目錄
Browser Use是什么?
Playwright簡介
框架設計的核心目標與原則
Playwright 在 UI 自動化測試中的優勢
如何高效攔截錯誤
實現視頻錄制
UI自動化框架設計的挑戰
測試框架的結構與模塊化設計
自動化測試不是銀彈
走進Browser Use
橫空出世的背景與意義
核心功能介紹
Browser Use的核心原理
Browser Use實戰示例
Briwser Uer的局限性和挑戰
持續關注和學習
小結
隨著AI的飛速發展,各種創新的AI自動化測試工具如雨后春筍般涌現,為軟件測試領域帶來了全新的活力和可能性。
自動化測試作為保障軟件質量的關鍵手段,正經歷著一場由AI驅動的深刻變革。在這場變革中,Github中一個高達51K Stars(截止2025.4.1)的Browser Use項目猶如一顆璀璨的新星,脫穎而出。

Browser Use是什么?
Browser Use是基于Playwright的增強工具,專注于將AI代理與瀏覽器自動化結合,通過簡化操作和擴展功能提升了開發效率。
具體來說,Browser Use圍繞Playwright做了以下增強:
- AI驅動的自動化能力:通過集成GPT-4、Gemini等大模型,用戶可以直接用自然語言描述任務,Browser Use自動生成Playwright腳本并執行。
- 視覺與HTML結合:同時分析網頁的視覺布局和HTML結構,幫助AI更精準理解頁面元素,處理動態渲染內容。
- 多標簽頁自動化:支持自動管理多個瀏覽器標簽頁,并行處理復雜工作流(如同時監控多個頁面數據)。
- 持久化會話:允許保持瀏覽器窗口長期運行,保存歷史記錄和狀態,方便調試和狀態復用。
- 自定義瀏覽器集成:直接連接用戶本地的Chrome等瀏覽器實例,無需重新登錄或處理認證問題。
- 自動重試機制:在操作失敗時自動嘗試恢復(如重新加載頁面、調整點擊位置等),提升自動化腳本的魯棒性。
- 錯誤日志與追蹤:記錄詳細的操作日志和錯誤信息,便于定位問題。
- 預置動作庫:封裝了Playwright的底層API,提供如“點擊元素”“滾動到指定位置”等高階操作接口,簡化代碼編寫。
- 自定義動作擴展:支持添加用戶自定義動作(如保存數據到數據庫、觸發通知等),適應多樣化場景。
- 多模型兼容性:除了OpenAI,還支持Anthropic、DeepSeek、Ollama等模型,用戶可按需選擇。
- 低成本方案適配:提供硅基流動等低成本模型的接入選項,降低AI代理的使用門檻。
- 結構化數據提取:自動從網頁中提取表格、列表等結構化數據,減少手動解析代碼的編寫。
- 上下文關聯操作:記錄用戶點擊元素的XPath路徑,確保后續操作的一致性(如重復執行相同流程)。
Browser Use通過自然語言交互、智能化錯誤恢復、多模型支持等特性,降低了瀏覽器自動化的技術門檻,同時擴展了復雜場景(如多標簽并行、長會話任務)的處理能力。對于需要快速實現自動化且對穩定性要求較高的項目(如數據爬蟲、自動化測試),Browser Use提供了更高效的解決方案。
Playwright簡介
如何設計一個UI自動化測試框架,特別是如何利用Playwright這一現代化工具,結合實踐中的挑戰和未來趨勢,幫助團隊構建更為高效的自動化測試體系是自動化測試成功的關鍵。
框架設計的核心目標與原則
在設計 UI 自動化測試框架時,核心目標在于提升測試效率、增強可維護性,并確保框架具備良好的擴展能力。一個高質量的測試框架不僅能加快測試執行速度,還要保證測試用例的高復用性,同時確保測試結果的穩定可靠。在構建過程中,以下設計原則至關重要:
簡潔性
框架應當保持精簡,避免不必要的復雜性。優先滿足核心需求,而非追求面面俱到的完美設計。
可復用性
測試框架應支持測試用例在不同場景中復用,以減少重復代碼,提高開發效率。
穩定性
框架需要具備較強的穩定性,能夠適應 UI 變更及環境波動,確保測試流程的可靠性和健壯性。
可擴展性
隨著項目的發展,框架應具備靈活擴展的能力,以適應新的業務需求。架構設計應提前規劃好,便于后續功能模塊的無縫集成。
Playwright 在 UI 自動化測試中的優勢
在眾多 UI 自動化測試工具中,Playwright 以其強大的功能和高效的執行能力脫穎而出,成為測試工程師的優選方案。相比傳統工具(如 Selenium),Playwright 具備諸多優勢,尤其適用于現代 Web 應用的 UI 自動化測試。
跨瀏覽器兼容性
Playwright 原生支持 Chromium、Firefox 和 WebKit,無需額外配置,即可在多個瀏覽器環境中運行測試,極大提升了跨瀏覽器測試的便捷性。
高效且穩定
由于 Playwright 直接與瀏覽器通信,其測試執行速度快于 Selenium,并且在處理復雜 JavaScript 交互時表現更為穩定,減少了因元素加載或異步操作導致的測試失敗。
豐富的 API 支持
Playwright 提供全面的 API,涵蓋截圖、視頻錄制、網絡攔截、瀏覽器上下文管理等功能,使自動化測試更加靈活,可滿足多種復雜測試場景。其強大的功能將在下文詳細介紹。
如何高效攔截錯誤
可能有同學說,出現錯誤時對頁面截圖很容易,類似的selenium也可以實現。但是達到同樣的效果,playwright可能會更加簡便,示例代碼:
from playwright.sync_api import sync_playwright, TimeoutError
def run(playwright):browser = playwright.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()try:# 這里放置你的測試代碼page.goto("https://example.com")# 假設這里有一個會導致異常的操作element = page.locator("non-existing-element").click(timeout=5000)except TimeoutError as e:# 當元素未找到時,捕獲異常并保存截圖page.screenshot(path="error_screenshot.png")print(f"An error occurred: {e}")finally:# 無論是否發生異常,都要確保關閉瀏覽器上下文context.close()browser.close()
with sync_playwright() as playwright:run(playwright)在這個例子中,如果定位到不存在的元素時觸發了TimeoutError異常,則會捕捉該異常并保存一個名為error_screenshot.png的截圖。
實現視頻錄制
要錄制測試過程中的視頻,需要在創建瀏覽器上下文時,通過 record_video_dir 參數指定視頻的存儲路徑。測試完成后,調用 context.close() 方法,以確保視頻成功保存。以下示例演示了具體的實現方式:
from playwright.sync_api import sync_playwright
def run(playwright):browser = playwright.chromium.launch(headless=False)context = browser.new_context(record_video_dir="videos/") # 指定視頻存儲目錄page = context.new_page()page.goto("https://example.com")# 執行需要錄制的操作page.fill("#username", "test_user")page.fill("#password", "password123")page.click("button[type='submit']")# 測試完成后,關閉上下文以保存視頻context.close()browser.close()
with sync_playwright() as playwright:run(playwright)在這個例子中,所有的操作都會被錄制下來,并且視頻文件會被保存在videos/目錄下。每個視頻文件都將有唯一的名稱。
UI自動化框架設計的挑戰
盡管構建UI自動化框架能夠顯著提高工作效率,但在實際開發過程中,我們常常會面臨一系列難題。這些難題主要體現在以下幾個方面:
框架的可維護性難題
隨著測試用例數量的不斷增加,框架的維護工作可能會變得愈發棘手。為了確保框架的穩定性和可擴展性,保持代碼簡潔明了、采用模塊化設計理念顯得尤為重要,這有助于降低后續維護的難度。
測試數據的管理挑戰
UI測試高度依賴大量測試數據,如何高效管理這些數據并確保其準確性和有效性,是測試過程中不容忽視的一環。采用數據驅動的設計方法,可以有效提升測試數據的復用率,從而優化測試流程。
與開發團隊的協同合作
自動化測試框架的設計離不開與開發團隊的緊密配合。雙方需共同協作,確保測試框架能夠全面覆蓋所有關鍵功能,同時避免遺漏任何重要的UI組件,以保障軟件質量。
測試框架的結構與模塊化設計
UI自動化測試框架的結構設計直接影響到其可維護性和可擴展性。常見的設計模式包括:
- 頁面對象模型(Page Object Model,POM)
POM是UI自動化測試中最常用的設計模式。它通過將頁面元素和操作封裝在單獨的類中,使得測試用例與UI實現解耦,提高了框架的可維護性。
- 數據驅動測試
數據驅動測試允許通過不同的數據集運行相同的測試用例,極大提高了測試的覆蓋率和復用性。
- 行為驅動開發(BDD)
BDD可以幫助團隊用更接近自然語言的方式描述測試場景,便于不同職能的人之間的溝通。
通過將框架分為多個模塊,每個模塊只負責特定的功能,能夠有效提升框架的可維護性和擴展性。
自動化測試不是銀彈
- 結合目前的現狀看,自動化測試與手工測試還得結合使用,
雖然UI自動化測試能夠顯著提升測試工作的效率,但它并非適用于所有情況的全能解決方案。當面對那些界面極為復雜、交互操作頻繁,或是需要精準模擬用戶多樣化行為模式的測試場景時,手工測試所展現出的靈活性和細致入微的觀察力,依然有著自動化測試無法替代的獨特優勢。
正因如此,將自動化測試與手工測試有機結合,形成優勢互補的測試策略,能夠更全面、更深入地覆蓋各種測試場景,從而有效提高測試工作的完整性和準確性。此外,我們也不應忽視其他新興技術的潛力,例如人工智能(AI)技術,它在測試領域的應用同樣值得我們深入探索和實踐。
- 要不要自動化?
在項目啟動之初,團隊需審慎評估自動化測試的必要性。對于周期僅三個月的短期項目而言,投入自動化測試往往顯得不切實際,此時應優先考慮更為靈活高效的測試策略。構建一個高效的UI自動化測試框架,不僅是對技術能力的嚴峻考驗,更是團隊協作精神的集中體現。
通過精心規劃框架架構、巧妙運用Playwright等前沿測試工具,團隊能夠顯著提升測試執行效率,有效降低后續維護成本。在軟件開發環境日趨復雜的當下,這種以高效自動化測試框架為支撐的測試體系,將成為團隊保持核心競爭力、應對各種挑戰的關鍵所在。
走進Browser Use
橫空出世的背景與意義
在互聯網技術日新月異的當下,網頁應用的功能日益多元,交互體驗愈發豐富。從最初單純的信息展示頁面,到如今功能完備的在線辦公系統、交易繁忙的電商平臺,網頁應用的復雜程度呈幾何級數攀升,其測試難度也隨之水漲船高。傳統的自動化測試工具,在應對這些復雜多變的網頁應用時,逐漸暴露出諸多短板,顯得捉襟見肘。
就在這一困境之中,Browser Use 閃亮登場。它憑借前沿的 AI 技術,成功突破了傳統測試工具的桎梏。Browser Use 能夠迅速且精準地模擬用戶在瀏覽器中的各種操作行為,對網頁應用展開全方位、深層次的測試。它的出現,為網頁自動化測試領域注入了全新的活力,帶來了別具一格的思路與高效實用的方法。通過 Browser Use 的應用,測試效率與質量得到了顯著提升,更為整個軟件測試行業的蓬勃發展提供了強大助力。
核心功能介紹
1. 通用大型語言模型(LLM)兼容支持
Browser Use 展現出卓越的通用性,能夠與多種主流大型語言模型(LLM)實現無縫對接,像 OpenAI 的 GPT 系列、Google 的 BERT 等均在其兼容列表之中。這一特性賦予用戶極大的自主選擇權,可依據自身需求與偏好,挑選最契合的語言模型來驅動測試流程。
以某些對語言理解精度要求嚴苛的測試場景為例,GPT 系列模型憑借其強大的自然語言解析能力,能夠精準剖析復雜的指令,為測試工作提供堅實有力的支持。不同的大型語言模型在各自擅長的應用場景中優勢盡顯,Browser Use 的這種高度兼容性,使用戶能夠充分挖掘各模型的長處,從而達成最佳的測試效果。
2. 網頁交互元素智能檢測
Browser Use 具備一項令人矚目的能力——自動檢測網頁交互元素。當加載一個網頁時,它能以極快的速度識別出頁面中的各類交互元素,如按鈕、文本框、下拉菜單、鏈接等。
這一功能極大地簡化了測試腳本的編寫流程。在過去,測試人員需要手動定位這些元素的位置和屬性,不僅操作繁瑣,還極易出錯,且效率低下。如今,Browser Use 自動完成這一工作,為后續的自動化測試操作筑牢了基礎。例如,在測試電商網站的購物流程時,它能迅速定位“添加到購物車”按鈕、“結算”按鈕等關鍵交互元素,為模擬用戶購物操作做好充分準備。
3. 便捷的多標簽管理功能
在實際的網頁瀏覽與測試過程中,多標簽操作屢見不鮮。Browser Use 的多標簽管理功能,讓用戶能夠在一個測試會話中輕松駕馭多個瀏覽器標簽。用戶可以在不同標簽間自由切換、操作,就如同日常瀏覽網頁一般自然流暢。
這一功能在需要同時測試多個頁面交互的場景中尤為實用。比如,在測試社交平臺時,可能需要在一個標簽中登錄賬號,在另一個標簽中查看好友動態。通過多標簽管理功能,Browser Use 能夠輕松模擬這種復雜的操作流程,有效提升測試的全面性和準確性。
4. 強大的 XPath 數據提取能力
XPath 作為在 XML 文檔中定位元素的重要語言,在網頁測試中對于精準獲取特定元素數據起著關鍵作用。Browser Use 提供了強大且高效的 XPath 提取功能,用戶借助它可以快速、準確地從網頁中抓取所需數據。
無論是網頁中的文本內容、圖片鏈接,還是表格數據等,都能通過 XPath 表達式輕松獲取。例如,在進行數據抓取任務時,通過編寫合適的 XPath 表達式,Browser Use 可以從新聞網站頁面中提取出所有文章的標題、作者、發布時間等信息,為后續的數據分析和處理提供了極大便利。
5. 先進的視覺模型支持
為進一步提升自動化測試的準確性,Browser Use 引入了視覺模型支持。它能夠模擬人類的視覺感知,“看”到網頁的視覺內容,并通過分析頁面的布局、顏色、圖像等信息,更深入地理解網頁的結構和功能。
這一功能在處理基于視覺的交互場景時尤為重要。例如,在測試圖片編輯應用時,Browser Use 可以通過視覺模型識別出圖片的裁剪區域、濾鏡效果等,從而更精準地模擬用戶操作,確保應用在各種視覺交互方面的功能正常運行。
6. 靈活的自定義動作功能
考慮到每個測試項目都有其獨特需求,Browser Use 貼心地提供了自定義動作功能。用戶可以根據自身測試需求,編寫特定代碼來定義新的操作。
例如,在測試特定行業的專業軟件時,可能存在一些特殊的業務流程和操作方式。通過自定義動作,用戶可以將這些特殊操作融入測試流程中,使 Browser Use 能夠滿足各種個性化的測試需求。
7. 出色的動態內容處理能力
現代網頁應用中充斥著大量動態內容,如實時更新的新聞資訊、滾動加載的商品列表等。Browser Use 在處理動態內容方面表現卓越,它采用先進技術手段,能夠實時監測網頁內容的變化,確保在動態環境下也能精準執行測試任務。
例如,在測試股票交易平臺時,股票價格等數據實時動態變化,Browser Use 可以及時捕捉這些變化,驗證平臺在數據更新和顯示方面的正確性,有力保障了測試的有效性。
8. 鏈式思維提示與記憶功能
在處理長期復雜的任務時,Browser Use 的鏈式思維提示與記憶功能發揮著重要作用。它能夠依據之前的操作和結果,生成合理的下一步操作建議,仿佛擁有了自主“思考能力”。
同時,它還能牢記之前的操作步驟和相關信息,避免重復勞動,提高測試效率。比如,在模擬用戶在電商平臺上的長期購物行為時,它可以記住用戶已瀏覽過的商品、添加到購物車的商品等信息,并根據用戶的購買習慣和操作邏輯,繼續進行后續操作,如結算、選擇配送方式等。
9. 高效的自我糾正機制
在自動化測試過程中,難免會遇到各種意外情況導致測試出錯。Browser Use 具備自我糾正功能,當檢測到測試出現錯誤時,它能夠自動分析錯誤原因,并嘗試進行自我修復。
例如,在點擊一個按鈕時,如果因網絡延遲等原因導致點擊失敗,它可以自動重試,或者調整操作策略,確保測試能夠順利推進,大大提高了測試的穩定性和可靠性。
Browser Use的核心原理
1、自然語言處理(NLP)的非凡魅力
Browser Use 能夠精準理解用戶輸入的自然語言指令,這背后離不開其卓越的自然語言處理能力。它借助前沿的 NLP 算法,對用戶輸入的文本展開深度剖析,涵蓋詞法分析、句法分析以及語義理解等多個層面。
在詞法分析階段,它會將輸入的文本巧妙拆解為一個個獨立的單詞或詞組,并精準判定它們的詞性;句法分析則聚焦于解析這些單詞之間的語法關聯,精心構建出句子的語法架構;而語義理解則是在前兩者的堅實基礎上,充分結合上下文信息,精準把握用戶的真實意圖。
以用戶輸入“點擊頁面上的登錄按鈕”這一指令為例,Browser Use 的 NLP 模塊會迅速識別出“點擊”為動作動詞,“登錄按鈕”為動作對象。隨后,通過對網頁結構的細致分析,精準定位到對應的按鈕元素,并果斷執行點擊操作。
2、與大型語言模型(LLM)的深度融合創新
Browser Use 與大型語言模型的深度融合,是其攻克復雜自動化測試任務的核心技術法寶之一。LLM 經過海量數據的精心訓練,具備強大的語言理解和生成能力。
Browser Use 會將用戶的測試需求巧妙轉化為語言模型能夠輕松理解的格式,并發送給它進行處理。LLM 憑借其深厚的知識儲備和豐富的經驗,生成與之對應的測試步驟和操作指令。之后,Browser Use 再將這些指令無縫轉化為實際的瀏覽器操作。
比如,在測試一個復雜的在線表單填寫功能時,用戶輸入“填寫所有必填字段并提交表單”這樣的指令。LLM 會深入分析表單中需要填寫的各個字段,并精心生成相應的填寫內容和操作步驟。Browser Use 則嚴格按照這些步驟,在瀏覽器中完美模擬用戶的填寫和提交操作。
3、瀏覽器自動化技術的精湛施展
Browser Use 巧妙運用了一系列先進的瀏覽器自動化技術,實現對瀏覽器的精準操控。它通過調用瀏覽器的開發者工具接口,能夠高度模擬用戶的各種操作,如點擊、輸入、滾動等。同時,它還能實時監控瀏覽器的各類事件,如頁面加載完成、元素出現或消失等。
以模擬用戶登錄操作為例,Browser Use 可以通過接口精準定位到用戶名和密碼輸入框,模擬用戶輸入賬號和密碼,然后觸發登錄按鈕的點擊事件。在頁面加載過程中,它會實時跟蹤頁面的加載狀態,確保在頁面完全加載后再推進下一步操作,從而有力保障測試的準確性和穩定性。
Browser Use實戰示例
1. 環境安裝
在開始使用 playwright 之前,需要安裝相關依賴,建議在Python3.11以上環境操作:
pip3 install playwright
playwright install
如果使用 pytest 進行自動化測試,可額外安裝:
pip install pytest pytest-playwright
2、添加API密鑰
如果使用的是需要API密鑰的語言模型(如OpenAI的GPT系列),需要將API密鑰添加到環境變量中。在Linux或macOS系統上,可以在終端中運行:
export OPENAI_API_KEY = your api key
3、代碼示例
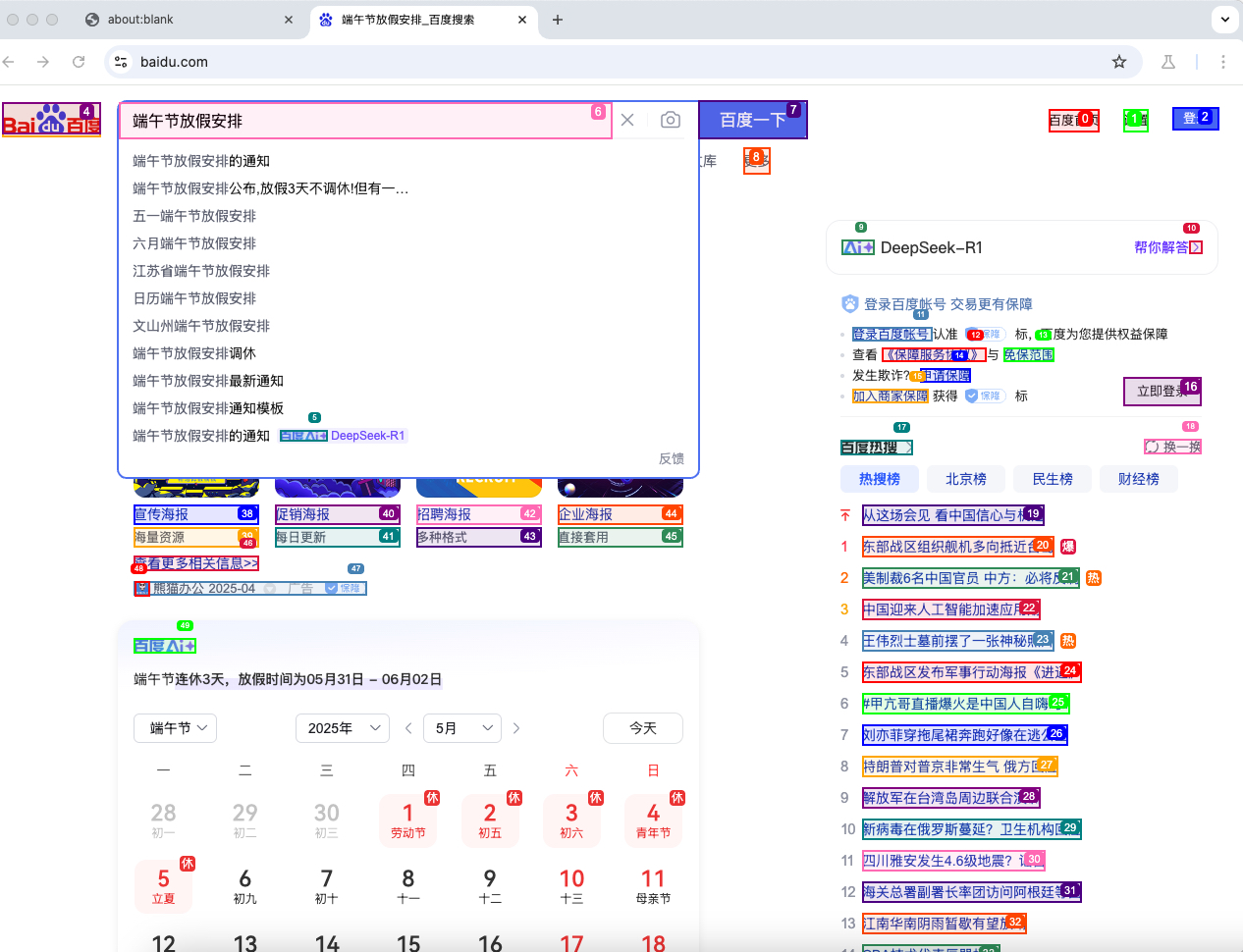
需求:打開百度自動查詢今年的端午節放假日期,
browser_use_demo.py
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asynciollm = ChatOpenAI(model="gpt-4o")async def main():agent = Agent(task="打開百度首頁,在輸入框中輸入:端午節放假安排,然后點擊百度一下按鈕,最后從搜索結果中找出準確的放假時間,要求使用中文輸出結果。",llm=llm,)result = await agent.run()# print(result)asyncio.run(main())
運行腳本后,預期控制臺的輸出結果如下, 可以看出可以準確的輸出結果:端午節的放假時間為5月31日至6月2日。
INFO [browser_use] BrowserUse logging setup complete with level info
INFO [root] Anonymized telemetry enabled. See https://docs.browser-use.com/development/telemetry for more information.
/opt/homebrew/lib/python3.13/site-packages/browser_use/agent/message_manager/views.py:59: LangChainBetaWarning: The function `load` is in beta. It is actively being worked on, so the API may change.value['message'] = load(value['message'])
INFO [agent] 🚀 Starting task: 打開百度首頁,在輸入框中輸入:端午節放假安排,然后點擊百度一下按鈕,最后從搜索結果中找出準確的放假時間,要求使用中文輸出結果。
INFO [agent] 📍 Step 1
INFO [agent] 🤷 Eval: Unknown - No previous action was performed.
INFO [agent] 🧠 Memory: 0 out of 1 tasks completed. Need to open Baidu and search for holiday schedule.
INFO [agent] 🎯 Next goal: Open the Baidu homepage.
INFO [agent] 🛠? Action 1/1: {"open_tab":{"url":"https://www.baidu.com"}}
INFO [controller] 🔗 Opened new tab with https://www.baidu.com
INFO [agent] 📍 Step 2
INFO [agent] 👍 Eval: Success - Baidu homepage opened.
INFO [agent] 🧠 Memory: 0 out of 1 tasks completed. Need to search for Duanwu Festival holiday arrangements.
INFO [agent] 🎯 Next goal: Input '端午節放假安排' into the search box and click '百度一下' button.
INFO [agent] 🛠? Action 1/2: {"input_text":{"index":12,"text":"端午節放假安排"}}
INFO [agent] 🛠? Action 2/2: {"click_element":{"index":13}}
INFO [controller] ?? Input 端午節放假安排 into index 12
INFO [agent] Something new appeared after action 1 / 2
INFO [agent] 📍 Step 3
INFO [agent] 👍 Eval: Success - Search was performed for '端午節放假安排'.
INFO [agent] 🧠 Memory: 0 out of 1 tasks completed. Found accurate holiday dates for Duanwu Festival. Dates are May 31st to June 2nd.
INFO [agent] 🎯 Next goal: Conclude the task by summarizing the holiday dates.
INFO [agent] 🛠? Action 1/1: {"done":{"text":"端午節的放假時間為5月31日至6月2日。","success":true}}
INFO [agent] 📄 Result: 端午節的放假時間為5月31日至6月2日。
INFO [agent] ? Task completed
INFO [agent] ? Successfully
因為我們沒有開無頭模式,所以在執行過程中也可以看到模擬人工的整個操作過程,如:打開瀏覽器及輸入qeury等,示例圖如下:
Briwser Uer的局限性和挑戰
第一個demo調通后還是比較興奮的,但實際上后面試了很多場景,都沒有一次成功,哪怕是簡單的任務:“查詢4月3日從北京首都機場到武漢天河機場最便宜的機票,然后打印出結果”。
還得看任務的復雜度,比如:總結網頁內容、寫一封郵件等這種對于結果容忍度比較高的場景比較合適。
盡管Browser Use已經取得了很大的進展,但在技術上仍面臨一些挑戰。例如,語言模型的輸出有時可能不夠穩定,會出現理解錯誤或生成不合理的操作指令的情況。此外,隨著瀏覽器技術的不斷更新,Browser Use需要及時跟進,以支持新的瀏覽器功能和API。在處理一些復雜的網頁結構和動態加載內容時,也可能會遇到性能瓶頸和識別不準確的問題。
在實際應用中,Browser Use可能會遇到一些復雜的場景,如需要處理復雜的驗證碼、繞過反爬蟲機制等。同時,對于一些對安全性要求極高的應用,如何確保Browser Use的操作不會對系統造成安全風險,也是需要解決的問題。此外,在與企業現有的測試流程和工具集成時,可能會面臨兼容性和數據交互的問題。
持續關注和學習
1.技術優化:針對語言模型輸出不穩定的問題,可以通過增加更多的訓練數據、優化模型的訓練算法、引入糾錯機制等方式來提高其穩定性和準確性。對于瀏覽器技術更新的問題,測試團隊需要密切關注瀏覽器的發展動態,及時更新Browser Use的代碼,以支持新的功能和API。在處理復雜網頁結構和動態加載內容時,可采用更先進的解析算法和異步加載處理技術,提升性能和識別的準確性。
2.應用改進:在面對復雜驗證碼時,可以集成第三方驗證碼識別服務,或者利用機器學習算法進行自定義的驗證碼識別訓練。繞過反爬蟲機制則需要深入研究目標網站的反爬蟲策略,采用合理的偽裝技術、控制請求頻率等方式來規避。為確保安全性,在對敏感應用進行測試前,進行全面的安全評估和模擬攻擊測試,確保Browser Use的操作不會被惡意利用。在與企業現有流程和工具集成方面,開發專門的適配器和接口,確保數據能夠順暢交互,并與現有工具形成互補,共同服務于企業的測試流程 。
小結
技術的發展是飛速的,我們需要以開放的心態去擁抱變化,持續關注最新的技術動態,實踐出真理,找到合適的場景比隨大流更重要。

)

)


)



)


與等距圓柱投影(Equirectangular projection))





