【動手學深度學習】卷積神經網絡(CNN)入門
- 1,卷積神經網絡簡介
- 2,卷積層
- 2.1,互相關運算原理
- 2.2,互相關運算實現
- 2.3,實現卷積層
- 3,卷積層的簡單應用:邊緣檢測
- 3.1,初始化輸入矩陣
- 3.2,構造卷積核用于邊緣檢測
- 3.3,通過學習得到卷積核
- 4,填充和步幅
- 4.1,填充
- 4.2,步幅
- 4.3,卷積層輸出矩陣形狀計算
- 5,多輸入通道和多輸出通道
- 5.3,多輸入通道
- 5.4,多輸出通道
- 5.5,1×1卷積層
- 6,池化層
- 6.1,最大池化和平均池化
- 6.2,實現池化操作
- 6.3,池化操作的填充和步幅
1,卷積神經網絡簡介
卷積神經網絡(CNN)的核心原理是通過局部感受野、參數共享和層級化特征提取,模仿生物視覺處理機制,自動從圖像或序列數據中學習特征。其應用廣泛,尤其在計算機視覺、語音識別、自然語言處理等領域效果顯著。CNN通過局部特征提取+層級抽象的原理,將復雜任務(如圖像分類)轉化為可學習的數學問題。其應用從早期的手寫識別發展到今天的自動駕駛、醫療診斷等關鍵領域,核心優勢在于自動特征學習和對空間/時序數據的高效處理,成為深度學習最成功的模型之一。
2,卷積層
2.1,互相關運算原理
卷積層中,輸入張量和核張量通過互相關運算生成輸出張量。 因此卷積神經網絡中的卷積層中表達的運算實際上是互相關運算。
以二維圖像為例解釋二維互相關運算:
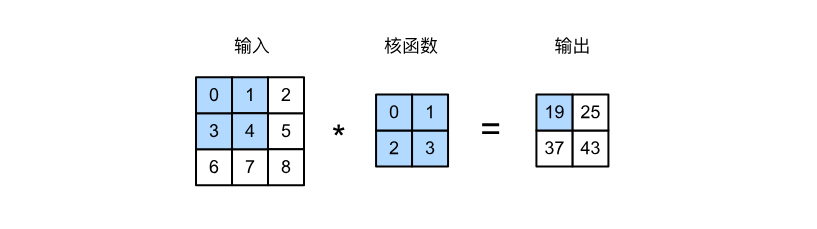
如上圖所示:
- 輸入是高度為 3、寬度為 3 的二維張量(即形狀為 3×3 );
- 卷積核的高度和寬度都是 2 ;
- 卷積的輸出形狀取決于輸入形狀和卷積核形狀。
二維互相關運算中,卷積窗口從輸入張量的左上角開始,從左到右、從上到下滑動。 當卷積窗口滑動到新一個位置時,包含在該窗口中的部分張量與卷積核張量進行按元素相乘,得到的張量再求和得到一個單一的標量值,由此我們得出了這一位置的輸出張量值。在如上例子中,輸出張量的四個元素由二維互相關運算得到。
則經過如下計算得到輸出矩陣:
0 × 0 + 1 × 1 + 3 × 2 + 4 × 3 = 19 , 1 × 0 + 2 × 1 + 4 × 2 + 5 × 3 = 25 , 3 × 0 + 4 × 1 + 6 × 2 + 7 × 3 = 37 , 4 × 0 + 5 × 1 + 7 × 2 + 8 × 3 = 43. 0\times0+1\times1+3\times2+4\times3=19,\\ 1\times0+2\times1+4\times2+5\times3=25,\\ 3\times0+4\times1+6\times2+7\times3=37,\\ 4\times0+5\times1+7\times2+8\times3=43. 0×0+1×1+3×2+4×3=19,1×0+2×1+4×2+5×3=25,3×0+4×1+6×2+7×3=37,4×0+5×1+7×2+8×3=43.
計算輸出矩陣形狀:
輸出矩陣的大小等于輸入大小 n h × n w n_h \times n_w nh?×nw?減去卷積核大小 k h × k w k_h \times k_w kh?×kw?,即:
( n h ? k h + 1 ) × ( n w ? k w + 1 ) (n_h-k_h+1) \times (n_w-k_w+1) (nh??kh?+1)×(nw??kw?+1)
因此上述例子的輸出矩陣形狀為: ( 3 ? 2 + 1 ) × ( 3 ? 2 + 1 ) = 2 × 2 (3-2+1) \times (3-2+1)=2\times2 (3?2+1)×(3?2+1)=2×2
2.2,互相關運算實現
導入相關庫:
import torch
from torch import nn
from d2l import torch as d2l
定義corr2d函數實現二維互相關運算:
"""輸入矩陣和核矩陣之間進行二維互相關運算"""
def corr2d(X, K): # K是核矩陣,h,w分別是核矩陣的高和寬h, w = K.shape# 先將輸出矩陣全部元素初始化為0(輸出矩陣的形狀由公式計算得到)Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):"""輸出矩陣 Y 的每一個位置 (i, j),從輸入矩陣 X 中取出對應的局部區域 X[i:i + h, j:j + w]即取出從輸入矩陣中的i行開始往后到(i+h)行,從j列開始往后到(j+w)列這么一個局部區域與核矩陣 K 進行元素級乘法,最后對相乘結果求和,將結果填入輸出矩陣對應的位置。此即為二維互相關運算。"""Y[i, j] = (X[i:i + h, j:j + w] * K).sum()return Y
驗證二維互相關運算:
# 輸入矩陣
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])# 核矩陣
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
corr2d(X, K)
運算結果如下:
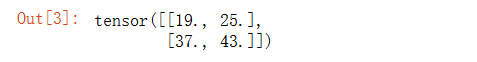
2.3,實現卷積層
卷積層對輸入和卷積核權重進行互相關運算,并在添加標量偏置之后產生輸出。 所以,卷積層中的兩個被訓練的參數是卷積核權重和標量偏置。 就像我們之前隨機初始化全連接層一樣,在訓練基于卷積層的模型時,我們也隨機初始化卷積核權重。
基于corr2d互相關運算函數實現二維卷積層:
# nn.Module 是 PyTorch 中所有神經網絡模塊的基類。
# PyTorch 中構建自己的神經網絡時,常通過繼承 nn.Module 類并定義自己的網絡層或整個網絡架構
class Conv2D(nn.Module):def __init__(self, kernel_size):super().__init__()# 隨機初始化權重(生成一個kernel_size型的隨機張量。如 kernel_size=(3, 3))self.weight = nn.Parameter(torch.rand(kernel_size))# 標量初始化為0self.bias = nn.Parameter(torch.zeros(1))# 重寫 nn.Module 的 forward 方法來定義模型的前向傳播邏輯def forward(self, x):# corr2d()二維互相關運算return corr2d(x, self.weight) + self.bias
總結:
- 卷積層將輸入和核矩陣進行交叉相關,加上偏移后得到輸出;
- 核矩陣和偏移是可學習的參數;
- 核矩陣的大小是超參數;
3,卷積層的簡單應用:邊緣檢測
介紹一個卷積層的簡單應用:通過找到像素變化的位置,來檢測圖像中不同顏色的邊緣。
3.1,初始化輸入矩陣
# 初始化矩陣:構造一個 6×8像素的黑白圖像。中間四列為黑色(0),其余像素為白色(1)。
X = torch.ones((6, 8))
# X的所有行和索引為2的列到索引為6的列(不包括索引為6的列)設置為0
X[:, 2:6] = 0
X # 輸出查看
運行結果如下:

3.2,構造卷積核用于邊緣檢測
# 構造一個高度為 1、寬度為 2的卷積核K
# 當進行互相關運算時,如果水平相鄰的兩元素相同,則輸出為零,否則輸出為非零
K = torch.tensor([[1.0, -1.0]])
對參數X(輸入)和K(卷積核)執行互相關運算:
Y = corr2d(X, K)
# 輸出結果查看
Y
運行結果如下:

注意:輸出Y中的1代表從白色到黑色的邊緣,-1代表從黑色到白色的邊緣,其他情況的輸出為 0
局限性:
現在我們將輸入X的二維圖像轉置,再進行如上的互相關運算。
# 轉置之后圖像中的邊變為橫向,而此核只能檢測垂直的
corr2d(X.t(), K)
運行結果如下:之前檢測到的垂直邊緣消失了。

因此當前手動設計的卷積核 K = torch.tensor([[1.0, -1.0]]) 只可檢測垂直邊緣,無法檢測水平邊緣。
3.3,通過學習得到卷積核
復雜數值情形下,手動設計卷積核肯定存在很大局限性。依然是垂直邊緣檢測的例子,本節介紹通過從輸入輸出對(X-Y)中學習得到卷積核。
給定X輸入和Y輸出,學習得到卷積核K
# 構造一個二維卷積層,它具有1個輸出通道和形狀為(1,2)的卷積核
"""
nn.Conv2d是二維卷積層的構造函數,在pytorch用于執行二維卷積操作
* 第一個參數表示輸入通道的數量,1表示輸入數據只有一個通道,如灰度圖像
* 第二個參數表示輸出通道的數量,1表示 卷積層將輸出一個通道的數據
* kernel_size=(1, 2)表示卷積核的大小,此處高為1,寬為2
* bias=False,這個參數指定卷積操作后不添加可學習的偏置項
"""
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)# 二維卷積層使用四維輸入和輸出格式(批量大小、通道、高度、寬度)(XY均被重塑為4維張量)
# 其中批量大小和通道數都為1
# X和Y都使用上面的XY
X = X.reshape((1, 1, 6, 8))"""
輸出矩陣高:輸入矩陣高-核矩陣高+1=6
輸出矩陣寬:輸入矩陣的寬-核矩陣寬+1=7
"""
Y = Y.reshape((1, 1, 6, 7))lr = 3e-2 # 學習率for i in range(10): # 迭代十次Y_hat = conv2d(X)# 計算損失,以便通過反向傳播算法將損失梯度傳播回網絡的每一層l = (Y_hat - Y) ** 2# 更新參數之前需要將參數梯度置為0conv2d.zero_grad()# l.sum是計算損失l中所有元素的和# 計算損失函數關于卷積層權重的梯度(此處反向傳播,將損失梯度傳播回網絡的每一層)l.sum().backward()# 迭代卷積核(梯度下降法更新卷積層權重)conv2d.weight.data[:] -= lr * conv2d.weight.grad# 每兩個bitch輸出一下lossif (i + 1) % 2 == 0:print(f'epoch {i+1}, loss {l.sum():.3f}')
運行結果如下:

根據輸出可以看出:十次迭代之后,誤差已經降到最低。
查看經過十次迭代之后,學習得到的卷積核的權重張量:
# 輸出所學卷積核的權重張量
conv2d.weight.data.reshape((1, 2))
輸出結果如下:
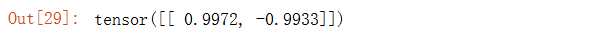
此時我們就會發現,此處經過學習得到的卷積核權重非常接近我們之前自定義的卷積核。能夠很好地應用到垂直邊緣檢測。
4,填充和步幅
通過以上學習,我們已知卷積的輸出形狀取決于輸入形狀和卷積核的形狀。
假設輸入形狀為 n h × n w n_h\times n_w nh?×nw?,卷積核形狀為 k h × k w k_h\times k_w kh?×kw?,那么輸出形狀將是 ( n h ? k h + 1 ) × ( n w ? k w + 1 ) (n_h-k_h+1) \times (n_w-k_w+1) (nh??kh?+1)×(nw??kw?+1)。
填充和步幅可用于有效地調整數據的維度。 填充可以增加輸出的高度和寬度,步幅可以減小輸出的高和寬。接下來詳細解釋填充和步幅:
4.1,填充
在應用了連續的卷積之后,我們最終得到的輸出大小會遠小于輸入大小。這是由于卷積核的寬度和高度通常大于 1 所導致的。一個 240×240 像素的圖像,經過 10 層 5×5 的卷積后,將減少到 200×200 像素。如此一來,原始圖像的邊界丟失了許多有用信息。 解決這個問題的簡單方法即為填充(padding):在輸入圖像的邊界填充元素(通常填充元素是 0)。我們將 3×3 輸入填充到 5×5,那么它的卷積輸出就會增加為到4×4 。
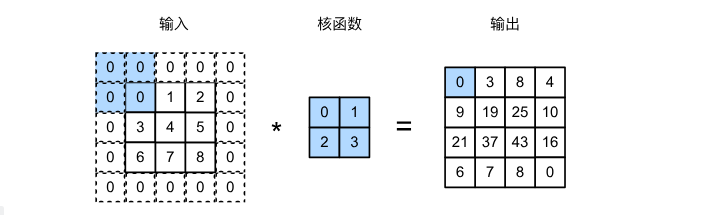
如果我們添加 p h p_h ph?行填充(大約一半在頂部,一半在底部)和 p w p_w pw?列填充(左側大約一半,右側一半),則輸出形狀將為:
( n h ? k h + p h + 1 ) × ( n w ? k w + p w + 1 ) 。 (n_h-k_h+p_h+1)\times(n_w-k_w+p_w+1)。 (nh??kh?+ph?+1)×(nw??kw?+pw?+1)。
這意味著輸出的高度和寬度將分別增加 p h p_h ph?和 p w p_w pw?。
在許多情況下,我們需要設置 p h = k h ? 1 p_h=k_h-1 ph?=kh??1和 p w = k w ? 1 p_w=k_w-1 pw?=kw??1,消去兩項,使輸入和輸出具有相同的高度和寬度。 這樣可以在構建網絡時更容易地預測每個圖層的輸出形狀。
-
假設 k h k_h kh?是奇數(此時 p h p_h ph?為偶數),我們將在高度的兩側填充 p h / 2 p_h/2 ph?/2行;
-
假設 k h k_h kh?是偶數(很少發生,萬一發生的話,此時 p h p_h ph?為奇數),則一種可能性是在輸入頂部填充 ? p h / 2 ? \lceil p_h/2\rceil ?ph?/2?行,在底部填充 ? p h / 2 ? \lfloor p_h/2\rfloor ?ph?/2?行。同理,我們填充寬度的兩側。
比如,在下面的例子中,我們創建一個高度和寬度為3的二維卷積層(即卷積核大小為3*3),并
在所有側邊填充1個像素。給定高度和寬度為8的輸入,則輸出的高度和寬度也是8。
import torch
from torch import nn
"""
comp_conv2d()對二維數據執行二維卷積操作,并返回卷積后的結果,但去除了批量大小和通道數維度,只保留了高度和寬度。此函數初始化卷積層權重,并對輸入和輸出提高和縮減相應的維數
"""
def comp_conv2d(conv2d, X):# 首先將輸入矩陣 X 重新塑形,以適應二維卷積層的輸入要求# 這里的(1,1)表示批量大小和通道數都是1# 如下是一個元組拼接操作。將元組 (1, 1) 與 X.shape 返回的元組(height, width)拼接在一起,形成新的形狀 (1, 1, height, width)X = X.reshape((1, 1) + X.shape)# 二維卷積層輸出格式為:批量大小、通道、高度、寬度。此時 Y四維Y = conv2d(X)"""返回時省略前兩個維度:批量大小和通道(只保留索引為2的元素到最后一個元素)若張量 Y 的形狀為 (batch_size, in_channels, height, width),即它是一個四維張量,那么 Y.shape[2:] 將返回一個包含 height 和 width 的元組( batch_size 和 in_channels 是前兩個維度)"""return Y.reshape(Y.shape[2:])"""
* nn.Conv2d()是二維卷積層的一個構造函數,入參可以是為輸入輸出通道數、核函數形狀、填充數、是否加入偏置項。最終返回一個conv2d實例;
* conv2d(X)表示使用Conv2d實例對輸入張量X進行卷積;其中X通常是4維的,四個維度分別代表:批量大小、通道數、高、寬前兩個參數1表示輸入和輸出的通道數都為1;
padding表示上下左右各填充一行;
請注意,這里*每邊*都填充了1行或1列,因此總共添加了2行或2列。
"""
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)# 隨機初始化一個8*8的矩陣
X = torch.rand(size=(8, 8))"""8-3+2+1=8.所以輸出Y的形狀為8*8"""
comp_conv2d(conv2d, X).shape
運行結果如下:

特殊情況下的填充處理:
卷積核的高度和寬度不相同的情況下,我們可以填充不同的高度和寬度,使得輸入和輸出具有相同的高度和寬度。
代碼示例:
# 輸入X大小依然是8*8
# 構造二維卷積層(卷積核大小是5*3;上下各填充2,左右各填充1)
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))# 輸出經過comp_conv2d計算后的形狀
# (8-5+2*2+1)×(8-3+1*2+1)=8*8
comp_conv2d(conv2d, X).shape
運行結果如下:

4.2,步幅
有時,如果我們發現原始的輸入分辨率十分冗余,我們可能希望大幅降低圖像的寬度和高度。此時步幅則可以在這類情況下提供幫助。
在計算互相關時,卷積窗口從輸入張量的左上角開始,從左向右、從上到下滑動。在前面的例子中,我們
默認每次滑動一個元素。但是,有時候為了高效計算或是縮減采樣次數,卷積窗口可以跳過中間位置,每次滑動多個元素。 可以成倍的減少輸出形狀。我們將 每次滑動元素的數量稱為步幅 (stride)。
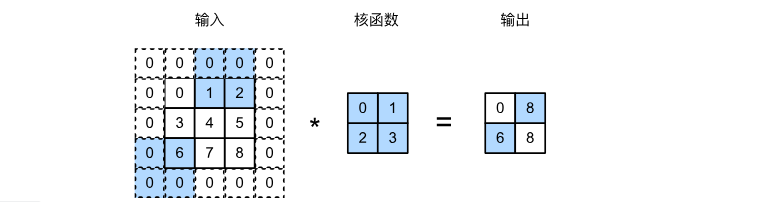
如上圖所示,可以看到,為了計算輸出中第一列的第二個元素和第一行的第二個元素,卷積窗口分別向下滑動三行和向右滑動兩列。但是,當卷積窗口繼續向右滑動兩列時,沒有輸出,除非我們添加另一列填充。
4.3,卷積層輸出矩陣形狀計算
假設輸入形狀為 n h × n w n_h\times n_w nh?×nw?,卷積核形狀為 k h × k w k_h\times k_w kh?×kw?。
無填充、步幅默認為1時,輸出矩陣形狀為:
( n h ? k h + 1 ) × ( n w ? k w + 1 ) (n_h-k_h+1) \times (n_w-k_w+1) (nh??kh?+1)×(nw??kw?+1)
添加 p h p_h ph?行填充(大約一半在頂部,一半在底部)和 p w p_w pw?列填充(左側大約一半,右側一半),步幅為1時。輸出矩陣形狀為:
( n h ? k h + p h + 1 ) × ( n w ? k w + p w + 1 ) 。 (n_h-k_h+p_h+1)\times(n_w-k_w+p_w+1)。 (nh??kh?+ph?+1)×(nw??kw?+pw?+1)。
添加 p h p_h ph?行、 p w p_w pw?列填充,設置垂直步幅 s h s_h sh?,水平步幅 s w s_w sw?時,輸出矩陣形狀為:
? n h ? k h + p h s h + 1 ? × ? n w ? k w + p w s w + 1 ? \lfloor\frac{n_h-k_h+p_h}{s_h}+1\rfloor \times \lfloor\frac{n_w-k_w+p_w}{s_w}+1\rfloor ?sh?nh??kh?+ph??+1?×?sw?nw??kw?+pw??+1?
此時輸出形狀可換算為:
? ( n h ? k h + p h + s h ) / s h ? × ? ( n w ? k w + p w + s w ) / s w ? \lfloor(n_h-k_h+p_h+s_h)/s_h\rfloor \times \lfloor(n_w-k_w+p_w+s_w)/s_w\rfloor ?(nh??kh?+ph?+sh?)/sh??×?(nw??kw?+pw?+sw?)/sw??
如果我們設置了 p h = k h ? 1 p_h=k_h-1 ph?=kh??1和 p w = k w ? 1 p_w=k_w-1 pw?=kw??1,則輸出形狀將簡化為: ? ( n h + s h ? 1 ) / s h ? × ? ( n w + s w ? 1 ) / s w ? \lfloor(n_h+s_h-1)/s_h\rfloor \times \lfloor(n_w+s_w-1)/s_w\rfloor ?(nh?+sh??1)/sh??×?(nw?+sw??1)/sw??
更進一步,如果輸入的高度和寬度可以被垂直和水平步幅整除,則輸出形狀將為: ( n h / s h ) × ( n w / s w ) (n_h/s_h) \times (n_w/s_w) (nh?/sh?)×(nw?/sw?)
代碼演示: 將高度和寬度的步幅設置為2,從而將輸入的高度和寬度減半。
# 輸入X大小依然是8*8
# stride=2表示將寬度和高度的步幅均設置為2
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)# (8-3+1*2+2)÷2向下取整后為4
# (8-3+1*2+2)÷2向下取整后為4。因此輸出形狀為4*4
comp_conv2d(conv2d, X).shape
運行結果如下:

下面是一個更復雜的例子:
# 輸入X大小依然是8*8
# 行填充0,列填充1。垂直步幅3,水平步幅4
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))# 計算輸出矩陣的形狀
# (8-3+0+3)÷3向下取整=2
# (8-5+1*2+4)÷4向下取整=2。因此2*2
comp_conv2d(conv2d, X).shape
輸出結果如下:

5,多輸入通道和多輸出通道
到目前為止,我們僅展示了單個輸入和單個輸出通道的例子。 這使得我們可以將輸入、卷積核和輸出看作二維張量。實際應用中的大多數場景下并非為單純的單通道,比如:彩色圖像具有標準的RGB通道來代表紅、綠和藍,而RGB圖像轉為1通道的灰度圖像會丟失信息。
當我們添加通道時,我們的輸入和隱藏的表示都變成了三維張量。例如,每個RGB輸入圖像具有 3×?×𝑤 的形狀。我們將這個大小為 3 的軸稱為
通道(channel)維度。
5.3,多輸入通道
當輸入中包含多個通道時,需要構造一個與輸入數據具有相同輸入通道數的卷積核。以便與輸入數據進行互相關運算。
比如,假設輸入通道數為 C i C_i Ci?,則卷積核的輸入通道數也為 C i C_i Ci?。卷積核窗口形狀設為 k h × k w k_h×k_w kh?×kw?,那么:
- C i = 1 C_i=1 Ci?=1時可以將卷積核看作形狀為 k h × K w k_h×K_w kh?×Kw?的二維張量;
- C i > 1 C_i>1 Ci?>1時,卷積核的每個輸入通道將包含形狀為 k h × K w k_h×K_w kh?×Kw?的張量,即得到形狀為 C i × k h × K w C_i×k_h×K_w Ci?×kh?×Kw?的卷積核;
由于每個輸入和卷積核都有 C i C_i Ci?個通道,我們可以對每個通道
輸入的二維張量和卷積核的二維張量進行互相關運算,再對各通道求和得到二維張量。示例如下:
以下是一個具有兩個輸入通道的二位互相關運算示例:
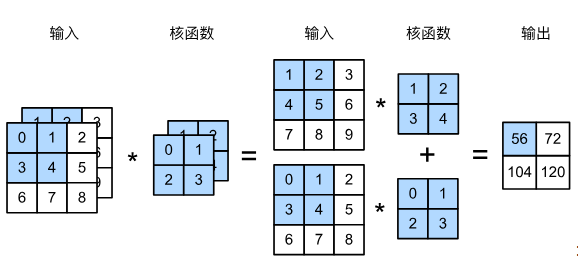
計算式子為:
( 1 × 1 + 2 × 2 + 4 × 3 + 5 × 4 ) + ( 0 × 0 + 1 × 1 + 3 × 2 + 4 × 3 ) = 56 (1\times1+2\times2+4\times3+5\times4)+(0\times0+1\times1+3\times2+4\times3)=56 (1×1+2×2+4×3+5×4)+(0×0+1×1+3×2+4×3)=56
代碼示例如下:
先定義多個輸入通道X與多個卷積核K之間的互相關運算函數
import torch
from d2l import torch as d2l# 其中corr2d()是前面節定義的二維互相關操作
def corr2d_multi_in(X, K):# 先遍歷“X”和“K”的第0個維度(通道維度),再把它們加在一起# corr2d()二維互相關操作# zip()將元素按位置配對形成一個元組的序列,創建成一個迭代器"""X和K的第一個維度即通道維度,一定是相等的,因此可以通過zip配對成功;for x, k in zip(X, K) 是遍歷zip()生成的元組序列:每次迭代中,它解包元組以獲取 x 和 k,這兩個變量分別綁定到來自 X 和 K 的當前元素。"""return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
構造輸入張量X和核張量K,驗證相關運算的輸出
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])print(X.shape) # X形狀為(2, 3, 3)
print(K.shape) # K形狀為(2, 2, 2)corr2d_multi_in(X, K)
運行結果如下:

5.4,多輸出通道
到目前為止,不論有多少輸入通道,我們還只有一個輸出通道。而實際上,在最流行的神經網絡架構中,隨著神經網絡層數的加深,我們常會增加輸出通道的維數,通過減少空間分辨率以獲得更大的通道深度。
- 用 c i c_i ci?和 c o c_o co? 分別表示輸入和輸出通道的數目, k h k_h kh?和 k w k_w kw? 為卷積核的高度和寬度;
- 為了獲得多個通道的輸出,我們可以為每個輸出通道創建一個形狀為 c i × k h × k w c_i\times k_h\times k_w ci?×kh?×kw?的三維卷積核張量,這樣
最終變為四維卷積核,形狀是 c o × c i × k h × k w c_o\times c_i\times k_h\times k_w co?×ci?×kh?×kw?; - 簡單來說就是:有多個三維卷積核,每個卷積核生成一個輸出通道。
可以認為每個輸出通道可識別特定的模式;
# 使用上面定義的K,K形狀為(2, 2, 2)則K、K+1、K+2形狀均為(2, 2, 2)
# torch.stack 的作用:沿著一個新維度將多個張量拼接起來。
# torch.stack 要求所有輸入張量必須具有相同的形狀。新維度的索引由參數 dim 指定(dim=0 表示在最前面添加維度)。
K = torch.stack((K, K + 1, K + 2), 0)# 打印K形狀
K.shape
三個輸出通道的三維卷積核,每個卷積核2個輸入通道,每個輸入通道都是2*2。因此拼接完是一個四維卷積核,形狀為(3,2,2,2),運行結果如下:

接下來對輸入張量 X 和卷積核張量 K 執行互相關運算。
def corr2d_multi_in(X, K):# 先遍歷“X”和“K”的第0個維度(通道維度),再把它們加在一起# corr2d()二維互相關操作# zip()將元素按位置配對形成一個元組的序列,創建成一個迭代器"""X和K的第一個維度即通道維度,一定是相等的,因此可以通過zip配對成功;for x, k in zip(X, K) 是遍歷zip()生成的元組序列:每次迭代中,它解包元組以獲取 x 和 k,這兩個變量分別綁定到來自 X 和 K 的當前元素。"""return sum(d2l.corr2d(x, k) for x, k in zip(X, K))# 打印出X和K
print(X)
print(K)
# 調用函數
corr2d_multi_in_out(X, K)
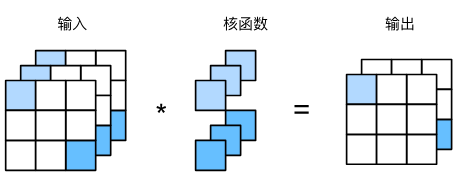
在互相關運算中,
每個輸出通道先獲取所有輸入通道,再拿對應該輸出通道的卷積核計算出結果。
- K形狀為(3,2,2,2),
三個形狀為(2,2,2)的三維卷積核,對應三個輸出通道;- X形狀為(2, 3, 3);
- 可以下圖的一個1×1的卷積核為例,類比互相關運算的計算原理;
上述代碼運行結果如下:

5.5,1×1卷積層
1×1卷積層的作用等價于全連接層。因為使用了最小窗口,1×1 卷積失去了卷積層在高度和寬度維度上識別相鄰元素間相互作用的能力。 實際上 1×1 卷積的計算發生在通道上。
1×1卷積就像是一個“信息處理器”,但它
只在通道之間做文章,不改變圖片的寬和高,只調整通道的數量。實際意義如下:
- 壓縮信息(降維):假設你有一本厚厚的書(比如100個章節),但很多章節內容重復或無關。你用1×1卷積就像請一個編輯,把100章的內容壓縮成20章,保留核心信息,去掉冗余;
- 擴展信息(升維):假設你有一張黑白照片(1個通道),想生成一張更豐富的藝術畫。1×1卷積可以幫你把1個通道擴展成10個通道,每個通道代表不同的“風格特征”(比如線條、陰影、顏色);
- 跨通道交互:讓不同通道的信息互相“交流”,生成更綜合的特征;
- …
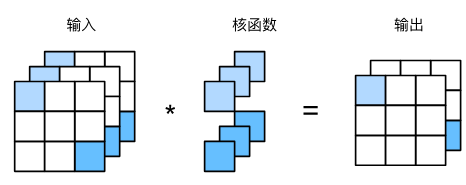
實現1×1卷積
# 采用卷積核大小為1x1的卷積。這樣的卷積操作可以簡化為輸入通道和輸出通道之間的線性變換(或稱為全連接層,但在空間維度上獨立應用)。
def corr2d_multi_in_out_1x1(X, K):# 獲取:輸入通道數、高、寬 c_i, h, w = X.shape # 獲取輸出通道數,輸出通道數和卷積核的第一個維度相等c_o = K.shape[0]# 多輸入通道X形狀為:𝑐_𝑖×𝑛_?×𝑛_𝑤。此處每個輸入通道的所有元素都被展平成一個長向量。X = X.reshape((c_i, h * w))# 多輸出通道核矩陣形狀為𝑐_𝑜×𝑐_𝑖×𝑘_?×𝑘_𝑤。此處卷積核大小為1x1,不需要額外的高寬維度。因此核矩陣形狀為𝑐_𝑜×𝑐_𝑖# K就變成了一個標準的權重矩陣,可以用于矩陣乘法K = K.reshape((c_o, c_i))# 全連接層中的矩陣乘法。由于 K 的形狀是 (c_o, c_i) 和 X 的形狀是 (c_i, h * w),結果 Y 的形狀將是 (c_o, h * w)。Y = torch.matmul(K, X)# 再reshape成形狀(c_o, h, w)return Y.reshape((c_o, h, w))
初始化輸入張量 X 和卷積核張量 K
# X 是一個形狀為 (3, 3, 3) 的張量,每個元素的值服從標準正態分布(均值 0,標準差 1)。
X = torch.normal(0, 1, (3, 3, 3))# 卷積核張量K的形狀為(2, 3, 1, 1)(分別對應輸出通道數,輸入通道數,卷積核的高寬)
K = torch.normal(0, 1, (2, 3, 1, 1))# 打印輸出查看
print(X)
print(K)
運行結果如下:
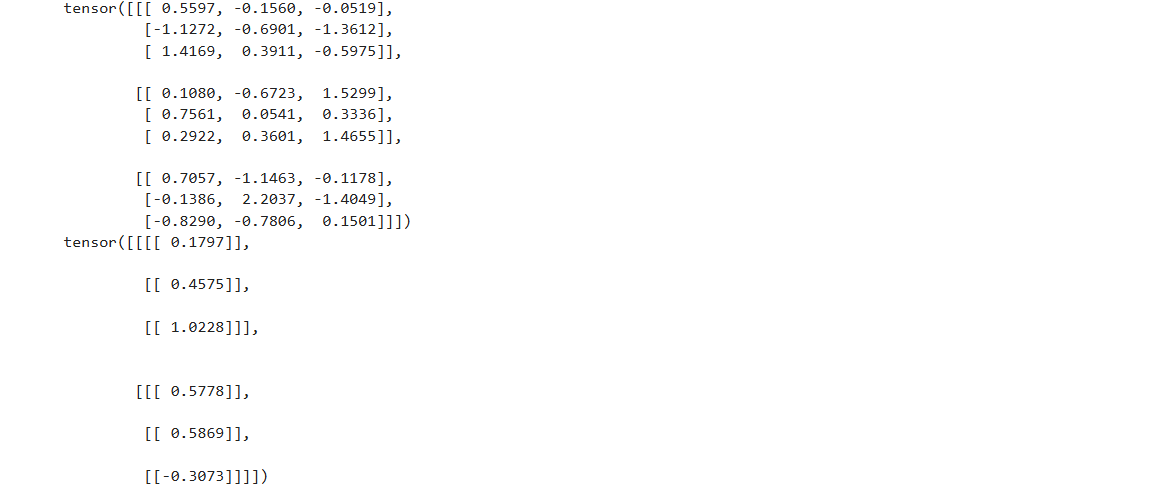
# corr2d_multi_in_out_1x1。專用于1*1的卷積核
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)# 打印輸出查看
# 由于 K 的形狀是 (c_o, c_i) 和 X 的形狀是 (c_i, h * w),結果 Y 的形狀將是 (c_o, h , w)。即二者相乘之后形狀為2×3×3
print(Y1)
print(Y2)
"""
assert 是一個內置的關鍵字,它用于在代碼中設置檢查點,以確保程序在運行時滿足特定的條件。
如果條件評估為 True,則程序會繼續執行;
如果條件評估為 False,則會觸發一個 AssertionError 異常,并且程序會中斷執行(除非異常被捕獲和處理)。
"""
# 沒有報錯說明二者結果幾乎完全一樣
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
運行結果如下:

6,池化層
正如我們在第三節,垂直邊緣檢測的例子中講的那樣:卷積對位置信息敏感,但我們理想的效果是讓卷積層兼具平移不變性。因此引入池化層(或匯聚層):降低卷積層對位置的敏感性,同時降低對空間降采樣表示的敏感性。
- 池化層的超參數有:窗口大小、填充、步幅。
6.1,最大池化和平均池化
與卷積層類似,匯聚層也由一個固定形狀的窗口組成,該窗口根據其步幅大小從輸入張量的左上角開始,從左往右、從上往下的在輸入張量內滑動。遍歷的每個位置計算一個輸出。 在匯聚窗口到達的每個位置,它計算該窗口中
輸入子張量的最大值或平均值。計算最大值或平均值是取決于使用了最大池化層還是平均池化層。
比如:輸出張量的高度為2,寬度為2。每個匯聚窗口中的最大值:
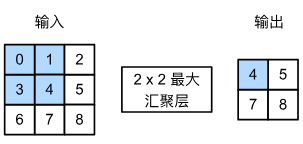
max ? ( 0 , 1 , 3 , 4 ) = 4 , max ? ( 1 , 2 , 4 , 5 ) = 5 , max ? ( 3 , 4 , 6 , 7 ) = 7 , max ? ( 4 , 5 , 7 , 8 ) = 8. \max(0, 1, 3, 4)=4,\\ \max(1, 2, 4, 5)=5,\\ \max(3, 4, 6, 7)=7,\\ \max(4, 5, 7, 8)=8.\\ max(0,1,3,4)=4,max(1,2,4,5)=5,max(3,4,6,7)=7,max(4,5,7,8)=8.
6.2,實現池化操作
導入相關庫
import torch
from torch import nn
from d2l import torch as d2l
自定義池化操作函數
# 自定義池化操作函數。X是輸入;pool_size:池化窗口大小;mode決定最大池化還是平均池化
# 假設是單通道場景下。代碼實現和卷積操作類似
def pool2d(X, pool_size, mode='max'):p_h, p_w = pool_size# 初始化輸出YY = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):if mode == 'max':Y[i, j] = X[i: i + p_h, j: j + p_w].max()elif mode == 'avg':Y[i, j] = X[i: i + p_h, j: j + p_w].mean()return Y
驗證二維最大匯聚層的輸出
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
# 打印輸入張量X的形狀
print(X.shape)# 調用函數
pool2d(X, (2, 2))
運行結果如下:

同理,驗證平均匯聚層
pool2d(X, (2, 2), 'avg')
運行結果如下:

6.3,池化操作的填充和步幅
與卷積層一樣,匯聚層也可以改變輸出形狀。和以前一樣,我們可以通過填充和步幅以獲得所需的輸出形狀。
# torch.arange(16, dtype=torch.float32)生成一個從 0 到 15(包含0,不包含16)的一維張量
# .reshape((1, 1, 4, 4)):這個方法將一維張量重新塑形為一個四維張量(批量大小、通道數、高度、寬度),實際上是一個4*4矩陣(因為前兩個參數為1)
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))# 輸出X查看
X
運行結果如下:

特別注意:默認情況下,深度學習框架中的步幅與匯聚窗口的大小相同(窗口沒有重疊) 。因此,如果我們使用形狀為(3, 3)的匯聚窗口,那么默認情況下,我們得到的步幅形狀為(3, 3)。
# MaxPool2d:是 torch.nn 模塊下的一個類,用于執行二維空間上的最大池化操作。
# pool2d = nn.MaxPool2d(3) 創建了一個 MaxPool2d 的實例,其中池化窗口的大小被設置為 3x3。
pool2d = nn.MaxPool2d(3)# 默認情況下,深度學習框架中的步幅與匯聚窗口的大小相同(窗口沒有重疊)
pool2d(X)
運行結果如下:

如果不想使用默認的填充和步幅,也可以手動設定。
# 3表示池化窗口大小3*3,stride步幅為2
# padding=1可以在輸入張量的每一個邊界上填充 1
pool2d = nn.MaxPool2d(3, padding=1, stride=2)# 函數調用
pool2d(X)
運行結果如下:

設定一個任意大小的矩形匯聚窗口,并分別設定填充和步幅的高度和寬度
# stride=(2, 3)表示步長在高度方向上是2,在寬度方向上是3。
# padding=(0, 1)表示高度方向上沒有添加填充(即填充為0),而寬度方向上添加了1個像素的填充。
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
pool2d(X)
以上為單輸入通道的池化情況,接下來我們看一下多通道場景
在處理多通道輸入數據時,池化層在每個輸入通道上單獨運算,而不是像卷積層一樣在通道上對輸入進行匯總。匯聚層的輸出通道數與輸入通道數相同。
下面,我們將在通道維度上連結張量X和X + 1,以構建具有2個通道的輸入。
# 通過cat操作將X和X+1沿指定維度1(第二個維度)進行拼接
X = torch.cat((X, X + 1), 1)
# 輸出查看
X
運行結果如下:

執行匯聚操作:匯聚后輸出通道的數量仍然是2。
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)





、雙引號( )和反引號( `)使用)
:DMP與PCP系統核心功能剖析)



)


安裝步驟)


——client子窗口功能)
-張量拼接操作)
)

