文章目錄
- 邏輯回歸 (Logistic Regression)
- 問題的引出
- Sigmoid function
- 邏輯回歸的解釋
- 決策邊界 (Decision boundary)
- 邏輯回歸的代價函數
- 機器學習中代價函數的設計
- 1. 代價函數的來源
- (1)從概率模型推導而來(統計學習視角)
- (2)直接針對算法目標設計(優化視角)
- 2. 代價函數與算法的適配性
- 總結
- 邏輯回歸的簡化代價函數
- 梯度下降實現
邏輯回歸 (Logistic Regression)
問題的引出
假設使用線性回歸來解決分類問題
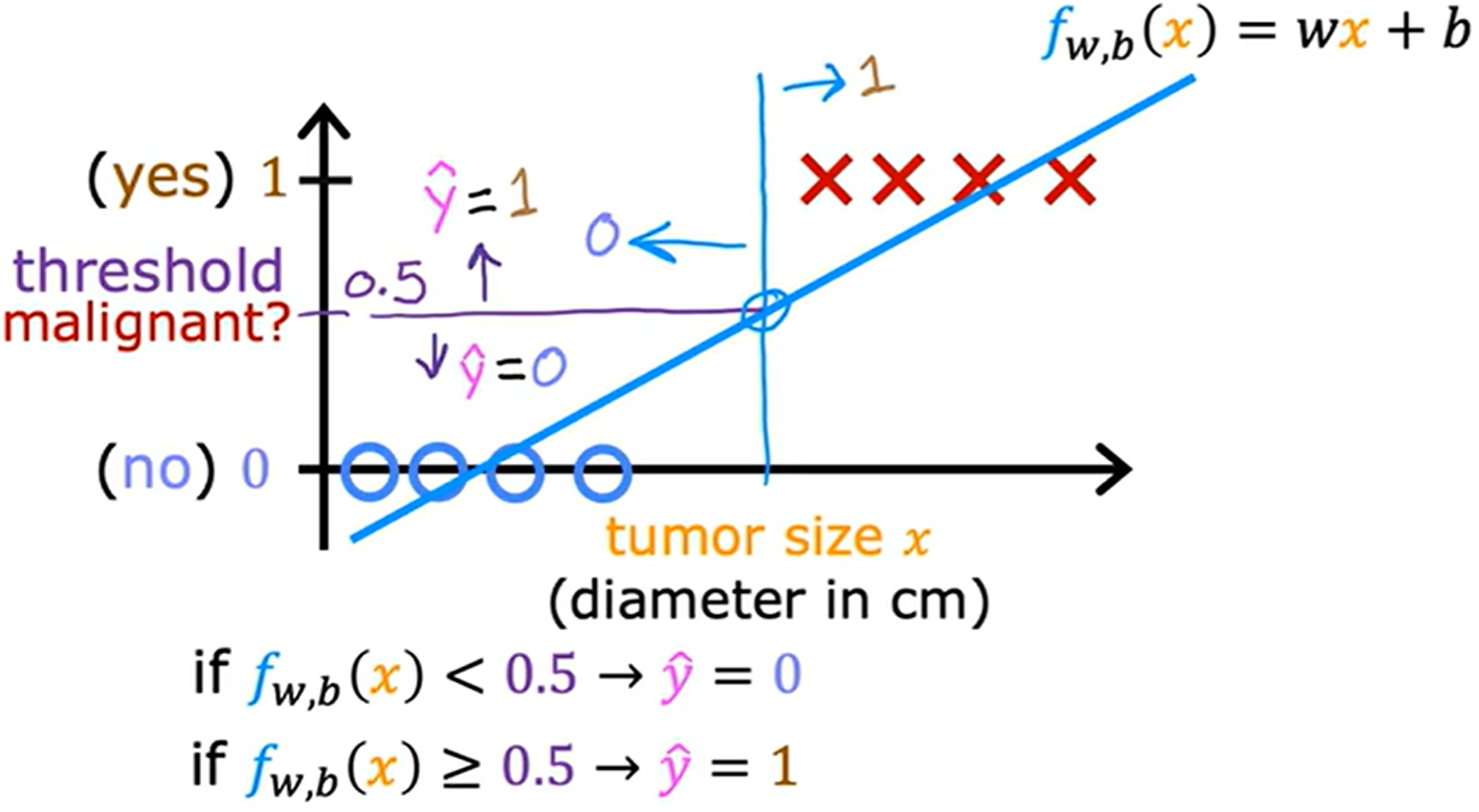
看起來還不錯,但若是沿橫軸正方向的遠處加入訓練樣本,就會導致線性回歸的擬合線偏移,如下圖所示。
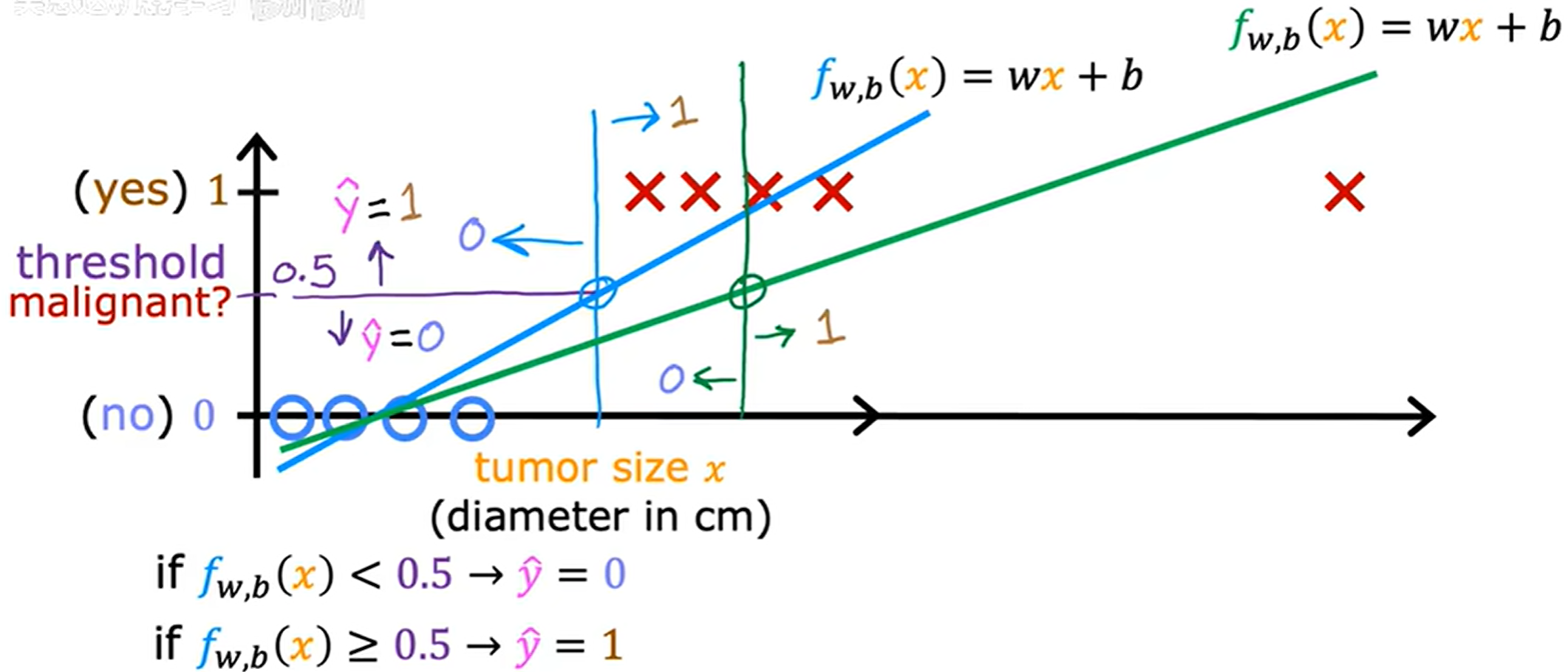
圖中決策邊界右移,這樣就會導致先前的部分訓練樣本預測值從 yes 變為 no。
整個模型變的很糟糕。
分類問題的目標是找到一個決策邊界,能夠正確區分不同類別的樣本。理想情況下,決策邊界應該由靠近邊界的樣本(支持向量)決定,而不是由遠處的樣本點決定。
在分類問題中,增加新的訓練樣本(尤其是遠離決策邊樣的樣本)不應顯著改變原有的分類結論。
由此引入邏輯回歸來解決分類問題。
Sigmoid function
為了更好擬合訓練樣本,整個線條呈現 s 型,由此引入 Sigmoid function(又常稱為 logistic函數)。
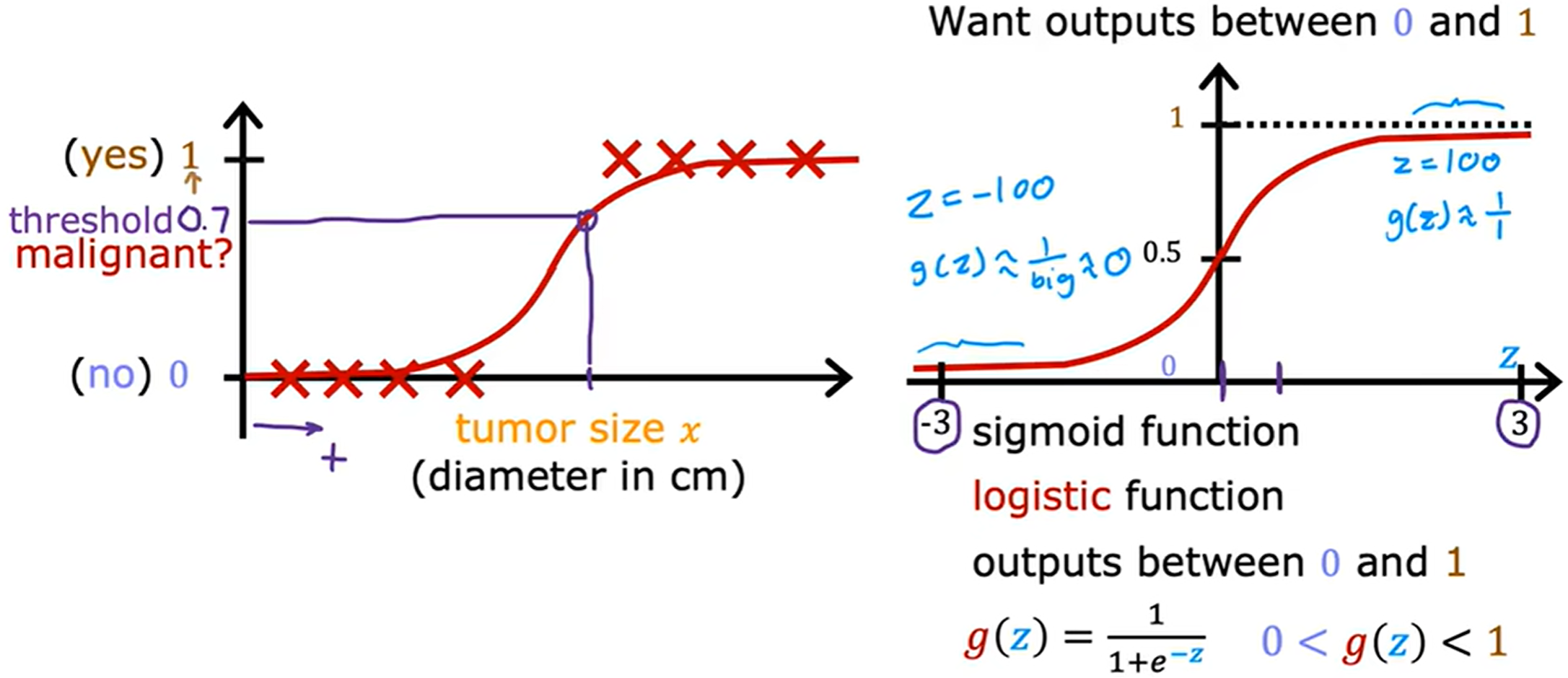
Sigmoid函數,又稱logistic函數,是最早使用的激活函數之一。但是由于其固有存在的一些缺點,如今很少將其作為激活函數,但是依然常用于二分類問題中的概率劃分。
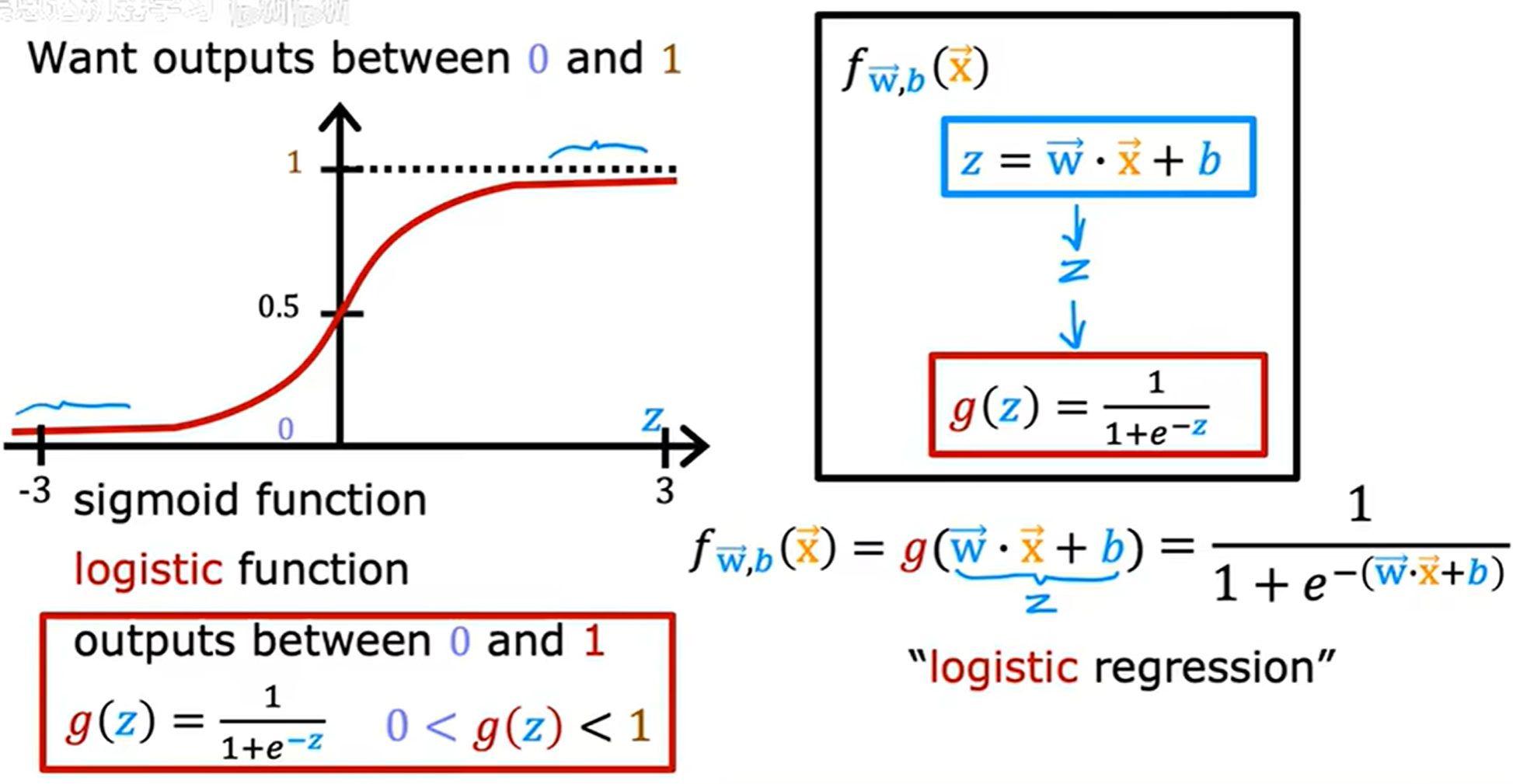
將線性回歸的結果,通過sigmoid函數轉換到0-1的范圍,實現分類。
邏輯回歸的解釋

f w ? , b ( x ? ) = P ( y = 1 ∣ x ? ; w ? , b ) f_{\vec{w}, b}(\vec{x}) = P(y = 1|\vec{x};\vec{w},b) fw,b?(x)=P(y=1∣x;w,b)
表示為給定輸入特征為 x x x, y y y 等于 1 1 1 的概率。
(given x, and with parameters w and b)
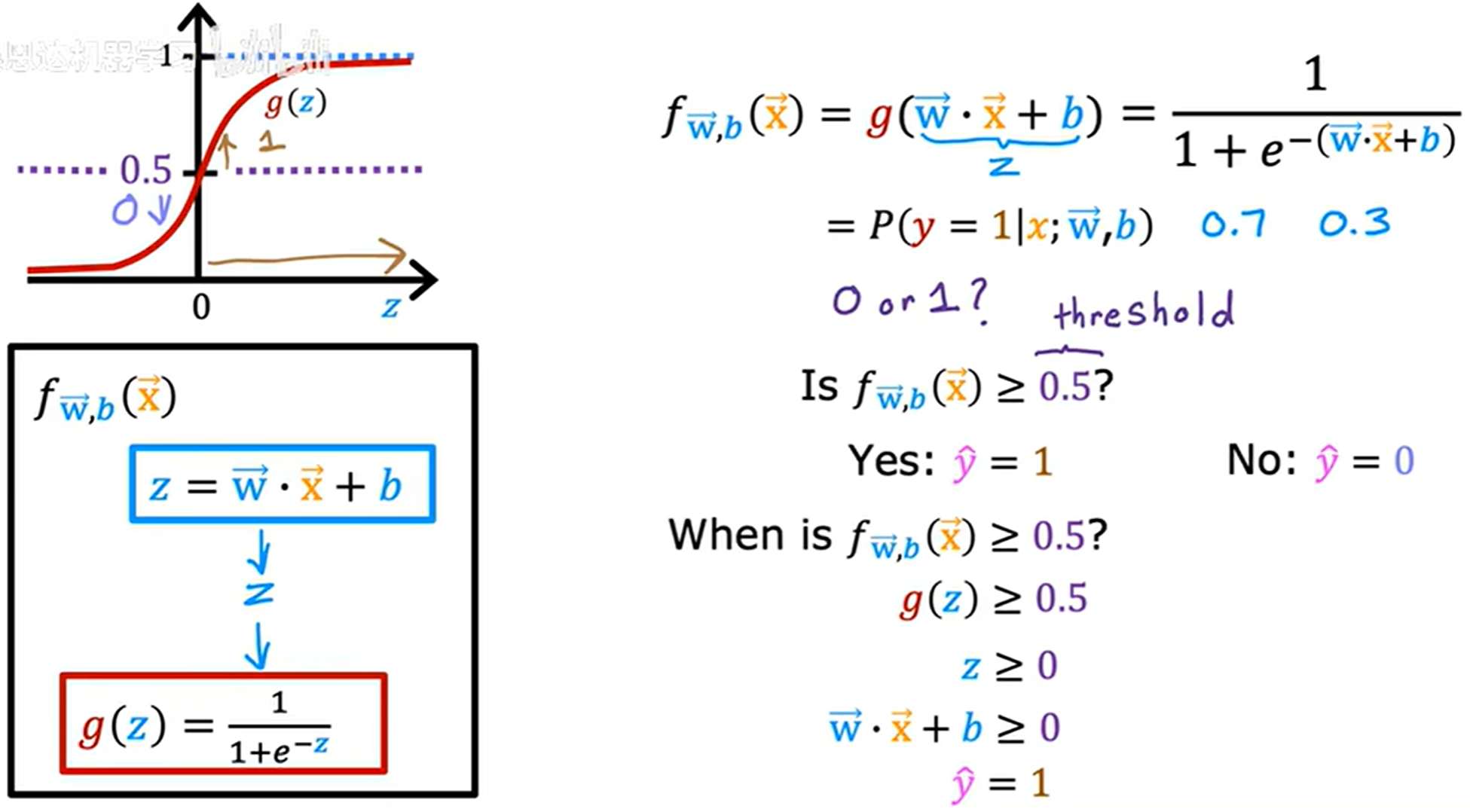
threshold 閾值
通過與閾值進行比較來決定 y ^ \hat{y} y^? 為 0 0 0 還是 1 1 1,通常將 0.5 0.5 0.5 作為閾值。
決策邊界 (Decision boundary)
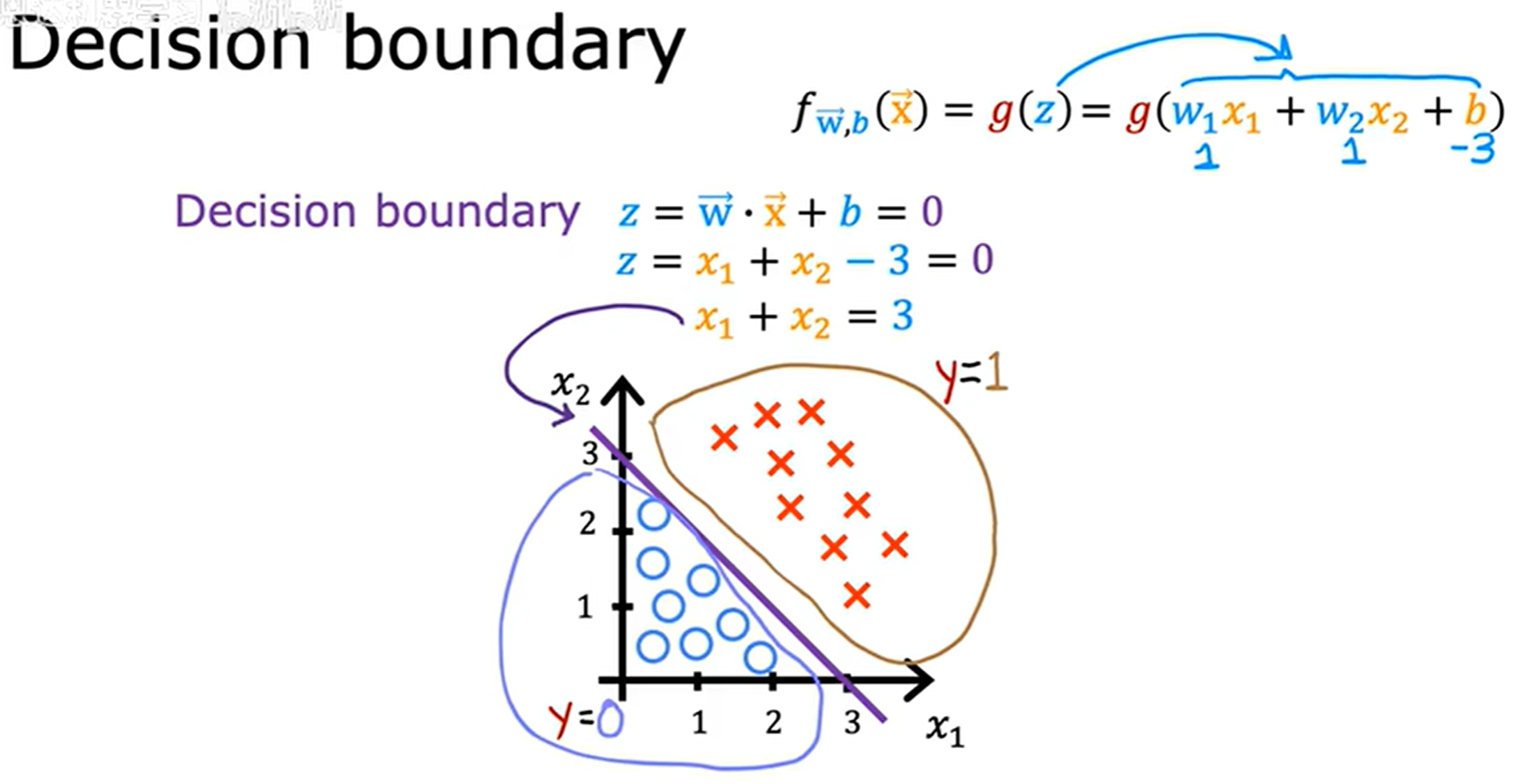
決策邊界便是讓 z = 0 z = 0 z=0 的地方,在這里設 w ? = [ 1 , 1 ] \vec{w} = [1, 1] w=[1,1],由此令 z = 0 z = 0 z=0,則 x 1 + x 2 = 3 x_1 + x _ 2 = 3 x1?+x2?=3,在這個例子中通過線性規劃可以做出對應的直線,如上圖所示。
決策邊界也不一定是直線,通過前面學過的多項式回歸,可以得到下圖關系。

先通過梯度下降算法對樣本擬合出曲線或者曲面或者更高緯度,然后對其進行分類。

通過多項式特征,可以獲得非常復雜的決策邊界,換句話說邏輯回歸可以擬合非常復雜的數據。
邏輯回歸的代價函數

線性回歸中,通過平方誤差作為代價函數來決定 w ? \vec{w} w 和 b b b 的取值,同理邏輯回歸也可以去尋找對應的代價函數來決定 w ? \vec{w} w 和 b b b 的取值。
convex function 下凸函數
concave function 上凸函數
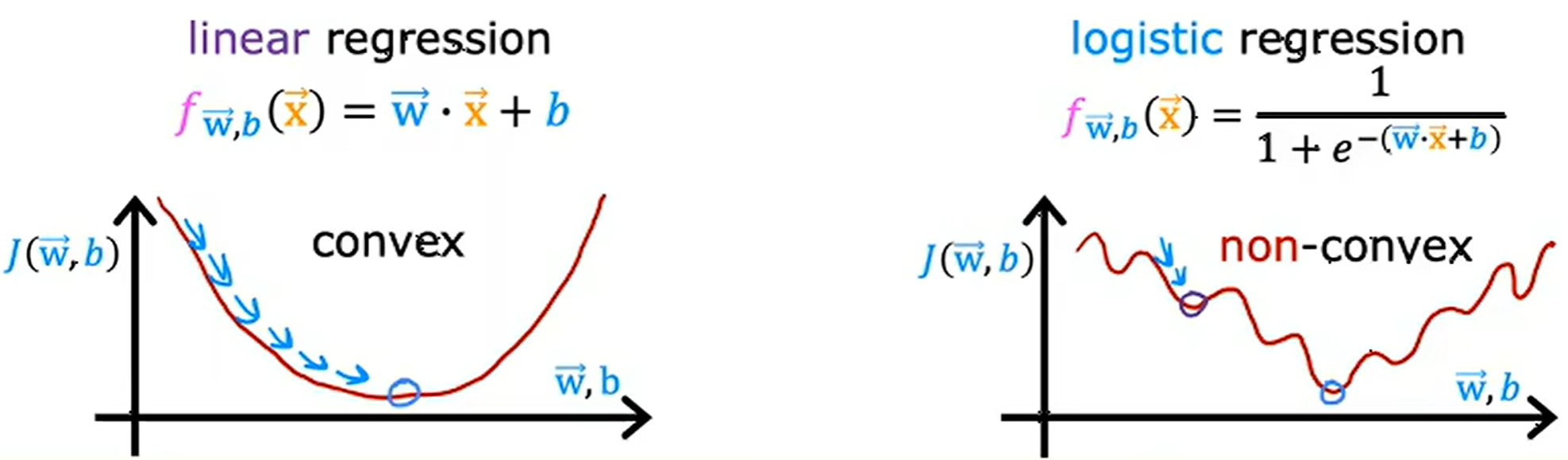
如果同樣使用前面平方誤差作為代價函數的話,從上圖結果來看,這將導致代價函數為非下凸函數 (non-convex function),使用梯度下降會導致很容易陷入局部最小值,而非全局最小值。因此,平方誤差代價函數對于邏輯回歸并不是一個好的選擇。
將以下符號稱為單個訓練實例的損失 (loss)。
L ( f w ? , b ( x ? ( i ) ) , y ( i ) ) L(f_{\vec{w}, b}(\vec{x}^{(i)}), y^{(i)}) L(fw,b?(x(i)),y(i))
例如,在之前學到的線性回歸中,代價函數形式如下。
J ( w , b ) = 1 2 m ∑ i = 1 m ( y ^ ( i ) ? y ( i ) ) 2 J(w, b) = \frac{1}{2m} \sum_{i=1}^m (\hat y^{(i)} - y^{(i)}) ^ 2 J(w,b)=2m1?i=1∑m?(y^?(i)?y(i))2
因此單個訓練實例的損失定義如下。( 1 2 \frac{1}{2} 21? 要提到內部單項)
L ( f w ? , b ( x ? ( i ) ) , y ( i ) ) = 1 2 ( f w ? , b ( x ? ( i ) ) ? y ? ( i ) ) L(f_{\vec{w}, b}(\vec{x}^{(i)}), y^{(i)}) = \frac{1}{2}(f_{\vec{w}, b}(\vec{x}^{(i)}) - \vec{y}^{(i)}) L(fw,b?(x(i)),y(i))=21?(fw,b?(x(i))?y?(i))
另外可以得到,以下定義。
J ( w , b ) = 1 m ∑ i = 1 m L ( f w ? , b ( x ? ( i ) ) , y ( i ) ) J(w, b) = \frac{1}{m} \sum_{i = 1}^{m}L(f_{\vec{w}, b}(\vec{x}^{(i)}), y^{(i)}) J(w,b)=m1?i=1∑m?L(fw,b?(x(i)),y(i))
這里選用以下函數作為邏輯回歸的代價函數,個人感覺是一種針對sigmoid函數的 e x e^x ex 的特殊構造。(不到怎么推出來的,問就是前人的智慧😂)
L ( f w ? , b ( x ? ( i ) ) , y ( i ) ) = { ? log ? ( f w ? , b ( x ? ( i ) ) ) i f y ( i ) = 1 ? log ? ( 1 ? f w ? , b ( x ( i ) ) ) i f y ( i ) = 0 L(f_{\vec{w}, b}(\vec{x}^{(i)}), y^{(i)}) = \begin{cases} -\log(f_{\vec{w}, b}(\vec{x}^{(i)})) &if \quad y^{(i)} = 1\\ -\log (1 - f_{\vec{w}, b}(x^{(i)})) &if \quad y^{(i)} = 0 \end{cases} L(fw,b?(x(i)),y(i))={?log(fw,b?(x(i)))?log(1?fw,b?(x(i)))?ify(i)=1ify(i)=0?
稱為二分類交叉熵損失(Binary Cross-Entropy, BCE)
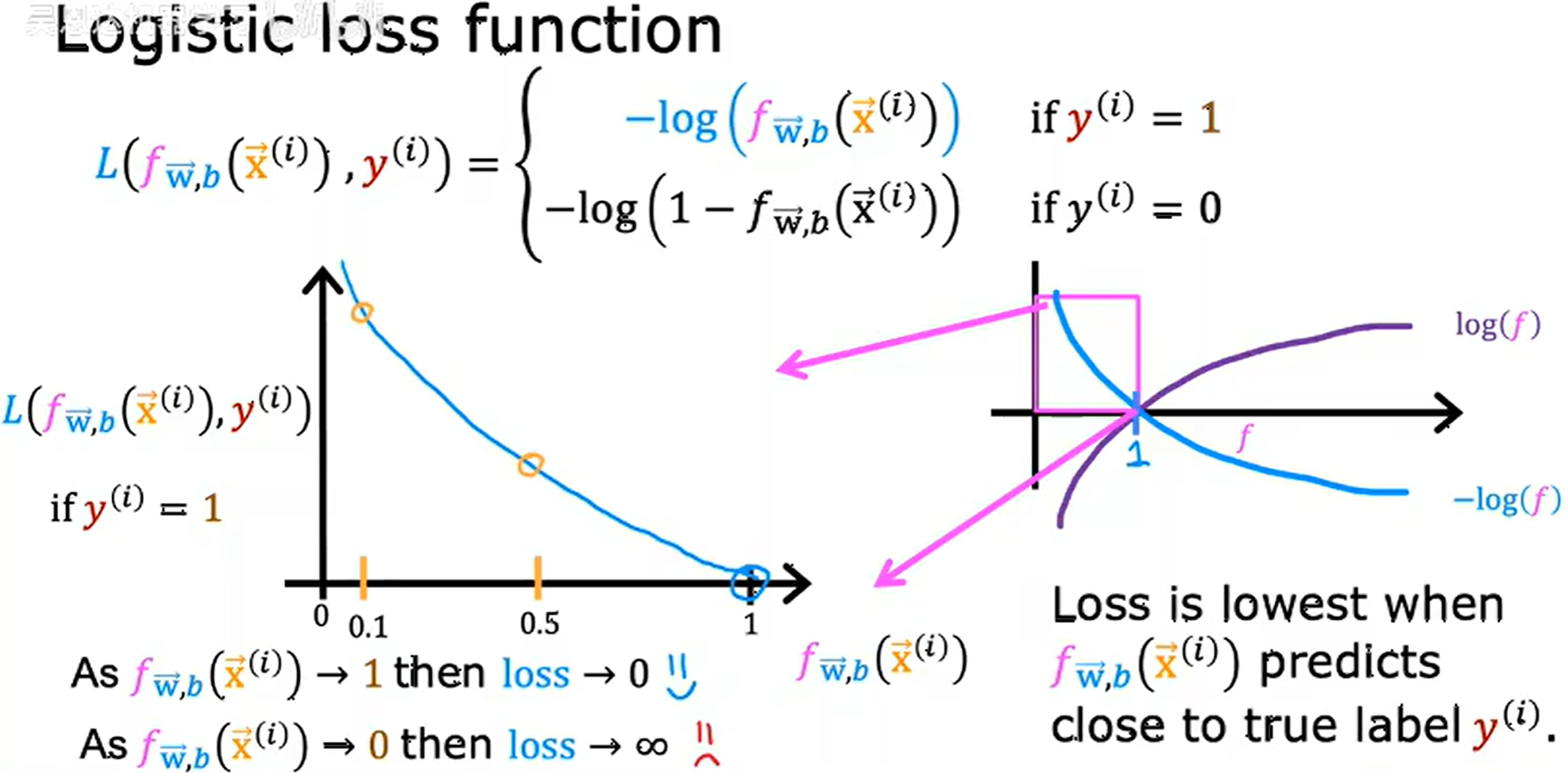
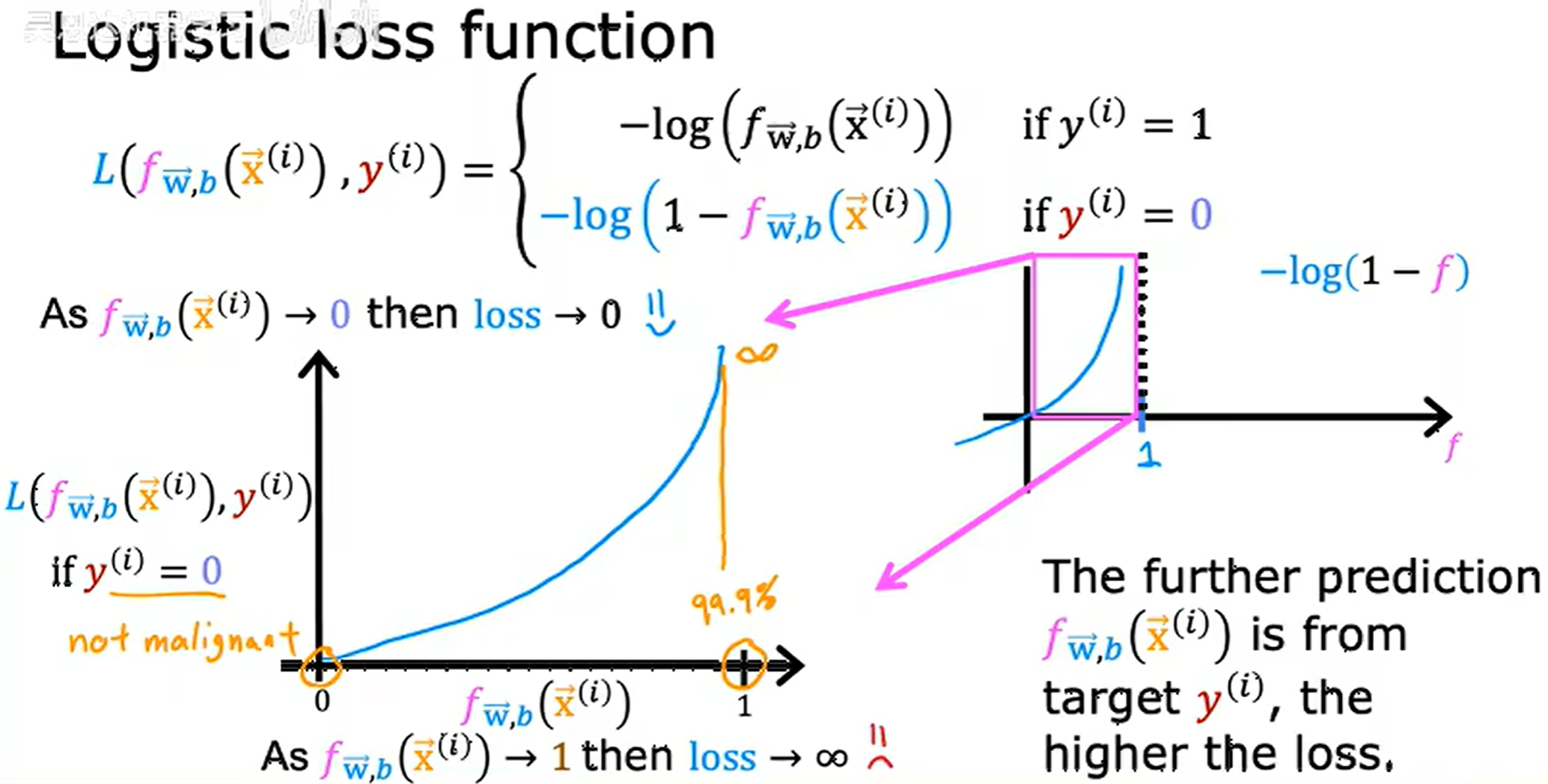
如果模型預測 99.9% 的概率為惡性腫瘤,但是結果為非惡性腫瘤,loss 就會非常高用來懲罰模型。
用原來的平方和的損失函數導致在邏輯回歸情況下,函數是非凹非凸的,會落入局部最小值。兩個拆開的凸函數達到局部最優,也就是整體的全局最優,而改用為這個,把邏輯回歸分為訓練事例 y y y 的真實值為 0 0 0,為 1 1 1,依據log形成兩個拆開的凸函數。

事實證明選擇這個損失函數,整體函數為下凸函數 (convex function),這個構型是高斯誤差方程。
機器學習中代價函數的設計
1. 代價函數的來源
(1)從概率模型推導而來(統計學習視角)
- 核心思想:假設數據服從某種概率分布,通過極大似然估計(MLE) 或 最大后驗估計(MAP) 推導出損失函數。
- 典型例子:
- 均方誤差(MSE):假設噪聲服從高斯分布(線性回歸)。
- 交叉熵損失:假設標簽服從伯努利/多項分布(邏輯回歸、Softmax分類)。
- 泊松損失:假設數據服從泊松分布(計數數據回歸)。
- 為什么有效:
這類損失函數天然具備概率解釋,優化它們等價于最大化數據似然或后驗概率。
(2)直接針對算法目標設計(優化視角)
- 核心思想:不依賴概率假設,而是直接定義優化目標(如間隔最大化、稀疏性等)。
- 典型例子:
- Hinge Loss(SVM):目標是最大化分類間隔,無顯式概率模型。
- 0-1損失:直接優化分類錯誤率(但不可導,實際常用替代損失)。
- 自定義損失:如Focal Loss(解決類別不平衡)、Huber Loss(魯棒回歸)。
- 為什么有效:
這些函數直接反映算法的核心目標(如分類準確性、魯棒性),即使沒有概率解釋。
2. 代價函數與算法的適配性
不同算法使用不同的代價函數,因為它們的目標和假設不同:
| 算法 | 典型代價函數 | 設計依據 |
|---|---|---|
| 線性回歸 | 均方誤差(MSE) | 高斯噪聲假設 + MLE |
| 邏輯回歸 | 交叉熵損失 | 伯努利分布 + MLE |
| 支持向量機(SVM) | Hinge Loss | 最大化分類間隔(幾何目標) |
| 決策樹 | 基尼系數/信息增益 | 分割純度的直接度量 |
| 神經網絡 | 多種(MSE/交叉熵等) | 根據任務選擇(回歸/分類) |
總結
- 回歸問題:常用MSE(高斯假設)、MAE(拉普拉斯假設)、Huber Loss(魯棒性)。
- 分類問題:常用交叉熵(概率校準)、Hinge Loss(間隔最大化)。
- 特定需求:如類別不平衡用Focal Loss,稀疏性用L1正則。
邏輯回歸的簡化代價函數

合并二分類交叉熵損失(Binary Cross-Entropy, BCE)
L ( f w ? , b ( x ? ( i ) ) , y ( i ) ) = ? y ( i ) log ? ( f w ? , b ( x ? ( i ) ) ) ? ( 1 ? y ( i ) ) log ? ( 1 ? f w ? , b ( x ( i ) ) ) L(f_{\vec{w}, b}(\vec{x}^{(i)}), y^{(i)}) = -y ^{(i)} \log(f_{\vec{w}, b}(\vec{x}^{(i)})) - (1 - y ^{(i)}) \log (1 - f_{\vec{w}, b}(x^{(i)})) L(fw,b?(x(i)),y(i))=?y(i)log(fw,b?(x(i)))?(1?y(i))log(1?fw,b?(x(i)))

梯度下降實現


上述求導中,將 log ? \log log 默認看為了 ln ? \ln ln 然后進行。

上述形式看起來很像線性回歸所求的,但是注意 f w ? , b ( x ? ( i ) ) f_{\vec{w}, b}(\vec{x}^{(i)}) fw,b?(x(i)) 已經發生了改變。

)
)









微服務)

-Spring事務簡介(P40)-Spring事務角色(P41)-Spring事務屬性(P42))

超時)


