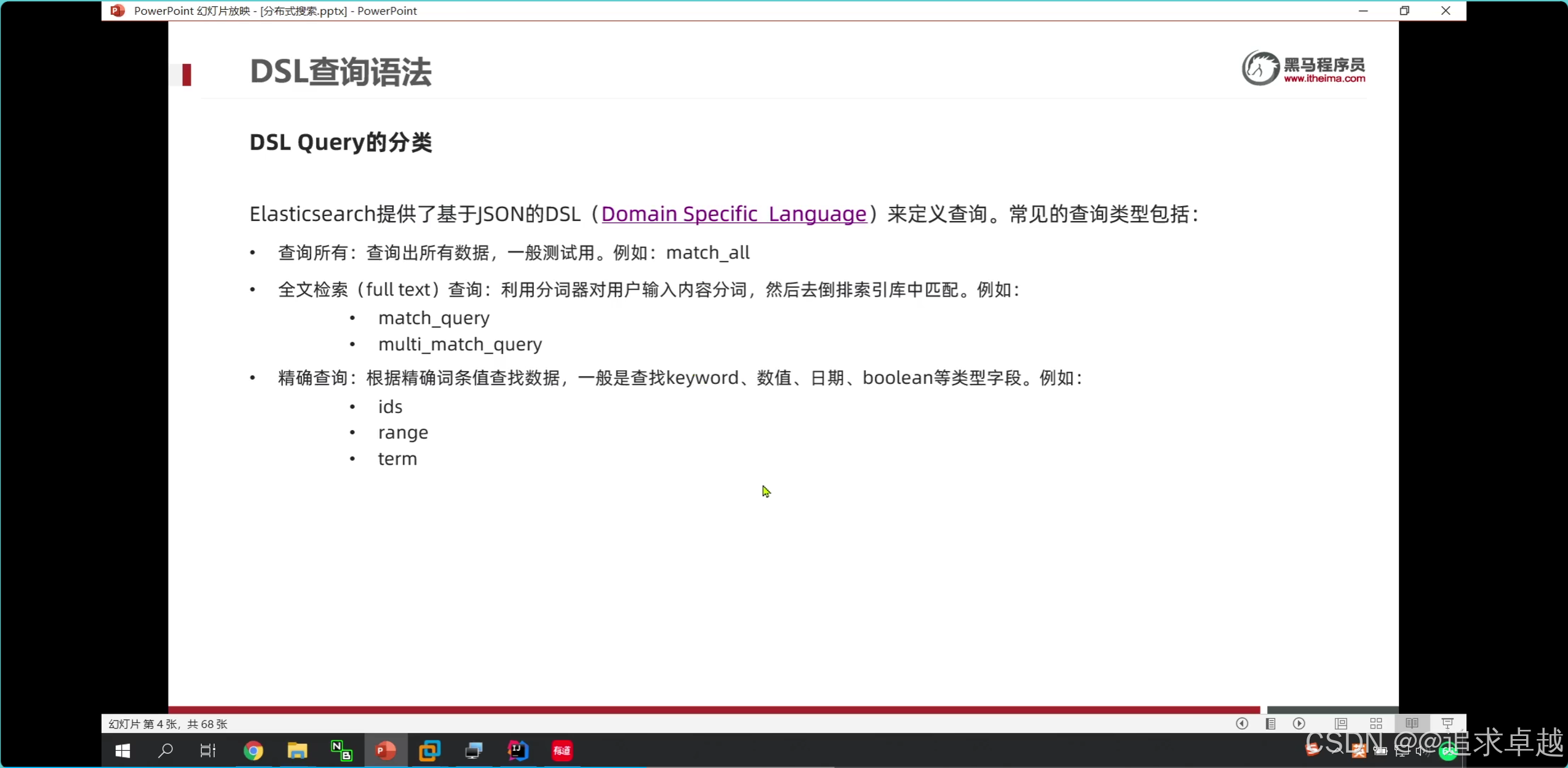
ES

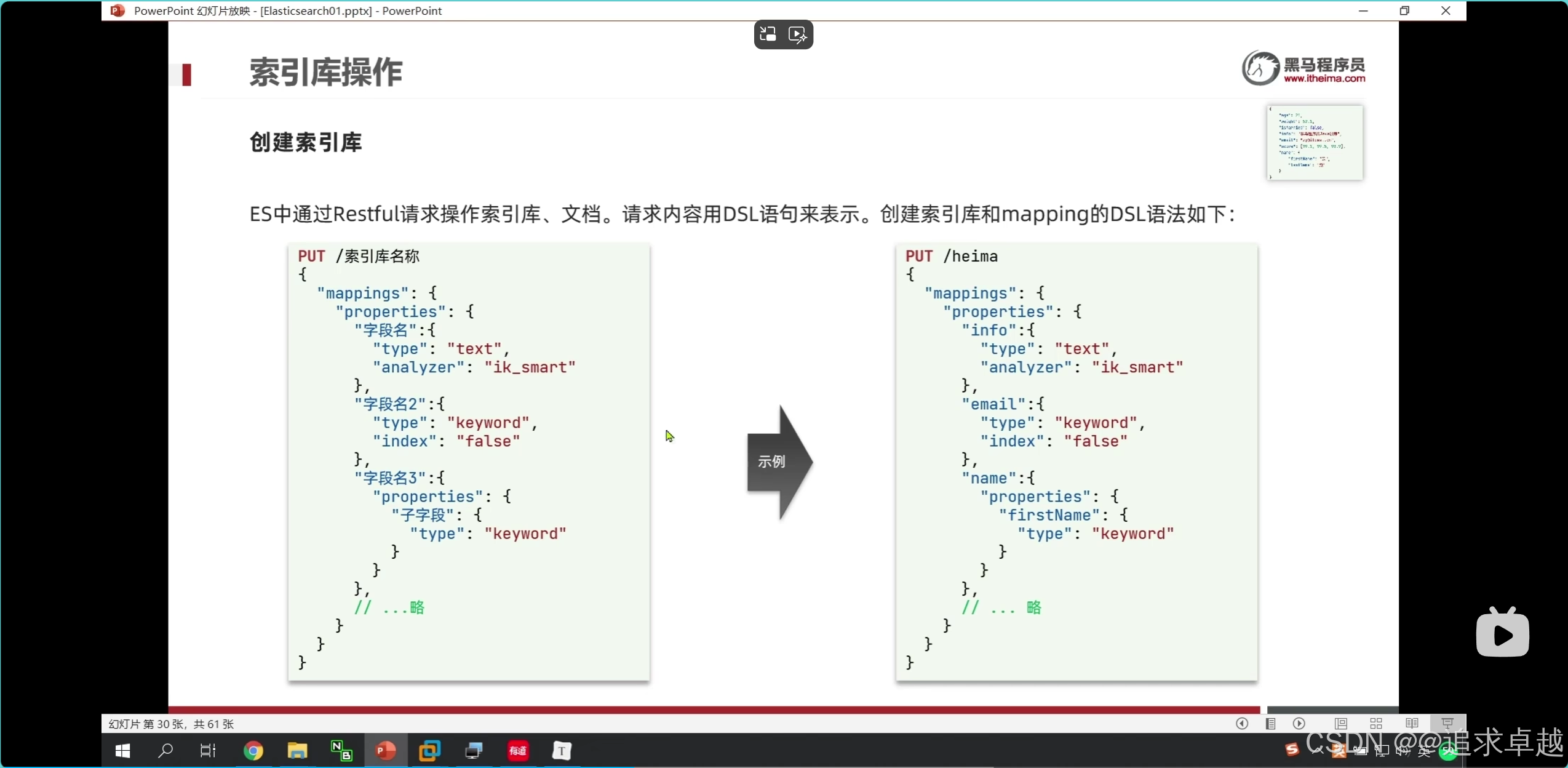
- 手機% 才會對索引生效。
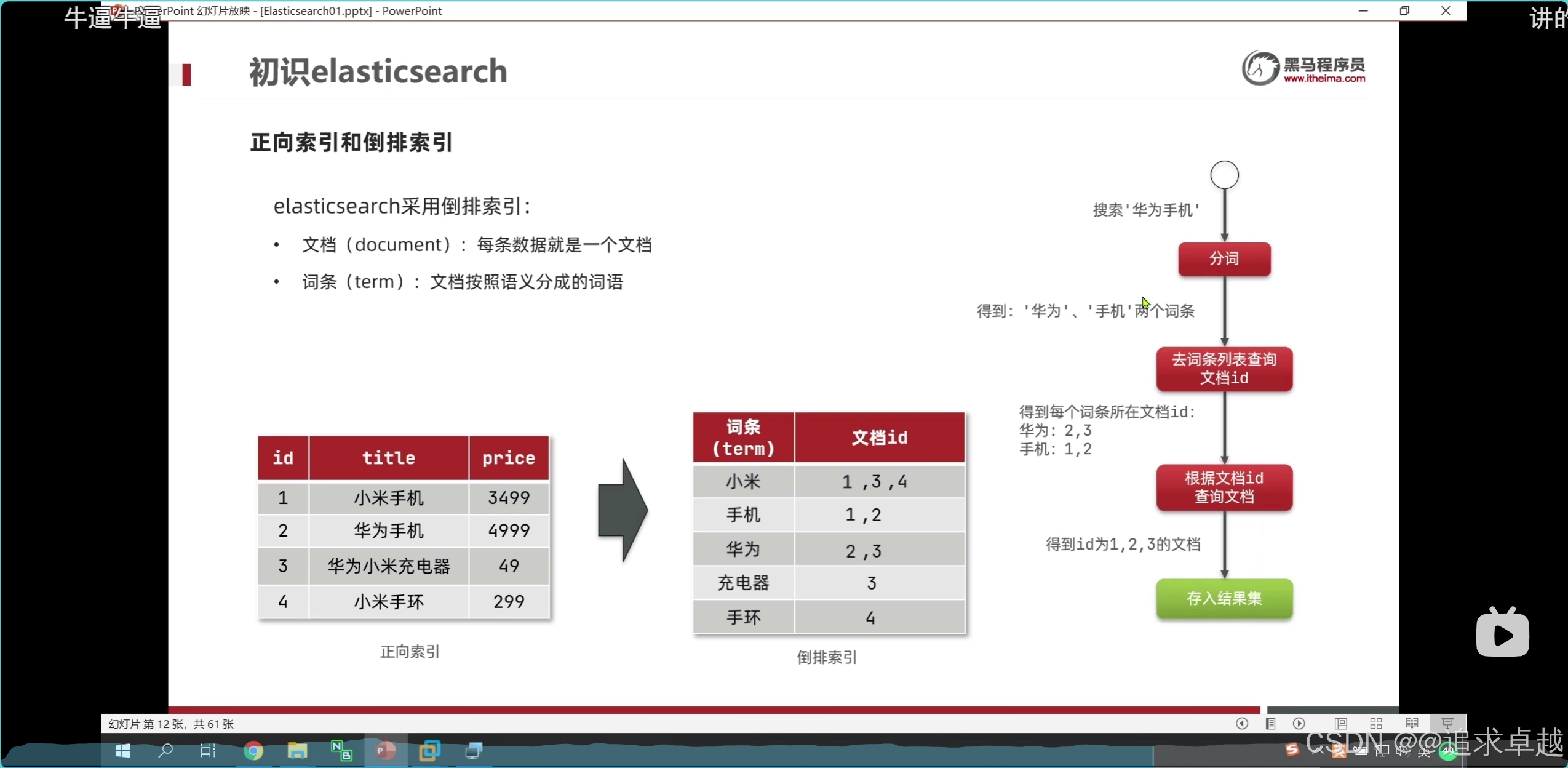

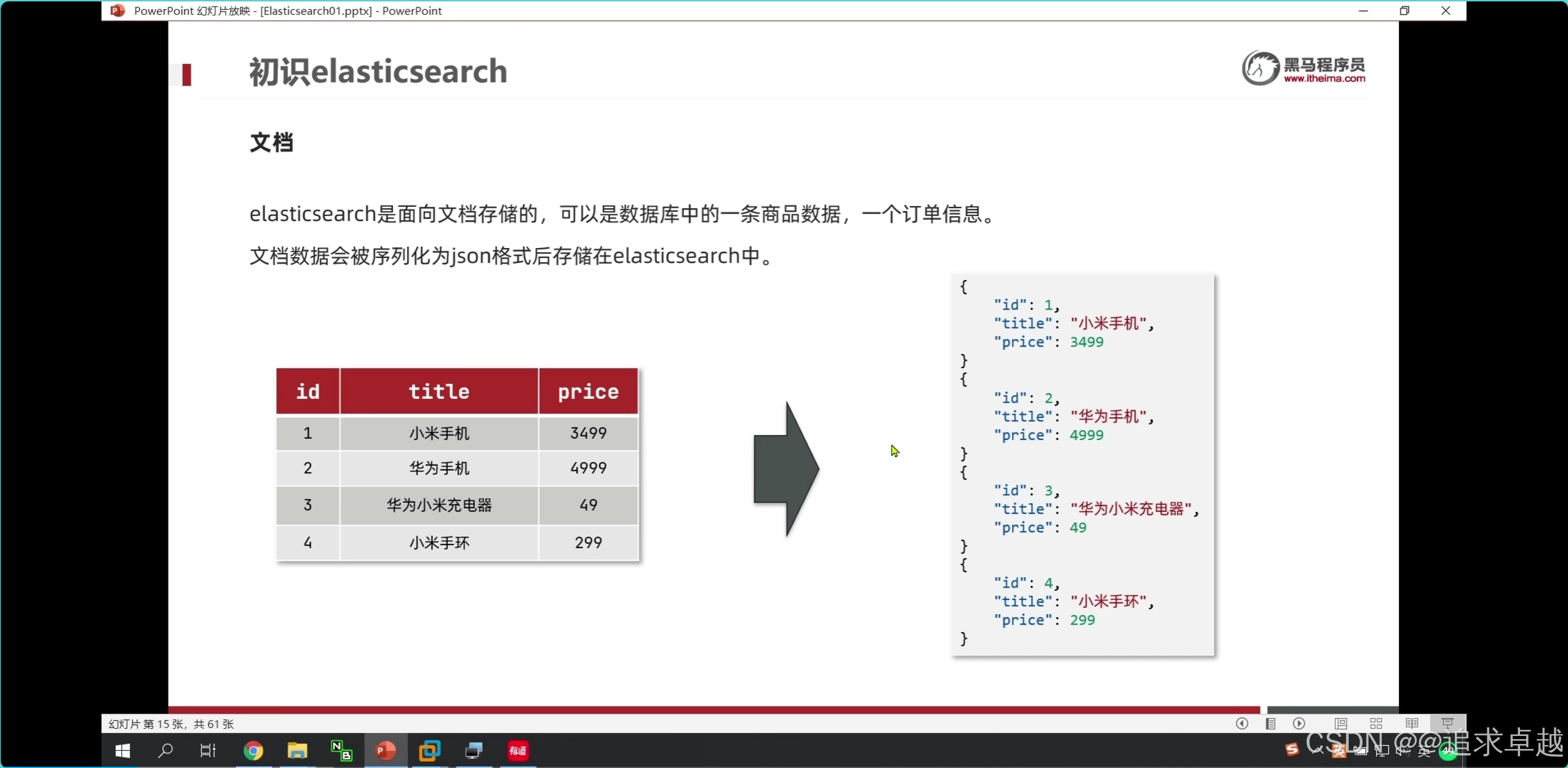




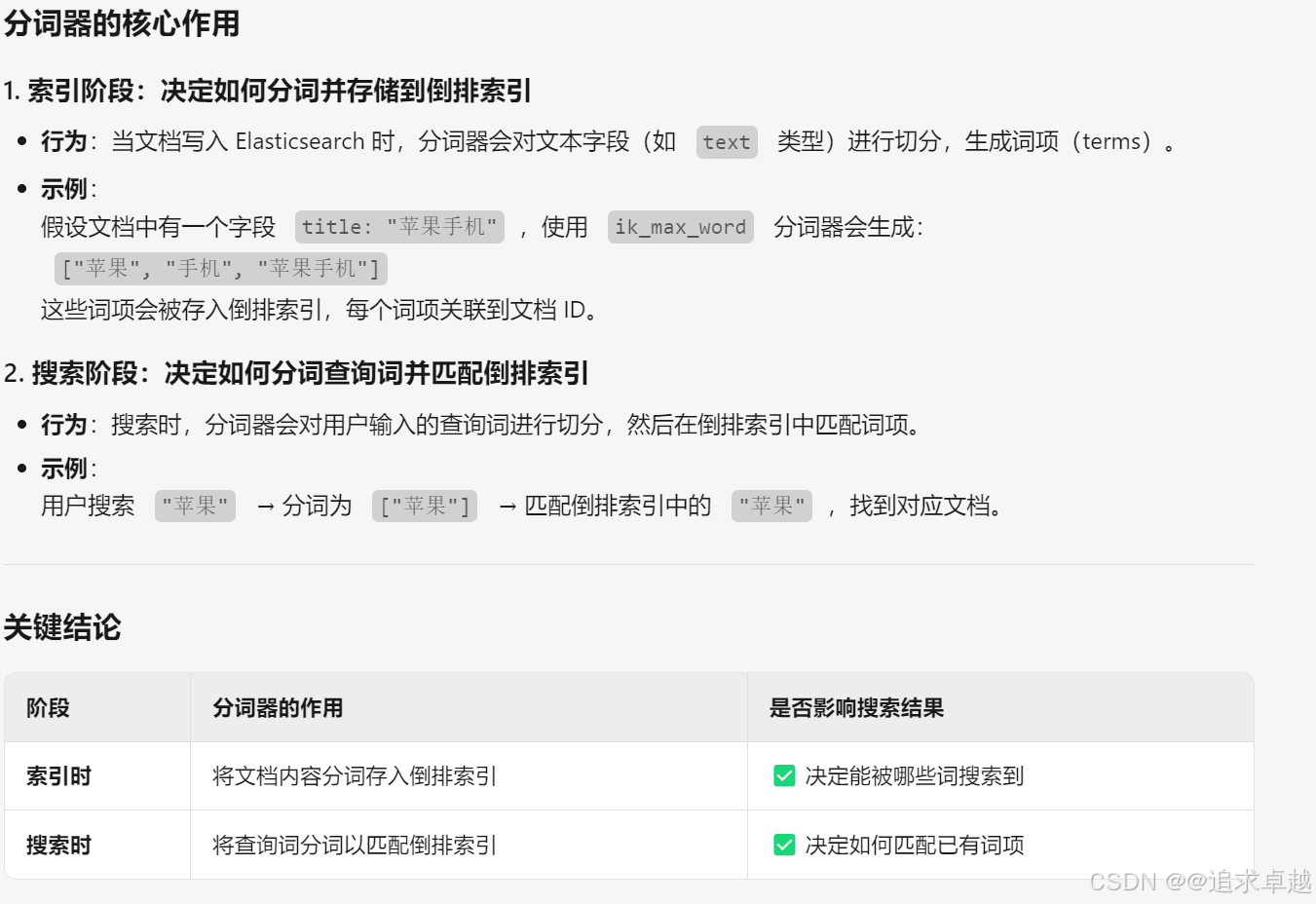
- ik分詞器是創建倒排索引和搜索分詞的。

問題

結論:
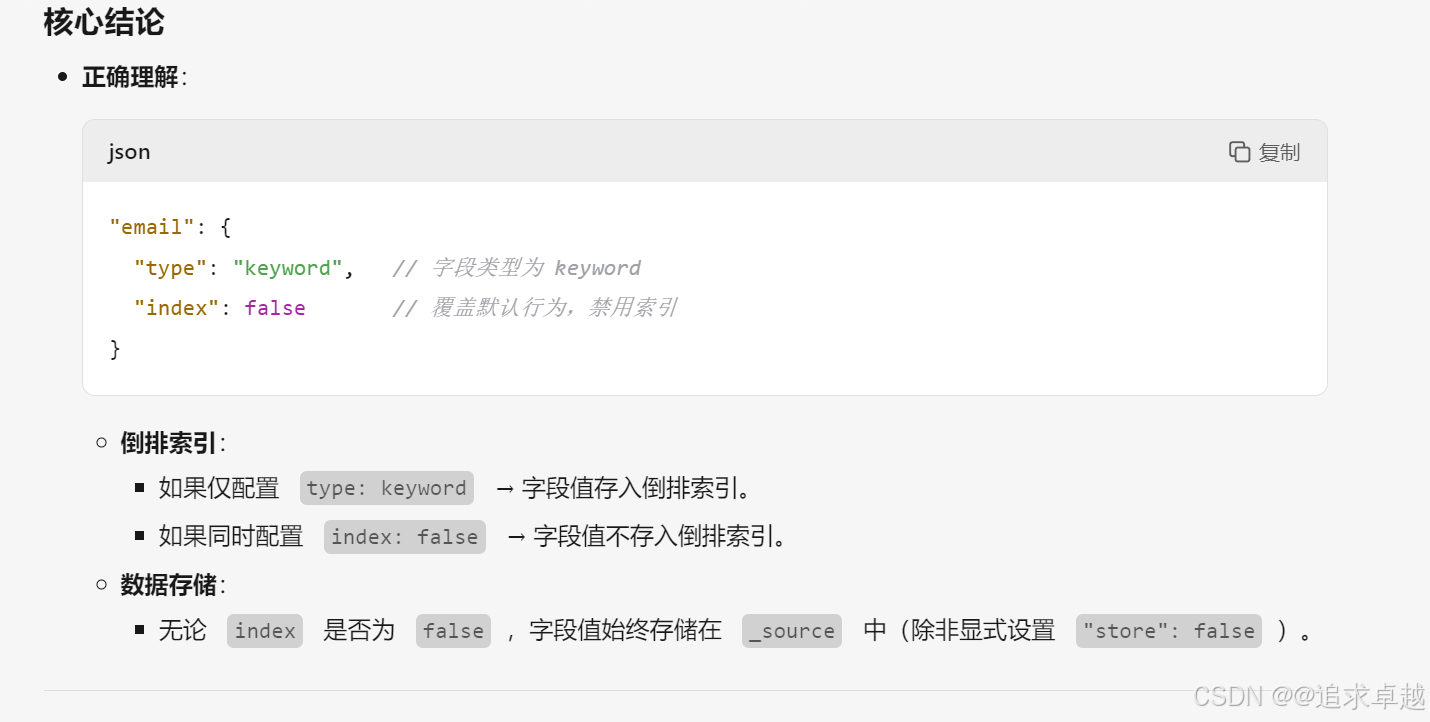
- text是創建到倒排索引的,而且會分詞。
- keyword也會創建倒排,但是如果使用index:false的話是不會創建的。所以不會放到倒排中。
問題 :索引庫和倒排索引有什么關系?
- 索引庫就是存儲到es中的文檔數據。
- 倒排索引就是基于索引庫的文檔創建的。
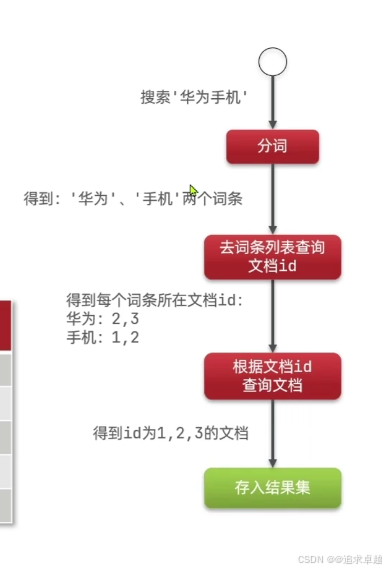
- 搜索就是根據分詞器先分詞之后匹配倒排索引庫。之后查詢。
- 存儲就是先分詞和存儲索引庫。
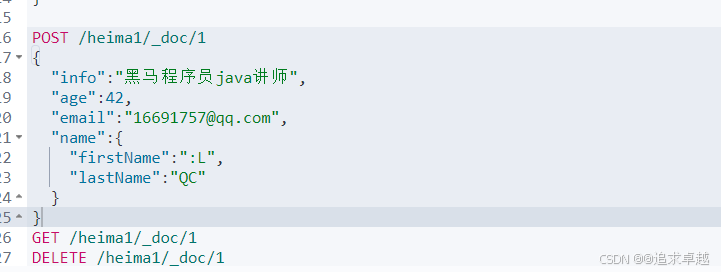

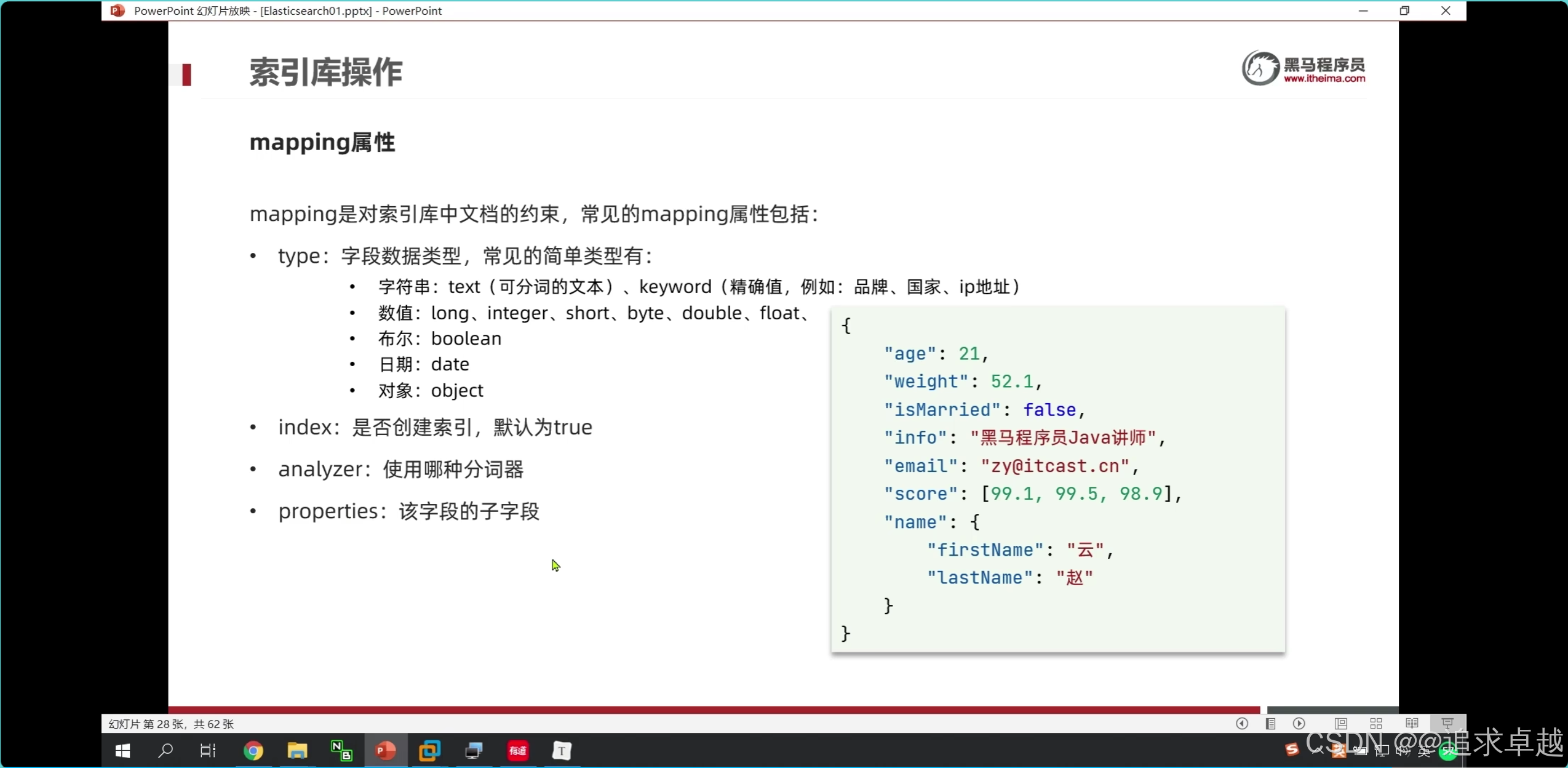
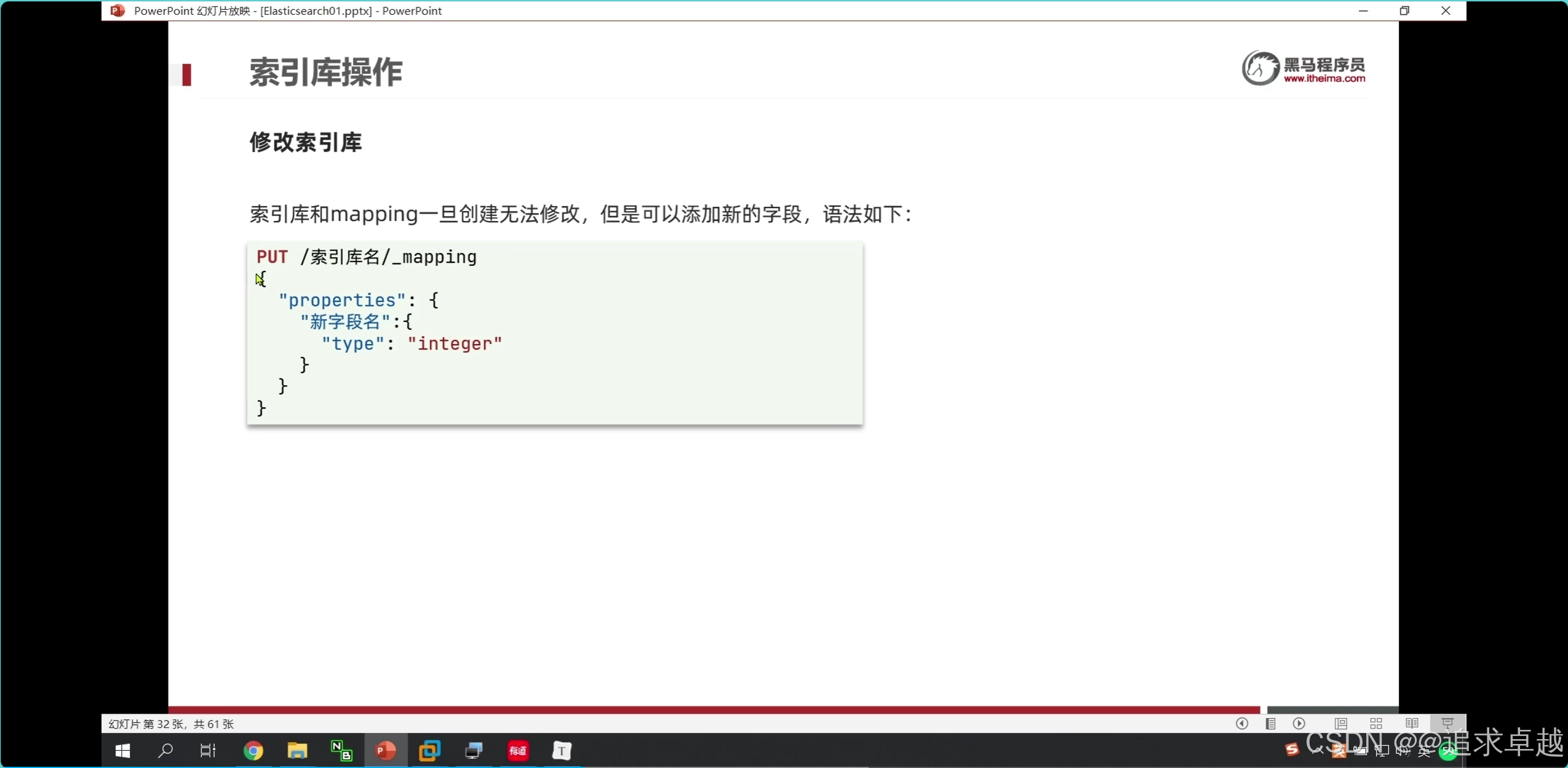
- put用于操作索引庫的字段和新增字段。全量修改。
- 新增使用post
- 獲得使用get
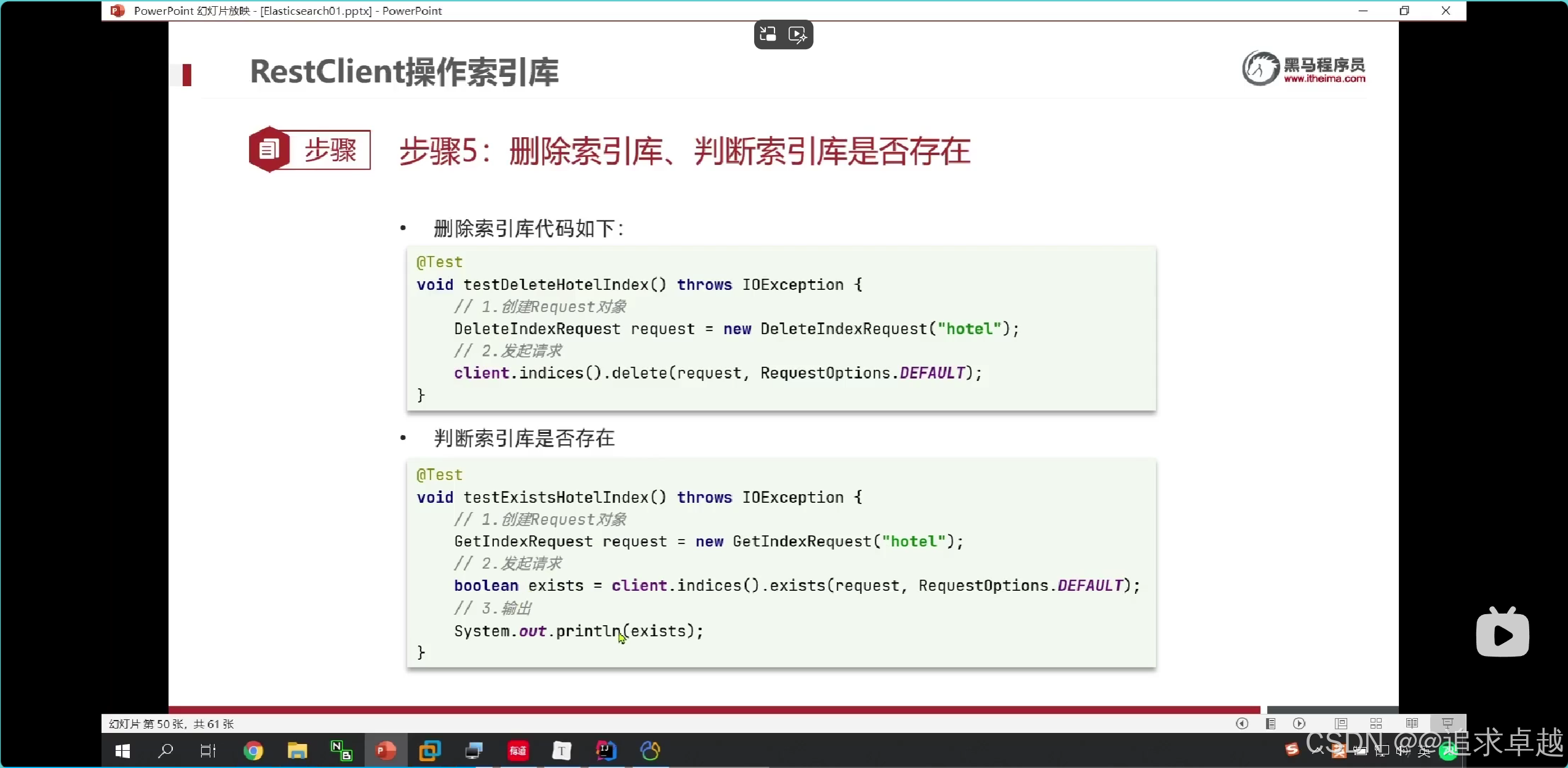
- 刪除delete。

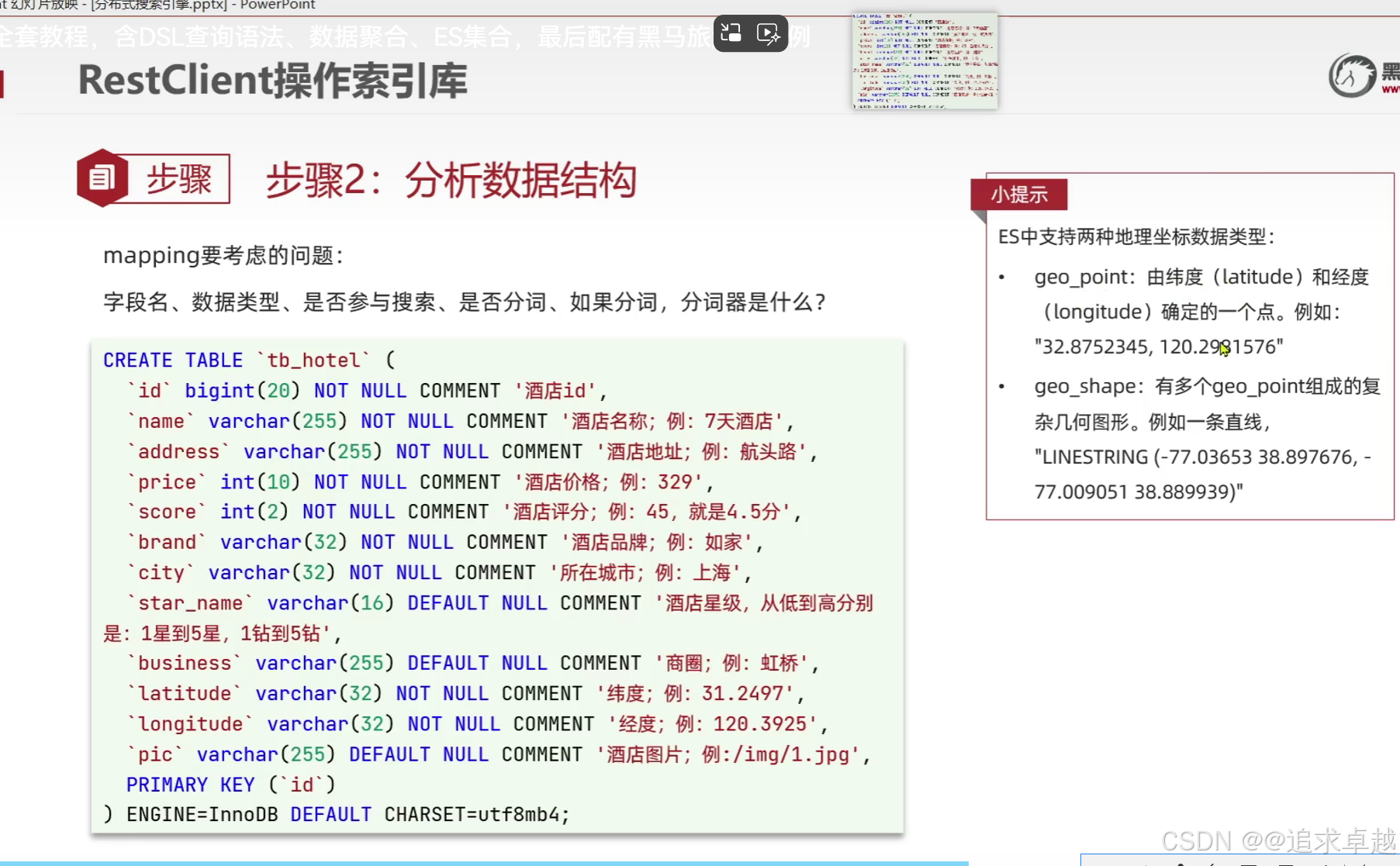
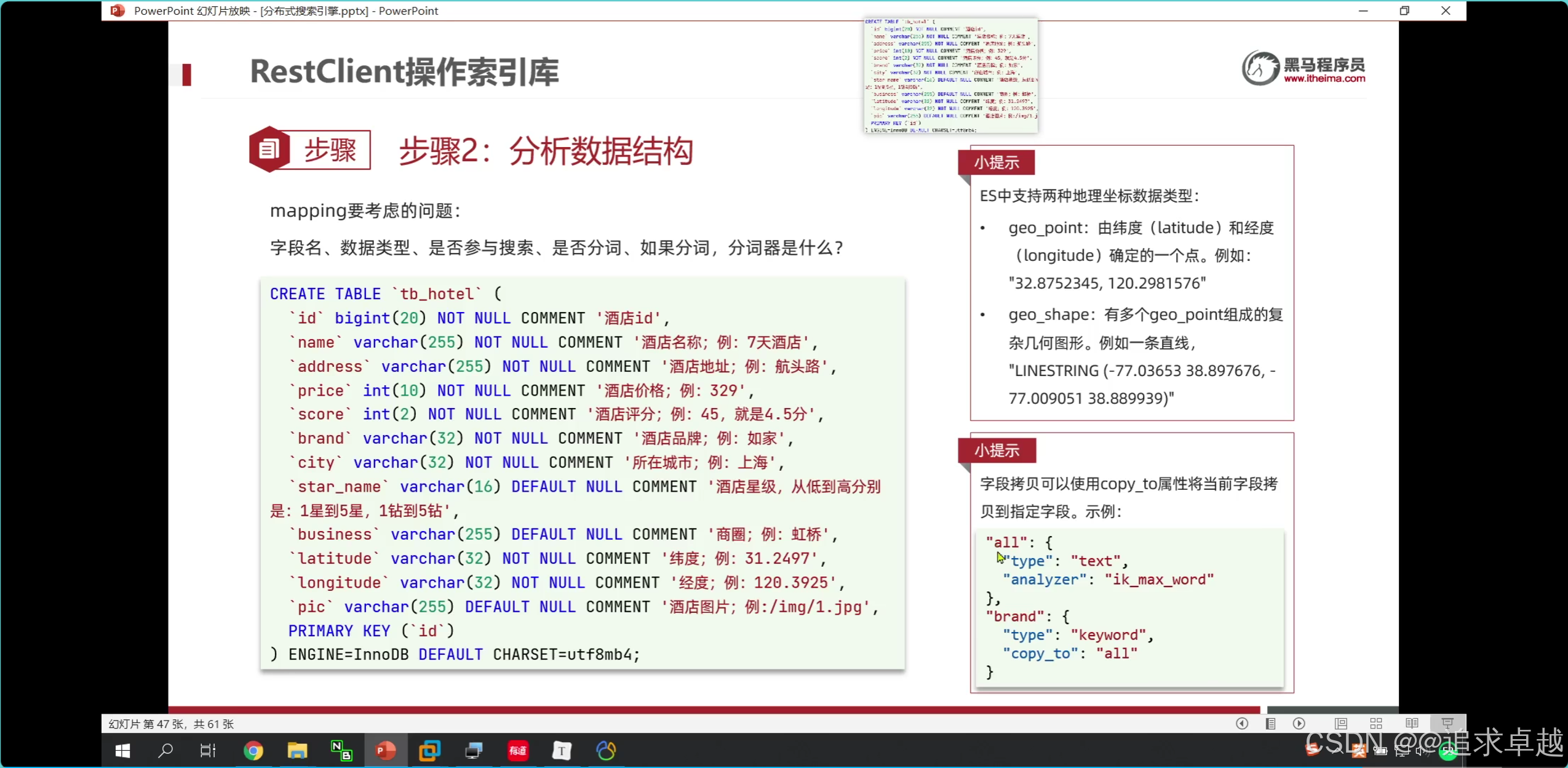
PUT /hotel
{"mappings": {"properties": {"id":{"type":"keyword"},"name":{"type":"text","analyzer": "ik_max_word","copy_to": "all"},"address":{"type":"keyword","index":false},"price":{"type":"integer"},"score":{"type":"integer"},"brand":{"type":"keyword","copy_to": "all"},"city":{"type":"keyword"},"starName":{"type":"keyword"},"business":{"type":"keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type":"keyword","index": false},"all":{"type": "text","analyzer": "ik_max_word"}}}
}
- id在es中是不可分割的。
- 把品牌和名字和商圈給到all.就是參與復合搜索。
public void test2() throws IOException {CreateIndexRequest request=new CreateIndexRequest("hotel1");request.source(MAPPING_TEMPLATE,XContentType.JSON);client.indices().create(request,RequestOptions.DEFAULT);}酒店的crud
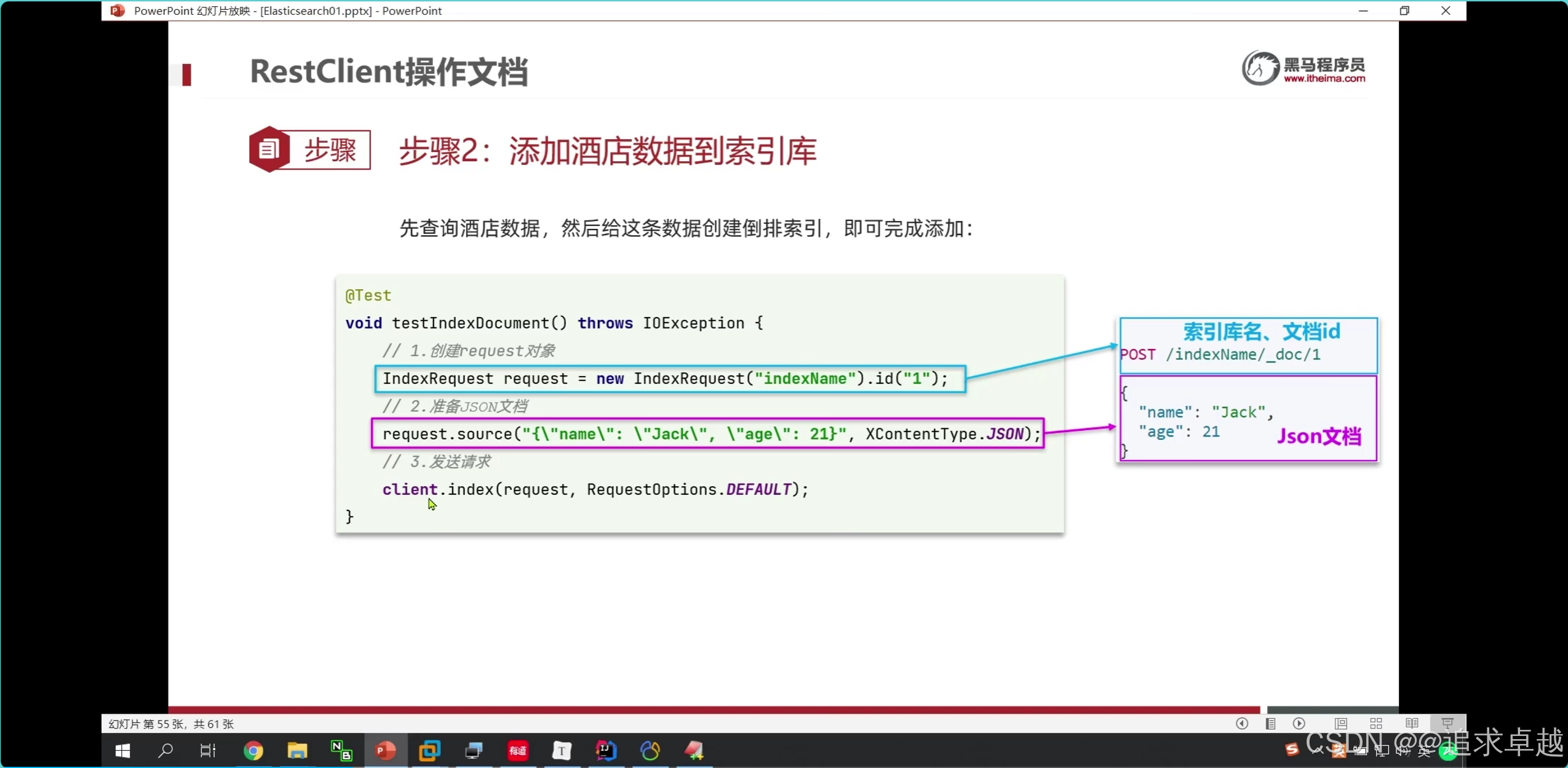
新增就是post /hotel/_doc/1
- 第一次都是從數據庫獲得對應數據,之后存儲到es中。
- es和mysql的pojo是需要兩個的。因為es的維度經度是一個。javabean是兩個。
@Testpublic void test5() throws IOException {Hotel byId = hotelService.getById(38609);System.out.println(byId);HotelDoc hotelDoc = new HotelDoc(byId);// post /hotel/_doc/1IndexRequest hotel = new IndexRequest("hotel").id(hotelDoc.getId().toString());hotel.source(JSON.toJSONString(hotelDoc), XContentType.JSON);client.index(hotel, RequestOptions.DEFAULT);// IndexRequest indexRequest=new IndexRequest("hotel1").id("1");
// indexRequest.source("",RequestOptions.DEFAULT);
// client.index(indexRequest,RequestOptions.DEFAULT);}
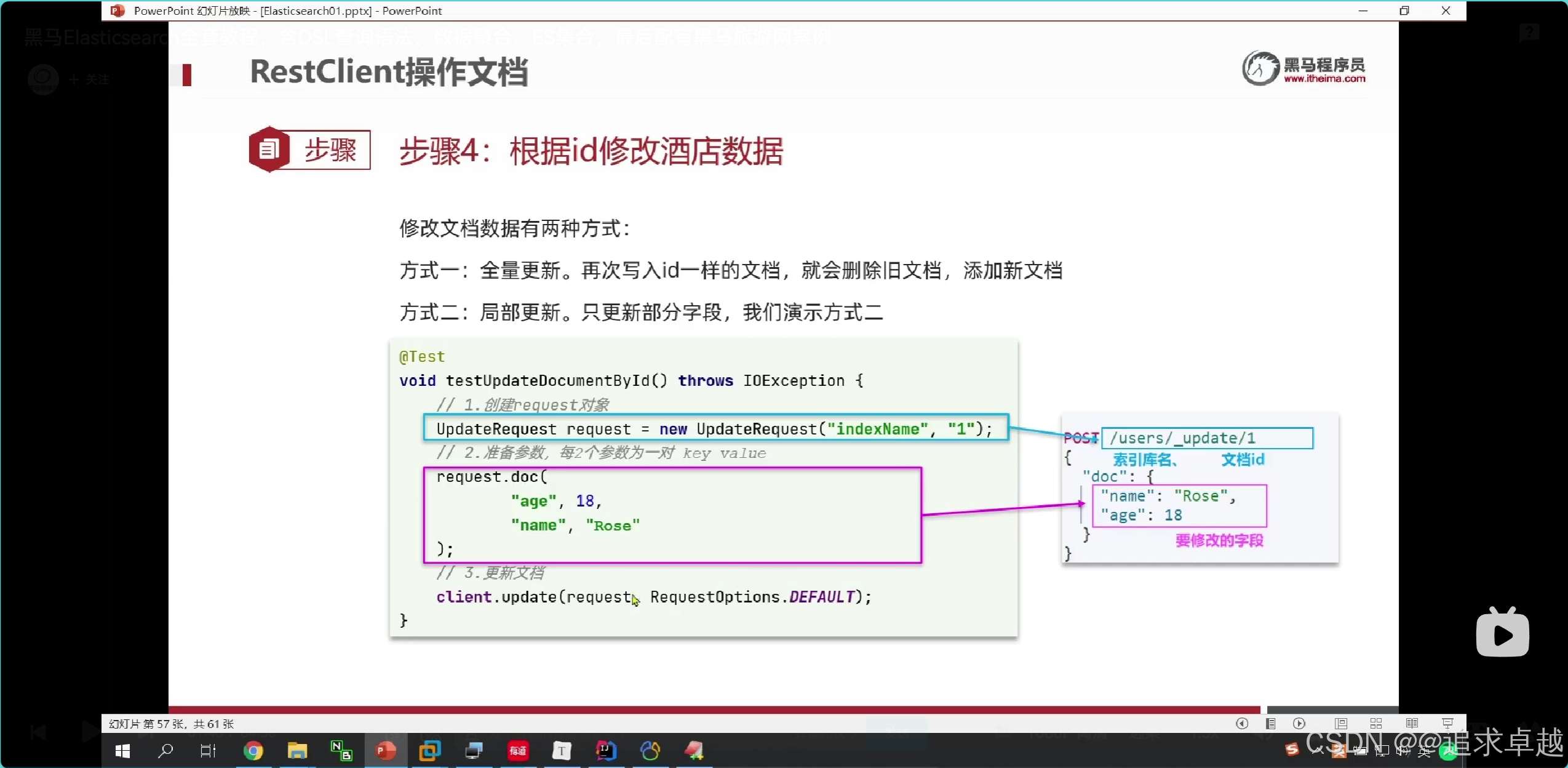
// post /hotel/_update/1
// 更新@Testpublic void test7() throws IOException {UpdateRequest hotel = new UpdateRequest("hotel", "38609");hotel.doc("price", 100,"city","上海浦東");client.update(hotel,RequestOptions.DEFAULT);}- DELETE /hotel/_doc/38609
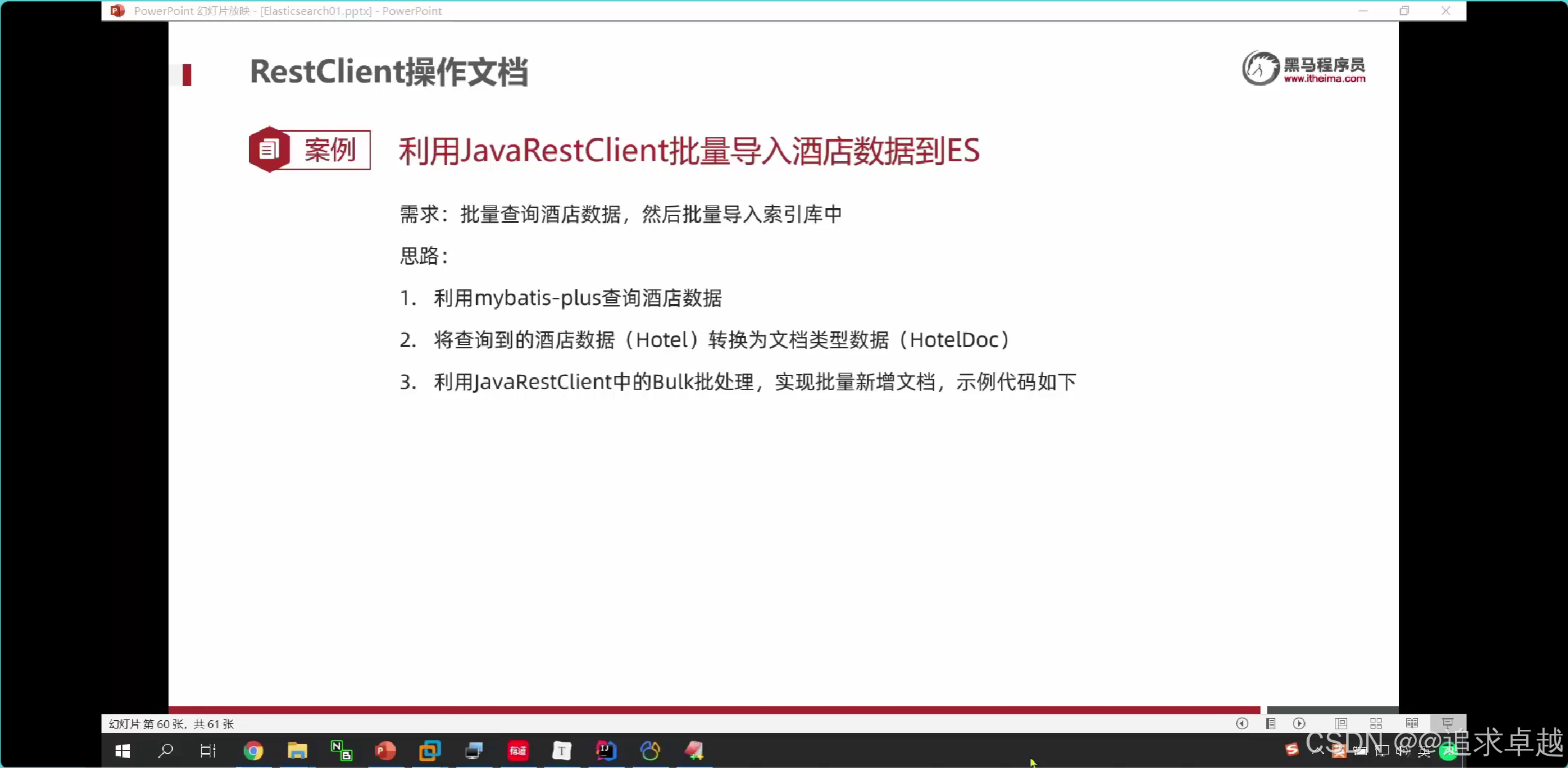
搜索數據

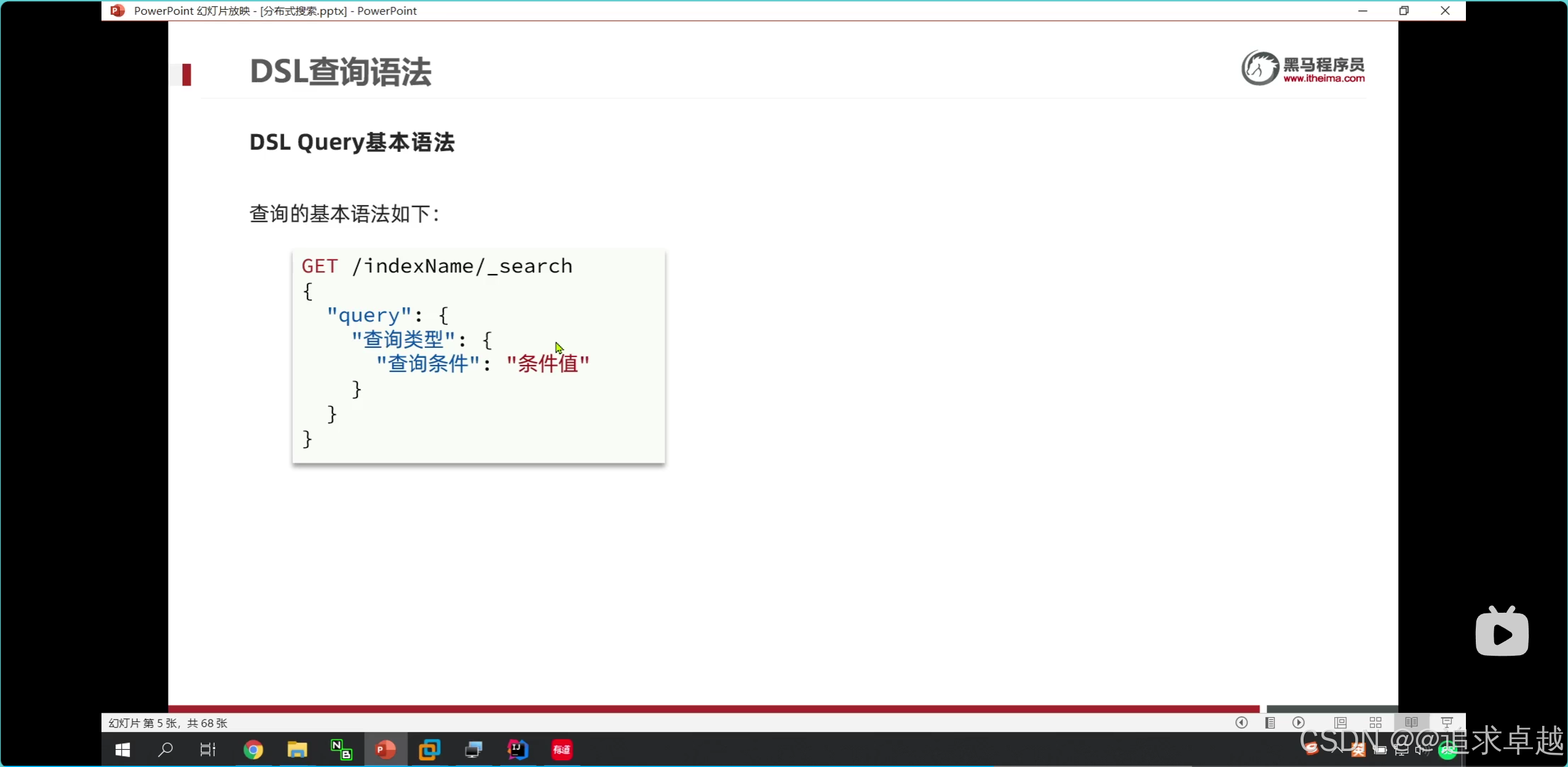
全局搜索
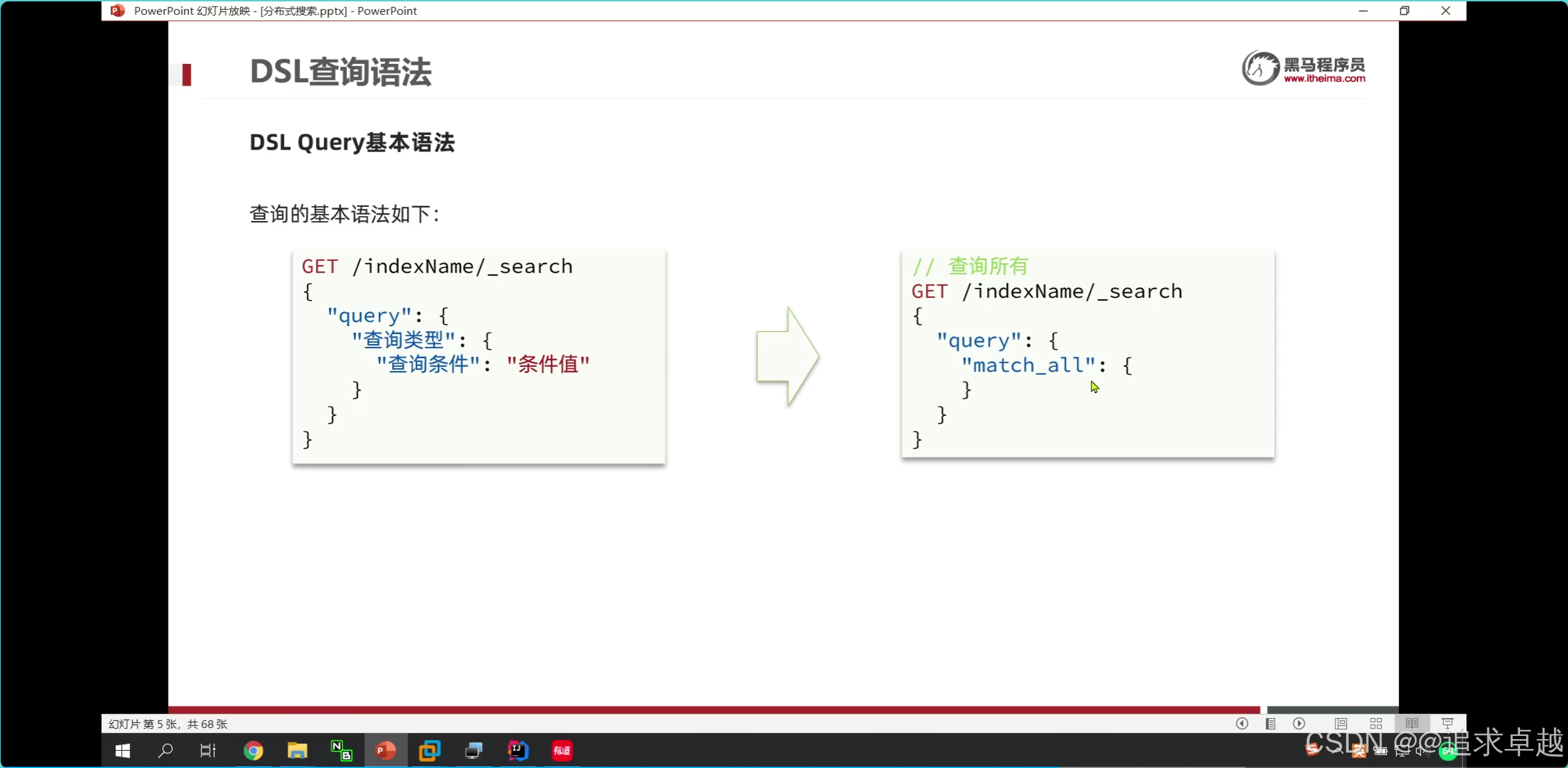

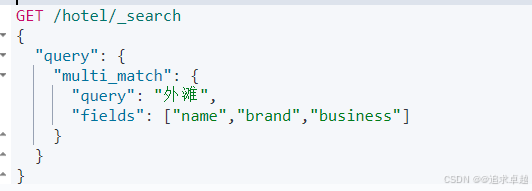
GET /hotel/_search
{"query": {"match": {"all": "外灘如家"}}
}GET /hotel/_search
{"query": {"multi_match": {"query": "外灘","fields": ["name","brand","business"]}}
}
- name brand business是分詞的字段。
- query 里面就是查詢類型。
- match_all就是查詢所有類型。
全文檢索:對詞語進行分詞,之后查詢索引庫,獲得索引。
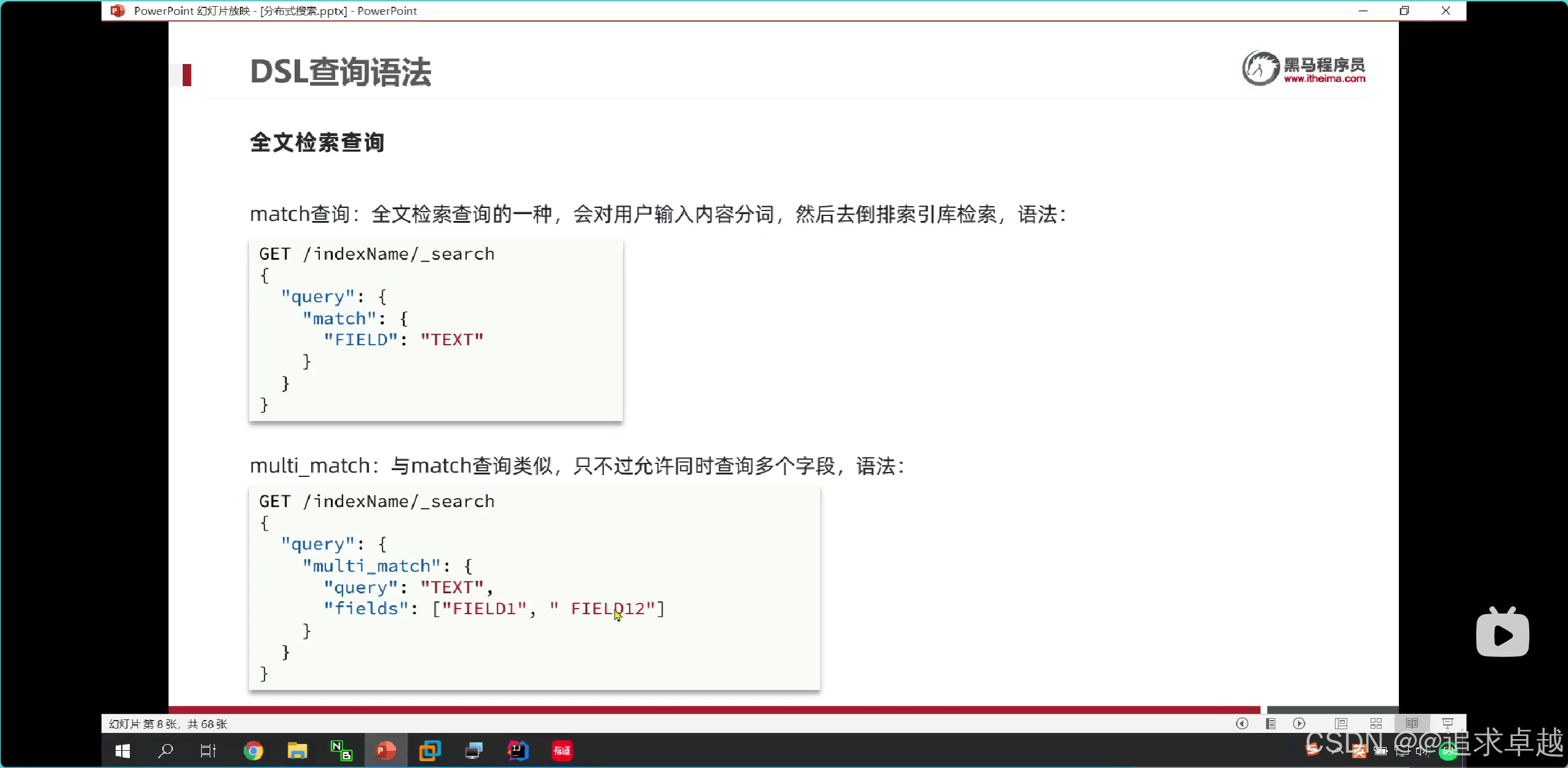
GET /hotel/_search
{"query": {"match_all": {}}
}GET /hotel/_search
{"query": {"match": {"all": "外灘如家"}}
}- 第一個是查詢全部的。
- 第二個是查詢一個字段的。
- 查詢出來的相關度越高排名越靠前。
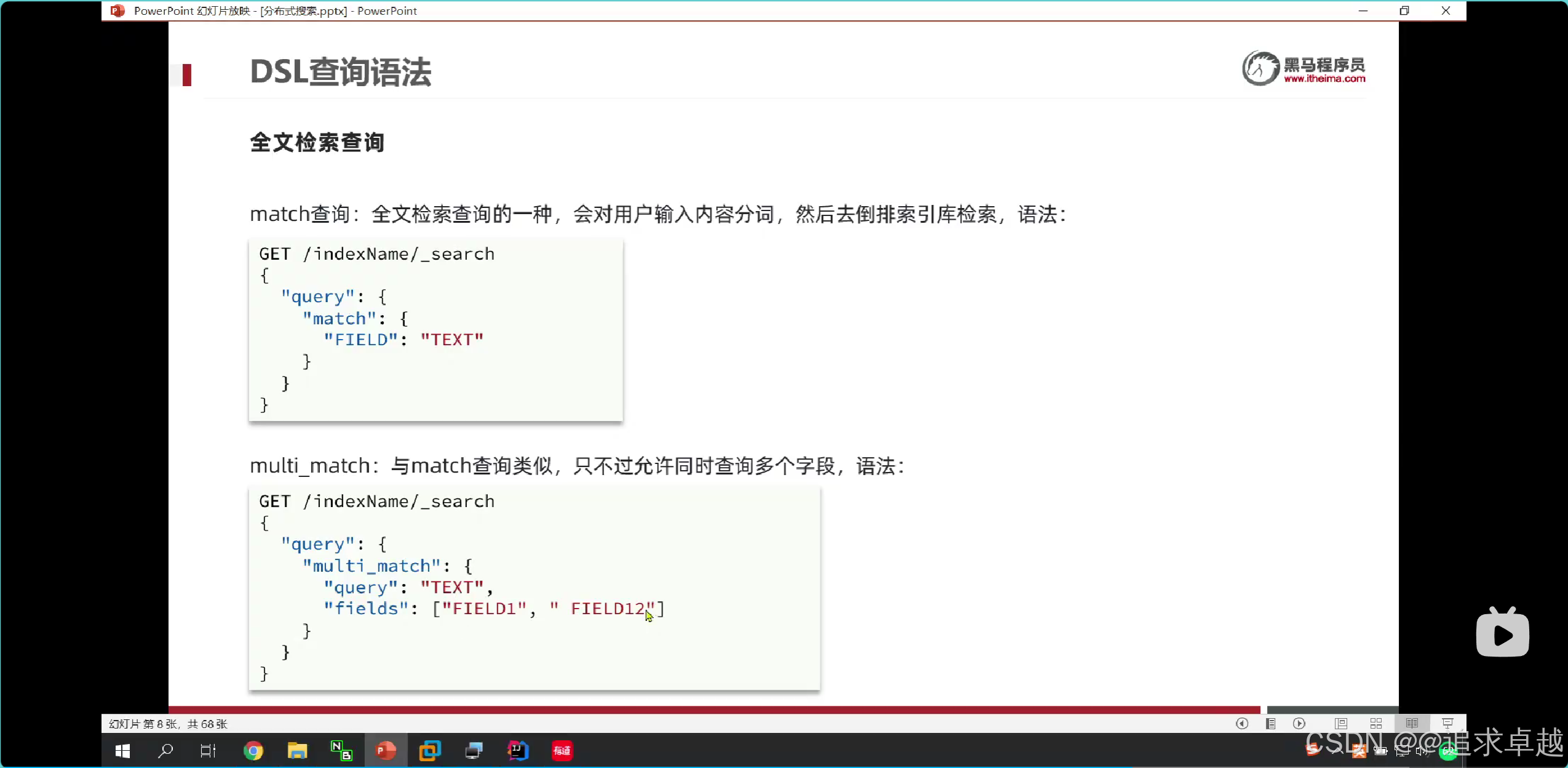
- 可以查詢多個索引庫。
為什么使用all更快呢?
- 因為每個被分詞的字段都會被構建一個索引庫,所以有時候需要查詢多個。
- 但是all也是分詞的,只需要查詢一遍索引庫。
- 要給字段類型給 “type”: “text”。
??普通多字段查詢??(如 multi_match):
- 需要分別檢索每個字段的倒排索引,例如同時查詢 name、address、 escription 三個字段。
??性能損耗??:
多次倒排索引查找(每個字段一次)
合并多個字段的匹配結果(相關性計算更復雜)
可能涉及不同字段的分詞器和詞項差異 - ??all 字段查詢??:
所有目標字段的內容在 ??索引階段?? 已合并到 all 字段中,只需檢索一個倒排索引。
??性能優勢??:
單次倒排索引查找
統一的分詞器(確保詞項一致性)
無需跨字段合并結果
📊 性能對比示例
假設 name、address、description 各有獨立的倒排索引:
- ??查詢方式?? 倒排索引訪問次數 詞項合并復雜度
multi_match 3次 高
all 字段 1次 低
問題: 一般是不是經常在搜索框的是字段用分詞,在下面固定的使用不分詞
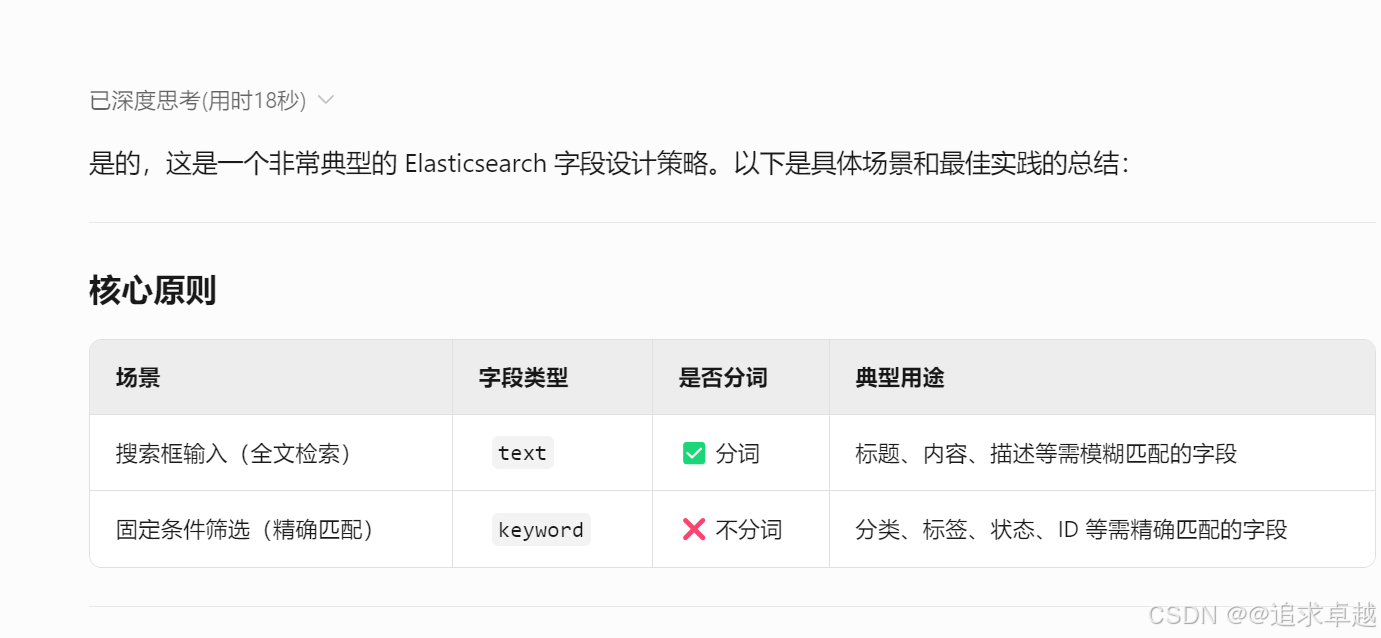
精確查詢:無需進行分詞
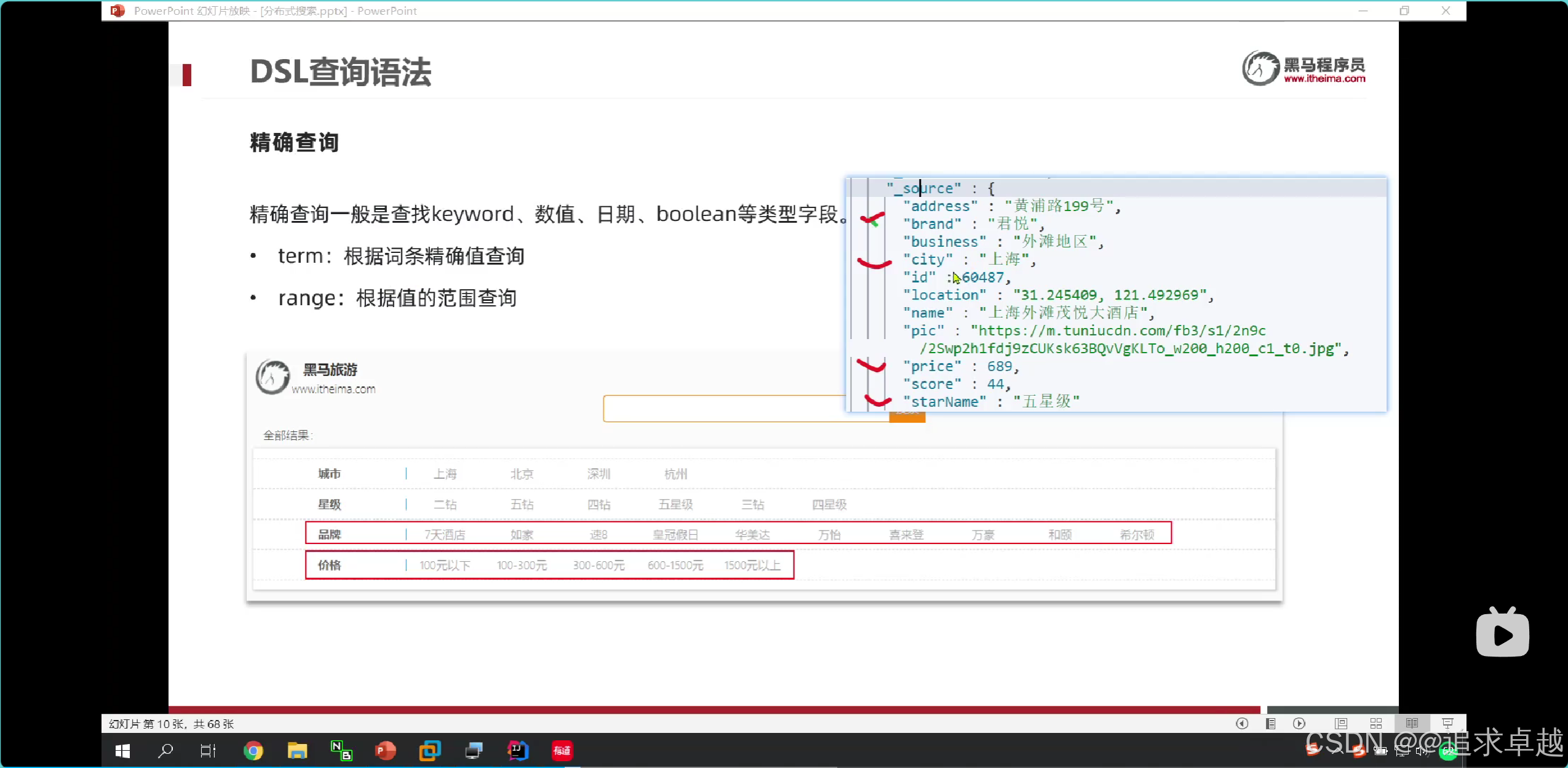

#range查詢
GET /hotel/_search
{"query": {"range": {"price": {"gte": 200,"lte": 300}} }
}
- 范圍查詢。對于integer類型很好用。
經緯度查詢
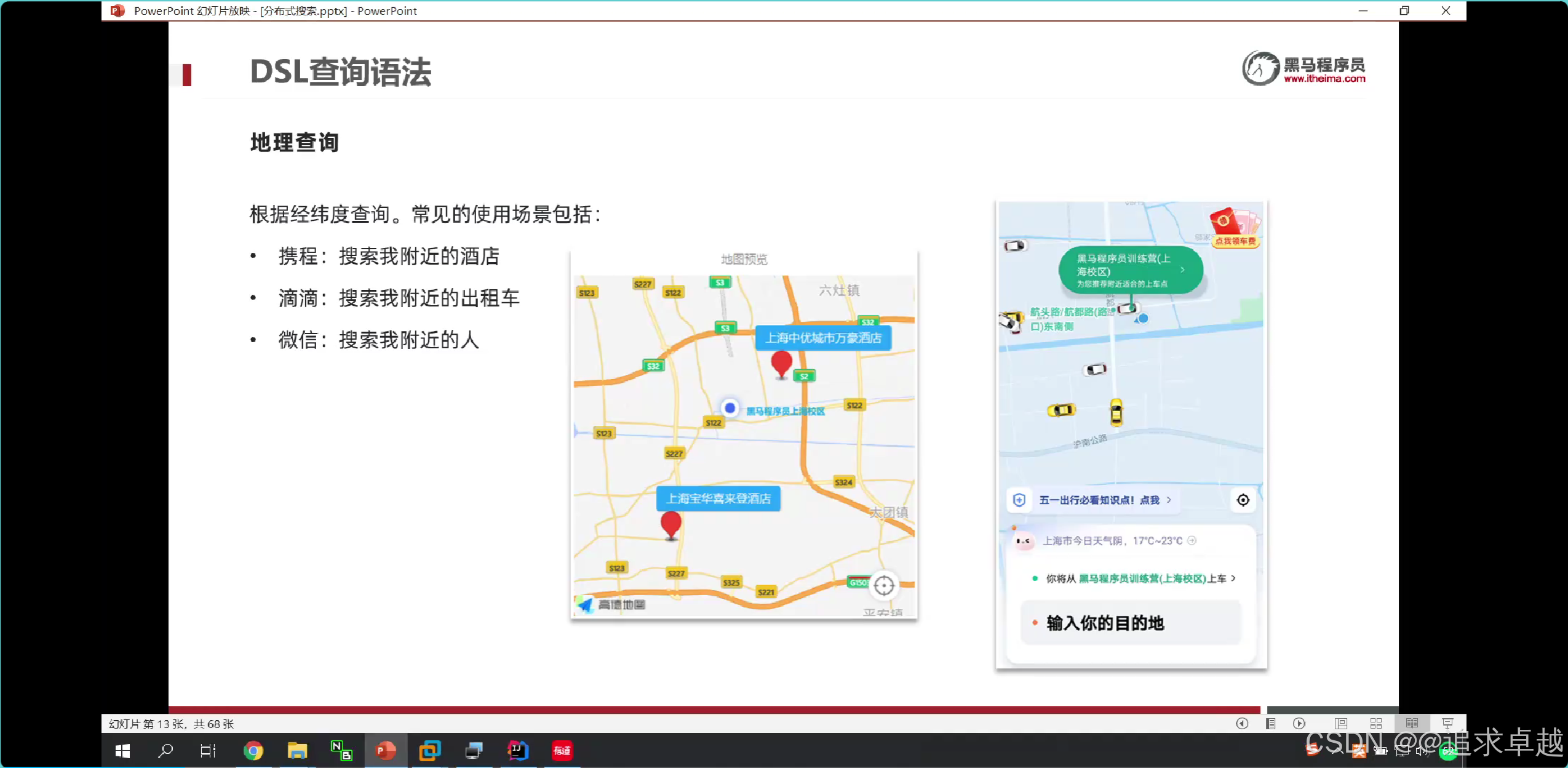
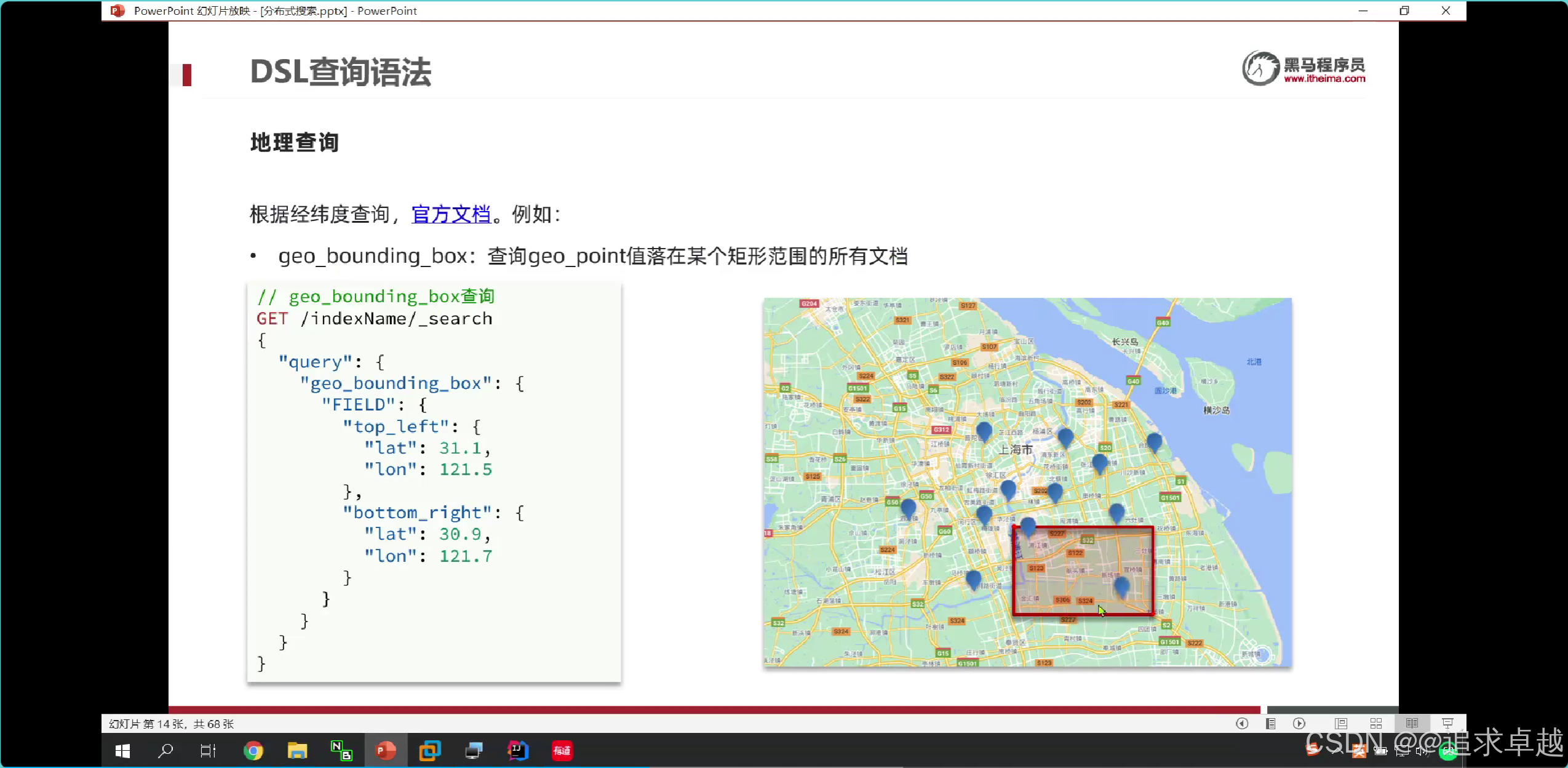
# 已自己為中心點。周圍5km。
GET /hotel/_search
{"query": {"geo_distance": {"distance":"5km","location":"40.048969, 116.619566"} }
}
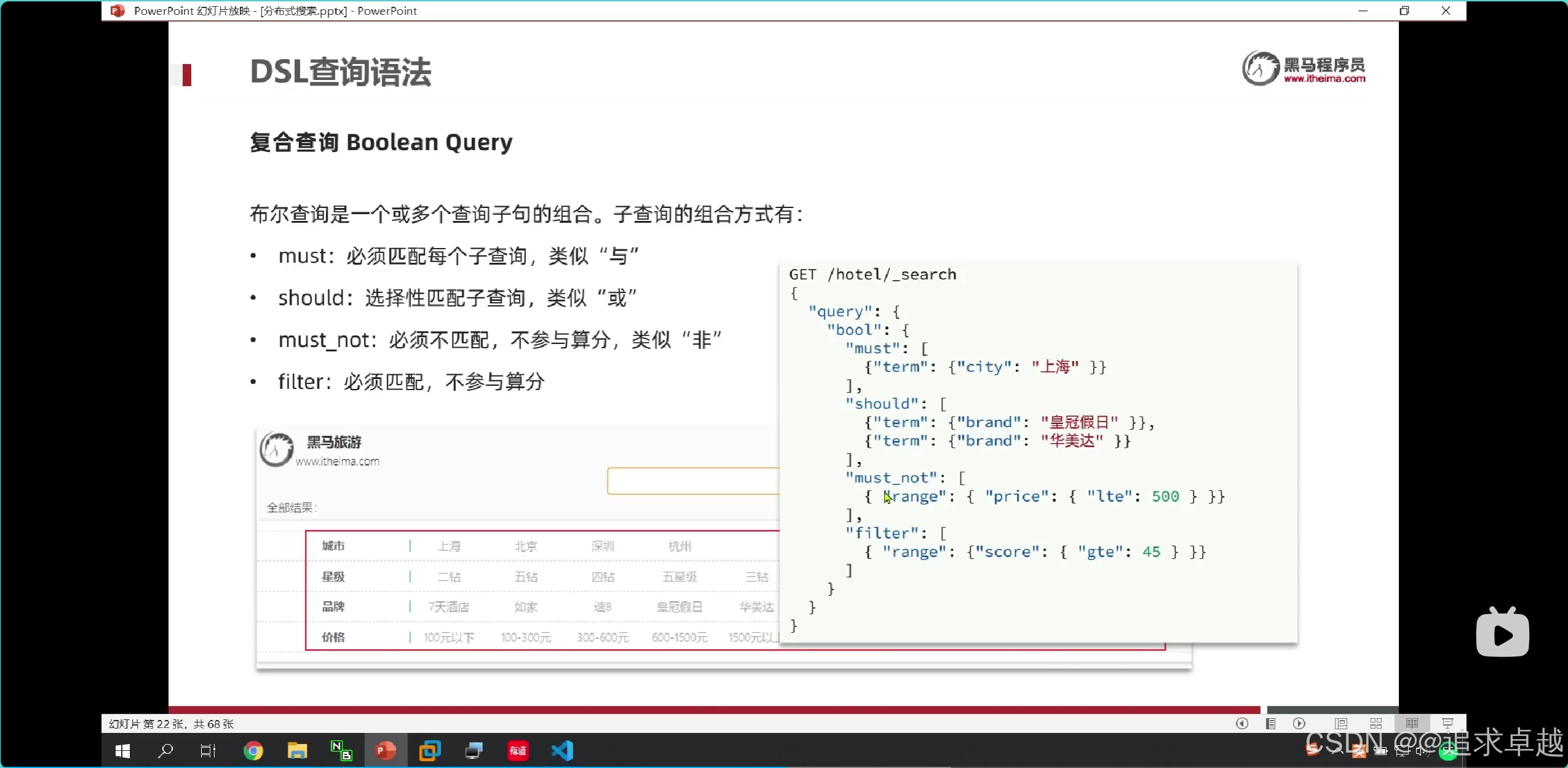
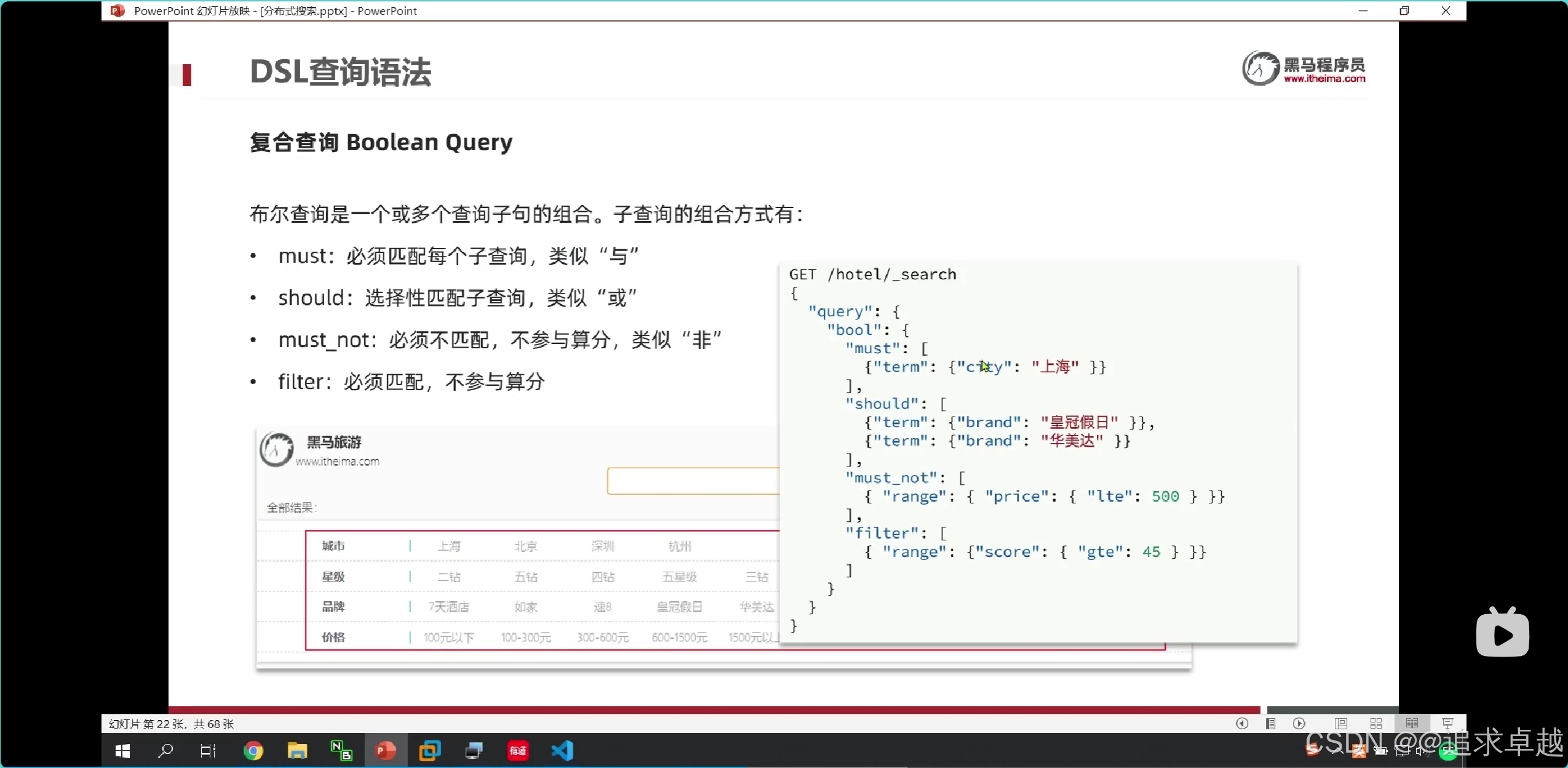
{"query": {"bool": {"must": [ ... ], // AND 邏輯(必須滿足)"should": [ ... ], // OR 邏輯(至少滿足一個)"must_not": [ ... ], // NOT 邏輯(必須不滿足)"filter": [ ... ] // 精確過濾(不計算相關性得分,性能更高)}}
}
- 在多條件查詢中,必須在外面bool。
- query -> bool -> must、should、must_not、filter。
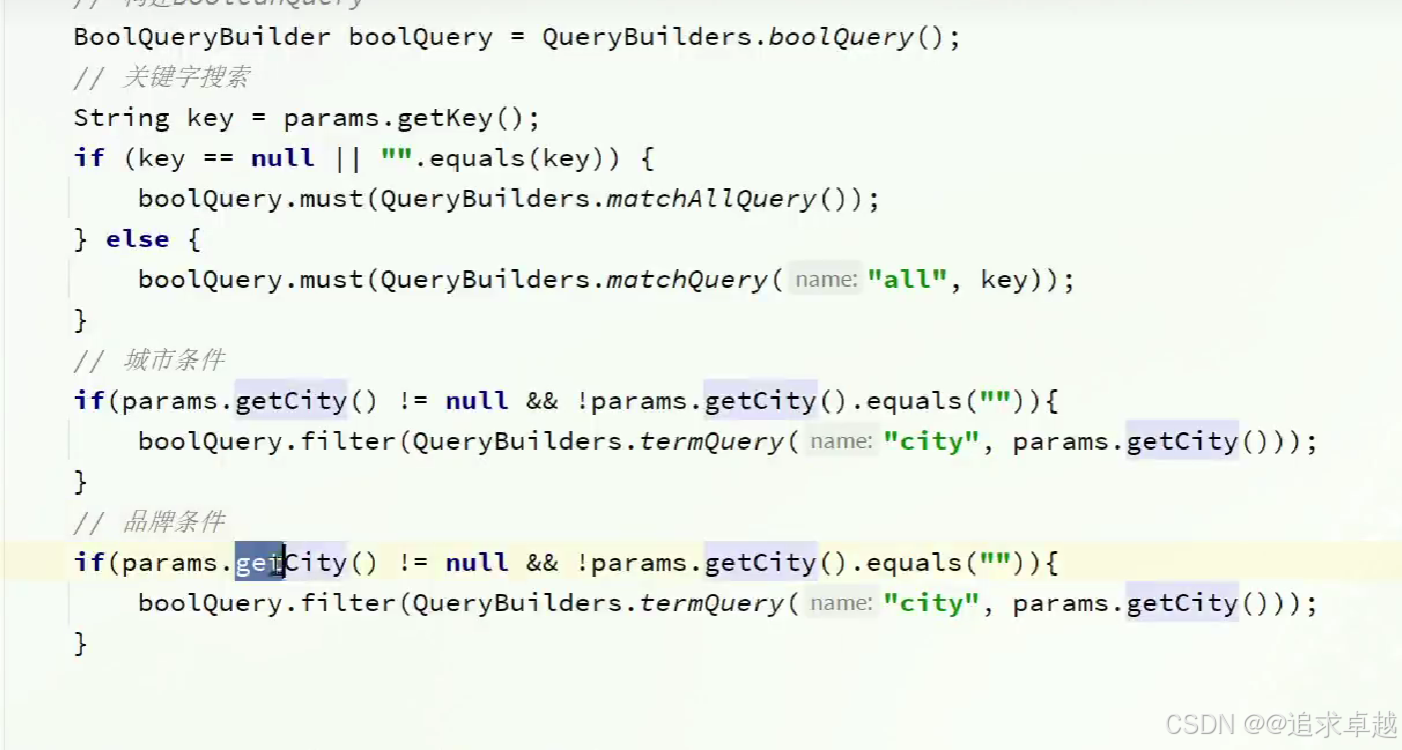
GET /hotel/_search
{"query": {"bool": {"must": [{"term": {"city": "上海"}}],"should": [{"term":{"brand":"如家"}},{"term":{"brand":"華美達"}}],"must_not": [{"range":{"price": {"gte": 300}}}],"filter": [{"range": {"score": {"gte": 30,"lte": 40}}}]}}
}
- match和multi_match是分詞查詢的。
- term是精確
- range是范圍
排序
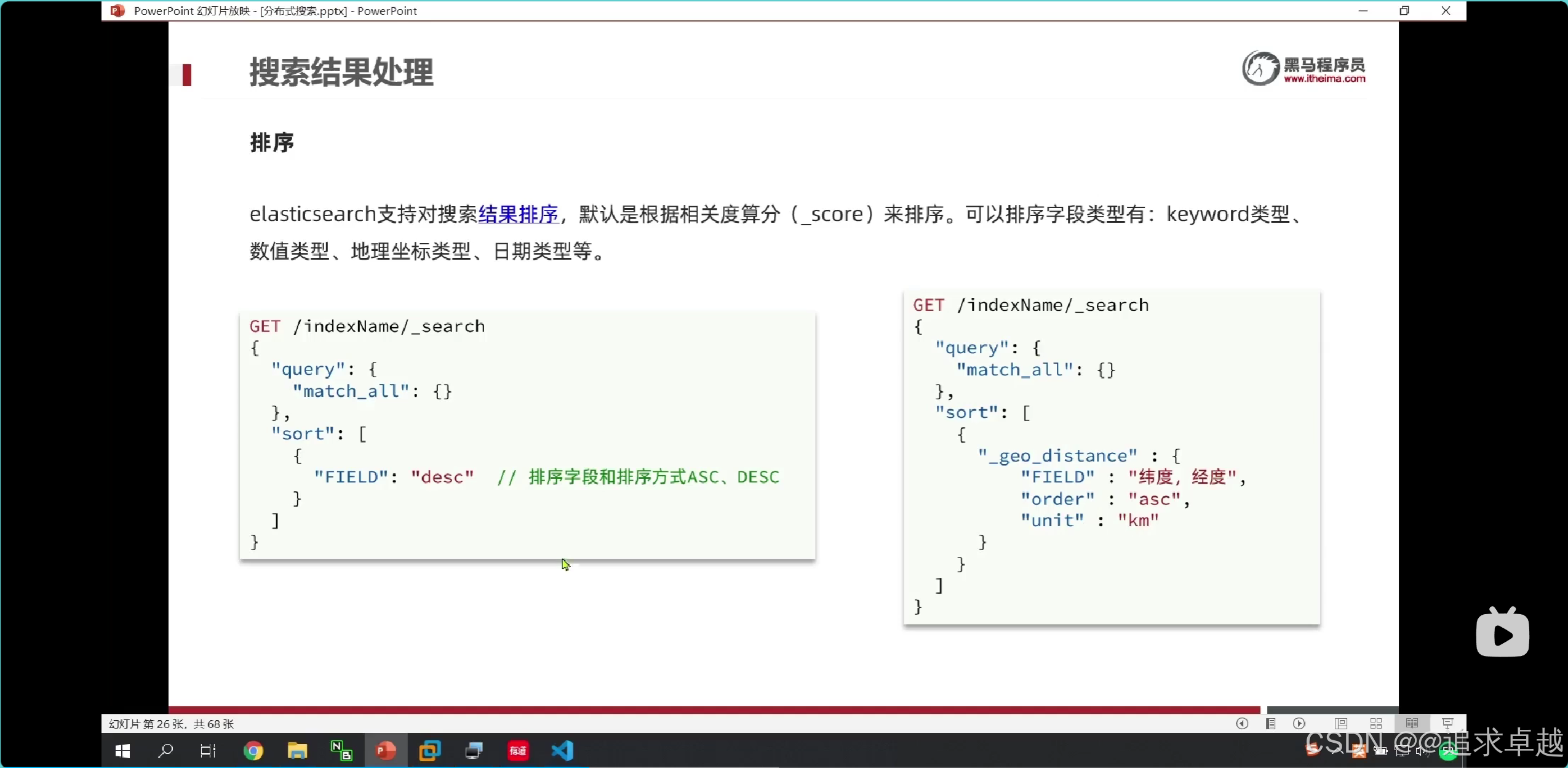
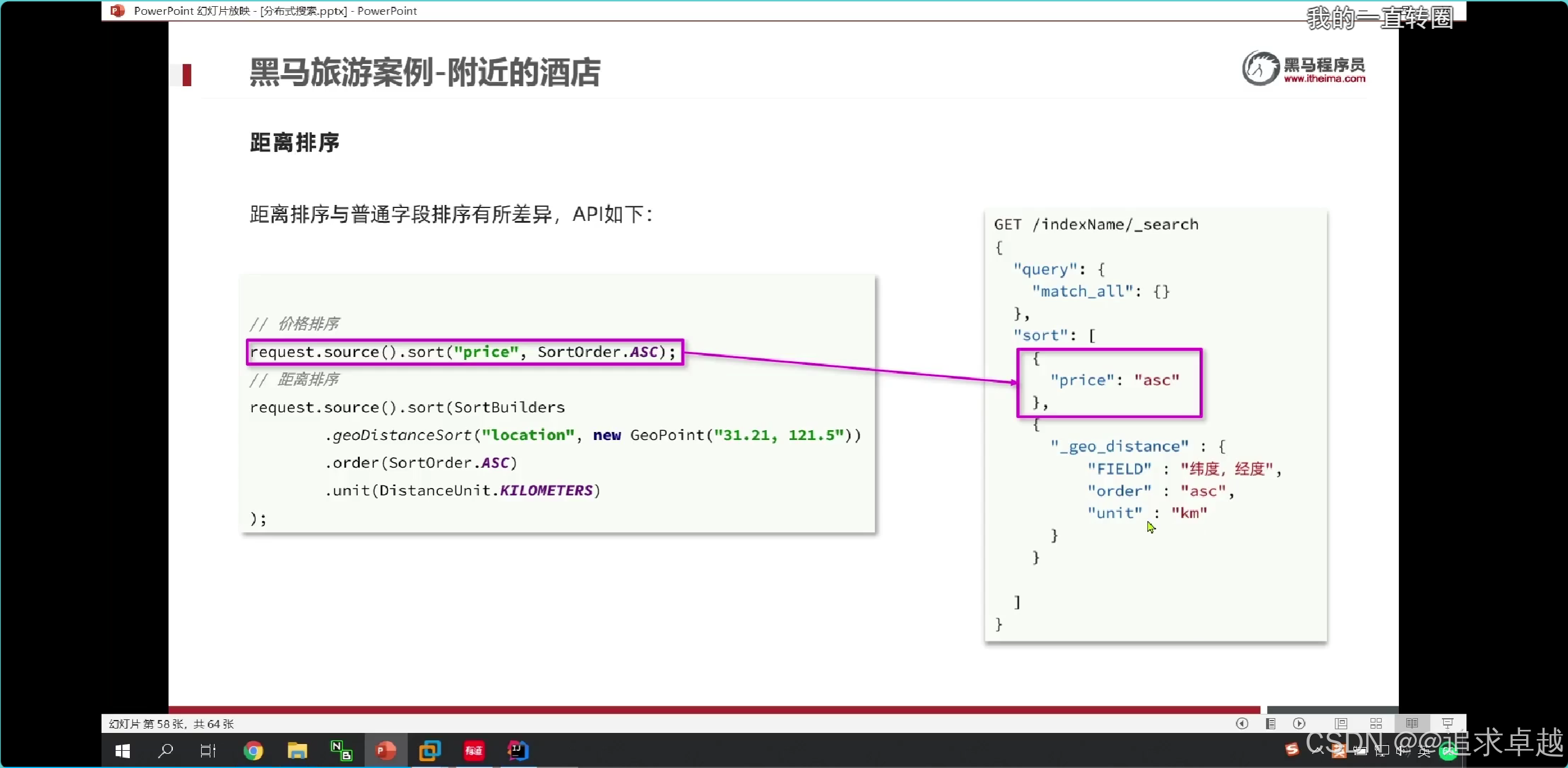
# 排序
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"score": {"order": "asc"},"price": {"order": "desc"}}]
}
# 地圖排序
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": {"lat": 31.034661,"lon": 121.612282},"order": "asc","unit": "km"}}]
}
分頁:es獲得990到1000的數據,是先找出0-1000數據,之后進行截取的,不擅長做這個。
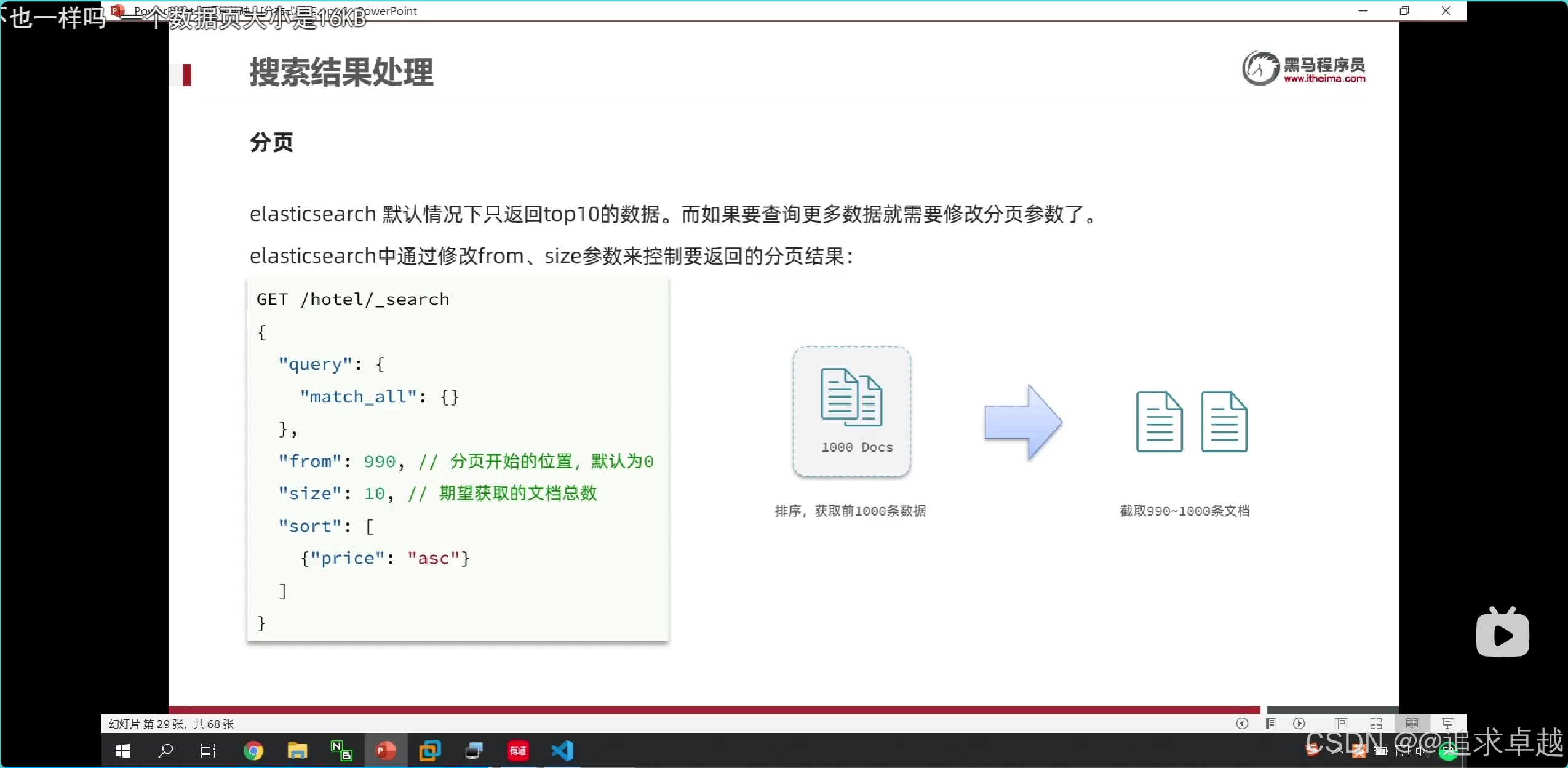
+
GET /hotel/_search
{"query": {"match_all": {}},"from":1,"size":10
}
在這里插入圖片描述
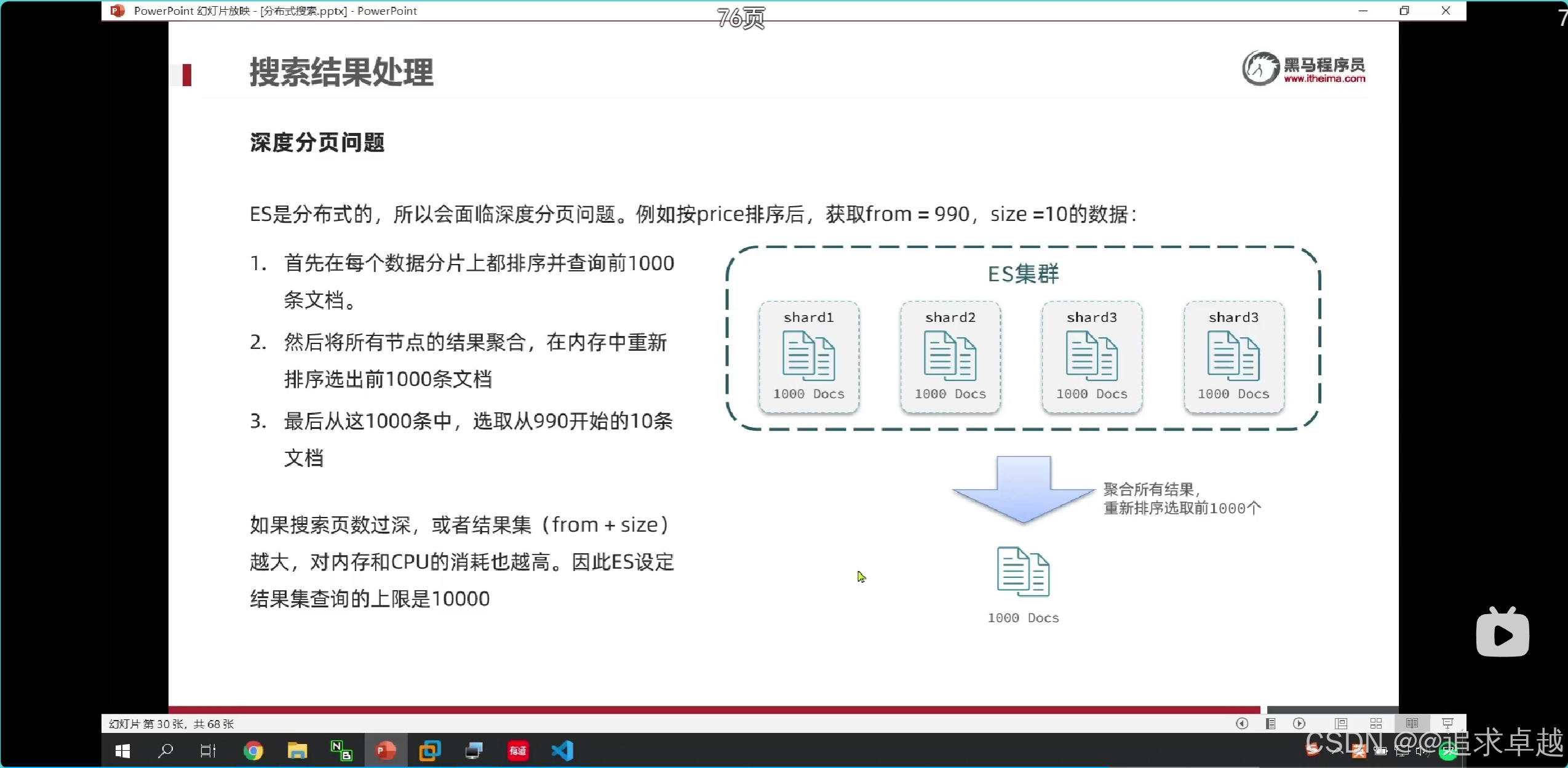
- 一個es就是排序之后獲得前面1000,之后進行截取。
- 多個就是先排序獲得前面1000,之后合在一個,進行排序獲得前面1000,之后進行截取。
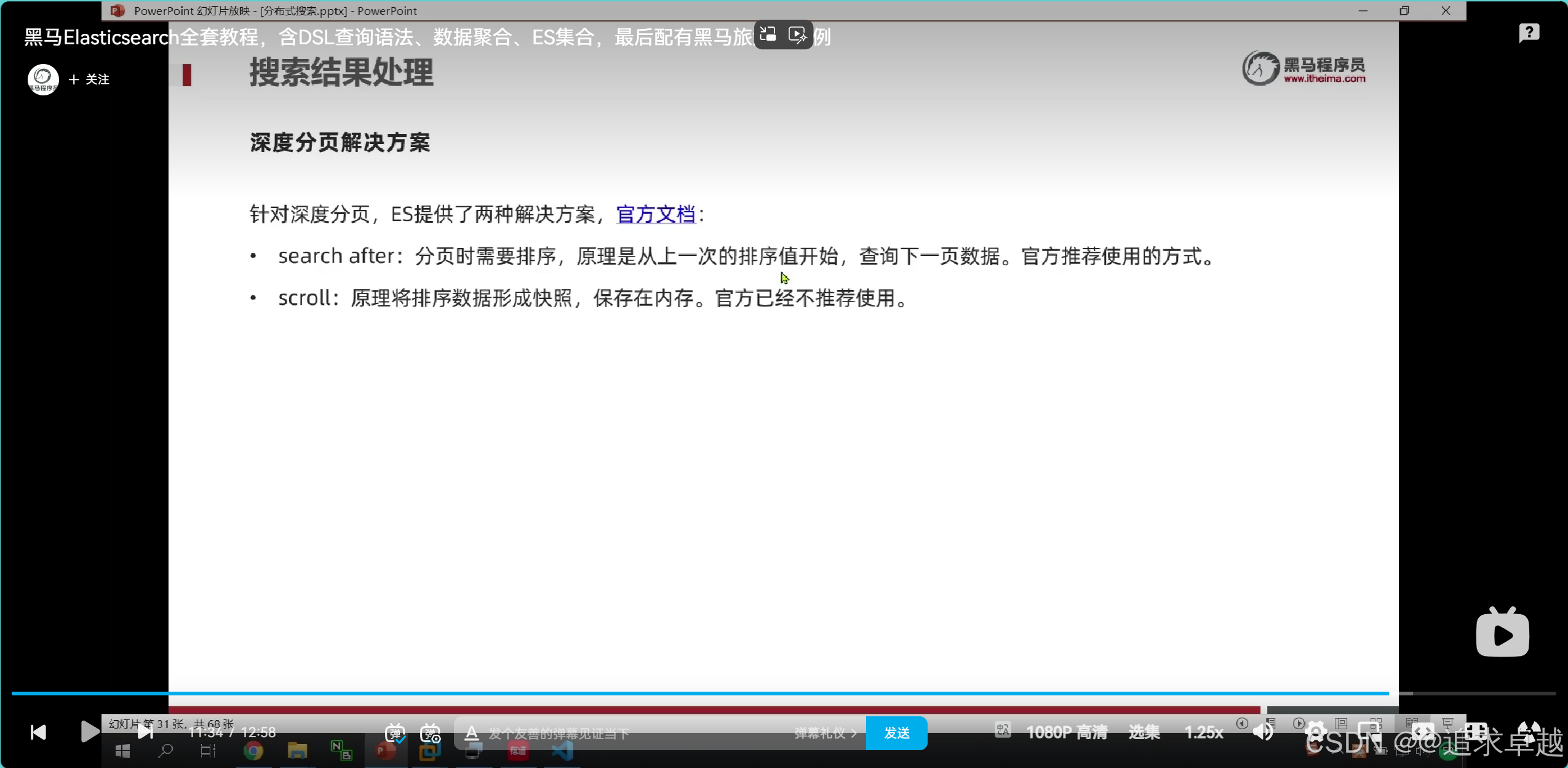
高亮處理
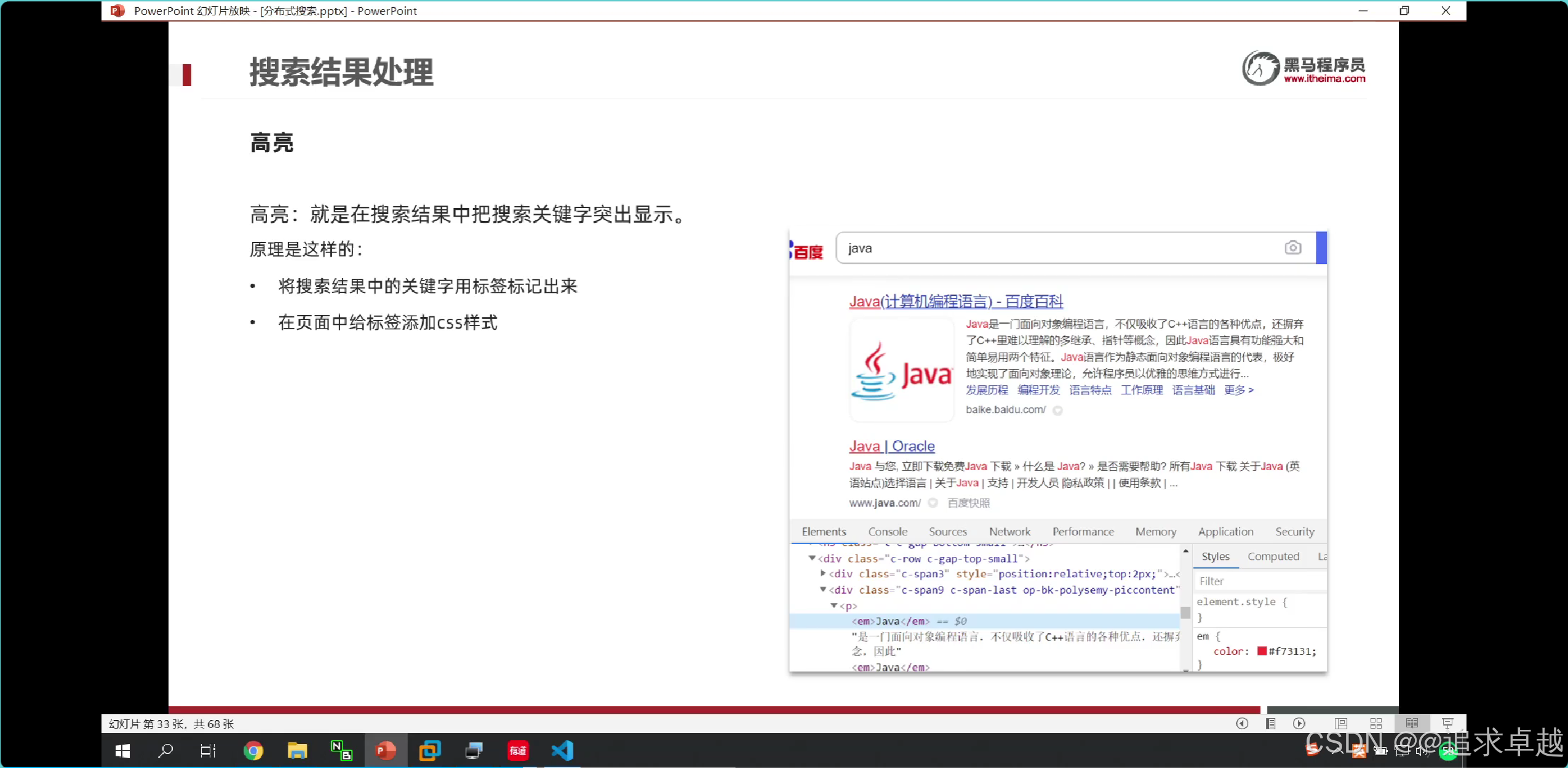
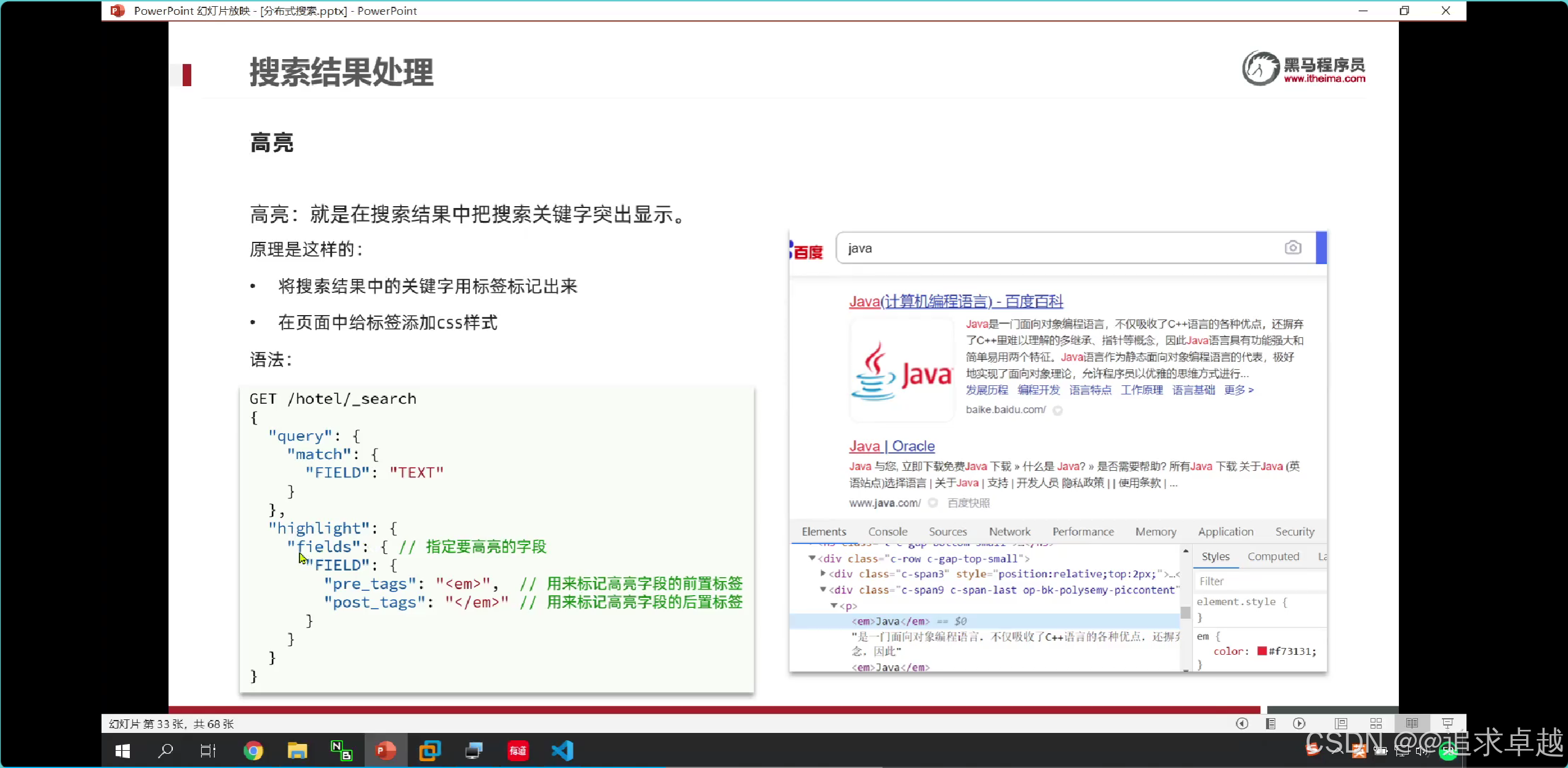
- 這種不是前端寫的
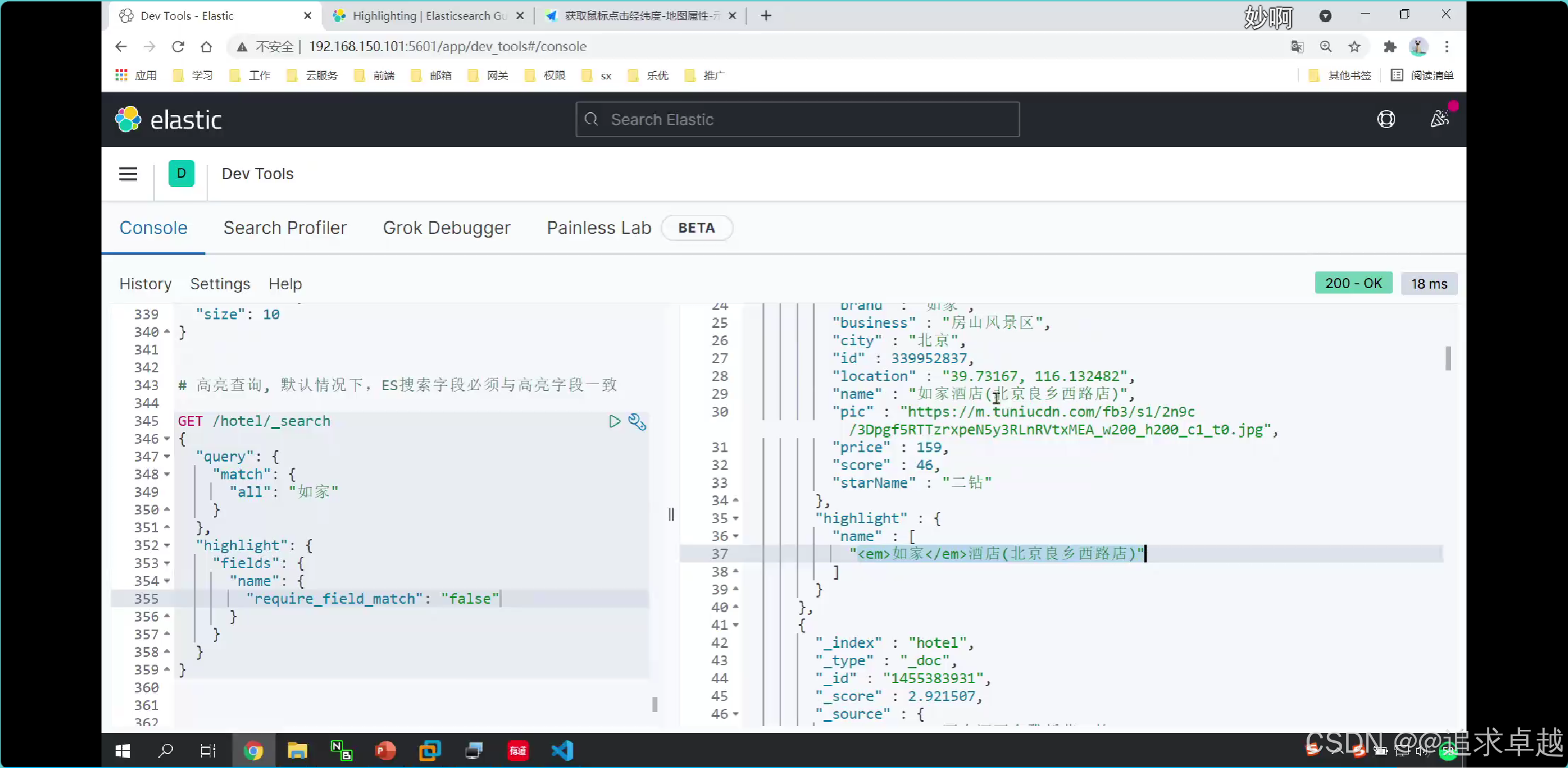

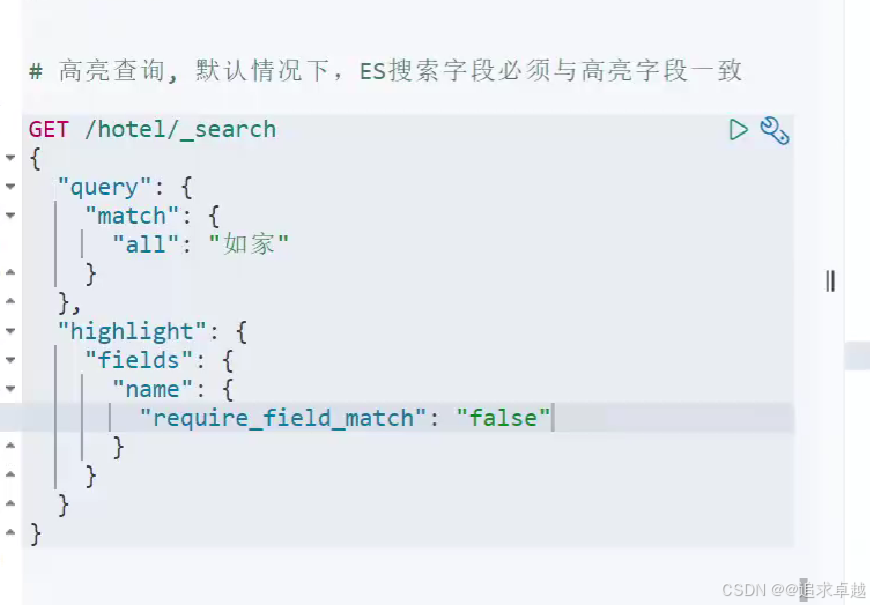
GET /hotel/_search
{"query": {"match": {"all": "如家"}},"highlight": {"fields": {"name": {"require_field_match": "false"}}}
}
DSL查詢作用
package cn.itcast.hotel;import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.blobstore.DeleteResult;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;
import java.util.List;import static cn.itcast.hotel.constants.HotelIndexConstants.MAPPING_TEMPLATE;@SpringBootTest
class HotelIndexTest {private RestHighLevelClient client;@Testvoid testCreateIndex() throws IOException {// 1.準備Request PUT /hotelCreateIndexRequest request = new CreateIndexRequest("hotel");// 2.準備請求參數request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.發送請求client.indices().create(request, RequestOptions.DEFAULT);}@Testvoid testExistsIndex() throws IOException {// 1.準備RequestGetIndexRequest request = new GetIndexRequest("hotel");// 3.發送請求boolean isExists = client.indices().exists(request, RequestOptions.DEFAULT);System.out.println(isExists ? "存在" : "不存在");}@Testvoid testDeleteIndex() throws IOException {// 1.準備RequestDeleteIndexRequest request = new DeleteIndexRequest("hotel");// 3.發送請求client.indices().delete(request, RequestOptions.DEFAULT);}@BeforeEachvoid setUp() {
// client = new RestHighLevelClient(RestClient.builder(
// HttpHost.create("http://192.168.150.101:9200")
// ));this.client= new RestHighLevelClient(RestClient.builder(HttpHost.create("http://127.0.0.1:9200")));}@AfterEachvoid tearDown() throws IOException {client.close();}@Testpublic void test1(){System.out.println(client);}@Testpublic void test2() throws IOException {CreateIndexRequest request=new CreateIndexRequest("hotel1");request.source(MAPPING_TEMPLATE,XContentType.JSON);client.indices().create(request,RequestOptions.DEFAULT);}@Testpublic void test3() throws IOException {DeleteIndexRequest request=new DeleteIndexRequest("hotel1");client.indices().delete(request,RequestOptions.DEFAULT);}@Testpublic void test4() throws IOException {GetIndexRequest hotel1 = new GetIndexRequest("hotel1");boolean exists = client.indices().exists(hotel1, RequestOptions.DEFAULT);System.out.println(exists);}@Autowiredprivate IHotelService hotelService;@Testpublic void test5() throws IOException {Hotel byId = hotelService.getById(38609);System.out.println(byId);HotelDoc hotelDoc = new HotelDoc(byId);// post /hotel/_doc/1IndexRequest hotel = new IndexRequest("hotel").id(hotelDoc.getId().toString());hotel.source(JSON.toJSONString(hotelDoc), XContentType.JSON);client.index(hotel, RequestOptions.DEFAULT);// IndexRequest indexRequest=new IndexRequest("hotel1").id("1");
// indexRequest.source("",RequestOptions.DEFAULT);
// client.index(indexRequest,RequestOptions.DEFAULT);}@Testpublic void test6() throws IOException {GetRequest hotel = new GetRequest("hotel", "38609");GetResponse documentFields = client.get(hotel, RequestOptions.DEFAULT);String sourceAsString = documentFields.getSourceAsString();System.out.println(sourceAsString);HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);System.out.println(hotelDoc);}
// post /hotel/_update/1
// 更新@Testpublic void test7() throws IOException {UpdateRequest hotel = new UpdateRequest("hotel", "38609");hotel.doc("price", 100,"city","上海浦東");client.update(hotel,RequestOptions.DEFAULT);}@Test //刪除public void test8() throws IOException {DeleteRequest deleteRequest = new DeleteRequest("hotel","38609");client.delete(deleteRequest, RequestOptions.DEFAULT);}// 這是一個從數據庫很多數據拿到拿到es中。@Testpublic void test9() throws IOException {BulkRequest bulkRequest = new BulkRequest();List<Hotel> hotelList = hotelService.list();for (Hotel hotel : hotelList) {HotelDoc hotelDoc = new HotelDoc(hotel);bulkRequest.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}client.bulk(bulkRequest, RequestOptions.DEFAULT);}
}
- 這是一個存儲的。
多條件查詢。
GET /your_index/_search
{"query": {"match": {"all": "搜索關鍵詞" // 在 all 字段中匹配關鍵詞}},"from": 0, // 分頁起始位置(頁碼-1)*每頁數量"size": 10, // 每頁返回文檔數"sort": [ // 排序規則(可多字段){ "price": "desc" }, // 按價格降序{ "_score": "desc" } // 按相關性評分降序(可選)]
}@Overridepublic PageResult search(RequestParams params) throws IOException {SearchRequest hotel = new SearchRequest("hotel");
// 這個是分詞查找,all是字段if(params.getKey() != null||params.getKey()!=""){hotel.source().query(QueryBuilders.matchQuery("all", params.getKey()));} else{hotel.source().query(QueryBuilders.matchAllQuery());}//分頁int page = params.getPage();int size = params.getSize();hotel.source().from((page-1)*size).size(size);//高亮顯示hotel.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));SearchResponse search = restClient.search(hotel, RequestOptions.DEFAULT);return handleResponse(search);}public PageResult handleResponse(SearchResponse response) {List<HotelDoc> arrayList = new ArrayList<>();SearchHits hits = response.getHits();
//獲得個數。long value = hits.getTotalHits().value;SearchHit[] hits1 = hits.getHits();for (SearchHit hit : hits1) {String sourceAsString = hit.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);arrayList.add(hotelDoc);}return new PageResult(value,arrayList);}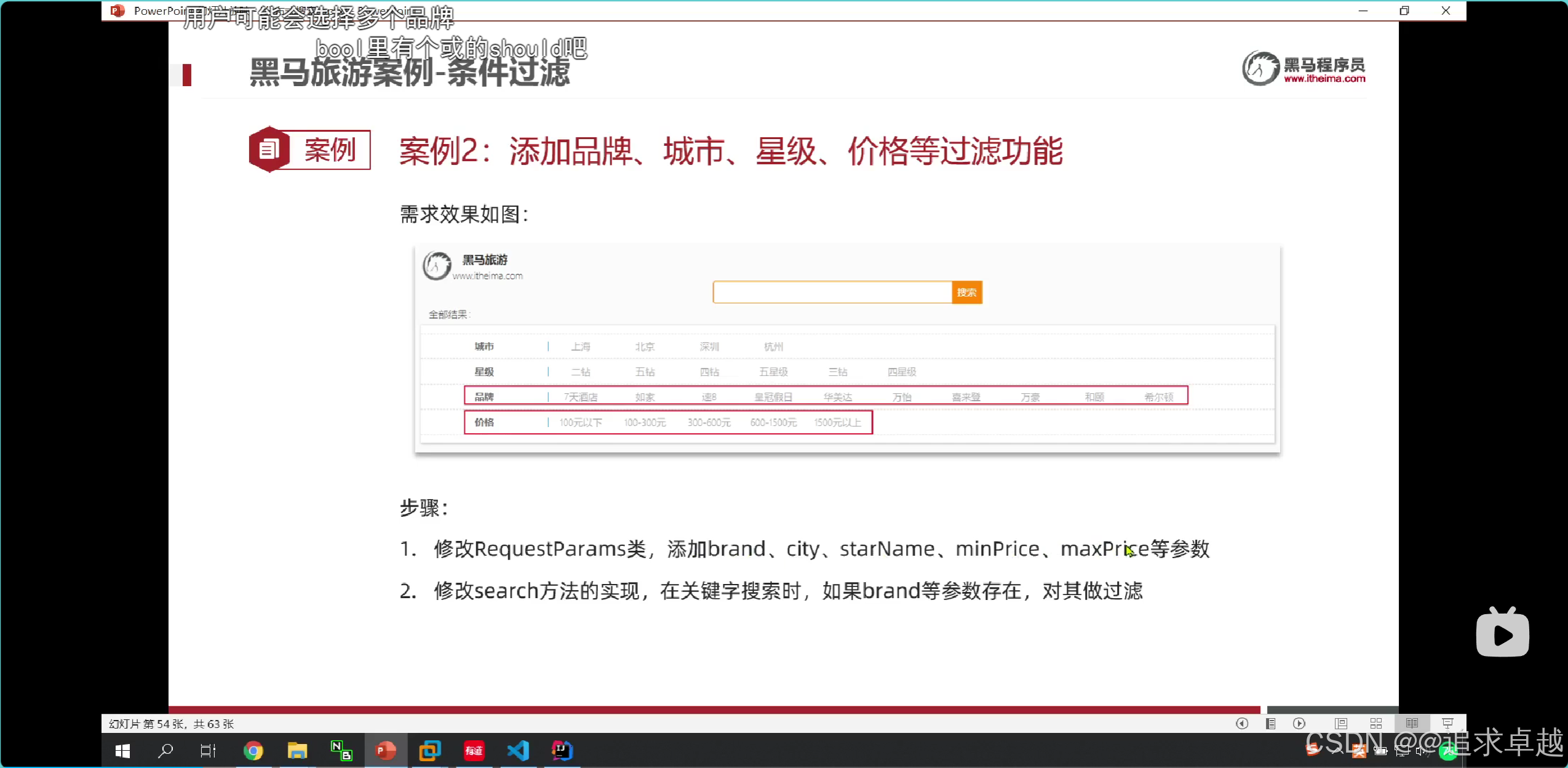
- 搜索一個字段下面每個都一個字段還有分頁操作。
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "泳池")) // 條件1.should(QueryBuilders.boolQuery() // 嵌套條件2.must(QueryBuilders.matchQuery("address", "外灘")).must(QueryBuilders.rangeQuery("price").lte(600)));
- 只有一個的話不需要
- 多個條件的話就是BoolQueryBuilder。
多條件問題
- must是and ,should是or ,must_no是非。
- term是準確,match 是分詞,range范圍.
距離排序
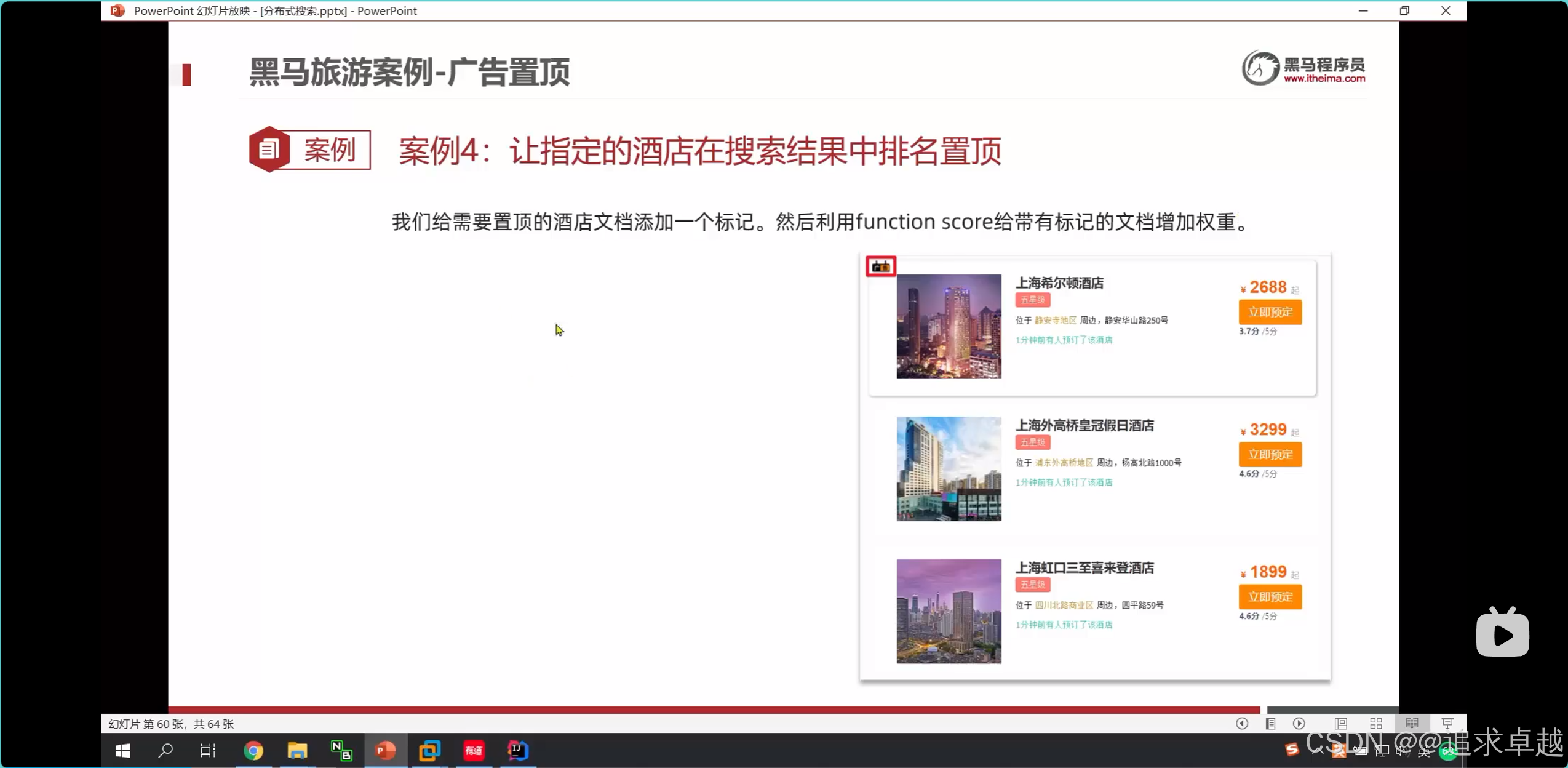
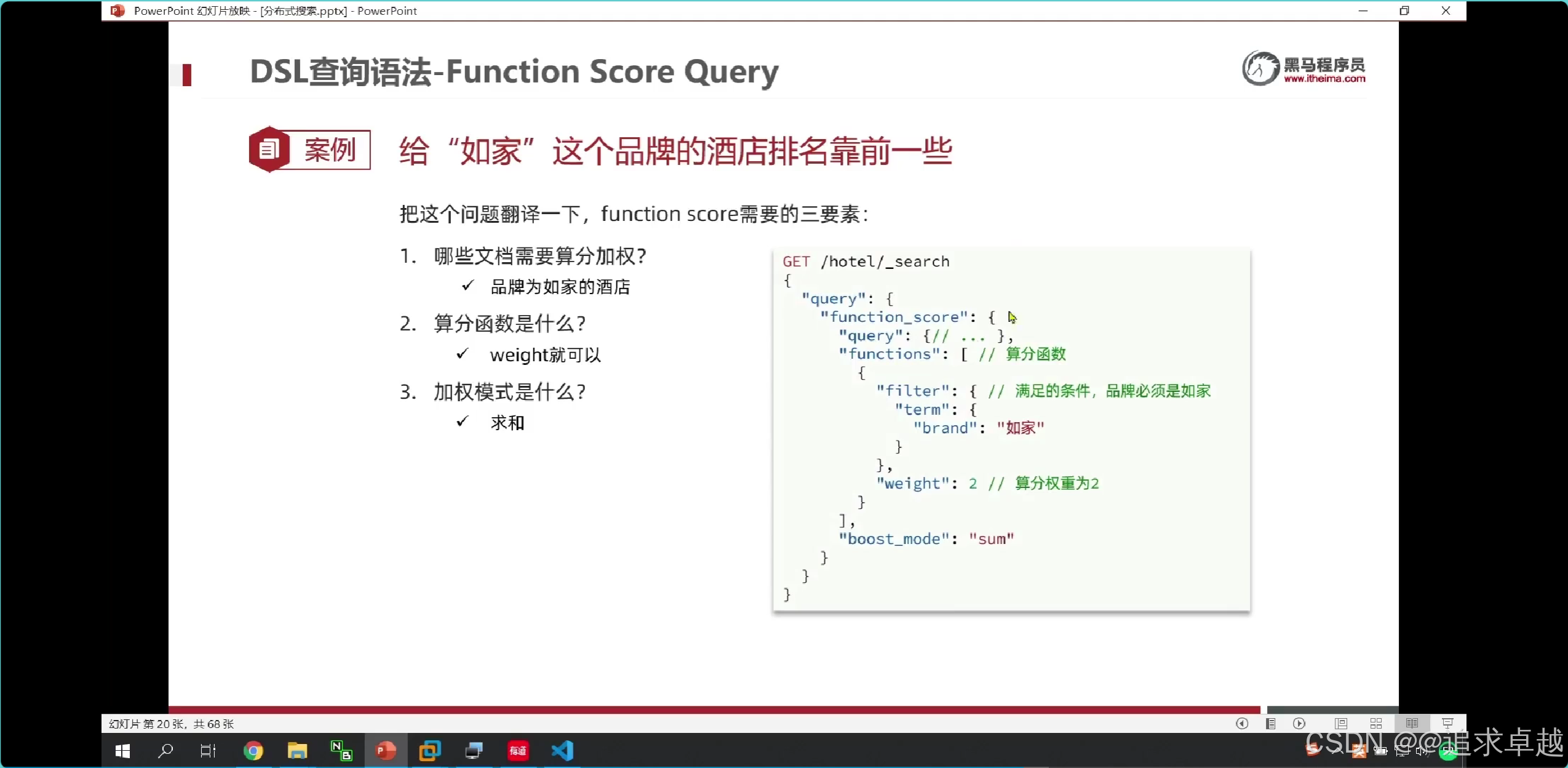
廣告定制
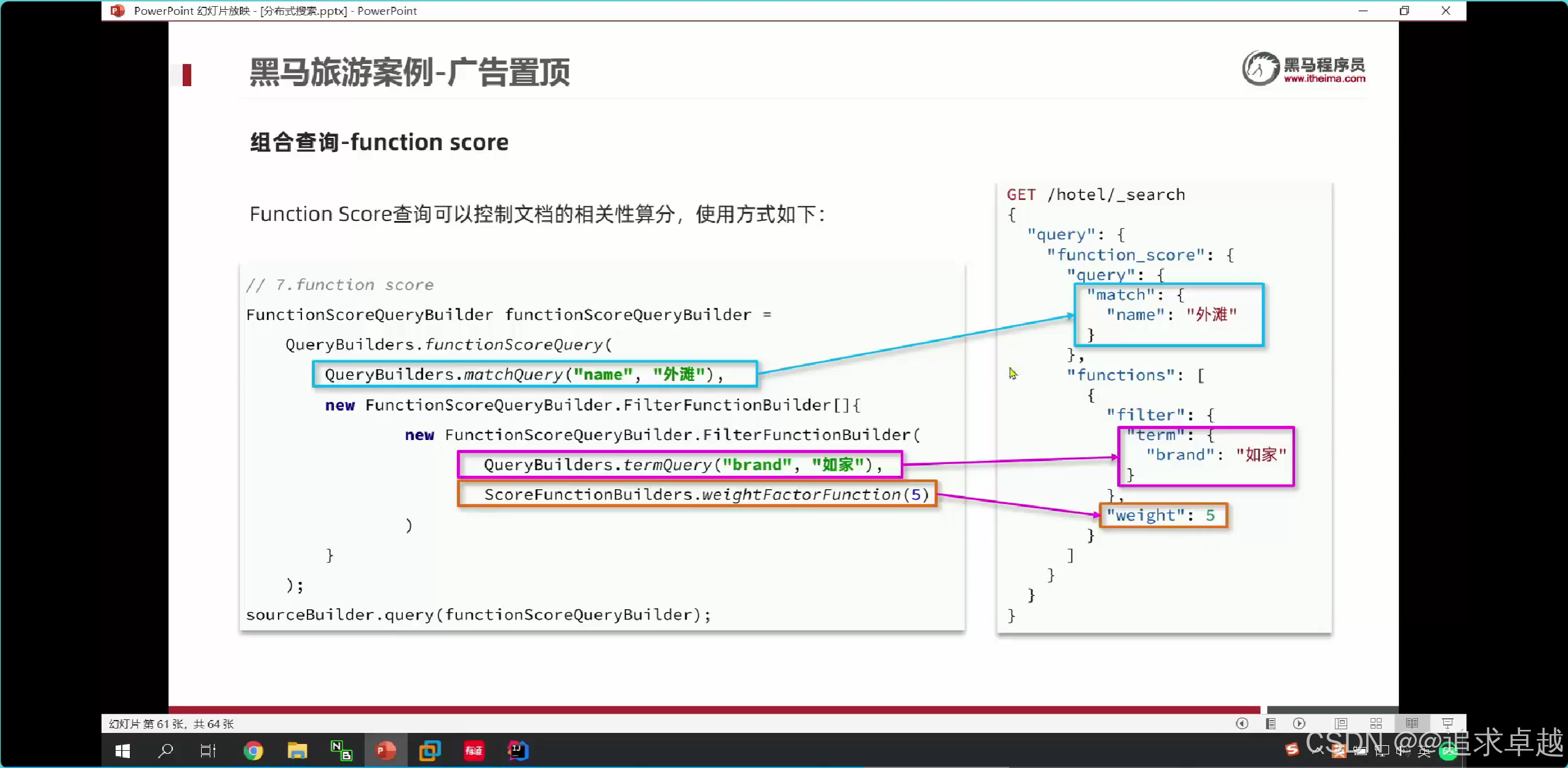
- functionScore是增加算分的。
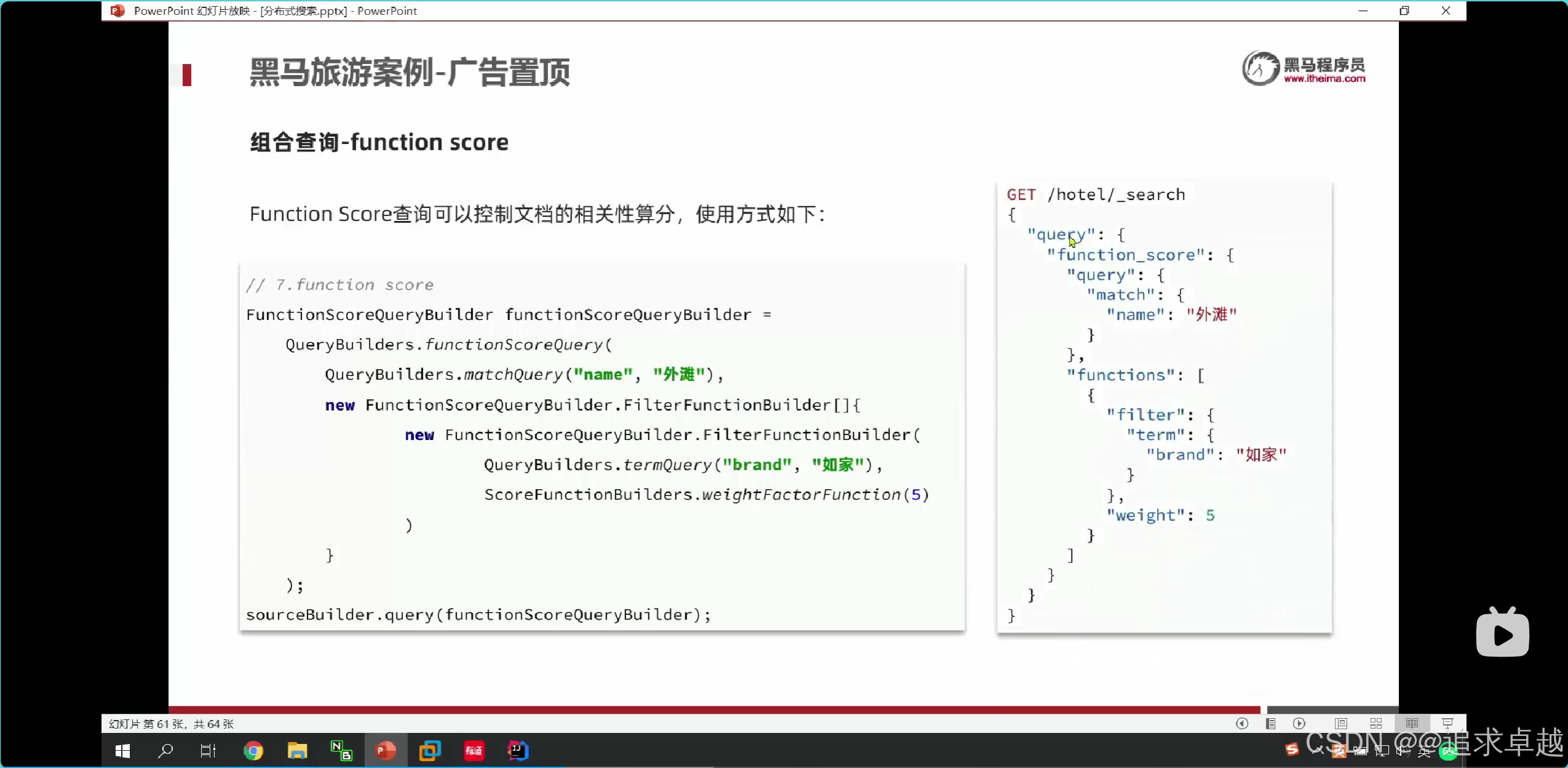
{"from": (page-1)*size,"size": size,"query": {"function_score": {"query": {"bool": {"must": [{"match": {"all": "用戶輸入的關鍵詞"}}],"filter": [{"term": {"city": "城市參數"}},{"term": {"brand": "品牌參數"}},{"term": {"starName": "星級參數"}},{"range": {"price": {"gte": 最低價,"lte": 最高價}}}]}},"functions": [{"filter": {"term": {"isAD": true}},"weight": 10}]}},"sort": [{"_geo_distance": {"location": "緯度,經度","order": "asc","unit": "km"}}]
}拼音分詞
GET /_analyze
{"text": ["如家酒店"], "analyzer": "ik_max_word"
}
GET /_analyze
{"text": ["如家酒店"], "analyzer": "pinyin"
}
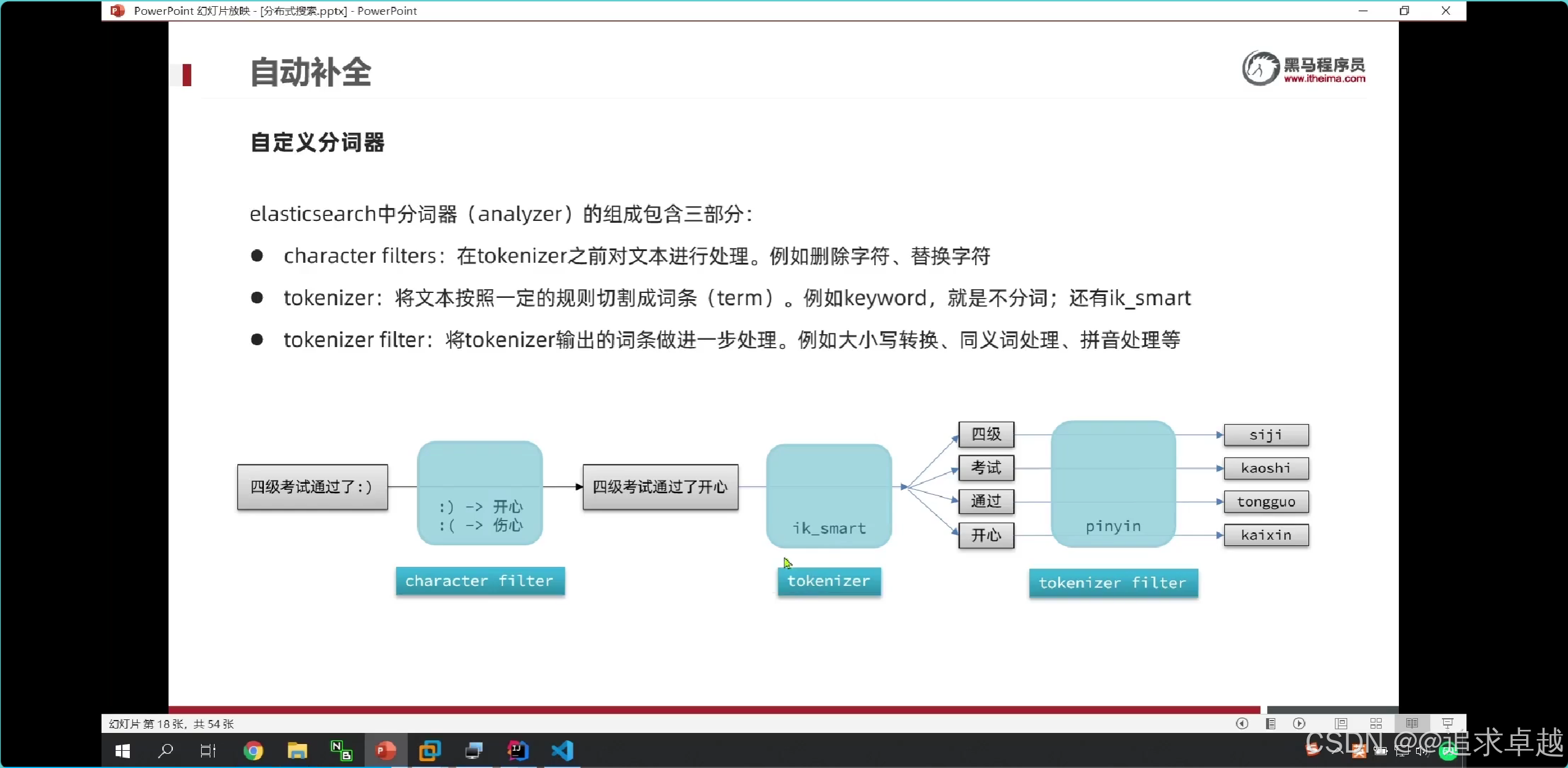
- 使用pinyin的話是, 他只有一個字一個拼音。
# 自定義分詞器。
PUT /test1
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_joined_full_pinyin": true,"keep_full_pinyin": false,"keep_original": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"name":{"type":"text","analyzer": "my_analyzer"}}}
}- 只會影響 name 字段.
分詞器,會把分詞字段分到倒排索引中;自定義分詞器是分出拼音和漢字到倒排中。
GET /test1/_analyze
{"text": ["如家酒店"], "analyzer": "my_analyzer"
}# 自定義分詞器。
PUT /test1
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_joined_full_pinyin": true,"keep_full_pinyin": false,"keep_original": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"name":{"type":"text","analyzer": "my_analyzer"}}}
}- 拼音分詞器就是name把所有的詞語有中文、英文變到倒排索引庫中。
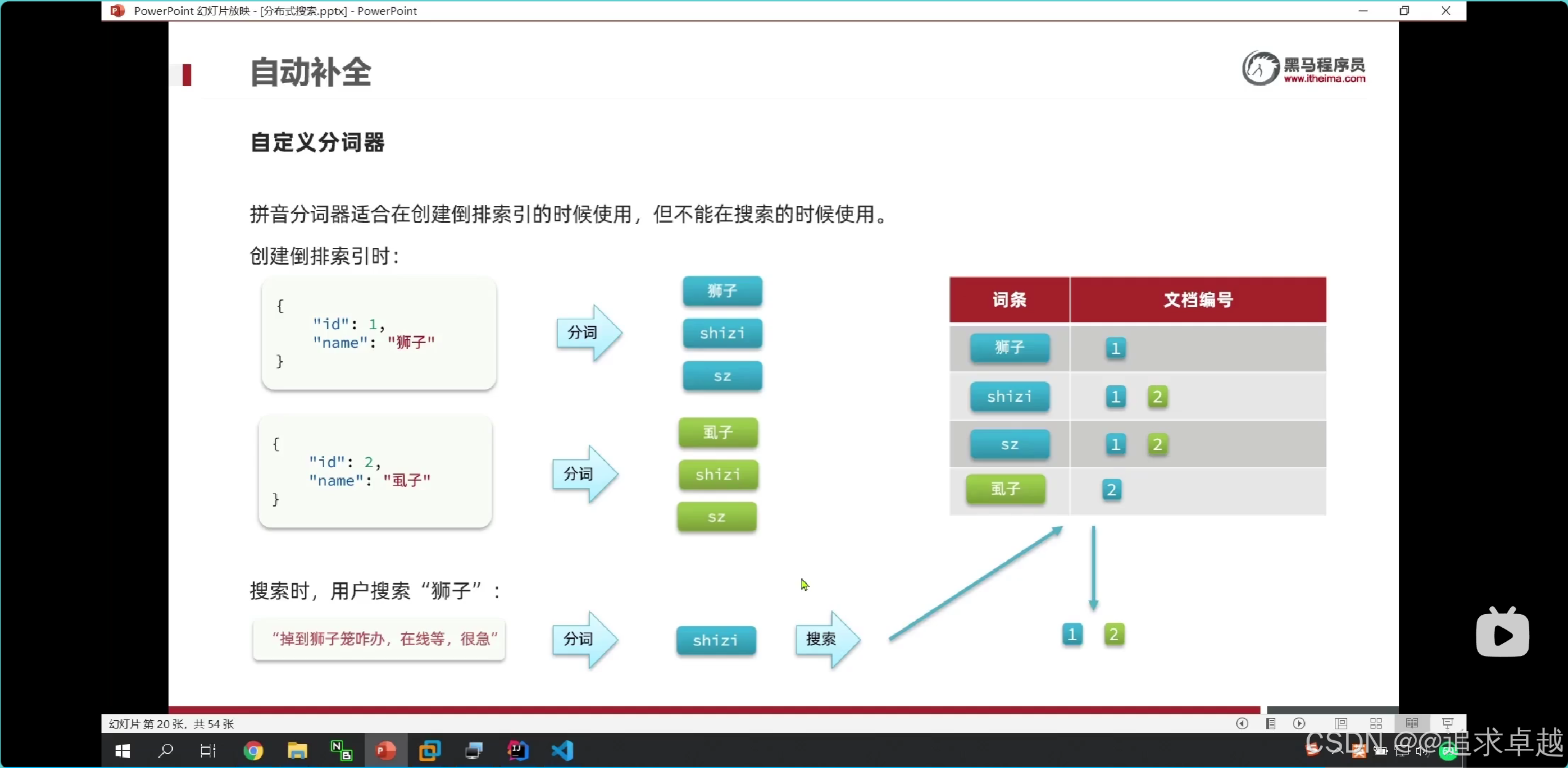
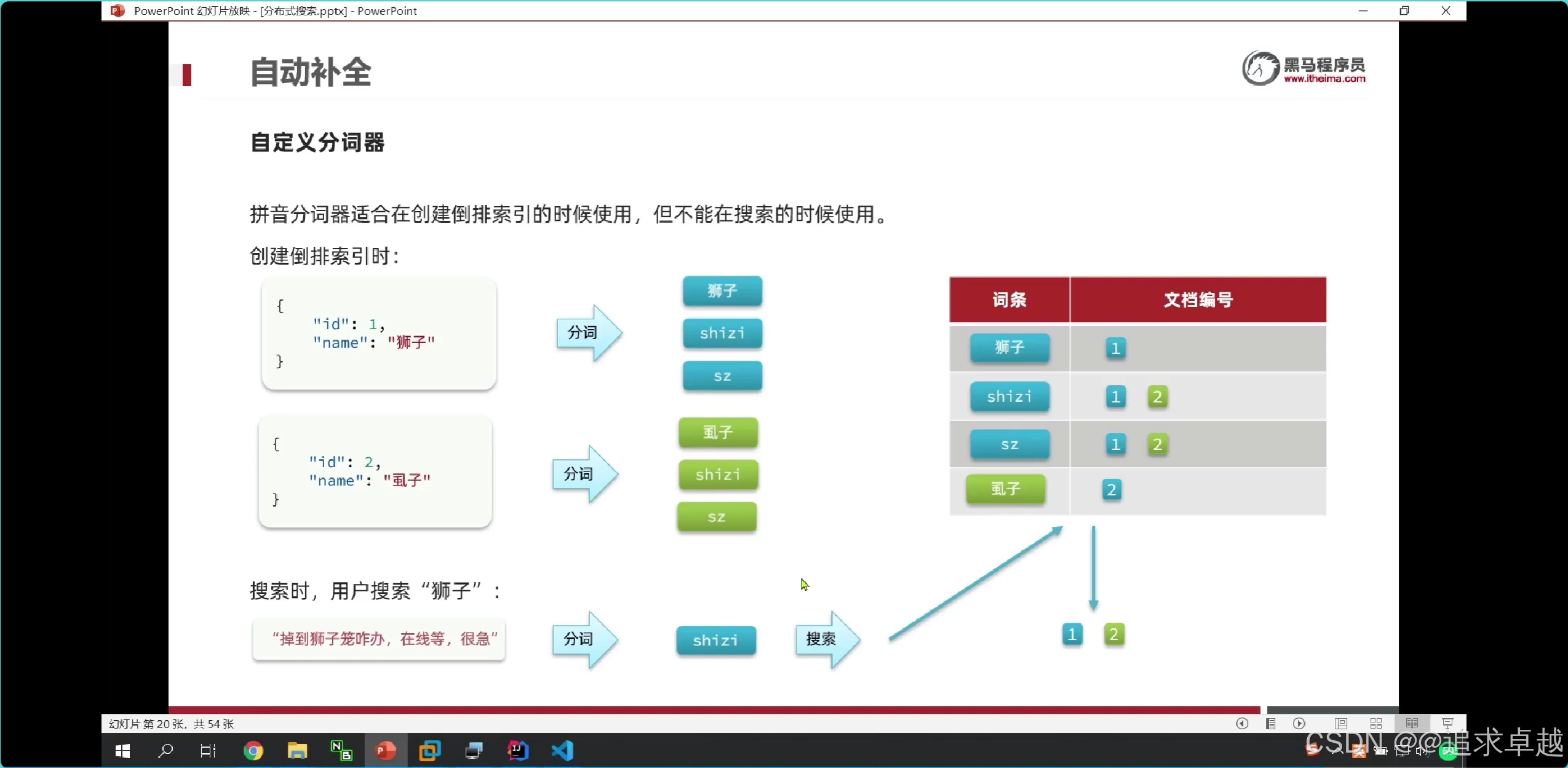
- 在shizi拼音的時候可以有1,2。查詢獅子就只有一個1.
- 在存儲的時候是拼音中文都存出倒排索引中。
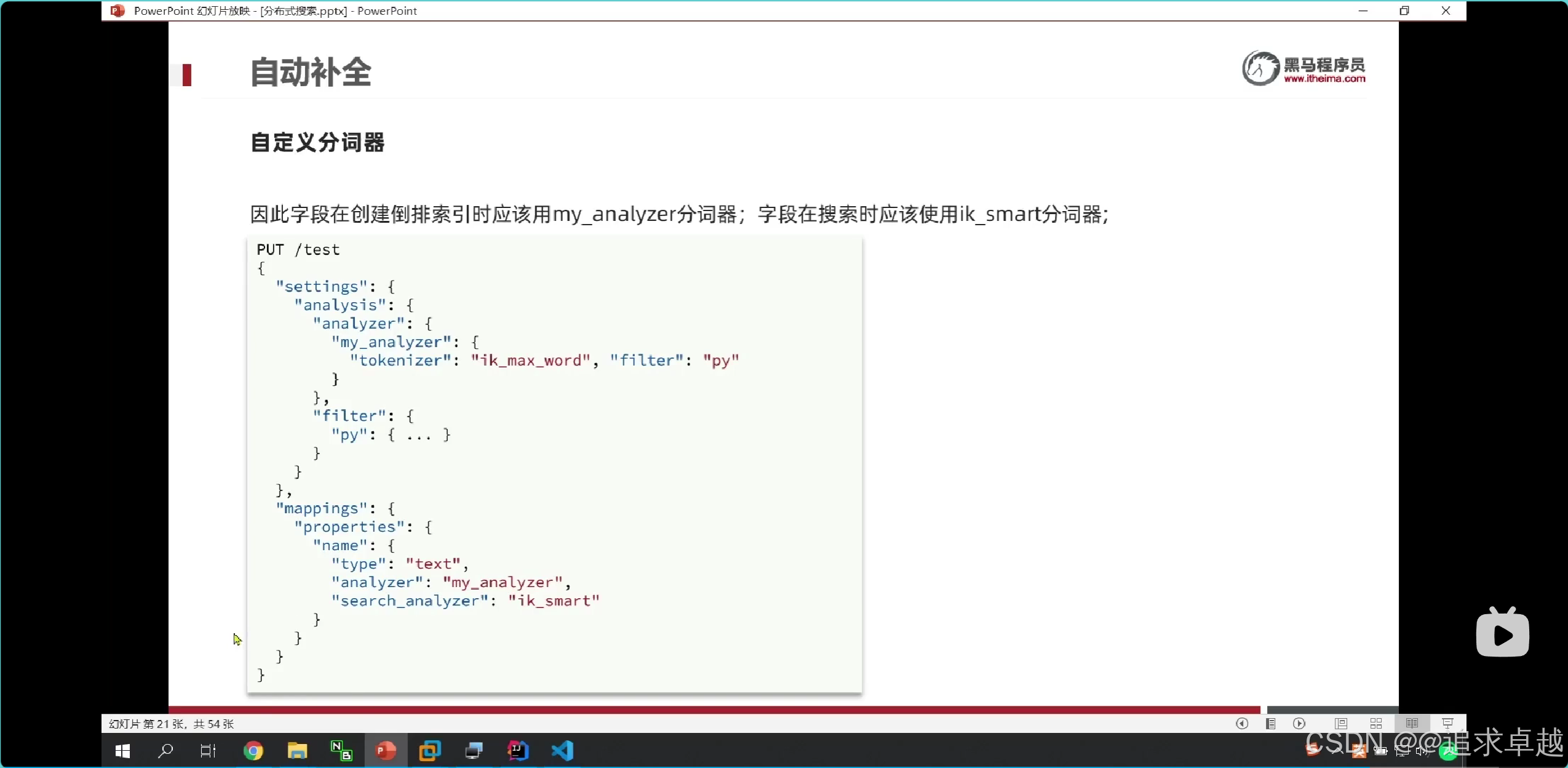
- 在搜索的時候只能中文查詢中文,拼音查詢拼音的。只有使用ik分詞器。
GET /test1
POST /test1/_doc
{"name":"獅子","id":1
}
POST /test1/_doc
{"name":"師資","id":2
}GET /test1/_search
{"query": {"match": {"name": "師資"}}
}

自動補全
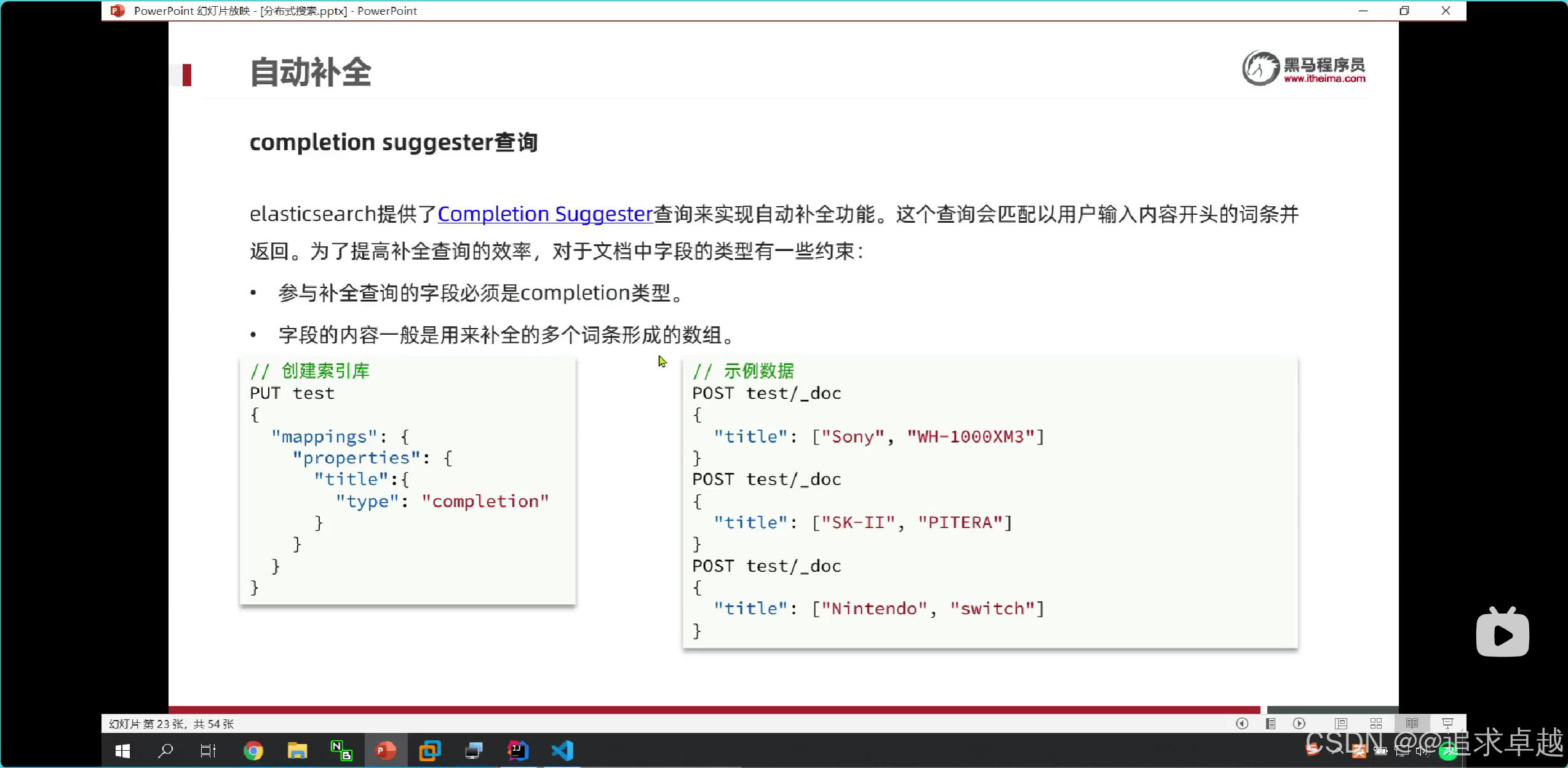
+
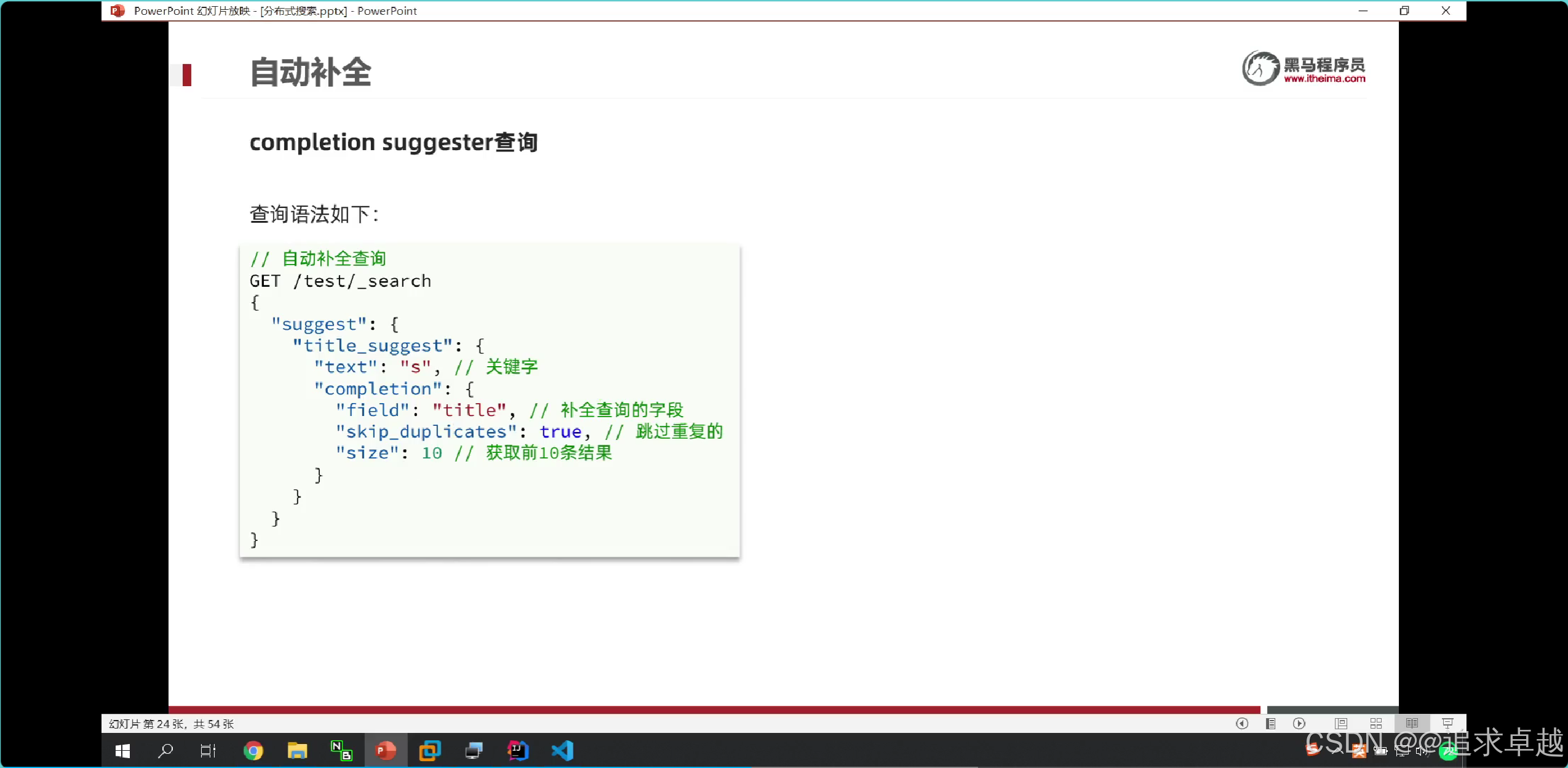
# 自定義分詞器。
PUT /test1
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_joined_full_pinyin": true,"keep_full_pinyin": false,"keep_original": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"name":{"type":"completion","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}DELETE /test1
GET /test1
POST /test1/_doc
{"name":"獅子","id":1
}
POST /test1/_doc
{"name":"師資","id":2
}GET /test1/_search
{"query": {"match": {"name": "師資"}}
}POST test1/_doc
{"name":["Sony","WH-1000XM3"]
}POST test1/_doc
{"name":["Sk-II","POYera"]
}
GET /test1/_search
{"suggest": {"name_suggest": {"text": "so","completion": {"field": "name","skip_duplicates":true,"size":10}}}
}
上面就是給title設置一個自定義分詞器,讓倒排索引有拼音和中文混合的。但是搜索就用ik分詞;之后給這個字段設置類型,之后給他搜索詞。
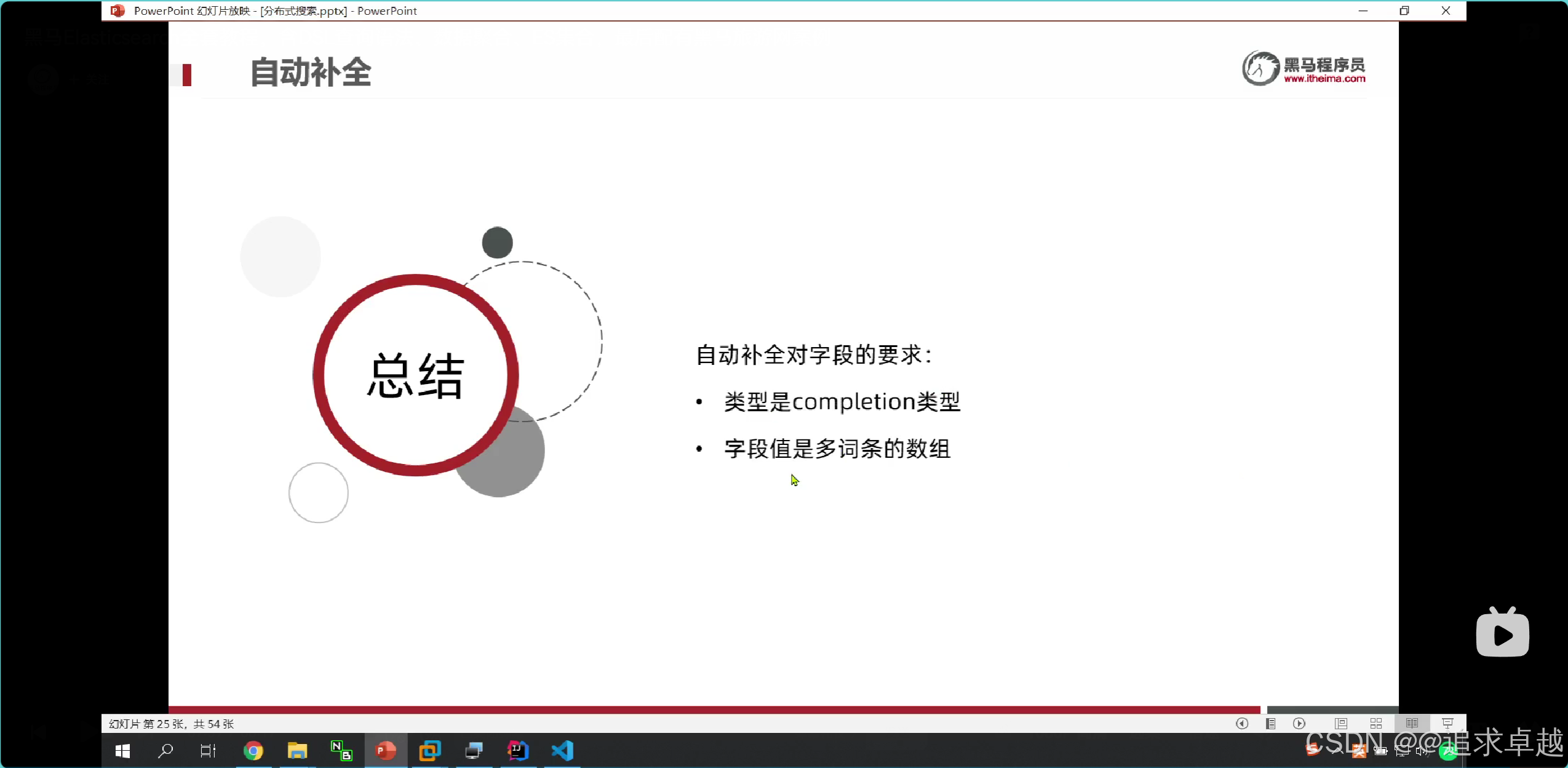
酒店數據補全
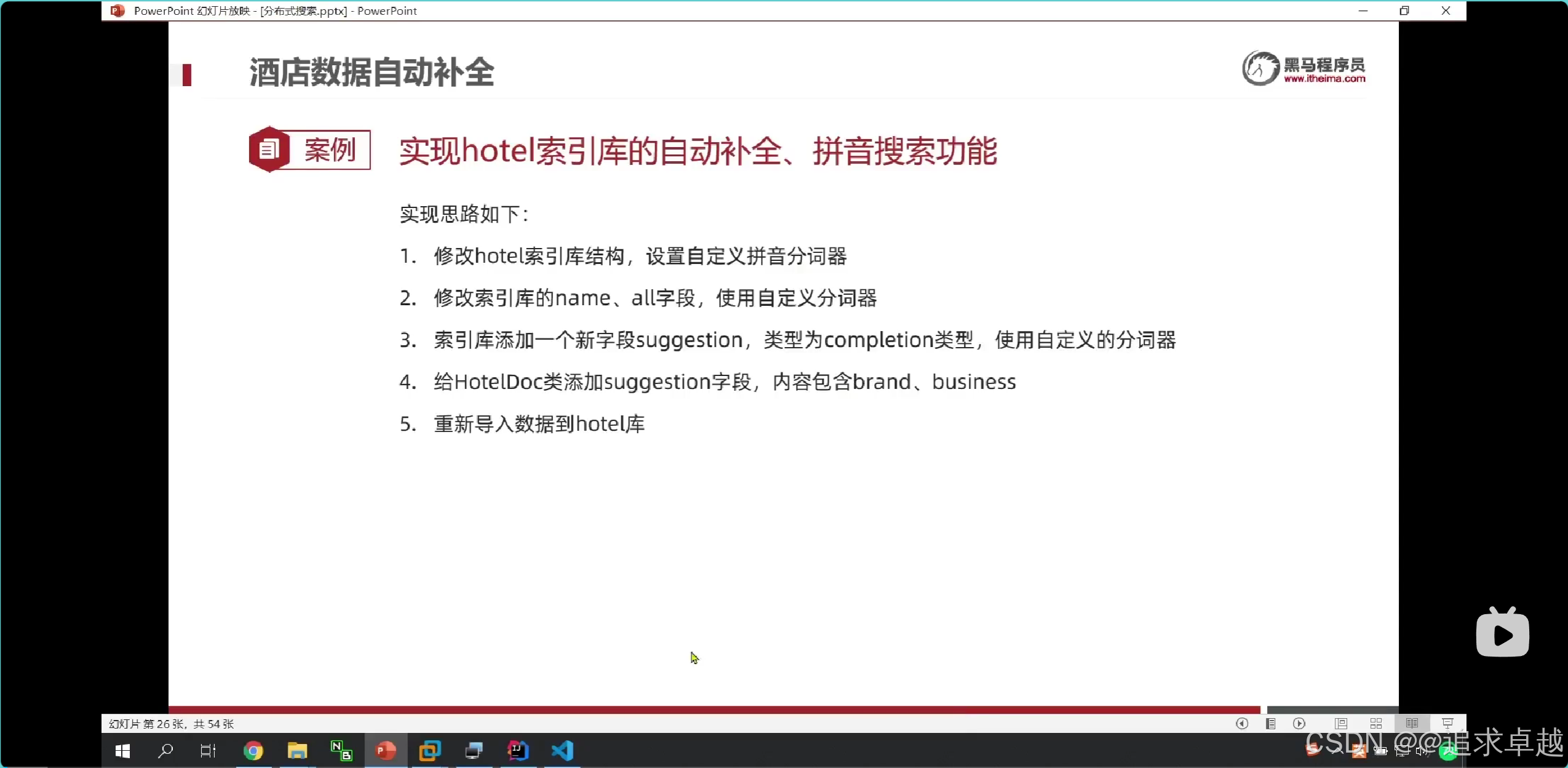 ## 自動補全字段的是分詞器里面是使用keyword的。
## 自動補全字段的是分詞器里面是使用keyword的。




)



![[論文梳理] 足式機器人規劃控制流程 - 接觸碰撞的控制 - 模型誤差 - 自動駕駛車的安全合規(4個課堂討論問題)](http://pic.xiahunao.cn/[論文梳理] 足式機器人規劃控制流程 - 接觸碰撞的控制 - 模型誤差 - 自動駕駛車的安全合規(4個課堂討論問題))


)






)
