內容來源:小林coding
本文是對小林coding的TPC流量控制的精簡總結
什么是流量控制
發送方不能無腦的發數據給接收方,要考慮接收方處理能力
如果一直無腦的發數據給對方,但對方處理不過來,那么就會導致觸發重發機制
從而導致網絡流量的無端的浪費
為了解決這種現象發生,TCP 提供一種機制可以讓「發送方」根據「接收方」的實際接收能力控制發送的數據量,這就是所謂的流量控制
操作系統緩沖區與滑動窗口的關系
前面的流量控制例子,我們假定了發送窗口和接收窗口是不變的
但是實際上,發送窗口和接收窗口中所存放的字節數,都是放在操作系統內存緩沖區中的
而操作系統的緩沖區,會被操作系統調整
當應用進程沒辦法及時讀取緩沖區的內容時,也會對我們的緩沖區造成影響
操作系統緩沖區是如何影響發送窗口和接收窗口的呢?
例子一:應用程序沒有及時讀取緩存
當應用程序沒有及時讀取緩存時,發送窗口和接收窗口的變化。
考慮以下場景:
- 客戶端作為發送方,服務端作為接收方,發送窗口和接收窗口初始大小為 360;
- 服務端非常的繁忙,當收到客戶端的數據時,應用層不能及時讀取數據
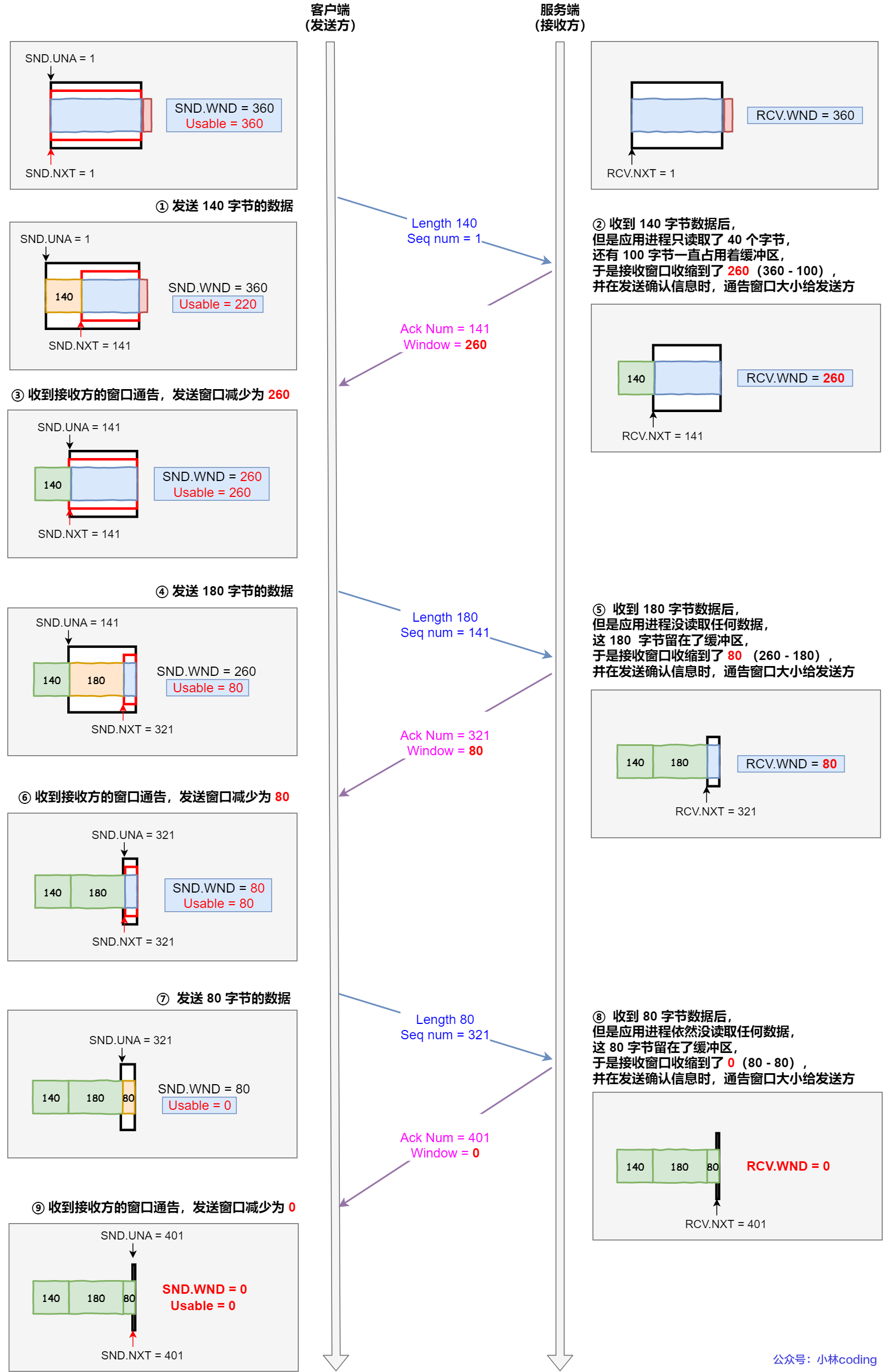
根據上圖的流量控制,說明下每個過程:
- 客戶端發送 140 字節數據后,可用窗口變為 220(360 - 140)。
- 服務端收到 140 字節數據,但是服務端非常繁忙,應用進程只讀取了 40 個字節,還有 100 字節占用著緩沖區,于是接收窗口收縮到了 260(360 - 100),最后發送確認信息時,將窗口大小通告給客戶端。
- 客戶端收到確認和窗口通告報文后,發送窗口減少為 260。
- 客戶端發送 180 字節數據,此時可用窗口減少到 80。
- 服務端收到 180 字節數據,但是應用程序沒有讀取任何數據,這 180 字節直接就留在了緩沖區,于是接收窗口收縮到了 80(260 - 180),并在發送確認信息時,通過窗口大小給客戶端。
- 客戶端收到確認和窗口通告報文后,發送窗口減少為 80。
- 客戶端發送 80 字節數據后,可用窗口耗盡。
- 服務端收到 80 字節數據,但是應用程序依然沒有讀取任何數據,這 80 字節留在了緩沖區,于是接收窗口收縮到了 0,并在發送確認信息時,通過窗口大小給客戶端。
- 客戶端收到確認和窗口通告報文后,發送窗口減少為 0。
簡單總結
1.應用進程沒有及時讀取部分數據,導致數據暫時留在了緩沖區
2.為了讓接收窗口能成功我們緩沖區中還沒讀取的數據,所以我們的接收窗口要變小,告訴發送端我們不能再接收大于這個量的數據了(接收大于這個量的數據我們會丟失)
3.然后我們把接收端改變的窗口大小發送給發送端,發送窗口大小減少
可見最后窗口都收縮為 0 了,也就是發生了窗口關閉。
當發送方可用窗口變為 0 時,發送方實際上會定時發送窗口探測報文,以便知道接收方的窗口是否發生了改變
例子二:系統資源緊張然后減少了接收緩沖區大小,導致數據包丟失
當服務端系統資源非常緊張的時候,操作系統可能會直接減少了接收緩沖區大小
這時應用程序又無法及時讀取緩存數據,那么這時候就有嚴重的事情發生了,會出現數據包丟失的現象
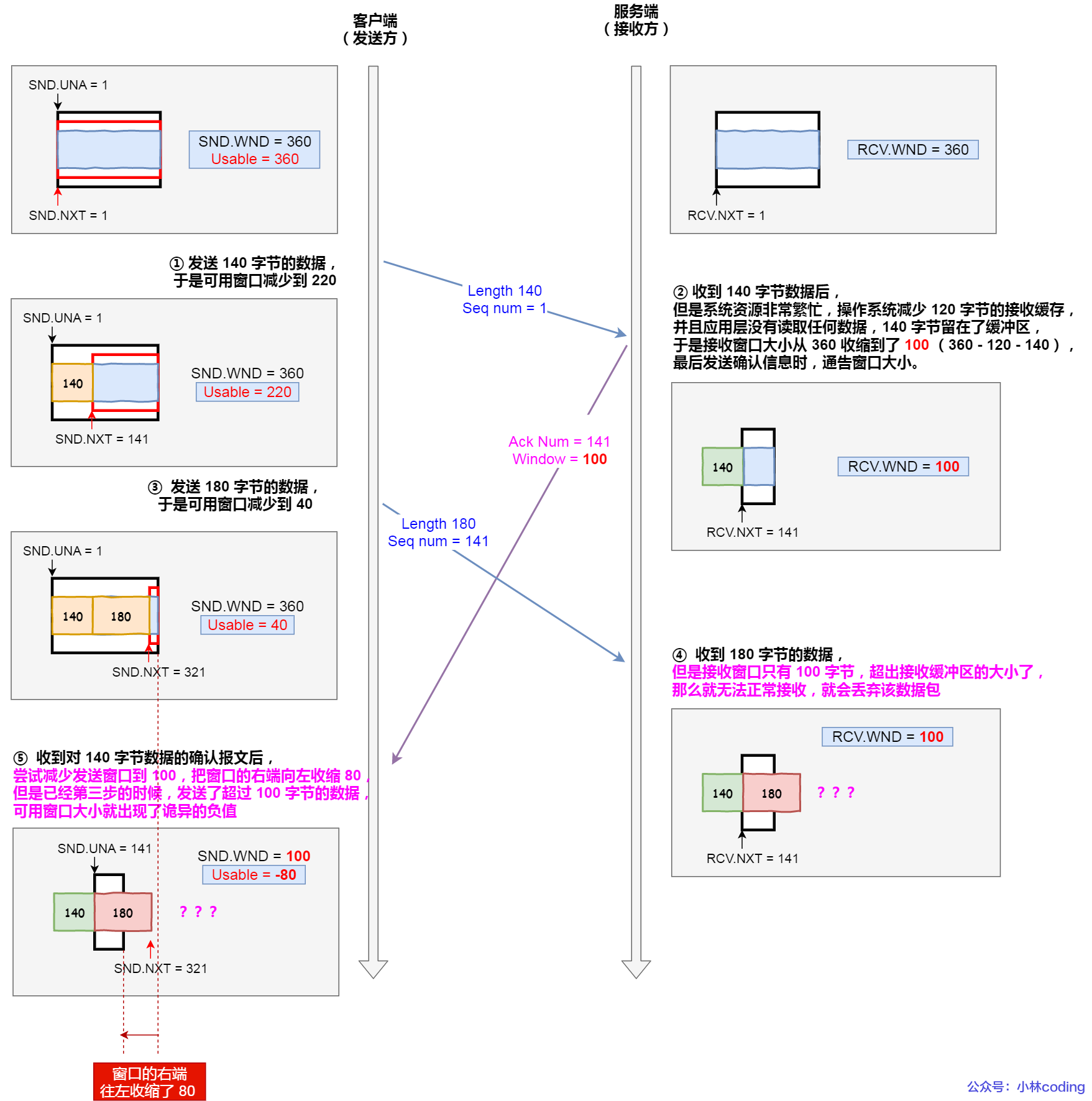
說明下每個過程:
- 客戶端發送 140 字節的數據,于是可用窗口減少到了 220。
- 服務端因為現在非常的繁忙,操作系統于是就把接收緩存減少了 120 字節,當收到 140 字節數據后,又因為應用程序沒有讀取任何數據,所以 140 字節留在了緩沖區中,于是接收窗口大小從 360 收縮成了 100,最后發送確認信息時,通告窗口大小給對方。
- 此時客戶端因為還沒有收到服務端的通告窗口報文,所以不知道此時接收窗口收縮成了 100,客戶端只會看自己的可用窗口還有 220,所以客戶端就發送了 180 字節數據,于是可用窗口減少到 40。
- 服務端收到了 180 字節數據時,發現數據大小超過了接收窗口的大小,于是就把數據包丟失了。
- 客戶端收到第 2 步時,服務端發送的確認報文和通告窗口報文,嘗試減少發送窗口到 100,把窗口的右端向左收縮了 80,此時可用窗口的大小就會出現詭異的負值。
所以,如果發生了先減少緩存,再收縮窗口,就會出現丟包的現象
為了防止這種情況發生,TCP 規定是不允許同時減少緩存又收縮窗口的
而是采用先收縮窗口,過段時間再減少緩存
這樣就可以避免了丟包情況
窗口關閉
什么是窗口關閉
在前面我們都看到了,TCP 通過讓接收方指明希望從發送方接收的數據大小(窗口大小)來進行流量控制
如果窗口大小為 0 時,就會阻止發送方給接收方傳遞數據,直到窗口變為非 0 為止
這就是窗口關閉
窗口關閉的潛在危險(ACK報文丟失導致發送方一直等待非0窗口通知)
接收方向發送方通告窗口大小時,是通過 ACK 報文來通告的
那么,當發生窗口關閉時,接收方處理完數據后,會向發送方通告一個窗口非 0 的 ACK 報文
如果這個通告窗口的 ACK 報文在網絡中丟失了,那麻煩就大了
這會導致發送方一直等待接收方的非 0 窗口通知,接收方也一直等待發送方的數據
如不采取措施,這種相互等待的過程,會造成了死鎖的現象
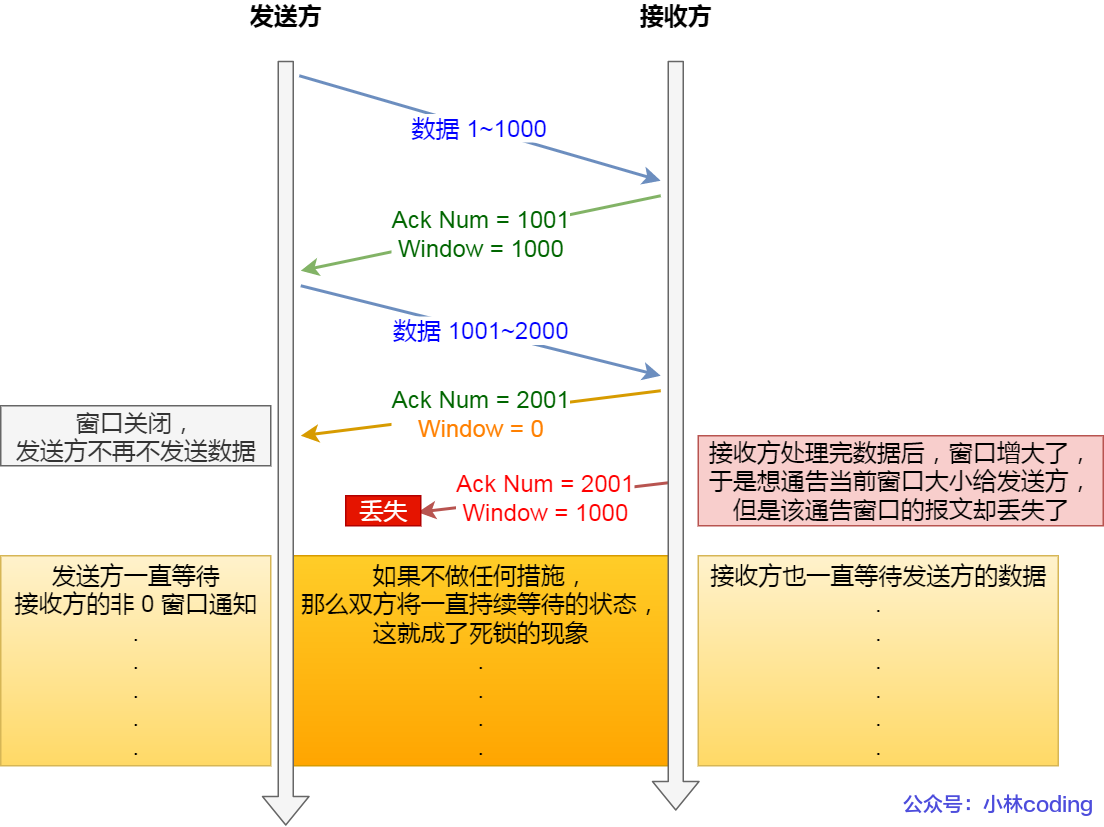
TCP是如何解決窗口關閉時潛在的死鎖現象的(通過持續計數器)
為了解決這個問題,TCP 為每個連接設有一個持續定時器
只要 TCP 連接一方收到對方的零窗口通知,就啟動持續計時器。
如果持續計時器超時,就會發送窗口探測(Window probe)報文
而對方在確認這個探測報文時,給出自己現在的接收窗口大小
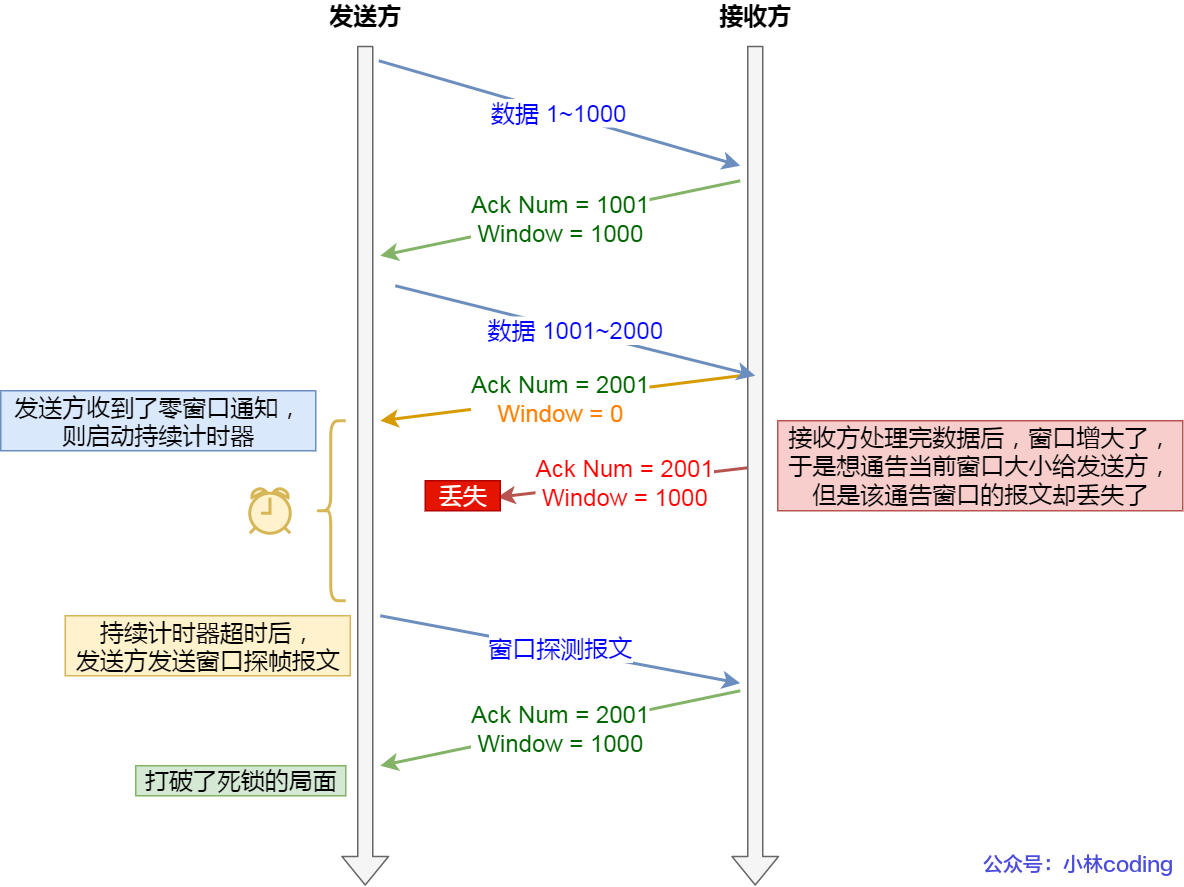
- 如果接收窗口仍然為 0,那么收到這個報文的一方就會重新啟動持續計時器;
- 如果接收窗口不是 0,那么死鎖的局面就可以被打破了
窗口探測的次數一般為 3 次,每次大約 30 - 60 秒(不同的實現可能會不一樣)
如果 3 次過后接收窗口還是 0 的話,有的 TCP 實現就會發 RST 報文來中斷連接
糊涂窗口綜合癥
什么是糊涂窗口綜合癥
如果接收方太忙了來不及取走接收窗口里的數據,那么就會導致發送方的發送窗口越來越小。
到最后,如果接收方騰出幾個字節并告訴發送方現在有幾個字節的窗口
而發送方會義無反顧地發送這幾個字節
這就是糊涂窗口綜合癥(接收方一有空間,發送方就會拼盡全力發送去爭奪接收方那一點空間)
糊涂窗口綜合癥帶來的問題
要知道,我們的 TCP + IP 頭有 40 個字節,為了傳輸那幾個字節的數據,要搭上這么大的開銷,這太不經濟了
就好像一個可以承載 50 人的大巴車,每次來了一兩個人,就直接發車
除非家里有礦的大巴司機,才敢這樣玩,不然遲早破產
要解決這個問題也不難,大巴司機等乘客數量超過了 25 個,才認定可以發車
糊涂窗口綜合癥的場景例子
現舉個糊涂窗口綜合癥的栗子,考慮以下場景:
接收方的窗口大小是 360 字節,但接收方由于某些原因陷入困境,假設接收方的應用層讀取的能力如下:
- 接收方每接收 3 個字節,應用程序就只能從緩沖區中讀取 1 個字節的數據(每次只能讀三分之一);
- 在下一個發送方的 TCP 段到達之前,應用程序還從緩沖區中讀取了 40 個額外的字節;
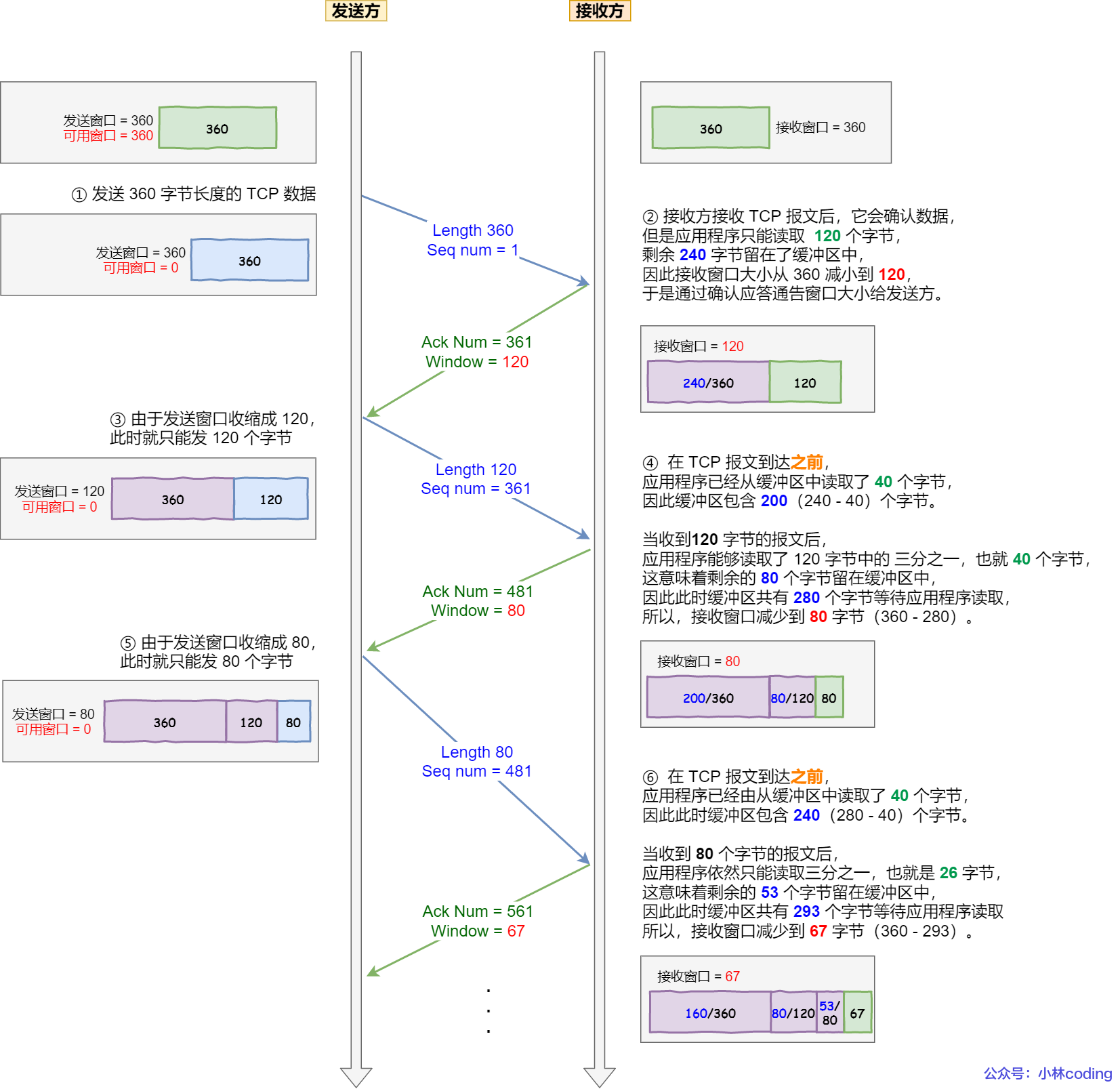
每個過程的窗口大小的變化,在圖中都描述的很清楚了,可以發現窗口不斷減少了,并且發送的數據都是比較小的了。
總結:也就是我們的窗口不斷減小,導致我們能發送的數據都在不斷減小,用更多的請求發更少的數據造成了資源浪費
所以,糊涂窗口綜合癥的現象是可以發生在發送方和接收方:
- 接收方可以通告一個小的窗口
- 而發送方可以發送小數據
如何解決糊涂窗口綜合癥
要解決糊涂窗口綜合癥,就要同時解決上面兩個問題:
- 讓接收方不通告小窗口給發送方
- 讓發送方避免發送小數據
MSS(Maximum Segment Size):最大報文段長度,指的是 TCP 報文段中數據部分的最大長度。它決定了每次傳輸的數據塊大小,與網絡傳輸效率相關。
緩存空間:接收方用于存儲接收到但尚未被應用程序讀取的數據的內存空間
如何讓接收方不通告小窗口
接收方通常的策略如下:
當「窗口大小」小于 min (MSS,緩存空間 / 2),也就是小于 MSS 與 1/2 緩存大小中的最小值時 就會向發送方通告窗口為 0,也就阻止了發送方再發數據過來。
?
等到接收方處理了一些數據后,窗口大小 >=MSS,或者接收方緩存空間有一半可以使用 就可以把窗口打開讓發送方發送數據過來
如何讓發送方避免發送小數據
發送方通常的策略如下:
使用 Nagle 算法,該算法的思路是延時處理,只有滿足下面兩個條件中的任意一個條件,才可以發送數據:
- 條件一:要等到窗口大小 >= MSS 并且數據大小 >= MSS
- 條件二:收到之前發送數據的 ack 回包
只要上面兩個條件都不滿足,發送方一直在囤積數據,直到滿足上面的發送條件
Nagle 偽代碼如下:
if 有數據要發送 {if 可用窗口大小 >= MSS and 可發送的數據 >= MSS {立刻發送MSS大小的數據} else {if 有未確認的數據 {將數據放入緩存等待接收ACK} else {立刻發送數據}}
}PS:如果接收方不能滿足「不通告小窗口給發送方」,那么即使開了 Nagle 算法,也無法避免糊涂窗口綜合癥
因為如果對端 ACK 回復很快的話(達到 Nagle 算法的條件二),Nagle 算法就不會拼接太多的數據包,這種情況下依然會有小數據包的傳輸,網絡總體的利用率依然很低。
所以,接收方得滿足「不通告小窗口給發送方」+ 發送方開啟 Nagle 算法,才能避免糊涂窗口綜合癥
另外,Nagle 算法默認是打開的,如果對于一些需要小數據包交互的場景的程序,比如,telnet 或 ssh 這樣的交互性比較強的程序,則需要關閉 Nagle 算法。
可以在 Socket 設置 TCP_NODELAY 選項來關閉這個算法(關閉 Nagle 算法沒有全局參數,需要根據每個應用自己的特點來關閉)
setsockopt(sock_fd, IPPROTO_TCP, TCP_NODELAY, (char *)&value, sizeof(int));簡單總結一下流量控制
什么是流量控制
發送方不能無腦的發數據給接收方,要考慮接收方處理能力
不然就會導致觸發重發機制,造成網絡流量的無端浪費
發送窗口和接收窗口中所存放的字節數,都是放在操作系統內存緩沖區中的,所以說和緩沖區大小有關
操作系統緩沖區影響發送窗口和接收窗口(未及時讀取or資源緊張導致窗口收縮)
應用程序沒有及時讀取緩存
因為應用層沒有及時讀取數據導致我們的接收窗口的量不斷減少
因為接收窗口不斷減少,導致我們的發送窗口量不斷減少
系統資源緊張然后減少了接收緩沖區大小,導致數據包丟失
如果發生了先減少緩存,再收縮窗口,就會出現丟包的現象
為了防止這種情況發生,TCP 規定是不允許同時減少緩存又收縮窗口的
而是采用先收縮窗口,過段時間再減少緩存
這樣就可以避免了丟包情況
窗口關閉
什么是窗口關閉
如果窗口大小為 0 時,就會阻止發送方給接收方傳遞數據,直到窗口變為非 0 為止
窗口關閉的危險
當發生窗口關閉時,接收方處理完數據后,會向發送方通告一個窗口非 0 的 ACK 報文,如果這個通告窗口的 ACK 報文在網絡中丟失了,這會導致發送方一直等待接收方的非 0 窗口通知,接收方也一直等待發送方的數據
如不采取措施,這種相互等待的過程,會造成了死鎖的現象
TCP是如何解決窗口關閉時潛在的死鎖現象的(通過持續計數器)
TCP 為每個連接設有一個持續定時器
只要 TCP 連接一方收到對方的零窗口通知,就啟動持續計時器
如果持續計時器超時,就會發送窗口探測(Window probe)報文
- 如果接收窗口仍然為 0,那么收到這個報文的一方就會重新啟動持續計時器;
- 如果接收窗口不是 0,那么死鎖的局面就可以被打破了
窗口探測的次數一般為 3 次,每次大約 30 - 60 秒(不同的實現可能會不一樣)
如果 3 次過后接收窗口還是 0 的話,有的 TCP 實現就會發 RST 報文來中斷連接
窗口糊涂綜合癥
什么是窗口糊涂綜合征
(接收方一有空間,發送方就會拼盡全力發送去爭奪接收方那一點空間)
窗口糊涂綜合征帶來的問題
太浪費了,那么點空間我們還拼盡全力去發送還發送不完全
一個可以承載 50 人的大巴車,每次來了一兩個人,就直接發車
除非家里有礦的大巴司機,才敢這樣玩,不然遲早破產
要解決這個問題也不難,大巴司機等乘客數量超過了 25 個,才認定可以發車
糊涂窗口綜合癥是怎么發生的
糊涂窗口綜合癥的現象是可以發生在發送方和接收方:
- 接收方可以通告一個小的窗口
- 而發送方可以發送小數據
如何解決糊涂窗口綜合征
兩個問題,兩個概念
我們要解決兩個問題:
1.讓接收方不通告小窗口給發送方
2.讓發送方避免發送小數據
兩個概念
1.MSS(Maximum Segment Size):最大報文段長度,指的是 TCP 報文段中數據部分的最大長度。它決定了每次傳輸的數據塊大小,與網絡傳輸效率相關
2.緩存空間:接收方用于存儲接收到但尚未被應用程序讀取的數據的內存空間
如何讓接收方不通告小窗口
當「窗口大小」小于 min (MSS,緩存空間 / 2),也就是小于 MSS 與 1/2 緩存大小中的最小值時 就會向發送方通告窗口為 0,也就阻止了發送方再發數據過來。
?
等到接收方處理了一些數據后,窗口大小 >=MSS,或者接收方緩存空間有一半可以使用 就可以把窗口打開讓發送方發送數據過來
如何讓發送方避免發送小數據
使用 Nagle 算法,該算法的思路是延時處理,只有滿足下面兩個條件中的任意一個條件,才可以發送數據:
- 條件一:要等到窗口大小 >= MSS 并且數據大小 >= MSS
- 條件二:收到之前發送數據的 ack 回包
PS:如果接收方不能滿足「不通告小窗口給發送方」,那么即使開了 Nagle 算法,也無法避免糊涂窗口綜合癥
因為如果對端 ACK 回復很快的話(達到 Nagle 算法的條件二),Nagle 算法就不會拼接太多的數據包,這種情況下依然會有小數據包的傳輸,網絡總體的利用率依然很低。
所以,接收方得滿足「不通告小窗口給發送方」+ 發送方開啟 Nagle 算法,才能避免糊涂窗口綜合癥

)
)





)
調試ros2節點)
,源碼可白嫖!)



:QMetaObject::invokeMethod的使用和實現原理)




