NLP方向CRF算法面試題
- 什么是CRF?CRF的主要思想是什么?
????設X與Y是隨機變量,P(Y | X)是給定條件X的條件下Y的條件概率分布,若隨機變量Y構成一個由無向圖G=(V,E)表示的馬爾科夫隨機場。則稱條件概率分布P(X | Y)為條件隨機場。CRF的主要思想統計全局概率,在做歸一化時,考慮了數據在全局的分布。
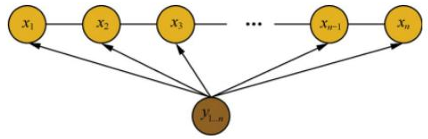
- CRF的三個基本問題是什么?
- 概率計算問題定義:給定觀測序列x和狀態序列y,計算概率P(y | x)
- 解決方法:前向計算、后向計算
- 學習計算問題定義:給定訓練數據集估計條件隨機場模型參數的問題,即條件隨機場的學習問題。
- 公式定義:利用極大似然的方法來定義目標函數
- 解決方法:隨機梯度法、牛頓法、擬牛頓法、迭代尺度法這些優化方法來求解得到參數。
- 目標:解耦模型定義,目標函數,優化方法
- 預測問題定義:給定條件隨機場P(Y | X)和輸入序列(觀測序列)x,求條件概率最大的輸出序列(標記序列)y*,即對觀測序列進行標注。
- 方法:維特比算法
- 線性鏈條件隨機場的參數化形式?
????在隨機變量X取值為X的條件下,隨機變量Y取值為y的條件概率如下: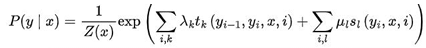 其中,
其中,
- Z(x):是規范化因子,求和是在所有可能得輸出序列上進行的。
- t_k:是定義在邊上的特征函數,稱為轉移特征,依賴于當前和前一個位置
- s_l:是定義在結點上的特征函數,稱為狀態特征,依賴于當前位置;
- CRF的優缺點是什么?
- 優點:為每個位置進行標注過程中可利用豐富的內部及上下文特征信息
- CRF模型在結合多種特征方面的存在優勢
- 避免了標記偏置問題
- CRF的性能更好,對特征的融合能力更強
- 缺點:訓練模型的時間比ME更長,且獲得的模型非常大。在一般的PC機上可能無法執行
- 特征的選擇和優化是影響結果的關鍵因素。特征選擇問題的好與壞,直接決定了系統性能的高低
- HMM與CRF的區別?
- 共性:都常用來做序列標注的建模,像詞性標注。HMM是有向圖,CRF是無向圖.
- HMM只使用了局部特征(齊次馬爾科夫假設和觀測獨立性假設),只能找到局部最優解;CRF使用了全局特征(在所有特征進行全局歸一化),可以得到全局的最優值。
- 隱馬爾可夫模型(HMM)是描述兩個序列聯合分布P(I,O)的概率模型;條件隨機場模型(CRF)是給定觀測狀態O的條件下預測狀態序列I的P(I/O)的條件概率模型。
- HMM是生成模型,CRF是判別模型。CRF包含HMM,或者說HMM是CRF的一種特殊情況。
- 生成模型與判別模型的區別?
- 生成模型:學習得到聯合概率分布P(x, y),即特征X,共同出現的概率
- 常見的生成模型:樸素貝葉斯模型,混合高斯模型,HMM模型。
- 判別模型:學習得到條件概率分布P(y | x),即在特征x出現的情況下標記y出現的概率。
- 常見的判別模型:感知機,決策樹,邏輯回歸,SVM,CRF等。
- 判別式模型:要確定一個羊是山羊還是綿羊,用判別式模型的方法是從歷史數據中學習到模型,然后通過提取這只羊的特征來預測出這只羊是山羊的概率,是綿羊的概率。
- 生成式模型:是根據山羊的特征首先學習出一個山羊的模型,然后根據綿羊的特征學習出一個綿羊的模型,然后從這只羊中提取特征,放到山羊模型中看概率是多少,再放到綿羊模型中看概率是多少,哪個大就是哪個。
NLP方向文本分類常見面試題
- 文本分類任務有哪些應用場景?
????文本分類時機器學習匯總常見的監督學習任務質疑,常見的應用場景如情感分類、新聞分類、主題分類、問答匹配、意圖識別、推斷等等。分類任務根據具體的數據集的標簽情況,還可以分為二分類、多分類、多標簽分類等。
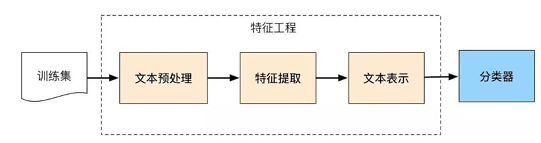
- 文本分類的具體流程?
????文本分類的流程一般包括文本預處理、特征提取、文本表示、最后分類輸出。文本處理通常需要做分詞及去除停用詞等操作,常會使用一些分詞工具,如hanlp、jieba、哈工大LTP、北大pkuseg等。
- fastText的分類過程?fastText的優點?
????fastText首先把輸入轉化為詞向量,取平均,再經過線性分類器得到類別。輸入的詞向量可以是預先訓練好的,也可以隨機初始化,跟著分類狂務一起訓練fastText是一個快速文本分類算法,與基于神經網絡的分類算法相比有兩大優點:
- fastText在保持高精度的情況下加快了訓練速度和測試速度
- fastText不需要預訓練好的詞向量,fastText會自己訓練詞向量
- fastText兩個重要的優化:使用層級Softmax提升效率、采用了char-level的n-gram作為附加特征。
- TextCNN進行文本分類的過程?
????卷積神經網絡的核心思想是捕捉局部特征,對于文本來說,局部特征就是由若干單詞組成的滑動窗口,類似于N-gram。卷積神經網絡的優勢在于能夠自動地對N-gram特征進行組合和篩選,獲得不同抽象層次的語義信息。因此文本分類任務中可以利用CNN來提取句子中類似n-gram的關鍵信息。
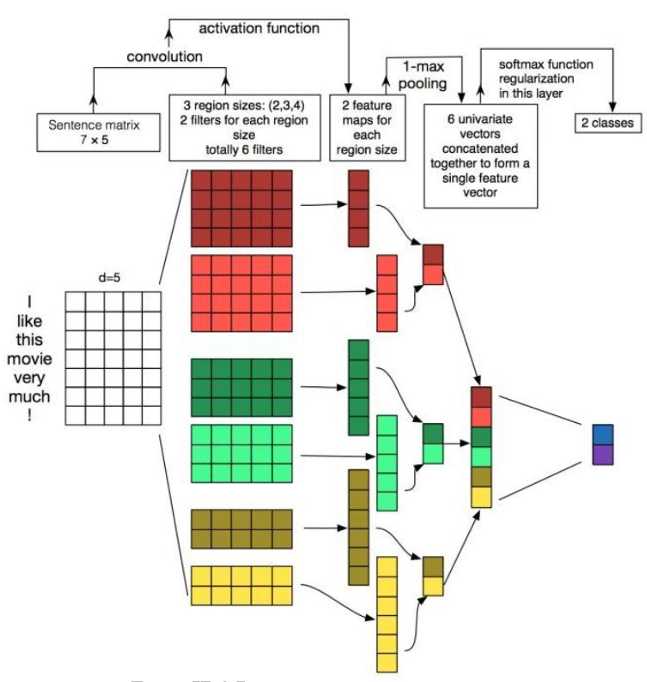
- 第一層為輸入層。將最左邊的7乘5的句子矩陣,每行是詞向量,維度=5,這個可以類比為圖像中的原始像素點了。圖中的輸入層實際采用了雙通道的形式,即有兩個n×k的輸入矩陣,其中一個用預訓練好的詞嵌入表達,并且在訓練過程中不再發生變化;另外一個也由同樣的方式初始化,但是會作為參數,隨著網絡的訓練過程發生改變。
- 第二層為卷積層。然后經過有filter_size=(2,3,4)的一維卷積層,每個filter_size有兩個輸出channel。第三層是一個1-max_pooling層,這樣不同長度句子經過pooling層之后都能變成定長的表示了。
- 最后接一層全連接的softmax層,輸出每個類別的概率。每個詞向量可以是預先在其他語料庫中訓練好的,也可以作為未知的參數由網絡訓練得到。
- TextCNN可以調整哪些參數?
- 輸入詞向量表征:詞向量表征的選取(如選word2vec還是GloVe)
- 卷積核大小:一個合理的值范圍在1~10。若語料中的句子較長,可以考慮使用更大的卷積核。另外,可以在尋找到了最佳的單個filter的大小后,嘗試在該filter的尺寸值附近尋找其他合適值來進行組合。實踐證明這樣的組合效果往往比單個最佳filter表現更出色
- feature map特征圖個數:主要考慮的是當增加特征圖個數時,訓練時間也會加長,因此需要權衡好。這個參數會影響最終特征的維度,維度太大的話訓練速度就會變慢。這里在100-600之間調參即可。當特征圖數量增加到將性能降低時,可以加強正則化效果,如將dropout率提高過0.5
- 激活函數:ReLU和tanh
- 池化策略:1-max pooling表現最佳,復雜任務選擇k-max
- 正則化項(dropout/機2):指對CNN參數的正則化,可以使用dropout或L2,但能起的作用很小,可以試下小的dropout率(<0.5),L2限制大一點
- 文本分類任務使用的評估指標有哪些?
????準確率、召回率、ROC,AUC,F1、混淆矩陣
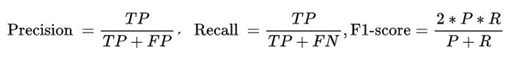
NLP方向文本摘要常見面試題
- 抽取式摘要和生成式摘要存在哪些問題?
- 抽取式摘要在語法、句法上有一定的保證,但是也面臨了一定的問題,例如:內容選擇錯誤、連貫性差、靈活性差等問題。
- 生成式摘要優點是相比于抽取式而言用詞更加靈活,因為所產生的詞可能從未在原文中出現過。但存在以下問題:
- OOV問題。源文檔語料中的詞的數量級通常會很大,但是經常使用的詞數量則相對比較固定。因此通常會根據詞的頻率過濾掉一些詞做成詞表。這樣的做法會導致生成摘要時會遇到UNK的詞。
- 摘要的可讀性。通常使用貪心算法或者beam search方法來做decoding。這些方法生成的句子有時候會存在不通順的問題。
- 摘要的重復性。這個問題出現的頻次很高。與2的原因類似,由于一些decoding的方法的自身缺陷,導致模型會在某一段連續timesteps生成重復的詞。
- 長文本摘要生成難度大。對于機器翻譯來說,NLG的輸入和輸出的語素長度大致都在一個量級上,因此NLG在其之上的效果較好。但是對摘要來說,源文本的長度與目標文本的長度通常相差很大,此時就需要encoder很好的將文檔的信息總結歸納并傳遞給decoder,decoder需要完全理解并生成句子。
- Pointer-generator network解決了什么問題?
- 指針生成網絡從兩方面針對seq-to-seq模型在生成式文本摘要中的應用做了改進。
- 第一,使用指針生成器網絡可以通過指向從源文本中復制單詞(解決OOV的問題),這有助于準確復制信息,同時保留generater的生成能力。PGN可以看作是抽取式和生成式摘要之間的平衡。通過一個門來選擇產生的單詞是來自于詞匯表,還是來自輸入序列復制。
- 第二,使用coverage跟蹤摘要的內容,不斷更新注意力,從而阻止文本不斷重復(解決重復性問題)。利用注意力分布區追蹤目前應該被覆蓋的單詞,當網絡再次注意同一部分的時候予以懲罰。
- 文本摘要有哪些應用場景?
????文本摘要技術有許多應用場景。例如,在新聞報道領域,可以使用文本摘要技術快速生成新聞摘要,使讀者可以快速了解新聞內容:在市場調查領域,可以使用文本摘要技術對大量用戶反饋進行快速分析,提取出關鍵信息,從而更好地了解市場需求;在醫學領域,可以使用文本摘要技術從海量醫學文獻中快速找到相關研究成果,以幫助醫生更好地做出診療決策。
- 幾種ROUGE指標之間的區別是什么?
- ROUGE是將待審摘要和參考摘要的元組共現統計量作為評價依據。
- ROUGE-N=每個n-gram在參考摘要和系統摘要中同現的最大次數之和/參考摘要中每個n-gram出現的次數之和
- ROUGE-L計算最長公共子序列的匹配率,L是LCS(longest common subsequence)的首字母。如果兩個句子包含的最長公共子序列越長,說明兩個句子越相似。
- Rouge-W是Rouge-L的改進版,使用了加權最長公共子序列(Weighted LongestCommon Subsequence),連續最長公共子序列會擁有更大的權重。
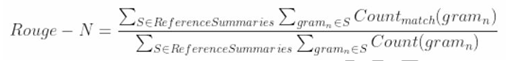
- BLEU和ROUGE有什么不同?
- BLEU是2002年提出的,而ROUGE是2003年提出的。
- BLEU的計算主要基于精確率,ROUGE的計算主要基于召回率。
- ROUGE用作機器翻譯評價指標的初衷是這樣的;在SMT(統計機器翻譯)時代,機器翻譯效果稀爛,需要同時評價翻譯的準確度和流暢度;等到MT(神經網絡機器翻譯)出來以后,神經網絡腦補能力極強,翻譯出的結果都是通順的,但是有時候容易瞎翻譯。
- ROUGE的出現很大程度上是為了解決NMT的漏翻問題(低召回率)。所以ROUGE只適合評價NMT,而不適用于SMT,因為它不管候選譯文流不流暢。
- BLEU需要計算譯文1-gram,2-gram,.,N-gram的精確率,一般N設置為4即可,公式中的Pn指n-gram的精確率。Wn指n-gram的權重,一般設為均勻權重,即對于任意n都有Wn=1/N。BP是懲罰因子,如果譯文的長度小于最短的參考譯文,則BP小于1。BLEU的1-gram精確率表示譯文忠于原文的程度,而其他n-gram表示翻譯的流暢程度。
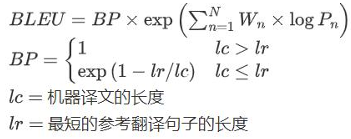
海康-CV算法工程師實習面試題
- YOLO的正負樣本是什么?
????在YOLO算法中,目標物體被定義為一組邊界框,也稱為錨框(anchor box)。每個錨框都由其中心點坐標、寬度和高度來定義。對于每個錨框,計算它與所有目標物體的loU(交并比)值。如果U大于某個閾值(如0.5),則將該錨框標記為正樣本,否則將其標記為負樣本。
- 模型壓縮和加速的方法有哪些?
- 參數剪枝(Parameter Pruning):別除模型中冗余的參數,減少模型的大小。通常情況下,只有很少一部分參數對模型的性能貢獻較大,其余參數對性能的貢獻較小或沒有貢獻,因此可以刪除這些冗余參數。
- 量化(Quantization):將浮點型參數轉換為更小的整數或定點數,從而減小模型大小和內存占用,提高計算效率。
- 知識蒸餾(Knowledge Distillation):利用一個較大、較準確的模型的預測結果來指導一個較小、較簡單的模型學習。這種方法可以減小模型的復雜度,提高模型的泛化能力和推理速度。
- 網絡剪枝(Network Pruning):刪除模型中冗余的神經元,從而減小模型的大小。與參數剪枝不同,網絡剪枝可以刪除神經元而不會刪除對應的參數。
- 蒸餾對抗網絡(Distil訓ation Adversarial Networks):在知識蒸餾的基礎上,通過對抗訓練來提高模型的魯棒性和抗干擾能力。
- 模型量化(Model Quantization):將模型的權重和激活函數的精度從32位浮點數減少到更小的位數,從而減小模型的大小和計算開銷。
- 層次化剪枝(Layer–wise Pruning):對模型的不同層進行不同程度的剪枝,以實現更高效的模型壓縮和加速。
- 低秩分解(Low-Rank Decomposition):通過將一個較大的權重矩陣分解為幾個較小的權重矩陣,從而減少計算開銷。
- 卷積分解(Convolution Decomposition):將卷積層分解成幾個更小的卷積層或全連接層,以減小計算開銷。
- 網絡剪裁(Network Trimming):通過對模型中一些不重要的連接進行剪裁,從而減小計算開銷。
- 半精度是什么?
????半精度是指使用16位二進制浮點數(half-precision floating point.)來表示數字的數據類型,可以加速計算和減小內存占用。
- 半精度的理論原理是什么?
????半精度使用16位二進制浮點數來表示數字,其中1位表示符號位,5位表示指數,10位表示尾數。相比于單精度(32位)和雙精度(64位)的浮點數,半精度的表示范圍和精度更小,但可以通過降低內存占用和加速計算來實現高效的運算。
- 你了解的知識蒸餾模型有哪些?
- FitNets:使用一個大型模型作為教師模型來指導一個小型模型的訓練。
- Hinton蒸餾:使用一個大型模型的輸出作為標簽來指導一個小型模型的訓練。
- Borm-Again Network(BAN):使用一個已經訓練好的模型來初始化一個新模型,然后使用少量的數據重新訓練模型。
- TinyBERT:使用一個大型BERT模型作為教師模型來指導一個小型BERT模型的訓練。
- 自監督、半監督、無監督的區別?
- 自監督學習:使用輸入數據的某些屬性(例如,數據本身的結構或某些隱含信息)來作為監督信號,從而避免了手動標注的成本。例如,圖像數據可以通過旋轉、剪切等方式進行擴增,并使用數據自身的變換作為監督信號來訓練模型。
- 半監督學習:是指使用有標注和無標注的數據來訓練模型。通常情況下,有標注的數據只是無標注數據的一個子集。通過同時使用有標注和無標注數據進行訓練,可以提高模型的性能和泛化能力。
- 無監督學習:是指在沒有標注數據的情況下,通過分析數據本身的結構、模式和相關性來學習模型。無監督學習的目標是從數據中發現一些有用的結構,例如聚類、降維、密度估計等。常見的無監督學習方法包括自編碼器、生成對抗網絡、變分自編碼器等。與監督和半監督學習不同,無監督學習不需要手動標注數據,因此可以處理大量未標注的數據,從而提高數據利用率和模型性能。
ASCLL娛樂篇5)







入門指南:用Web開發的視角理解下一代AI引擎)





)
)



