list即是我們之前學的鏈表,這篇主要還是講解list的底層實現,前面會講一些list區別于前面string和vector的一些接口以及它們的注意事項。
一.list的基本使用
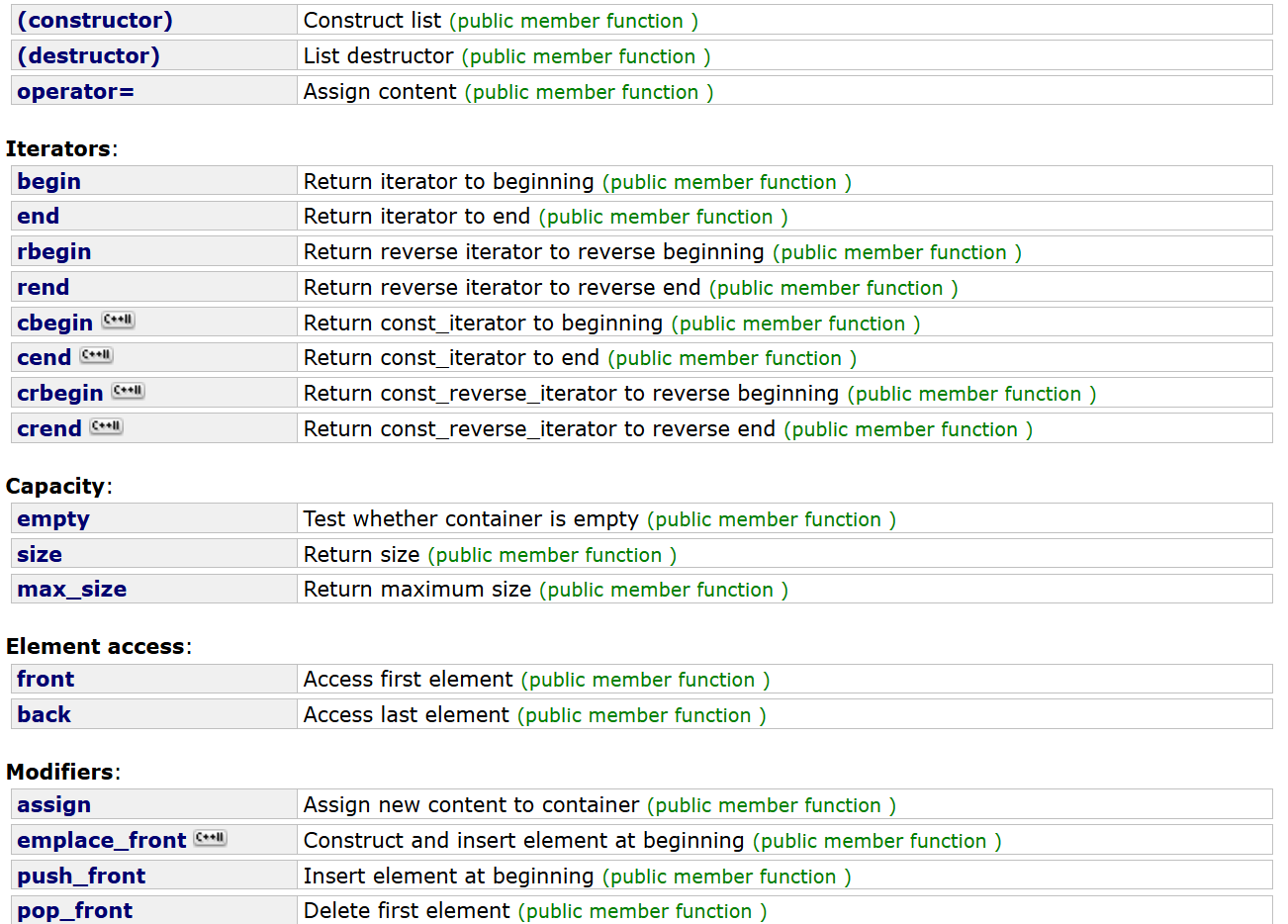
和之前的string,vector一樣,有很多之前見過的一些接口,經過前面兩篇的講解,很多接口不用講解相信大家都會使用,主要就是Operations中的一些接口之前沒有講過,前面主要就是講解這些接口。
這里主要講splice,remove,unique和sort:
1.1splice:
splice的作用是將一個列表中的內容拷貝給另一個鏈表。

可以看出splice有三種傳參的方式,每種方式都會產生不一樣的結果:
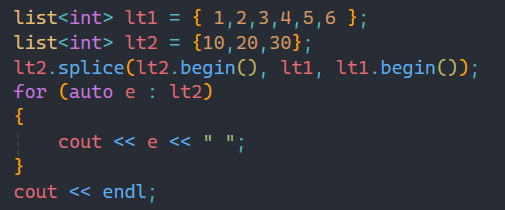
1.1.1第一種傳參
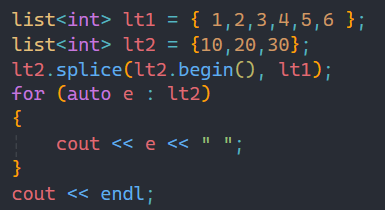
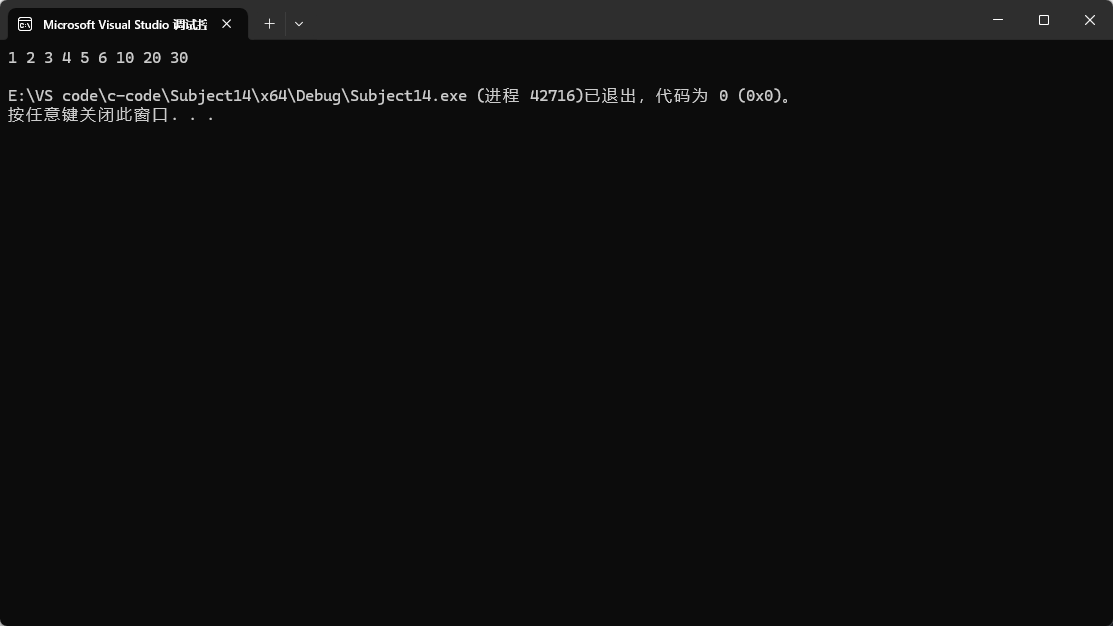
第一種傳參中的兩個參數:第一個參數就是從目標位置開始拷貝數據過去,第二個參數代表某個鏈表。
第一種傳參方式就是把第二個參數中鏈表的所有數據都拷貝到第一個參數之前,結果如第二張圖所示,lt1的所有數據都被拷貝到lt2的begin位置之前。
1.1.2第二種傳參
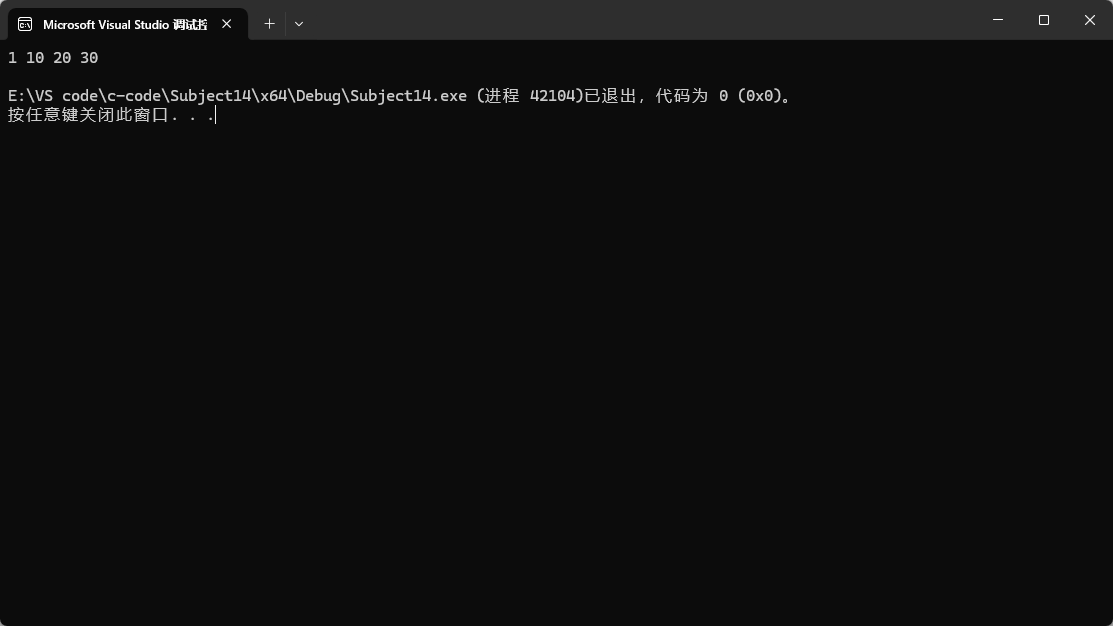
第二種傳參比第一種多了一個參數,意思就是把具體某個位置的值拷貝到目標位置之前,就比如上圖所示的將lt1中的第一個數據拷貝過去。
1.1.3第三種傳參方式
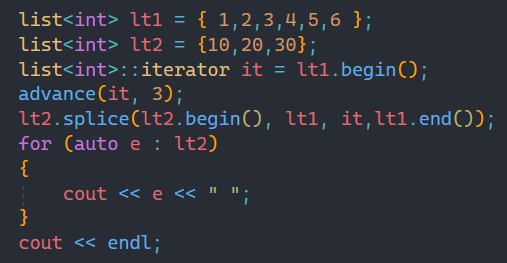
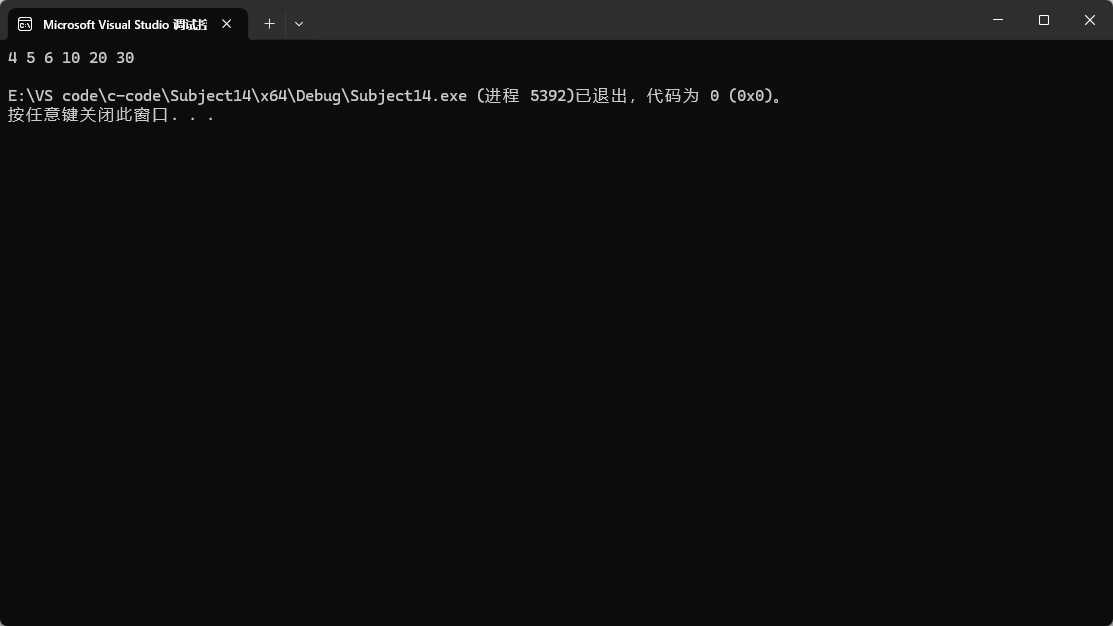
第三種傳參就是把某個范圍的數據拷貝過去,就比如上圖中將lt1中的4到6拷貝過去。
這里可能會有人疑惑:為什么第三個參數直接寫lt1.begin()+3呢?這樣寫不是更簡潔嗎?
這個問題我下面講sort時會講,這里先跳過。
splice還有一種玩法就是可以將自己的數據拷貝到某個位置之前,就比如將最后一個數據拷貝到第一個位置:
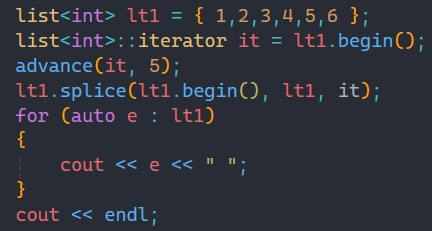
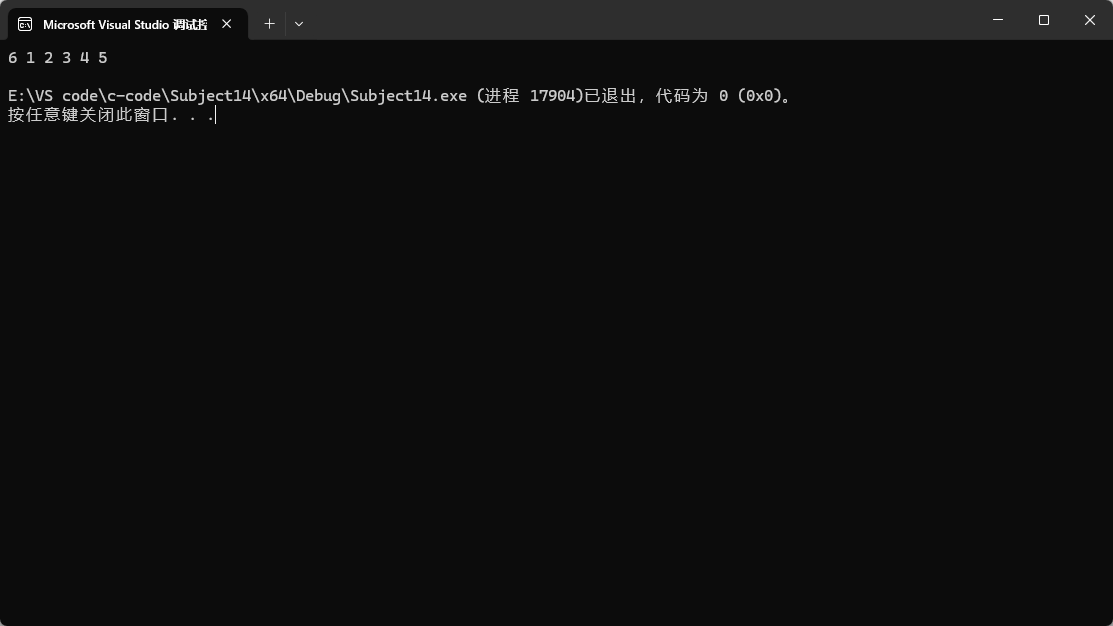
這樣就將6放到了第一個位置,這種用法是要比前面的用法更為普遍的。
1.2remove
list中remove作用是將鏈表中所有和你要刪除的值相同的數據一并刪除。
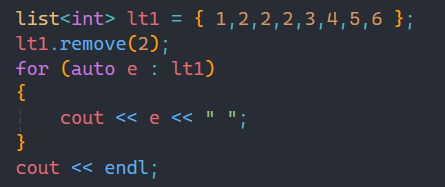
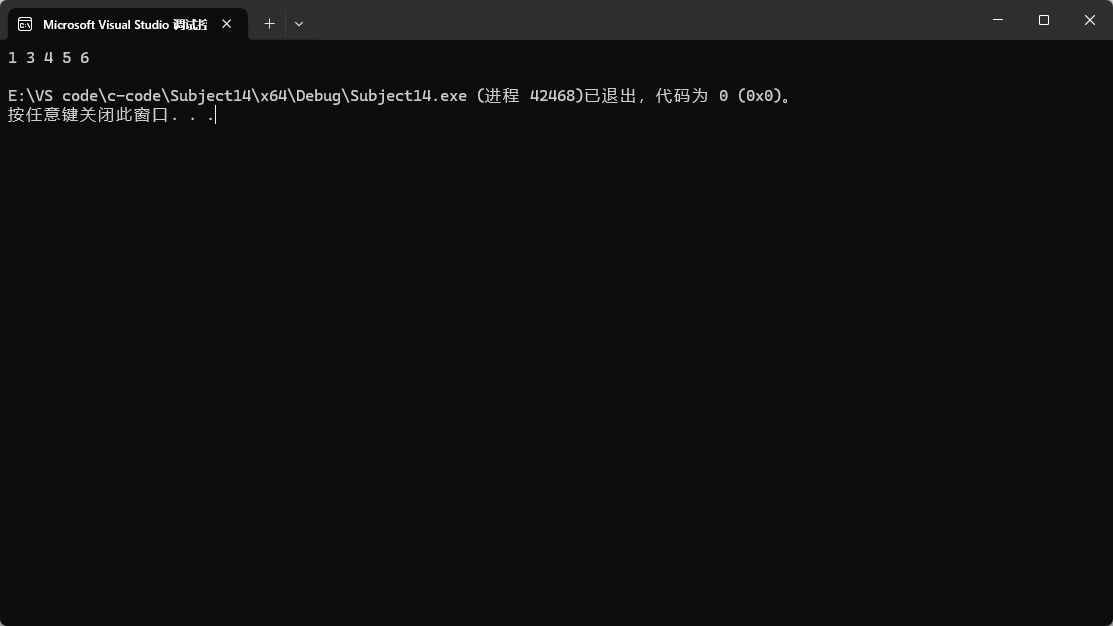
如上圖所示,這里就把所有的2都給刪除了,remove的基本用法就是如此。
1.3unique
unique的作用就是刪除一個有序鏈表中重復的數據。
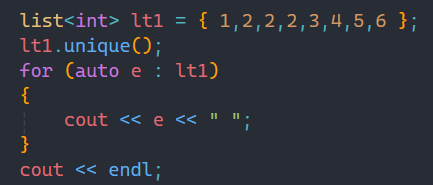
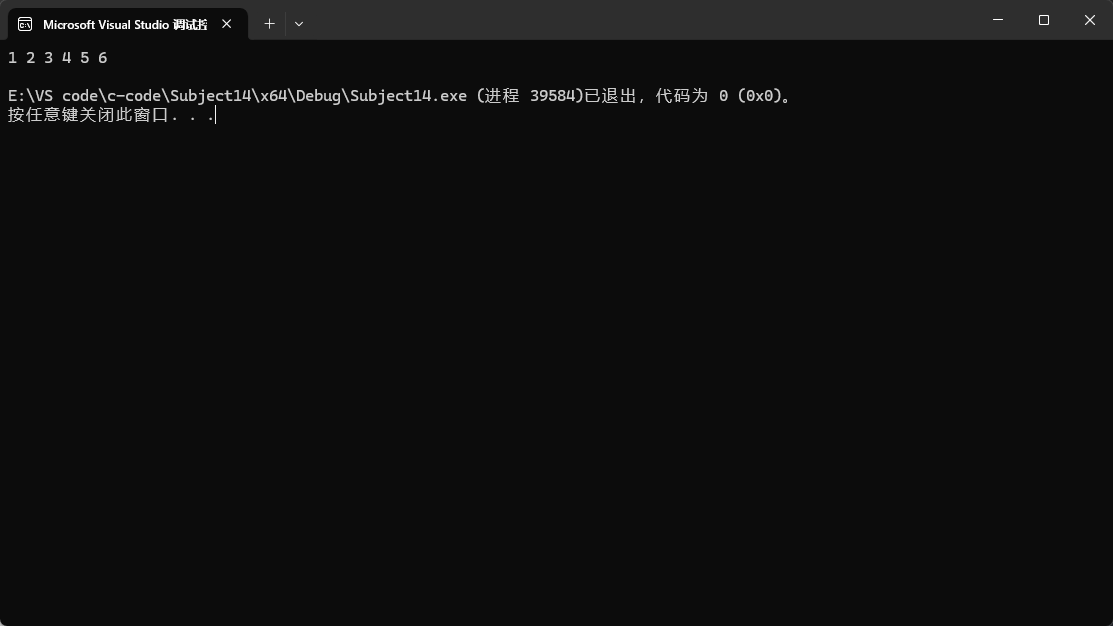
通過unique就可以把重復的數據給刪掉。
注意:一定要是有序的,如果不是有序的就無法做到刪除重復的數據。
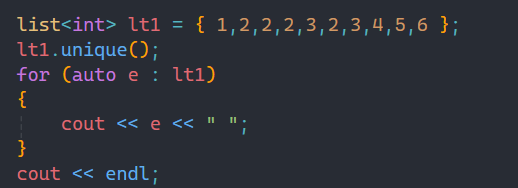
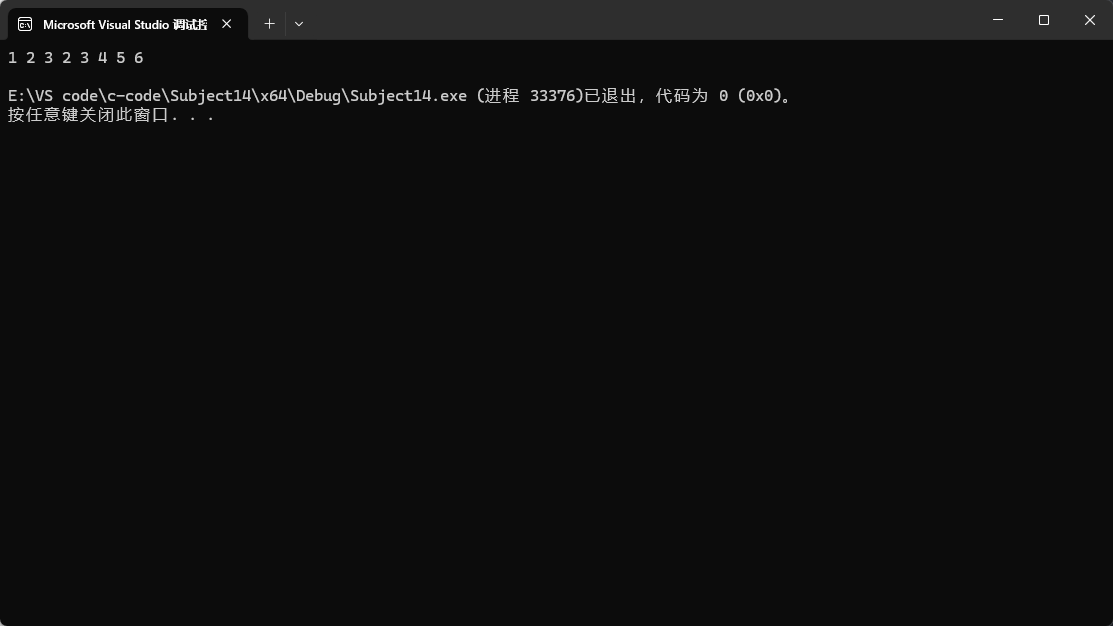
此時鏈表數據不是有序的,unique就沒有發揮作用。
1.4sort
sort的作用相信就不用多說大家都知道,但是在這里我們要思考兩個問題:
1.string和vector都沒有實現sort接口,為什么list要單獨實現?
2.list實現的sort效率怎么樣?
先來解釋第一個問題:
這個問題的答案也能解釋上面splice出現的疑點,這就涉及到迭代器的分類。
迭代器分為三類(移動迭代方式):
1.單向迭代器,如:forword_list/unordered_map...? ?++
2.雙向迭代器,如:list/map...? ?++/--
3.隨機迭代器,如:string/vector/deque.. ++/--/+/-
后面就是它們能夠進行的移動迭代方式,而語法庫中的sort參數是隨機迭代器,list都是雙向迭代器,所以不能使用語法庫中的sort,而上面的splice出現的疑點也是因為雙向迭代器不能+/-,所以不能那樣使用。

中間藍色的單詞的意思就是雙向迭代器。


這是string和vector的隨機迭代器。

這是語法庫中的sort的參數要求,上去就要求隨機迭代器,所以list才需要自己實現。
而迭代器的分類和之前講的權限放大和縮小的概念有些類似,就是如果函數參數要求是雙向迭代器,此時我們傳隨機迭代器也是可以的,相當于權限的縮小,同理單向迭代器也是如此。
雙向迭代器和隨機迭代器就是特殊的單向迭代器。
再來說第二個問題:
我就直接說結論,list自己實現的sort效率不高,比起語法庫中的sort效率低了很多。
不過在數量較少時,效率差不多,但是在數量較大時效率就會低很多,舉個例子:
在數量較大時,把list中的數據拷貝到vector,調用語法庫中的sort,再把數據傳回list的效率都比直接調用list本身的sort高。
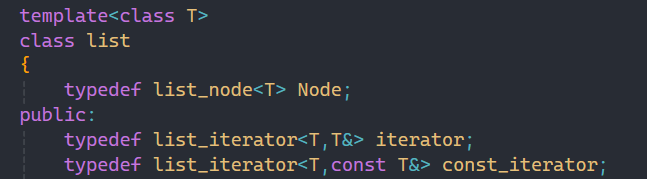
二.list的底層實現
2.1list框架的實現
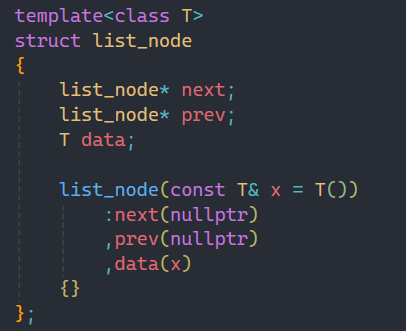
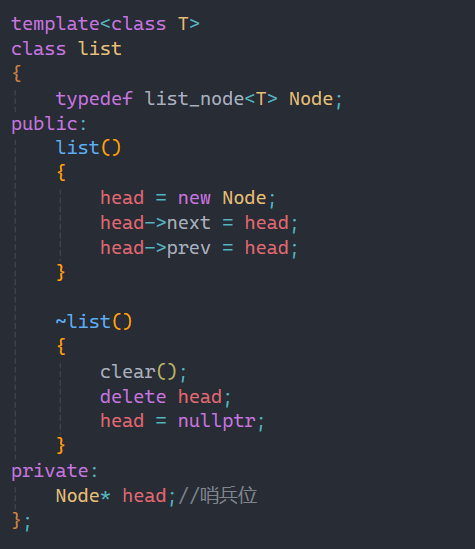
鏈表我們之前在數據結構階段都了解過,鏈表要把整個鏈表和單個結點區分開,所以這里也是同理。
這里定義哨兵位,相信大家都知道底層list其實就是雙向帶頭循環鏈表。
可能有人會疑惑:為什么單個結點要用struct而不用class?
其實我們在實際應用中,想讓別人使用的用class,不想別人訪問的用struct,我們只想讓別人用鏈表整體,而不能直接訪問我一個結點中的變量。
在單個結點類中運用初始化列表進行初始化,這樣在list類中初始化哨兵位時就不需要傳數據,直接創捷一個哨兵位,并讓prev和next都指向自己即可,和之前講鏈表是一樣的。
2.2push_back尾插
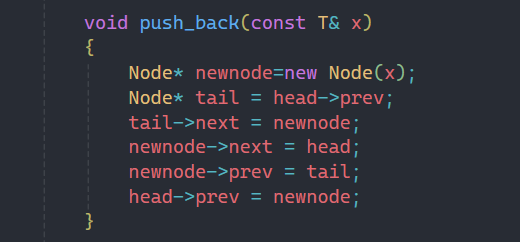
思路和之前講鏈表是一樣的,創建一個節點,并更新哨兵位,原尾節點和新建結點的next和prev即可。
2.3iterator迭代器的實現
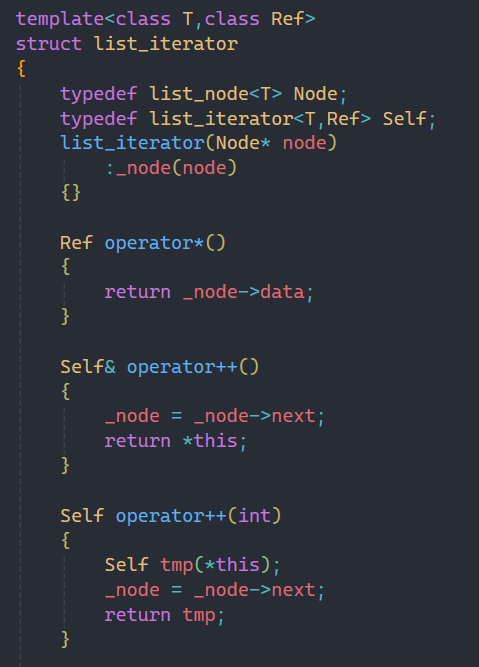
之前在string中講過迭代器并不就一定是指針,在list中印證了。
為什么在list中要單獨實現iterator迭代器呢?
因為在之前的string和vector中,它們兩個底層都是數組,它們的原生指針就能完成解引用和++等操作,而鏈表我們知道解引用是訪問一個結點,而一個結點不止有數據,還有prev和next,而迭代器我們要求解引用就是直接拿出其中的數據。
包括++等操作,鏈表底層并不是數組,每個結點的地址并不是連續的,所以通過++等操作是不能找到相鄰的結點的。
基于以上兩點,所以在list終究要我們自己實現iterator迭代器,而自定義類型的迭代器其實執行的還是指針的作用,所以成員變量依舊還是單個結點的地址。
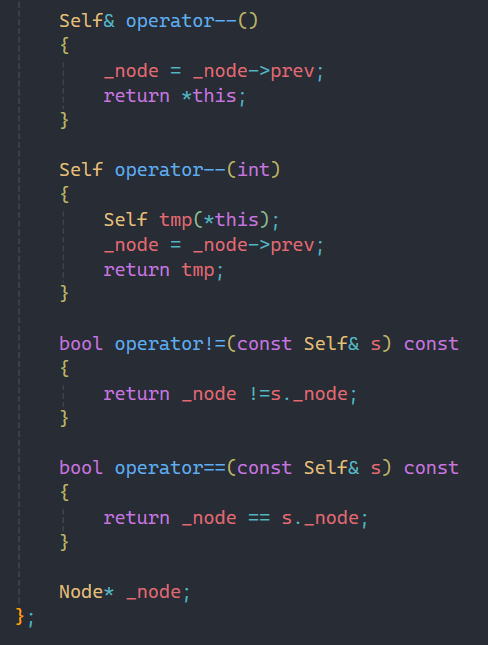
其中里面所實現的各種比較我就不過多贅述了,之前都講過,這里主要講解一下為什么多加了一個類型Ref。
因為不僅有iterator,還有const_iterator,兩者的區別無非就是解引用的值能不能修改的問題,但是如果我們沒有多加Ref這個類型,那我們是不是還要寫一個函數重載?
但是從之前學過的函數重載中我們知道,是不能以返回值不同而進行函數重載的,程序會報錯,
那要解決這個問題就只能在單獨寫一個const_iterator類,內容和iterator一樣,除了解引用符號的重載這一個不同而已。
這樣寫代碼就太冗余了,有很多重復代碼,但是我們加一個類型Ref就可以解決這個問題,根據傳過去的參數不同將其分為iterator和const_iterator:
可能有人會疑惑:iterator類不需要實現析構函數嗎?
我們所實現的iterator只是用于解引用和遍歷鏈表而已,不能使用后直接把這個節點給銷毀了,所以不能實現析構函數,相應的也不需要實現拷貝構造函數。
上面的結點類也是一樣,析構操作只需要在list類中實現即可。
另外其中的!=,==等符號的重載是因為現在iterator是自定義類型,不再是原生指針,所以如果要比較自定義類型,就要重載相應的符號。
2.3begin和end
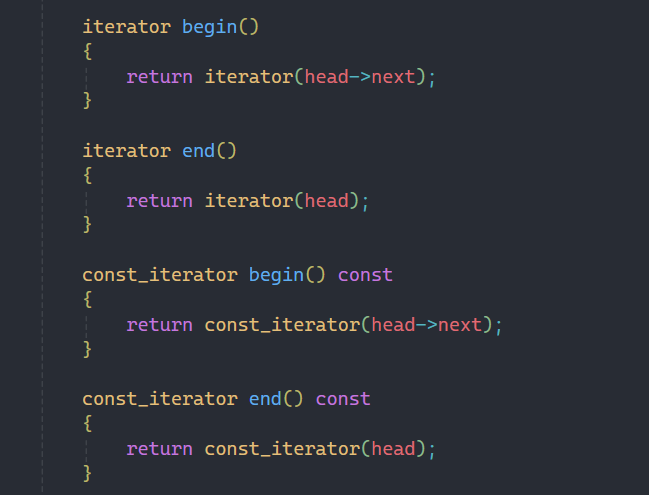
實現了迭代器iterator,接下來就要實現begin和end,也是分為普通和const版本,注意返回值是需要調用iterator類并進行傳參的,頭結點是哨兵位的下個結點,end返回就是哨兵位。
2.4insert
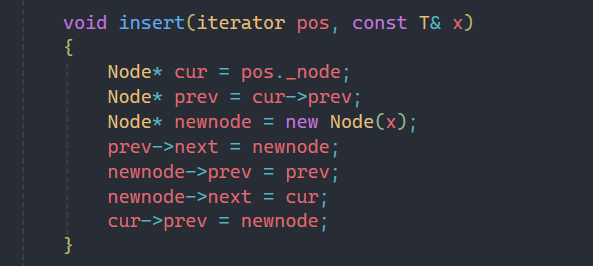
insert實現邏輯和之前一樣,找到目標結點的prev和next,并更新三個結點的next和prev即可。
2.5erase
 ?
?
相信現在看到這個返回值大家就知道erase會出現什么問題了,沒錯,還是迭代器失效的問題,所以還是要在erase后更新指針。
需要注意的地方有兩個:
1.目標結點不能是哨兵位
2.刪除當前結點后,要更新指針的位置,指向下個結點
2.6push_front,pop_back和pop_front

這三個包括之前實現的push_back就都可以通過復用insert和erase來實現,要注意的就是尾刪不能直接傳end,要讓end--才是尾結點的位置。
2.7clear
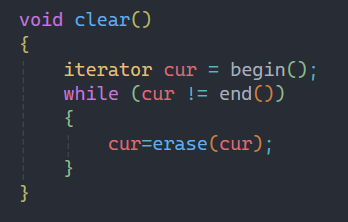
clear的作用就是銷毀除哨兵位之外的所有結點,實現起來也較為容易,遍歷整個鏈表挨個銷毀即可。
2.7拷貝構造函數
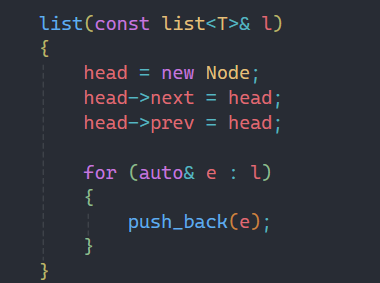
實現拷貝構造函數也是為了深拷貝做準備,一樣也要創建哨兵位,不過這和構造函數的代碼一樣,所以其實可以將這段代碼封裝成一個函數也可以,這里因為就幾行代碼所以我就沒整。
下面就是遍歷目標鏈表,把相應的節點push_back進去即可。
2.8=符號重載
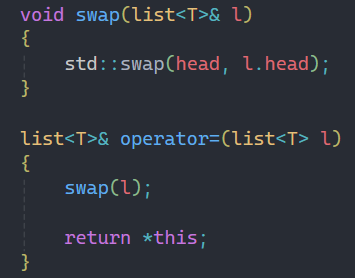
以及是需要用到std標準庫中的swap函數進行操作,最后=符號重載復用即可。
我們再看最后一種情況:
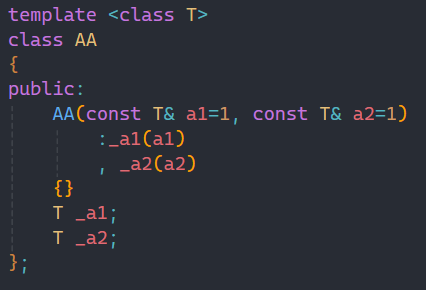
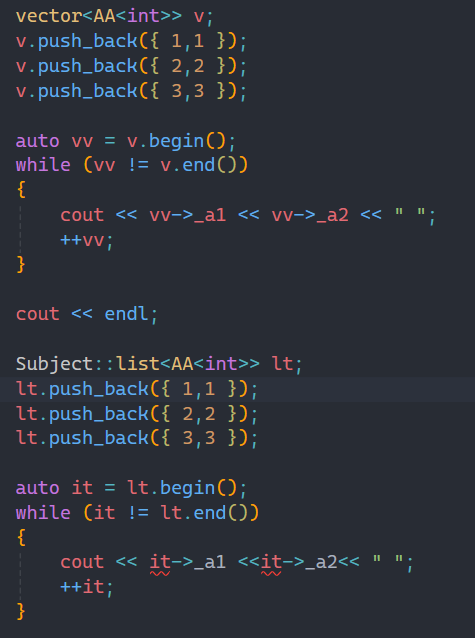
當傳進去的參數類型是自定義類型時,我們要訪問其中的數據要用到->符號,但是vector是可以直接用的,因為它用的是原生指針,而list不能使用,因為是自定義類型迭代器,所以在這里我們要自己實現->符號。
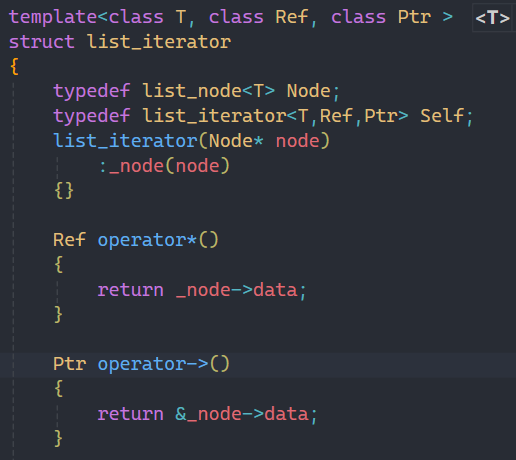
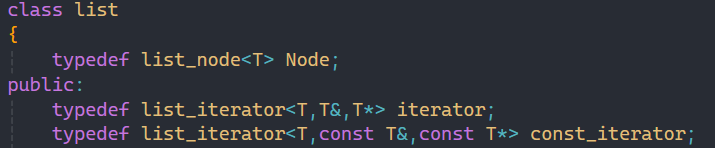
和上面的解引用重載一樣,這里我們引進一種類型Ptr,代表要輸出的數據的地址,所以也分為普通和const版本,作用也就和vector原生指針作用是一樣的。

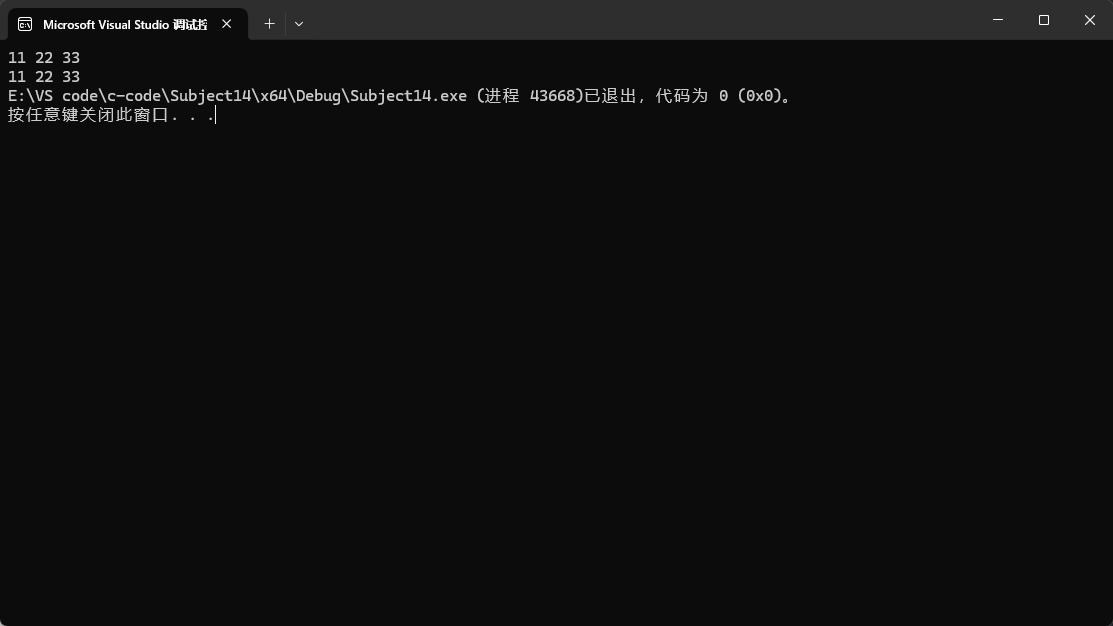
此時就不再會報錯,但是可能有人會覺得很奇怪:不應該是兩個箭頭嗎?
第一個箭頭返回的是指針,應該還有一個箭頭才能指向數據啊。
這個想法沒錯,出現這現象的原因是為了可讀性高,編譯器把另一個箭頭給省略了。
以上就是list的內容。



)

)
)









微服務)

-Spring事務簡介(P40)-Spring事務角色(P41)-Spring事務屬性(P42))
