目錄
- 前言
- 一、自求導的方法實現線性回歸
- 1.1自求導的方法實現線性回歸的理論講解
- 1.1.1 線性回歸是什么?
- 1.1.2線性回歸方程是什么?
- 1.1.3散點輸入
- 1.2參數初始化
- 1.2.1?參數與超參數
- 1.2.1.1?參數定義
- 1.2.1.2 參數內容
- 1.2.1.3 超參數定義
- 1.2.1.4 超參數內容
- 1.2.2 參數設定
- 1.3 損失函數
- 1.4 開始迭代
- 1.5 反向傳播
- 1.6 顯示頻率設置
- 1.9 梯度下降顯示
- 2.0 自求導實現線性回歸程序?
- 二、深度學習框架Pytorch的tensor
- 2.2 PyTorch是什么?
- 2.3 PyTorch的特點
- 2.4 tensor是什么?
- 2.5 torch 安裝命令
- 2.6 tensor的存儲機制
- 2.6.1?tensor
- 2.6.2 數據類型
- 2.6.2.1 基本構成
- 2.6.2.2 計算方式
- 2.6.2.3 實戰計算
- 2.6.3? Storage 存儲與共享
- 2.7 tensor的步長
- 2.8 tensor的偏移
- 2.9 Tensor的連續性
- 2.9.1 tensor的連續性是什么?
- 2.9.2 tensor的不連續性是什么?
- 2.9.3 不連續的缺點與解決方案
- 總結
前言
書接上文
線性回歸的前向傳播、反向傳播與數學求解詳解-CSDN博客文章瀏覽閱讀1k次,點贊40次,收藏19次。本文從前向傳播的代碼實現出發,展示了如何利用線性模型對二維數據進行擬合及誤差分析,接著深入講解了反向傳播中的學習率和梯度下降算法的理論基礎及優化方法,結合Python代碼動態演示了參數更新和損失函數的變化過程;最后,文章通過數學推導詳細揭示了線性回歸模型參數的計算公式,并用代碼實現了數學解法的擬合過程,幫助讀者全面掌握線性回歸的基本原理、優化方法及編程實現。https://blog.csdn.net/qq_58364361/article/details/147264719?spm=1011.2415.3001.10575&sharefrom=mp_manage_link
一、自求導的方法實現線性回歸
從以下2個方面對自求導的方法實現線性回歸算法進行介紹
1.自求導的方法實現線性回歸算法理論講解
2.編程實例與步驟
上面這2方面的內容,讓大家,掌握并理解自求導的方法實現線性回歸算法。
1.1自求導的方法實現線性回歸的理論講解
在了解前向傳播、反向傳播、損失函數、學習率、梯度下降這些概念后,我們就可以通過自求導的方式來實現線性回歸算法。
1.1.1 線性回歸是什么?
定義:
線性回歸是一種用于建立自變量與因變量之間關系的統計方法。
它假設因變量(或響應變量)與一個或多個自變量(或預測變量)之間的關系是線性的。
其主要目標是通過擬合一個線性模型來預測因變量的數值。
1.1.2線性回歸方程是什么?
公式:
線性回歸模型可以表示為:
Y=β_0+β_1X_1+β_2X_2+...+β_nX_n+ε
其中:
Y是因變量
X_1,X_2,...,X_n是自變量
β_0,β_1,...,β_n是模型的系數,表示自變量對因變量的影響。
ε是誤差項,表示模型無法解釋的隨機誤差
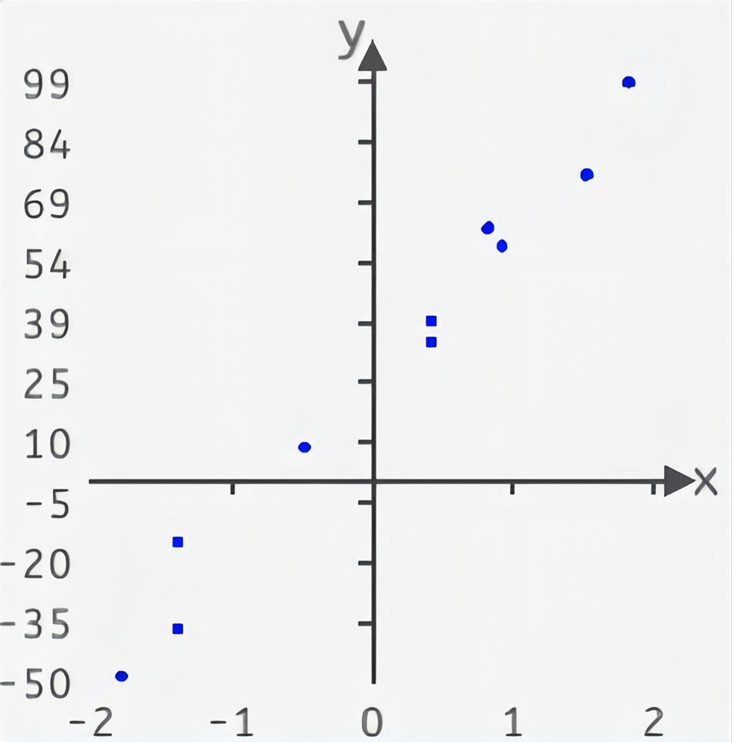
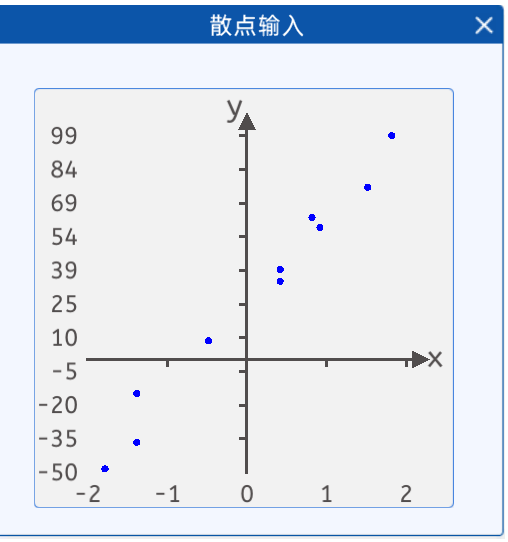
1.1.3散點輸入
算法實現需要的數據,一些散點,將它們繪制在一個二維坐標中,其分布如下圖所示:
1.2參數初始化
1.2.1?參數與超參數
1.2.1.1?參數定義
模型中可調整的變量,它們用來捕捉數據中的模式和特征。這些參數在模型訓練過程中被不斷調整以最小化損失函數或優化某種目標。
1.2.1.2 參數內容
權重(Weights):用來表示不同輸入特征與神經元之間的連接強度
偏置(Biases):用于調整每個神經元的激活閾值,使模型能夠更好地擬合數據。
1.2.1.3 超參數定義
超參數不是通過訓練數據學習得到的,而是在訓練過程之前需要手動設置的參數。
1.2.1.4 超參數內容
包括學習率、正則化參數、迭代次數、批量大小、神經網絡層數和每層的神經元數量、激活函數。
學習率(Learning Rate):用于控制優化算法中每次更新參數時的步長。較小的學習率會導致訓練收斂較慢,而較大的學習率可能導致訓練不穩定或震蕩。
正則化參數(Regularization Parameter):用于控制正則化的強度,如L1正則化和L2正則化。較大的正則化參數會增強正則化效果,有助于防止過擬合。
迭代次數(Number of Iterations):用于控制訓練的迭代次數。迭代次數太小可能導致模型未完全學習數據的特征,而迭代次數太大可能導致過擬合。
批量大小(Batch Size):用于控制每次訓練時用于更新參數的樣本數量。批量大小的選擇會影響訓練速度和內存消耗。
神經網絡層數和每層的神經元數量(Number of Layers and Neurons per Layer):用于定義神經網絡的結構。
激活函數(Activation Function):用于控制神經網絡每個神經元的輸出范圍,如Sigmoid、ReLU等。
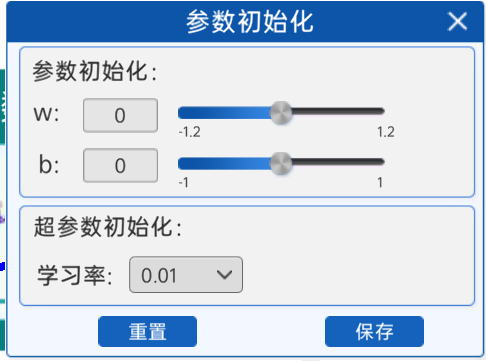
1.2.2 參數設定
在前向傳播實驗中,知道了參數不同時對應的損失函數值也不同,所以需要先初始化一下參數和超參數,進行一次前向傳播,得到損失值,這樣才能通過反向傳播減小損失,使直線的擬合效果更好。這里通過“參數初始化”組件來初始化w和b以及學習率這三個參數/超參數
1.3 損失函數
與前向傳播實驗和反向傳播實驗不同,此時b的值不再是0,也就意味著損失函數不僅僅受到w的影響,還會受到b的影響,將 y=wx+b 帶入損失函數的表達式后,新的損失函數就變成了如下圖所示的表達式:

1.4 開始迭代
迭代次數通常指的是反向傳播的次數,即通過反向傳播來更新模型的參數,直到達到一定的迭代次數或者達到收斂的條件為止。
迭代的次數越多,模型參數就越接近最優解,從而使得損失函數達到最小值,但是可能會造成過擬合(過擬合在之后的實驗會講到)。
一般來說,迭代次數需要根據具體情況來確定,通常需要進行多次迭代來更新模型參數,直到達到收斂的條件為止,在“開始迭代”組件中默認的是500次。
1.5 反向傳播
當參數和損失函數都設置好之后,就開始反向傳播了,也就是損失函數對w和b進行求導并且不斷更新w和b的過程,是一個復合函數
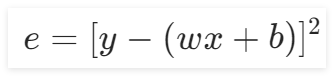
求導的過程。損失函數對w和b的求導過程如下:

1.6 顯示頻率設置
求導完成之后,使用梯度下降的方法來更新w和b的值。為了更好的在實驗中看現象,這里有一個“顯示頻率設置”組件,就是每經過多少次迭代,繪制一次當前參數的擬合線及損失函數的大小。
1.9 梯度下降顯示
迭代的結果通過“梯度下降顯示”組件進行查看。如下圖所示,38.4是w 的實時值,24.58是b的實時值,42.68是最后的損失值。
除此之外,該組件還有三個圖,左邊的是實時的直線圖,參數每更新一次,該直線就更新一次,右邊的是損失值的圖像,顯示的是經過迭代后的損失值的大小,下方的圖是W和B隨著不斷的更新而變化的等高線圖

2.0 自求導實現線性回歸程序?
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspecfrom 機器學習.test import iter_num_list # 導入外部模塊中的iter_num_list(此處未使用)# 1. 準備數據:散點坐標
data = [[-0.5, 7.7],[1.8, 98.5],[0.9, 57.8],[0.4, 39.2],[-1.4, -15.7],[-1.4, -37.3],[-1.8, -49.1],[1.5, 75.6],[0.4, 34],[0.8, 62.3]]# 轉換為numpy數組,便于矩陣運算
data = np.array(data)
x_data = data[:, 0] # 取第一列作為x數據
y_data = data[:, 1] # 取第二列作為y數據# 初始化線性模型參數w和b
w = 0
b = 0# 設置學習率
learning_rate = 0.01# 定義損失函數(均方誤差)
def loss_function(x_data, y_data, w, b):predicted = np.dot(x_data, w) + b # 線性預測y_mean = np.mean((y_data - predicted) ** 2) # 均方誤差計算return y_mean# 創建畫布,采用2行2列的格子布局
fig = plt.figure("show figure")
gs = gridspec.GridSpec(2, 2)# 左上子圖:繪制散點圖及擬合直線
ax1 = fig.add_subplot(gs[0, 0])
ax1.set_xlabel('X')
ax1.set_ylabel('y')
ax1.set_title('figure1 data')# 左下子圖:繪制損失隨迭代變化圖
ax2 = fig.add_subplot(gs[1, 0])
ax2.set_xlabel('iter')
ax2.set_ylabel('e')
ax2.set_title('figure2 data')# 右上子圖:繪制損失函數關于w和b的三維表面
ax3 = fig.add_subplot(gs[0, 1], projection='3d')# 設置權重w和偏置b的取值范圍
w_values = np.linspace(-20, 80, 100)
b_values = np.linspace(-20, 80, 100)# 生成網格數據用于繪制曲面
W, B = np.meshgrid(w_values, b_values)# 初始化對應損失函數值矩陣
loss_values = np.zeros_like(W)# 計算每個(w, b)組合的損失值
for i, w_value in enumerate(w_values):for j, b_value in enumerate(b_values):loss_values[j, i] = loss_function(x_data, y_data, w_value, b_value)# 繪制三維曲面圖(顏色映射采用viridis)
ax3.plot_surface(W, B, loss_values, cmap='viridis', alpha=0.8)# 設置三維坐標軸標簽和標題
ax3.set_xlabel('w')
ax3.set_ylabel('b')
ax3.set_zlabel('loss')
ax3.set_title('figure3 surface plot')# 右下子圖:繪制損失函數的等高線填充圖
ax4 = fig.add_subplot(gs[1, 1])
ax4.set_xlabel('w')
ax4.set_ylabel('b')
ax4.set_title('coutour plot')
ax4.contourf(W, B, loss_values, levels=20, cmap='viridis')# 迭代次數設置
num_iterations = 100# 初始化列表,用于存儲損失(sh)、迭代次數(cs)、和參數軌跡(gj)
sh = [] # 記錄每次迭代的損失
cs = [] # 記錄迭代次數
gj = [] # 記錄每次迭代的(w, b)參數值軌跡# 梯度下降主循環
for i in range(1, num_iterations + 1):gj.append((w, b)) # 保存當前參數yc = np.dot(x_data, w) + b # 預測值e = np.mean((y_data - yc) ** 2) # 當前均方誤差sh.append(e) # 記錄損失cs.append(i) # 記錄迭代次數# 計算梯度(損失對w和b的偏導數)dw = (-2 * (y_data - yc).dot(x_data)) / len(x_data)db = np.mean(-2 * (y_data - yc))# 參數更新,梯度下降法w = w - learning_rate * dwb = b - learning_rate * db# 每隔10次迭代或第1次迭代,更新繪圖顯示f = 10if i % f == 0 or i == 1:# 清空左上子圖,重新繪制散點和擬合直線ax1.clear()ax1.set_xlabel('X')ax1.set_ylabel('y')ax1.set_title('figure1 data')ax1.scatter(x_data, y_data, c='b', marker='o') # 繪制散點x_min, x_max = x_data.min(), x_data.max()y_min, y_max = w * x_min + b, w * x_max + bax1.plot([x_min, x_max], [y_min, y_max], c='r') # 繪制擬合直線# 清空左下子圖,重新繪制損失隨迭代次數的變化曲線ax2.clear()ax2.set_xlabel('iter')ax2.set_ylabel('e')ax2.set_title('figure2 data')ax2.plot(cs, sh, c='g') # 繪制損失曲線# 繪制右上三維曲面上的梯度下降軌跡if len(gj) > 0:g_w, g_b = zip(*gj) # 解包軌跡參數# 繪制軌跡點(散點線)ax3.plot(g_w, g_b, [loss_function(x_data, y_data, w_, b_) for w_, b_ in gj], c='b')ax3.set_xlim(-20, 80)ax3.set_ylim(-20, 80)ax3.set_xlabel('w')ax3.set_ylabel('b')ax3.set_zlabel('loss')ax3.set_title('figure3 surface plot')# 繪制當前參數對應的點,用黑點高亮ax3.scatter(w, b, loss_function(x_data, y_data, w, b), c='b', s=20)# 右下等高線圖繪制迭代軌跡曲線ax4.plot(g_w, g_b)# 暫停0.01秒,更新動畫效果
二、深度學習框架Pytorch的tensor
從以下4個方面對深度學習框架Pytorch的tensor進行介紹
1.PyTorch是什么?
2.tensor是什么?
3.tensor的存儲機制
4.tensor的連續性
上面這4方面的內容,讓大家,掌握并理解深度學習框架Pytorch的tensor。
2.2 PyTorch是什么?
概念:
PyTorch是一個開源的深度學習框架,由Meta公司(原名:Facebook)的人工智能團隊開發和維護。它提供了一個靈活、動態的計算圖計算模型,使得在深度學習領域進行實驗和開發變得更加簡單和直觀。
pytorch網址
PyTorch documentation — PyTorch 2.6 documentation![]() https://pytorch.org/docs/stable/index.html
https://pytorch.org/docs/stable/index.html

2.3 PyTorch的特點
2.1動態計算圖
PyTorch使用動態計算圖,這意味著計算圖在運行時構建的,而不是在編譯時靜態定義的。
2.2 自動求導(微分)
PyTorch提供了自動求導機制,稱為Autograd。它能夠自動計算張量的梯度,這對于訓練神經網絡和其他深度學習模型非常有用。
2.3 豐富的神經網絡庫
PyTorch 提供了豐富的神經網絡庫,包括各種各樣的層,損失函數、優化器等。這些庫使得構建和訓練神經網
絡變得更加容易。
2.4支持GPU加速
PyTorch 充分利用了GPU的并行計算能力,能夠在GPU上高效地進行計算,加速模型訓練過程。
2.4 tensor是什么?
tensor是一種多維數組,類似于NumPy的ndarray.它是Pytorch中最基本的數據結構,用于存儲和操作數據。
tensor可以是標量、向量、矩陣或者更高維度的數組,可以包含整數、浮點數或者其他數據類型的元素。
PyTorch的Tensor和NumPy的ndarray非常相似,但在設計和功能上有一些不同之處。主要的區別包括:GPU加速、自動求導、動態計算圖。

2.5 torch 安裝命令
python -m pip install --upgrade pip
pip install torch==2.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install torch==2.4.1 -i Simple Index
import torch""" 01
-------------------打印標量 向量 矩陣
"""# 打印一個標量張量
# 標量是只有一個數值的張量,這里值為3.14
scalar_tensor = torch.tensor(3.14)
print("scalar_tensor:", scalar_tensor, "\n")# 打印一個向量張量
# 向量是1維張量,這里包含5個元素:[1, 2, 3, 4, 5]
vector_tensor = torch.tensor([1, 2, 3, 4, 5])
print("vector_tensor:", vector_tensor, "\n")# 打印一個矩陣張量
# 矩陣是2維張量,這里是2行2列的矩陣[[1, 2], [3, 4]]
matrix_tensor = torch.tensor([[1, 2], [3, 4]])
print("matrix_tensor:", matrix_tensor, "\n")
D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\機器學習\test.py
scalar_tensor: tensor(3.1400) vector_tensor: tensor([1, 2, 3, 4, 5]) matrix_tensor: tensor([[1, 2],[3, 4]]) 進程已結束,退出代碼為 02.6 tensor的存儲機制
2.6.1?tensor
在PyTorch中,tensor包含了兩個部分,即Storage 和metadata。Storage(存儲):存儲是tensor中包含的實際的底層緩沖區,它是一維數組,存儲了tensor的元素值。不同tensor可能共享相同的存儲,即使它們具有不同的形狀和步幅。存儲是一塊連續的內存區域,實際上存儲了tensor中的數據。
Metadata(元數據):元數據是tensor的描述性信息,包括tensor的形狀、數據類型、步幅、存儲偏移量、設備等。元數據提供了關于tensor的結構和屬性信息,但并不包括tensor中的實際數據。元數據允許PyTorch知道如何正確地解釋存儲中的數據以及如何訪問它們。
描述性信息元數據:
| tensor | tensor:tensor([[1,2,3],[4,5,6]]) |
| Metadata | 形狀 數據類型 步幅/步長 存儲偏移量 設備 |
| Storage | 一維數組 |
import torch
import torch# tensor 存儲示例
# 創建一個2行3列的浮點數張量
tensor_2_3_float = torch.tensor([[1.0, 2.0, 3.0], [4, 5, 6]])# 打印張量的數據類型(dtype),比如float32
print(tensor_2_3_float.dtype, "\n")# 打印張量的底層存儲結構(storage),顯示存儲的數據信息
print(tensor_2_3_float.storage(), "\n")# 將底層存儲的數據轉換為列表,方便查看具體元素順序
print(tensor_2_3_float.storage().tolist(), "\n")# 打印存儲偏移量,表示張量數據起始位置相對底層存儲的偏移索引
print(tensor_2_3_float.storage_offset(), "\n")# 再次打印存儲偏移量,結果相同
print(tensor_2_3_float.storage_offset(), "\n")
D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\機器學習\test.py
torch.float32 1.02.03.04.05.06.0
[torch.storage.TypedStorage(dtype=torch.float32, device=cpu) of size 6] [1.0, 2.0, 3.0, 4.0, 5.0, 6.0] 0 0 C:\Users\98317\PycharmProjects\study_python\機器學習\test.py:11: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()print(tensor_2_3_float.storage(), "\n")進程已結束,退出代碼為 02.6.2 數據類型
整型、無符號整數類型
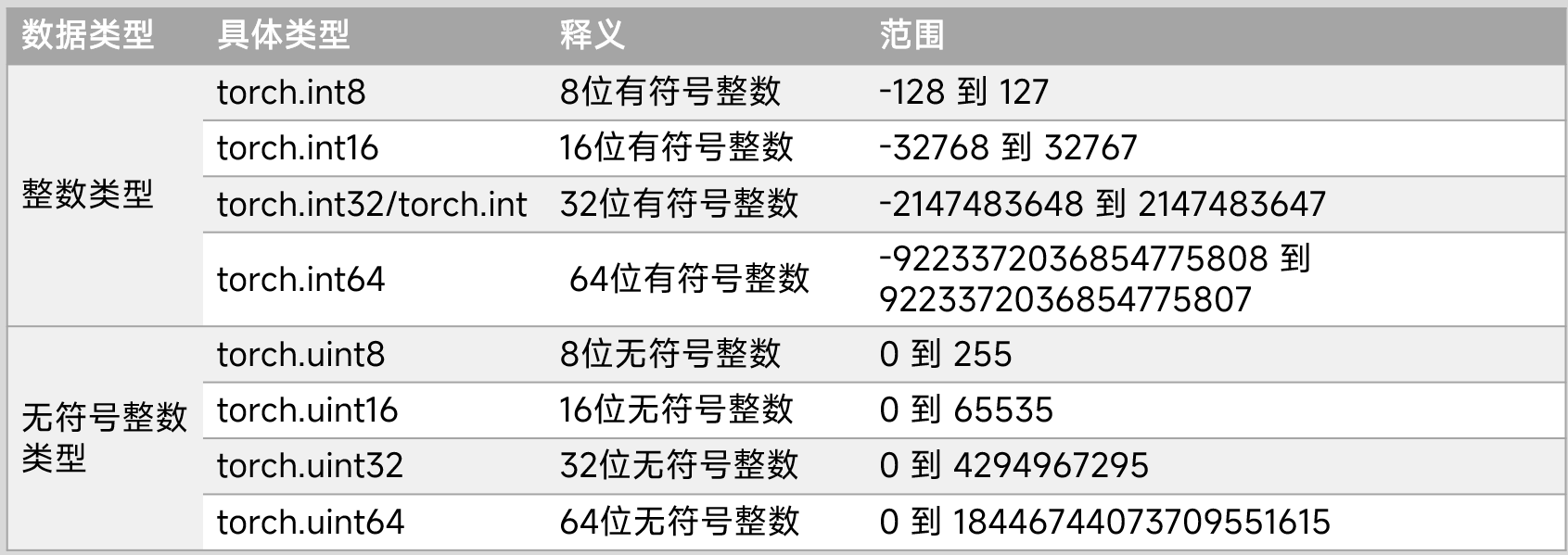
浮點型
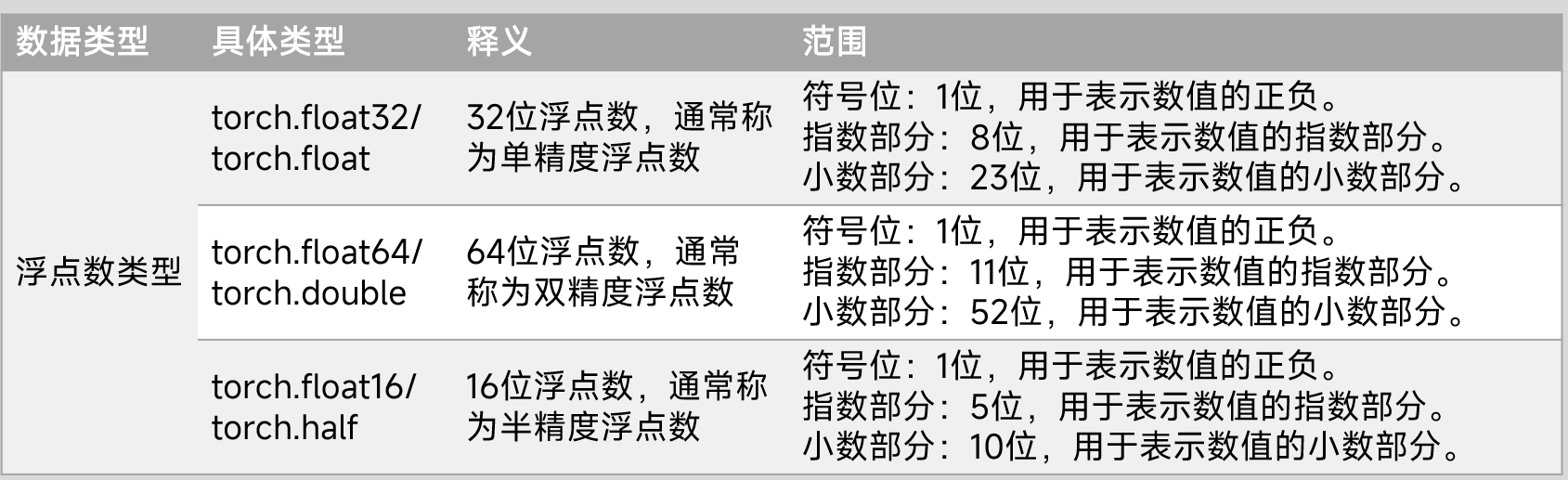
torch.Float16,也被稱為FP16或半精度浮點數,是一種用于表示浮點數的數據類型,在計算機科學中廣泛應用于各種領域。以下是對Float16的詳細說明:
2.6.2.1 基本構成
Float16使用16位(即2個字節)來表示一個浮點數,這16位被分為三部分:
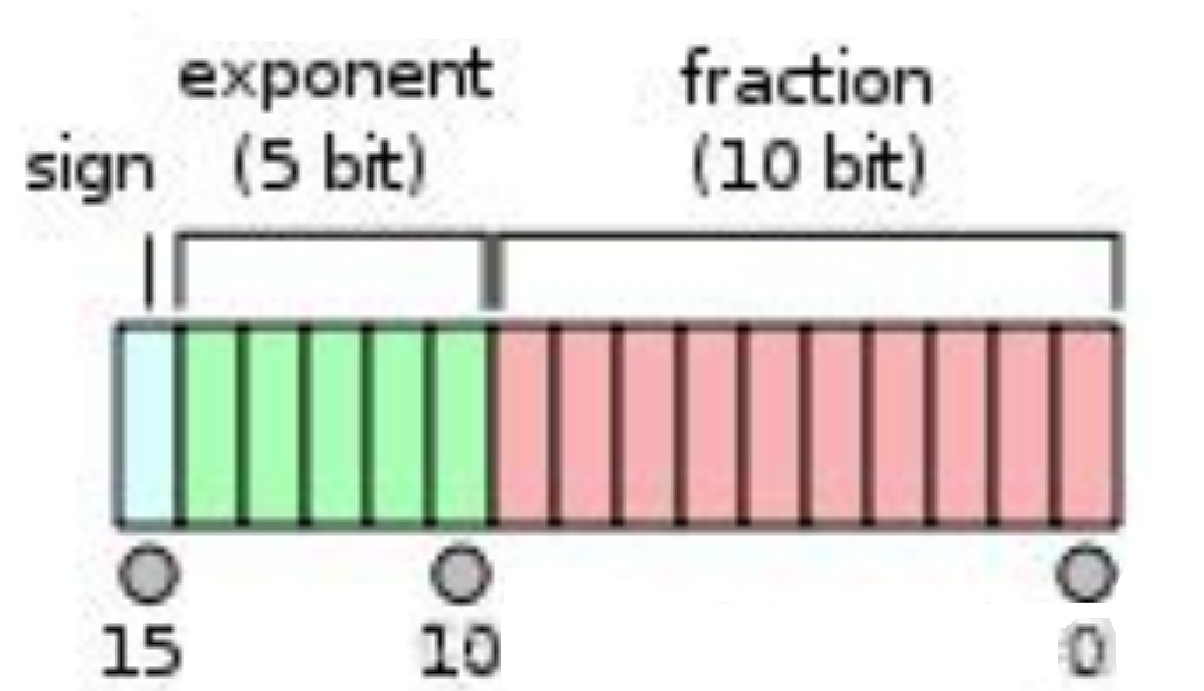
符號位:1位,用于表示數的正負。0代表正數,1代表負數。
指數位:5位,用于表示數的大小。其范圍是00001~11110,對應的十進制數是1~30。為了得到實際的指數值,需要從這些值中減去一個偏置值15,因此實際指數的范圍是-14~15。
尾數位:10位,用于表示數的精度。其范圍是0~1023,這些值除以1024后得到實際的尾數值,范圍是0~0.9990234375。
2.6.2.2 計算方式
Float16類型的數的計算公式是:

2.6.2.3 實戰計算
對于給出的float16值:0011101000000000
根據計算公式得出:為0.75
符號位:0(表示這是一個正數)
指數部分:01110(二進制),轉換為十進制是2^3+2^2+2^1=8+4+2=14
小數部分(尾數):1000000000(二進制)
接下來,將指數部分轉換為實際的指數值。在float16中,指數的偏移量是15,因為最大為2^(5-1)-1=15,所以實際的指數是14-15=-1。
將小數部分轉成十進制:2^(9)=512; 512/1024=0.5; 0.5+1=1.5
最終計算方法:(-1)^符號位×2^(-1)×1.5=0.75。
2.6.3? Storage 存儲與共享
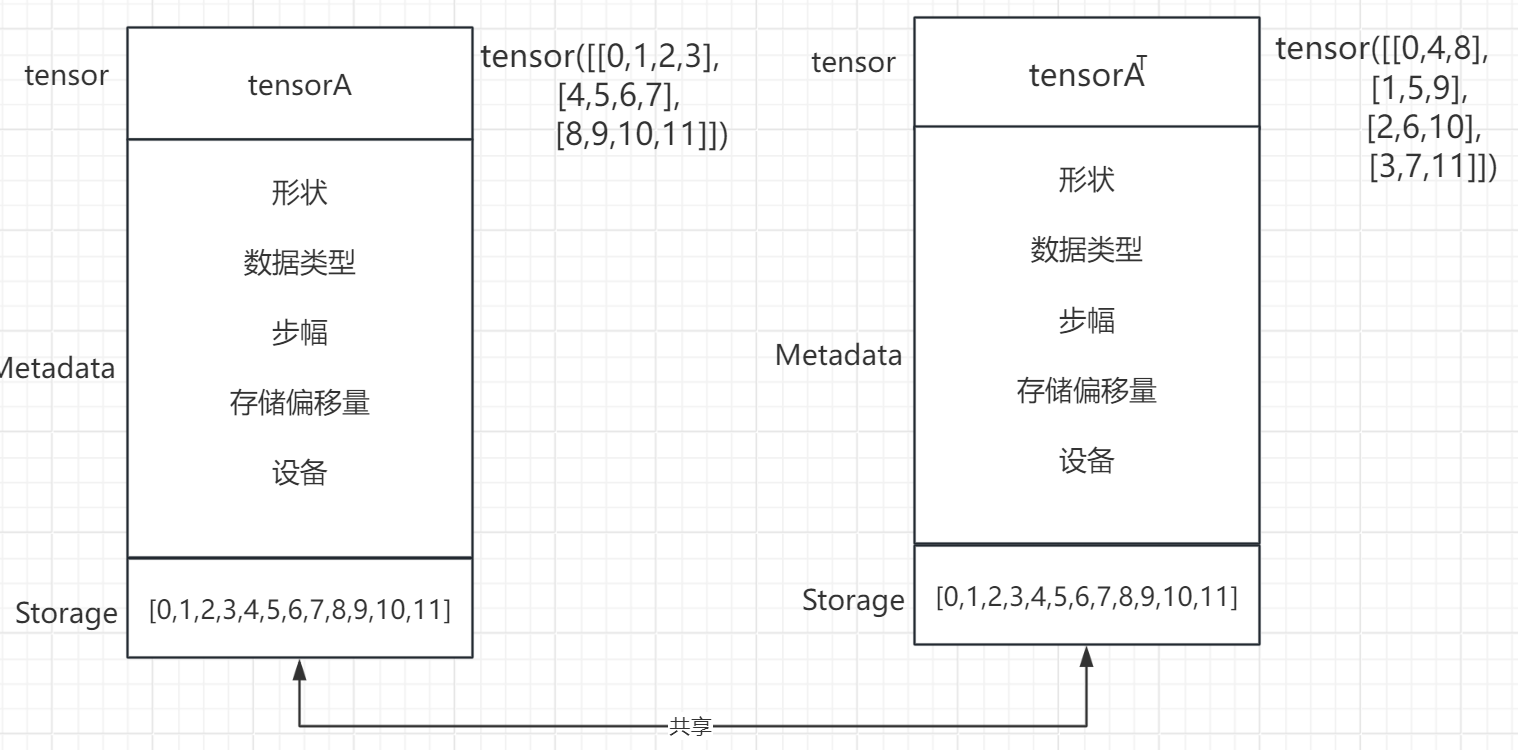
tensor結構圖
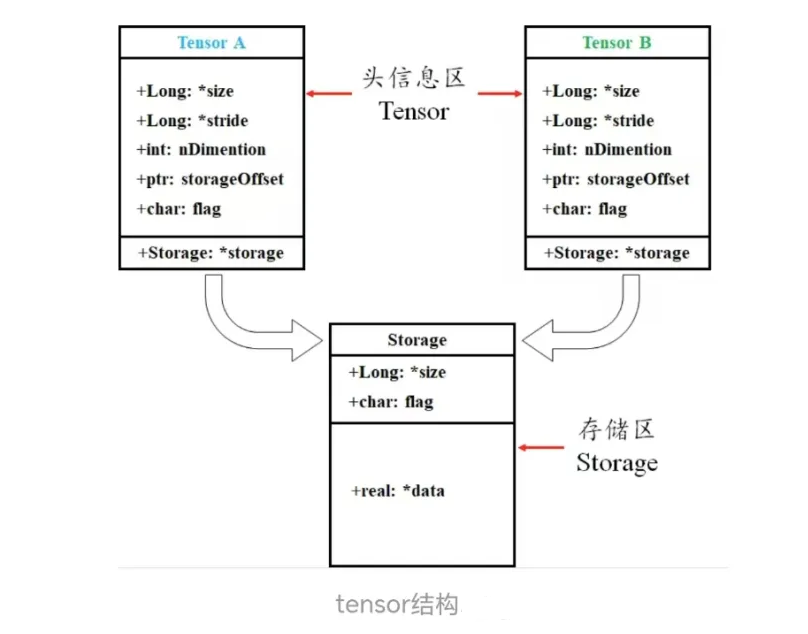
對張量進行操作時(比如調整形狀(不是reshape是view),轉置等),它不會創建一個新的張量,而是返回一個指向相同數據的視圖。即PyTorch通常會共享相同的存儲對象,以節省內存和提高效率。
import torch# 驗證storage存儲與共享
# 1. 查看兩個張量的底層存儲是否相同,判斷它們是否共享存儲
# 2. 通過比較存儲的內容和內存地址,確認它們是否指向同一塊內存空間
# 3. 如果兩者的底層存儲內容和內存地址都一致,則說明它們共享同一份數據# 使用 arange 生成0到11的連續整數,共12個元素
# 然后使用 reshape 將其變形成3行4列的張量
tensorA = torch.arange(12).reshape(3, 4)# 打印張量tensorA的底層storage內容(以列表形式)
print(tensorA.storage().tolist())# 對tensorA進行轉置操作,交換第0維和第1維,生成tensorB
tensorB = tensorA.transpose(0, 1)# 打印tensorB的底層storage內容(以列表形式)
# 可觀察轉置操作后底層存儲數據是否發生變化
print(tensorB.storage().tolist(), "\n")# 打印tensorA存儲內容的內存地址(指針)
print(tensorA.storage().data_ptr(), "\n")# 打印tensorB存儲內容的內存地址(指針)
print(tensorB.storage().data_ptr(), "\n")# 打印tensorA對象的id(內存地址,用于區分不同對象)
print(id(tensorA), "\n")# 打印tensorB對象的id,和tensorA相比確認是否為不同對象
print(id(tensorB), "\n")
D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\機器學習\test.py
C:\Users\98317\PycharmProjects\study_python\機器學習\test.py:13: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()print(tensorA.storage().tolist())
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] 5948693287232 5948693287232 1573108881744 1573115855632 進程已結束,退出代碼為 0Storage存儲的具體過程
在PyTorch中,張量的存儲是通過torch.Storage類來管理的。張量的值被分配在連續的內存塊中,這些內存塊中,這些內存塊是大小可變的一維數組,可以包含不同類型的數據,如float或int32。
具體來說,當我們創建一個張量時,PyTorch會根據我們提供的數據和指定的數據類型來分配一塊連續的內存空間。這塊內存空間由torch.Storage對象管理,而張量本身則提供了一種視圖,讓我們可以通過索引來訪問這些數據。
此外,PyTorch還提供了一系列的函數和方法來操作張量,包括改變形狀,獲取元素、拼接和拆分等。這些操作通常不會改變底層的存儲,而是返回一個新的張量視圖,這個視圖指向相同的數據但是可能有不同的形狀或索引方式。
總的來說,張量的存儲實現是PyTorch能夠高效進行張量運算的關鍵。通過管理一塊連續的內存空間,并提供了豐富的操作方法,使得用戶可以方便地對多維數組進行各種計算和變換。
2.7 tensor的步長
步長指的是在每個維度上移動一個元素時在底層存儲中需要跨越的元素數。
import torch"""
04
展示張量的步長(stride)概念及其轉置操作對步長和存儲的影響
"""
# 創建一個3行4列的張量,元素為0到11,數據類型為float32
tensor_A = torch.arange(12, dtype=torch.float32).reshape(3, 4)# 打印原張量
print(tensor_A, "\n")# 打印原張量的步長,每個維度跨越內存元素的步長
print(tensor_A.stride(), "\n")# 打印原張量的轉置(交換行列)
print(tensor_A.T, "\n")# 打印轉置后張量的步長,步長的變化反映了維度的交換
print(tensor_A.T.stride(), "\n")# 打印轉置張量底層存儲的所有元素,存儲不變只是視圖變換
print(tensor_A.T.untyped_storage().tolist())D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\機器學習\test.py
tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.]]) (4, 1) tensor([[ 0., 4., 8.],[ 1., 5., 9.],[ 2., 6., 10.],[ 3., 7., 11.]]) (1, 4) [0, 0, 0, 0, 0, 0, 128, 63, 0, 0, 0, 64, 0, 0, 64, 64, 0, 0, 128, 64, 0, 0, 160, 64, 0, 0, 192, 64, 0, 0, 224, 64, 0, 0, 0, 65, 0, 0, 16, 65, 0, 0, 32, 65, 0, 0, 48, 65]進程已結束,退出代碼為 0tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
(4, 1)
第一個數字4表示矩陣的行(第一個維度)上移動一個元素時需要跨越的存儲單元數。因為矩陣的每行包含4個元素,所以每次沿著行移動一個元素需要跨越4個存儲單元。
第二個數字1表示在矩陣的列(第二個維度)上移動一個元素時需要跨越的存儲單元數,因為矩陣的列數是1,所以在列上移動一個元素時只需要跨越一個存儲單元。
2.8 tensor的偏移
偏移是指從張量的第一個元素開始的索引位置。
偏移程序演示
tensor的偏移
import torch""" 04
張量偏移(storage_offset)示例說明
"""
# 創建一個3行4列的浮點型張量,元素為0到11
tensor_A = torch.arange(12, dtype=torch.float32).reshape(3, 4)# 打印張量tensor_A的內容
print("tensor_A的內容:\n", tensor_A)# 打印張量tensor_A底層存儲的所有元素列表
print("tensor_A的底層存儲元素列表:\n", tensor_A.storage().tolist())# 打印tensor_A的存儲偏移量,指示張量數據在底層存儲中的起始位置
print("tensor_A的存儲偏移量:\n", tensor_A.storage_offset())# 利用切片選取tensor_A第2行到第3行、第2列的數據,生成子張量tensorB
tensorB = tensor_A[1:3, 1:2]# 打印子張量tensorB的內容
print("tensorB的內容:\n", tensorB)# 打印tensorB的存儲偏移量,可以看到相對于底層存儲的起始位置發生了變化
print("tensorB的存儲偏移量:\n", tensorB.storage_offset())# 打印tensorB底層存儲的所有元素,注意存儲仍為tensor_A共享的完整元素列表
print("tensorB的底層存儲元素列表:\n", tensorB.storage().tolist())D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\機器學習\test.py
C:\Users\98317\PycharmProjects\study_python\機器學習\test.py:13: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()print("tensor_A的底層存儲元素列表:\n", tensor_A.storage().tolist())
tensor_A的內容:tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.]])
tensor_A的底層存儲元素列表:[0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0]
tensor_A的存儲偏移量:0
tensorB的內容:tensor([[5.],[9.]])
tensorB的存儲偏移量:5
tensorB的底層存儲元素列表:[0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0]進程已結束,退出代碼為 02.9 Tensor的連續性
2.9.1 tensor的連續性是什么?
Tensor的連續性指的是其元素在內存中按照其在張量中的順序緊密存儲,沒有間隔。

生成的tensor根據"行優先"策略,在展開后與Storage存儲的順序一致,即該tensor連續。

2.9.2 tensor的不連續性是什么?
對上面的tensor進行轉置操作

生成的tensor根據"行優先"策略,在展開后與Storage存儲的順序不一致,即該tensor不連續。
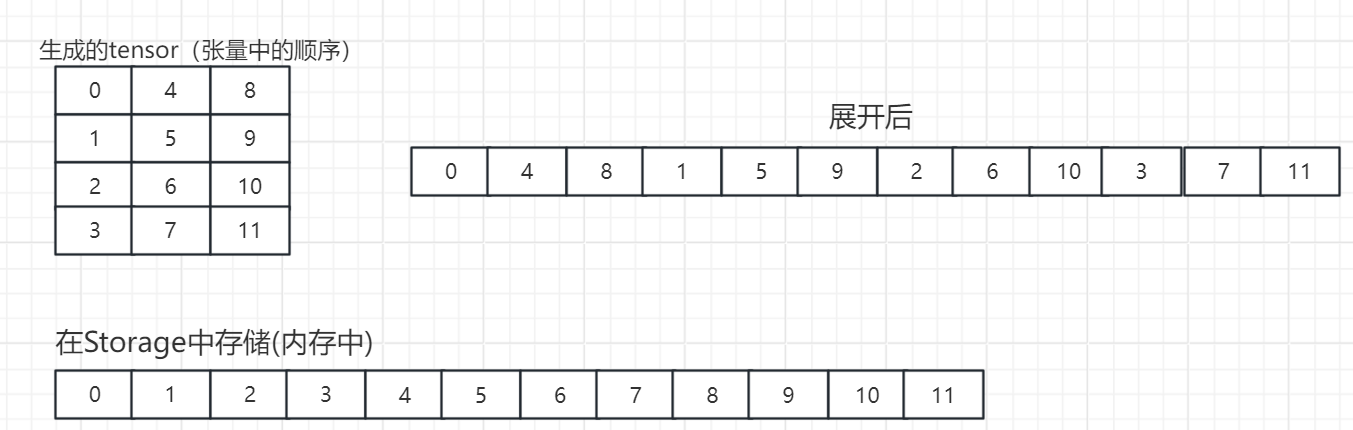
2.9.3 不連續的缺點與解決方案
當對Tensor進行某些操作,如轉置(transpose)時,可能會導致Tensor變得不連續。
連續的tensor優勢
高效的內存訪問:連續的張量在內存中占用一塊連續的空間,這使得CPU可以高效地按順序訪問數據,減少了內存尋址的時間,從而提高了數據處理的速度。
優化的計算性能:在進行數學運算時,連續張量可以減少數據的移動和復制,因為數據已經按照計算所需的順序排序排列,這樣可以減少計算中的延遲,提高整體的計算性能。
其它:在不連續的tensor上進行view()操作會報錯
連續性和非連續性編程
import torch"""06
連續性和非連續性示例說明
"""
# 創建一個包含0到11的張量,并將其形狀調整為3行4列
tensorA = torch.arange(12).reshape(3, 4) # arange生成0到11的序列,reshape調整形狀為3x4# 將tensorA展平成一維張量,默認按行優先順序
print("tensorA展平結果:", tensorA.flatten()) # 按行優先展平# 轉置tensorA,交換0軸和1軸,生成tensorB
tensorB = tensorA.transpose(0, 1)# 嘗試將tensorB展平成一維張量,默認按行優先順序
print("tensorB展平結果:", tensorB.flatten())# 打印tensorB數據在內存中的起始地址
print("tensorB數據起始地址:", tensorB.data_ptr())# 判斷tensorB是否是內存中連續存儲的張量,返回False表示不連續
print("tensorB是否連續:", tensorB.is_contiguous())# 由于tensorB不是連續的,不能直接使用view改變形狀,以下語句會報錯
# tensorB.view(1, 12)# 將tensorB轉化為內存連續的張量,生成新的tensorB
tensorB = tensorB.contiguous()# 對轉化后的tensorB執行展平操作,按行優先順序展開
print("轉化為連續后tensorB展平結果:", tensorB.flatten())# 查看tensorB底層存儲中的元素列表
print("tensorB底層存儲元素列表:", tensorB.storage().tolist())# 打印轉化后tensorB的數據起始地址,地址可能改變
print("連續化后tensorB數據起始地址:", tensorB.data_ptr())# 使用view成功改變tensorB的形狀為1行12列
print("使用view改變形狀為(1,12):", tensorB.view(1, 12))D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\機器學習\test.py
tensorA展平結果: tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
tensorB展平結果: tensor([ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11])
tensorB數據起始地址: 4949521994112
tensorB是否連續: False
轉化為連續后tensorB展平結果: tensor([ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11])
tensorB底層存儲元素列表: [0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11]
連續化后tensorB數據起始地址: 4949521994432
使用view改變形狀為(1,12): tensor([[ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11]])
C:\Users\98317\PycharmProjects\study_python\機器學習\test.py:34: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()print("tensorB底層存儲元素列表:", tensorB.storage().tolist())進程已結束,退出代碼為 0解決方案:
通過contiguous()方法將不連續的張量轉換為連續的張量。
如果tensor不是連續的,則會重新開辟一塊內存空間保證數據是在內存中是連續的。
如果tensor是連續的,則contiguous()無操作
不論是reshape view 或者其他的操作 如果連續就只改變形狀不改變storage ,如果不連續就直接申請新的內存確保連續。
總結
????????本文系統介紹了自求導方法實現線性回歸的理論基礎與具體實現步驟,首先闡述線性回歸的定義、模型方程及參數初始化,詳細講解了損失函數構建、迭代優化過程及反向傳播求導更新參數的原理與過程,輔以完整的Python編程實例,直觀展示了梯度下降的迭代效果和損失變化。此外,文章深入解析了深度學習框架PyTorch中的張量(tensor)結構,包括其定義、存儲機制、數據類型以及連續性等關鍵概念,說明了tensor底層的Storage及元數據構成,探討了步長和偏移對內存訪問的影響,并通過代碼示例演示了tensor的存儲共享、不連續性的成因及解決方案,幫助讀者全面理解PyTorch tensor的底層機制及高效操作方法,為實際深度學習模型開發打下堅實基礎。
)




Java/python/JavaScript/C++/C語言/GO六種最佳實現)











 創建教程(附 iso))
)
