介紹
問題分析
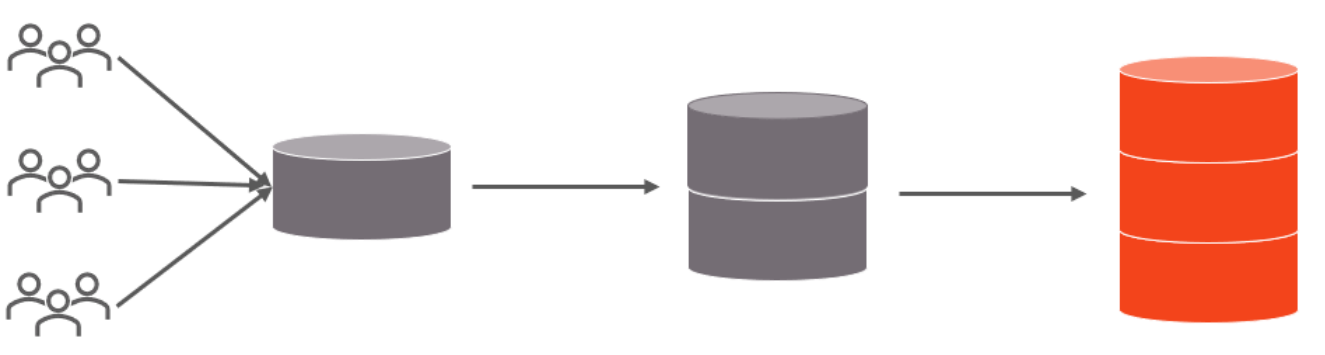
隨著互聯網及移動互聯網的發展,應用系統的數據量也是成指數式增長,若采用單數據庫進行數據存
儲,存在以下性能瓶頸:
1. IO瓶頸:熱點數據太多,數據庫緩存不足,產生大量磁盤IO,效率較低。 請求數據太多,帶寬
不夠,網絡IO瓶頸。
2. CPU瓶頸:排序、分組、連接查詢、聚合統計等SQL會耗費大量的CPU資源,請求數太多,CPU出
現瓶頸。
為了解決上述問題,我們需要對數據庫進行分庫分表處理。
分庫分表的中心思想都是將數據分散存儲,使得單一數據庫/表的數據量變小來緩解單一數據庫的性能
問題,從而達到提升數據庫性能的目的。
拆分策略
分庫分表的形式,主要是兩種:垂直拆分和水平拆分。而拆分的粒度,一般又分為分庫和分表,所以組
成的拆分策略最終如下:
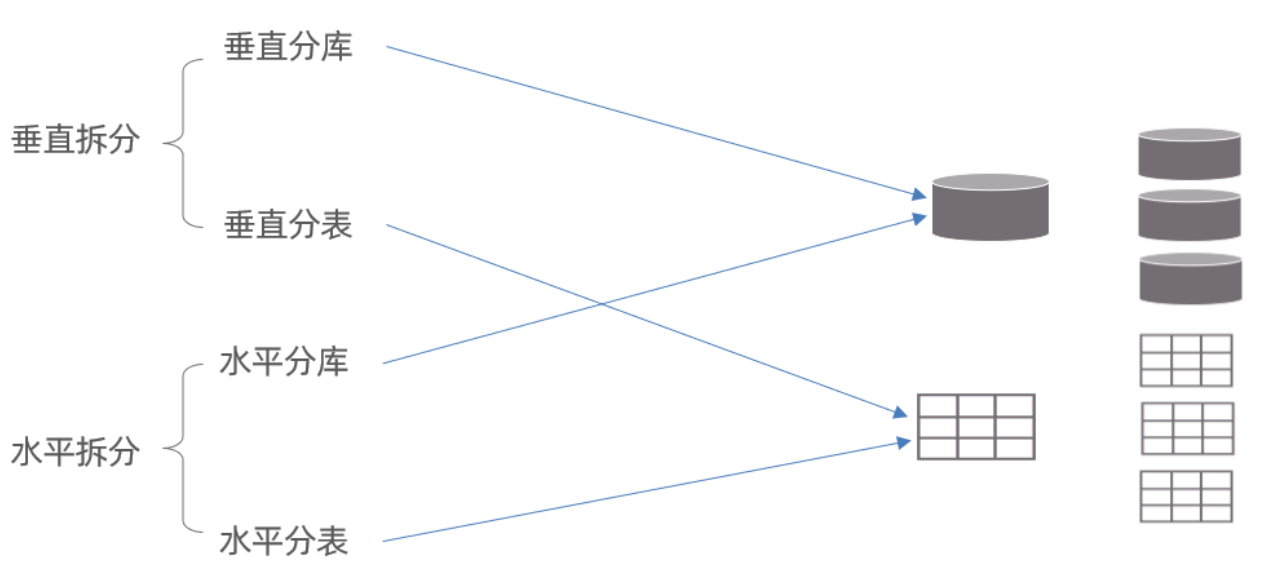
垂直拆分
垂直分庫
垂直分庫:以表為依據,根據業務將不同表拆分到不同庫中。
特點:
每個庫的表結構都不一樣。
每個庫的數據也不一樣。
所有庫的并集是全量數據
垂直分表
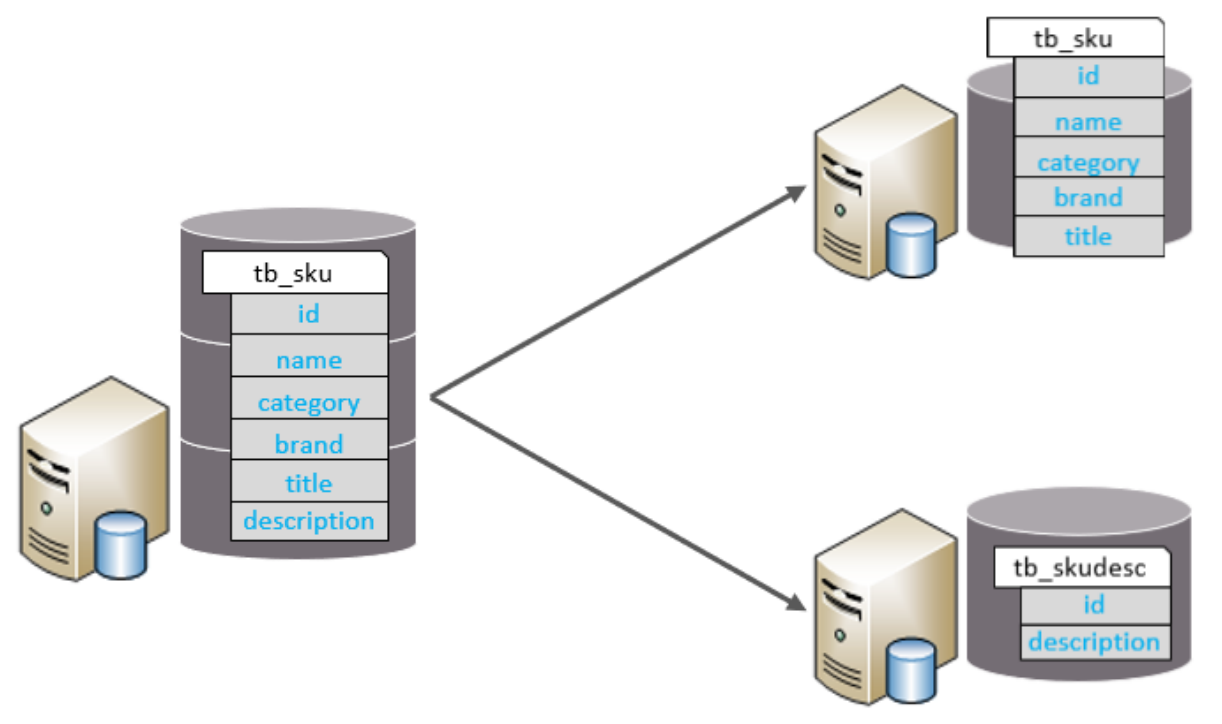
垂直分表:以字段為依據,根據字段屬性將不同字段拆分到不同表中。
特點:
每個表的結構都不一樣。
每個表的數據也不一樣,一般通過一列(主鍵/外鍵)關聯。
所有表的并集是全量數據。
水平拆分
水平分庫
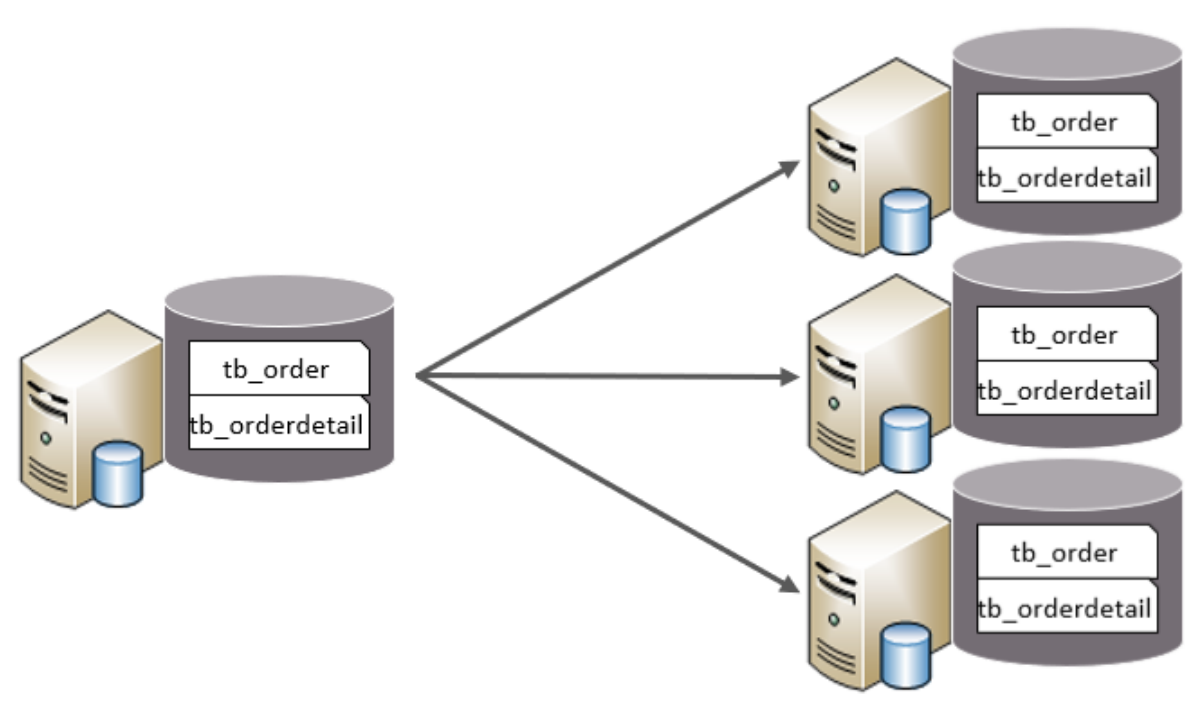
水平分庫:以字段為依據,按照一定策略,將一個庫的數據拆分到多個庫中。
特點:
每個庫的表結構都一樣。
每個庫的數據都不一樣。
所有庫的并集是全量數據。
水平分表
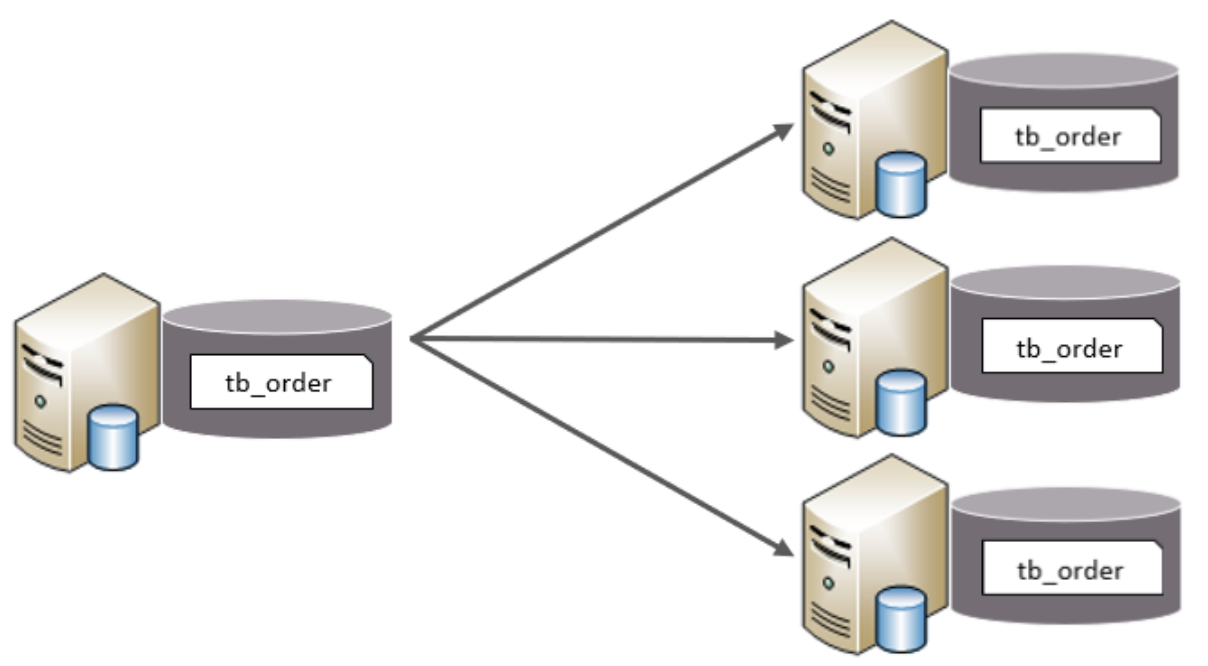
水平分表:以字段為依據,按照一定策略,將一個表的數據拆分到多個表中。
特點:
每個表的表結構都一樣。
每個表的數據都不一樣。
所有表的并集是全量數據。
在業務系統中,為了緩解磁盤IO及CPU的性能瓶頸,到底是垂直拆分,還是水平拆分;具體是分
庫,還是分表,都需要根據具體的業務需求具體分析。實現技術
shardingJDBC:基于AOP原理,在應用程序中對本地執行的SQL進行攔截,解析、改寫、路由處
理。需要自行編碼配置實現,只支持java語言,性能較高。
MyCat:數據庫分庫分表中間件,不用調整代碼即可實現分庫分表,支持多種語言,性能不及前
者。
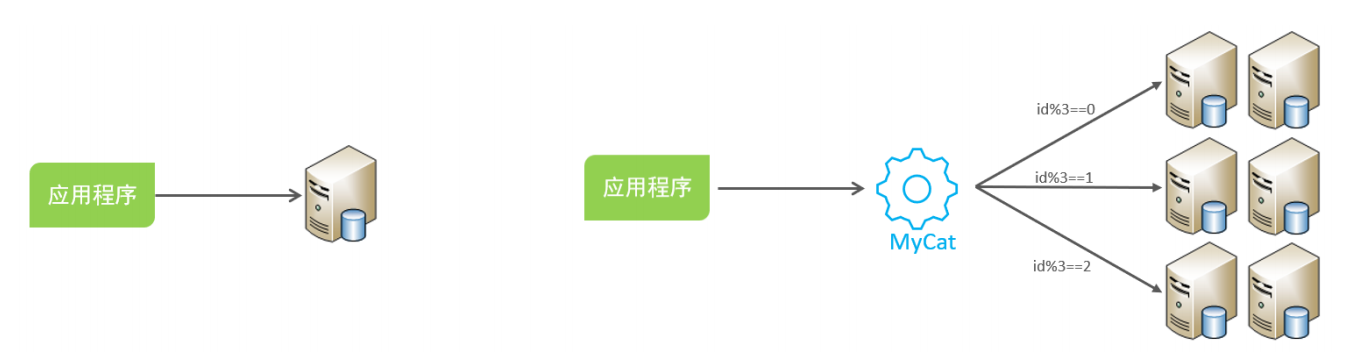
后面介紹的是根據是MyCat數據庫中間件,通過MyCat中間件來完成分庫分表操作。
MyCat概述
介紹
Mycat是開源的、活躍的、基于Java語言編寫的MySQL數據庫中間件。可以像使用mysql一樣來使用
mycat,對于開發人員來說根本感覺不到mycat的存在。
開發人員只需要連接MyCat即可,而具體底層用到幾臺數據庫,每一臺數據庫服務器里面存儲了什么數
據,都無需關心。 具體的分庫分表的策略,只需要在MyCat中配置即可。
優勢:
性能可靠穩定
強大的技術團隊
體系完善
社區活躍
下載
下載地址:http://dl.mycat.org.cn/
安裝
Mycat是采用java語言開發的開源的數據庫中間件,支持Windows和Linux運行環境,下面介紹
MyCat的Linux中的環境搭建。我們需要在準備好的服務器中安裝如下軟件。
MySQL
JDK
Mycat
| 服務器 | 安裝軟件 | 說明 |
| 192.168.200.210 | Jdk,Mycat | Mycat中間件服務器 |
| 192.168.200.210 | MySQL | 分片服務器 |
| 192.168.200.213 | MySQL | 分片服務器 |
| 192.168.200.214 | MySQL | 分片服務器 |
目錄介紹

bin : 存放可執行文件,用于啟動停止mycat
conf:存放mycat的配置文件
lib:存放mycat的項目依賴包(jar)
logs:存放mycat的日志文件
概念介紹
在MyCat的整體結構中,分為兩個部分:上面的邏輯結構、下面的物理結構。
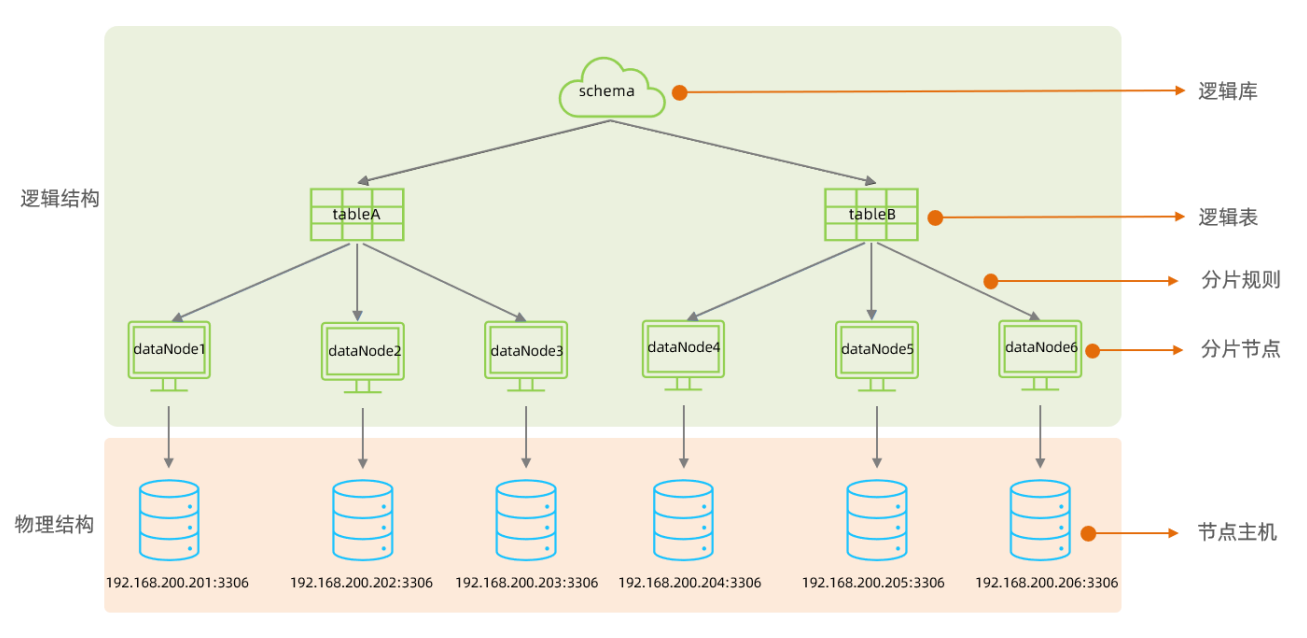
在MyCat的邏輯結構主要負責邏輯庫、邏輯表、分片規則、分片節點等邏輯結構的處理,而具體的數據
存儲還是在物理結構,也就是數據庫服務器中存儲的。
MyCat入門
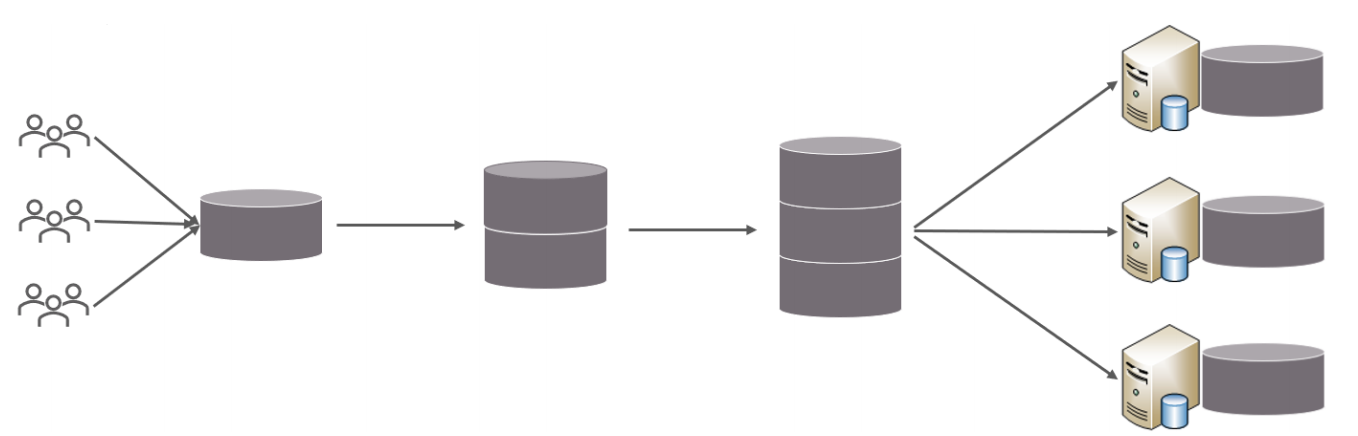
需求
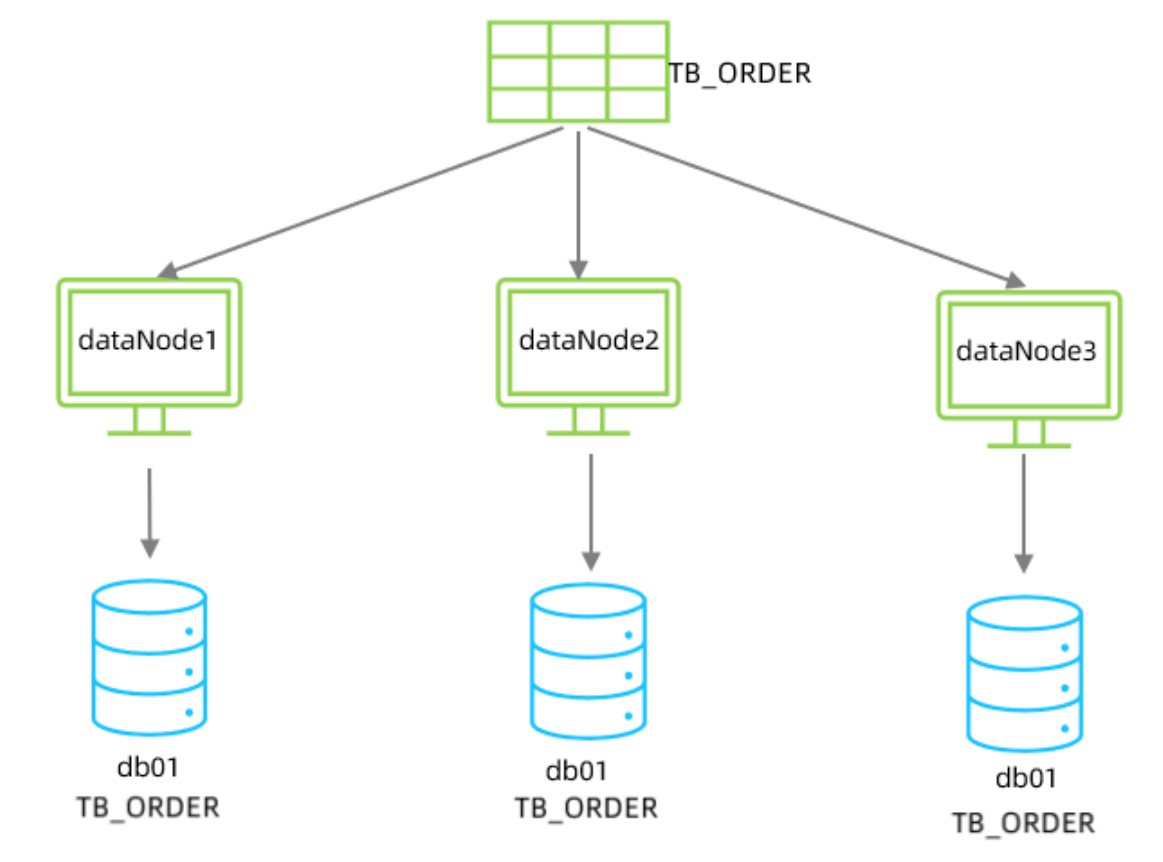
由于 tb_order 表中數據量很大,磁盤IO及容量都到達了瓶頸,現在需要對 tb_order 表進行數
據分片,分為三個數據節點,每一個節點主機位于不同的服務器上, 具體的結構,參考下圖:
環境準備
準備3臺服務器:
192.168.200.210:MyCat中間件服務器,同時也是第一個分片服務器。
192.168.200.213:第二個分片服務器。
192.168.200.214:第三個分片服務器。
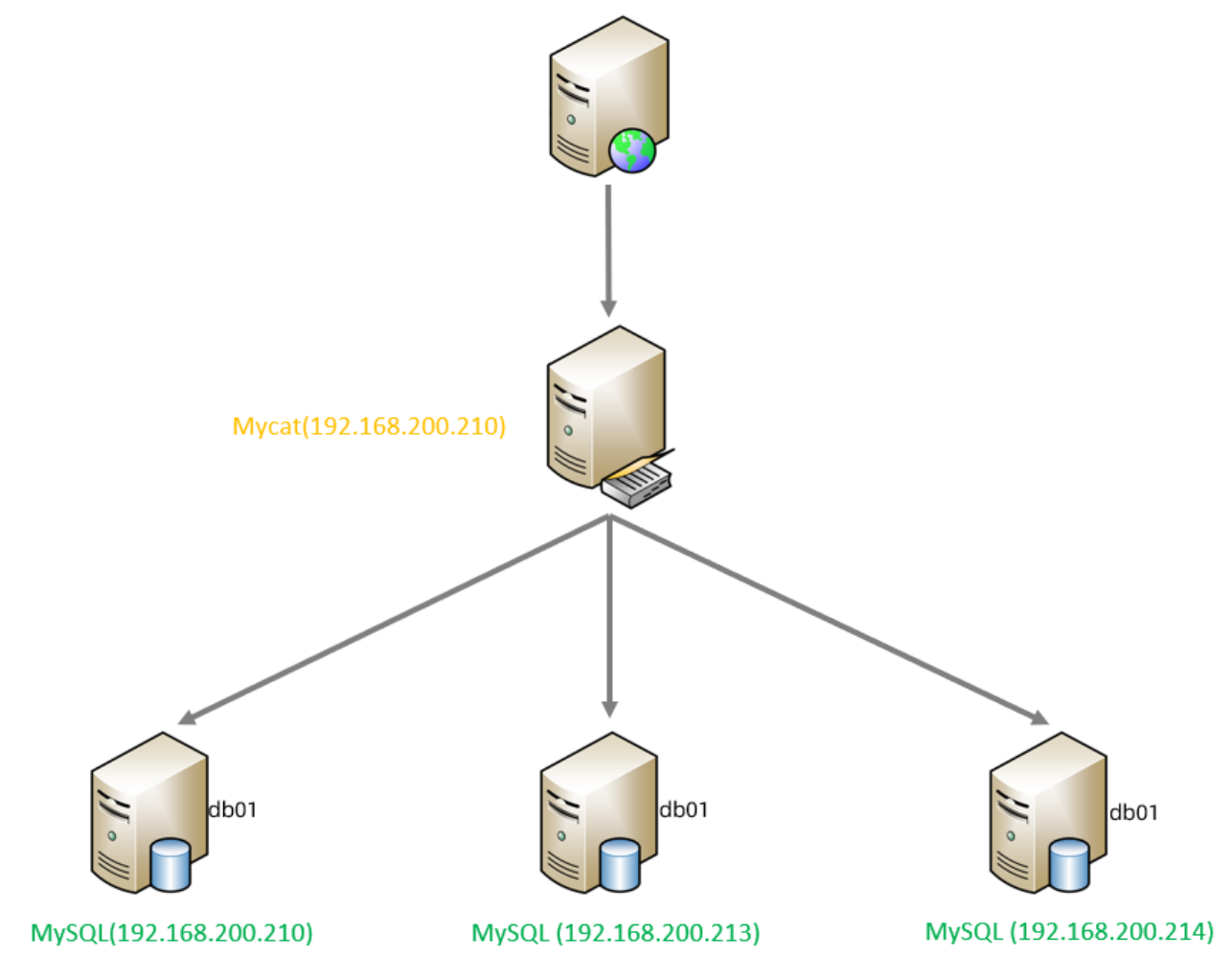
并且在上述3臺數據庫中創建數據庫 db01 。
配置
schema.xml
在schema.xml中配置邏輯庫、邏輯表、數據節點、節點主機等相關信息。具體的配置如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><schema name="DB01" checkSQLschema="true" sqlMaxLimit="100"><table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long"/></schema><dataNode name="dn1" dataHost="dhost1" database="db01" /><dataNode name="dn2" dataHost="dhost2" database="db01" /><dataNode name="dn3" dataHost="dhost3" database="db01" /><dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.210:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"user="root" password="1234" />
</dataHost><dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"user="root" password="1234" />
</dataHost><dataHost name="dhost3" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"user="root" password="1234" />
</dataHost></mycat:schema>server.xml
需要在server.xml中配置用戶名、密碼,以及用戶的訪問權限信息,具體的配置如下:
<user name="root" defaultAccount="true"><property name="password">123456</property><property name="schemas">DB01</property><!-- 表級 DML 權限設置 --><!--<privileges check="true"><schema name="DB01" dml="0110" ><table name="TB_ORDER" dml="1110"></table></schema></privileges>-->
</user><user name="user"><property name="password">123456</property><property name="schemas">DB01</property><property name="readOnly">true</property>
</user>上述的配置表示,定義了兩個用戶 root 和 user ,這兩個用戶都可以訪問 DB01 這個邏輯庫,訪
問密碼都是123456,但是root用戶訪問DB01邏輯庫,既可以讀,又可以寫,但是 user用戶訪問
DB01邏輯庫是只讀的。
測試
啟動
配置完畢后,先啟動涉及到的3臺分片服務器,然后啟動MyCat服務器。切換到Mycat的安裝目錄,執
行如下指令,啟動Mycat:
#啟動
bin/mycat start#停止
bin/mycat stopMycat啟動之后,占用端口號 8066。
啟動完畢之后,可以查看logs目錄下的啟動日志,查看Mycat是否啟動完成。
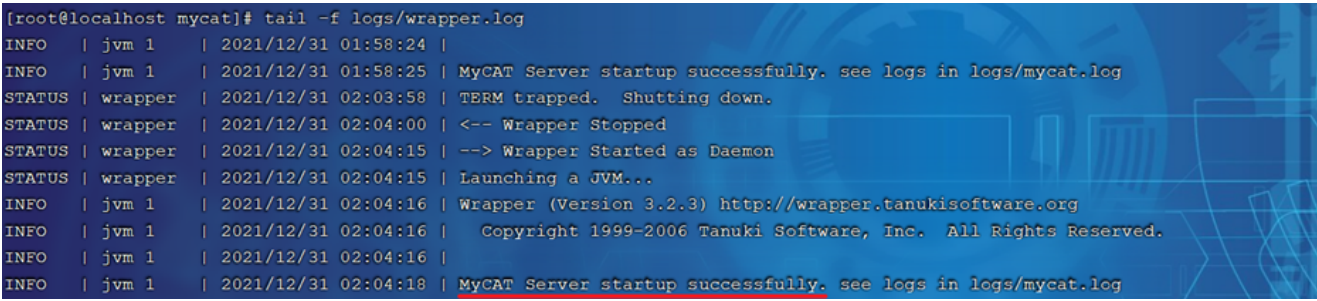
測試
連接Mycat
通過如下指令,就可以連接并登陸MyCat。
mysql -h 192.168.200.210 -P 8066 -uroot -p123456我們看到我們是通過MySQL的指令來連接的MyCat,因為MyCat在底層實際上是模擬了MySQL的協議。
數據測試
然后就可以在MyCat中來創建表,并往表結構中插入數據,查看數據在MySQL中的分布情況。
CREATE TABLE TB_ORDER (
id BIGINT(20) NOT NULL,title VARCHAR(100) NOT NULL ,
PRIMARY KEY (id)
) ENGINE=INNODB DEFAULT CHARSET=utf8 ;
INSERT INTO TB_ORDER(id,title) VALUES(1,'goods1');
INSERT INTO TB_ORDER(id,title) VALUES(2,'goods2');
INSERT INTO TB_ORDER(id,title) VALUES(3,'goods3');
INSERT INTO TB_ORDER(id,title) VALUES(1,'goods1');
INSERT INTO TB_ORDER(id,title) VALUES(2,'goods2');
INSERT INTO TB_ORDER(id,title) VALUES(3,'goods3');
INSERT INTO TB_ORDER(id,title) VALUES(5000000,'goods5000000');
INSERT INTO TB_ORDER(id,title) VALUES(10000000,'goods10000000');
INSERT INTO TB_ORDER(id,title) VALUES(10000001,'goods10000001');
INSERT INTO TB_ORDER(id,title) VALUES(15000000,'goods15000000');
INSERT INTO TB_ORDER(id,title) VALUES(15000001,'goods15000001');經過測試,我們發現,在往 TB_ORDER 表中插入數據時:
如果id的值在1-500w之間,數據將會存儲在第一個分片數據庫中。
如果id的值在500w-1000w之間,數據將會存儲在第二個分片數據庫中。
如果id的值在1000w-1500w之間,數據將會存儲在第三個分片數據庫中。
如果id的值超出1500w,在插入數據時,將會報錯。
為什么會出現這種現象,數據到底落在哪一個分片服務器到底是如何決定的呢? 這是由邏輯表配置時
的一個參數 rule 決定的,而這個參數配置的就是分片規則。
Mycat配置
schema.xml
schema.xml 作為MyCat中最重要的配置文件之一 , 涵蓋了MyCat的邏輯庫 、 邏輯表 、 分片規
則、分片節點及數據源的配置。

主要包含以下三組標簽:
schema標簽
datanode標簽
datahost標簽
scheml標簽
schema定義邏輯庫

schema 標簽用于定義 MyCat實例中的邏輯庫 , 一個MyCat實例中, 可以有多個邏輯庫 , 可以通
過 schema 標簽來劃分不同的邏輯庫。MyCat中的邏輯庫的概念,等同于MySQL中的database概念
, 需要操作某個邏輯庫下的表時, 也需要切換邏輯庫(use xxx)。
核心屬性:
1、name:指定自定義的邏輯庫庫名
2、checkSQLschema:在SQL語句操作時指定了數據庫名稱,執行時是否自動去除;true:自動去
除,false:不自動去除
3、sqlMaxLimit:如果未指定limit進行查詢,列表查詢模式查詢多少條記錄
schema中的table定義邏輯表

table 標簽定義了MyCat中邏輯庫schema下的邏輯表 , 所有需要拆分的表都需要在table標簽中定
義 。核心屬性:
1、name:定義邏輯表表名,在該邏輯庫下唯一
2、dataNode:定義邏輯表所屬的dataNode,該屬性需要與dataNode標簽中name對應;多個
dataNode逗號分隔
3、rule:分片規則的名字,分片規則名字是在rule.xml中定義的
4、primaryKey:邏輯表對應真實表的主鍵
5、type:邏輯表的類型,目前邏輯表只有全局表和普通表,如果未配置,就是普通表;全局表,配
置為 global
datanode標簽

核心屬性:
name:定義數據節點名稱
dataHost:數據庫實例主機名稱,引用自 dataHost 標簽中name屬性
database:定義分片所屬數據庫
datahost標簽

該標簽在MyCat邏輯庫中作為底層標簽存在, 直接定義了具體的數據庫實例、讀寫分離、心跳語句。
核心屬性:
1、name:唯一標識,供上層標簽使用
2、maxCon/minCon:最大連接數/最小連接數
3、balance:負載均衡策略,取值 0,1,2,3
4、writeType:寫操作分發方式(0:寫操作轉發到第一個writeHost,第一個掛了,切換到第二
個;1:寫操作隨機分發到配置的writeHost)
5、dbDriver:數據庫驅動,支持 native、jdbc
rule.xml
rule.xml中定義所有拆分表的規則, 在使用過程中可以靈活的使用分片算法, 或者對同一個分片算法
使用不同的參數, 它讓分片過程可配置化。主要包含兩類標簽:tableRule、Function。
server.xml
server.xml配置文件包含了MyCat的系統配置信息,主要有兩個重要的標簽:system、user。
system標簽

主要配置MyCat中的系統配置信息,對應的系統配置項及其含義參考
user標簽
配置MyCat中的用戶、訪問密碼,以及用戶針對于邏輯庫、邏輯表的權限信息,具體的權限描述方式及
配置說明如下:

在測試權限操作時,我們只需要將 privileges 標簽的注釋放開。 在 privileges 下的schema
標簽中配置的dml屬性配置的是邏輯庫的權限。 在privileges的schema下的table標簽的dml屬性
中配置邏輯表的權限。
Mycat分片
垂直拆分
場景
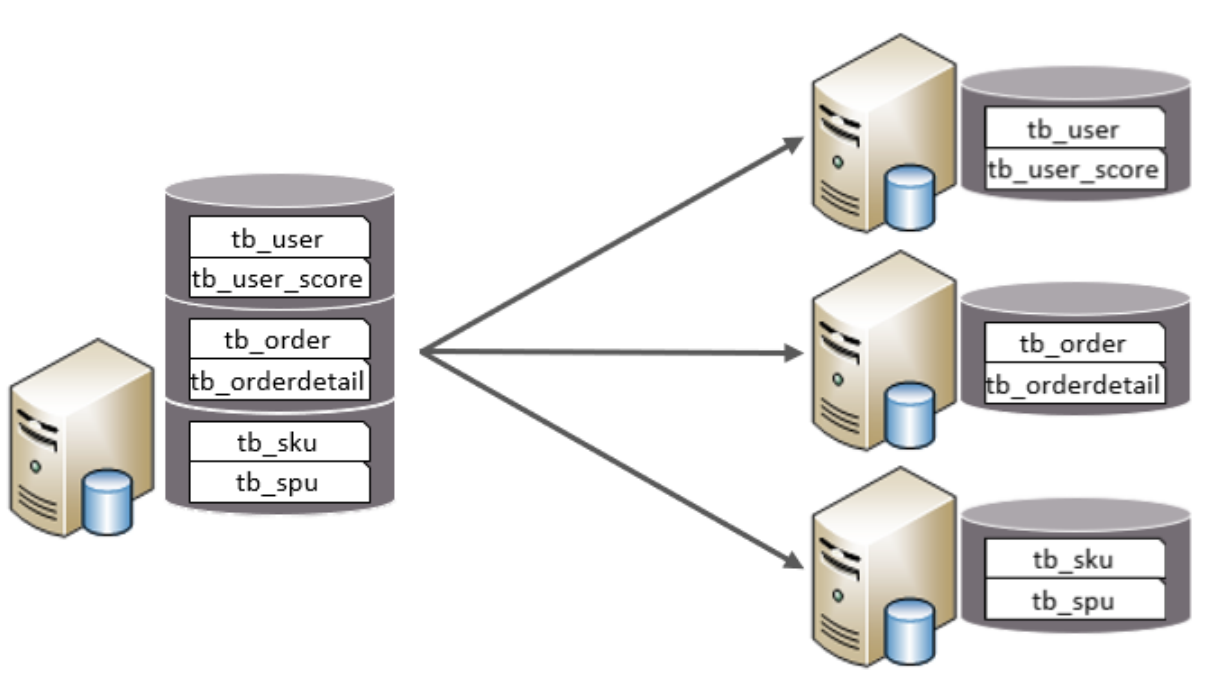
在業務系統中, 涉及以下表結構 ,但是由于用戶與訂單每天都會產生大量的數據, 單臺服務器的數據
存儲及處理能力是有限的, 可以對數據庫表進行拆分, 原有的數據庫表如下。
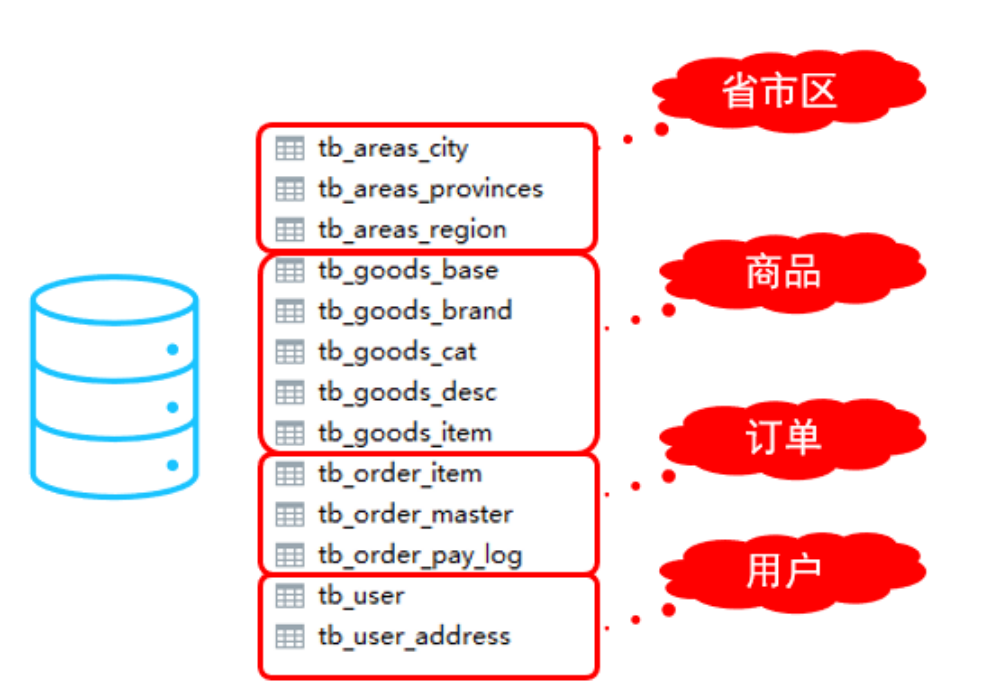
現在考慮將其進行垂直分庫操作,將商品相關的表拆分到一個數據庫服務器,訂單表拆分的一個數據庫
服務器,用戶及省市區表拆分到一個服務器。最終結構如下:
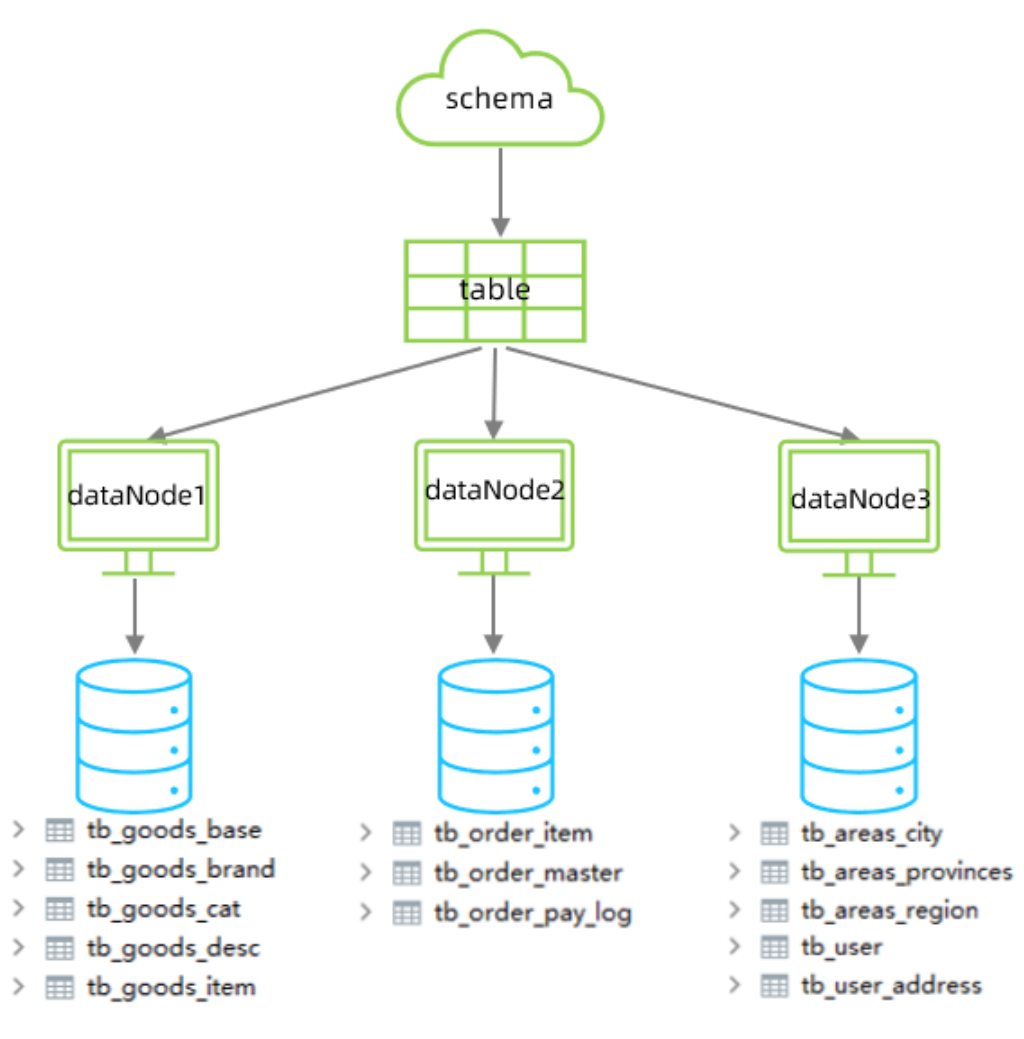
準備
準備三臺服務器,IP地址如圖所示:
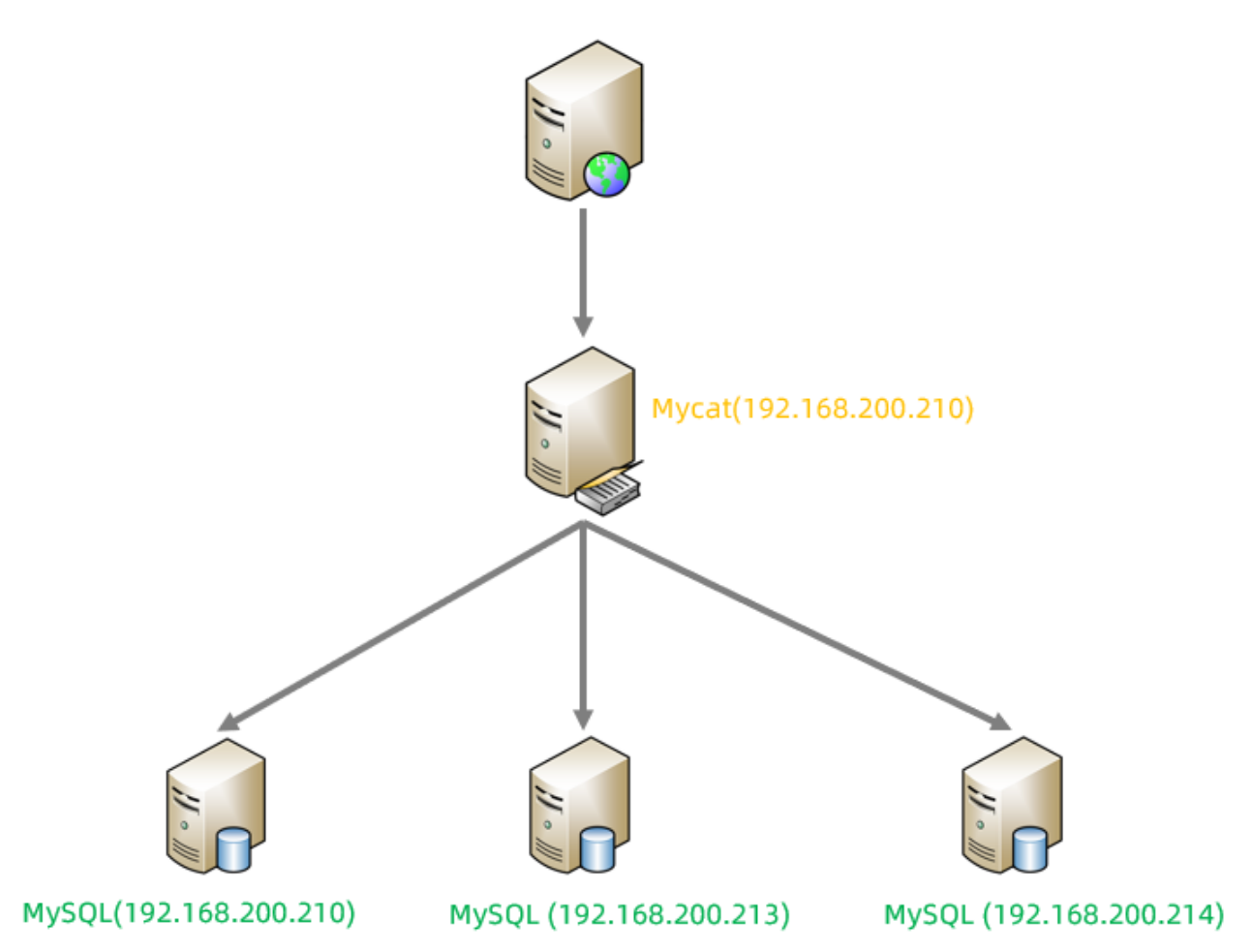
并且在192.168.200.210,192.168.200.213, 192.168.200.214上面創建數據庫 shopping。
配置
schema.xml
<schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100"><table name="tb_goods_base" dataNode="dn1" primaryKey="id" /><table name="tb_goods_brand" dataNode="dn1" primaryKey="id" /><table name="tb_goods_cat" dataNode="dn1" primaryKey="id" /><table name="tb_goods_desc" dataNode="dn1" primaryKey="goods_id" /><table name="tb_goods_item" dataNode="dn1" primaryKey="id" /><table name="tb_order_item" dataNode="dn2" primaryKey="id" /><table name="tb_order_master" dataNode="dn2" primaryKey="order_id" /><table name="tb_order_pay_log" dataNode="dn2" primaryKey="out_trade_no" /><table name="tb_user" dataNode="dn3" primaryKey="id" /><table name="tb_user_address" dataNode="dn3" primaryKey="id" /><table name="tb_areas_provinces" dataNode="dn3" primaryKey="id"/><table name="tb_areas_city" dataNode="dn3" primaryKey="id"/><table name="tb_areas_region" dataNode="dn3" primaryKey="id"/>
</schema><dataNode name="dn1" dataHost="dhost1" database="shopping" />
<dataNode name="dn2" dataHost="dhost2" database="shopping" />
<dataNode name="dn3" dataHost="dhost3" database="shopping" /><dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.210:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"user="root" password="1234" />
</dataHost><dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"user="root" password="1234" />
</dataHost><dataHost name="dhost3" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"user="root" password="1234" />
</dataHost>server.xml
<user name="root" defaultAccount="true"><property name="password">123456</property><property name="schemas">SHOPPING</property><!-- 表級 DML 權限設置 --><!--<privileges check="true"><schema name="DB01" dml="0110" ><table name="TB_ORDER" dml="1110"></table></schema></privileges>-->
</user><user name="user"><property name="password">123456</property><property name="schemas">SHOPPING</property><property name="readOnly">true</property>
</user>測試
上傳SQL腳本到/root目錄

導入測試數據
重新啟動MyCat后,在mycat的命令行中,通過source指令導入表結構,以及對應的數據,查看數據。
分布情況。
source /root/shopping-table.sql
source /root/shopping-insert.sql將表結構及對應的測試數據導入之后,可以檢查一下各個數據庫服務器中的表結構分布情況。 檢查是
否和我們準備工作中規劃的服務器一致。
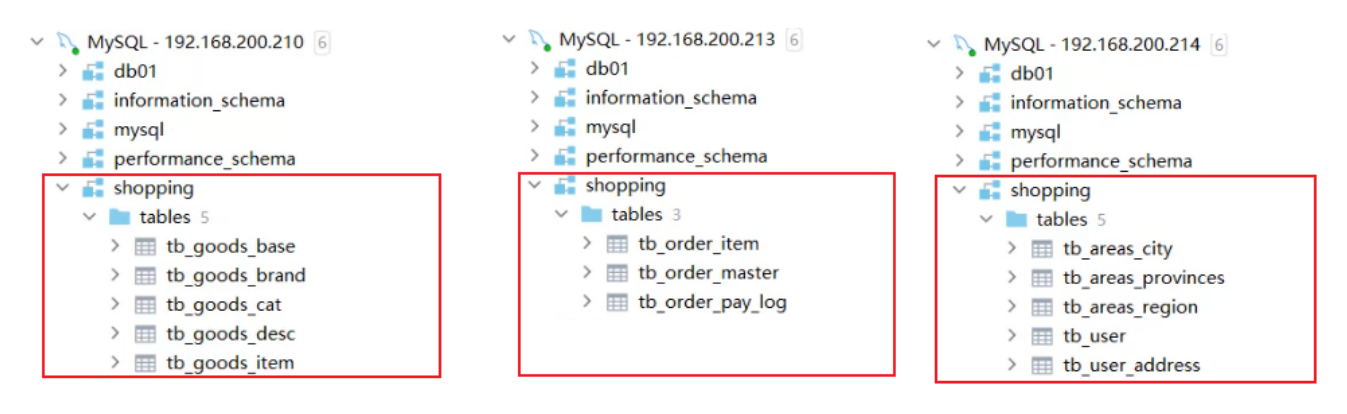
查詢用戶的收件人及收件人地址信息
在MyCat的命令行中,當我們執行以下多表聯查的SQL語句時,可以正常查詢出數據。
select ua.user_id, ua.contact, p.province, c.city, r.area , ua.address from
tb_user_address ua ,tb_areas_city c , tb_areas_provinces p ,tb_areas_region r
where ua.province_id = p.provinceid and ua.city_id = c.cityid and ua.town_id =
r.areaid ;
查詢每一筆訂單及訂單的收件地址信息
實現該需求對應的SQL語句如下:
SELECT order_id , payment ,receiver, province , city , area FROM tb_order_master o
, tb_areas_provinces p , tb_areas_city c , tb_areas_region r WHERE
o.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND
o.receiver_region = r.areaid ;但是現在存在一個問題,訂單相關的表結構是在 192.168.200.213 數據庫服務器中,而省市區的數
據庫表是在 192.168.200.214 數據庫服務器中。那么在MyCat中執行是否可以成功呢?

經過測試,我們看到,SQL語句執行報錯。原因就是因為MyCat在執行該SQL語句時,需要往具體的數
據庫服務器中路由,而當前沒有一個數據庫服務器完全包含了訂單以及省市區的表結構,造成SQL語句
失敗,報錯。
對于上述的這種現象,我們如何來解決呢? 下面我們介紹的全局表,就可以輕松解決這個問題。
全局表
對于省、市、區/縣表tb_areas_provinces , tb_areas_city , tb_areas_region,是屬于
數據字典表,在多個業務模塊中都可能會遇到,可以將其設置為全局表,利于業務操作。
修改schema.xml中的邏輯表的配置,修改 tb_areas_provinces、tb_areas_city、
tb_areas_region 三個邏輯表,增加 type 屬性,配置為global,就代表該表是全局表,就會在
所涉及到的dataNode中創建給表。對于當前配置來說,也就意味著所有的節點中都有該表了。
<table name="tb_areas_provinces" dataNode="dn1,dn2,dn3" primaryKey="id"type="global"/><table name="tb_areas_city" dataNode="dn1,dn2,dn3" primaryKey="id"type="global"/><table name="tb_areas_region" dataNode="dn1,dn2,dn3" primaryKey="id"type="global"/>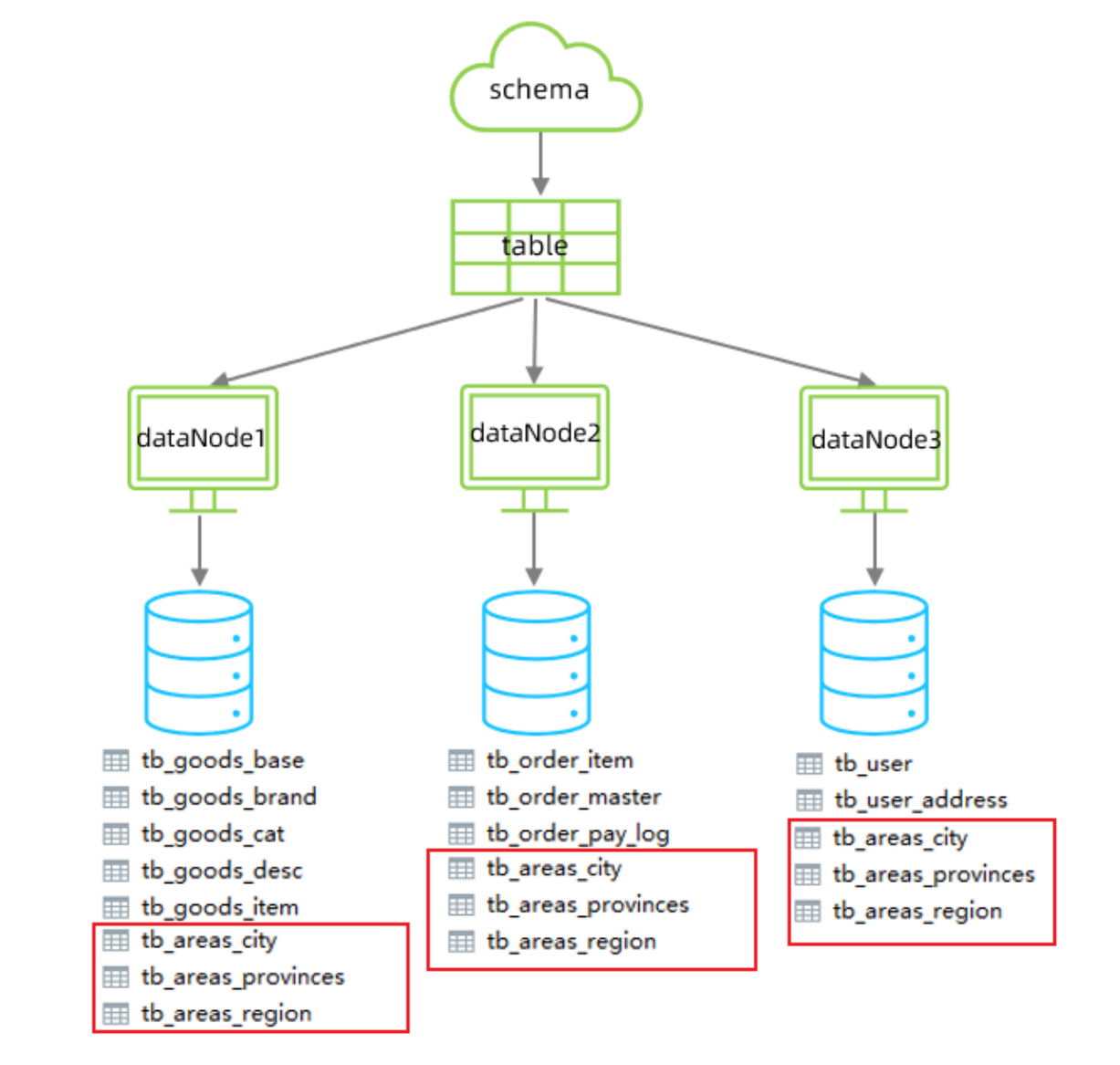
配置完畢后,重新啟動MyCat。
1). 刪除原來每一個數據庫服務器中的所有表結構。
2). 通過source指令,導入表及數據。
source /root/shopping-table.sql
source /root/shopping-insert.sql3).檢查每一個數據庫服務器中的表及數據分布,看到三個節點中都有這三張全局表。
4). 然后再次執行上面的多表聯查的SQL語句。
SELECT order_id , payment ,receiver, province , city , area FROM tb_order_master o
, tb_areas_provinces p , tb_areas_city c , tb_areas_region r WHERE
o.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND
o.receiver_region = r.areaid ;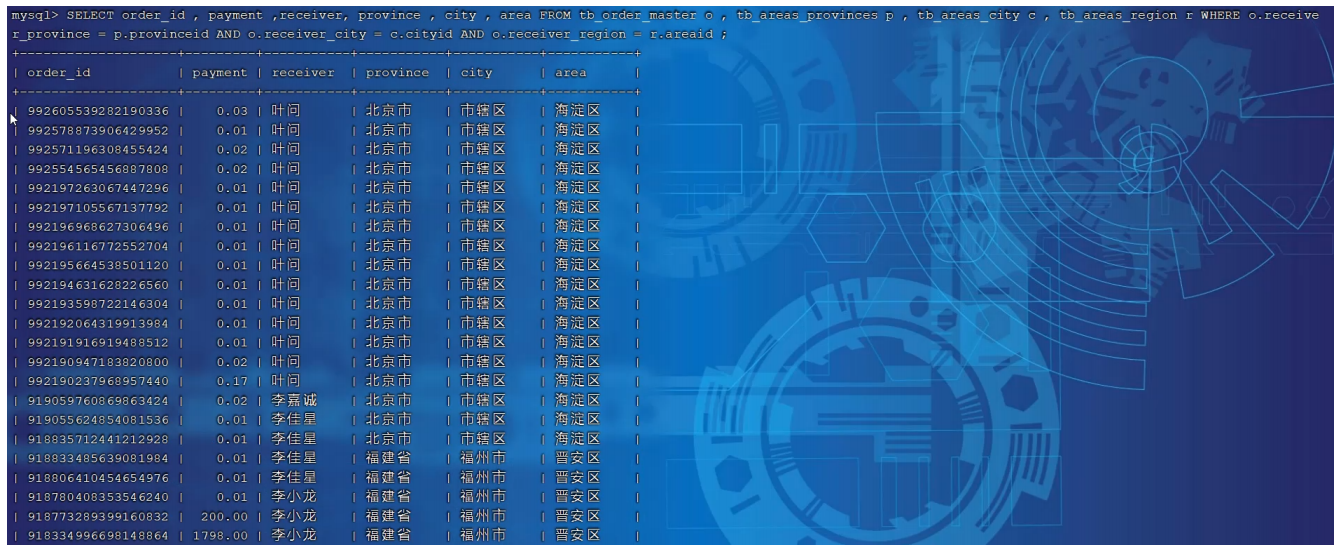
是可以正常執行成功的。
5). 當在MyCat中更新全局表的時候,我們可以看到,所有分片節點中的數據都發生了變化,每個節
點的全局表數據時刻保持一致。
水平拆分
場景
在業務系統中, 有一張表(日志表), 業務系統每天都會產生大量的日志數據 , 單臺服務器的數據存
儲及處理能力是有限的, 可以對數據庫表進行拆分。
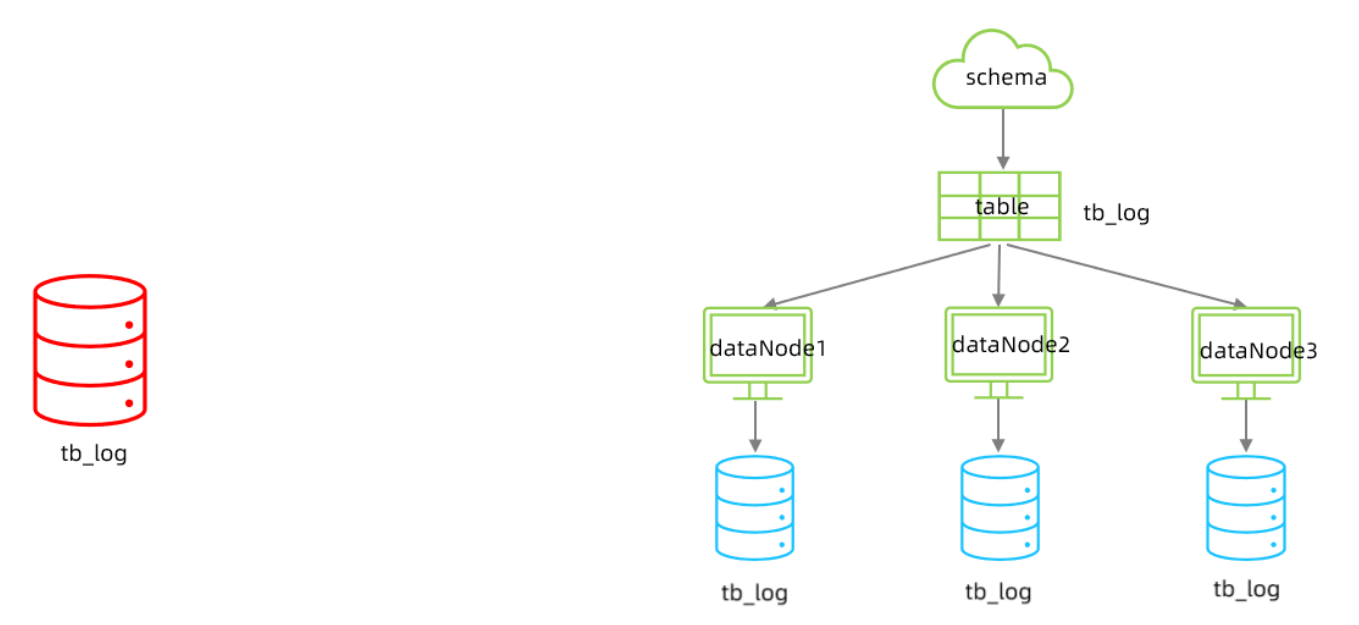
準備
準備三臺服務器,具體的結構如下:
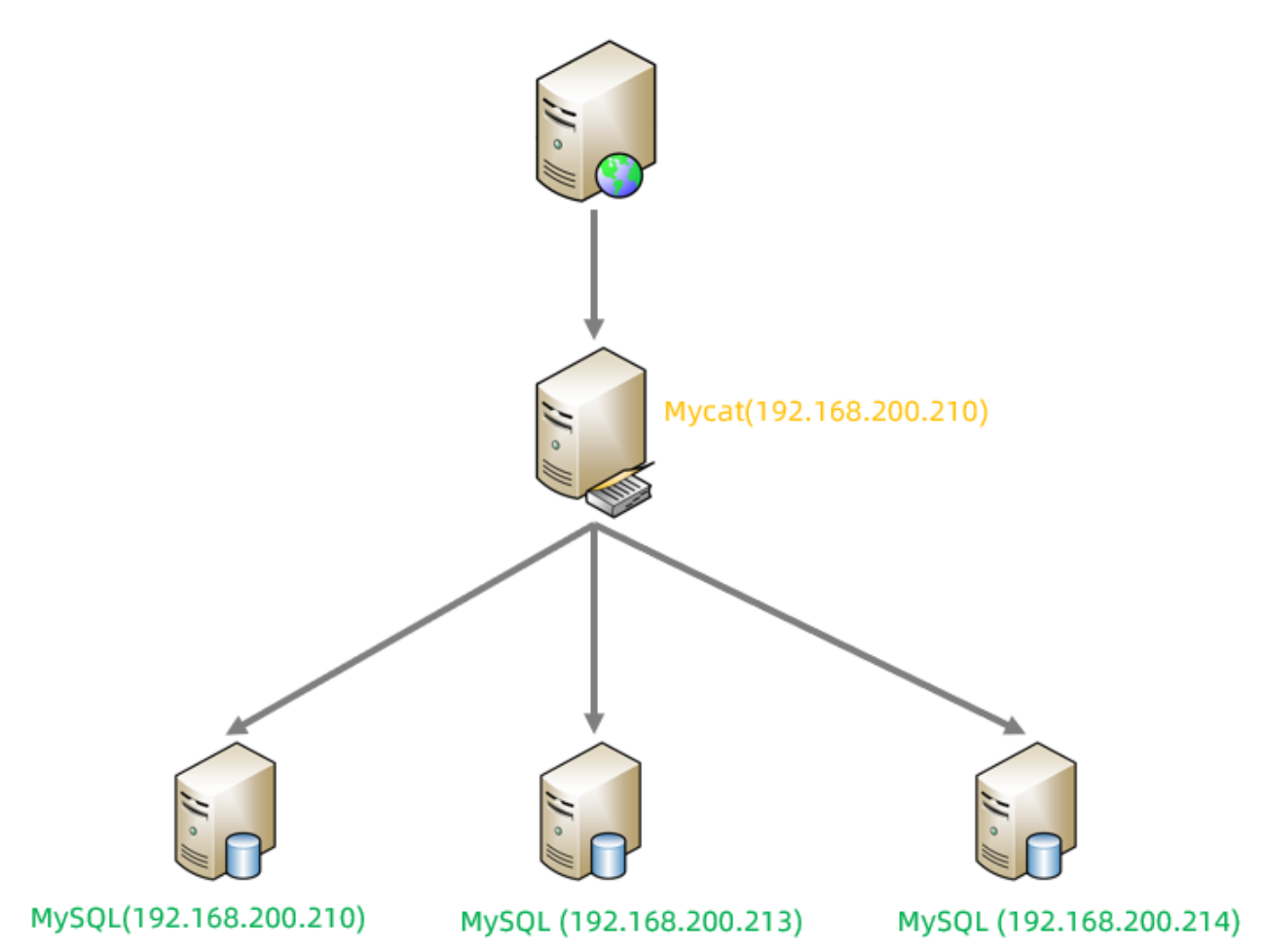
并且,在三臺數據庫服務器中分表創建一個數據庫itcast。
配置
schema.xml
<schema name="ITCAST" checkSQLschema="true" sqlMaxLimit="100"><table name="tb_log" dataNode="dn4,dn5,dn6" primaryKey="id" rule="mod-long" />
</schema><dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />tb_log表最終落在3個節點中,分別是 dn4、dn5、dn6 ,而具體的數據分別存儲在 dhost1、
dhost2、dhost3的itcast數據庫中。
server.xml
配置root用戶既可以訪問 SHOPPING 邏輯庫,又可以訪問ITCAST邏輯庫。
<user name="root" defaultAccount="true"><property name="password">123456</property><property name="schemas">SHOPPING,ITCAST</property><!-- 表級 DML 權限設置 --><!--<privileges check="true"><schema name="DB01" dml="0110" ><table name="TB_ORDER" dml="1110"></table></schema></privileges>-->
</user>測試
配置完畢后,重新啟動MyCat,然后在mycat的命令行中,執行如下SQL創建表、并插入數據,查看數
據分布情況。
CREATE TABLE tb_log (id bigint(20) NOT NULL COMMENT 'ID',model_name varchar(200) DEFAULT NULL COMMENT '模塊名',model_value varchar(200) DEFAULT NULL COMMENT '模塊值',return_value varchar(200) DEFAULT NULL COMMENT '返回值',return_class varchar(200) DEFAULT NULL COMMENT '返回值類型',operate_user varchar(20) DEFAULT NULL COMMENT '操作用戶',operate_time varchar(20) DEFAULT NULL COMMENT '操作時間',param_and_value varchar(500) DEFAULT NULL COMMENT '請求參數名及參數值',operate_class varchar(200) DEFAULT NULL COMMENT '操作類',operate_method varchar(200) DEFAULT NULL COMMENT '操作方法',cost_time bigint(20) DEFAULT NULL COMMENT '執行方法耗時, 單位 ms',source int(1) DEFAULT NULL COMMENT '來源 : 1 PC , 2 Android , 3 IOS',PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;INSERT INTO tb_log (id, model_name, model_value, return_value, return_class,
operate_user, operate_time, param_and_value, operate_class, operate_method,
cost_time,source)
VALUES('1','user','insert','success','java.lang.String','10001','2022-01-06
18:12:28','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.contro
ller.UserController','insert','10',1);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class,
operate_user, operate_time, param_and_value, operate_class, operate_method,
cost_time,source)
VALUES('2','user','insert','success','java.lang.String','10001','2022-01-06
18:12:27','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.contro
ller.UserController','insert','23',1);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class,
operate_user, operate_time, param_and_value, operate_class, operate_method,
cost_time,source)
VALUES('3','user','update','success','java.lang.String','10001','2022-01-06
18:16:45','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.contro
ller.UserController','update','34',1);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class,
operate_user, operate_time, param_and_value, operate_class, operate_method,
cost_time,source)
VALUES('4','user','update','success','java.lang.String','10001','2022-01-06
18:16:45','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.contro
ller.UserController','update','13',2);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class,
operate_user, operate_time, param_and_value, operate_class, operate_method,
cost_time,source)
VALUES('5','user','insert','success','java.lang.String','10001','2022-01-06
18:30:31','{\"age\":\"200\",\"name\":\"TomCat\",\"gender\":\"0\"}','cn.itcast.co
ntroller.UserController','insert','29',3);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class,
operate_user, operate_time, param_and_value, operate_class, operate_method,
cost_time,source)
VALUES('6','user','find','success','java.lang.String','10001','2022-01-06
18:30:31','{\"age\":\"200\",\"name\":\"TomCat\",\"gender\":\"0\"}','cn.itcast.co
ntroller.UserController','find','29',2);分片規則
范圍分片
介紹
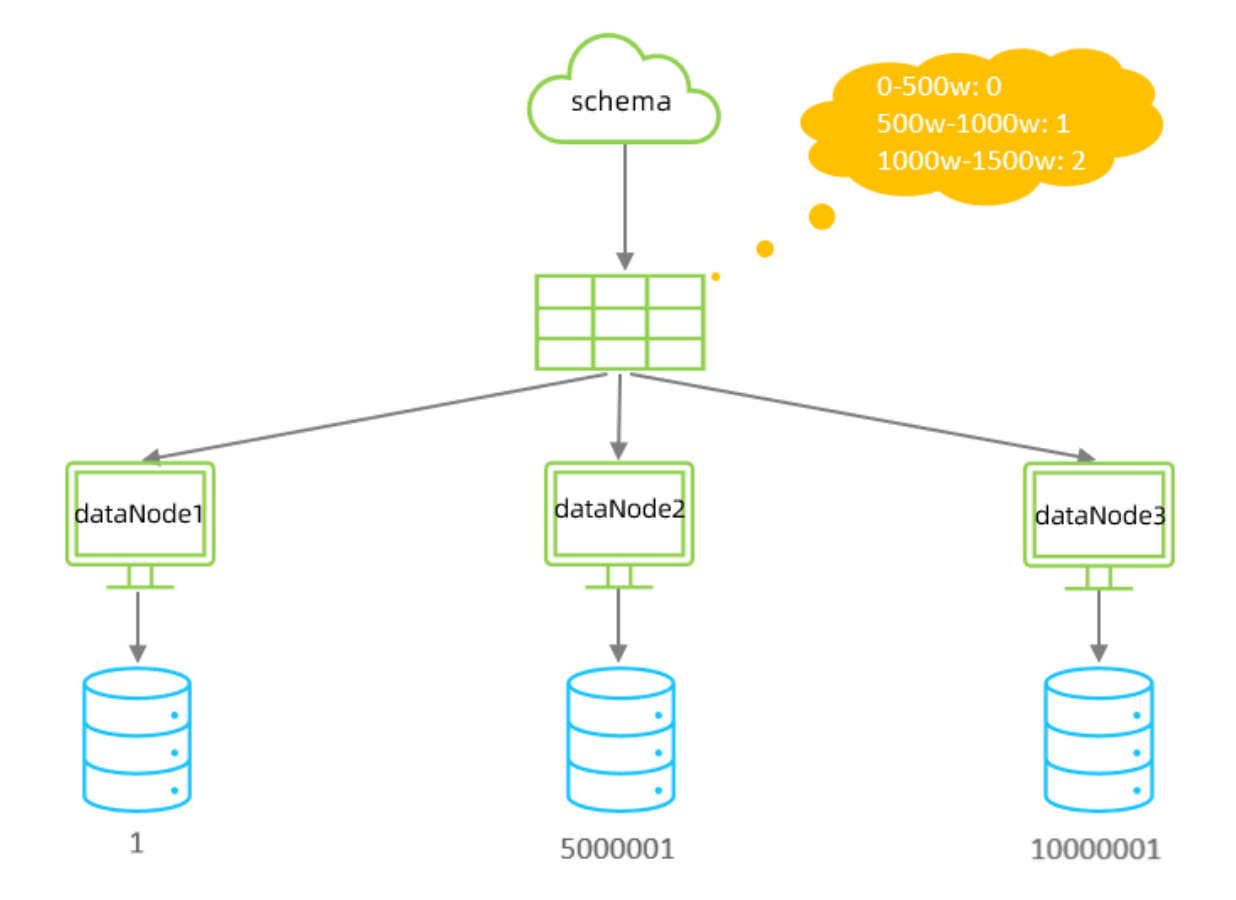
根據指定的字段及其配置的范圍與數據節點的對應情況, 來決定該數據屬于哪一個分片。
配置
schema.xml 邏輯表配置
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />schema.xml 數據節點配置
<dataNode name="dn1" dataHost="dhost1" database="db01" />
<dataNode name="dn2" dataHost="dhost2" database="db01" />
<dataNode name="dn3" dataHost="dhost3" database="db01" />rule.xml 分片規則配置
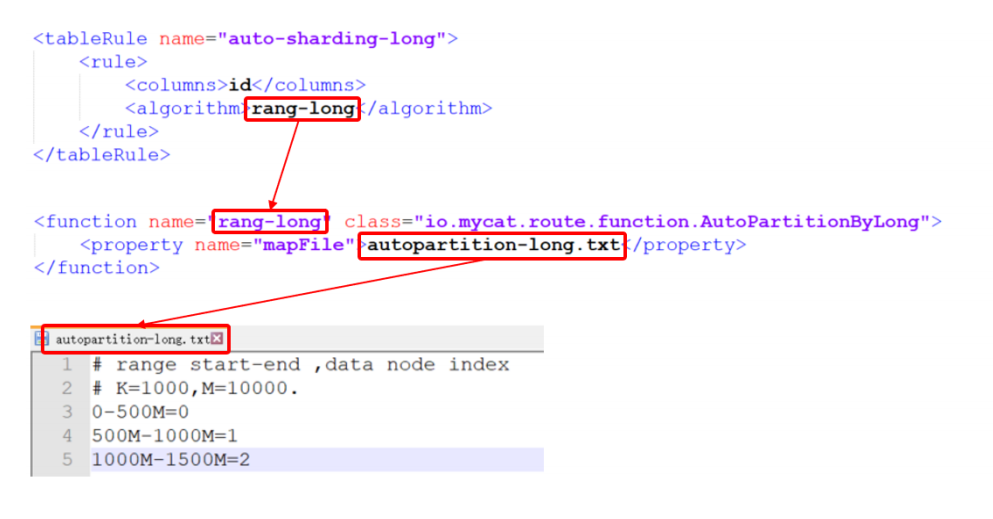
<tableRule name="auto-sharding-long"><rule><columns>id</columns><algorithm>rang-long</algorithm></rule>
</tableRule><function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong"><property name="mapFile">autopartition-long.txt</property><property name="defaultNode">0</property>
</function>分片規則配置屬性含義:
| 屬性 | 描述 |
| columns | 標識將要分片的表字段 |
| algorithm | 指定分片函數與function的對應關系 |
| class | 指定該分片算法對應的類 |
| mapFile | 對應的外部配置文件 |
| type | 默認值為0 ; 0 表示Integer , 1 表示String |
| dafaultNode | 默認節點 默認節點的所用:枚舉分片時,如果碰到不識別的枚舉值, 就讓它路 由到默認節點 ; 如果沒有默認值,碰到不識別的則報錯 。 |
在rule.xml中配置分片規則時,關聯了一個映射配置文件 autopartition-long.txt,該配置文
件的配置如下:
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2含義:0-500萬之間的值,存儲在0號數據節點(數據節點的索引從0開始) ; 500萬-1000萬之間的
數據存儲在1號數據節點 ; 1000萬-1500萬的數據節點存儲在2號節點 ;
該分片規則,主要是針對于數字類型的字段適用。 在MyCat的入門程序中,我們使用的就是該分片規
則。
取模分片
介紹
根據指定的字段值與節點數量進行求模運算,根據運算結果, 來決定該數據屬于哪一個分片。
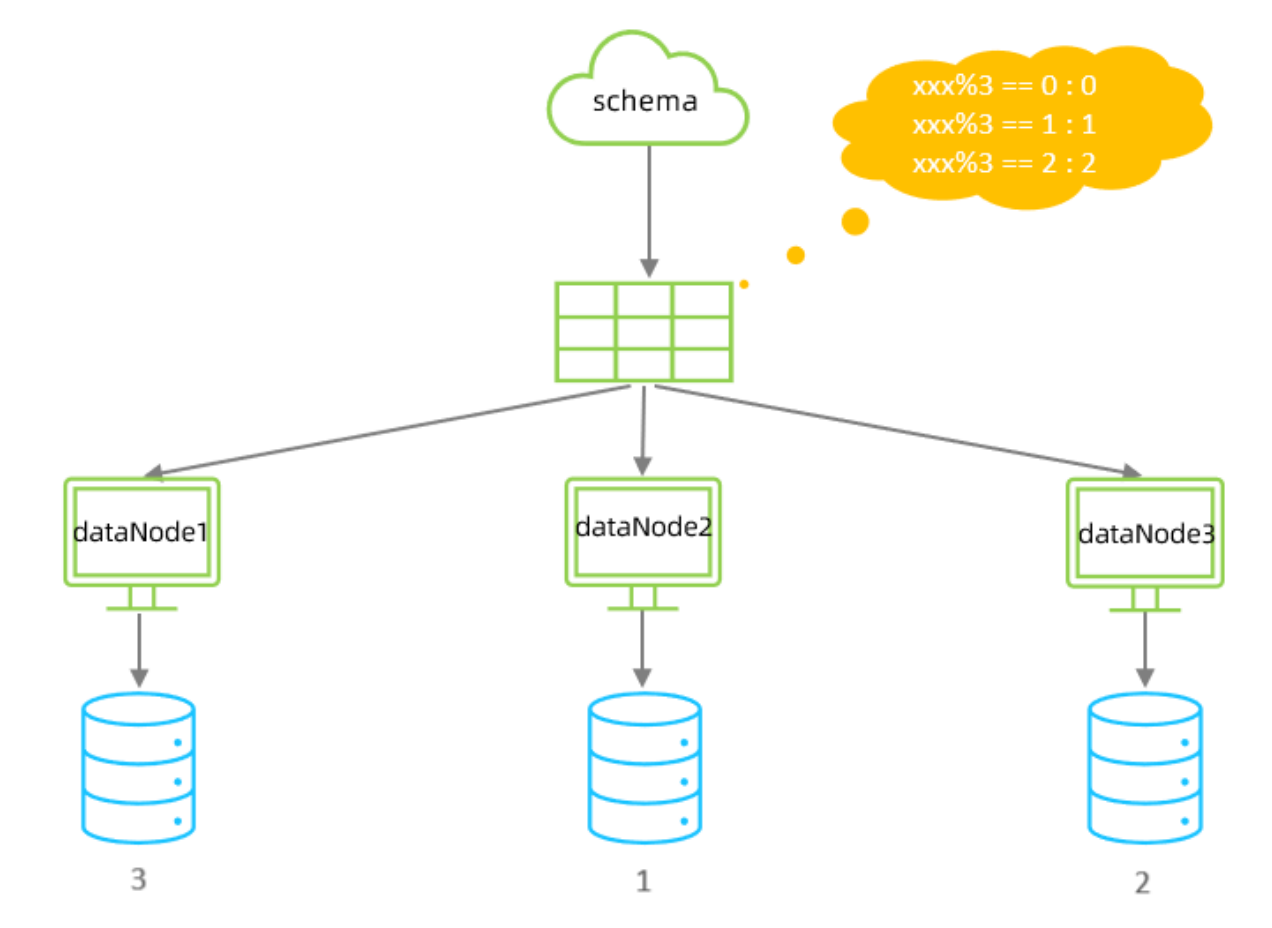
配置
schema.xml配置
<table name="tb_log" dataNode="dn4,dn5,dn6" primaryKey="id" rule="mod-long" />schema.xml 數據節點配置
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rulex.xml配置
<tableRule name="mod-long"><rule><columns>id</columns><algorithm>mod-long</algorithm></rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod"><property name="count">3</property>
</function>分片規則屬性說明如下:
| 屬性 | 描述 |
| columns | 標識將要分片的表字段 |
| algorithm | 指定分片函數與function的對應關系 |
| class | 指定該分片算法對應的類 |
| count | 數據節點的數量 |
該分片規則,主要是針對于數字類型的字段適用。 在前面水平拆分的演示中,我們選擇的就是取模分
片。
測試
配置完畢后,重新啟動MyCat,然后在mycat的命令行中,執行如下SQL創建表、并插入數據,查看數
據分布情況。
一致性分片
介紹
所謂一致性哈希,相同的哈希因子計算值總是被劃分到相同的分區表中,不會因為分區節點的增加而改
變原來數據的分區位置,有效的解決了分布式數據的拓容問題。
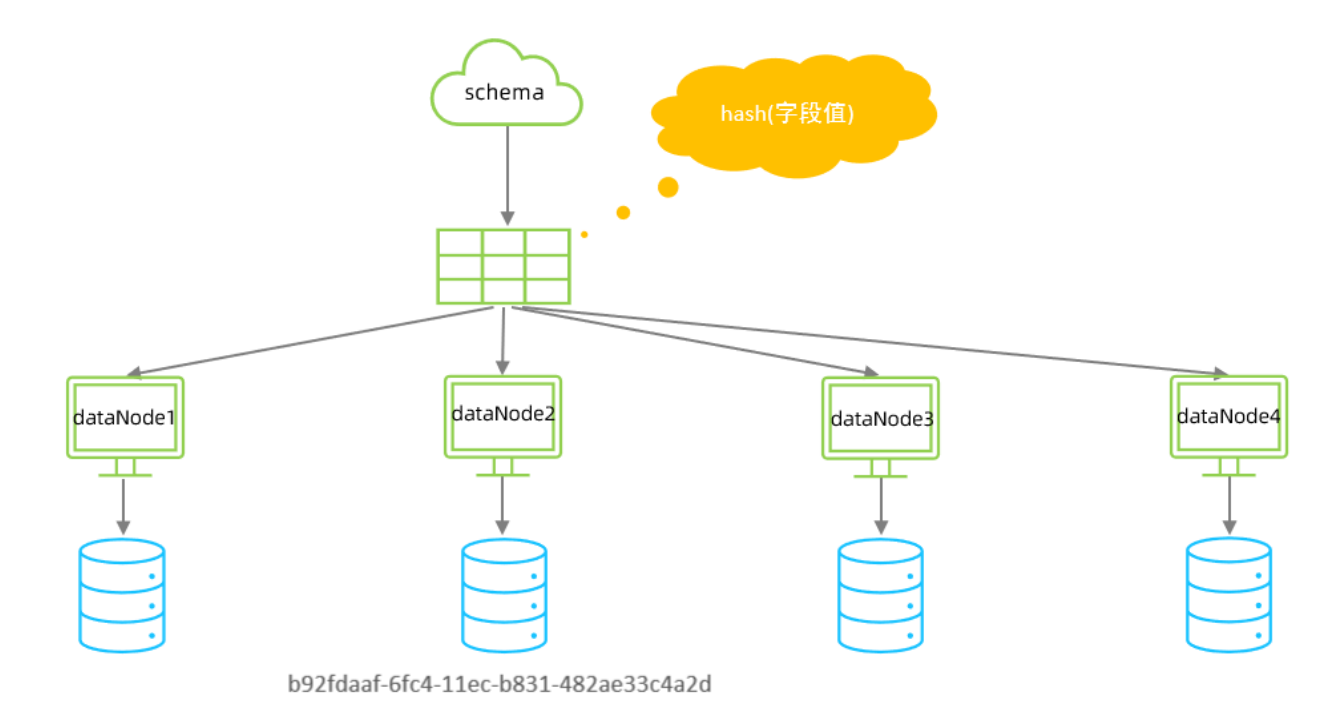
配置
schema.xml配置
<!-- 一致性hash -->
<table name="tb_order" dataNode="dn4,dn5,dn6" rule="sharding-by-murmur" />schema.xml 中數據節點配置
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml 配置
<tableRule name="sharding-by-murmur"><rule><columns>id</columns><algorithm>murmur</algorithm></rule>
</tableRule><function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash"><property name="seed">0</property><!-- 默認是0 --><property name="count">3</property><property name="virtualBucketTimes">160</property>
</function>分片規則屬性含義
| 屬性 | 描述 |
| columns | 標識將要分片的表字段 |
| algorithm | 指定分片函數與function的對應關系 |
| class | 指定該分片算法對應的類 |
| seed | 創建murmur_hash對象的種子,默認0 |
| count | 要分片的數據庫節點數量,必須指定,否則沒法分片 |
| virtualBucketTimes | 一個實際的數據庫節點被映射為這么多虛擬節點,默認是160倍,也 就是虛擬節點數是物理節點數的160 倍;virtualBucketTimes*count就是虛擬結點數量 ; |
| weightMapFile | 節點的權重,沒有指定權重的節點默認是1。以properties文件的 格式填寫,以從0開始到count-1的整數值也就是節點索引為key, 以節點權重值為值。所有權重值必須是正整數,否則以1代替 |
| bucketMapPath | 用于測試時觀察各物理節點與虛擬節點的分布情況,如果指定了這個 屬性,會把虛擬節點的murmur hash值與物理節點的映射按行輸出 到這個文件,沒有默認值,如果不指定,就不會輸出任何東西 |
測試
配置完畢后,重新啟動MyCat,然后在mycat的命令行中,執行如下SQL創建表、并插入數據,查看數
據分布情況。
create table tb_order(
id varchar(100) not null primary key,
money int null,
content varchar(200) null
);
INSERT INTO tb_order (id, money, content) VALUES ('b92fdaaf-6fc4-11ec-b831-
482ae33c4a2d', 10, 'b92fdaf8-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b93482b6-6fc4-11ec-b831-
482ae33c4a2d', 20, 'b93482d5-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b937e246-6fc4-11ec-b831-
482ae33c4a2d', 50, 'b937e25d-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b93be2dd-6fc4-11ec-b831-
482ae33c4a2d', 100, 'b93be2f9-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b93f2d68-6fc4-11ec-b831-
482ae33c4a2d', 130, 'b93f2d7d-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9451b98-6fc4-11ec-b831-
482ae33c4a2d', 30, 'b9451bcc-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9488ec1-6fc4-11ec-b831-
482ae33c4a2d', 560, 'b9488edb-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b94be6e6-6fc4-11ec-b831-
482ae33c4a2d', 10, 'b94be6ff-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b94ee10d-6fc4-11ec-b831-
482ae33c4a2d', 123, 'b94ee12c-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b952492a-6fc4-11ec-b831-
482ae33c4a2d', 145, 'b9524945-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b95553ac-6fc4-11ec-b831-
482ae33c4a2d', 543, 'b95553c8-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9581cdd-6fc4-11ec-b831-
482ae33c4a2d', 17, 'b9581cfa-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b95afc0f-6fc4-11ec-b831-
482ae33c4a2d', 18, 'b95afc2a-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b95daa99-6fc4-11ec-b831-
482ae33c4a2d', 134, 'b95daab2-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b9667e3c-6fc4-11ec-b831-
482ae33c4a2d', 156, 'b9667e60-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b96ab489-6fc4-11ec-b831-
482ae33c4a2d', 175, 'b96ab4a5-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b96e2942-6fc4-11ec-b831-
482ae33c4a2d', 180, 'b96e295b-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b97092ec-6fc4-11ec-b831-
482ae33c4a2d', 123, 'b9709306-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b973727a-6fc4-11ec-b831-
482ae33c4a2d', 230, 'b9737293-6fc4-11ec-b831-482ae33c4a2d');
INSERT INTO tb_order (id, money, content) VALUES ('b978840f-6fc4-11ec-b831-
482ae33c4a2d', 560, 'b978843c-6fc4-11ec-b831-482ae33c4a2d');枚舉分片
介紹
通過在配置文件中配置可能的枚舉值, 指定數據分布到不同數據節點上, 本規則適用于按照省份、性
別、狀態拆分數據等業務。
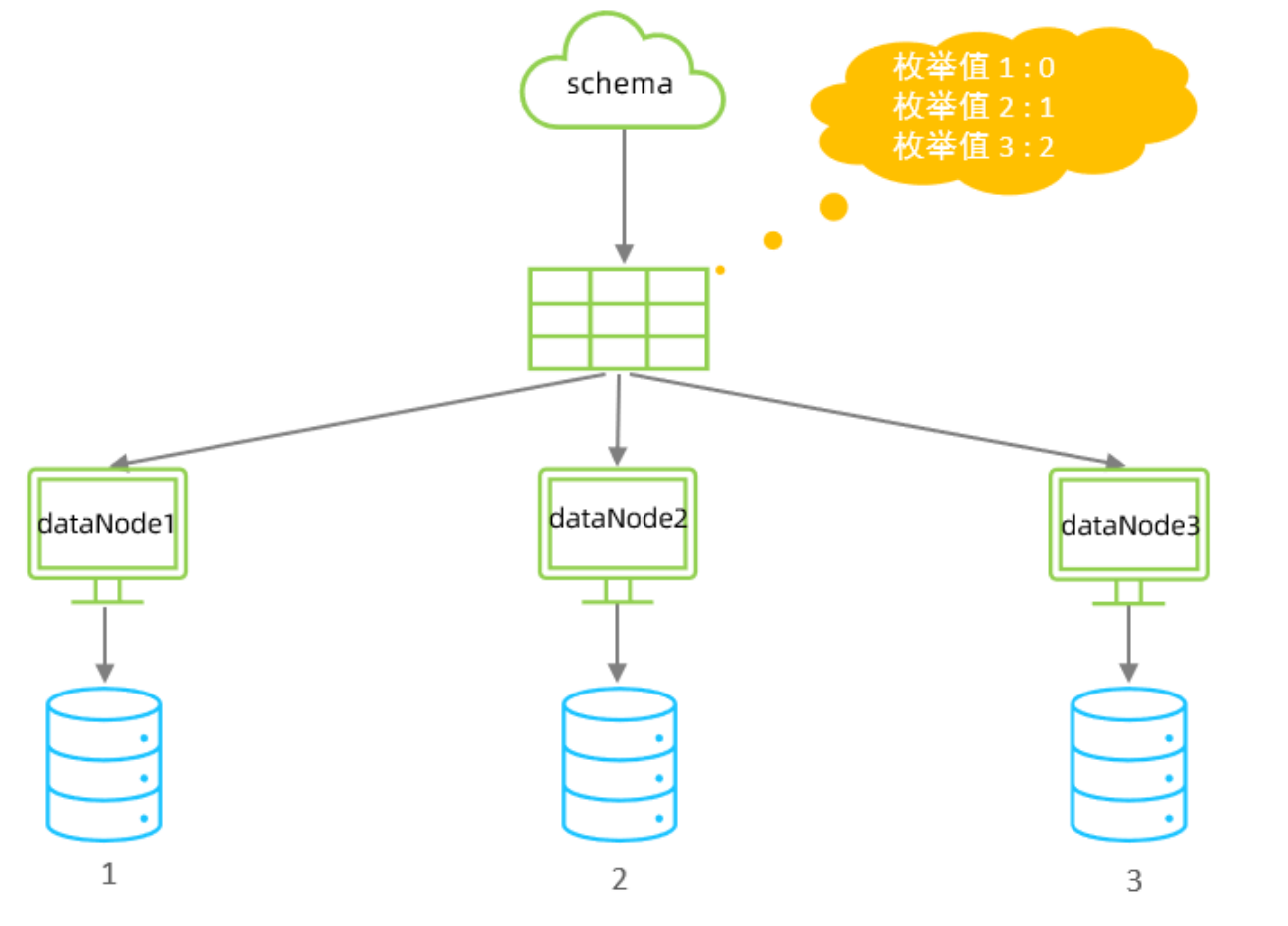
配置
schema.xml 邏輯表配置
<!-- 枚舉 -->
<table name="tb_user" dataNode="dn4,dn5,dn6" rule="sharding-by-intfile-enumstatus"/>schema.xml 數據節點配置
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml分片規則配置
<tableRule name="sharding-by-intfile"><rule><columns>sharding_id</columns><algorithm>hash-int</algorithm></rule>
</tableRule><!-- 自己增加 tableRule -->
<tableRule name="sharding-by-intfile-enumstatus"><rule><columns>status</columns><algorithm>hash-int</algorithm></rule>
</tableRule><function name="hash-int" class="io.mycat.route.function.PartitionByFileMap"><property name="defaultNode">2</property><property name="mapFile">partition-hash-int.txt</property>
</function>partition-hash-int.txt 內容如下 :
1=0
2=1
3=2分片規則屬性含義:
| 屬性 | 描述 |
| columns | 標識將要分片的表字段 |
| algorithm | 指定分片函數與function的對應關系 |
| class | 指定該分片算法對應的類 |
| mapFile | 對應的外部配置文件 |
| type | 默認值為0 ; 0 表示Integer , 1 表示String |
| defaultNode | 默認節點 ; 小于0 標識不設置默認節點 , 大于等于0代表設置默認節點 ; 默認節點的所用:枚舉分片時,如果碰到不識別的枚舉值, 就讓它路由到默認節 點 ; 如果沒有默認值,碰到不識別的則報錯 。 |
測試
配置完畢后,重新啟動MyCat,然后在mycat的命令行中,執行如下SQL創建表、并插入數據,查看數
據分布情況。
CREATE TABLE tb_user (
id bigint(20) NOT NULL COMMENT 'ID',
username varchar(200) DEFAULT NULL COMMENT '姓名',
status int(2) DEFAULT '1' COMMENT '1: 未啟用, 2: 已啟用, 3: 已關閉',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_user (id,username ,status) values(1,'Tom',1);
insert into tb_user (id,username ,status) values(2,'Cat',2);
insert into tb_user (id,username ,status) values(3,'Rose',3);
insert into tb_user (id,username ,status) values(4,'Coco',2);
insert into tb_user (id,username ,status) values(5,'Lily',1);
insert into tb_user (id,username ,status) values(6,'Tom',1);
insert into tb_user (id,username ,status) values(7,'Cat',2);
insert into tb_user (id,username ,status) values(8,'Rose',3);
insert into tb_user (id,username ,status) values(9,'Coco',2);
insert into tb_user (id,username ,status) values(10,'Lily',1);應用指定算法
介紹
運行階段由應用自主決定路由到那個分片 , 直接根據字符子串(必須是數字)計算分片號。
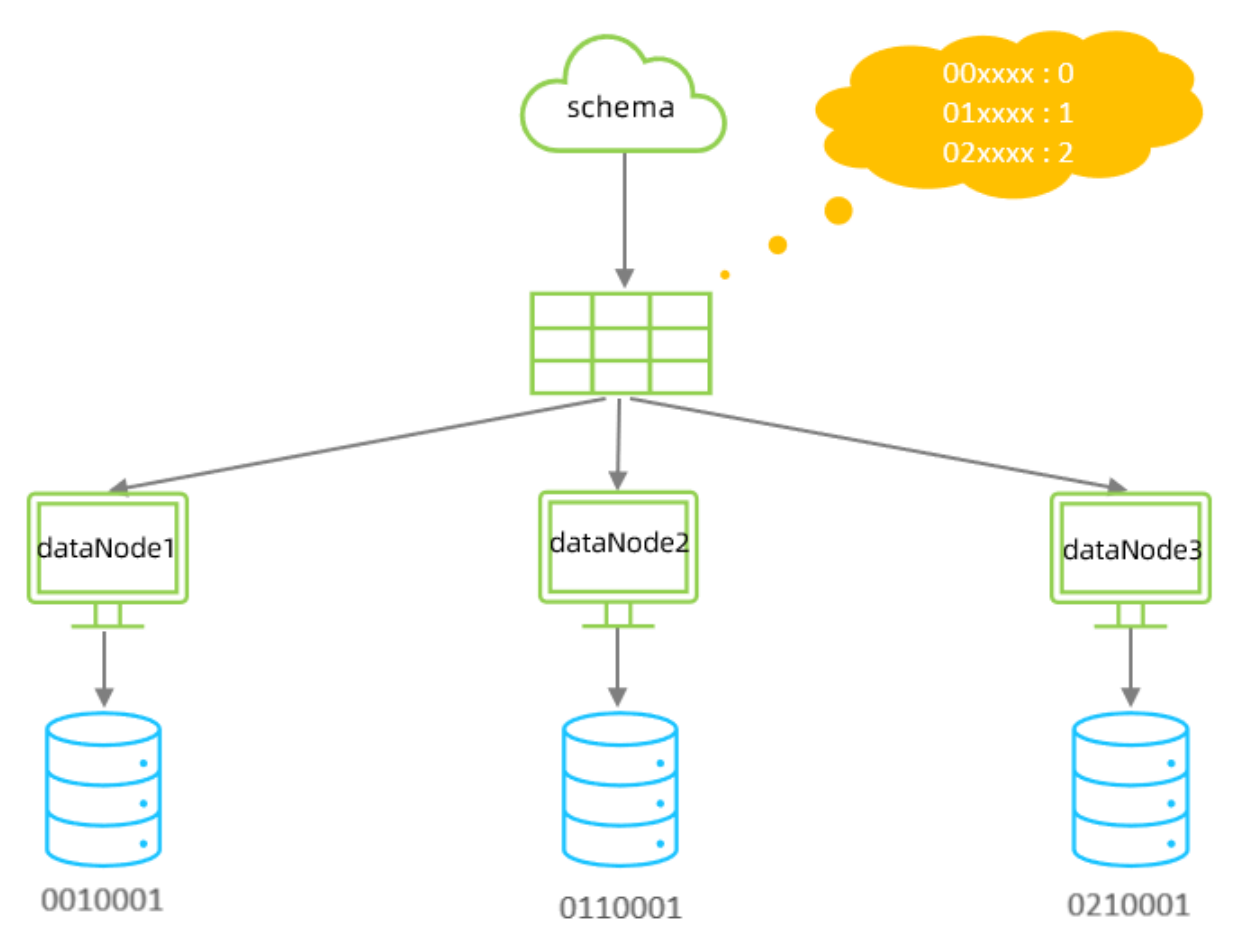
配置
schema.xml配置
<!-- 應用指定算法 -->
<table name="tb_app" dataNode="dn4,dn5,dn6" rule="sharding-by-substring" />schema.xml數據節點配置
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml分片規則配置
<tableRule name="sharding-by-substring"><rule><columns>id</columns><algorithm>sharding-by-substring</algorithm></rule>
</tableRule><function name="sharding-by-substring"class="io.mycat.route.function.PartitionDirectBySubString"><property name="startIndex">0</property> <!-- zero-based --><property name="size">2</property><property name="partitionCount">3</property><property name="defaultPartition">0</property>
</function>分片規則屬性含義:
| 屬性 | 描述 |
| columns | 標識將要分片的表字段 |
| algorithm | 指定分片函數與function的對應關系 |
| class | 指定該分片算法對應的類 |
| startIndex | 字符子串起始索引 |
| size | 字符長度 |
| partitionCount | 分區(分片)數量 |
| defaultPartition | 默認分片(在分片數量定義時, 字符標示的分片編號不在分片數量內時, 使用默認分片) |
示例說明
id=05-100000002 , 在此配置中代表根據id中從 startIndex=0,開始,截取siz=2位數字即
05,05就是獲取的分區,如果沒找到對應的分片則默認分配到defaultPartition 。
測試
配置完畢后,重新啟動MyCat,然后在mycat的命令行中,執行如下SQL創建表、并插入數據,查看數
據分布情況。
CREATE TABLE tb_app (id varchar(10) NOT NULL COMMENT 'ID',name varchar(200) DEFAULT NULL COMMENT '名稱',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_app (id,name) values('0000001','Testx00001');
insert into tb_app (id,name) values('0100001','Test100001');
insert into tb_app (id,name) values('0100002','Test200001');
insert into tb_app (id,name) values('0200001','Test300001');
insert into tb_app (id,name) values('0200002','TesT400001');固定分片hash算法
介紹
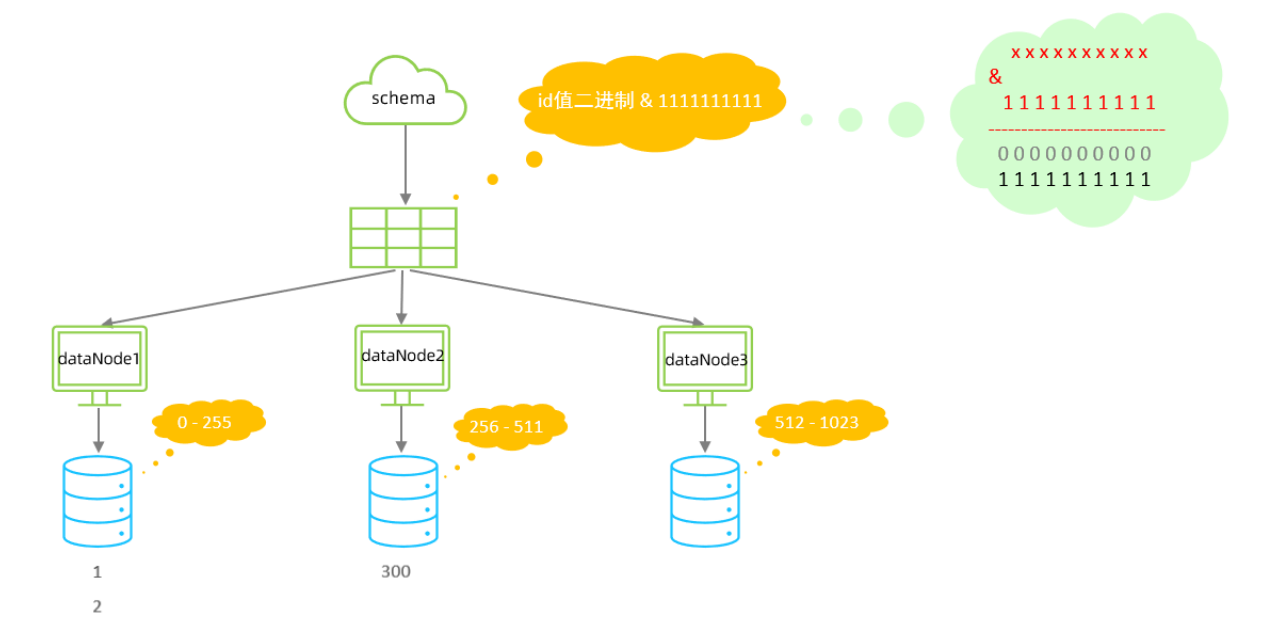
該算法類似于十進制的求模運算,但是為二進制的操作,例如,取 id 的二進制低 10 位 與
1111111111 進行位 & 運算,位與運算最小值為 0000000000,最大值為1111111111,轉換為十
進制,也就是位于0-1023之間。
特點
1、如果是求模,連續的值,分別分配到各個不同的分片;但是此算法會將連續的值可能分配到相同的
分片,降低事務處理的難度。
2、可以均勻分配,也可以非均勻分配。
3、分片字段必須為數字類型。
配置
schema.xml配置
<!-- 固定分片hash算法 -->
<table name="tb_longhash" dataNode="dn4,dn5,dn6" rule="sharding-by-long-hash" />schema.xml數據節點配置
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml配置
<tableRule name="sharding-by-long-hash"><rule><columns>id</columns><algorithm>sharding-by-long-hash</algorithm></rule>
</tableRule><!-- 分片總長度為1024,count與length數組長度必須一致; -->
<function name="sharding-by-long-hash"
class="io.mycat.route.function.PartitionByLong"><property name="partitionCount">2,1</property><property name="partitionLength">256,512</property>
</function>分片規則屬性含義:
| 屬性 | 描述 |
| columns | 標識將要分片的表字段名 |
| algorithm | 指定分片函數與function的對應關系 |
| class | 指定該分片算法對應的類 |
| partitionCount | 分片個數列表 |
| partitionLength | 分片范圍列表 |
約束
1). 分片長度 : 默認最大2^10 , 為 1024 ;
2). count, length的數組長度必須是一致的 ;
以上分為三個分區:0-255,256-511,512-1023
示例說明

測試
配置完畢后,重新啟動MyCat,然后在mycat的命令行中,執行如下SQL創建表、并插入數據,查看數
據分布情況。
CREATE TABLE tb_longhash (id int(11) NOT NULL COMMENT 'ID',name varchar(200) DEFAULT NULL COMMENT '名稱',firstChar char(1) COMMENT '首字母',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_longhash (id,name,firstChar) values(1,'七匹狼','Q');
insert into tb_longhash (id,name,firstChar) values(2,'八匹狼','B');
insert into tb_longhash (id,name,firstChar) values(3,'九匹狼','J');
insert into tb_longhash (id,name,firstChar) values(4,'十匹狼','S');
insert into tb_longhash (id,name,firstChar) values(5,'六匹狼','L');
insert into tb_longhash (id,name,firstChar) values(6,'五匹狼','W');
insert into tb_longhash (id,name,firstChar) values(7,'四匹狼','S');
insert into tb_longhash (id,name,firstChar) values(8,'三匹狼','S');
insert into tb_longhash (id,name,firstChar) values(9,'兩匹狼','L');字符串hash解析算法
介紹
截取字符串中的指定位置的子字符串, 進行hash算法, 算出分片。
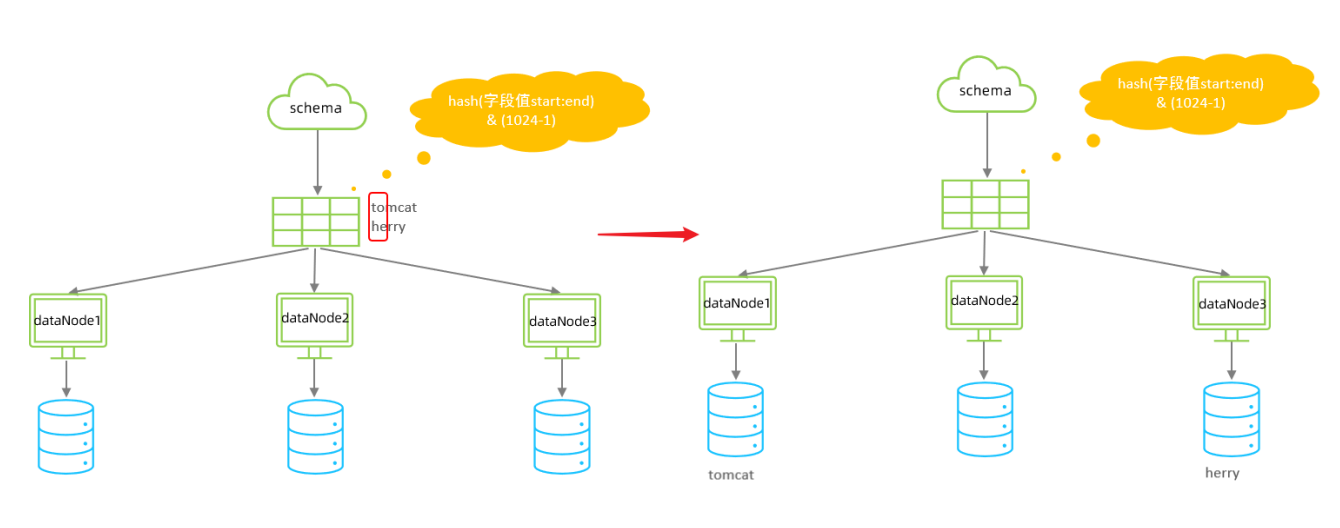
配置
schema.xml邏輯表配置
<!-- 字符串hash解析算法 -->
<table name="tb_strhash" dataNode="dn4,dn5" rule="sharding-by-stringhash" />schema.xml數據節點配置
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />rule.xml配置
<tableRule name="sharding-by-stringhash"><rule><columns>name</columns><algorithm>sharding-by-stringhash</algorithm></rule>
</tableRule><function name="sharding-by-stringhash"
class="io.mycat.route.function.PartitionByString"><property name="partitionLength">512</property> <!-- zero-based --><property name="partitionCount">2</property><property name="hashSlice">0:2</property>
</function>分片屬性含義:
| 屬性 | 描述 |
| columns | 標識將要分片的表字段 |
| algorithm | 指定分片函數與function的對應關系 |
| class | 指定該分片算法對應的類 |
| partitionLength | hash求模基數 ; length*count=1024 (出于性能考慮) |
| partitionCount | 分區數 |
| hashSlice | hash運算位 , 根據子字符串的hash運算 ; 0 代表 str.length() , -1 代表 str.length()-1 , 大于0只代表數字自身 ; 可以理解 為substring(start,end),start為0則只表示0 |
示例說明

測試
配置完畢后,重新啟動MyCat,然后在mycat的命令行中,執行如下SQL創建表、并插入數據,查看數
據分布情況。
create table tb_strhash(name varchar(20) primary key,content varchar(100)
)engine=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO tb_strhash (name,content) VALUES('T1001', UUID());
INSERT INTO tb_strhash (name,content) VALUES('ROSE', UUID());
INSERT INTO tb_strhash (name,content) VALUES('JERRY', UUID());
INSERT INTO tb_strhash (name,content) VALUES('CRISTINA', UUID());
INSERT INTO tb_strhash (name,content) VALUES('TOMCAT', UUID());按天分片算法
介紹
按照日期及對應的時間周期來分片。
配置
schema.xml配置
<!-- 按天分片 -->
<table name="tb_datepart" dataNode="dn4,dn5,dn6" rule="sharding-by-date" />schema.xml數據節點配置
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml配置
<tableRule name="sharding-by-date"><rule><columns>create_time</columns><algorithm>sharding-by-date</algorithm></rule>
</tableRule><function name="sharding-by-date"
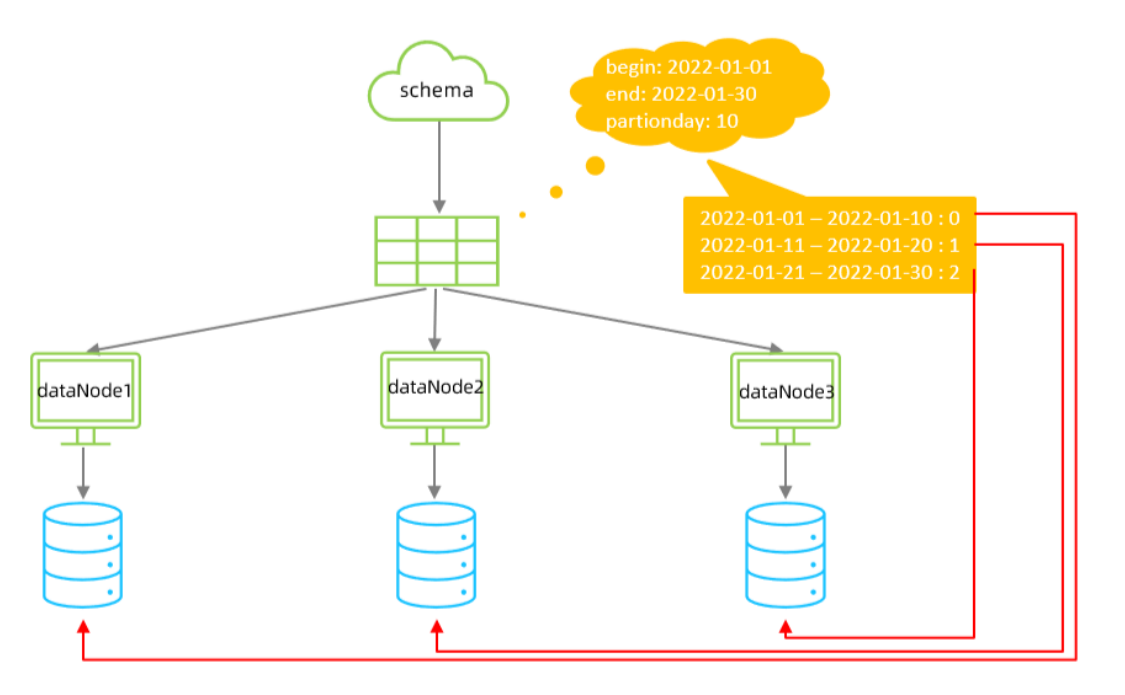
class="io.mycat.route.function.PartitionByDate"><property name="dateFormat">yyyy-MM-dd</property><property name="sBeginDate">2022-01-01</property><property name="sEndDate">2022-01-30</property><property name="sPartionDay">10</property>
</function>
<!--
從開始時間開始,每10天為一個分片,到達結束時間之后,會重復開始分片插入
配置表的 dataNode 的分片,必須和分片規則數量一致,例如 2022-01-01 到 2022-12-31 ,每
10天一個分片,一共需要37個分片。
-->分片屬性含義
| 屬性 | 描述 |
| columns | 標識將要分片的表字段 |
| algorithm | 指定分片函數與function的對應關系 |
| class | 指定該分片算法對應的類 |
| dateFormat | 日期格式 |
| sBeginDate | 開始日期 |
| sEndDate | 結束日期,如果配置了結束日期,則代碼數據到達了這個日期的分片后,會重 復從開始分片插入。 |
| sPartionDay | 分區天數,默認值 10 ,從開始日期算起,每個10天一個分區 |
測試
配置完畢后,重新啟動MyCat,然后在mycat的命令行中,執行如下SQL創建表、并插入數據,查看數
據分布情況。
create table tb_datepart(id bigint not null comment 'ID' primary key,name varchar(100) null comment '姓名',create_time date null
);
insert into tb_datepart(id,name ,create_time) values(1,'Tom','2022-01-01');
insert into tb_datepart(id,name ,create_time) values(2,'Cat','2022-01-10');
insert into tb_datepart(id,name ,create_time) values(3,'Rose','2022-01-11');
insert into tb_datepart(id,name ,create_time) values(4,'Coco','2022-01-20');
insert into tb_datepart(id,name ,create_time) values(5,'Rose2','2022-01-21');
insert into tb_datepart(id,name ,create_time) values(6,'Coco2','2022-01-30');
insert into tb_datepart(id,name ,create_time) values(7,'Coco3','2022-01-31');自然月分片
介紹
使用場景為按照月份來分片, 每個自然月為一個分片。
配置
schema.xml邏輯表配置
<!-- 按自然月分片 -->
<table name="tb_monthpart" dataNode="dn4,dn5,dn6" rule="sharding-by-month" />schema.xml數據節點配置
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml配置
<tableRule name="sharding-by-month"><rule><columns>create_time</columns><algorithm>partbymonth</algorithm></rule>
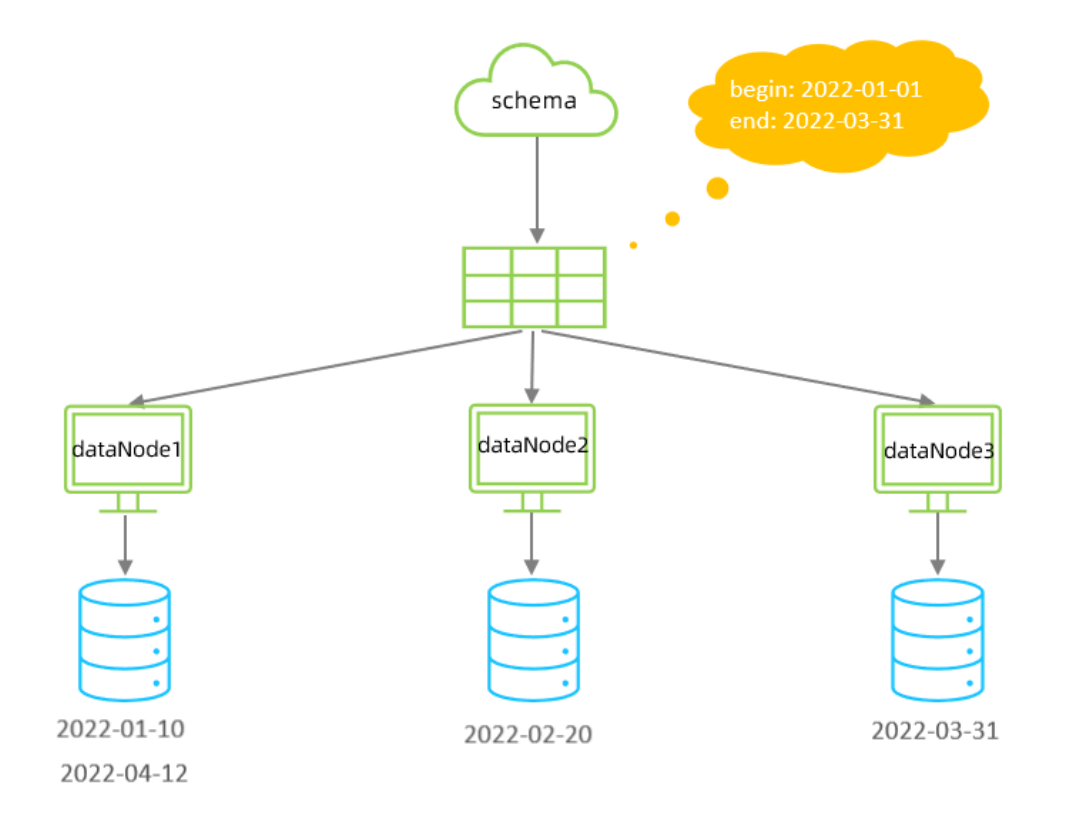
</tableRule><function name="partbymonth" class="io.mycat.route.function.PartitionByMonth"><property name="dateFormat">yyyy-MM-dd</property><property name="sBeginDate">2022-01-01</property><property name="sEndDate">2022-03-31</property>
</function>
<!--
從開始時間開始,一個月為一個分片,到達結束時間之后,會重復開始分片插入
配置表的 dataNode 的分片,必須和分片規則數量一致,例如 2022-01-01 到 2022-12-31 ,一
共需要12個分片。
-->分片規則屬性含義:
| 屬性 | 描述 |
| columns | 標識將要分片的表字段 |
| columns | 指定分片函數與function的對應關系 |
| class | 指定該分片算法對應的類 |
| dateFormat | 日期格式 |
| sBeginDate | 開始日期 |
| sEndDate | 結束日期,如果配置了結束日期,則代碼數據到達了這個日期的分片后,會重復從開始分片插入。 |
測試
配置完畢后,重新啟動MyCat,然后在mycat的命令行中,執行如下SQL創建表、并插入數據,查看數
據分布情況。
create table tb_monthpart(id bigint not null comment 'ID' primary key,name varchar(100) null comment '姓名',create_time date null
);
insert into tb_monthpart(id,name ,create_time) values(1,'Tom','2022-01-01');
insert into tb_monthpart(id,name ,create_time) values(2,'Cat','2022-01-10');
insert into tb_monthpart(id,name ,create_time) values(3,'Rose','2022-01-31');
insert into tb_monthpart(id,name ,create_time) values(4,'Coco','2022-02-20');
insert into tb_monthpart(id,name ,create_time) values(5,'Rose2','2022-02-25');
insert into tb_monthpart(id,name ,create_time) values(6,'Coco2','2022-03-10');
insert into tb_monthpart(id,name ,create_time) values(7,'Coco3','2022-03-31');
insert into tb_monthpart(id,name ,create_time) values(8,'Coco4','2022-04-10');
insert into tb_monthpart(id,name ,create_time) values(9,'Coco5','2022-04-30');MyCat管理及監控
Mycat原理
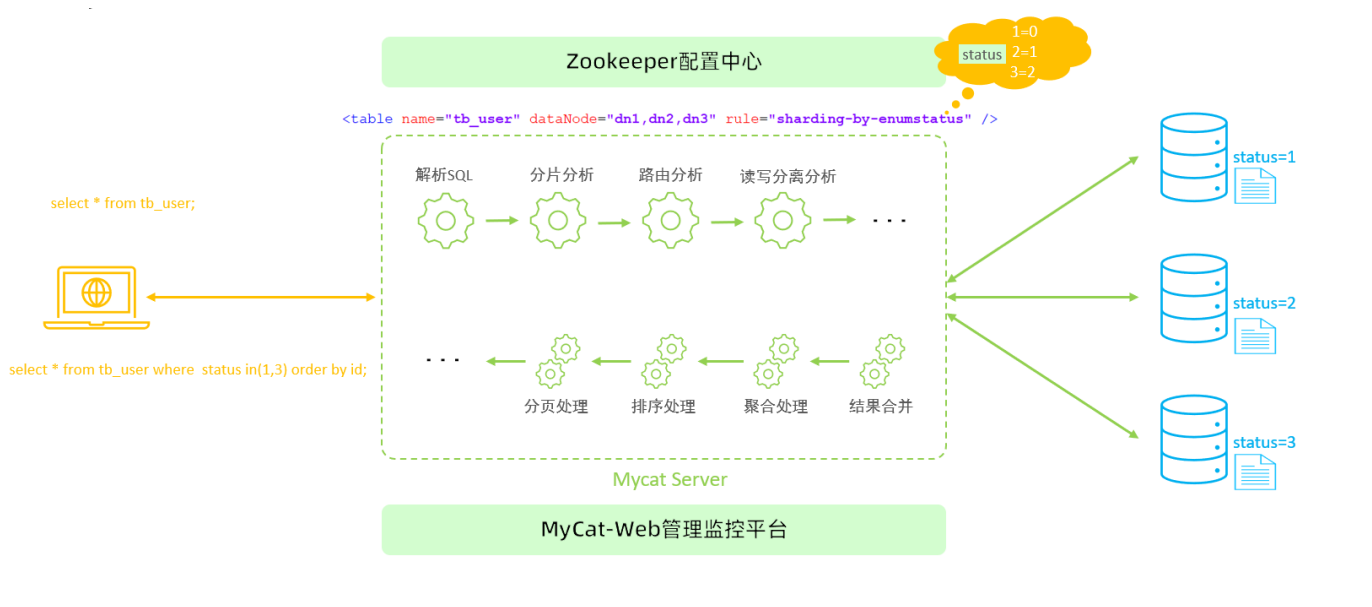
在MyCat中,當執行一條SQL語句時,MyCat需要進行SQL解析、分片分析、路由分析、讀寫分離分析
等操作,最終經過一系列的分析決定將當前的SQL語句到底路由到那幾個(或哪一個)節點數據庫,數據
庫將數據執行完畢后,如果有返回的結果,則將結果返回給MyCat,最終還需要在MyCat中進行結果合
并、聚合處理、排序處理、分頁處理等操作,最終再將結果返回給客戶端。
而在MyCat的使用過程中,MyCat官方也提供了一個管理監控平臺MyCat-Web(MyCat-eye)。
Mycat-web 是 Mycat 可視化運維的管理和監控平臺,彌補了 Mycat 在監控上的空白。幫 Mycat
分擔統計任務和配置管理任務。Mycat-web 引入了 ZooKeeper 作為配置中心,可以管理多個節
點。Mycat-web 主要管理和監控 Mycat 的流量、連接、活動線程和內存等,具備 IP 白名單、郵
件告警等模塊,還可以統計 SQL 并分析慢 SQL 和高頻 SQL 等。為優化 SQL 提供依據。
Mycat管理
Mycat默認開通2個端口,可以在server.xml中進行修改。
8066 數據訪問端口,即進行 DML 和 DDL 操作。
9066 數據庫管理端口,即 mycat 服務管理控制功能,用于管理mycat的整個集群狀態。
連接MyCat的管理控制臺:
mysql -h 192.168.200.210 -p 9066 -uroot -p123456| 命令 | 含義 |
| show @@help | 查看Mycat管理工具幫助文檔 |
| show @@version | 查看Mycat的版本 |
| reload @@config | 重新加載Mycat的配置文件 |
| show @@datasource | 查看Mycat的數據源信息 |
| show @@datanode | 查看MyCat現有的分片節點信息 |
| show @@threadpool | 查看Mycat的線程池信息 |
| show @@sql | 查看執行的SQL |
| show @@sql.sum | 查看執行的SQL統計 |
Mycat-exe
介紹
Mycat-web(Mycat-eye)是對mycat-server提供監控服務,功能不局限于對mycat-server使
用。他通過JDBC連接對Mycat、Mysql監控,監控遠程服務器(目前僅限于linux系統)的cpu、內
存、網絡、磁盤。
Mycat-eye運行過程中需要依賴zookeeper,因此需要先安裝zookeeper。
安裝
1). zookeeper安裝
2). Mycat-web安裝
這些參考
https://www.yuque.com/daimaxiaohuihui/oeghvh/oxogbcorrmzhrkgs
訪問
http://192.168.200.210:8082/mycat

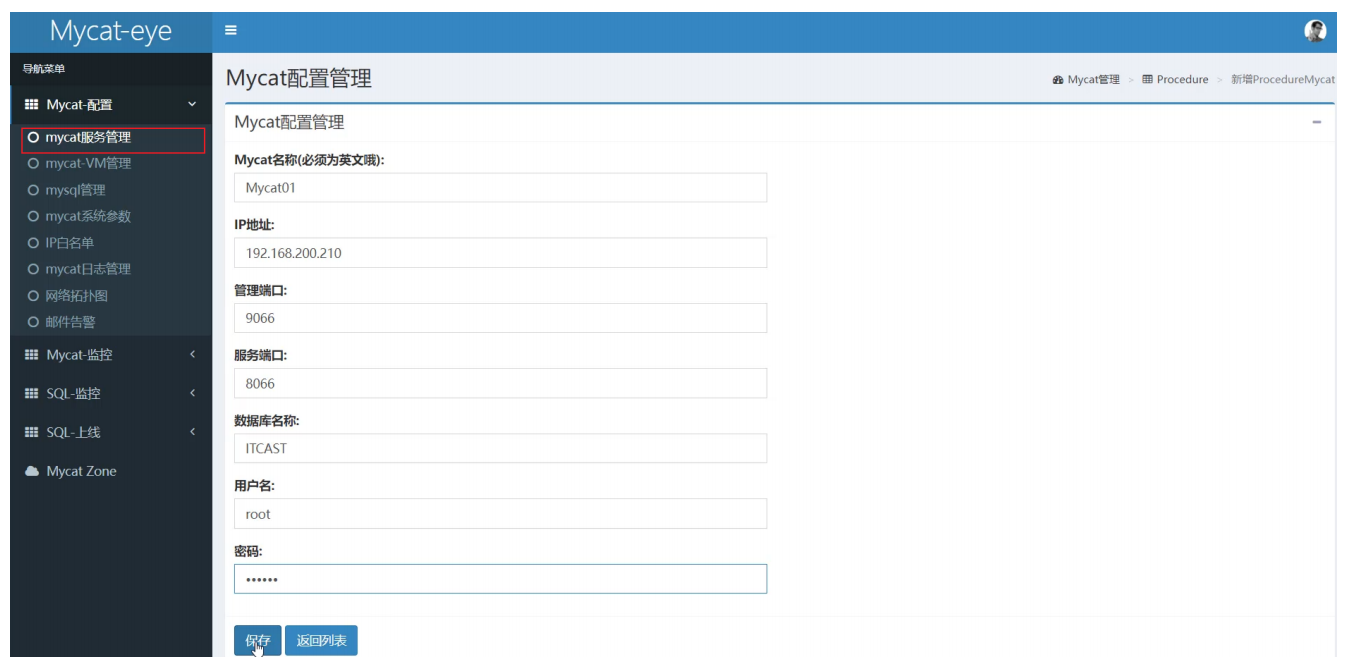
配置
開啟Mycat實時統計功能((server.xml)
<property name="useSqlStat">1</property> <!-- 1為開啟實時統計、0為關閉 -->在Mycat監控界面配置服務地址
測試
配置好了之后,我們可以通過MyCat執行一系列的增刪改查的測試,然后過一段時間之后,打開
mycat-eye的管理界面,查看mycat-eye監控到的數據信息。
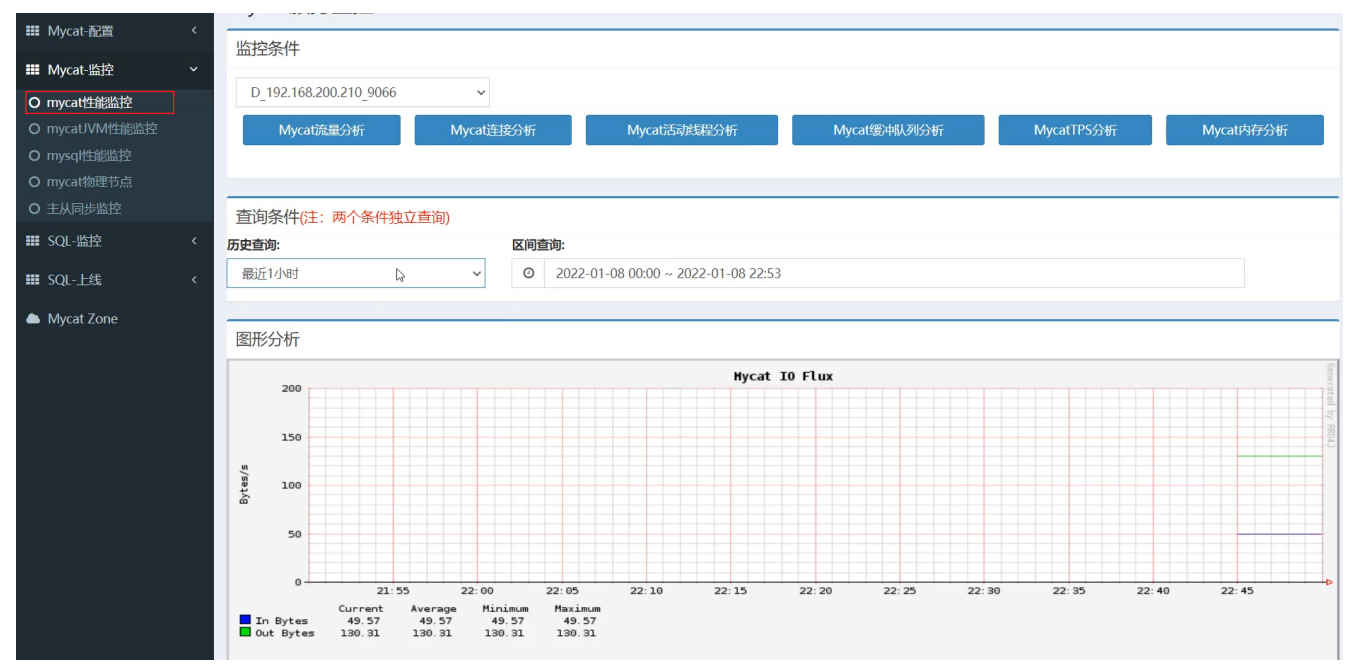
性能監控
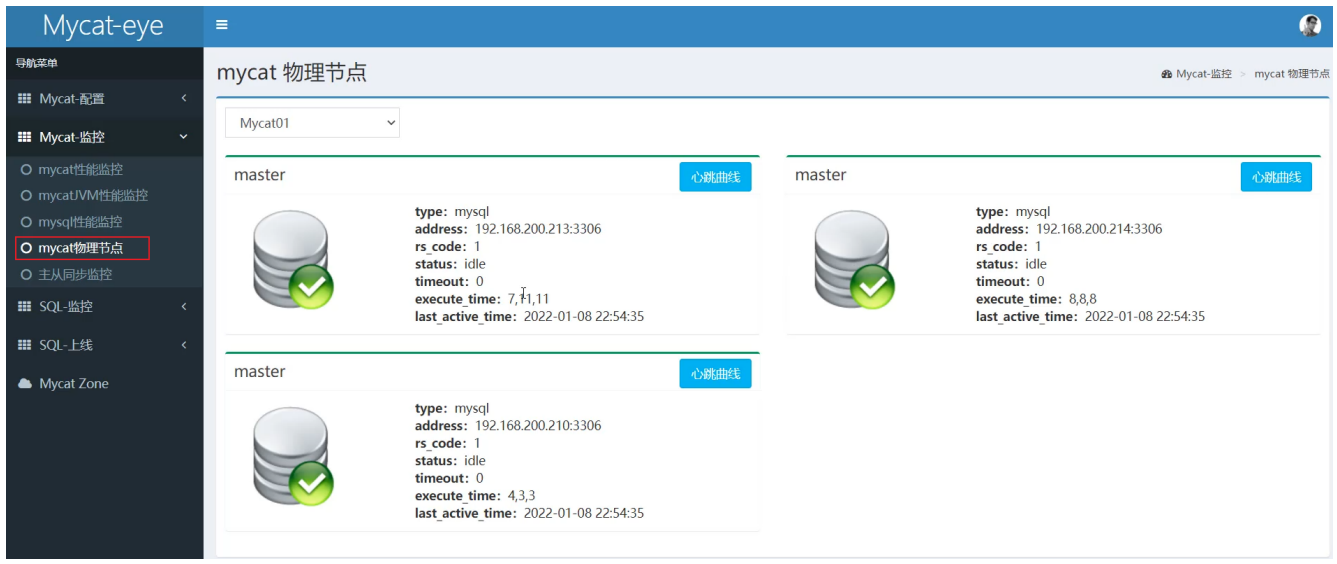
物理節點
SQL統計
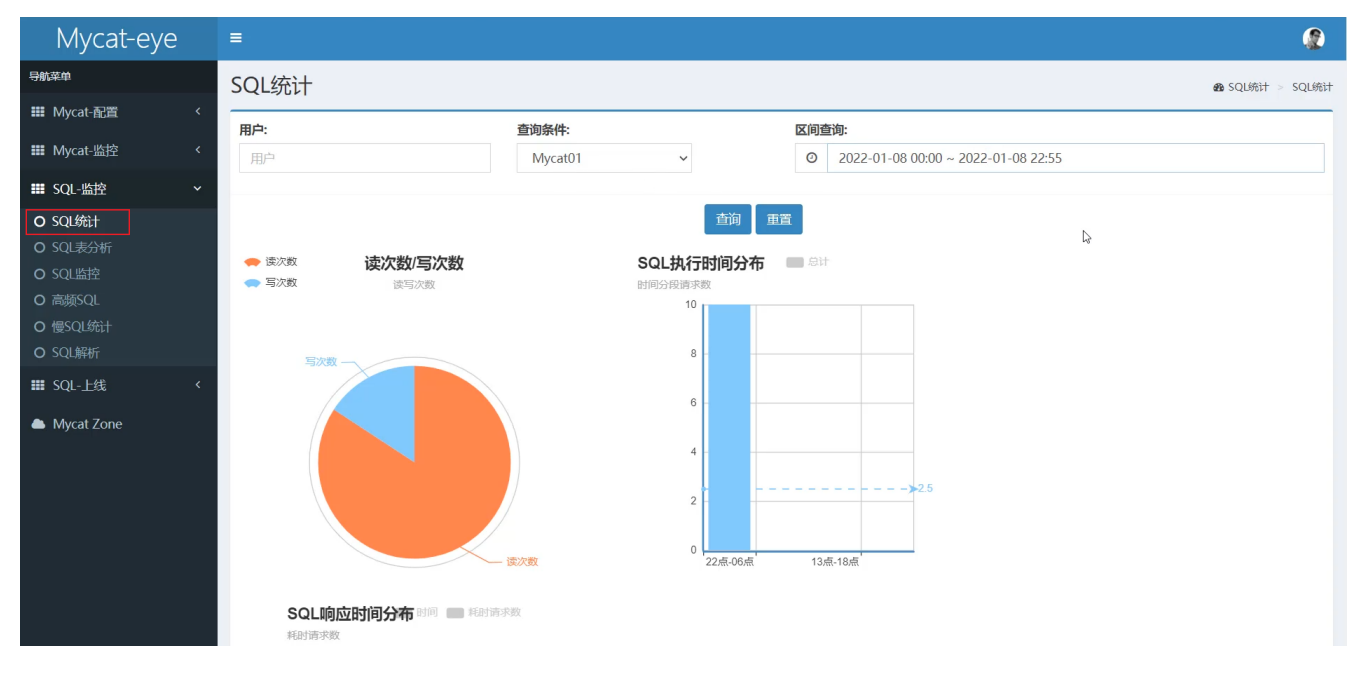
SQL表分析
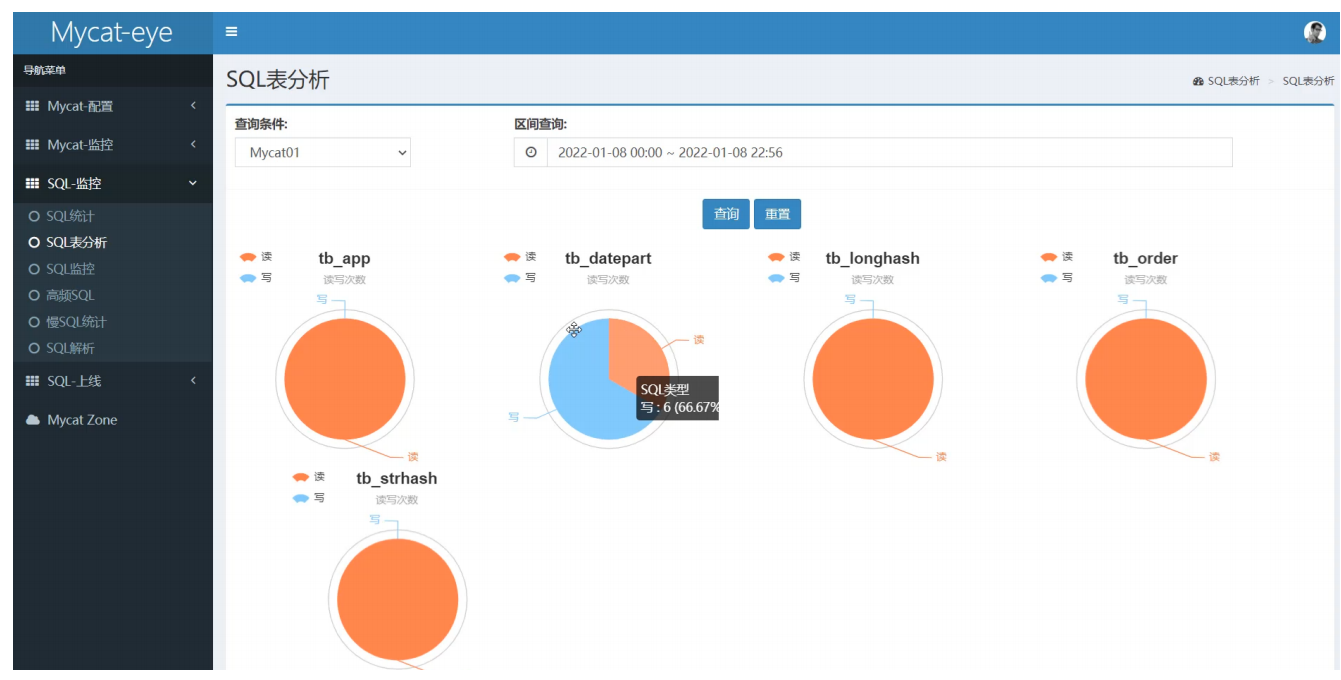
SQL監控
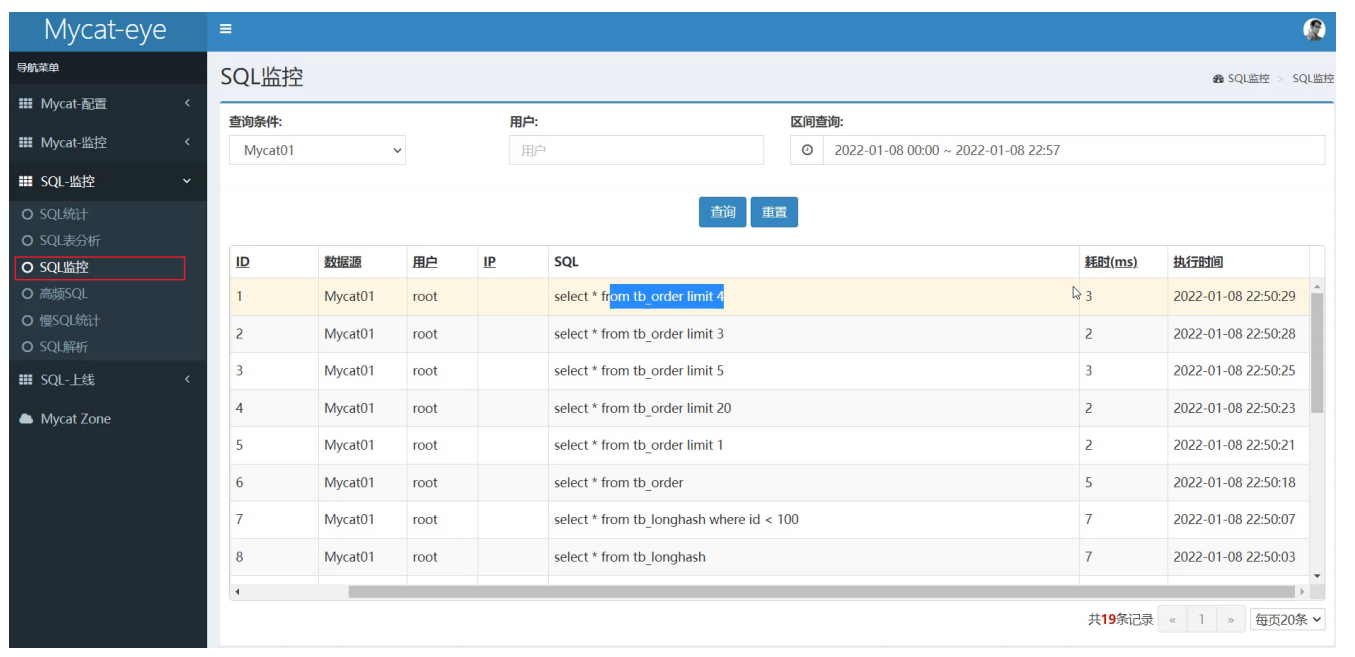
高頻SQL
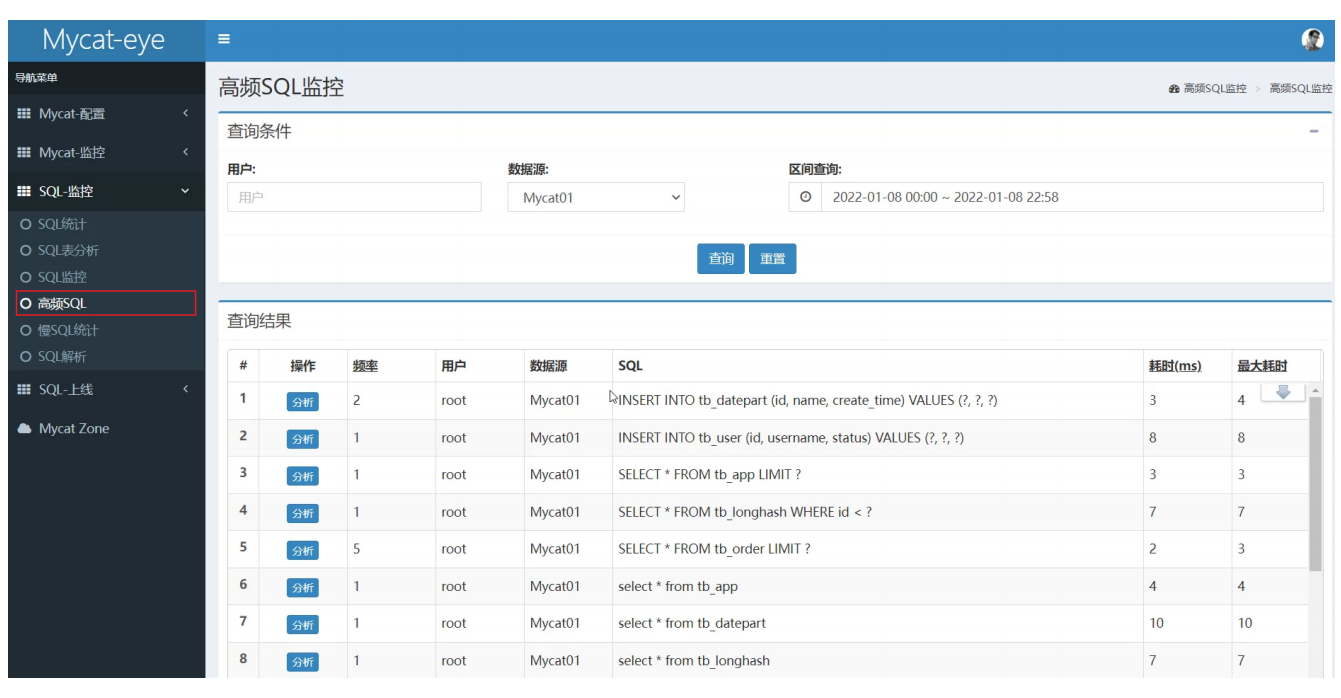




)

)
)









微服務)

-Spring事務簡介(P40)-Spring事務角色(P41)-Spring事務屬性(P42))