上一篇 --- 網絡基礎概念(下)![]() https://blog.csdn.net/Small_entreprene/article/details/147320155?fromshare=blogdetail&sharetype=blogdetail&sharerId=147320155&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link
https://blog.csdn.net/Small_entreprene/article/details/147320155?fromshare=blogdetail&sharetype=blogdetail&sharerId=147320155&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link
理解源IP地址和目的IP地址
在我們當前的認識當中,IP地址是用來標識主機的唯一性的,后面我們會詳細的對IP進行分類。
數據傳輸到主機并不是最終目的,因為數據是給人使用的。例如,聊天是人在聊天,下載是人在下載,瀏覽網頁是人在瀏覽。那么,人是如何看到聊天信息、執行下載任務以及瀏覽網頁信息的呢?答案是通過啟動的 QQ、迅雷、瀏覽器等軟件。而這些啟動的 QQ、迅雷、瀏覽器等都是進程。換句話說,進程是人在系統中的代表,只要把數據交給進程,人就相當于拿到了數據。
因此,數據傳輸到主機只是手段,而不是目的。真正的目的是將數據傳輸到主機內部,并交給主機內的目標進程。
我們上網,其實可以概括成兩種行為:
- 從遠端服務器,獲取數據(刷抖音,其實就是將抖音推送到手機端)
- 本地數據,上傳到遠端服務器?(登入,將賬號密碼推送到遠端;上傳文件到百度網盤)
不管我們的上網行為有多么豐富多樣,在技術角度也就只有兩種情況,一種上傳,一種下載!因為我們的數據是通過進程來做的,進程又是在內存當中的,上網的時候,所有的數據都是要經過網卡的,而網卡需要將數據給網絡。(是進程和網卡之間的關系,網絡和網卡的關系)
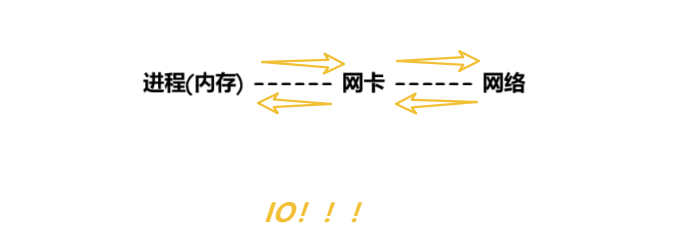
我們將上面兩者兩者之間的關系叫做IO!!!?說白了:馮諾依曼體系結構規定,網卡只能進行IO操作,就決定了我們的應用層軟件上,只能做獲取信息和發送信息的行為。
說明了網絡通信的本質就是兩個不同主機的進程在進行數據交互,更本質就是進程間通信!
進程間通信的本質就是要看到同一份資源,那么兩個不同主機的進程要看到的同一份資源又是誰呢?就是網絡!!!?(今天只是從在同一臺主機內進行進程間通信換成了在不同的兩臺主機間進行進程間通信而已)
我們現在知道,數據傳輸到主機只是手段,而不是目的。真正的目的是將數據傳輸到主機內部,并交給主機內的目標進程。然而,在系統中,同時會存在非常多的進程。因為收到的數據是要分配給一個或多個進程的,哪些數據對應哪一個進程,那么當數據到達目標主機之后,如何將數據轉發給目標進程呢?這需要在網絡的背景下,通過某種方式在系統中標識主機的唯一性,從而確保數據能夠準確地被轉發到目標進程。
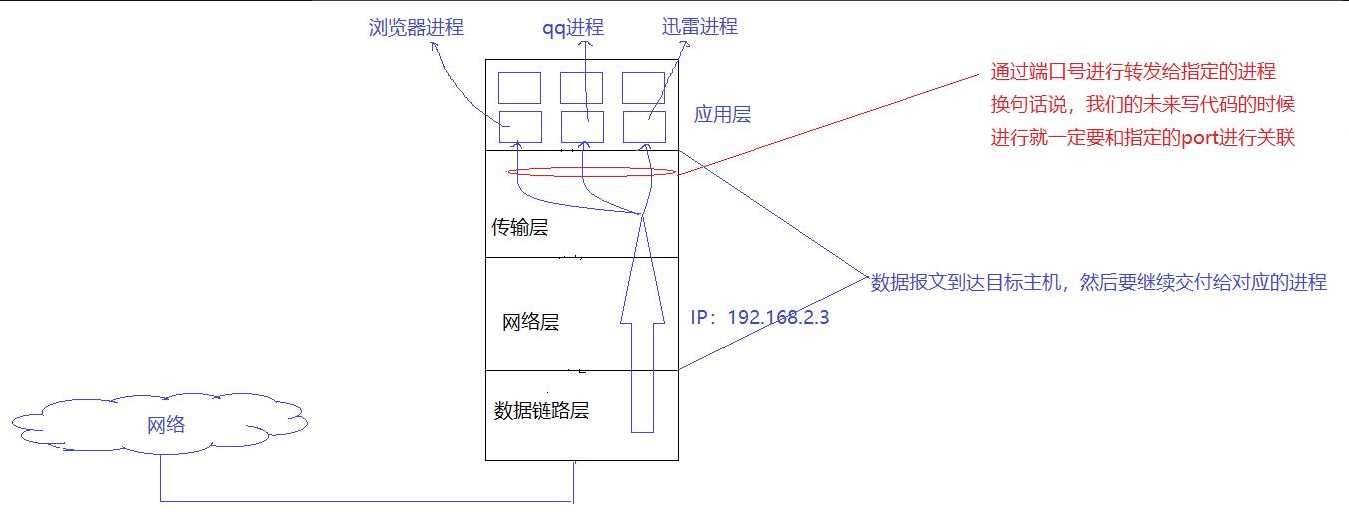
?我們主機會收到來自遠端主機發送來的各種數據,這些數據需要按照對應不同的數據分發到對應的進程當中,所以我們就必須要在系統層面上有一種辦法來標識主機的唯一性,為了能夠實現主機唯一性的標識,我們在網絡的范疇當中,我們就引入了新的概念:端口號!
認識端口號
端口號(Port)是傳輸層協議的內容。
-
端口號是一個2字節16位的整數。
-
端口號用來標識一個進程,告訴操作系統,當前的這個數據要交給哪一個進程來處理。(也就是說,未來寫的網絡服務,比如說QQ,這個網絡服務要進行啟動的時候,需要通過操作系統提供的一些系統調用來讓這個進行和對應的端口號(在傳輸層提取報文中的目的端口號)產生對應的關聯)
-
IP地址 + 端口號能夠標識網絡上的某一臺主機的某一個進程。
-
一個端口號只能被一個進程占用。(就是端口號可以用來標識系統中唯一的一個網絡進程!!!)(其實反過來,一個進程是可以和多個端口號進行綁定的,因為我們要的是從端口號查進程的方向是唯一的)
網絡通信的本質是全網范圍內唯二的兩個進程在進行進程間通信!!!我們用對方的IP和Port標識對方的唯一性。我們將IP+Port稱為Socket(套接字)
不過,端口號端口號可以用來標識系統中唯一的一個網絡進程,但是我們學習過,pid也是進程的唯一標識,那為什么不直接用進程pid呢?
不是所有的進程都需要進行網絡通信,不過我們從技術角度上來說,使用pid不使用端口號,這是可行的,但是pid是一個系統的概念,如果未來pid這個概念變化了,伴隨著網絡就需要變,這就是耦合性差,使用端口號就可以進行解耦!!!
端口號的范圍劃分是【0,65535】,因為是一個兩字節(16比特位)的整數
- 0 - 1023:知名端口號,HTTP、FTP、SSH 等這些廣為使用的應用層協議,它們的端口號都是固定的。
- 1024 - 65535:操作系統動態分配的端口號。客戶端程序的端口號,就是由操作系統從這個范圍分配的。
傳輸層協議(TCP 和 UDP)的數據段中有兩個端口號,分別叫做源端口號和目的端口號,就是在描述“數據是哪臺主機的哪一個進程發的,要發給哪臺主機上的哪一個進程”。
理解socket
綜上,IP 地址用來標識互聯網中唯一的一臺主機,port 用來標識該主機上唯一的一個網絡進程。
-
IP + Port 就能表示互聯網中唯一的一個進程。
-
所以,通信的時候,本質是兩個互聯網進程代表人來進行通信,{srcIp,srcPort,dstIp,dstPort}這樣的 4 元組就能標識互聯網中唯二的兩個進程。
-
所以,網絡通信的本質,也是進程間通信。
-
我們把 ip + port 叫做套接字 socket。
傳輸層的典型代表
如果我們了解了系統,也了解了網絡協議棧,我們就會清楚,傳輸層是屬于內核的。那么我們要通過網絡協議棧進行通信,必定調用的是傳輸層提供的系統調用,來進行網絡通信。
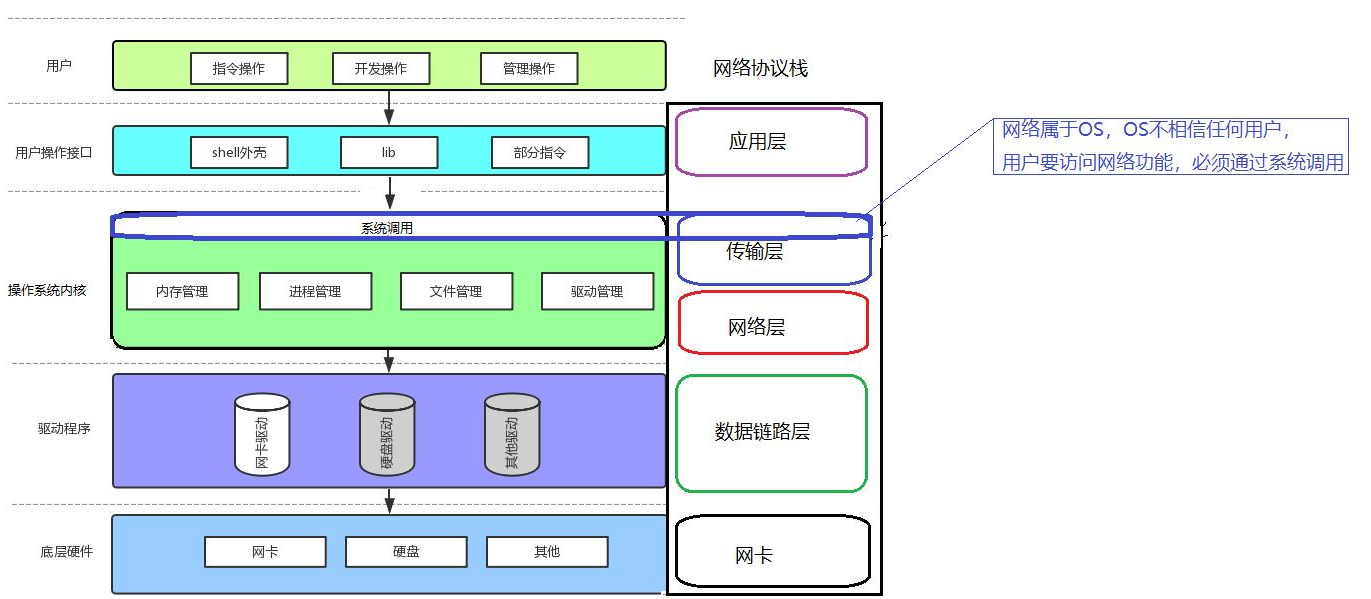
傳輸層有兩個重要協議:TCB和UDP。?
認識 TCP 協議
此處我們先對 TCP(Transmission Control Protocol 傳輸控制協議)有一個直觀的認識;后面我們再詳細討論 TCP 的一些細節問題。
-
傳輸層協議
-
有連接:在數據傳輸之前,需要先建立連接。(打電話,你喂我喂的過程就是建立連接的過程)
-
可靠傳輸:保證數據的完整性和順序性,通過確認和重傳機制確保數據可靠傳輸。
-
面向字節流:數據以字節流的形式傳輸,不保留消息邊界。(自來水,怎么接,接多少,都是自己自主決定的;文件打開也叫文件流,字節流和文件流沒有區別,都是流式的;學習完自定義協議后我們就能理解了)
認識 UDP 協議
此處我們也是對 UDP(User Datagram Protocol 用戶數據報協議)有一個直觀的認識;后面再詳細討論。
-
傳輸層協議
-
無連接:不需要建立連接,直接發送數據。(對講機)
-
不可靠傳輸:不保證數據的完整性和順序性,數據可能丟失或亂序到達。
-
面向數據報:數據以數據報的形式傳輸,保留消息邊界。(發快遞,發幾個就只能幾個)
TCP是可靠的,丟包了可以再發,但是UDP不可靠,那為什么還要保留UDP呢?(屬于同層協議,但是還保留一個不可靠的???)
我們要注意,這里的可靠和不可靠不可以將其視為貶義詞,而是一種中性詞,是一種特點。TCP保證可靠性,意味著他一定要做更多的工作,也就是意味著TCP協議會更加復雜一些,復雜帶來的就是占有資源會比較多。UDP協議就會很簡單,簡單的話就是代表開發周期短,可維護性好。
因為我們暫時還沒有深入了解 TCP 和 UDP 協議,此處只做了解即可。
網絡字節序
我們以前學過,計算機在存儲數據的時候,是有大端和小端的,大小端是按照字節為單位的。
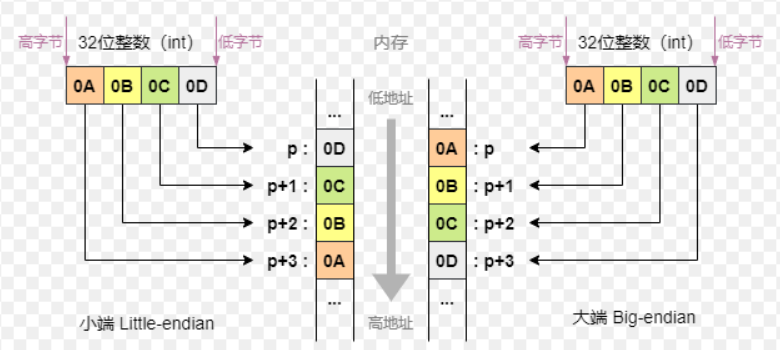
大端(Big-Endian)
定義:大端字節序是指高位字節存放在內存的低地址端,低位字節存放在內存的高地址端。
?假設有一個32位的整數 0x12345678,在大端字節序下,它在內存中的存儲順序如下:
內存地址: 0x00 0x01 0x02 0x03
存儲內容: 12 34 56 78-
0x12存儲在最低地址0x00 -
0x78存儲在最高地址0x03
小端(Little-Endian)(小-小-小)
定義:小端字節序是指低位字節存放在內存的低地址端,高位字節存放在內存的高地址端。
假設有一個32位的整數 0x12345678,在小端字節序下,它在內存中的存儲順序如下:
內存地址: 0x00 0x01 0x02 0x03
存儲內容: 78 56 34 12-
0x78?(低權值位:就是16的幾次方)存儲在最低地址0x00 -
0x12存儲在最高地址0x03
#include <stdio.h>// 函數:將整數從當前字節序轉換為網絡字節序(大端)
unsigned int htonl(unsigned int hostlong) {unsigned char *bytes = (unsigned char*)&hostlong;return ((unsigned int)(bytes[0] << 24) | (bytes[1] << 16) | (bytes[2] << 8) | bytes[3]);
}int main() {unsigned int x = 1;if (*((char *)&x) == 0) {printf("大端(Big-Endian)\n");} else {printf("小端(Little-Endian)\n");printf("轉換前的值:%u\n", x);// 調用 htonl 函數將整數轉換為大端字節序x = htonl(x);printf("轉換后(大端)的值:%u\n", x);}return 0;
}如果今天主機A是小端存儲,主機B是大端存儲,兩臺主機間要進行網絡通信,A將數據發送給B的話,主機B就解釋反了。所以在網絡當中,兩臺主機,如果主機間的存儲序列不同的話,經過網絡通信,會導致對方將接收到的數據解釋錯了!
所以在網絡中就有規定:凡是將數據發送到網絡當中的話,一定是要按照大端的形式發送!
發送主機通常將發送緩沖區中的數據按內存地址從低到高的順序發出。接收主機把從網絡上接到的字節依次保存在接收緩沖區中,也是按內存地址從低到高的順序保存。因此,網絡數據流的地址應這樣規定:先發出的數據是低地址,后發出的數據是高地址。TCP/IP 協議規定,網絡數據流應采用大端字節序,即低地址高字節。不管這臺主機是大端機還是小端機,都會按照這個 TCP/IP 規定的網絡字節序來發送/接收數據。如果當前發送主機是小端,就需要先將數據轉成大端;否則就忽略,直接發送即可。
為使網絡程序具有可移植性,使同樣的 C 代碼在大端和小端計算機上編譯后都能正常運行,可以調用以下庫函數做網絡字節序和主機字節序的轉換。

-
這些函數名很好記,h 表示 host,n 表示 network,l 表示 32 位長整數,s 表示 16 位短整數。
-
例如,
htonl表示將 32 位的長整數從主機字節序轉換為網絡字節序,例如將 IP 地址轉換后準備發送。 -
如果主機是小端字節序,這些函數將參數做相應的大小端轉換然后返回。
-
如果主機是大端字節序,這些函數不做轉換,將參數原封不動地返回。
注意:所有發送到網絡上的數據,都必須是大端的!
socket編程接口
socket常見API
// 創建 socket 文件描述符 (TCP/UDP, 客戶端 + 服務器)
int socket(int domain, int type, int protocol);// 綁定端口號 (TCP/UDP, 服務器)
int bind(int socket, const struct sockaddr *address, socklen_t address_len);// 開始監聽 socket (TCP, 服務器)
int listen(int socket, int backlog);// 接收請求 (TCP, 服務器)
int accept(int socket, struct sockaddr* address, socklen_t* address_len);// 建立連接 (TCP, 客戶端)
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);這些API的詳細細節我們會在后續寫代碼的時候進行說明。
我們發現大部分的接口參數中都有const struct sockaddr*的結構體指針(其他暫時不關心)
下面,我們來聊一聊這個sockaddr這個結構體。
sockaddr結構體
我們現在清楚,網絡通信的本質其實是進程間通信,我們之前學習的system V這個標準屬于本地之間進行進程間通信,我們后面還會見到的POSIX標準,這個是主要用于網絡通信的,網絡通信也是進程通信,也能進行本地通信的,也就是為什么我們之前說System V版本的進程間通信被淘汰了,因為POSIX這套標準,我們直接就可以進行了,還順帶了網絡通信。
socket套接字會有許多不同的種類來滿足各種各樣的不同的應用場景--網絡socket/本地socket(unix域間通信)/原始socket,原始socket我們不需要考慮,未來我們只需要學懂網絡socket,本地socket我們自然而然也就清楚了。也是正因為有不同的場景的socket,我們socket未來的接口,也是會有不同的通信接口規范(網絡的一套,本地的一套......)但是socket的設計者并不想這么干,只想要提供一套通信接口!!!(這一套既可以做網絡通信,也可以做本地通信)
所以就需要對接口進行設計,為了能夠支持設計出來的接口可以進行不同種類的通信,就設計了一個結構體---sockaddr結構體!
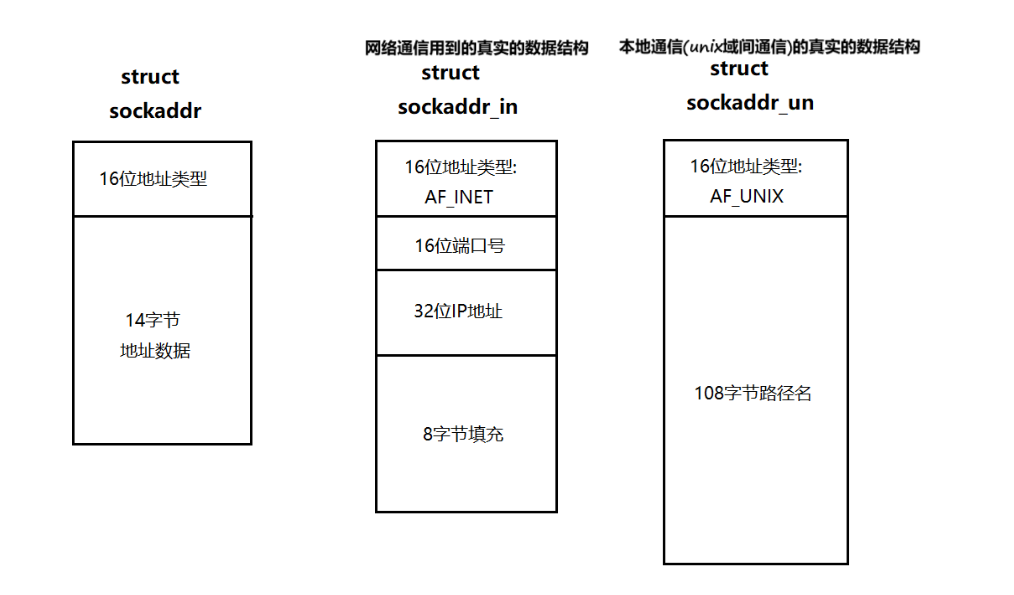
-
通用性:
struct sockaddr提供了一個通用的接口,適用于各種網絡協議。 -
專用性:
struct sockaddr_in和struct sockaddr_un分別針對IPv4網絡通信和本地通信進行了優化,提供了必要的信息和靈活性。
在網絡編程中,sockaddr 結構體及其相關的結構體如 sockaddr_in 和 sockaddr_un 經常需要進行強制類型轉換。這是因為 sockaddr 是一個通用的地址結構體,設計用來支持多種不同的網絡協議和地址類型。而 sockaddr_in 和 sockaddr_un 是針對特定協議(如IPv4、IPv6和UNIX域套接字)的具體實現。
當你需要將 sockaddr_in 或 sockaddr_un 結構體傳遞給需要 sockaddr 類型參數的函數時,通常需要進行強制類型轉換。例如,在調用 bind() 或 connect() 函數時,你需要將 sockaddr_in 結構體的地址轉換為 sockaddr 類型的指針。
這樣做的原因是因為 sockaddr 結構體定義了一個通用的接口,它包含了一個地址族字段(sa_family),用于指示地址的具體類型。sockaddr_in 和 sockaddr_un 結構體都以這個地址族字段開始,但它們包含的地址信息不同。通過將它們轉換為 sockaddr 類型,你可以確保函數能夠正確識別和處理不同類型的地址。
至于為什么不將參數設置為 void*,原因在于 void* 類型雖然可以指向任何類型的數據,但它不提供足夠的信息來處理不同協議的地址。使用 sockaddr 類型及其派生的結構體可以提供必要的語義信息,使函數能夠根據地址類型字段來正確處理地址數據。此外,原始套接字API是在1983年發布的,早于1989年的ANSI C標準,其前身——K&R C——根本沒有 void *,所以您無論如何都必須將其轉換為某個東西。
其實本質就是繼承和多態:(C語言實現的)
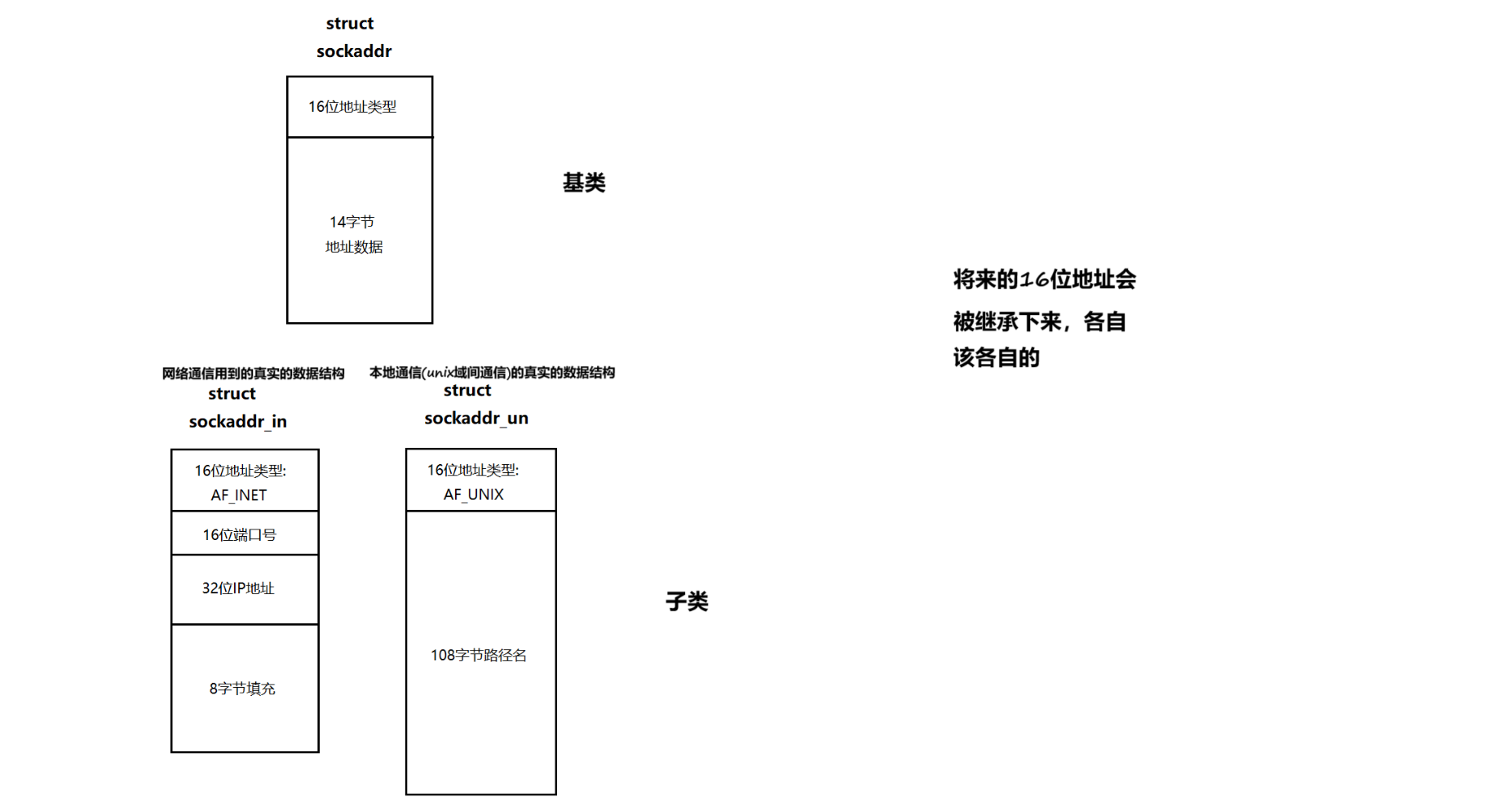
)
)


上使用Qt編譯時遇到“type_traits文件未找到”的錯誤)








:專業級地理數據可視化賞析-《杭州市國土空間總體規劃(2021-2035年)》)





