自動微分
自動微分模塊torch.autograd負責自動計算張量操作的梯度,具有自動求導功能。自動微分模塊是構成神經網絡訓練的必要模塊,可以實現網絡權重參數的更新,使得反向傳播算法的實現變得簡單而高效。
1. 基礎概念
-
張量
Torch中一切皆為張量,屬性requires_grad決定是否對其進行梯度計算。默認是 False,如需計算梯度則設置為True。
-
計算圖:
torch.autograd通過創建一個動態計算圖來跟蹤張量的操作,每個張量是計算圖中的一個節點,節點之間的操作構成圖的邊。
在 PyTorch 中,當張量的 requires_grad=True 時,PyTorch 會自動跟蹤與該張量相關的所有操作,并構建計算圖。每個操作都會生成一個新的張量,并記錄其依賴關系。當設置為
True時,表示該張量在計算圖中需要參與梯度計算,即在反向傳播(Backpropagation)過程中會自動計算其梯度;當設置為False時,不會計算梯度。? -
x 和 y 是輸入張量,即葉子節點,z 是中間結果,loss 是最終輸出。每一步操作都會記錄依賴關系:
z = x * y:z 依賴于 x 和 y。
loss = z.sum():loss 依賴于 z。
這些依賴關系形成了一個動態計算圖,如下所示:
? ? x ? ? ? y
? ? ? ?\ ? ? /
? ? ? ? \ ? /
? ? ? ? ?\ /
? ? ? ? ? z
? ? ? ? ? |
? ? ? ? ? |
? ? ? ? ? v
? ? ? ? loss
 ?
?
detach():張量 x 從計算圖中分離出來,返回一個新的張量,與 x 共享數據,但不包含計算圖(即不會追蹤梯度)。
特點:
-
返回的張量是一個新的張量,與原始張量共享數據。
-
對 x.detach() 的操作不會影響原始張量的梯度計算。
-
推薦使用 detach(),因為它更安全,且在未來版本的 PyTorch 中可能會取代 data。
-
反向傳播
使用tensor.backward()方法執行反向傳播,從而計算張量的梯度。這個過程會自動計算每個張量對損失函數的梯度。例如:調用 loss.backward() 從輸出節點 loss 開始,沿著計算圖反向傳播,計算每個節點的梯度。
-
梯度
計算得到的梯度通過tensor.grad訪問,這些梯度用于優化模型參數,以最小化損失函數。
2. 計算梯度
使用tensor.backward()方法執行反向傳播,從而計算張量的梯度
2.1 標量梯度計算
參考代碼如下:
import torchdef test001():# 1. 創建張量:必須為浮點類型x = torch.tensor(1.0, requires_grad=True)# 2. 操作張量y = x ** 2# 3. 計算梯度,也就是反向傳播y.backward()# 4. 讀取梯度值print(x.grad) # 輸出: tensor(2.)if __name__ == "__main__":test001()?向量梯度計算
# 1. 創建張量:必須為浮點類型
? ? x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
? ? # 2. 操作張量
? ? y = x ** 2
? ? # 3. 計算梯度,也就是反向傳播
? ? y.backward()
? ? # 4. 讀取梯度值
? ? print(x.grad)
我們也可以將向量 y 通過一個標量損失函數(如 y.mean())轉換為一個標量,反向傳播時就不需要提供額外的梯度向量參數了。這是因為標量的梯度是明確的,直接調用 .backward() 即可。
調用 loss.backward() 從輸出節點 loss 開始,沿著計算圖反向傳播,計算每個節點的梯度。
損失函數loss=mean(y)=\frac{1}{n}∑_{i=1}^ny_i,其中 n=3。
對于每個 y_i,其梯度為 \frac{?loss}{?y_i}=\frac{1}{n}=\frac13。
對于每個 x_i,其梯度為:
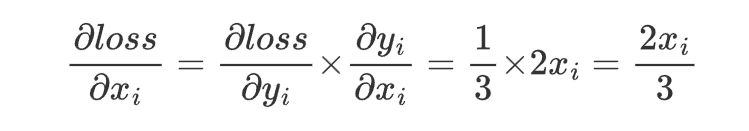
?
?
模型定義組件
模型(神經網絡,深度神經網絡,深度學習)定義組件幫助我們在 PyTorch 中定義、訓練和評估模型等。
在進行模型訓練時,有三個基礎的概念我們需要顆粒度對齊下:

常用損失函數舉例:
1.均方誤差損失(MSE Loss)
-
函數: torch.nn.MSELoss
-
適用場景: 通常用于回歸任務,例如預測連續值。
-
特點: 對異常值敏感,因為誤差的平方會放大較大的誤差。
2.L1 損失(L1 Loss)
也叫做MAE(Mean Absolute Error,平均絕對誤差)
-
函數: torch.nn.L1Loss
-
適用場景: 用于回歸任務,對異常值的敏感性較低。
-
特點: 比 MSE 更魯棒,但計算梯度時可能不穩定。
3.交叉熵損失(Cross-Entropy Loss)
-
函數: torch.nn.CrossEntropyLoss
-
參數:reduction:mean-平均值,sum-總和
-
公式:
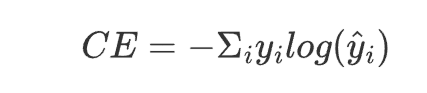
-
適用場景: 用于多分類任務,輸入是未經 softmax 處理的 logits。
-
特點: 自帶 softmax 操作,適合分類任務,能夠有效處理類別不平衡問題。
4.二元交叉熵損失(Binary Cross-Entropy Loss)
-
函數: torch.nn.BCELoss 或 torch.nn.BCEWithLogitsLoss
-
參數:reduction:mean-平均值,sum-總和
-
公式:
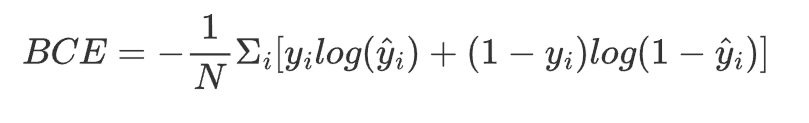
-
適用場景: 用于二分類任務。
-
特點: BCEWithLogitsLoss 更穩定,因為它結合了 Sigmoid 激活函數和 BCE 損失。
?
平臺無關?相關?)











)



)


