以下是 AI在多Agent協同領域的核心概念、技術方法、應用場景及挑戰 的詳細解析:
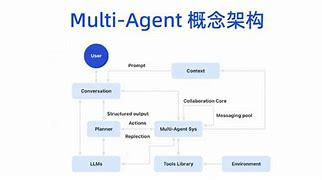
1. 多Agent協同的定義與核心目標
- 多Agent系統(MAS, Multi-Agent System):
由多個獨立或協作的智能體(Agent)組成,每個Agent具有自主決策能力,通過通信與協作完成復雜任務。 - 核心目標:
- 協調多個Agent的行動以實現全局最優(而非個體最優)。
- 解決單個Agent難以處理的復雜問題(如動態環境、分布式任務)。
2. 多Agent協同的核心AI技術
(1) 多Agent強化學習(MARL, Multi-Agent Reinforcement Learning)
- 原理:
多個Agent通過試錯學習,在交互中優化各自的策略,同時考慮其他Agent的行動影響。 - 關鍵挑戰:
- 非平穩環境(Non-stationarity):其他Agent的策略變化會改變學習環境。
- 信用分配(Credit Assignment):如何將全局獎勵合理分配給各Agent。
- 典型方法:
- 獨立Q-學習(Independent Q-Learning):每個Agent獨立學習,忽略其他Agent的影響(適用于簡單任務)。
- 集中式訓練,分布式執行(Centralized Training, Decentralized Execution, CTDE):利用全局信息訓練策略,但執行時僅依賴局部信息。
- 深度多Agent強化學習(如MADDPG、QMIX):結合深度學習處理高維狀態空間。
(2) 博弈論與納什均衡
- 應用:
通過博弈模型(如合作博弈、非合作博弈)建模Agent之間的交互,尋找穩定策略(納什均衡)。 - 典型場景:
- 資源競爭(如自動駕駛車輛路徑規劃中的避讓決策)。
- 電力市場競價(Agent代表不同發電廠商競爭市場份額)。
(3) 群體智能(Swarm Intelligence)
- 原理:
向自然界的群體行為(如螞蟻覓食、鳥群飛行)學習,通過簡單規則實現復雜協作。 - 典型算法:
- 粒子群優化(PSO):用于優化問題(如任務分配)。
- 蟻群算法(ACO):用于路徑規劃或網絡路由優化。
(4) 分布式優化與共識算法
- 應用場景:
- 多Agent在分布式網絡中協作求解優化問題(如分布式機器學習)。
- 通過共識算法(如DESIREE、異步參數服務器)同步參數,確保全局一致性。
3. 典型應用場景與案例
(1) 自動駕駛與交通系統
- 場景:
車輛、行人、交通信號燈等作為Agent協同決策。 - 技術應用:
- 路徑規劃:車輛通過強化學習協調避讓動作,減少擁堵。
- V2X通信:車輛間實時共享位置與意圖,避免事故。
- 案例:
Waymo自動駕駛系統通過多Agent協作實現復雜路況下的安全駕駛。
(2) 機器人協作
- 場景:
多機器人協同完成任務(如倉庫物流、救災救援)。 - 技術應用:
- 任務分配:基于Q-learning或博弈論分配任務以最小化總成本。
- 路徑協調:通過A*算法或群體智能避免碰撞。
- 案例:
亞馬遜倉庫的Kiva機器人通過分布式算法協作揀貨。
(3) 游戲AI與虛擬環境
- 場景:
多個AI角色在開放世界中協作或對抗(如《星際爭霸》)。 - 技術應用:
- AlphaStar:DeepMind通過多Agent強化學習訓練《星際爭霸》AI,實現多兵種協同作戰。
- 非玩家角色(NPC):通過群體智能生成自然行為模式(如人群疏散模擬)。
(4) 分布式系統與物聯網(IoT)
- 場景:
設備、傳感器等作為Agent協作管理資源(如能源、網絡帶寬)。 - 技術應用:
- 動態資源分配:通過MARL優化邊緣計算節點的任務分配。
- 網絡安全防御:多Agent協同檢測并阻斷攻擊(如DDoS防御)。
4. 技術挑戰與解決方案
(1) 通信與隱私問題
- 挑戰:
- Agent間通信開銷大,或存在延遲。
- 敏感數據共享可能引發隱私泄露。
- 解決方案:
- 輕量化通信協議(如基于注意力機制的選擇性通信)。
- 聯邦學習:在不共享原始數據的情況下協作訓練模型。
(2) 可擴展性與魯棒性
- 挑戰:
- 系統規模擴大時,策略復雜度指數級增長(“維度災難”)。
- 外部干擾或Agent故障導致系統崩潰。
- 解決方案:
- 分層架構:將Agent分組協作,減少直接交互。
- 容錯機制:設計冗余路徑或動態任務再分配策略。
(3) 激勵兼容與公平性
- 挑戰:
- Agent可能因利益沖突導致合作失敗(如“搭便車”現象)。
- 資源分配不均引發公平性爭議。
- 解決方案:
- 機制設計:通過博弈論設計激勵機制,確保合作收益大于個體背叛收益。
- 公平性約束:在優化目標中加入公平性指標(如基尼系數)。
5. 未來趨勢
- 混合智能體架構:結合強化學習與群體智能,提升復雜任務的適應性。
- 可解釋性與倫理:設計可解釋的多Agent系統,確保決策透明與公平。
- 與區塊鏈結合:利用智能合約實現去中心化的多Agent協作(如分布式能源交易)。
- 元學習(Meta-Learning):Agent通過元知識快速適應新任務或環境。
總結表格
| 技術方向 | 核心方法 | 典型應用 | 優勢 |
|---|---|---|---|
| 多Agent強化學習 | MADDPG、QMIX、CTDE | 自動駕駛、游戲AI | 復雜動態環境中的自適應決策 |
| 群體智能 | 蟻群算法、粒子群優化 | 機器人編隊、物流調度 | 分布式、低通信開銷的協作 |
| 博弈論 | 納什均衡、機制設計 | 電力市場、交通信號控制 | 理性決策與利益協調 |
| 分布式優化 | DESIREE、參數服務器架構 | 分布式計算、邊緣計算 | 高效資源利用與全局一致性 |
關鍵工具與框架
- 開源框架:
- PettingZoo:多Agent強化學習基準測試平臺。
- MADRL:基于PyTorch的多Agent強化學習庫。
- OpenAI Multi-Agent:支持復雜環境的協作與競爭實驗。
- 仿真平臺:
- Gazebo(機器人協作模擬)。
- StarCraft II(游戲AI訓練環境)。
通過AI驅動的多Agent協同,復雜系統可實現更高效、智能的協作,未來將在智能制造、智慧城市、元宇宙等領域發揮關鍵作用。




平臺無關?相關?)











)


