作者:來自 Elastic?Thomas Veasey?及?Mayya Sharipova

過去,我們曾討論過搜索多個 HNSW 圖時所面臨的一些挑戰,以及我們是如何緩解這些問題的。當時,我們也提到了一些計劃中的改進措施。本文正是這項工作的成果匯總。
你可能會問,為什么要使用多個圖?這是 Lucene 中架構選擇的一個副作用:不可變段(immutable segments)。正如大多數架構決策一樣,它既有優點也有缺點。例如,我們最近正式發布了無服務器版本的 Elasticsearch。在這個背景下,我們從不可變段中獲得了非常顯著的優勢,包括高效的索引復制、索引計算與查詢計算的解耦,以及它們各自的自動擴展能力。對于向量量化,段合并讓我們有機會更新參數,以更好地適應數據特性。在這個方向上,我們認為通過測量數據特性并重新評估索引選擇,還可以帶來其他優勢。
本文將探討我們為顯著減少構建多個 HNSW 圖的開銷,特別是為了降低圖合并成本所做的工作。
背景
為了保持可管理的段(segment)數量,Lucene 會定期檢查是否需要合并段。這基本上是檢查當前段數量是否超過了一個由基礎段大小和合并策略決定的目標段數。如果超過了這個限制,Lucene 就會將若干段合并,直到約束條件不再被違反。這個過程在其他文檔中已有詳細描述。
Lucene 傾向于合并相似大小的段,因為這樣可以實現寫放大的對數增長。對于向量索引來說,寫放大指的是同一個向量被插入圖的次數。Lucene 通常嘗試將大約 10 個段合并成一組。因此,向量大約會被插入圖 1 + 9/10 × log??(n/n?) 次,其中 n 是索引中的總向量數量,n? 是每個基礎段的預期向量數量。由于這種對數增長,即便在非常大的索引中,寫放大仍能保持在個位數。然而,合并圖所花費的總時間與寫放大呈線性關系。
在合并 HNSW 圖時,我們已經采用了一個小的優化:保留最大段的圖,并將其他段的向量插入這個圖。這就是上述公式中 9/10 系數的原因。接下來我們將展示,如何通過利用所有參與合并的圖中的信息,顯著提高這一過程的效率。
圖合并
之前,我們保留了最大的圖,并插入了其他圖中的向量,忽略了包含它們的圖。我們在下面利用的關鍵見解是,每個我們丟棄的圖包含了它所包含的向量的相似性信息。我們希望利用這些信息來加速插入至少一部分向量。
我們專注于將一個較小的圖 插入到一個較大的圖?
? 的問題,因為這是一個原子操作,我們可以用它來構建任何合并策略。
該策略是找到一個小圖中頂點的子集? 來插入到大圖中。然后,我們利用這些頂點在小圖中的連接性來加速插入剩余的頂點
?。以下我們用
和
?分別表示小圖和大圖中頂點
的鄰居。該過程的示意如下。

我們使用下文將討論的一個過程(第1行)來計算集合 。然后,使用標準的 HNSW 插入過程(第2行)將?
中的每個頂點插入到大圖中。對于尚未插入的每個頂點,我們會找到其已插入的鄰居及這些鄰居在大圖中的鄰居(第 4 和第 5 行)。接著,使用以這個集合為種子的 FAST-SEARCH-LAYER 過程(第 6 行),從 HNSW 論文中的 SELECT-NEIGHBORS-HEURISTIC 中找到候選集合(第 7 行)。實際上,我們是在替換 INSERT 方法(論文中的算法1)中的 SEARCH-LAYER 過程,其他部分保持不變。最后,將剛插入的頂點加入集合 J(第8行)。
顯然,為了使這個過程有效,每個 ?中的頂點必須至少有一個鄰居在 J 中。實際上,我們要求對于每個
,都有
?,其中
,即最大層連接數。我們觀察到,在實際的 HNSW 圖中,頂點度數的分布差異很大。下圖展示了 Lucene HNSW 圖底層中頂點度數的典型累計密度函數。

我們嘗試了使用固定值的 ? 和將其設為頂點度數的函數這兩種方法。第二種選擇帶來了更大的加速,并對召回率的影響較小,因此我們選擇了以下公式:
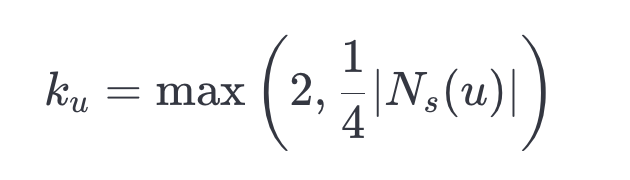
請注意, 是頂點
在小圖中的度數。設定下限為 2 意味著我們將插入所有度數小于 2 的頂點。
一個簡單的計數論證表明,如果我們仔細選擇 ,我們只需要直接將約
的頂點插入到大圖?
中。具體而言,我們對圖的邊進行著色,如果我們將它的一個端點插入到
?中。然后我們知道,為了確保
中的每個頂點都有至少
? 個鄰居在 J 中,我們需要著色至少
條邊。此外,我們預期:
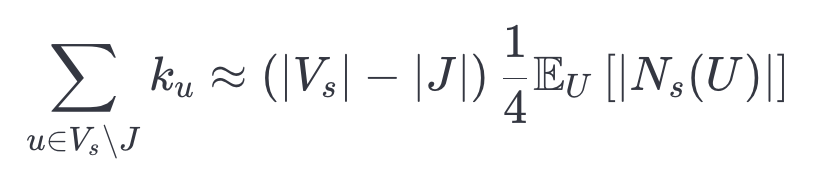
這里, 是小圖中頂點的平均度數。對于每個頂點
,我們最多會著色
條邊。因此,我們預期著色的總邊數最多為
。我們希望通過仔細選擇
,能夠著色接近這個數量的邊。因此,為了覆蓋所有的頂點,
需要滿足:
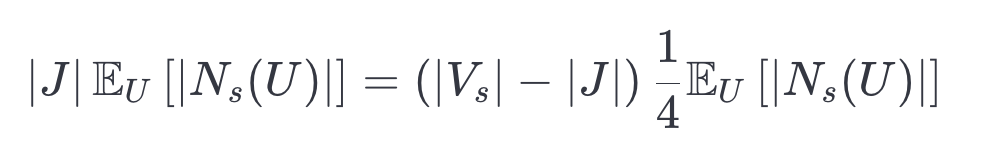
這意味著:
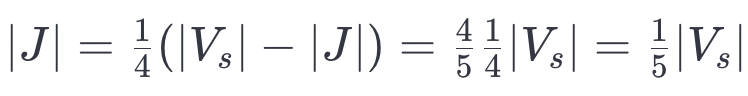
提供 SEARCH-LAYER 支配了運行時間,這表明我們可以在合并時間上實現最多 5 倍的加速。考慮到寫入放大效應的對數增長,這意味著即使對于非常大的索引,我們的構建時間通常也僅僅是構建一個圖時的兩倍。
這種策略的風險在于我們可能會損害圖的質量。最初,我們嘗試了一個無操作的 FAST-SEARCH-LAYER。我們發現這會導致圖質量下降,特別是在合并到單個段時,召回率作為延遲的函數會降低。然后我們探索了使用有限圖搜索的各種替代方案。最終,最有效的選擇是最簡單的。使用 SEARCH-LAYER,但設置一個較低的 ef_construction。通過這種參數設置,我們能夠在保持優良圖質量的同時,減少約一半的合并時間。
計算連接集
找到一個好的連接集可以表述為一個圖覆蓋問題。貪心啟發式算法是一種簡單有效的啟發式方法,用于逼近最優的圖覆蓋。我們采用的方法是使用貪心啟發式算法,一次選擇一個頂點將其加入到 中,使用以下定義的每個候選頂點的增益:
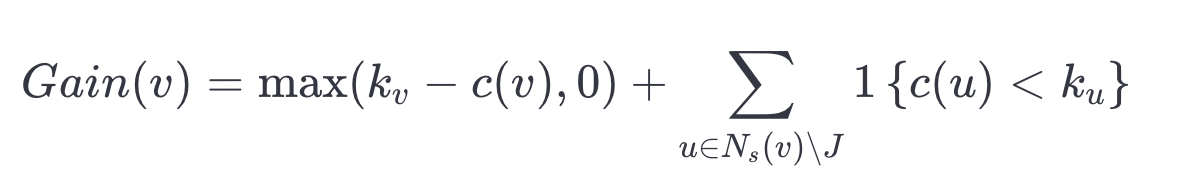
在這里, 表示向量
在
中的鄰居數量,
是指示函數。增益包括我們加入到
中的頂點的鄰居數量變化,即
,因為通過加入一個覆蓋較少的頂點,我們可以獲得更多的增益。增益計算在下圖中對于中央橙色節點進行了說明。

我們為每個頂點 維護以下狀態:
-
是否過時(stale)
-
它的增益
-
在
中相鄰頂點的計數,記作?
-
一個在 [0, 1] 范圍內的隨機數,用于打破平局。
計算加入集合的偽代碼如下。

我們首先在第 1-5 行初始化狀態。
在主循環的每次迭代中,我們首先提取最大增益的頂點(第 8 行),并在存在平局時隨機打破平局。在做任何修改之前,我們需要檢查該頂點的增益是否過時。特別地,每次我們將一個頂點添加到 中時,會影響其他頂點的增益:
-
由于它的所有鄰居在
-
如果它的任何鄰居現在已經完全覆蓋,那么它們所有鄰居的增益都可能發生變化(第14-16行)。
我們以懶惰的方式重新計算增益,因此只有在我們要將一個頂點插入到 中時,才會重新計算該頂點的增益(第18-20行)。
請注意,我們只需要跟蹤我們已添加到 中的頂點的總增益,以決定何時退出。此外,盡管
,至少會有一個頂點具有非零增益,因此我們始終會取得進展。
結果
我們在4個數據集上進行了實驗,涵蓋了我們支持的三種距離度量(歐幾里得、余弦和內積),并采用了兩種類型的量化方法:1)int8 —— 每個維度使用1字節的整數;2)BBQ —— 每個維度使用一個比特。
實驗 1:int8 量化
從基準到候選方案(提出的改進)的平均加速比為:
-
索引時間加速:1.28×
-
強制合并加速:1.72×
這對應于以下運行時間的劃分:

為了完整性,以下是各項時間數據:
-
quora-E5-small; 522931 文檔;384 維度;余弦度量
基準:索引時間:112.41s,強制合并:113.81s
候選:索引時間:81.55s,強制合并:70.87s -
cohere-wikipedia-v2; 100萬文檔;768 維度;余弦度量
基準:索引時間:158.1s,強制合并:425.20s
候選:索引時間:122.95s,強制合并:239.28s -
gist; 960 維度,100萬文檔;歐幾里得度量
基準:索引時間:141.82s,強制合并:536.07s
候選:索引時間:119.26s,強制合并:279.05s -
cohere-wikipedia-v3; 100萬文檔;1024 維度;內積度量
基準:索引時間:211.86s,強制合并:654.97s
候選:索引時間:168.22s,強制合并:414.12s
下面是與基準進行對比的召回率與延遲圖,比較了候選方案(虛線)與基準在兩種檢索深度下的表現:recall@10 和 recall@100,分別針對具有多個分段的索引(即索引所有向量后默認合并策略的最終結果)以及強制合并為單個分段的索引。曲線越高且越靠左表示性能越好,這意味著在較低的延遲下獲得更高的召回率。
從下面的圖表可以看出,在多個分段索引上,候選方案在 Cohere v3 數據集上的表現更好,對于其他所有數據集,曲線稍差但幾乎可比。當合并為單個分段后,所有數據集的召回曲線幾乎相同。




實驗 2:BBQ 量化
從基準到候選方案的平均加速比為:
-
索引時間加速:1.33×
-
強制合并加速:1.34×
以下是具體的細分:

為完整性考慮,以下是時間數據:
-
quora-E5-small; 522931 個文檔; 384 維度; 余弦度量
基準:索引時間:70.71秒,強制合并:59.38秒
候選方案:索引時間:58.25秒,強制合并:40.15秒 -
cohere-wikipedia-v2; 100 萬個文檔; 768 維度; 余弦度量
基準:索引時間:203.08秒,強制合并:107.27秒
候選方案:索引時間:142.27秒,強制合并:85.68秒 -
gist; 960 維度,100 萬個文檔; 歐氏度量
基準:索引時間:110.35秒,強制合并:323.66秒
候選方案:索引時間:105.52秒,強制合并:202.20秒 -
cohere-wikipedia-v3; 100 萬個文檔; 1024 維度; 內積度量
基準:索引時間:313.43秒,強制合并:165.98秒
候選方案:索引時間:190.63秒,強制合并:159.95秒
從多個段索引的圖表可以看到,候選方案在幾乎所有數據集上表現更好,除了 cohere v2 數據集,基準略優。對于單個段索引,所有數據集的召回曲線幾乎相同。




總的來說,我們的實驗涵蓋了不同的數據集特征、索引設置和檢索場景。實驗結果表明,我們能夠在保持強大的圖質量和搜索性能的同時,實現顯著的索引和合并加速,這些結果在各種測試場景中表現一致。
結論
本文討論的算法將在即將發布的 Lucene 10.2 版本中提供,并將在基于該版本的 Elasticsearch 發布中可用。用戶將在這些新版本中受益于改進的合并性能和縮短的索引構建時間。這個變化是我們不斷努力使 Lucene 和 Elasticsearch 成為一個快速高效的向量搜索數據庫的一部分。
自己親自體驗向量搜索,通過這款自定進度的搜索 AI 實踐學習。你可以開始免費的云試用或立即在本地機器上嘗試 Elastic。
原文:Speeding up merging of HNSW graphs - Elasticsearch Labs
)

)




)

-MPU6050模塊詳解以及軟件IIC驅動)



![測試用例 [軟件測試 基礎]](http://pic.xiahunao.cn/測試用例 [軟件測試 基礎])

)



)