1. 自然語言處理基礎概念
1.1 什么是自然語言處理
自然語言處理( Natural Language Processing, NLP)是計算機科學領域與人工智能領域中的一個重要方向。它研究能實現人與計算機之間用自然語言進行有效通信的各種理論和方法。自然語言處理是一門融語言學、計算機科學、數學于一體的科學。因此,這一領域的研究將涉及自然語言,即人們日常使用的語言,所以它與語言學的研究有著密切的聯系,但又有重要的區別。自然語言處理并不是一般地研究自然語言,而在于研制能有效地實現自然語言通信的計算機系統,特別是其中的軟件系統。因而它是計算機科學的一部分。
1.2 自然語言處理的應用領域
自然語言處理主要應用于機器翻譯、輿情監測、自動摘要、觀點提取、文本分類、問題回答、文本語義對比、語音識別、中文OCR等方面。
- 文本檢索:多用于大規模數據的檢索,典型的應用有搜索引擎。
- 機器翻譯:跨語種翻譯,該領域目前已較為成熟。目前谷歌翻譯已用上機翻技術。
- 文本分類/情感分析:本質上就是個分類問題。目前也較為成熟,難點在于多標簽分類(即一個文本對應多個標簽,把這些標簽全部找到)以及細粒度分類(二極情感分類精度很高,即好中差三類,而五級情感分類精度仍然較低,即好、較好、中、較差、差)
- 信息抽取:從不規則文本中抽取想要的信息,包括命名實體識別、關系抽取、事件抽取等。應用極廣。
- 序列標注:給文本中的每一個字/詞打上相應的標簽。是大多數NLP底層技術的核心,如分詞、詞性標注、關鍵詞抽取、命名實體識別、語義角色標注等等。曾是HMM、CRF的天下,近年來逐步穩定為BiLSTM-CRF體系。
- 文本摘要:從給定的文本中,聚焦到最核心的部分,自動生成摘要。
- 問答系統:接受用戶以自然語言表達的問題,并返回以自然語言表達的回答。常見形式為檢索式、抽取式和生成式三種。近年來交互式也逐漸受到關注。典型應用有智能客服
- 對話系統:與問答系統有許多相通之處,區別在于問答系統旨在直接給出精準回答,回答是否口語化不在主要考慮范圍內;而對話系統旨在以口語化的自然語言對話的方式解決用戶問題。對話系統目前分閑聊式和任務導向型。前者主要應用有siri、小冰等;后者主要應用有車載聊天機器人。(對話系統和問答系統應該是最接近NLP終極目標的領域)
- 知識圖譜:從規則或不規則的文本中提取結構化的信息,并以可視化的形式將實體間以何種方式聯系表現出來。圖譜本身不具有應用意義,建立在圖譜基礎上的知識檢索、知識推理、知識發現才是知識圖譜的研究方向。
- 文本聚類:一個古老的領域,但現在仍未研究透徹。從大規模文本數據中自動發現規律。核心在于如何表示文本以及如何度量文本之間的距離。
1.3 自然語言處理基本技術
- 分詞:基本算是所有NLP任務中最底層的技術。不論解決什么問題,分詞永遠是第一步。
- 詞性標注:判斷文本中的詞的詞性(名詞、動詞、形容詞等等),一般作為額外特征使用。
- 句法分析:分為句法結構分析和依存句法分析兩種。
- 詞干提取:從單詞各種前綴后綴變化、時態變化等變化中還原詞干,常見于英文文本處理。
- 命名實體識別:識別并抽取文本中的實體,一般采用BIO形式。
- 指代消歧:文本中的代詞,如“他”“這個”等,還原成其所指實體。
- 關鍵詞抽取:提取文本中的關鍵詞,用以表征文本或下游應用。
- 詞向量與詞嵌入:把單詞映射到低維空間中,并保持單詞間相互關系不變。是NLP深度學習技術的基礎。
- 文本生成:給定特定的文本輸入,生成所需要的文本,主要應用于文本摘要、對話系統、機器翻譯、問答系統等領域。
2. NLTK
NLTK常見模塊及用途:
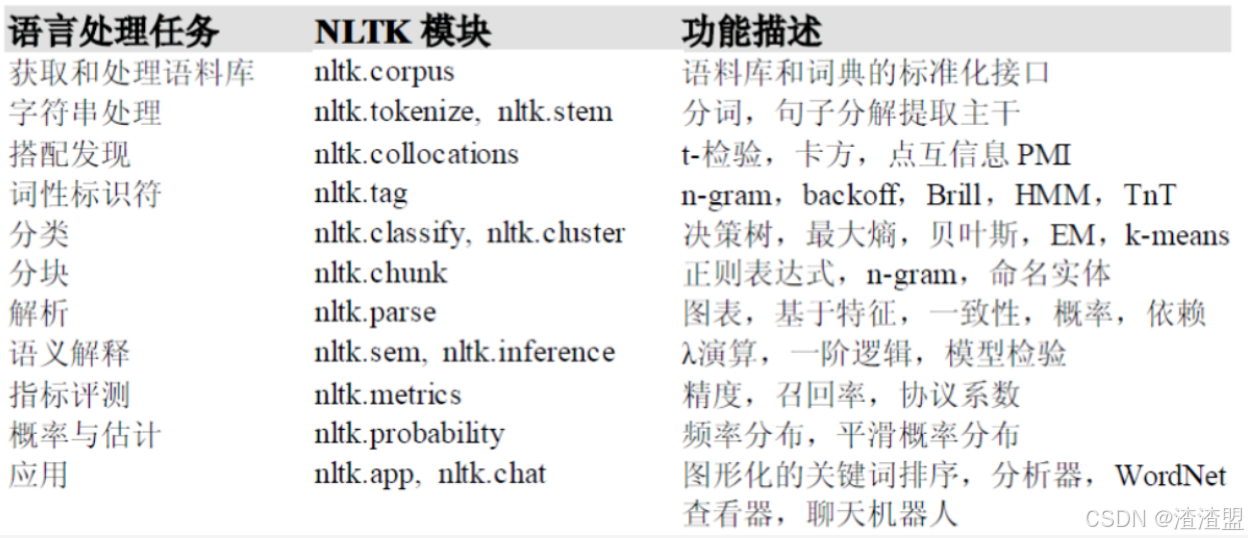
NLTK中的語料庫
古騰堡語料庫:gutenberg;
網絡聊天語料庫:webtext、nps_chat;
布朗語料庫:brown;
路透社語料庫:reuters;
就職演說語料庫:inaugural;
其他語料庫;
任務實施:
NLTK全稱為Natural Language Toolkit,自然語言處理工具包,在NLP領域中,最常使用的一個Python庫。
!pip install nltk==3.7
1.字符串處理
1.1 清理與替換
strip() 方法用于移除字符串頭尾指定的字符(默認為空格或換行符)或字符序列。注意:該方法只能刪除開頭或是結尾的字符,不能刪除中間部分的字符。
lstrip() 方法用于截掉字符串左邊的空格或指定字符。
rstrip() 刪除 string 字符串末尾的指定字符,默認為空白符,包括空格、換行符、回車符、制表符。
en_str = " .hello world, hello, my name is XiaoLu, "
en_str1 = en_str.strip() # 去頭尾空格
print(“去頭尾空格后:”+ en_str1)
en_str2 = en_str.lstrip(’ .‘) # 去左邊的“ .”
print(“去左邊的.后:”+ en_str2)
en_str3 = en_str.rstrip(’, ') # 去右邊的“, ”
print(“去右邊的,后:”+ en_str3)
replace() 方法把字符串中的 old(舊字符串) 替換成 new(新字符串),如果指定第三個參數max,則替換不超過 max 次。
replace()方法語法:
str.replace(old, new[, max])
參數:
old:將被替換的子字符串。
new:新字符串,用于替換old子字符串。
max:可選字符串, 替換不超過 max 次
en_str.replace(‘hello’,‘hi’) #字符串替換
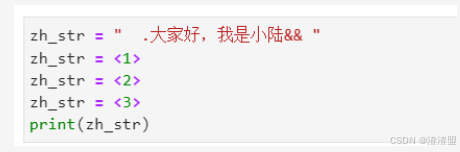
動手練習1
- 模仿上述代碼,在<1>處填寫代碼,將空格和特殊符號“.”和“&”去除;
- 在<2>處填寫代碼,將“小陸”替換為“小陸老師”;
- 在<3>處填寫代碼,將“大家好,”刪除。
#在這里手敲上面代碼并填補缺失代碼
zh_str=“.大家好,我是小陸&& "
zh_str=zh_str.strip().lstrip(’ .‘) .rstrip(’&& ')
zh_str=zh_str.replace(“小陸”,“小陸老師”)
zh_str=zh_str.replace(“大家好,”,”")
print(zh_str)
若輸出結果為我是小陸老師,則填寫正確。
1.2 截取
截取字符串使用變量[頭下標:尾下標],就可以截取相應的字符串,其中下標是從0開始算起,可以是正數或負數,下標可以為空表示取到頭或尾。
str1 = ‘大家好,我是小陸,我在NEWLAND!’
print(str1[0:3]) # 訪問前三個字符
print(str1[3:3+2]) #[3,5)
print(str1[-3:-1]) #和列表一樣 可以使用負索引 代表反方向 從右到左 -1代表最后一個(不包含)
print(str1[::2]) #也可以設置步長 [start:stop:step] #隔一個取一個 #start默認為0 stop默認到最后(包含)
print(str1[::-1]) ##字符串逆序最快的辦法 -1代表從尾到頭 步長為1 進行取值
1.3 連接與分割
字符串連接,就是將2個或以上的字符串合并成一個,看上去連接字符串是一個非常基礎的小問題,但是在Python中,我們可以用多種方式實現字符串的連接,稍有不慎就有可能因為選擇不當而給程序帶來性能損失。
方法1:加號連接
很多語言都支持使用加號連接字符串,Python也不例外,只需要簡單的將2個或多個字符串相加就可以完成拼接。
str1 = “大家好,我是小陸,太好了!”
str2 = ‘大家好,我是小陸,吃飯了嗎?’
print(str1+str2) # 使用+連接
方法2:使用str.join()方法
join() 方法用于將序列中的元素以指定的字符連接生成一個新的字符串。join()方法語法:
str.join(sequence)
參數:
sequence:要連接的元素序列。
str3 = [‘我是小陸’,‘我是大陸’,‘太開心了,太棒了!’]
print(‘;’.join(str3)) #使用join進行連接,使用";"對列表中的各個字符串進行連接
分割字符串使用變量.split(“分割標示符號”[分割次數]),分割次數表示分割最大次數,為空則分割所有。
str4 = ‘我是小陸,我是大陸;太開心了,太棒了!’
print(str4.split(‘;’)) # split進行切分,使用“;”對字符串進行切分 得到字符串列表
1.4 比較與排序
sorted() 函數對所有可迭代的對象進行排序操作。
sort 與 sorted 區別:sort 是應用在 list 上的方法,sorted 可以對所有可迭代的對象進行排序操作。list 的 sort 方法返回的是對已經存在的列表進行操作,無返回值,而內建函數 sorted 方法返回的是一個新的 list,而不是在原來的基礎上進行的操作。
sorted 語法:
sorted(iterable, cmp=None, key=None, reverse=False)
參數說明:
- iterable:可迭代對象。
- cmp:比較的函數,這個具有兩個參數,參數的值都是從可迭代對象中取出,此函數必須遵守的規則為,大于則返回1,小于則返回-1,等于則返回0。
- key:主要是用來進行比較的元素,只有一個參數,具體的函數的參數就是取自于可迭代對象中,指定可迭代對象中的一個元素來進行排序。
- reverse:排序規則,reverse = True 降序 , reverse = False 升序(默認)。
可以看到默認排序,是按照首字母大寫到小寫,字母順序從A到Z進行排序。
strs = [‘alice’,‘Uzi’,‘dancy’,‘Mlxg’,‘uzi’]
print(sorted(strs)) #sorted()可以對序列(列表,元組等)進行排序
可以通過定義排序方式函數,帶入參數key進行自定義排序,以下代碼是按照第二個字母小寫的字母順序進行排序。
#使用顯式函數
def sort_func(x):
return x[1].lower() #按照第2個字母小寫的字母順序進行排序
print(sorted(strs,key=sort_func)) #可以通過key關鍵字 自定義排序方式
可以通過lambda表達式,帶入參數key進行自定義排序,以下代碼是按照第三個字母大寫的字母順序進行排序。
#使用匿名函數
print(sorted(strs,key=lambda x:x[2].upper())) #按照第3個字母大寫的字母順序進行排序
1.5 查找與包含
index() 方法檢測字符串中是否包含子字符串 str ,如果指定 beg(開始) 和 end(結束) 范圍,則檢查是否包含在指定范圍內,該方法與 python find()方法一樣,只不過如果str不在 string中會報一個異常。index()方法語法:
str.index(str, beg=0, end=len(string))
參數說明:
- str:指定檢索的字符串
- beg:開始索引,默認為0。
- end:結束索引,默認為字符串的長度。
str1 = ‘我是小陸;我是大陸;太開心了,太棒了!’
#返回第一次出現的第一個位置的索引
print(str1.index(‘小陸’))
print(str1.index(‘大陸’, 3,len(str1)))
find() 方法檢測字符串中是否包含子字符串 str ,如果指定 beg(開始) 和 end(結束) 范圍,則檢查是否包含在指定范圍內,如果包含子字符串返回開始的索引值,否則返回-1。find()方法語法:
str.find(str, beg=0, end=len(string))
參數說明:
- str:指定檢索的字符串
- beg:開始索引,默認為0。
- end:結束索引,默認為字符串的長度。
str1 = ‘我是小陸;我是大陸;太開心了,太棒了!’
#index和find的區別是 find更安全 對于找不到的子串會返回-1
print(str1.find(‘怎么回事’))
print(str1.find(‘太開心了’))
1.6 大小寫與其他變化
lower()方法轉換字符串中所有大寫字符為小寫。upper()方法將字符串中的小寫字母轉為大寫字母。capitalize()將字符串的第一個字母變成大寫,其他字母變小寫。title()方法返回"標題化"的字符串,就是說所有單詞的首個字母轉化為大寫,其余字母均為小寫。
str1 = ‘hello,my name is XiaoLU.’
print(str1.lower()) #轉換小寫
print(str1.upper()) #轉換大寫
print(str1.capitalize()) #首字母大寫
print(str1.title()) #每個單詞首字母大寫
動手練習2
根據以上學習內容,完成動手練習2。要求輸入為“hello xiao lu”,輸出為“Lu Xiao Hello”。提示信息如下:
.split():將輸入的字符串按空格分離成單獨的字符串[::-1]:將字符串倒著打印' '.join():以空格鏈接.title():每個單詞首字母大寫

#在這里手敲上面代碼并填補缺失代碼
str1= “hello xiao lu”
words = str1.split()
reversed_words = words[::-1]
capitalized_words = [word.title() for word in reversed_words]
output_str = ’ '.join(capitalized_words)
print(output_str)
若輸出為Lu Xiao Hello,則說明填寫正確。
2 模式匹配與正則表達式
學習與驗證工具
我們可以使用正則表達式在線驗證工具http://regexr.com/ 來實踐,左邊還有對應的工具和速查表。
可以在這里正則表達式進階練習https://alf.nu/RegexGolf?world=regex&level=r00 練習正則表達式,挑戰更復雜的正則表達式。
re模塊
Python通過re模塊提供對正則表達式的支持。
使用re模塊的一般步驟:
1.將正則表達式的字符串形式編譯為Pattern實例
2.使用Pattern實例處理文本并獲得匹配結果(一個Macth實例)
3.使用Match實例獲得信息,并進行其他的操作
import re #導入re模塊
pattern = re.compile(r’hello.*!') # 將正則表達式的字符串形式編譯成Pattern對象
match = pattern.match(‘hello, Xiaolu! How are you?’) # 使用Pattern匹配文本,獲得匹配結果,無法匹配時將返回None
if match:
print(match.group()) # 使用Match獲得分組信息
2.1 匹配字符串
獲取包含關鍵字的句子
import re
text_string=‘’’
文本最重要的來源無疑是網絡。我們要把網絡中的文本獲取形成一個文本數據庫。
利用一個爬蟲抓取到網絡中的信息。爬取的策略有廣度爬取和深度爬取。
根據用戶的需求,爬蟲可以有主題爬蟲和通用爬蟲之分。
‘’’
regex=‘爬蟲’ #關鍵字
p_string = text_string.split(‘。’)#以句號為分隔符通過split切分
for line in p_string:
if re.search(regex,line) is not None: #search 方法是用來查找匹配當前行是否匹配這個regex,返回的是一個match對象
print(line) #如果匹配到,打印這行信息
可以看到,匹配到了以下兩句話:
利用一個爬蟲抓取到網絡中的信息
根據用戶的需求,爬蟲可以有主題爬蟲和通用爬蟲之分
動手練習3
嘗試模仿上述代碼,在<1>處填寫代碼,打印包含“文本”這個字符串的行內容。

#在這里手敲上面代碼并填補缺失代碼
import re
text_string=‘’’
文本最重要的來源無疑是網絡。我們要把網絡中的文本獲取形成一個文本數據庫。
利用一個爬蟲抓取到網絡中的信息。爬取的策略有廣度爬取和深度爬取。
根據用戶的需求,爬蟲可以有主題爬蟲和通用爬蟲之分。
‘’’
regex=‘文本’ #關鍵字
p_string = text_string.split(‘。’)#以句號為分隔符通過split切分
for line in p_string:
if re.search(regex,line) is not None: #search 方法是用來查找匹配當前行是否匹配這個regex,返回的是一個match對象
print(line) #如果匹配到,打印這行信息
若輸出為以下兩句話,說明填寫正確。
文本最重要的來源無疑是網絡
我們要把網絡中的文本獲取形成一個文本數據庫
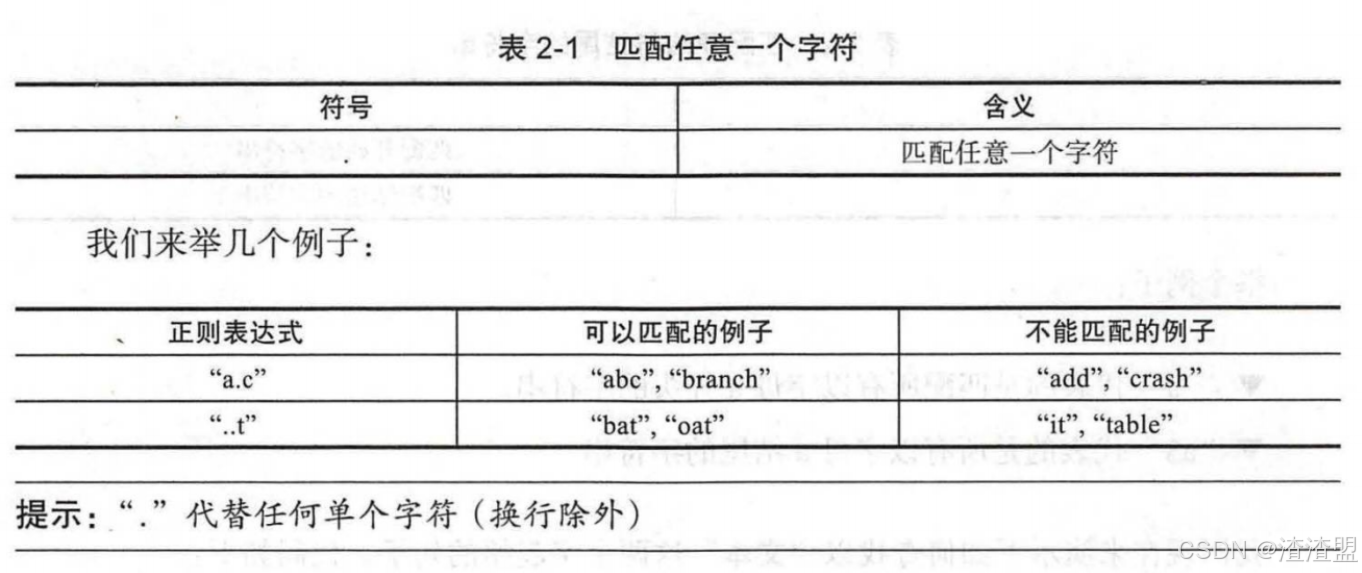
匹配任意一個字符
正則表達式中,有一些保留的特殊符號可以幫助我們處理一些常用邏輯。比如下圖中的“.”可以匹配任一字符,換行符除外。
我們現在來演示下如何查找包含“爬”+任意一個字的句子。代碼如下:
import re
text_string = ‘文本最重要的來源無疑是網絡。我們要把網絡中的文本獲取形成一個文本數據庫。利用一個爬蟲抓取到網絡中的信息。爬取的策略有廣度爬取和深度爬取。根據用戶的需求,爬蟲可以有主題爬蟲和通用爬蟲之分。’
regex =‘爬.’
p_string = text_string.split(‘。’) #以句號為分隔符通過split切分
for line in p_string:
if re.search(regex,line) is not None: #search 方法是用來查找匹配當前行是否匹配這個regex,返回的是一個match對象
print(line) # 如果匹配到,打印這行信息
上述代碼基本不變,只需要將regex中的“爬”之后加一個“.”即可以滿足需求。
我們來看下輸出會多一行。因為不僅是匹配到了“爬取”也匹配到了“爬蟲”。
利用一個爬蟲抓取到網絡中的信息
爬取的策略有廣度爬取和深度爬取
根據用戶的需求,爬蟲可以有主題爬蟲和通用爬蟲之分
匹配起始和結尾字符串

“^a”代表的是匹配所有以字母a開頭的字符串。
“a$”代表的是所有以字母a結尾的字符串。
我們現在來演示下如何查找以“文本”這兩個字起始的句子。代碼如下:
import re
text_string = ‘文本最重要的來源無疑是網絡。我們要把網絡中的文本獲取形成一個文本數據庫。利用一個爬蟲抓取到網絡中的信息。爬取的策略有廣度爬取和深度爬取。根據用戶的需求,爬蟲可以有主題爬蟲和通用爬蟲之分。’
regex =‘^文本’
p_string = text_string.split(‘。’) #以句號為分隔符通過split切分
for line in p_string:
if re.search(regex,line) is not None: #search 方法是用來查找匹配當前行是否匹配這個regex,返回的是一個match對象
print(line) # 如果匹配到,打印這行信息
輸出為
文本最重要的來源無疑是網絡
動手練習4
嘗試模仿上述代碼,在<1>處填寫代碼,嘗試設計一個案例匹配以“信息”這個字符串結尾的行,并打印。

#在這里手敲上面代碼并填補缺失代碼
import re
text_string = ‘文本最重要的來源無疑是網絡。我們要把網絡中的文本獲取形成一個文本數據庫。利用一個爬蟲抓取到網絡中的信息。爬取的策略有廣度爬取和深度爬取。根據用戶的需求,爬蟲可以有主題爬蟲和通用爬蟲之分。’
regex =“信息”
p_string = text_string.split(‘。’) #以句號為分隔符通過split切分
for line in p_string:
if re.search(regex,line) is not None: #search 方法是用來查找匹配當前行是否匹配這個regex,返回的是一個match對象
print(line) # 如果匹配到,打印這行信息
若輸出為以下這句話,說明填寫正確。
利用一個爬蟲抓取到網絡中的信息
使用中括號匹配多個字符

"[bcr]at"代表的是匹配“bat”,“cat”以及“rat”
我們先看下文字信息。句子和句子之間以句號分隔。
[重要的]今年第七號臺風23日登陸廣東東部沿海地區。
上海發布車庫銷售監管通知:違規者暫停網簽資格。
[緊要的]中國對印連發強硬信息,印度急切需要結束對峙。
我們希望提取以[重要的]或者[緊要的]為起始的新聞標題。代碼如下:
import re
text_string = [‘[重要的]今年第七號臺風23日登陸廣東東部沿海地區’,’ 上海發布車庫銷售監管通知:違規者暫停網簽資格’,‘[緊要的]中國對印連發強硬信息,印度急切需要結束對峙’]
regex = ‘^[[ 重緊]…]’
for line in text_string:
if re.search(regex,line) is not None:
print(line)
else :
print(‘not match’)
觀測下數據集,我們發現一些新聞標題是以“[重要的]”“[緊要的]”為起始,所以我們需要添加“^”特殊符號代表起始,之后因為存在“重”或者“緊”,所以我們使
用“[]”匹配多個字符,然后以“.”“.”代表之后的任意兩個字符。運行以上代碼,我們看到結果正確提取了所需的新聞標題。
[重要的]今年第七號臺風23日登陸廣東東部沿海地區
not match
[緊要的]中國對印連發強硬信息,印度急切需要結束對峙
2.2 抽取文本中的數字
通過正則表達式表示年份
[0-9]”代表的是從0到9的所有數字,那相對的”[a-z]” 代表的是從a到z的所有小寫字母。
我們通過一個小例子來講解下如何使用。首先我們定義一個list分配于一個變量strings,匹配年份是在1000 年~ 2999年之間。代碼如下:
import re
year_strings=[]
strings = [ ‘1979年,那是一個春天’,‘時速60公里/小時’, ‘你好,2022!’]
for string in strings:
if re.search(‘[1-2][0-9]{3}’, string):# 字符串有中文有數字,匹配其中的數字部分,并且是在1000 ~ 2999之間,{3} 代表的是重復之前的[0-9]三次,是[0-9] [0-9][0-9]的簡化寫法。
year_strings.append(string)
print(year_strings)
抽取所有的年份
我們使用Python中的re模塊的另-個方法 findall() 來返回匹配帶正則表達式的那部分字符串。
re.findall(“[a-z]”,“abc1234") 得到的結果是 [“a”,“b”,“c”]。
我們定義一個字符串years_ string, 其中的內容是‘2021是很好的一年,但我相信2022會是更好的一年!’。現在我們來抽取一下所有的年份。代碼如下:
import re
years_string = ‘2021是很好的一年,但我相信2022會是更好的一年!’
years = re.findall(‘[2][0-9]{3}’ ,years_string)
years
3.英文文本處理與解析
3.1 分詞
文本是不能成段送入模型中進行分析的,我們通常會把文本切成獨立含義的字、詞或短語,這個過程叫Tokenization。
在NLTK中提供了2種不同的方式的Tokenization,sentence Tokenization(斷句)和word Tokenization(分詞).
按句子分割使用nltk.sent_tokenize(text) ,分詞使用nltk.word_tokenize(sentence)。nltk的分詞是句子級別的,所以對于一篇文檔首先要將文章按句子進行分割,然后句子進行分詞:
!cp -r nltk_data /home/jovyan
import nltk
from nltk import word_tokenize, sent_tokenize
corpus = ‘’‘It is most recommended for those who want to visit China for the first time with short days.
Great contrast of China’s past and present is the best highlight of this tour.
Besides, great accommodation and dinning make your trip more enjoyable.
‘’’
斷句
sentences = sent_tokenize(corpus)
print(“斷句結果:***”)
print(sentences)
分詞
words = word_tokenize(corpus)
print(“分詞結果:***”)
print(words)
3.2 停用詞
由于一些常用字或者詞使用的頻率相當的高,英語中比如a,the, he等,每個頁面幾乎都包含了這些詞匯,如果搜索引擎它們當關鍵字進行索引,那么所有的網站都會被索引,而且沒有區分度,所以一般把這些詞直接去掉,不可當做關鍵詞。
nltk有內置的停用詞列表,首先看看打印停用詞的結果。
#導入內置停用詞
from nltk.corpus import stopwords
#導入英文停用詞
stop_words = set(stopwords.words(‘english’))
print(stop_words)
print(“分詞結果:***”)
print(words)
將文本剔除停用詞
filtered_corpus = [w for w in words if not w in stop_words]
print(“去除停用詞結果:***”)
print(filtered_corpus)
可以看到一些符號如:“,” “.” "'"沒有被去掉,這是因為默認的停用詞表中沒有這部分內容。在很多任務(比如對話任務中)中,停用詞還包括下面這些符號和后綴:['!',',','.','?','’','\''],使用下面代碼,將他們加上去:
stop_words = set(stopwords.words(‘english’))
#添加符號
new_stopwords = [‘!’,‘,’,‘.’,‘?’,‘’’,‘’',‘good’,‘bad’]
new_stopwords_list = stop_words.union(new_stopwords)
print(new_stopwords_list)
動手練習5
- 在<1>處填寫代碼,將’good’,'bad’設為需要從停用詞表中刪除的內容;
- 在<2>處填寫代碼,從停用詞表中刪除內容。

#在這里手敲上面代碼并填補缺失代碼
not_stopwords = {‘good’, ‘bad’}
final_stop_words = set([word for word in stop_words if word not in not_stopwords])
print(final_stop_words)
final_filtered_corpus = [w for w in words if not w in final_stop_words]
print(“去除停用詞結果:”)
print(final_filtered_corpus)
如果輸出為以下內容,則說明填寫正確。

3.3 詞性標注
nltk.download(‘averaged_perceptron_tagger’)
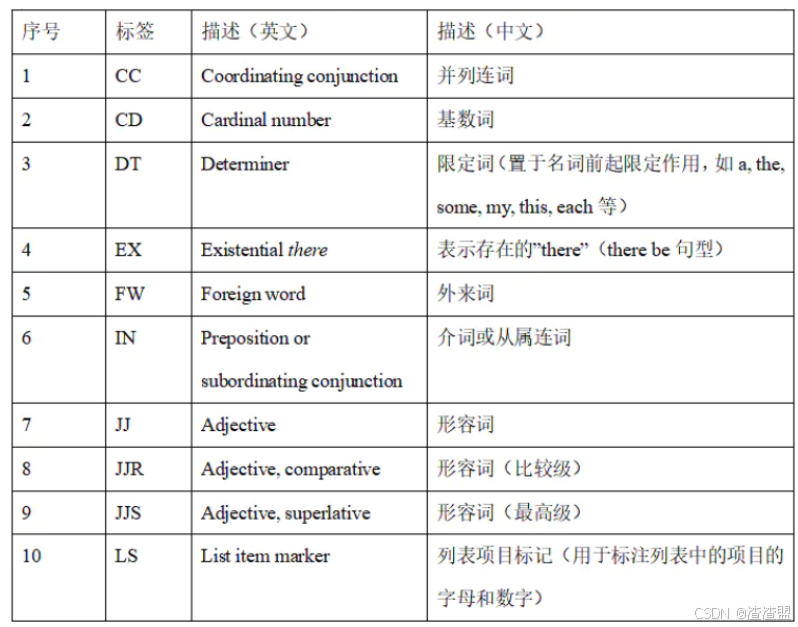
詞性標注是對分詞結果中的每個單詞標注一個正確的詞性的程序(如名詞、動詞等)。詞性標注是很多NLP任務的預處理步驟,如句法分析。下表為NLTK詞性標注對照表:
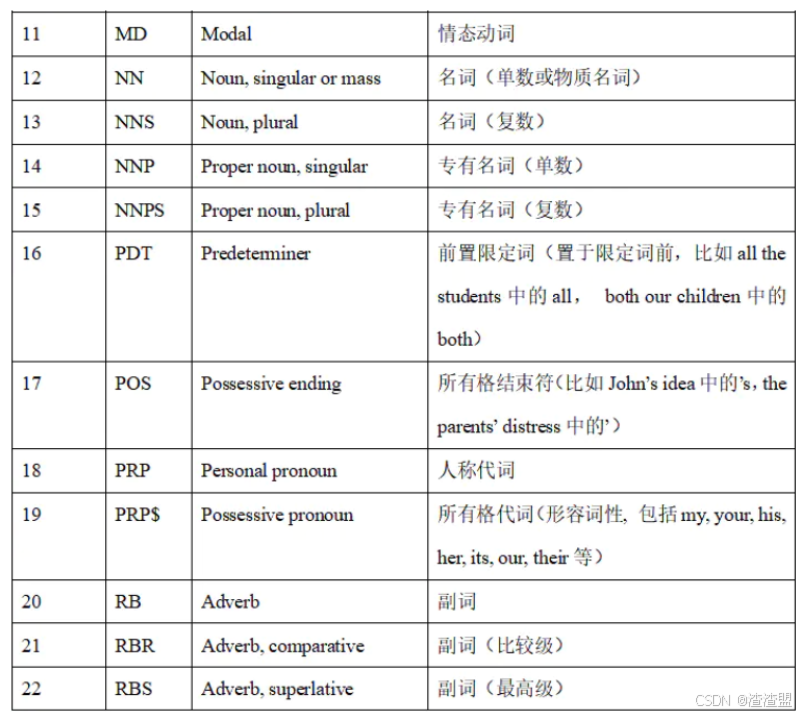
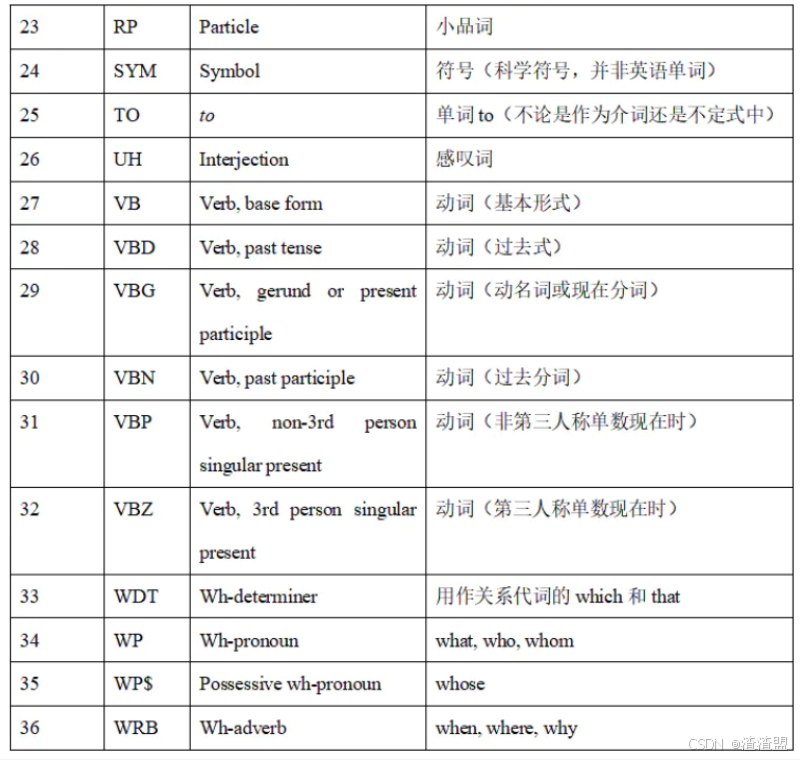
nltk.pos_tag(words):對指定的單詞列表進行詞性標記,返回標記列表。
import nltk
words = nltk.word_tokenize(‘I love China’)
print(words)
word_tag = nltk.pos_tag(words)
print(word_tag)
從結果我們可以看到China是NNP,NNP代表專有名詞。
為什么nltk.pos_tag()方法可以對單詞進行詞性標記?這是因為NLTK預先使用一些語料庫訓練出了一個詞性標注器,這個詞性標注器可以對單詞列表進行標記。
詞性標注過后,我們可以通過單詞的詞性來過濾出相應的數據,如我們要過濾出詞性為 NNP 的單詞,代碼如下:
import nltk
document = ‘Today the Netherlands celebrates King’s Day. To honor this tradition, the Dutch embassy in San Francisco invited me to’
sentences = nltk.sent_tokenize(document)
data = []
for sent in sentences:
data = data + nltk.pos_tag(nltk.word_tokenize(sent))
for word in data:
if ‘NNP’ == word[1]:
print(word)
3.4 時態語態歸一化
很多時候我們需要對英文中的時態語態等做歸一化,這時我們需要 Stemming 詞干提取。
Stemming是抽取詞的詞干或詞根形式(不一定能夠表達完整語義)。NLTK中提供了三種最常用的詞干提取器接口,即Porterstemmer,LancasterStemmer和SnowballStemmer。
PorterStemmer基于Porter詞干提取算法,來看例子:
可以用PorterStemmer
import nltk
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem(‘running’))
print(stemmer.stem(‘makes’))
print(stemmer.stem(‘tagged’))
Snowball Stemmer基于Snowball 詞干提取算法,來看例子:
也可以用SnowballStemmer
from nltk.stem import SnowballStemmer
stemmer1 = SnowballStemmer(‘english’) #指定為英文
print(stemmer1.stem(‘growing’))

)
)


上使用Qt編譯時遇到“type_traits文件未找到”的錯誤)








:專業級地理數據可視化賞析-《杭州市國土空間總體規劃(2021-2035年)》)




