?
?Google DeepMind
Google Research
發表于 2024-04-29

相關鏈接:
數據集:https://huggingface.co/datasets/katielink/med-gemini-medqa-relabeled
注:長EHR是長的電子健康記錄(Electronic Health Record)
未開源!
?摘要
在眾多醫療應用中實現卓越表現對人工智能來說是巨大挑戰,這需要先進的推理能力、獲取最新醫學知識的途徑,以及對復雜多模態數據的理解。Gemini模型在多模態和長上下文推理方面具備強大的通用能力,為醫學領域帶來了令人期待的可能性。基于Gemini 1.0和Gemini 1.5的這些核心優勢,我們推出了Med - Gemini,這是一系列功能強大的多模態模型,專門針對醫學領域進行了優化,能夠無縫整合網絡搜索功能,并且可以通過定制編碼器高效地適配新的模態。
我們在涵蓋文本、多模態和長上下文應用的14個醫學基準測試中對Med - Gemini進行評估,在其中10個測試中創造了新的最先進(SoTA)性能,并且在所有能夠直接比較的基準測試中都超越了GPT - 4模型系列,且往往優勢明顯。在廣受歡迎的MedQA(美國醫學執照考試,USMLE)基準測試中,我們表現最佳的Med - Gemini模型采用了一種新的不確定性引導搜索策略,達到了91.1%的準確率,創造了新的SoTA性能,比我們之前表現最佳的Med - PaLM 2高出4.6%。
我們基于搜索的策略在《新英格蘭醫學雜志》(NEJM)的復雜診斷挑戰和GeneTuring基準測試中也展現出了SoTA性能。在包括NEJM圖像挑戰和MMMU(健康與醫學)在內的7個多模態基準測試中,Med - Gemini比GPT - 4V的平均相對優勢提高了44.5%。我們通過在從長去標識化健康記錄的“大海撈針”式檢索任務和醫學視頻問答中達到SoTA性能,展示了Med - Gemini的長上下文能力,超越了僅使用上下文學習的先前定制方法。
最后,Med - Gemini的性能表明了其在現實世界中的實用性,在醫學文本摘要和轉診信生成等任務中超越了人類專家,同時在多模態醫學對話、醫學研究和教育方面也顯示出了巨大的潛力。總體而言,我們的結果為Med - Gemini在醫學眾多領域的應用前景提供了有力證據,盡管在這個對安全性要求極高的領域進行實際部署之前,進一步嚴格的評估至關重要。
?1 引言
醫學是一項復雜的工作。臨床醫生的日常工作包括與患者會診,在這個過程中,清晰地溝通診斷結果、治療方案以及表達同理心對于建立信任至關重要。復雜病例需要深入了解患者電子病歷中的病史,同時還需要從醫學圖像和其他診斷中進行多模態推理。為了在不確定的情況下做出決策,臨床醫生必須及時了解從研究出版物到手術視頻等各種權威來源的最新醫學信息。醫療服務的藝術在于臨床醫生能夠進行先進的臨床推理,從多樣的多模態來源綜合復雜信息,并與其他臨床醫生有效協作,以幫助患者進行治療。雖然人工智能(AI)系統可以輔助完成個別醫療任務 ,并且在多模態多任務“通用”醫療應用方面也展現出了初步的前景,但開發更復雜的推理、多模態和長上下文理解能力,將為臨床醫生和患者帶來更加直觀且實用的輔助工具。
大語言模型(LLMs)和大多模態模型(LMMs),如GPT4、PaLM和Gemini的出現,表明這些模型能夠有效地編碼臨床知識,甚至在需要專業知識的復雜病例和場景的醫學問答基準測試中也能有出色表現。然而,在這些任務上的表現并不能直接反映其在現實世界中的實用性。醫學數據的獨特性質以及對安全性的嚴格要求,需要專門的提示、微調,或者可能兩者都需要,同時還需要仔細校準這些模型。
經過醫學微調的大語言模型可以為數百萬互聯網用戶提出的細致且開放式的醫學問題提供高質量的長篇答案,Med - PaLM 2在事實性、推理、危害和偏差等方面超越了醫生。其潛力不僅限于問答領域。諸如Flamingo - CXR和Med - PaLM M等大多模態模型在受控環境下生成放射學報告的能力與放射科醫生相當。在與患者進行基于文本的診斷咨詢這一更具挑戰性的場景中,Articulate Medical Intelligence Explorer(AMIE)模型在診斷對話的多個評估維度上優于初級保健醫生。
盡管取得了這些有前景的成果,但性能仍有很大的提升空間。大語言模型在不確定性下的臨床推理表現欠佳,虛構信息和偏差仍然是主要挑戰。對于大語言模型來說,使用工具和獲取最新醫學信息以完成醫療任務仍然是一個難題,與臨床醫生的有效協作也是如此。此外,它們處理復雜多模態醫學數據(例如,整合圖像、視頻和隨時間變化的去標識化健康記錄)的能力目前也較為有限。盡管這些能力在醫學應用中尤為重要,但性能的提升可能不僅限于醫學領域。為衡量和加速醫學大語言模型的進展而開發的任務和基準測試將產生廣泛的影響。
Gemini模型,如Gemini 1.0和1.5技術報告中所述,是新一代功能強大的多模態模型,具有新的基礎能力,有可能解決醫學人工智能的一些關鍵挑戰。這些模型是基于Transformer解碼器架構的模型,通過在架構、優化和訓練數據方面的創新得到增強,使其能夠在包括圖像、音頻、視頻和文本在內的各種模態中展現出強大的能力。最近引入的專家混合架構,使Gemini模型能夠在推理時高效地擴展并處理更長、更復雜的數據。
基于Gemini模型的優勢,我們推出了Med - Gemini,這是一系列針對醫學領域進行微調并專門化的模型。通用醫學人工智能模型的概念受到了廣泛關注,這類系統的潛力也得到了令人矚目的展示。然而,盡管通用方法在醫學研究中是一個有意義的方向,但現實世界的考慮因素帶來了權衡和特定任務優化的要求,這些要求之間可能相互沖突。在這項工作中,我們并不試圖構建一個通用的醫學人工智能系統。相反,我們引入了一系列模型,每個模型都針對不同的能力和特定應用場景進行了優化,同時考慮了訓練數據、計算資源可用性和推理延遲等因素。
Med - Gemini繼承了Gemini在語言和對話、多模態理解以及長上下文推理方面的基礎能力。對于基于語言的任務,我們通過自訓練增強了模型使用網絡搜索的能力,并在代理框架內引入了推理時的不確定性引導搜索策略。這種結合使模型能夠為復雜的臨床推理任務提供更符合事實、可靠且細致入微的結果。這使得Med - Gemini在MedQA(USMLE)測試中達到了91.1%的準確率,創造了新的最先進性能,比之前的Med - PaLM 2模型高出4.6%。我們還通過與多位獨立的專家臨床醫生重新標注MedQA(USMLE)數據,仔細檢查了數據質量,識別出由于信息缺失和錯誤而無法回答的問題,從而能夠對我們的最先進性能進行可靠的分析和描述。不確定性引導搜索策略具有通用性,在《新英格蘭醫學雜志》(NEJM)臨床病理會議(CPC)病例和GeneTuring基準測試中也帶來了最先進的性能。除了在這些基準測試中的出色表現,我們的模型在與人類醫生進行醫學筆記總結和臨床轉診信生成等任務的比較中也表現出色,這表明了其在現實世界中的實用性。
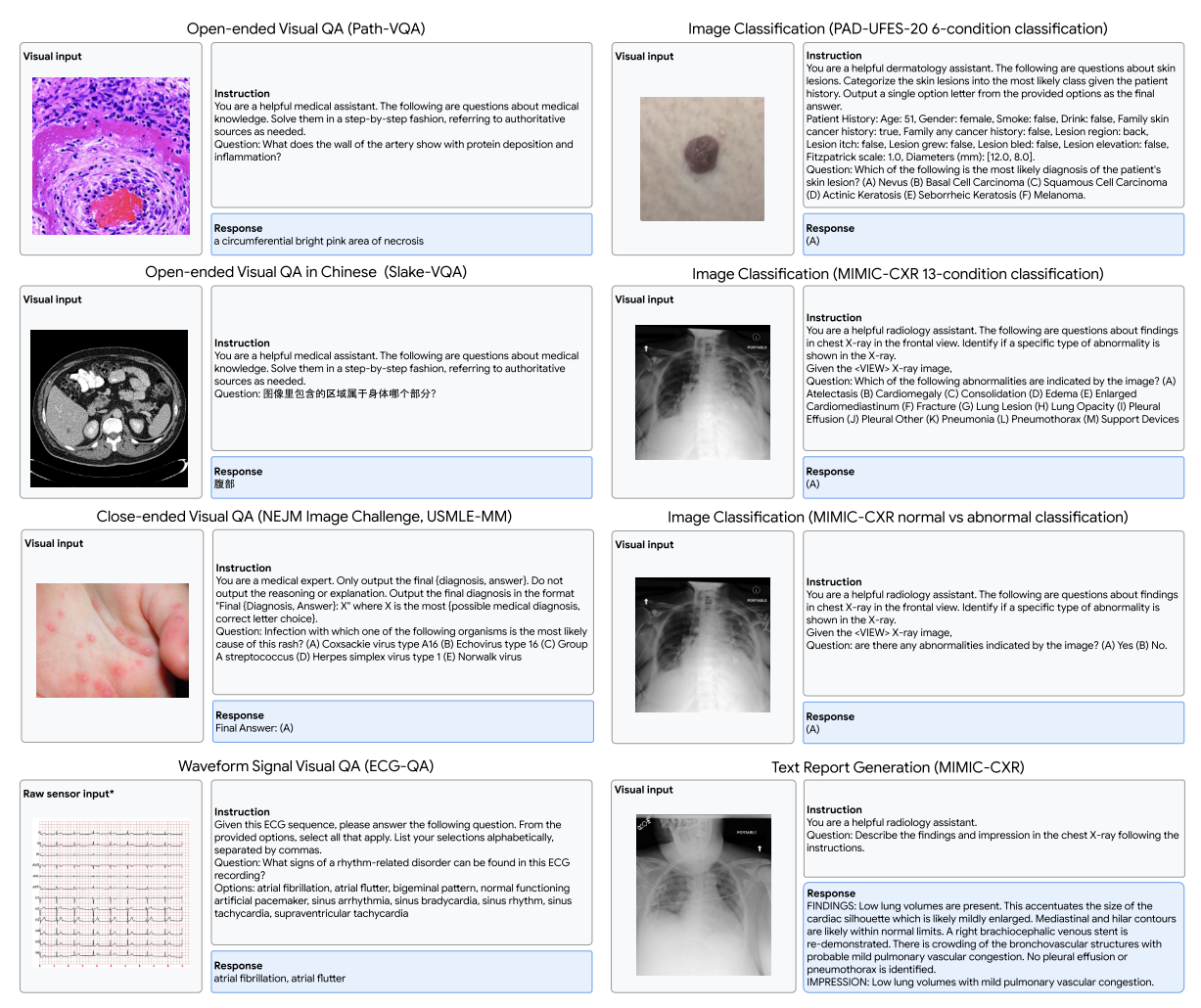
由于Gemini模型經過訓練能夠處理與多種其他數據模態交織的文本輸入,因此它們在多模態任務中表現出色。這使得它們在一些多模態醫學基準測試中,如NEJM圖像挑戰,具有令人印象深刻的開箱即用的最先進性能。然而,當處理在預訓練數據中代表性不足的專業醫學模態時,它們的性能仍有提升空間。我們通過多模態微調解決了這個問題,并展示了模型使用定制編碼器適應新醫學模態的能力,在Path - VQA和ECG - QA等基準測試中達到了最先進的性能。我們定性地展示了我們的模型在各種分布內和分布外數據模態上進行具有臨床意義的多模態對話的能力。
最后,Gemini模型的長上下文能力為醫學應用開辟了許多令人興奮的可能性,因為在臨床決策中,經常需要解析大量數據,而這存在“信息過載”的風險。我們配置用于長上下文處理的Med - Gemini模型能夠無縫分析復雜的長格式模態,如去標識化的電子健康記錄(EHRs)和視頻。我們在“大海撈針”式的長EHR理解、醫學教學視頻問答、視頻中的手術動作識別以及手術視頻的安全關鍵視圖(CVS)評估等任務中取得了令人矚目的成績,展示了這些能力的有效性。
Med - Gemini的進展前景廣闊,但在大規模實際部署之前,仔細考慮醫學領域的細微差別、明確AI系統作為專家臨床醫生輔助工具的作用,并進行嚴格的驗證仍然至關重要。
我們的主要貢獻總結如下:
Med - Gemini,我們新的多模態醫學模型系列:我們推出了一個新的功能強大的多模態醫學模型系列,基于Gemini構建。Med - Gemini在臨床推理、多模態和長上下文能力方面取得了重要進展。它們經過進一步微調,能夠利用網絡搜索獲取當前信息,并可以通過使用特定模態的編碼器定制以適應新的醫學模態。
全面的基準測試:我們在14個醫學基準測試中的25個任務上評估了Med - Gemini的能力,涵蓋了文本、多模態和長上下文應用。據我們所知,這是迄今為止對多模態醫學模型最全面的基準測試。
臨床語言任務的最先進結果:針對臨床推理進行優化的Med - Gemini在MedQA(USMLE)測試中使用一種新的不確定性引導搜索策略,達到了91.1%的最先進性能。我們通過與臨床專家對MedQA數據集進行仔細的重新標注,量化并描述了我們的性能提升,發現這些改進是有意義的。我們還通過在NEJM CPC和GeneTuring基準測試中的最先進性能,展示了搜索策略的有效性。
多模態和長上下文能力:Med - Gemini在本研究評估的7個多模態醫學基準測試中的5個中達到了最先進性能。我們展示了多模態醫學微調的有效性,以及使用專門的編碼器層定制以適應新醫學模態(如心電圖,ECGs)的能力。Med - Gemini還展現出強大的長上下文推理能力,在諸如長電子健康記錄中的“大海撈針”任務或醫學視頻理解基準測試等具有挑戰性的基準測試中達到了最先進水平。此外,在未來的工作中,我們還將嚴格探索Gemini在放射學報告生成方面的能力。
Med - Gemini在現實世界中的實用性:除了在流行的醫學基準測試中的表現,我們還通過對醫學筆記總結、臨床轉診信生成和EHR問答等任務的定量評估,預展示了Med - Gemini在現實世界中的潛在實用性。我們進一步展示了多模態診斷對話的定性示例,以及模型的長上下文能力在醫學教育、面向臨床醫生的工具和生物醫學研究中的應用。我們注意到,這些應用(特別是在像診斷這樣對安全性要求極高的領域)將需要大量的進一步研究和開發。
?2 方法
如Gemini技術報告中所介紹的,Gemini生態系統包含一系列在大小、模態編碼器和架構上有所不同的模型,這些模型在多種模態的大量高質量數據上進行訓練。Gemini模型在各種語言、推理、編碼、多語言、圖像和視頻基準測試中都取得了最先進的結果。
值得注意的是,Gemini 1.0 Ultra模型在需要復雜推理的基于語言的任務中表現出色,而Gemini 1.5 Pro模型則增加了有效處理和利用跨越數百萬個標記的長上下文輸入和 / 或多模態輸入(如數小時的視頻或數十小時的音頻)的能力。Gemini 1.0 Nano是Gemini模型系列中最小的模型變體,可以在設備上高效運行。
我們基于Gemini系列開發Med - Gemini模型,重點關注以下能力和方法:
1. 通過自訓練和網絡搜索集成實現先進推理:對于需要較少復雜推理的語言任務,如總結醫學筆記和生成轉診信,我們通過微調Gemini 1.0 Pro模型引入了Med - Gemini - M 1.0。對于其他需要更先進推理的任務,我們通過使用自訓練方法微調Gemini 1.0 Ultra模型引入了Med - Gemini - L 1.0,使模型能夠有效地使用網絡搜索。我們在推理時開發了一種新的不確定性引導搜索策略,以提高在復雜臨床推理任務中的性能。
2. 通過微調定制編碼器實現多模態理解:Gemini模型本質上是多模態的,并且在許多多模態基準測試中展示了令人印象深刻的零樣本性能。然而,一些醫學模態的獨特性質和異質性需要進行微調才能實現最佳性能。我們通過在一系列多模態醫學數據集上對Gemini 1.5 Pro進行微調,引入了Med - Gemini - M 1.5。我們還引入了Med - Gemini - S 1.0,并展示了Gemini模型使用專門的編碼器適應新醫學模態的能力,該模型基于Gemini 1.0 Nano構建。
3. 通過推理鏈實現長上下文處理:對于長上下文處理任務,我們使用具有長上下文配置的Med - Gemini - M 1.5。此外,我們還開發了一種受Tu等人啟發的新的推理時推理鏈技術,以更好地理解長EHRs。
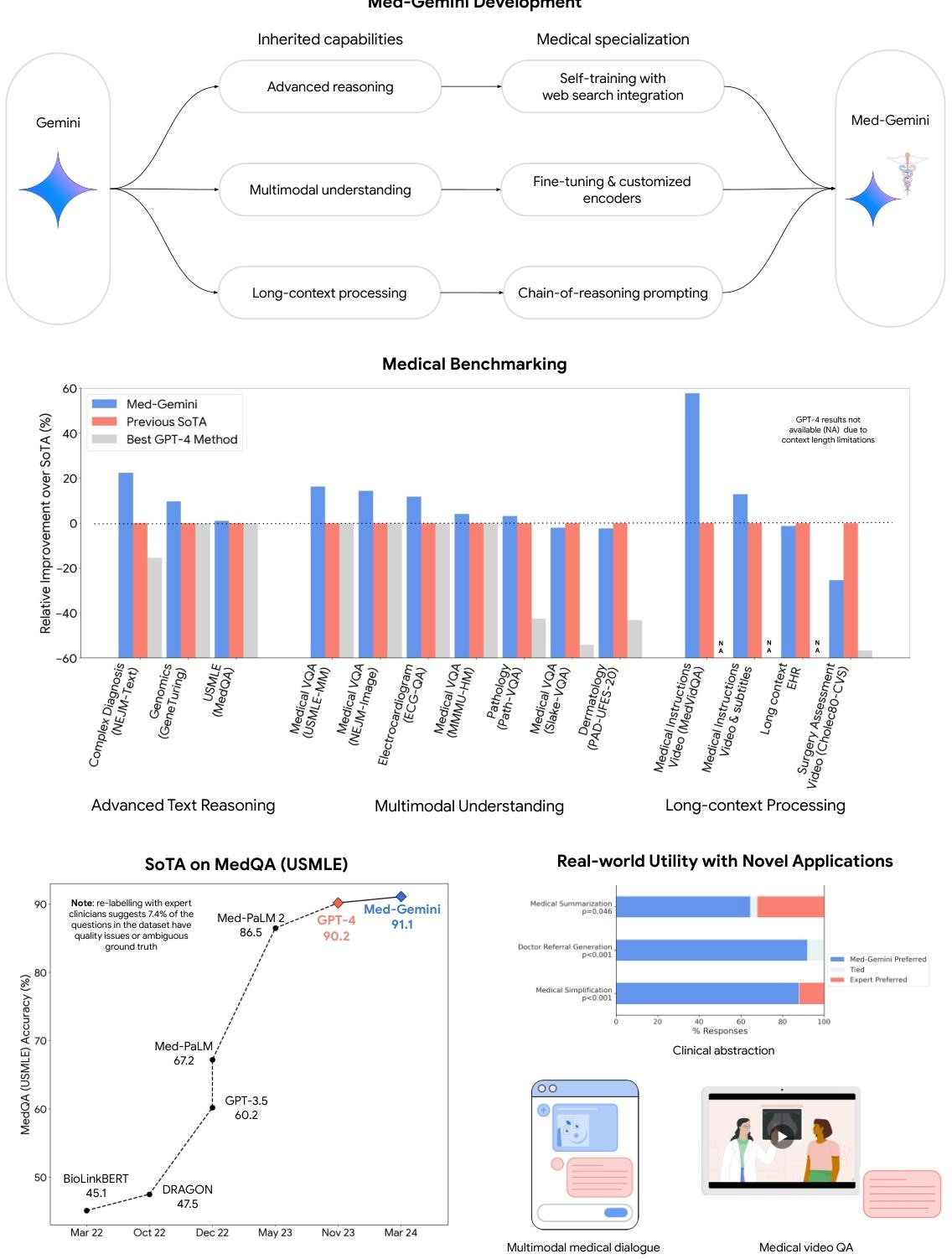
圖1 | 我們的研究貢獻概述。我們推出了Med - Gemini,這是一系列基于Gemini構建的高性能多模態醫學模型。我們通過自訓練和網絡搜索集成來增強模型的臨床推理能力,同時通過微調與定制編碼器提升多模態性能。Med - Gemini模型在涵蓋文本、多模態和長上下文應用的14個醫學基準測試中,有10個達到了最先進(SoTA)水平,并且在所有可直接比較的基準測試中均超越了GPT - 4模型系列。柱狀圖展示了我們的模型相對于先前最先進方法在各個基準測試中的相對百分比提升。特別是在MedQA(美國醫學執照考試,USMLE)基準測試中,我們達到了新的最先進水平,比我們之前最好的Med - PaLM 2模型大幅高出4.6%。此外,由專家臨床醫生對數據集進行重新標注后發現,7.4%的問題被認為不適合用于評估,因為這些問題要么缺少關鍵信息、答案錯誤,要么存在多種合理的解釋。我們考慮到這些數據質量問題,以便更精確地描述我們模型的性能。Med - Gemini模型在多模態和長上下文能力方面表現卓越,在多個基準測試中達到最先進水平就是證明,這些測試包括從長時間去標識化健康記錄中進行“大海撈針”式的檢索任務,以及醫學視頻問答基準測試。除了基準測試,我們還通過對醫學總結、轉診信生成和醫學簡化任務的定量評估,展示了Med - Gemini在現實世界中的潛力,在這些任務中我們的模型表現優于人類專家,此外還提供了多模態醫學對話的定性示例。
?2.1 通過自訓練和網絡搜索集成實現先進推理
臨床推理是成功醫療的一項基本技能。雖然它是一個廣泛的領域,有許多定義,但臨床推理可以被概念化為一個迭代過程,在這個過程中,醫生將自己的臨床知識與初始患者信息相結合,形成病例表征。
然后,這個表征被用于指導進一步信息的迭代獲取,直到達到置信閾值,以支持最終的診斷以及治療和管理計劃。在這個過程中,醫生可能會對許多不同的輸入進行推理,如患者癥狀、醫學和社會經濟病史、檢查和實驗室測試、先前對治療的反應以及其他更廣泛的因素,如流行病學數據。
此外,許多這些輸入都具有時間成分,例如一系列不斷變化的癥狀、隨時間變化的實驗室測量值,或者為監測健康而收集的各種時間數據,如心電圖(ECGs)。醫學知識是高度動態的,由于研究的快速發展,醫學信息量的“翻倍時間”不斷縮短。
為了確保其輸出反映該領域的最新信息,大語言模型不僅需要具備強大的推理能力,還需要能夠整合最新信息,例如從權威的網絡來源獲取信息。這種對外部知識的依賴有可能減少模型響應中的不確定性,但需要一種明智的信息檢索方法。
我們對Gemini 1.0 Ultra進行醫學微調的主要目標是提高模型進行最有幫助的網絡搜索查詢的能力,并在推理過程中整合搜索結果以生成準確答案。最終得到的模型是Med - Gemini - L 1.0。
指令微調已被證明可以提高大語言模型的臨床推理能力。一個常用的指令調優數據集是MedQA,它由代表美國醫學執照考試(USMLE)問題的多項選擇題組成,旨在評估在各種場景下的醫學知識和推理能力,涉及大量感興趣的變量。
然而,MedQA只提供了多項選擇題的正確答案,缺乏訓練大語言模型在不同環境下進行臨床推理所需的專家推理過程示范。因此,在MedQA上進行微調的大語言模型,如Med - PaLM 2,仍然存在顯著的推理缺陷。再加上此類系統無法訪問網絡搜索,這導致了事實性錯誤,這些錯誤會在下游推理步驟中累積,或者導致模型在未考慮所有可能推理路徑的情況下過早得出結論。
為基于語言的任務微調數據集,收集專家臨床推理示范,包括專家如何明智地使用網絡搜索等知識檢索工具,既耗時又難以擴展。為了克服這個問題,我們通過如下所述的自訓練生成了兩個新的數據集:MedQA - R(推理),它通過合成生成的推理解釋(即“思維鏈”,CoTs)擴展了MedQA;以及MedQA - RS(推理和搜索),它在MedQA - R的基礎上增加了使用網絡搜索結果作為額外上下文以提高答案準確性的指令。
為了給Med - Gemini - L 1.0的微調數據增加更多樣性,我們還添加了一個長篇問答數據集,該數據集包含對MultiMedQA基準測試中HealthSearchQA、LiveQA和MedicationQA問題的260個由專家精心編寫的長篇答案,以及一個醫學摘要數據集,其中包含65個由臨床醫生撰寫的來自MIMIC - III的醫學筆記摘要。我們在表C1中概述了用于基于語言的指令微調數據集。
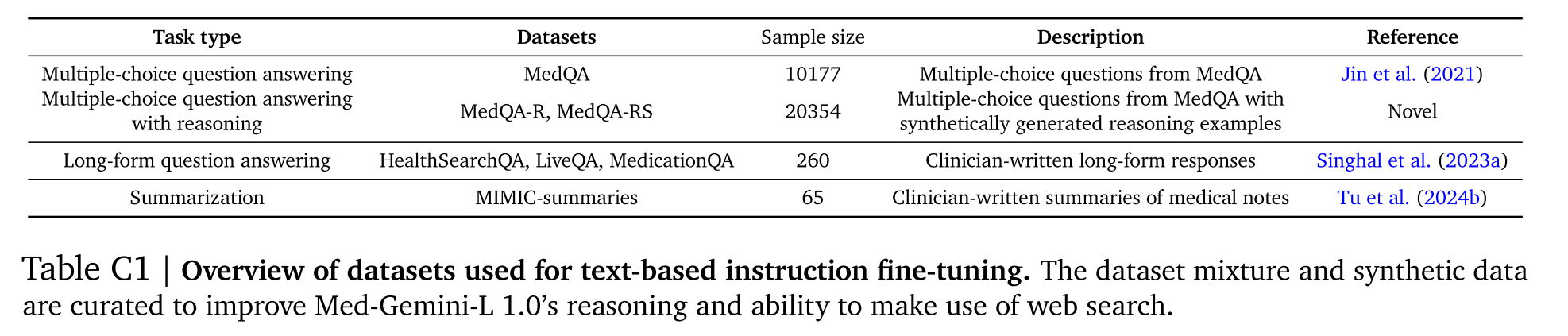
表C1|用于基于文本的指令微調的數據集概述。對數據集混合和合成數據進行管理,以提高Med-Gemini-L 1.0的推理能力和利用網絡搜索的能力。
受最近自訓練在合成數據生成方面取得成功的啟發,我們實施了一個迭代數據生成框架,旨在精心策劃使用網絡搜索的高質量臨床推理合成示例。
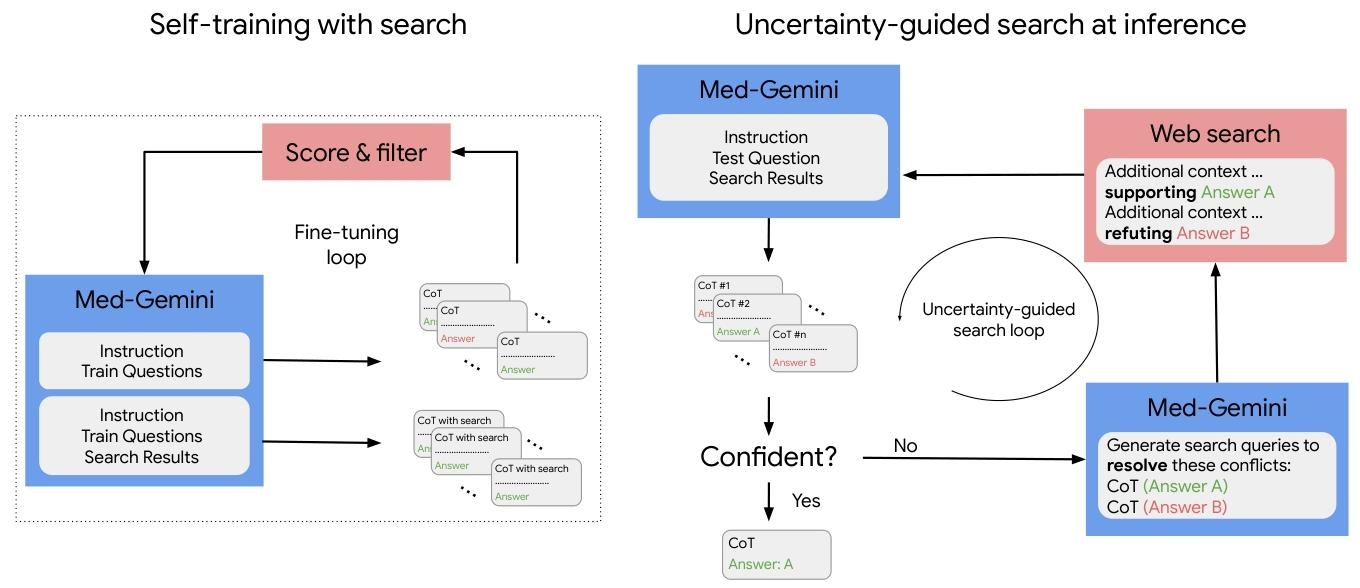
?圖2 | 自訓練與搜索工具的使用。左圖展示了用于對Med - Gemini - L 1.0進行微調的搜索自訓練框架,以實現先進的醫學推理和網絡搜索的運用。該框架通過迭代生成有網絡搜索和無網絡搜索的推理響應(思維鏈,CoTs),提升模型利用外部信息得出準確答案的能力。右圖展示了Med - Gemini - L 1.0在推理時的不確定性引導搜索過程。這個迭代過程包括生成多個推理路徑、基于不確定性進行篩選、生成搜索查詢以消除歧義,以及整合檢索到的搜索結果以獲得更準確的響應。
左側:自訓練與搜索
- Med - Gemini 模塊:接收指令(Instruction)、訓練問題(Train Questions) ,以及訓練問題對應的搜索結果(Search Results)。
- 生成推理響應:模型生成兩類推理響應(Chain of Thought, CoT),一類是無搜索的 CoT,另一類是有搜索的 CoT(CoT with search),每個 CoT 都對應一個答案(Answer)。
- 評分與篩選(Score & filter):對生成的推理響應進行評分和篩選,篩選后的結果進入微調循環(Fine - tuning loop),反饋給 Med - Gemini 模塊,用于進一步訓練模型,提升其利用外部信息得出準確答案的能力。
右側:推理時的不確定性引導搜索
- 初始輸入:Med - Gemini 模型接收指令(Instruction)、測試問題(Test Question)以及搜索結果(Search Results),生成多個推理路徑(CoT #1, CoT #2 等 ),每個推理路徑對應不同答案(如 Answer A、Answer B )。
- 置信度判斷:判斷模型對生成答案是否有足夠的置信度(Confident? )。
- 是(Yes):直接輸出推理路徑和對應的答案(如 CoT 和 Answer: A )。
- 否(No):進入不確定性引導搜索循環(Uncertainty - guided search loop) 。模型根據相互沖突的推理路徑生成搜索查詢(Generate search queries to resolve these conflicts),發送到網絡搜索(Web search)。網絡搜索返回補充上下文信息,如支持答案 A 的信息和反駁答案 B 的信息等,這些信息再反饋給 Med - Gemini 模型,繼續下一輪循環,直至模型對答案有足夠置信度 。
如圖2左面板所示,對于每個訓練問題,我們生成兩條推理路徑,即思維鏈:一條不訪問搜索中的外部信息,另一條在思維鏈生成過程中將搜索結果作為額外上下文進行整合。我們的搜索自訓練框架包含以下關鍵要素:
網絡搜索:對于每個問題,我們促使Med - Gemini - L 1.0生成有助于回答醫學問題的搜索查詢。然后,我們將搜索查詢傳遞給網絡搜索API并檢索搜索結果。
上下文示范:對于每種推理響應路徑類型,我們手動策劃五個具有準確臨床推理的專家示范作為種子,解釋為什么正確答案是最合適的,而不是其他可能有效的答案。對于有搜索結果的問題示例,示范明確引用并引用搜索結果中的有用信息,以最好地回答問題。
生成思維鏈:我們促使Med - Gemini - L 1.0使用訓練集上的上下文種子示范生成思維鏈。在對生成的思維鏈進行模型微調之前,我們過濾掉那些導致錯誤預測的思維鏈。
微調循環:在對生成的思維鏈進行Med - Gemini - L 1.0微調后,模型遵循專家示范的推理風格和搜索整合能力得到提高。然后,我們使用改進后的模型重新生成思維鏈,并迭代重復這個自訓練過程,直到模型性能達到飽和。
下面我們提供一個MedQA - RS的輸入提示示例,以及檢索到的搜索結果和一個生成的思維鏈示例,該思維鏈隨后用于進一步微調Med - Gemini - L 1.0。為簡潔起見,我們在下面的示例中僅顯示一個代表性的搜索結果我們設計了一種新穎的、基于不確定性引導的迭代搜索過程,以提高Med - Gemini - L 1.0在推理時的生成結果質量。
如圖2右面板所示,每次迭代包含四個步驟:多推理路徑生成、基于不確定性的搜索調用、不確定性引導的搜索查詢生成,以及最后的搜索檢索以擴充提示信息。需要注意的是,雖然推理時的不確定性引導搜索可能在多模態場景中也有益處,但我們目前僅將這種方法應用于純文本基準測試,多模態方面的探索留待未來研究。
1. 多推理路徑生成:給定一個包含醫學問題的輸入上下文提示,我們讓Med - Gemini - L 1.0生成多個推理路徑。在第一次迭代時,提示僅包含指令和問題。在后續迭代中,提示還包括下面步驟(4)中的搜索結果。
2. 基于不確定性的搜索調用:根據步驟(1)中生成的多個推理路徑,我們基于答案選擇分布的香農熵定義一個不確定性度量。具體來說,我們通過將每個答案選擇的出現次數除以總響應次數來計算其概率,并基于這些概率應用熵公式(Horvitz等人,1984)。高熵(模型響應在不同答案選擇中分布更均勻)表示較高的認知不確定性。如果一個問題的不確定性高于定義的閾值,我們就執行步驟(3)和(4)中的不確定性引導搜索過程;否則,將多數投票的答案作為最終答案返回。
3. 不確定性引導的搜索查詢生成:根據步驟(1)中相互沖突的響應,我們促使Med - Gemini - L 1.0生成三個有助于解決沖突的搜索查詢。我們基于先前生成但相互沖突的響應來生成查詢,目的是檢索能夠直接解決模型對該問題不確定性的搜索結果。
4. 搜索檢索:生成的查詢隨后被提交到網絡搜索引擎,檢索到的結果被整合到Med - Gemini - L 1.0的輸入提示中,用于下一次迭代,然后再回到步驟(1)。用搜索結果擴充提示信息,能使模型通過考慮從網絡搜索中獲得的外部相關見解來優化其響應。
?2.2 通過微調與定制編碼器實現多模態理解
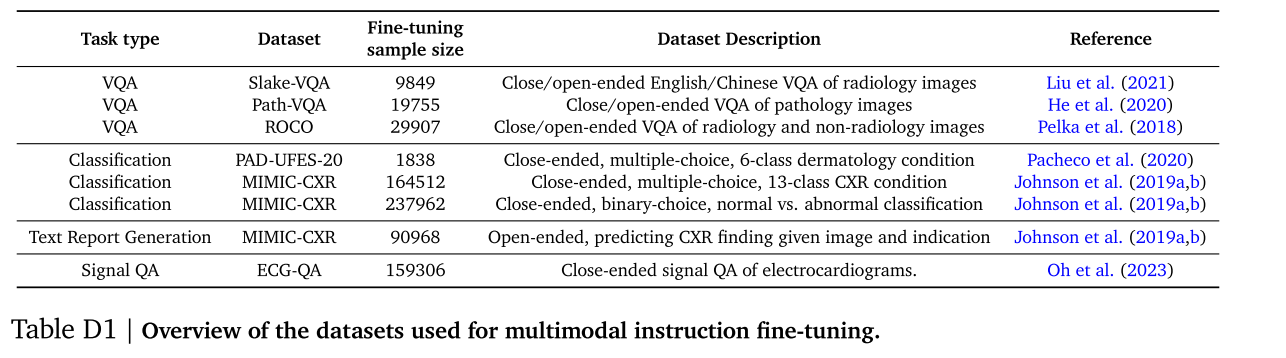
為了將Gemini的多模態推理和對話能力專門應用于醫學領域,我們按照Tu等人、Yu等人和Alayrac等人先前工作中的類似流程,在一系列特定領域的多模態任務上對Gemini進行指令微調。我們使用了六個數據集中的八個多模態任務,具體內容見表D1。附錄D.1中提供了數據集的詳細描述。
我們使用來自MultiMedBench的四個圖像到文本數據集,包括Slake - VQA、Path - VQA、MIMIC - CXR、PAD - UFES - 20,以及Radiology Objects in COntext(ROCO)數據集。Slake - VQA和Path - VQA分別包括放射學和病理學領域的開放式和封閉式視覺問答任務。ROCO包含跨越多種成像模態(包括計算機斷層掃描(CT)、超聲、X射線[胸部X射線(CXR)、熒光透視、乳腺攝影、血管造影]、正電子發射斷層掃描(PET)和磁共振成像(MRI))的放射學圖像字幕任務。PAD - UFES - 20是一個特定領域的數據集,具有診斷標簽和患者臨床信息,用于皮膚病圖像分類。MIMIC - CXR是一個放射學數據集,由胸部X射線、相應的文本報告以及一組使用CheXpert標注器得出的表示13種異常放射學狀況(如肺炎)的離散標簽組成。我們使用這個數據集來制定胸部X射線報告生成和圖像分類任務,用于微調。對于每個任務,我們通過提供特定任務的指令來微調Gemini 1.5 Pro,如圖D1所示。每個任務的混合比例大致與每個數據集中的訓練樣本數量成比例。最終得到的模型是Med - Gemini - M 1.5。
我們預計整合各種與健康相關的信號將顯著增強醫學模型和治療決策。這些信號包括來自消費級可穿戴設備的數據(例如長期心率測量、活動水平)、基因組信息、營養數據(例如餐食圖像)以及環境因素(例如空氣質量測量)。作為概念驗證,我們擴展了Med - Gemini處理原始生物醫學信號的能力。具體而言,我們通過使用基于Flamingo的交叉注意力機制為Gemini 1.0 Nano添加一個專門的編碼器,開發了Med - Gemini - S 1.0,使其能夠直接以原始12通道心電圖(ECG)波形作為輸入來回答問題。我們使用來自ECG - QA數據集的一部分帶標簽的ECG示例,并按照圖D1中的指令將任務制定為封閉式問答。
?2.3 通過指令提示與推理鏈實現長上下文處理
醫學領域的許多應用需要分析大量信息,并具備識別該領域細微細節的專業知識。如前所述,Gemini模型具有突破性的長上下文能力。我們通過為兩種不同的醫學應用有意義地處理大量細粒度信息,來評估Med - Gemini - M 1.5在醫學相關長上下文方面的性能:一個是從冗長的電子健康記錄(EHR)筆記和記錄中進行“大海撈針”式的檢索任務;另一個是需要理解醫學視頻的任務。我們描述了各種提示策略和推理鏈,以實現對信息的準確回憶和推理。
從長EHR筆記和記錄中搜索和檢索臨床相關信息是患者護理中一項常見且重要的任務,但必須以高精度和高召回率進行,以提高臨床醫生的工作效率并減少工作量。臨床醫生經常整理患者歷史病情、癥狀或手術的摘要(即“問題列表”),對于病歷冗長的患者來說,這既耗時又具有挑戰性。電子健康記錄中存在多個因素阻礙了有效信息檢索。
首先,經典的查詢擴展和匹配機制由于相似分類法的病癥之間的文本相似性以及電子健康記錄中使用的多樣化信息模型(例如“Miller”與“Miller Fisher綜合征”、“糖尿病腎病”與“糖尿病”)而受到限制。電子健康記錄系統內部和之間的詞匯不一致會帶來問題,包括醫學術語編碼方式的差異,如首字母縮寫(“rx”與“prescription”)、拼寫錯誤或同一病癥的同義詞。
其次,電子健康記錄通常包含異構數據結構,例如清單式數據模板:“[ ]咳嗽 [x]頭痛”,其中提及并不總是表示存在某種醫學病癥。第三,提及的上下文會影響其解釋。例如,在患者的“家族病史”和“既往病史”中提及相同病癥,可能對患者的護理有不同的解釋和影響。最后,醫學筆記中的多義首字母縮寫可能導致誤解。
這些挑戰促使需要人工智能系統來解決從長電子健康記錄中進行上下文感知檢索細微或罕見病癥、藥物或手術提及的任務,這是評估Med - Gemini在醫學領域實用性的一個實際基準。我們基于先前的工作設置了長上下文電子健康記錄理解任務,在該任務中,我們從MIMIC - III中精心挑選了一組長且具有挑戰性的電子健康記錄案例,并針對一系列電子健康記錄筆記和記錄,制定了一個關于細微醫學問題(病癥/癥狀/手術)的搜索檢索任務,模擬臨床上相關的“大海撈針”問題。附錄E.1和第3.3節中描述了數據集和任務策劃過程的詳細信息。
為了評估Med - Gemini - M 1.5的長上下文檢索和推理能力,我們在每個示例中聚合單個患者多次就診的電子健康記錄筆記,并利用模型的長上下文窗口,采用兩步推理鏈方法(僅使用上下文學習)。在第一步中,我們促使Med - Gemini - M 1.5通過一次示范檢索與給定問題(病癥/癥狀/手術)相關的所有提及(證據片段)。在第二步中,我們進一步促使Med - Gemini - M 1.5根據檢索到的提及來確定給定問題實體的存在與否。指令提示的詳細信息見圖8和第3.3節。

圖8| Med-Gemini-M 1.5在長EHR理解上的長上下文能力示例(MIMIC-III大海撈針)。Med-Gemini-M 1.5執行兩步流程,根據患者的大量EHR記錄確定患者是否有特定疾病史。(a)第1步(檢索):Med-Gemini-M 1.5識別EHR注釋中所有提及的“體溫過低”,提供直接引用[例如,“+汗。口腔溫度93.7.轉至重癥監護病房(MICU)"]并記錄每次提及的ID。(b)第2步(確定是否存在):Med-Gemini-M 1.5然后評估每個檢索到的提及的相關性,將其分類為明確確認、強烈指示或體溫過低的相關提及。基于此分析,模型得出結論,患者確實有體溫過低的歷史,為決策提供了清晰的推理。?
我們使用先前基于啟發式的注釋聚合方法作為與Med - Gemini - M 1.5進行比較的基線方法。這種基于啟發式的方法需要大量的手動特征工程,以從一組醫療記錄中確定問題(病癥/癥狀/手術)的存在。這是一個依賴本體的多步驟過程,包括一個注釋步驟,用于標記每個電子健康記錄筆記中的問題;一個基于規則的選擇步驟,用于選擇置信度高的問題實體提及;以及另一個基于規則的聚合步驟,用于匯總所有選定的問題提及以得出最終結論。需要注意的是,手動制定的聚合規則只能有限地覆蓋所有可能的病癥,因此需要額外的工程工作來將覆蓋范圍擴展到新的病癥。
為了策劃一個“大海撈針”式的評估基準,我們從電子健康記錄集合中選擇在聚合步驟中僅找到一個證據片段的醫學病癥。需要注意的是,電子健康記錄中提及某病癥并不總是意味著患者患有該病癥。這個任務使我們能夠評估Med - Gemini - M 1.5識別罕見記錄和細微病癥、癥狀和手術的能力,以及準確全面地推斷它們是否存在的能力。
對手術和操作視頻的理解是醫學人工智能領域一個非常活躍的研究課題。計算機視覺在語義分割、目標檢測與跟蹤以及動作分類方面的前沿進展,催生了新的臨床應用,如手術階段識別、工具檢測與跟蹤,甚至手術技能評估。
有限的模型上下文窗口阻礙了視覺語言模型捕捉視頻中的長程依賴關系和復雜關系。Gemini的長上下文能力為醫學視頻理解提供了潛在的突破。通過處理整個視頻輸入,Med - Gemini - M 1.5能夠識別視覺模式,并理解跨越較長時間框架的事件之間的動作和關系。
為了使Med - Gemini - M 1.5能夠理解醫學視頻,我們采用零樣本提示,并結合特定任務的指令,如圖10、圖9和圖11所示。目標是使模型能夠分析語言查詢和視頻內容,并執行與輸入醫學視頻相關的給定任務,即在醫學視覺答案定位(MVAL)任務中定位與查詢匹配的相關視覺片段,或在安全關鍵視圖(CVS)評估任務中識別視頻幀中的手術視圖。附錄E.1和第3.3節中描述了醫學視頻數據集和評估指標的更多詳細信息。

圖10| Med-Gemini-M 1.5在醫學教學視頻中的長上下文功能示例。Med-Gemini-M 1.5分析來自醫學視頻問答(MedVidQA)數據集的視頻,以回答有關緩解小腿勞損的特定問題。該模型識別相關的視頻片段(02:22-02:58),其中理療師解釋并演示針對該狀況的鍛煉。MedVidQA地面真實時間跨度注釋為02:22-03:00。
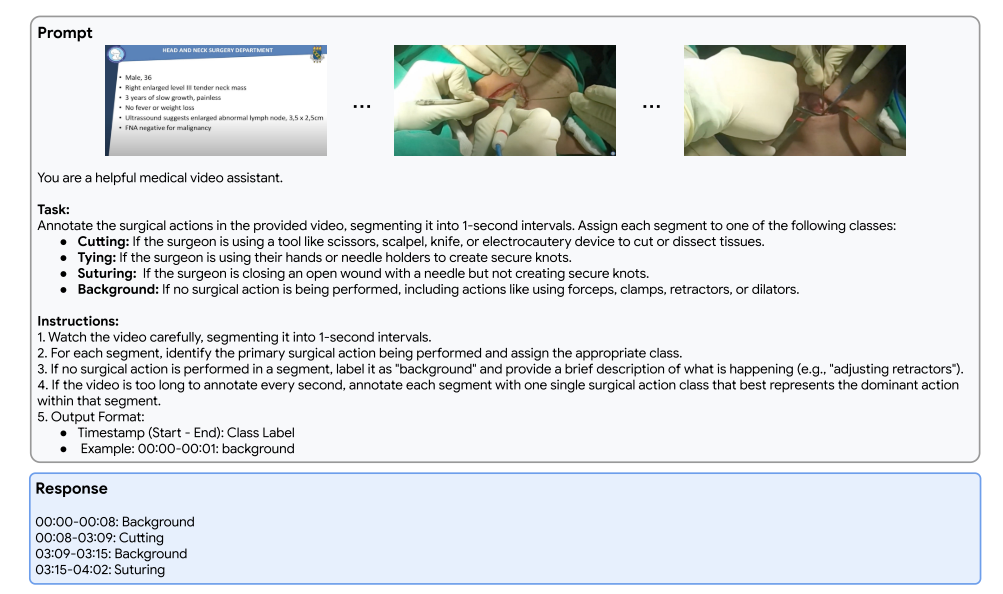
圖11| Med-Gemini-M 1.5在手術動作視頻跨度預測方面的長上下文能力示例。Med-Gemini-M 1.5分析來自手術動作識別(AVOS)數據集的視頻,以注釋視頻中的手術動作。它將視頻分段并基于正在執行的手術動作(例如,切割、打結、縫合),或者如果沒有動作發生,則將其分類為背景。本例的地面真實AVOS注釋為:00:00 - 00:11:背景,00:12 - 03:05:切割,03:05 - 03:15:背景,03:15 - 04:02:縫合。
?3 評估
我們展示了涵蓋(1)基于文本的推理、(2)多模態以及(3)長上下文處理任務的評估基準,展示了Med - Gemini在醫學領域廣泛能力的性能表現。
?3.1 基于文本任務的先進推理評估
我們在三個評估臨床推理和使用網絡搜索檢索信息以減少不確定性能力的文本基準上,評估Med - Gemini - L 1.0的醫學推理能力:
- MedQA(USMLE):這是一個封閉式多項選擇(4個選項)數據集,包含1273個由Jin等人整理的USMLE風格測試題。
- NEJM臨床病理會議(NEJM CPC):該數據集包含《新英格蘭醫學雜志》(NEJM)中的復雜診斷案例挑戰,由McDuff等人整理。
- GeneTuring:一個包含600個開放式/封閉式問答對的數據集,用于評估大語言模型的基因組知識(Hou和Ji,2023)。
對于MedQA,我們遵循Singhal等人描述的輸入 - 輸出格式和評估方法,使用預測準確率作為指標。在推理時,我們進行四輪不確定性引導搜索。此外,我們邀請美國的董事會認證初級保健醫生(PCPs)對MedQA測試集進行重新標注。這使我們能夠識別出缺少信息(如圖表或圖形)的問題、標注錯誤的問題,以及其他可能存在多個正確答案的模糊問題。總體而言,這有助于我們更好地描述我們在MedQA(USMLE)上的性能。關于這個評級任務的更多詳細信息,可以在附錄C.2中找到。
NEJM CPC評估是一個開放式診斷任務。輸入是一個基于文本的、具有挑戰性的臨床病理案例(CPC)報告,輸出是一個鑒別診斷列表,包含10個潛在診斷。我們使用識別給定具有挑戰性案例正確診斷的前1名和前10名準確率,并遵循McDuff等人的相同提示程序。在推理時,我們進行一輪不確定性引導搜索。
GeneTuring由12個模塊組成,每個模塊包含50個開放式或封閉式問答對。我們使用預測準確率作為評估指標,每個模塊的評估方法和評分技術遵循Hou和Ji中描述的方法。具體來說,我們在數值評估中排除模型輸出未直接回答或未承認局限性(即棄權)的情況。在推理時,我們同樣進行一輪不確定性引導搜索,與NEJM CPC評估類似。
除了這些基準測試,我們還在三個需要長篇文本生成的具有挑戰性的實際用例上進一步評估Med - Gemini - M 1.0。為此,我們進行了一項專家評估,由一組臨床醫生通過并排盲法偏好比較,將我們模型的響應與其他人類專家的響應進行比較(附錄C.4中提供了更多詳細信息):
- 醫學總結:根據去標識化的病史和體格檢查(H&P)筆記生成就診后總結(AVS)。AVS是患者在醫療預約結束時收到的結構化報告,用于總結和指導他們的治療過程。
- 轉診信生成:根據包含轉診建議的去標識化門診醫療筆記,生成轉診信給另一位醫療服務提供者。
- 醫學簡化:根據醫學系統評價的技術摘要生成通俗易懂的語言摘要(PLS)。PLS應該用通俗易懂的英語撰寫,大多數沒有大學教育背景的讀者都能理解。
?3.2 多模態能力評估
我們在七個多模態視覺問答(VQA)基準上評估Med - Gemini。對于分布內評估,我們選擇了在Med - Gemini指令微調中使用的四個醫學專科數據集:用于Med - Gemini M 1.5的PAD - UFES - 20(皮膚病學)、Slake - VQA(英語和中文放射學)和Path - VQA(病理學),以及用于Med - Gemini S 1.0的ECG - QA(心臟病學)。
我們還納入了三個跨專科基準,用于衡量Med - Gemini的開箱即用性能:NEJM圖像挑戰、USMLE - MM(多模態)和MMMU - HM(健康與醫學)數據集。這些數據集在任何訓練或微調過程中均未使用。在此,我們主要評估未進行任何多模態微調的Med - Gemini - L 1.0模型。
值得注意的是,PAD - UFES - 20、NEJM圖像挑戰、USMLE - MM數據集以及MMMU - HM中的大多數問題都是封閉式VQA,即在VQA設置中的多項選擇題。選定數據集的概述見表D2,附錄D.1和D.2中提供了更多詳細信息。
我們報告所有封閉式多項選擇VQA任務的預測準確率,包括NEJM圖像挑戰、USMLE - MM和PAD - UFES - 20的6類皮膚狀況分類。我們還遵循Yue等人的評估設置,報告MMMU - HM的準確率。對于ECG - QA,我們按照Oh等人的方法使用精確匹配準確率。對于開放式VQA任務(Slake - VQA和Path - VQA),我們按照Tu等人的方法使用標記級F1分數。
我們進一步在皮膚病學和放射學兩個專科的多模態醫學診斷對話中,通過專家臨床醫生對示例對話的定性評估,展示了Med - Gemini - M 1.5的多模態能力。我們注意到,這些展示表明了“可能實現的成果”,但在考慮將其部署用于像輔助臨床醫生診斷這樣對安全性要求極高的用例之前,還需要進行大量的進一步研究和驗證。
?3.3 視頻和EHR任務的長上下文能力評估
我們考慮三個任務來展示Med - Gemini - M 1.5無縫理解和推理長上下文醫學信息的能力(表E1,附錄E.1中有詳細信息):
- 長非結構化EHR筆記理解
- 醫學教學視頻問答
- 手術視頻的安全關鍵視圖(CVS)評估
對于長上下文電子健康記錄理解任務,我們策劃了一個MIMIC - III“大海撈針”任務,目標是在大量電子健康記錄臨床筆記中檢索任何提及給定醫學問題(病癥/癥狀/手術)的相關文本片段,并通過對檢索到的證據進行推理來確定該病癥的存在與否。具體而言,我們策劃了200個示例,每個示例由從44名具有長期病史的獨特ICU患者中選擇的一組去標識化電子健康記錄筆記組成,遵循以下標準:
記錄長的患者:超過100份醫療筆記(不包括結構化電子健康記錄數據)。每個示例的長度在200,000到700,000字之間。
在每個示例中,病癥在所有電子健康記錄筆記集合中僅被提及一次。
每個樣本有一個感興趣的單一病癥。
每個樣本的真實標簽是一個二進制變量,表示給定的感興趣問題實體是否存在,由三名醫生評分者的多數投票得出。在200個測試示例中,陽性案例和陰性案例的數量分別為121和79。
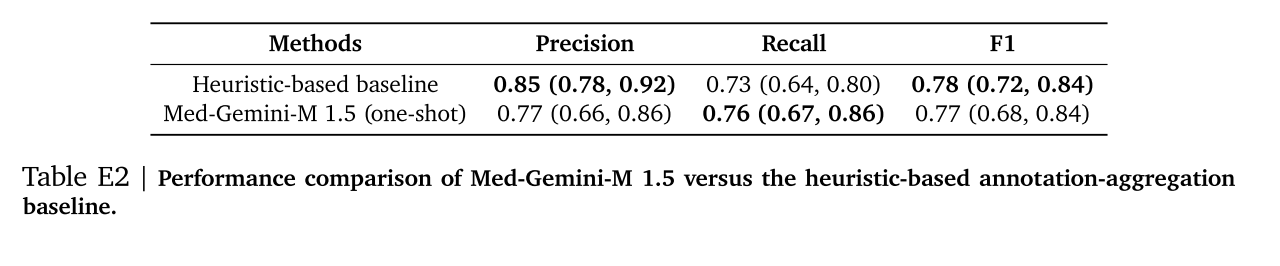
我們將Med - Gemini - M 1.5的一次性上下文學習性能與基于啟發式的注釋聚合基線方法在精度和召回率方面進行比較。
我們使用三個醫學視頻任務,在視頻問答設置中定量評估Med - Gemini - M 1.5的長上下文性能:兩個使用醫學教學視頻問答(MedVidQA)數據集的醫學視覺答案定位(MVAL)任務,以及在Cholec80 - CVS數據集上的安全關鍵視圖(CVS)評估任務。
MVAL的目標是根據自然語言描述(查詢)在給定視頻輸入中識別特定的視頻片段。對于MVAL,我們在MedVidQA測試集上對兩個視頻跨度預測任務進行基準測試,一個使用視頻輸入和字幕文本,另一個僅使用視頻輸入。我們遵循Gupta等人和Li等人的方法,使用閾值為0.3、0.5、0.7的交并比(IoU)和平均交并比(mIoU)作為視頻跨度預測任務的評估指標。IoU和mIoU用于衡量真實跨度與預測跨度的重疊程度。
我們評估Med - Gemini - M 1.5在評估腹腔鏡膽囊切除術(一種切除膽囊的微創手術)視頻中安全關鍵視圖(CVS)方法實現情況的長上下文能力。CVS是一種推薦的協議,用于安全識別膽囊管和膽囊動脈,以盡量減少膽管損傷(BDI)的風險,膽管損傷是一種嚴重的損傷,會導致術后發病率和死亡率上升、長期生存率降低以及對生活質量的影響。
我們在公開的Cholec80數據集和Cholec80 - CVS視頻剪輯注釋上評估CVS評估任務。具體來說,對于Cholec80數據集中的每個手術視頻,Cholec80 - CVS數據集提供了完整視頻內符合至少一個CVS標準的視頻剪輯注釋。
每個這樣的視頻剪輯針對三個CVS標準中的每一個都被標注為0、1或2分。給定視頻剪輯中的所有幀都被認為具有相同的注釋。我們評估模型根據整個視頻剪輯預測哪些CVS標準得到滿足的能力。
然后,我們計算模型答案相對于Cholec80 - CVS注釋在572個帶注釋視頻剪輯上的平均準確率。關于CVS任務的更多詳細信息可以在附錄E.1中找到。
此外,為了展示Med - Gemini - M 1.5在捕捉手術視頻中手術動作的實際能力,我們使用來自Annotated Videos of Open Surgery(AVOS)數據集的示例對手術動作識別任務進行定性評估,該數據集是一個上傳到YouTube平臺的開放手術視頻集合。
?4 結果
如前所述,我們在廣泛的醫學基準測試中對Med - Gemini的先進推理、多模態和長上下文能力進行了定量和定性評估。據我們所知,這項工作中考慮的任務范圍和多樣性是醫學大語言模型中最全面的。此外,我們對Med - Gemini的評估不僅限于模型能力的基準測試,還擴展到了反映現實世界實用性的任務,如醫學總結、多模態對話和手術視頻理解。
?4.1 Med - Gemini在基于文本的任務中展示了先進的推理能力
如表1所示,Med - Gemini - L 1.0在MedQA(USMLE)上的準確率達到91.1%,創造了新的最先進水平,比我們之前的Med - PaLM 2高出4.5%,比最近使用復雜、專門提示增強的GPT - 4(MedPrompt)高出0.9%。與MedPrompt不同,我們的原則性方法在不確定性引導的框架中利用通用網絡搜索,并且可以輕松擴展到MedQA之外的更復雜場景。
作為我們搜索集成泛化的證明,在NEJM CPC復雜診斷挑戰基準測試中,Med - Gemini - L 1.0在Top - 10準確率上比我們之前的最先進模型AMIE(其本身優于GPT - 4)高出13.2%,如圖3a所示。
同樣的搜索策略在基因組學知識任務中也很有效,如表1所示。Med - Gemini - L 1.0在包括基因名稱提取、基因別名、基因名稱轉換、基因位置、蛋白質編碼基因、基因本體和轉錄因子調控在內的七個GeneTuring模塊上優于Hou和Ji中報告的最先進模型。我們還在圖3b中比較了模型在12個模塊上的棄權情況。值得注意的是,GeneGPT通過專門的網絡API取得了更高的分數,而我們的比較主要集中在Hou和Ji中與我們模型類似使用通用網絡搜索的先前模型。
為了了解自訓練和不確定性引導搜索對性能的影響,我們比較了Med - Gemini - L 1.0在有和沒有自訓練情況下的性能,以及在MedQA(USMLE)中不同輪次不確定性引導搜索的性能。如圖4a所示,Med - Gemini - L 1.0的性能在自訓練后有顯著提升(準確率提高了3.2%),并且隨著搜索輪次的增加,從87.2%提高到了91.1%。同樣,對于NEJM CPC基準測試,圖3a顯示在推理時添加搜索后,Top - 10準確率提高了4.0%。在附錄C.3中,我們還按四個專科展示了NEJM CPC上的性能。
MedQA(USMLE)是評估大語言模型在醫學領域能力的一個流行基準。然而,一些MedQA測試問題存在信息缺失,如圖表或實驗室結果,以及可能過時的正確答案。為了解決這些問題,我們對MedQA(USMLE)測試集進行了全面重新標注。具體來說,我們招募了至少三名美國醫生對每個問題進行重新注釋,要求他們回答問題并評估提供的正確答案。我們還要求他們識別問題中是否有任何缺失信息。根據Stutz等人的方法,我們通過對每個問題由三名評分者組成的委員會進行投票引導,來確定由于信息缺失或標注錯誤而應排除的問題。我們還將允許多個正確答案的問題識別為模糊問題(更多細節可以在附錄C.2中找到)。
圖4b顯示,在投票引導的委員會中,平均有3.8%的問題存在信息缺失,這是根據委員會的一致投票得出的。此外,2.9%的問題可能存在標注錯誤。另有0.7%的問題是模糊的。排除這些問題得到了較高的評分者間一致性支持,分別為94%、87.6%和94.6%。重要的是,Med - Gemini - L 1.0的錯誤在很大程度上可以歸因于這些問題;我們基于熵的不確定性分數在這些問題上也往往更高(t檢驗,\(p值 = 0.033\))。過濾這兩種類型的問題后,準確率從91.1%提高到91.8%±0.2%。使用多數投票而不是一致投票,通過丟棄高達20.9%的不確定問題,進一步將準確率提高到92.9%±0.38%。
?4.1.1 長篇醫學文本生成的性能
Med - Gemini - M 1.0展示了為三個具有挑戰性的現實世界用例生成長篇文本的能力,即就診后臨床總結、醫生轉診信生成和醫學簡化。在并排比較中,臨床醫生評分者在超過一半的時間里認為Med - Gemini - M 1.0的回答與專家回答一樣好或更好,涵蓋這三個任務(圖5)。有關更多任務細節,請參見附錄C.4。值得注意的是,在轉診信生成任務中,模型生成的信件在所有評估樣本中都與專家的信件相當或更受青睞。
?4.2 Med - Gemini在各種任務中展示了多模態理解能力
我們的Med - Gemini模型在七個醫學多模態基準測試中優于或與最先進方法表現相當(見表2)。我們在圖D1中提供了多模態任務的代表性輸入和輸出示例以作說明。
具體來說,Med - Gemini - L 1.0在三個分布外封閉式VQA任務(NEJM圖像挑戰、多模態USMLE樣本問題(USMLE - MM)和MMMU(健康與醫學)子集(MMMU - HM))上達到了最先進水平,分別比GPT - 4V高出8.7%、13.1%和2.6%。同時,Med - Gemini - M 1.5在Path - VQA上的標記F1分數比我們之前的多模態模型Med - PaLM M高出2.0%,Med - Gemini - S 1.0在ECG - QA(Oh等人,2023)的心電圖問題類型上的宏觀平均準確率比之前的最先進模型(GPT - 4與SE - WR)高出6.1%。與之前的最先進方法(Med - PaLM M)相比,Med - Gemini - M 1.5在Slake - VQA和PAD - UFES - 20上也表現出色,但未達到最先進水平。
值得注意的是,我們在兩種不同的數據分割設置下評估了PAD - UFES - 20。我們首先在Med - PaLM M分割(圖像級分割)上進行評估,以便與之前的最先進方法進行直接、公平的比較。此外,我們還報告了模型在新的分割(患者級分割)上的性能(表2)。
對于USMLE - MM,我們的模型在USMLE第1步問題(\(n = 19\))、第2步問題(\(n = 14\))和第3步問題(\(n = 13\))上的準確率分別達到89.5%、92.9%和100.0%。
總體而言,在這七個基準測試中,Med - Gemini比GPT - 4V的平均相對優勢提高了44.5%。需要注意的是,對于USMLE - MM、PADS - UFES - 20和Slake - VQA數據集,我們使用公共API和用于相應Med - Gemini模型的相同提示來報告重現的GPT - 4V結果。
?4.2.1 多模態對話能力的預展示
為了超越多模態基準測試,我們通過兩個專科的假設性多模態醫學對話展示了Med - Gemini在未來現實世界中的潛在實用性。
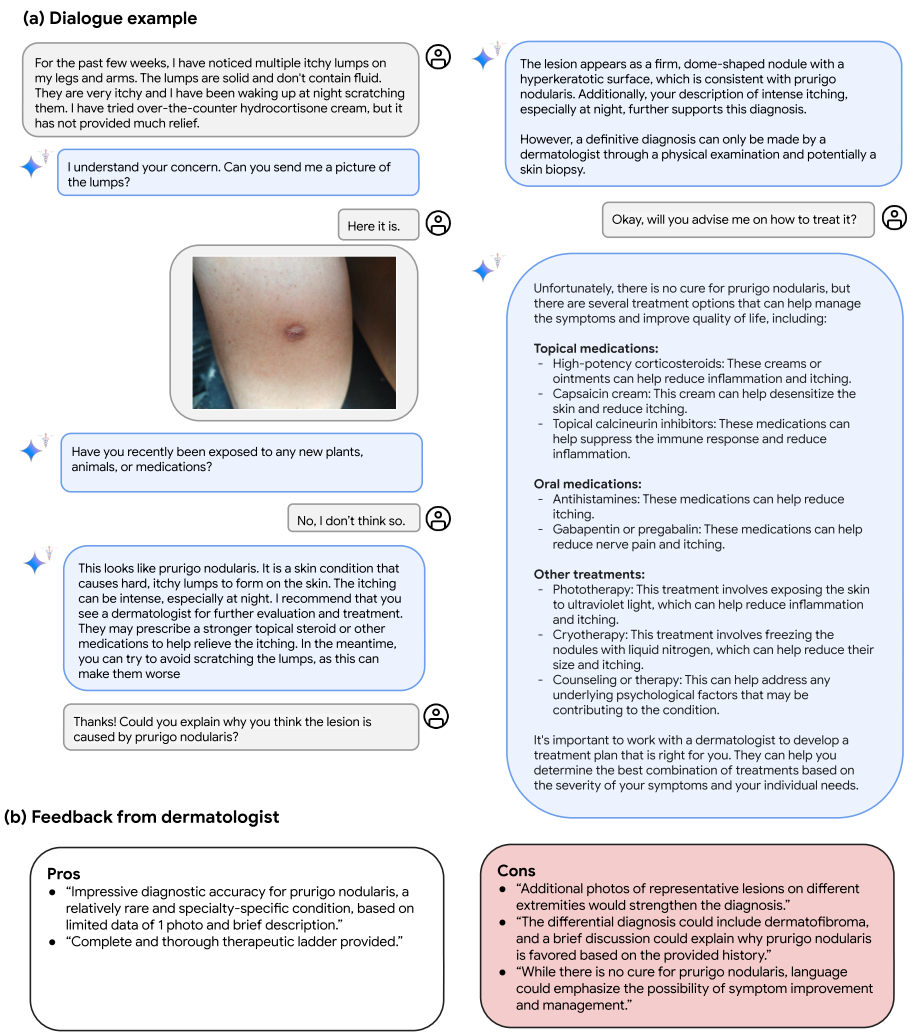
?圖6|在皮膚科環境中使用Med-Gemini-M 1.5進行假設多模式診斷對話的示例。(a)用戶與我們的多模式模型Med-Gemini-M 1.5交互,基于來自SCIN的病例充當患者(Ward等人,2024),不包括在微調混合物中的外部數據集。如果沒有大量的進一步研究和開發,該系統將不適合用于現實世界的診斷任務。盡管如此,這個例子表明了未來的初步承諾,如何從原始的雙子座模型繼承的會話能力和新獲得的多模態醫學知識的微調可以潛在地使豐富的多輪診斷對話的屬性。在這種互動中,Med-Gemini-M 1.5在沒有提供圖片時要求提供圖片(多模式信息采集),有效地得出正確的診斷(開放式診斷),通過整合相關視覺特征和其他收集的患者癥狀(可解釋性)來解釋推理,回答有關治療方案的問題,同時適當地推遲專家的最終決定。(b)顯示從皮膚科醫生收集的反饋,以評估定性的診斷對話的內容,特別是要求他們對積極和消極方面的評論。
圖6展示了一個分布外的場景,其中皮膚病學圖像來自一個未在多模態微調混合數據集中使用的數據集。用戶首先向Med - Gemini - M 1.5詢問腿部和手臂上的瘙癢腫塊;我們的模型隨后要求用戶分享腫塊的圖像;在用戶提供可疑病變的圖像后,模型提出后續問題,并繼續正確診斷為結節性癢疹,并推薦下一步措施和潛在的治療方案。
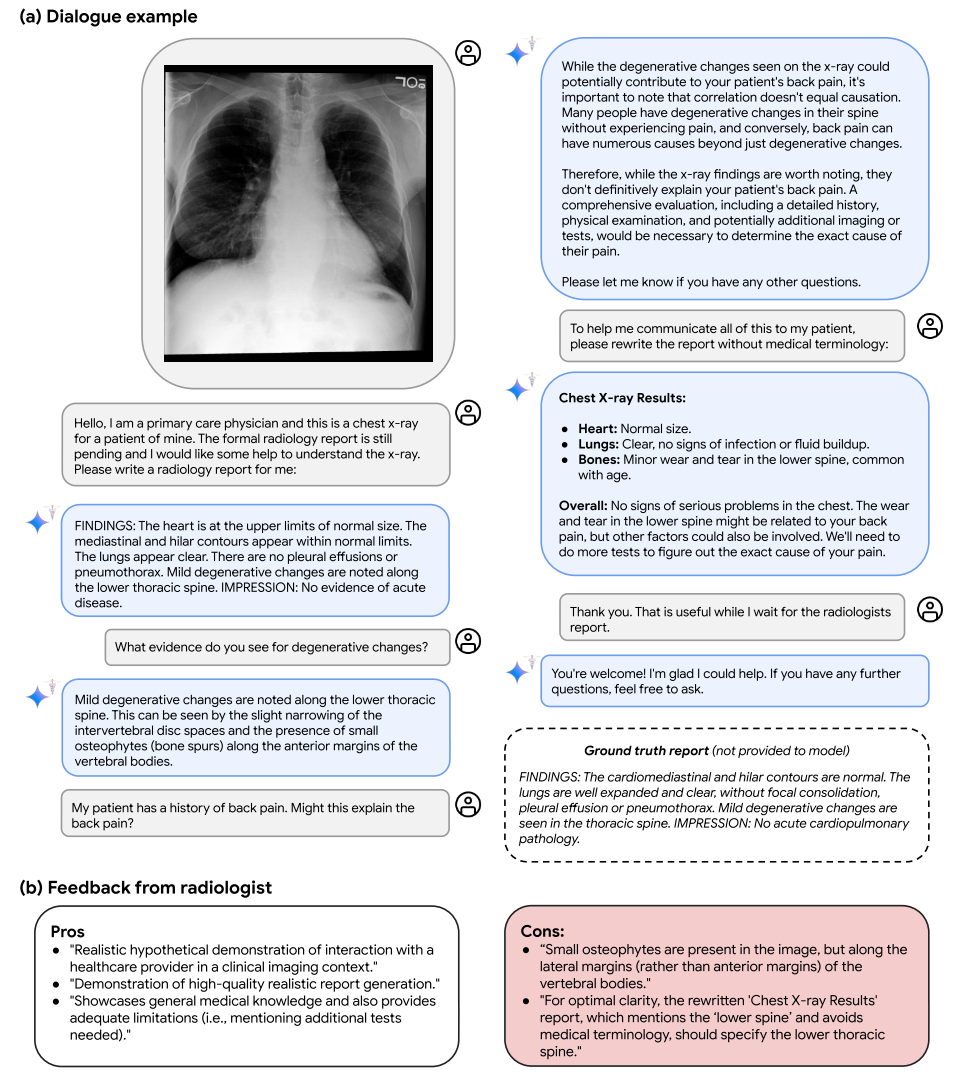
圖7|在放射學設置中與Med-Gemini-M 1.5進行假設的多模式診斷輔助對話的示例。(a)在這種互動中,Med-Gemini-M 1.5展示了其分析胸部X射線(CXR)并與初級保健醫生進行假設現實對話的能力。如上所述,Med-Gemini-M 1.5不適合在未經進一步研究的情況下實際使用。然而,該實施例證明了最初的希望,其中Med-Gemini-M 1.5識別沿著脊柱的輕度退行性變化沿著,并且可以回答關于導致該發現的推理的問題,證明關于退行性椎間盤疾病的一般醫學知識,并且區分與患者背痛史相關的相關性和因果關系。最后,在本例中,Med-Gemini-M 1.5能夠以外行的語言解釋其發現,證明其在臨床環境中促進患者理解和溝通的潛力。提供了本CXR的基礎事實報告。(b)來自放射科醫師的關于該放射學對話質量的反饋。
在圖7中,我們展示了一個放射學對話示例,示例圖像來自MIMIC - CXR數據集的測試集。Med - Gemini - M 1.5展示了與初級保健提供者互動以分析胸部X射線、識別退行性椎間盤疾病、討論與患者背痛病史之間的因果關系和相關性、建議進一步檢查以確定背痛原因,并使用通俗易懂的語言生成報告以促進患者理解和溝通的能力。我們觀察到Med - Gemini - M 1.5的回答會因提示而異(例如,對于某些提示,報告可能不會列出輕微的退行性變化,特別是如果提示關注其他解剖特征)。對Med - Gemini - M 1.5多模態對話能力和可變性的全面量化超出了本工作的范圍,但這些定性示例仍然說明了Med - Gemini - M 1.5支持基于多模態來源的醫學知識對話的能力,這對于考慮用戶 - AI和臨床醫生 - AI交互的應用來說是一個潛在有用的屬性。對這些用例的現實世界探索需要大量的進一步開發和驗證,以基于這些早期有前景的跡象進行拓展。
?4.3 Med - Gemini在長EHR和視頻任務中展示了長上下文處理能力
最后,我們通過從長EHR中進行“大海撈針”式的醫學病癥檢索任務以及三個醫學視頻任務(兩個MAVL和一個手術視頻的CVS評估)評估Med - Gemini - M 1.5的長上下文能力。
我們展示了Med - Gemini - M 1.5在長EHR筆記中正確識別罕見和細微問題實體(病癥/癥狀/手術)的實用性。Med - Gemini - M 1.5與基線方法之間的平均精度和召回率如表3所示(置信區間見表E2)。令人鼓舞的是,我們觀察到Med - Gemini - M 1.5的一次性能力與經過精心調整的、高度依賴任務的基于啟發式的注釋聚合基線方法相當。Med - Gemini - M 1.5處理長文檔或記錄的上下文學習能力可以輕松推廣到新的問題場景,而無需大量的手動工程。我們在圖8中提供了使用的提示示例以及我們模型的響應。我們嘗試在這個任務上對GPT - 4進行基準測試,但該數據集中的平均上下文令牌長度遠遠超過了公共API支持的最大上下文窗口。
Med - Gemini - M 1.5在兩個MedVidQA MAVL任務(一個同時使用視頻和字幕,另一個僅使用視頻)上也達到了最先進的性能,優于需要大量定制調整的非大語言模型的最先進模型。我們注意到MedVidQA中有7個問題由于YouTube視頻訪問問題(私人視頻、已刪除視頻)無法回答。因此,我們的結果是基于其余148個問題報告的。詳細信息見表3。我們在圖10中提供了使用的提示示例以及我們模型的響應。在評估MedVidQA時,我們還觀察到嵌入的字幕可以顯著幫助模型理解。未來的研究可以探索如何優化使用多模態視頻數據,包括圖像、文本和音頻,以進一步提高視頻理解能力。我們嘗試在這些任務上對GPT - 4V進行基準測試,但再次遇到了大多數視頻使用公共API時的上下文長度限制。
對于腹腔鏡膽囊切除術視頻的CVS評估任務,Med - Gemini - M 1.5比GPT - 4V高出21%。然而,我們觀察到使用ResNet3D架構的監督基線表現更好。可能需要進一步研究提示策略或指令微調,以提高我們模型在該任務上的性能。我們在圖9中提供了使用的提示示例以及我們模型的響應。
?4.3.1 長上下文能力在生物醫學中的應用
除了定量結果,我們還進一步預展示了長上下文能力在醫學教育、促進臨床醫生與EHR系統交互以及生物醫學文獻回顧和總結方面的潛力。
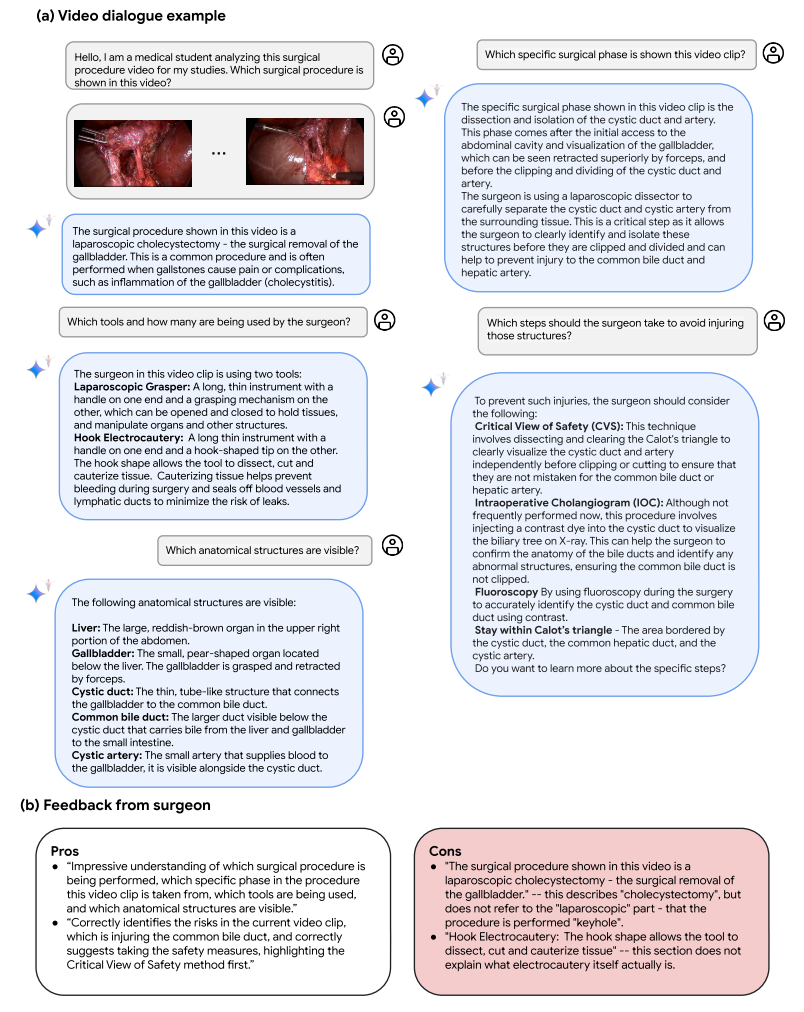
圖12| Med-Gemini-M 1.5在手術視頻對話方面的長上下文功能示例。Med-Gemini-M 1.5分析了來自Cholec 80數據集的視頻剪輯,包括腹腔鏡膽囊切除術(切除膽囊的鎖孔手術)的鏡頭。該模型展示了其分析視頻的能力,并與學習該過程的學生進行逼真的對話。
在圖11中,我們定性地預展示了Med - Gemini - M 1.5從AVOS數據集中的視頻識別手術動作的能力。這種能力在手術護理方面具有潛力,有望通過自動評估來增強手術培訓,通過分析工作流程來優化手術室效率,并可能在復雜手術過程中實時指導外科醫生,以提高準確性和患者預后。在圖12中,我們還展示了Med - Gemini -M 1.5在手術視頻對話中的長上下文能力示例,模型分析了一段來自腹腔鏡膽囊切除術的視頻片段。Med - Gemini - M 1.5展示了分析視頻并與可能正在學習該手術的學生進行對話的能力。這些有前景的能力有可能為臨床醫生提供有用的輔助工具,也許可以通過教育輔助或手術過程中的自動輔助和指導來提高患者安全性或增強醫學培訓過程。模型正確告知用戶他們正在觀察的是腹腔鏡膽囊切除術,并正確提及了“安全關鍵視圖”背后的關鍵結構。這些分類任務如果能夠大規模高精度地執行,可能能夠實現更好的手術審計(例如用于質量保證),甚至通過預測手術階段來提高前瞻性效率。對于更宏偉的目標,如對教育、手術指導或患者安全的益處,需要進行大量進一步的工作來評估更細微和復雜的能力。例如,我們沒有測試Med - Gemini準確分割或突出視頻中的物理結構并將對話與相關解剖結構聯系起來的能力;或者檢索和展示有用的教育資源,如圖解顯示的解剖結構或關鍵手術階段指南。對于像教育這樣的用途,教學對話目標可能也非常重要。進一步的工作應該在更廣泛的手術視頻場景中探索這些和其他令人興奮的新能力,手術視頻在醫學中越來越普遍。
在圖13中,我們展示了Med - Gemini - M 1.5有效地解析大量醫療記錄,將其綜合為清晰、簡潔的當前和歷史病癥總結的能力。此外,用戶可以基于這個總結數據發起對話,請求從記錄中獲取更詳細的信息。我們的示例展示了用戶如何進行自然語言查詢,詢問特定病癥(如肺炎)或相關診斷結果(如胸部X射線結果)。通過簡化對長篇醫學數據的訪問并以對話界面呈現交互,這種能力有可能顯著減輕臨床醫生和患者的認知負擔,在不影響工作人員福祉的情況下,潛在地提高對復雜醫學信息的理解和效率。要在現實世界中實現這種潛力,需要進行大量額外的評估和研究。僅舉一個例子,有必要仔細檢查從實際內容中檢索或生成的臨床顯著錯誤的發生率;并積極測量和減輕數據集和模型偏差問題(如我們在下面進一步討論的)。
在圖14中,我們展示了Med - Gemini - M 1.5處理多篇關于特定基因座(FTO)及其與肥胖關聯的研究文章的能力。在這個現實世界的應用中,Med - Gemini - M 1.5成功理解了當前研究中呈現的信息(12篇預先整理的便攜式文檔格式研究論文的完整內容),并為用戶編制了一個簡潔的總結。我們在這個示例中展示的FTO基因座(FTO基因內與BMI和肥胖相關的變異區域)是一個經典的全基因組關聯研究(GWAS)發現的機制理解案例。在這個例子中,其機制是一個相對復雜的多步驟過程,經過大量研究才確定——它涉及變異改變FTO基因內含子超增強子區域內轉錄抑制因子的結合,從而導致另外兩個基因的過表達,最終促進脂質積累。
我們評估Med - Gemini - M 1.5解析大量關于FTO基因座的學術論文,并提供FTO與肥胖之間機制聯系的簡潔易懂描述以及具體支持實驗結果列表的能力。如圖14所示,模型提供了關于FTO基因座如何促進肥胖生物學的簡潔、信息豐富且準確的描述,并以清晰易懂的方式呈現。模型可以通過列出與rs1421085處于高連鎖不平衡狀態的其他研究充分的變異,以及提供每條信息的來源參考來進一步改進。這個例子展示了Med - Gemini - M 1.5的長上下文能力如何有明顯的潛力減輕基因組研究人員和臨床醫生的認知負擔,增強他們對基因 - 疾病關聯最新發現的獲取;并且這種潛力在生物醫學和科學研究的其他領域也具有廣泛的相關性。
?討論
基于Gemini模型構建的Med - Gemini在醫學領域的臨床推理、多模態理解和長上下文處理方面展示了顯著的進展。這體現在它在涵蓋醫學知識、臨床推理、基因組學、波形、醫學成像、健康記錄和視頻的14個醫學基準測試的25個任務中的強勁表現。
值得注意的是,Med - Gemini - L 1.0在MedQA(USMLE)上使用基于自訓練的微調與搜索集成,達到了新的最先進水平。我們由主治臨床醫生對MedQA測試集進行的全面重新標注揭示了重要的見解。雖然MedQA(USMLE)是評估醫學知識和推理的有用基準,但必須認識到它的局限性。我們發現大約4%的問題包含缺失信息,另外3%可能存在標注錯誤。在醫學領域,建立明確的正確答案通常具有挑戰性,因為讀者間的差異和模糊性很常見,而且醫學知識也在不斷發展。我們的觀察表明,僅在MedQA(USMLE)基準上進一步提高最先進性能,可能并不直接等同于醫學大語言模型在有意義的現實世界任務中的能力進步。因此,進行更全面的、能代表現實世界臨床工作流程的基準測試和評估非常重要。一般來說,大多數基準測試在數據集大小和質量方面都存在局限性。雖然我們在此處主要分析MedQA(USMLE),但先前的研究表明其他流行的基準測試數據集也存在類似問題。用PAD - UFES - 20皮膚病數據集的新分割重新訓練Med - Gemini - M 1.5,與我們在表2中的結果相比,性能下降了7.1%。因此,在解釋和關聯模型性能時,需要仔細關注數據集的大小和質量。
Med - Gemini與網絡搜索的集成,為大語言模型在醫學查詢中提供更符合事實、可靠的答案帶來了令人期待的可能性。在這項工作中,我們專注于訓練Med - Gemini - L 1.0,使其在不確定時發出網絡搜索查詢,并在生成響應時整合結果。雖然在MedQA、NEJM CPC和GeneTuring基準測試中的結果很有前景,但仍需要進行大量進一步的研究。例如,我們尚未考慮將搜索結果限制在更權威的醫學來源,也未使用多模態搜索檢索,或對搜索結果的準確性、相關性以及引用質量進行分析。此外,較小的大語言模型是否也能學會利用網絡搜索,還有待觀察。我們將這些探索留待未來的工作。
Med - Gemini - M 1.5的多模態對話能力很有前景,因為它是在沒有任何特定醫學對話微調的情況下獲得的。這種能力使得人們、臨床醫生和人工智能系統之間能夠進行無縫、自然的交互。正如我們的定性示例所示,Med - Gemini - M 1.5有能力參與多輪臨床對話,在需要時請求額外信息(如圖像),以易懂的方式解釋其推理過程,甚至在適當將最終決策交給人類專家的同時,幫助提供對臨床決策有用的信息。這種能力在現實世界的應用中具有巨大潛力,包括輔助臨床醫生和患者,但當然也伴隨著非常重大的相關風險。雖然我們強調了該領域未來研究的潛力,但在這項工作中,我們并未像其他人在專門針對對話式診斷人工智能的研究中那樣,對臨床對話能力進行嚴格的基準測試。此外,在未來的工作中,我們還將嚴格探索Gemini在臨床特定多模態任務(如放射學報告生成)中的能力。
也許Med - Gemini最值得注意的方面是其長上下文處理能力,因為它為醫學人工智能系統開辟了新的性能前沿,以及以前無法實現的新穎應用可能性。在這項工作中,我們引入了一個新的電子健康記錄任務,專注于在非常長的電子患者記錄中識別和驗證病癥、癥狀和手術。這個“大海撈針”式的檢索任務反映了臨床醫生在現實世界中面臨的挑戰,Med - Gemini - M 1.5的性能表明,它有潛力通過從大量患者數據中高效提取和分析關鍵信息,顯著減輕認知負擔并增強臨床醫生的能力。醫學視頻問答和注釋的性能表明,這些能力可以推廣到復雜的多模態數據。值得強調的是,長上下文能力的展示是在少樣本的方式下進行的,沒有任何特定任務的微調。這種能力為基因組和多組學序列數據的精細分析和注釋、病理或體積圖像等復雜成像模態的分析,以及與健康記錄的綜合處理以揭示新見解和輔助臨床工作流程開辟了可能性。
Gemini模型本質上是多模態的,并且由于大規模多模態預訓練而擁有強大的醫學知識。這體現在它在多模態基準測試(如NEJM圖像挑戰)中令人印象深刻的開箱即用性能上,比類似的通用視覺語言模型(如GPT - 4V)有很大優勢。同時,醫學知識和數據(特別是多模態數據)是獨特而復雜的,不太可能在用于訓練大語言模型的公共互聯網上常見。Gemini是一個強大的智能基礎,但在醫學領域使用之前,即使是這樣強大的模型也需要進一步的微調、專門化和校準。同時,鑒于Gemini的通用能力,進行這種專門化和校準所需的數據量比前一代醫學人工智能系統要少得多,并且正如本文所示,確實有可能相對高效地使這些模型適應以前未見過但很重要的醫學模態(如心電圖)。
據我們所知,這項工作是對醫學大語言模型和大多模態模型最全面的評估。該工作包括醫學人工智能新能力的證據,以及表明現實世界實用性的任務。我們的模型在醫學總結和轉診信生成評估中的強勁表現尤其強化了這一點。診斷任務在研究中備受關注,但在安全可行地實際應用之前,需要解決重大的監管、臨床和公平相關風險。
因此,醫療保健領域中生成式人工智能更常見的現實世界用例是非診斷任務,在這些任務中錯誤的風險較低,但模型輸出可以通過減輕行政負擔和輔助日常工作中所需的復雜信息檢索或合成,顯著提高醫療服務提供者的效率。同時,即使對于這些非診斷任務,要確保現實世界的影響,也需要基于特定用例和環境進行評估。這些評估超出了初始基準測試的范圍,我們的結果應謹慎解讀。
為了評估我們在此展示的前景在現實世界臨床工作流程中的下游影響和泛化性,從業者應遵循負責任人工智能的最佳實踐,在預期環境中嚴格測量包括公平性、公正性和安全性在內的多個指標,同時考慮特定用例的多種社會技術因素,這些因素是影響的決定因素。最后,值得注意的是,雖然我們在本研究中考慮了14個多樣且具有挑戰性的基準測試,但社區中現有超過350個醫學基準測試。
我們的工作主要集中在Gemini模型的能力、改進以及其在可能實現的方面。未來探索的一個重要焦點是在整個模型開發過程中整合負責任人工智能的原則,包括但不限于公平、隱私、平等、透明和問責原則。隱私考慮尤其需要植根于現有的管理和保護患者信息的醫療政策和法規中。公平性是另一個需要關注的領域,因為醫療保健領域的人工智能系統存在無意反映或放大歷史偏見和不平等的風險,這可能導致模型性能的差異,并對邊緣化群體產生有害結果。這種健康不平等現象在性別、種族、民族、社會經濟地位、性取向、年齡以及其他敏感和/或受保護的個人特征方面都有體現。越來越需要對影響進行深入的交叉分析,盡管這仍然是一個棘手的技術問題,也是一個活躍的研究領域。
當我們展示大語言模型和大多模態模型的新能力時,在數據集偏差、模型偏差以及特定用例的社會技術考慮的交匯處,也出現了潛在問題的新機會。在我們討論的能力背景下,這些問題可能潛在地出現在長上下文利用中可能存在偏差的示例和指令的上下文學習、搜索集成、自訓練的動態過程,或多模態理解中的微調與定制數據編碼器中。在這些能力的每一個方面,都可能有多個需要考慮偏差的點。在網絡搜索集成方面,偏差可能在查詢構建時出現,反映在返回的結果集中,或嵌入在每個鏈接的外部來源中,并以各種其他微妙的方式表現出來,例如在生成最終答案時,結果如何整合到生成推理過程中。對于多模態模型,偏差可能分別出現在每個單獨的模態中,或者僅在數據的相互依賴模態中共同顯現。對潛在問題的全面分析可能需要分別考慮每個點,但也需要從整體上考慮,因為它們都是復雜系統的一部分。這些系統不僅需要單獨進行徹底評估,還需要在有人工專家參與的情況下進行評估。
然而,這些新能力也為減輕先前的問題并顯著提高不同用例的可及性提供了機會。例如,醫學領域新的長上下文能力可能使模型的用戶在推理時無需進行模型微調即可解決復雜問題,因為數據可以直接在查詢上下文中使用,然后跟隨一組自然語言指令。以前,此類系統的用戶需要具備工程專業知識,并投入額外的時間和資源來微調定制模型以處理這些復雜任務。另一方面,網絡搜索集成在快速整合新開發的醫學知識以及關于高度動態和非靜態醫學領域的外部共識方面可能被證明是非常寶貴的。COVID - 19大流行表明,公共衛生理解和建議可能需要多么迅速地更新,它也凸顯了醫學錯誤信息帶來的總體危險。能夠可靠地獲取最新權威外部來源信息的模型,不太可能導致此類錯誤信息。其他模型能力也帶來了類似的新機會,不過需要進一步研究來開發一個強大的評估框架,以評估偏差和不公平輸出的相關風險,這種評估需要在特定臨床用例的實際環境中從社會技術角度進行。
結論
大多模態語言模型正在為健康和醫學領域開創一個充滿可能性的新時代。Gemini和Med - Gemini展示的能力表明,在加速生物醫學發現、輔助醫療服務提供和改善醫療體驗方面,機會的深度和廣度都有了顯著的提升。然而,至關重要的是,在模型能力取得進展的同時,要密切關注這些系統的可靠性和安全性。通過同時重視這兩個方面,我們可以負責任地展望未來,讓人工智能系統的能力成為醫學科學進步和醫療服務的有意義且安全的加速器。
數據可用性
除了三個臨床抽象任務外,用于人工智能系統開發、基準測試和評估的其余數據集均為開源數據,或在獲得許可后可公開訪問。我們將公開我們對MedQA(USMLE)數據集的重新注釋。
代碼可用性
由于在醫療環境中不受監控地使用此類系統存在安全隱患,我們不會開源模型代碼和權重。出于負責任創新的考慮,我們將與研究合作伙伴、監管機構和供應商合作,驗證并探索我們醫學模型的安全后續用途,并期望在適當的時候通過谷歌云API提供這些模型。
利益沖突
本研究由Alphabet Inc和 / 或其附屬公司(“Alphabet”)資助。所有作者均為(或曾經是)Alphabet的員工,可能持有作為標準薪酬一部分的股票。
附錄
A 圖1 的補充
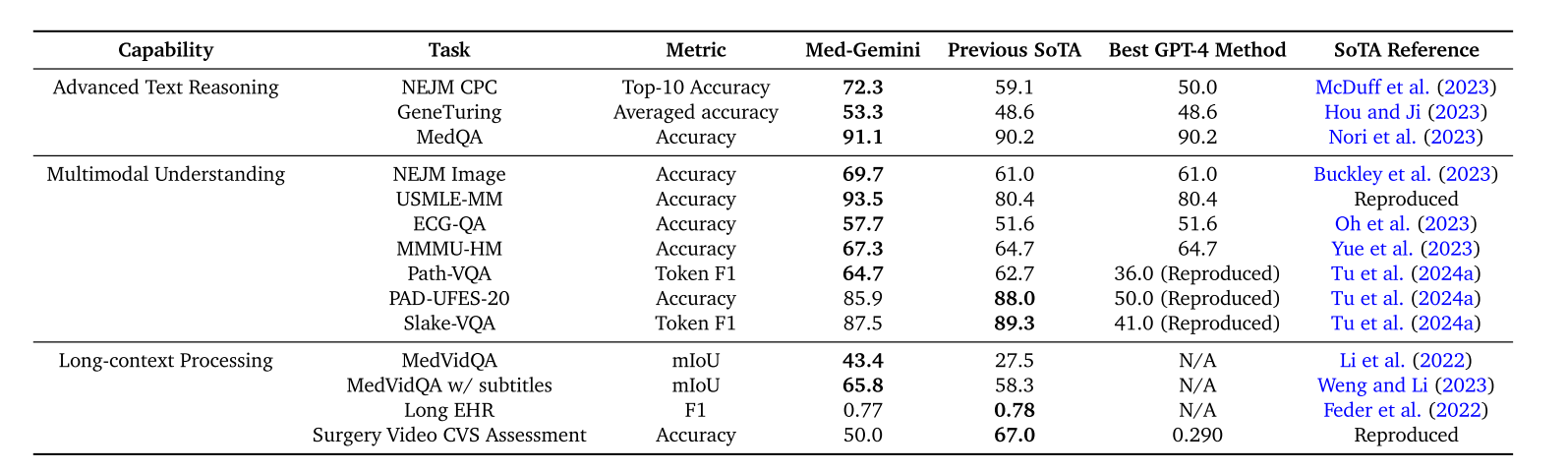
表 A1 | 圖 1 條形圖的性能結果。我們展示了綜合結果,對比了 Med - Gemini 與先前的最先進(SoTA)方法以及 GPT - 4 系列最佳方法在基于文本的任務、多模態任務和長上下文任務中的表現。對于在文獻中找不到 GPT - 4(或 GPT - 4V)報告數據的基準測試,我們使用公共 API 在相同的測試集上進行評估,以進行直接對比,采用與相應 Med - Gemini 模型相同的少樣本提示,包括確保輸出格式正確的指令。請注意,由于公共 GPT - 4 / GPT - 4V API 上下文窗口的限制,三個長上下文任務的 GPT - 4 結果不可用(N/A)。
?
B.相關工作
醫學領域大語言模型綜述
大語言模型(LLMs)徹底改變了機器學習和人工智能領域。研究人員采用了新穎的網絡架構,如 Transformer(Vaswani 等人,2017)和 Pathways(Barham 等人,2022),在大規模數據集上訓練這些模型。這種跨不同領域的自監督訓練涵蓋了多種模型,像 BERT(Devlin 等人,2018)、GPT(Radford 等人,2018)、T5(Raffel 等人,2020)、FLAN(Wei 等人,2021)、BLOOM(Le Scao 等人,2022)、Flamingo(Alayrac 等人,2022)、PaLM 和 PaLM2(Anil 等人,2023;Chowdhery 等人,2023)、LLaMA(Touvron 等人,2023)、PaLI(Chen 等人,2022)、PaLM-E(Driess 等人,2023),以及最近的 Gemini 模型(Gemini 團隊,谷歌,2023 年、2024 年)。通過處理文本或多模態信息,這些預訓練模型對語言、模式和關系有了強大的理解能力,并且具有出色的適應性。
只需進行少量微調,這些模型就能適應各種下游任務。在醫學領域,Med - PaLM(Singhal 等人,2023a)和 Med - PaLM 2(Singhal 等人,2023b)是具有開創性的醫學大語言模型,它們在電子健康記錄、考試問題和研究文獻上進行了微調。為了實現通用醫學人工智能(GMAI)的目標(Moor 等人,2023a),研究人員使用通用大語言模型并結合提示策略(例如,GPT - 4 搭配 Medprompt,Nori 等人,2023),或者用多模態數據對其進行優化,以增強醫學理解能力(例如,Med - PaLM - M,Tu 等人,2024a)。這些模型在診斷輔助(McDuff 等人,2023)、風險預測、藥物發現、診斷對話(Tu 等人,2024b)和評估精神功能(Galatzer - Levy 等人,2023)等方面展現出了潛力。我們的工作利用了最新的 Gemini 模型,通過直接指令提示或進一步微調,使其適用于專門的醫學任務。下面,我們將討論語言、多模態學習和長上下文建模等領域的相關工作。
基于語言任務的模型推理與工具使用
推理是一個邏輯思維過程,最終得出結論。最近大語言模型和大多模態模型(LMMs)的進展顯著提升了推理能力。這些改進源于更好的模型和直接模仿人類推理的方法的結合。之前的研究已經對基于語言模型的推理技術進行了綜述(Huang 和 Chang,2023;Qiao 等人,2023),并且這種綜述已經擴展到多模態推理領域(Wang 等人,2024)。增強語言推理的策略包括提示工程、改進流程,以及通過獲取外部元素(如工具或知識)來提升推理能力。提示工程的例子有思維鏈(CoT)提示(Wei 等人,2022),它涉及生成一系列中間推理步驟;還有從最少到最多提示法,即把一個問題分解成較小的子問題,然后依次解決(Zhou 等人,2023);以及其他探索不同推理路徑以得出結論的方法(Besta 等人,2024;Yao 等人,2023)。改進流程的方法包括通過自我改進進行模型更新(Zelikman 等人,2022)或基于集成的方法(Wang 等人,2022b)。
通過使用檢索增強生成(RAG)(Gao 等人,2024;Zhang 等人,2024)來獲取外部元素(如工具(Hao 等人,2024;Schick 等人,2024)或外部知識庫),也證明了可以提升語言模型的推理能力。最近,大語言模型還發展出了與信息和網絡工具交互的能力。在工具使用方面,大語言模型可以學習執行外部工具或應用程序編程接口(APIs),使其能夠在現實世界中執行諸如搜索、使用日歷或通過 API 使用翻譯服務等操作(Qin 等人,2023;Schick 等人,2024)。具體到網絡搜索,大語言模型通過理解復雜查詢并提供綜合多個來源信息的摘要,整合了傳統搜索引擎(Nakano 等人,2021;Varshney 等人,2023)。此外,大語言模型不僅能夠檢索信息,還能利用工具并根據用戶定義的需求創建工具(Cai 等人,2023)。Zakka 等人(2024)已經證明,在醫學指南和治療建議中,搜索工具的使用特別有用。在這項工作中,我們整合了搜索自訓練策略,以提高 Med - Gemini 的模型推理能力。
醫學領域的大多模態模型
醫療實踐通常需要整合多種模態的數據來提供有效的醫療服務,例如,整合來自患者病史、醫學成像、基因檢測和實驗室結果的數據。能夠整合這些模態的模型可以更全面地描繪患者的病情。現有的方法大致分為兩類:專科模型和通用模型。專科模型擅長醫學學科內的特定任務。例如,針對放射學報告生成進行優化的模型(Tanno 等人,2024;Zambrano Chaves 等人,2024)、病理學問答或組織病理學圖像字幕生成模型(Lu 等人,2023)、放射學相關任務模型(Xu 等人,2023),以及心臟病學心電圖圖像字幕生成模型(Wan 等人,2024)。
相反,“通用醫學人工智能”(GMAI)系統(Moor 等人,2023a),如 Med - PaLM M(Tu 等人,2024a)和 LLaVA - Med(Li 等人,2024),能夠處理多個專科的更廣泛任務,旨在在臨床環境中具有更廣泛的適用性。像 Med - PaLM M 這樣的系統所執行任務的多樣性仍然值得關注,它是醫學領域最早的通用多模態模型之一,能夠通過強大的預訓練大語言模型和適當的微調策略,在放射學、病理學、皮膚病學和基因組學任務中表現出色,甚至在不同專科中超越最先進水平。在本報告中,我們進一步證明了人工智能系統可以通過 Med - Gemini 在醫學領域提供強大的通用多模態能力,但主要重點是開發一個考慮特定應用權衡的模型系列。
大語言模型的長上下文能力
先前處理長上下文窗口任務的工作受到大語言模型有效利用大段文本能力的限制,這是由于基于 Transformer 的模型存在內存和計算限制(Liu 等人,2024;Vaswani 等人,2017)。最初的嘗試使用分層方法來推導無法放入模型有限上下文窗口的臨床文本表示(Dai 等人,2022)。隨后的工作,如 Clinical - Longformer 和 Clinical - BigBird(Li 等人,2023),致力于將上下文長度從 512 個標記擴展到 4096 個標記,從而在問答、文檔分類和信息檢索任務中提升了性能。后續的方法探索了將這些模型與成像編碼器結合使用,以處理多模態任務,如醫學視覺問答(Gupta 和 Demner - Fushman,2022)。隨著硬件和高效算法的進步,研究人員開發出了上下文窗口更大的大語言模型,可達 100K 個標記(Dai 等人,2019;Poli 等人,2023)。最近,Gemini 進一步將長上下文能力的邊界擴展到了 100 萬個標記(Gemini 團隊,谷歌,2024)。
然而,在醫學領域,大多數大語言模型仍然在相對較短的文本(Parmar 等人,2023)和單張圖像上進行評估。盡管長上下文能力在醫學和臨床實踐中非常重要,但在醫學領域,尤其是在多模態環境下,長上下文能力的研究還不夠深入。我們致力于滿足這一未被滿足的需求,研究 Med - Gemini 在不同長上下文應用場景中的潛力,包括視頻和與長電子健康記錄相關的任務。
C. 基于文本的先進推理任務的更多細節
C.1 基于文本的微調與評估數據集
表 C1 | 用于基于文本的指令微調的數據集概述。數據集的混合和合成數據經過精心策劃,以提高 Med - Gemini - L 1.0 的推理能力和利用網絡搜索的能力。

表 C2 | 用于基于文本的推理任務的評估基準概述。

C.2 MedQA(USMLE)重新標注
這項評分者研究的主要目的是識別:(a)由于信息缺失而無法回答的問題;(b)潛在的標注錯誤;(c)可能存在歧義的問題(Stutz 等人,2023)。為此,我們精心設計了一個兩步研究,具體如下:
- 步驟 1:給出 MedQA(USMLE)問題和所有四個答案選項:
- (Q1)我們詢問 “這些選項中有沒有適合回答這個問題的?”
- (Q2)如果有,“選擇一個或多個選項來回答這個問題。”(多選)
- (Q3)我們詢問 “問題中是否引用了任何缺失的額外信息(如圖表、繪圖、實驗室結果或類似內容)?”
- (Q4)如果有,我們詢問 “你認為獲取到缺失的信息會改變你的答案嗎?”
- 步驟 2:在評分者完成步驟 1 后,向他們展示 MedQA 的正確答案:
- (Q1)我們詢問 “在揭示了題庫的答案后,你之前的答案有改變嗎?”
- (Q2)如果有,我們重復上述前兩個問題。
采用這種兩步法的一個關鍵考慮因素是在合適的時間揭示 MedQA(USMLE)的正確答案,以避免在回答關于問題中潛在缺失信息的問題(Q3 和 Q4)時,正確答案對評分者產生偏見。然而,為了準確識別標注錯誤,我們向評分者展示正確答案,以便他們可以決定是否不同意(步驟 2 中的 Q1 和 Q2)。為了識別可能存在歧義的問題(允許多個 “正確” 或 “真實” 答案),我們進一步允許評分者選擇多個選項作為答案 。在詢問潛在缺失信息時,我們旨在確定這些缺失信息對回答問題是否至關重要。 表 C3 | 注釋一致性。頂部:各個評級與多數或一致投票在各種感興趣的評級任務上的一致性。底部:在揭示 MedQA 正確答案前后,評分者答案在平均重疊方面的一致性。
我們總共招募了 18 名來自美國的初級保健醫生(PCPs)參與這項研究。我們選擇美國的初級保健醫生是因為 MedQA 包含涵蓋多個專業的 USMLE 風格的問題。對于每個 MedQA(USMLE)問題,我們從獨立的評分者那里收集至少三個評級。雖然 Jin 等人(2021)的原始 MedQA 研究在評估專家表現時可以使用額外的文本材料,但我們的評分者并未被指示使用任何材料。不過,我們也沒有明確對此進行控制。初級保健醫生完成一個問題平均需要 255 秒;98% 的人在 10 分鐘內完成。
對于每個問題,我們匯總評級,以便高可信度地識別例如標注錯誤。首先,我們在表 C3 中評估每個評分者與多數或一致投票的一致性。具體來說,我們考慮四個感興趣的評級任務的評分者一致性:信息是否缺失、是否存在標注錯誤(即揭示 MedQA(USMLE)正確答案后,評分者的答案不包含 MedQA(USMLE)的正確答案)、問題是否存在歧義(即揭示 MedQA(USMLE)正確答案后,評分者的答案包含多個選項),以及原始答案選項在平均重疊方面的一致性(每個評分者可以選擇無選項或多個選項)。對于前三個任務,一致性通常較高(\(>87\%\)),盡管在 Med - Gemini - L 1.0 出錯的問題上通常較低。相比之下,對于第三個任務,所有答案對之間的平均重疊一致性要低得多:當評分者看到 MedQA(USMLE)正確答案時,通常約為 75%,但如果不向評分者揭示正確答案,一致性會降至約 50%。 圖 C1 | MedQA(USMLE)重新標注后的結果。該結果是圖 3b 的補充,展示了在使用多數投票(左圖)或一致投票(右圖)匯總評級時,過濾掉包含缺失信息、標注錯誤或被認為存在歧義的問題后,MedQA(USMLE)的準確率(藍色)和剩余問題(紅色)。
為了在考慮注釋不確定性的同時衡量過濾 MedQA(USMLE)中包含缺失信息或標注錯誤的問題對評估的影響,我們進行了一項自助抽樣實驗。具體來說,我們對每個問題重復抽樣一個由三名評分者組成的委員會(有放回抽樣)。對于每個評分者委員會,我們進行多數投票或一致投票,以識別出在評估時應過濾掉的包含缺失信息或標注錯誤的問題。這可以看作是 Stutz 等人(2023)提出的評估框架的一個實例。自助抽樣相對于簡單投票的優勢在于,我們可以得到可靠的不確定性估計,確保我們能夠將性能變化識別為具有統計學意義。我們重復這個實驗 1000 次,并在圖 C1 中報告準確率和剩余問題比例的平均值和標準差。
雖然由于一致性較高,可以高可信度地識別出包含缺失信息或標注錯誤的問題,但判斷一個問題是否存在歧義則更困難。在這里,我們將一個允許多個答案選項正確的問題定義為存在歧義的問題。MedQA(USMLE)測試集中的大多數問題特別要求選擇 “最佳”“最可能” 或 “最合適” 的選項。然而,在很多情況下,并不清楚答案是否真的只允許一個選項作為例如某個病例 “最佳下一步治療方案”。在使用多數投票排除包含缺失信息和標注錯誤的問題后,評分者平均選擇 1.065 個選項,這表明有些問題可能確實存在歧義。在揭示正確答案后,這個數字增加到 1.119。為了在評估時考慮到這一點,如果評分者在揭示正確答案后選擇了多個選項,我們就將該評級定義為存在歧義。然后,我們按照上述相同的分析方法,并在圖 C1 中展示結果。總體而言,我們發現過濾標注錯誤對 Med - Gemini - L 1.0 的性能影響最大,而過濾缺失信息或存在歧義的問題可以減少問題數量,但對準確率的影響并不顯著。
C.3 《新英格蘭醫學雜志》臨床病理會議數據集的更多結果
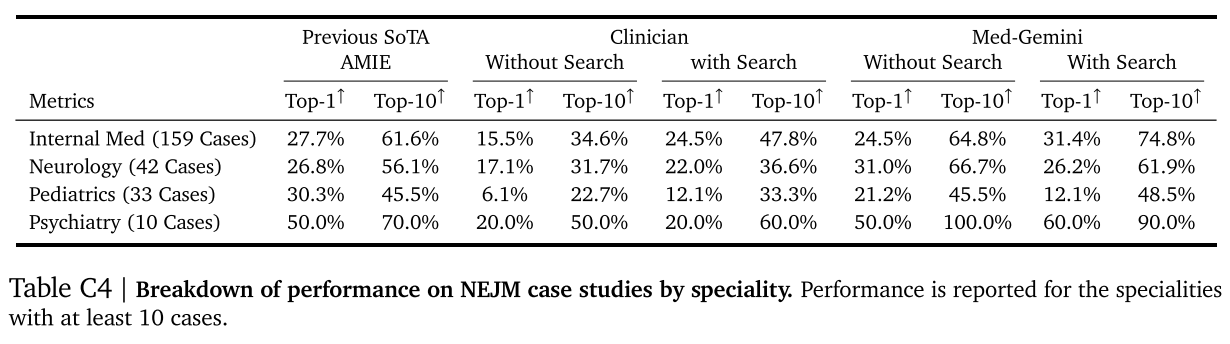
我們在表 C4 中按病例的主要專科(由《新英格蘭醫學雜志》確定)展示了《新英格蘭醫學雜志》臨床病理病例研究的前 1 名和前 10 名表現,這些專科至少有 10 個病例。在大多數專科,如內科、兒科和精神科,Med - Gemini - L 1.0 在不使用搜索或使用搜索的情況下,取得了最佳的前 1 名和前 10 名表現。?
表 C4 | 按專科劃分的《新英格蘭醫學雜志》病例研究表現細分。報告了至少有 10 個病例的專科的表現。
C.4 基于文本任務的先進推理在現實世界中的應用案例
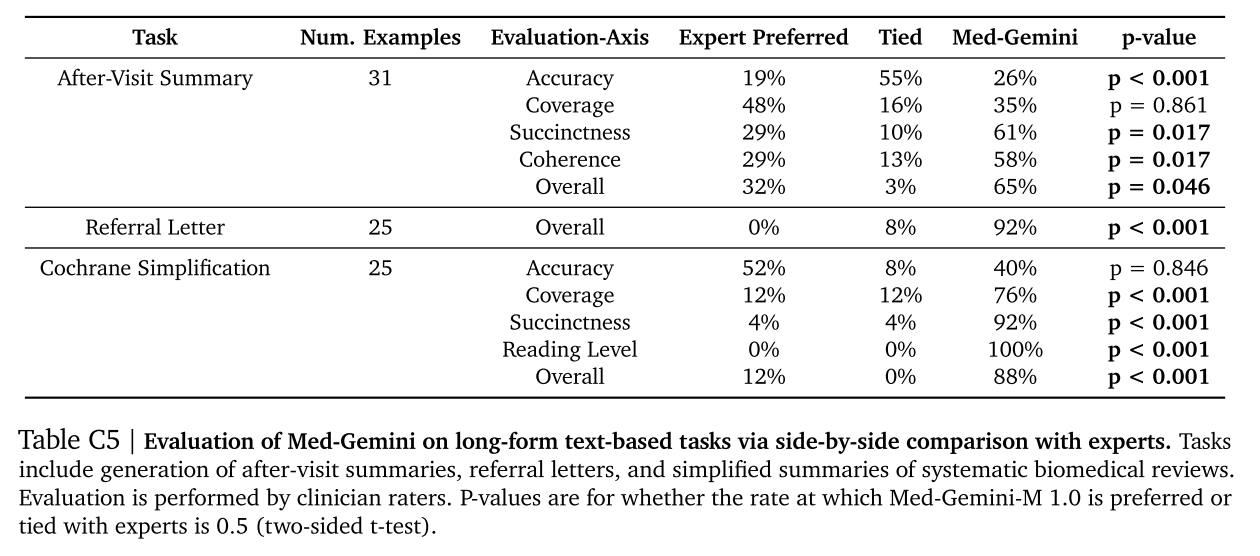
我們對 Med - Gemini - M 1.0 在三個需要長篇文本生成的具有挑戰性的現實世界任務上進行指令微調并評估。總結結果見圖 5。其他評估維度的詳細結果見表 C5。下面將更詳細地描述每個任務的數據集和評估程序。?
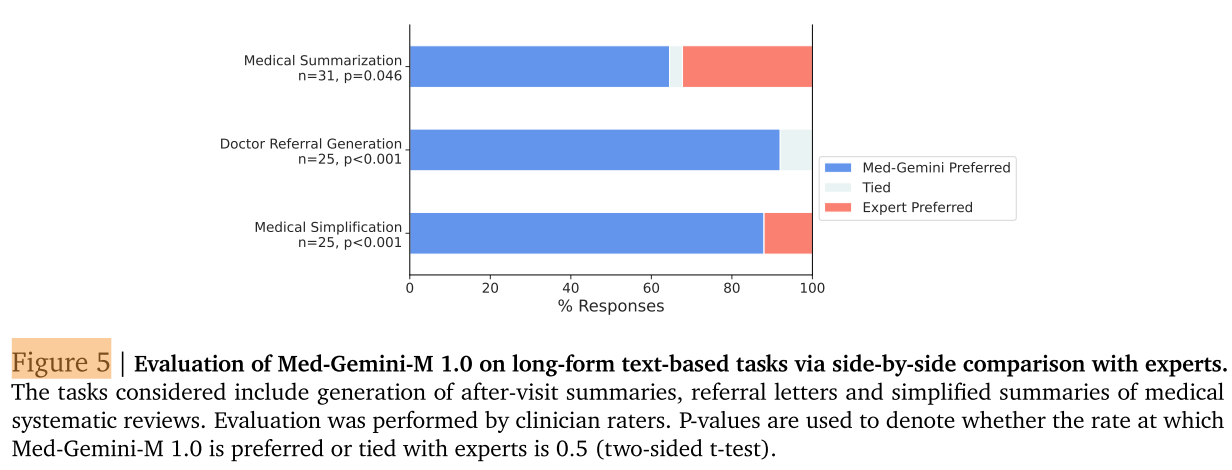
表 C5 | 通過與專家并排比較對 Med - Gemini 在基于長篇文本的任務上的評估。任務包括就診后總結、轉診信和生物醫學系統評價簡化總結的生成。評估由臨床醫生評分者進行。p 值用于表示 Med - Gemini - M 1.0 被認為與專家相當或更受青睞的比例是否為 0.5(雙側 t 檢驗)。
- 醫學總結評估:此任務涉及根據去標識化的病史和體格檢查(H&P)筆記生成就診后總結(AVS)。H&P 筆記是一份詳細的文件,醫療保健提供者在其中記錄患者就診的發現,包括患者的健康背景、當前癥狀和體格檢查結果。它主要是為其他醫療保健提供者編寫的,以確保協調護理。另一方面,AVS 是患者在醫療就診結束時收到的結構化報告,總結就診的最重要方面及其健康狀況。
我們從家庭醫學或內科門診就診的去標識化醫療筆記數據集中抽取了 31 份去標識化的 H&P 筆記。專家就診后總結由美國的臨床醫生根據 Sieferd 等人(2019)的指南編寫,并由另一輪臨床醫生進一步完善以提高質量。
給 Med - Gemini - M 1.0 輸入去標識化的 H&P 筆記,提示其生成就診后總結,如下所示: 請通讀提供的描述門診就診的醫療筆記,并為以下 12 個字段提取相關信息:
- 患者姓名 / 年齡 / 性別:應總結患者的姓名、年齡和性別。格式為:“[患者姓名],[年齡] 歲 [性別]”。如果筆記中未提及姓名,請回答 “不可用”。
- 今天為我看病的是:此字段應提供提供者的姓名。如果總結筆記中未提及為患者看病的提供者,請回答 “不可用”。
- 我今天來就診的原因是:此字段應指出導致就診的主要癥狀或問題。
- 今天新發現的健康問題是:此字段應指出因本次就診而確定的任何新診斷或其他問題。如果該問題是過去已確定的既往病癥,請回答 “無新診斷”。
- 我還有的其他健康問題是:此字段應指出筆記中確定的任何既往健康問題。
- 今天我們完成的事項:此字段應總結當前就診期間討論的主要話題和進行的任何程序的結果。總結可以是簡短的程序列表,也可以是對患者經歷的文本描述。在提供詳細信息(如測試結果或藥物名稱)時,請盡量簡潔。從患者的角度描述經歷,使用 “我的就診”“我的病情” 等短語。
- 我的重要數據:此字段應提供與就診相關的任何測量結果,包括生命體征。提供與就診相關的任何數值測量結果,包括生命體征、實驗室檢查或疼痛評分。請包括應監測的數值。不要編造筆記中未呈現的數字。
- 我的藥物變化是:此字段應說明就診后添加、劑量更新或不再需要的任何藥物。如果可能,請同時說明新添加和停用的藥物。如果從筆記中看不出有任何變化,請回答 “無變化”。
- 我正在服用的其他藥物是:如果筆記中指出患者應繼續服用且無變化的現有藥物,請在此列出。如果筆記中未提及任何藥物,請填寫 “未指定”。
- 我的下一步是:此字段應記錄患者的下一步行動,包括他們應采取的任何行動、預期的測試結果以及應安排的隨訪就診,以及每個步驟的適當時間框架。
- 如果出現以下情況我應立即尋求醫療幫助:如果筆記中指定了患者應立即尋求護理的任何情況,請在此處說明。確保只包括筆記中提到的情況。如果未提及任何情況,請寫 “未指定”。
- 我的醫生的其他意見:這是一個可選的額外字段,用于記錄醫生在筆記中指出的、對患者有用的任何其他相關信息。請勿包含前面字段中已列出的信息。
對于每個字段,請以六年級的閱讀水平書寫,避免使用縮寫或行話。 注意:{醫療筆記} 就診后總結:
醫生評分者會收到 H&P 筆記、臨床醫生生成的 AVS 和我們模型生成的 AVS。每個示例由三位不同的美國醫生中的一位進行評估,評估維度如下:
- 準確性:哪個總結更準確?(總結中的所有陳述是否正確?)
- A - B - 平局
- 覆蓋范圍:哪個總結的覆蓋范圍更好?(它是否包含筆記的所有相關方面?)
- A - B - 平局
- 連貫性:哪個總結更容易閱讀?(對于沒有特定醫學知識的普通消費者來說,以六年級閱讀水平來看,這個總結是否易懂?)
- A - B - 平局
- 簡潔性:哪個總結更簡潔?(總結是否比需要的更長?)
- A - B - 平局
- 總體評價:你認為哪個總結的質量更高?(除了這些指標之外,對總結的質量有沒有直觀的感覺?)
- A - B - 平局
- 轉診信生成評估:此任務涉及根據包含轉診建議的去標識化門診醫療筆記,生成轉診信給另一位醫療保健提供者。醫療轉診信是醫療保健專業人員撰寫的正式文件,請求另一位醫療保健專業人員對患者進行評估或治療。它是醫療保健提供者之間的溝通工具,確保護理的連續性并促進對患者的適當治療。
臨床醫生從去標識化的電子醫療記錄數據集中手動選擇了一組需要跨專科評估的去標識化醫療筆記。然后他們生成轉診信,這些轉診信由一位美國董事會認證的臨床醫生進一步審核質量。
給 Med - Gemini - M 1.0 輸入醫療筆記,提示其生成轉診信,如下所示: 你將收到一份描述患者就診的醫療筆記。該醫療筆記將包含將患者轉診給另一位醫療保健提供者的建議。你的任務是為這位醫療保健提供者生成醫療轉診信。
醫療轉診信是醫療保健專業人員撰寫的正式文件,請求另一位醫療保健專業人員對患者進行評估或治療。它是醫療保健提供者之間的溝通工具,確保護理的連續性并促進對患者的適當治療。 醫療筆記:{醫療筆記} 轉診信:
醫生評分者會收到門診筆記、臨床醫生生成的轉診信和我們模型生成的轉診信。他們不知道每封轉診信的來源,并被要求進行以下比較: 說明: 你收到一份提到轉診給另一位醫療保健提供者的醫療筆記。假設你需要根據筆記中的信息撰寫一封轉診信。你會看到由兩位不同助手撰寫的轉診信草稿。你更傾向于選擇哪一份草稿作為編輯最終版本的起點?請在 “備注” 欄中簡要說明你選擇的理由。 警告:請注意,不能保證草稿信準確反映轉診原因或患者病史。這需要根據提供的醫療筆記來確定,并且在你的選擇中應占重要考慮因素。 選項:
- A 非常傾向 - A 有點傾向 - 平局 - B 有點傾向 - B 非常傾向
我們招募了三位不同的美國董事會認證醫生,他們每個人評估所有 25 個示例。評分通過將李克特量表映射到數值范圍(\([-2,2]\))并取中位數的符號來匯總。
- 醫學簡化評估:此任務涉及從生物醫學系統評價的技術摘要生成通俗易懂的語言摘要(PLS)。PLS 是技術摘要的一個版本,用通俗易懂的英語撰寫,旨在讓大多數沒有大學教育背景的讀者能夠理解(Cochrane,2014)。
我們從 Devaraj 等人(2021)引入的數據集的測試分割中抽取了 25 個來自 Cochrane 系統評價的技術摘要和通俗易懂的語言摘要。專家撰寫的通俗易懂的語言摘要是由 Cochrane 系統評價的原始作者編寫的。
給 Med - Gemini - M 1.0 輸入技術摘要,提示其生成 PLS,如下所示: 請通讀提供的醫學研究技術總結,并提供一個對沒有醫學專業知識的普通讀者易懂的簡化總結。 技術總結:{技術摘要} 簡化總結:
臨床醫生會收到技術摘要、原始 PLS 和我們模型生成的 PLS。他們不知道每個 PLS 的來源,并被要求進行以下比較:
- 依據性:簡單總結中的所有信息在技術總結中是否都有事實依據?
- A 非常傾向 - A 有點傾向 - 平局 - B 有點傾向 - B 非常傾向
- 覆蓋范圍:簡單總結是否包含了對普通讀者最重要的要點?
- A 非常傾向 - A 有點傾向 - 平局 - B 有點傾向 - B 非常傾向
- 簡潔性:簡單總結是否只包含了對普通讀者最重要的要點?
- A 非常傾向 - A 有點傾向 - 平局 - B 有點傾向 - B 非常傾向
- 閱讀水平:簡單總結的閱讀水平是否適合普通讀者?
- A 非常傾向 - A 有點傾向 - 平局 - B 有點傾向 - B 非常傾向
- 總體評價:對于普通讀者來說,這個簡單總結的總體質量如何?
- A 非常傾向 - A 有點傾向 - 平局 - B 有點傾向 - B 非常傾向
三位不同的美國董事會認證醫生各自評估所有 25 個示例。評分的匯總方式與轉診信任務類似。
D. 多模態理解任務的更多細節
D.1 多模態微調數據集
為了對 Med - Gemini - M 1.5 進行多模態微調,我們使用了來自 MultiMedBench(Tanno 等人,2024;Tu 等人,2024a)的四個圖像 - 文本數據集,包括 Slake - VQA(Liu 等人,2021)、Path - VQA(He 等人,2020)、MIMIC - CXR(Johnson 等人,2019a,b)、PAD - UFES - 20(Pacheco 等人,2020),以及 Radiology Objects in COntext(ROCO)數據集(Pelka 等人,2018)。我們還進一步使用了 ECG - QA(Oh 等人,2023)的一個子集,為 Med - Gemini - S 1.0 開發用于編碼傳感器輸入的健康信號編碼器。下面我們詳細描述這些數據集: 表 D1 | 用于多模態指令微調的數據集概述。
- MIMIC - CXR 是一個帶有自由文本報告的胸部 X 光(CXR)數據集(Johnson 等人,2019a,b),由 377,110 張胸部 X 光圖像以及來自 65,379 名患者的相應去除受保護健康信息(PHI)的文本報告組成(227,835 次圖像研究,有一個或多個圖像視圖位置)。每份報告使用 CheXpert 標注軟件(Irvin 等人,2019)標注了 13 種常見的放射學狀況。我們對所有任務使用 MIMIC - CXR 中描述的官方訓練 / 測試分割。我們考慮使用 MIMIC - CXR 進行四個微調任務:(1)正常與異常的二元分類;(2)CXR 異常狀況視覺問答(VQA);(3)合成 CXR 視覺問答;(4)文本報告生成。對于正常與異常的二元分類任務,我們根據 CheXpert 的 “無異常發現” 標簽,使用所有正位視圖圖像(前后位(AP)和后前位(PA)視圖)將每張圖像分類為正常或異常類別,任務提示見圖 D1。對于 CXR 異常狀況視覺問答任務,我們排除所有正常發現的圖像,并將 13 種異常狀況(肺不張、心臟肥大、實變、水腫、縱隔增寬、骨折、肺部病變、肺部陰影、胸腔積液、胸膜其他病變、肺炎、氣胸和支持裝置)的陽性和不確定標簽歸為陽性類別。然后,我們將異常檢測問題構建為一個封閉式多類別多項選擇題設置,如圖 D1 所示。為了進一步豐富這些視覺問答任務,我們通過查詢 Gemini 基礎模型從放射學報告中生成一組合成的問答對。我們特別促使大語言模型從每份報告中提取是或否問題及其相應答案,使其與上述 13 種狀況的存在無關。我們確保每個問題的 “是” 和 “否” 答案數量相同,以避免引入虛假相關性。所有視覺問答任務都作為報告生成任務的輔助任務添加,該報告生成任務將圖像與來自 “檢查指征” 部分(研究原因)的上下文信息作為模型輸入,以生成報告的 “檢查結果” 和 “印象” 部分作為目標,與先前的工作類似(Hyland 等人,2023;Tu 等人,2024a)。此外,按照 Tanno 等人(2024)提出的程序,我們過濾掉報告中引用先前研究的訓練示例,只保留報告僅提及輸入圖像中存在的發現的示例。這旨在減輕對不存在的先前報告的引用幻覺,這是多個研究中提出的常見問題(Ramesh 等人,2022;Hyland 等人,2023)。MIMIC - CXR 的評估將在后續論文中報告。
- PAD - UFES - 20 包含 2,298 張臨床皮膚病變圖像,這些圖像是通過巴西圣埃斯皮里圖聯邦大學(UFES)的皮膚病學和外科援助計劃,從各種不同分辨率、尺寸和光照條件的智能手機設備上收集的(Pacheco 等人,2020)。數據集中包含六種類型的皮膚病變:基底細胞癌、黑色素瘤、鱗狀細胞癌、光化性角化病、黑素細胞痣和脂溢性角化病。每張圖像最多與 21 個臨床特征相關聯(例如,患者人口統計信息、家族癌癥病史、病變位置、病變大小)。由于沒有公布官方分割,我們采用了兩種 PAD - UFES - 20 分割設置。我們使用 Med - PaLM M 分割(圖像級分割),以便與先前的最先進方法進行直接、公平的評估和比較。我們還在一個新的分割(患者級分割)上進行評估(表 2)。我們設置了三個分類任務進行微調:(1)使用原始標簽分布和 14 個臨床特征(年齡、性別、吸煙、飲酒、皮膚癌病史、癌癥病史、地區、菲茨帕特里克皮膚分型、水平和垂直直徑、瘙癢、生長、出血和隆起)進行 6 類分類;(2)與前一個任務一樣使用圖像和臨床特征進行 6 類分類,但在訓練集上使用 8 種 RandAugment(Cubuk 等人,2020)操作進行圖像增強:自動對比度調整、均衡化、反轉、旋轉、色調分離、曝光、色彩調整和對比度調整;(3)與前一個任務相同的 6 類分類,但對四種較少見的皮膚狀況(黑色素瘤、鱗狀細胞癌、脂溢性角化病和痣)使用上采樣子集,并在訓練期間進行圖像增強,以緩解類別不平衡問題。后兩個輔助任務包含在訓練組合中,以幫助模型區分不同類型的臨床觀察結果。我們還將皮膚狀況分類問題構建為一個封閉式多項選擇題設置,如圖 D1 所示,并報告該任務的預測準確率。
- Path - VQA 是一個病理學問答(VQA)數據集,由 998 張病理圖像和 32,799 個問答對組成(He 等人,2020)。所有圖像均從醫學教科書和在線數字圖書館中提取。每張圖像都與一個或多個關于病理成像不同方面的問題相關,包括顏色、位置、外觀、形狀等。50.2% 的問答對是開放式問題(分為 7 類:什么、哪里、何時、誰的、如何以及多少)。49.8% 的問答對是簡單的 “是 / 否” 封閉式問題。我們采用官方分割,其中訓練 / 驗證 / 測試分割分別包含 19,755、6,279 和 6,761 個問答對。
- Slake - VQA 是一個雙語(英語和中文)放射學圖像視覺問答數據集(Liu 等人,2021),包含 642 張標注圖像和 14,028 個問答對,涵蓋三種成像模態(CT、MRI 和胸部 X 光)、39 個器官系統和 12 種疾病。問題與放射學圖像的各個方面相關,包括層面、質量、位置、器官、異常、大小、顏色、形狀、知識圖譜等,有開放式和封閉式問題。訓練 / 驗證 / 測試分割分別包含 9,849、2,109 和 2,070 個問答對。
- ROCO(Radiology Objects in Context)數據集是一個大規模的醫學和多模態成像數據集(Pelka 等人,2018)。ROCO 圖像來自 PubMed Central 開放訪問 FTP 鏡像上的出版物,這些圖像被自動標記為放射學或非放射學圖像。每張圖像都有其標題、關鍵詞、相應的 UMLS 語義類型(SemTypes)和 UMLS 概念唯一標識符(CUIs)。我們使用官方的放射學和非放射學訓練集,其中包含 29,907 個圖像 - 標題對,并設置了一個標題生成任務進行微調。我們僅在 ROCO 中包含具有 CC BY、CC BY ND、CC BY SA 和 CC0 許可的圖像。
- ECG - QA 是一個用于評估心臟健康的傳感器 - 文本多模態基準數據集(Oh 等人,2023)。它是第一個專門為基于 PTB - XL(Wagner 等人,2020)的心電圖分析設計的問答數據集,包含各種問題模板,每個模板都經過心電圖專家驗證,以確保臨床實用性。在 ECG - QA 上的出色表現表明能夠掌握復雜的醫學概念及其與原始波形信號的聯系。ECG - QA 包含兩種類型的問題:(1)單心電圖問題;(2)比較兩個心電圖的問題;每種問題類型又包括(1)是 / 否問題、(2)多項選擇題和(3)提供心電圖相關屬性的開放式問題。在這項工作中,我們專注于單心電圖問題,其訓練、驗證和測試集分別包含 159,306、31,137 和 41,093 個樣本。
D.2 多模態評估數據集
除了分布內數據集(上述部分有詳細介紹),我們還納入了三個分布外數據集來評估 Gemini 的多模態能力:?
表 D2 | 用于多模態理解評估的數據集概述。OOD:分布外數據集。

- 《新英格蘭醫學雜志》(NEJM)圖像挑戰是一個著名的臨床病例挑戰系列,用于測試全球醫學專業人員的診斷敏銳度和視覺觀察技能(《新英格蘭醫學雜志》,2024)。每周,NEJM 都會展示一幅臨床圖像,并附帶簡短的病例描述。這些圖像包括放射學圖像、自然和皮膚鏡下的皮膚圖像、心電圖、組織病理學圖像、內窺鏡圖像和眼底鏡圖像。讀者被邀請仔細分析照片,考慮患者的病史,并從五個可能的診斷候選中選擇最終診斷。我們收集了 2005 年至 2023 年的 942 個 NEJM 圖像挑戰病例。每個病例都由一幅醫學圖像、一個相關問題(例如,“最可能的診斷是什么?”)、五個多項選擇題選項和一個正確答案組成。有些病例在問題中還提供了帶有相關臨床背景或其他背景信息的文本說明。我們總共收集了 942 個病例,但最終為了公平比較,評估了 934 個病例(截至 10 月 12 日,20160519 和 20111103 這兩個病例由于 GPT - 4V 過濾器阻止了被認為是露骨內容的圖像而未被評估(Buckley 等人,2023))。
- USMLE - MM(多模態)是一個多模態多項選擇題數據集,在www.usmle.org提供的樣本考試中確定了 46 個問題,這些問題中包含圖像。樣本考試用于美國醫學執照考試(USMLE)的備考。
- MMMU - HM(健康與醫學)是公開可用基準 MMMU(大規模多學科多模態理解)驗證集(Yue 等人,2023)的一個子集。MMMU - HM 包括 150 個與基礎醫學科學、臨床醫學、診斷和實驗室醫學、藥學以及公共衛生領域相關的問題。
D.3 多模態任務的更多結果
在 ECG - QA 任務方面,為了擴展 Med - Gemini 處理原始生物醫學信號以用于 ECG - QA 任務的能力,我們為 Gemini 1.0 Nano 添加了一個特定于心電圖的編碼器,并使用兩種方法進行微調:保持 Gemini 模型不變(凍結)和微調 Gemini 模型(解凍)。我們將我們的 Med - Gemini - S 1.0 與相應的基線模型進行比較:將凍結 Gemini 模型的我們的模型與在輸入提示中使用 SE - WR 心電圖特征的 GPT - 4 進行比較(Oh 等人,2023),將解凍 Gemini 模型的我們的模型與基于\(M^{3}AE\)的心電圖基礎模型進行比較(Oh 等人,2023)。凍結和解凍 Gemini 的 Med - Gemini - S 1.0 在單心電圖問題上的準確率分別為 57.7% 和 58.4%,比 GPT - 4(51.6%)高出 6.1%,比\(M^{3}AE\)(57.6%)高出 0.8%。
E. 長上下文理解任務的更多細節
圖D1|多模態理解任務的代表性示例和提示。Med-Gemini在各種任務中進行了評估,包括圖像分類和視覺問答(VQA),證明了其分析和解釋各種生物醫學數據格式的能力。請注意,ECG-QA的輸入是原始ECG傳感器序列,在此可視化為來自PTB-XL的12導聯ECG圖像(瓦格納等人,2020年)的報告。另請注意,三個MIMIC-CXR任務僅用于指令微調。?
E.1 長上下文評估數據集
- MIMIC - III “大海撈針” 數據集是從 MIMIC - III(Johnson 等人,2016)中特別策劃的一個數據集,用于在長電子健康記錄(EHR)中進行細微醫學狀況的搜索檢索任務。它旨在模擬一個與臨床相關的 “大海撈針” 式挑戰性問題(Gemini 團隊,谷歌,2023)。MIMIC - III 是一個大型的公開可用醫學數據庫,包含入住重癥監護病房患者的醫療記錄。我們從 44 名具有 100 多份 “高價值” 臨床筆記的獨特患者中隨機選擇非結構化醫療筆記 。為了構建 “大海撈針” 示例,我們使用了先前的工作(Feder 等人,2022),該工作旨在通過以下方式從患者的電子健康記錄文檔集合中識別問題列表(病癥 / 癥狀 / 手術):(1)使用基于機器學習的注釋器標記醫療記錄中所有問題的提及(文本片段);(2)基于規則選擇和聚合提及內容,以確定問題是否實際存在。我們選擇在聚合步驟中僅識別出 1 個證據片段的示例,然后通過基于規則的方法隨機抽取 100 個陰性和 100 個陽性示例。然后將這 200 個選定的示例發送給 3 名人類醫學評分者,以確定問題是否實際存在。具體來說,評分者會看到病癥名稱和檢索到的支持證據片段。然后,評分者被要求回答問題:“根據提供的筆記摘錄中的證據,選擇患者確實患有的所有問題”。結果,根據多數投票 ,我們有 121 個陽性示例和 79 個陰性示例(Krippendorff's alpha 為 0.77,見表 E3)。多數投票標簽隨后被用作后續評估的真實標簽。對于每個示例,它由一組醫療記錄、一個關于感興趣病癥是否存在的測試問題以及一個二元真實標簽組成。醫療記錄的長度從 200,000 到 700,000 字不等。
- 醫學教學視頻問答(MedVidQA)是一個用于醫學視覺答案定位(MVAL)任務的視頻 - 語言跨模態數據集(Gupta 等人,2023)。三位醫學信息學專家為從 YouTube 上提取的 899 個視頻創建了 3,010 個與健康相關的教學問題,并通過在視頻中注釋時間戳來定位這些問題的視覺答案,即根據文本問題查詢確定時間戳跨度。這些視頻的平均時長為 383.29 秒。我們遵循官方的數據分割,其中 2,710、145 和 155 個問題及視覺答案分別用于訓練、驗證和測試。然而,由于 YouTube 視頻訪問限制(私人視頻、已刪除視頻),有 7 個問題被排除在外。
- Cholec80 和 Cholec80 - CVS。Cholec80 數據集包含 13 名外科醫生進行的 80 個高質量腹腔鏡膽囊切除術視頻(Twinanda 等人,2016)。Cholec80 是深度學習中用于腹腔鏡膽囊切除術視頻分析研究的最受歡迎的基準之一,最近在不同的視頻理解任務中得到了廣泛應用,包括手術階段的時間分割(Chen 等人,2018;Golany 等人,2022)和手術工具檢測(Leifman 等人,2022;Nwoye 等人,2019)。Cholec80 - CVS(Ríos 等人,2023)包含由熟練外科醫生為 Cholec80 數據集中的每個視頻提供的安全關鍵視圖(CVS)標準注釋。CVS(Strasberg 和 Brunt,2010)是一種強制性方法,由三個視覺標準定義,用于安全識別膽囊管和膽囊動脈,以最小化膽管損傷(BDI)的風險。對于 Cholec80 中的每個視頻,熟練的外科醫生選擇至少滿足一個 CVS 標準的不同視頻片段,然后對于每個選定的視頻片段,外科醫生根據(Sanford 和 Strasberg,2014)以及(Mascagni 等人,2021)提出的原始評分系統的擴展,為三個 CVS 標準中的每一個分配 0、1 或 2 分。總體而言,Cholec80 - CVS 為 Cholec80 視頻中的 572 個視頻片段提供了 CVS 標準注釋。我們評估 Med - Gemini - M 1.5 與 GPT - 4V 和 Resnet3D 相比的性能。需要注意的是,GPT - 4V 官方不支持視頻數據作為輸入。因此,我們以每秒 1 幀的速率從每個視頻剪輯中采樣幀,并將一系列幀組合作為模型的輸入。在實驗過程中,我們觀察到 GPT - 4V 的視覺上下文長度有限,我們最多只能插入 300 張低分辨率圖像。因此,我們過濾掉所有長度超過 5 分鐘的視頻剪輯。為了進行公平比較,我們在相同的過濾后視頻剪輯子集上評估 Med - Gemini - M 1.5。為了對 Resnet3D 進行評估,我們將數據集隨機分成 5 個連續的折疊,并分別評估每個驗證折疊上的性能。報告的是所有五個折疊的平均準確率。?
表 E1 | 用于長上下文能力評估的數據集概述。MVAL:醫學視覺答案定位。?

表 E2 | Med - Gemini - M 1.5 與基于啟發式注釋聚合的基線方法的性能比較。
E.2 長 EHR 理解任務的評分者一致性指標
為確保電子健康記錄基準的可靠性,我們為 200 個示例問題中的每一個都收集了三位獨立評分者的評分。以下指標顯示了評分者之間的高度一致性:
- 杰卡德相似系數(Jaccard Similarity Index):用于衡量評分者選擇集之間的重疊程度。設A、B和C分別代表每個評分者的選擇集。所有評分者一致選擇的杰卡德相似系數定義為\(J_{=3}=\frac{|A \cap B \cap C|}{|A \cup B \cup C|}\)。至少有兩個評分者一致的杰卡德相似系數定義為\(J_{\geq2}=\frac{|(A \cap B) \cup(A \cap C) \cup(B \cap C)|}{|A \cup B \cup C|}\)。
-
克里彭多夫 α 系數(Krippendorff’s Alpha):一種為多個評分者設計的信度系數。
?
?任務數量 \(J_{=3}\) \(J_{\geq2}\) 克里彭多夫 α 系數 病癥存在判斷 200 0.83 0.915 0.77 表 E3 | 長電子健康記錄(EHR)理解任務的評分者一致性指標。
?所有三位評分者選擇完全相同的情況下,杰卡德相似系數(Jaccard similarity index)為 0.83,這表明一致性程度較高。當三位評分者中至少有兩位做出相同選擇時,更高的杰卡德指數 0.915 反映出很強的一致性。克里彭多夫 α 系數為 0.77,表明在電子健康記錄數據中對醫療狀況存在與否的判斷上,評分者之間的一致性良好。
)

)

數組娛樂篇21)
)



)

)




)

-MPU6050模塊詳解以及軟件IIC驅動)
