Ollama+open-webui搭建私有本地大模型詳細教程
1. 什么是 Ollama?
1.1. Ollama 簡介
? Ollama 是一個輕量級的 AI 模型運行時,專注于簡化 AI 模型的部署和使用。它支持多種預訓練模型(如 Llama、Vicuna、Dolly 等),并且可以在本地運行,無需復雜的基礎設施。Ollama 的設計理念是讓 AI 模型的使用變得像運行普通程序一樣簡單,同時確保數據和隱私的安全性。
? Ollama 正在不斷優化和擴展,未來會支持更多模型類型、更高效的性能優化,以及更友好的用戶界面。Ollama的目標是成為 AI 模型部署領域的標準工具,讓更多人能夠輕松使用 AI 技術。
1.2. 核心特點
-
輕量化:Ollama 的資源占用非常低,適合在本地或小型服務器上運行,即使硬件配置有限也能流暢使用。
-
多模型支持:支持多種主流的預訓練模型,用戶可以根據需求選擇適合的模型。
-
本地運行:所有模型和數據完全在本地運行,無需上傳到云端,保護用戶隱私。
-
易于部署:安裝和啟動流程簡單,支持 Docker 和二進制文件部署,適合不同環境。
-
交互式使用:提供命令行工具,用戶可以通過簡單的命令與模型交互,快速獲取結果。
-
隱私保護:模型和數據完全在本地運行,無需上傳到云端。
1.3. 應用場景
- 個人開發者:快速測試和實驗 AI 模型,無需復雜的環境配置。
- 企業用戶:在本地運行 AI 模型,確保數據安全,同時滿足業務需求。
2. Ollama安裝與部署
ollama官方網站:https://ollama.com
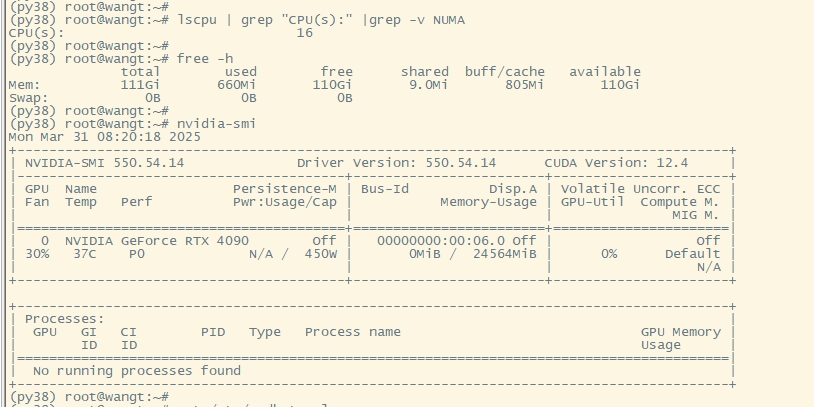
服務器資源準備(GPU服務器)
以實驗環境,操作環境為 ubuntu20.04,顯卡RTX 4090,配置16C/128G
2.1. 使用官方提供的安裝方式(推薦)
官方推薦方式
(py38) root@wangt:~# mkdir ollama
(py38) root@wangt:~# cd ollama/
(py38) root@wangt:~# curl -fsSL https://ollama.com/install.sh | sh
# 等待安裝結束即可,非常簡單(執行過程中下載安裝包比較耗時)# 更改服務默認端口(可選)
(py38) root@wangt:~/ollama# vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/cuda-11.8/bin:/root/miniconda3/envs/py38/bin:/root/miniconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
Environment="OLLAMA_HOST=0.0.0.0:8890"[Install]
WantedBy=default.target
Environment=“OLLAMA_HOST=0.0.0.0:8890”
可以自定義端口,和訪問控制,0.0.0.0表示任何網段和環境均可進行訪問,8890表示用8890端口啟動,不加則默認為11434
(py38) root@wangt:~/ollama# systemctl daemon-reload
(py38) root@wangt:~/ollama# systemctl restart ollama
(py38) root@wangt:~/ollama# netstat -tnlpu|grep 8890
tcp6 0 0 :::8890 :::* LISTEN 3073/ollama
2.2. 手動安裝詳細介紹(備選項)
官方提供的安裝方式,僅適合網絡下載速度較快的情況,否則安裝容易失敗,因為下載包速度慢,很可能下載失敗導致腳本運行異常,如果上面安裝總是不成功,以下提供下載包手動安裝的方式
# 下載安裝包可以用梯子下載,傳到服務器(windows下載后上傳服務器)
(py38) root@wangt:~/ollama# wget https://gh-proxy.com/github.com/ollama/ollama/releases/latest/download/ollama-linux-amd64.tgz# 拉取腳本但不執行
(py38) root@wangt:~# curl -fsSL https://ollama.com/install.sh > install.sh
(py38) root@wangt:~/ollama# chmod +x install.sh
(py38) root@wangt:~/ollama# vim install.sh
需要將腳本中原本下載安裝包的相關內容注釋,并把tar命令修改到正確位置
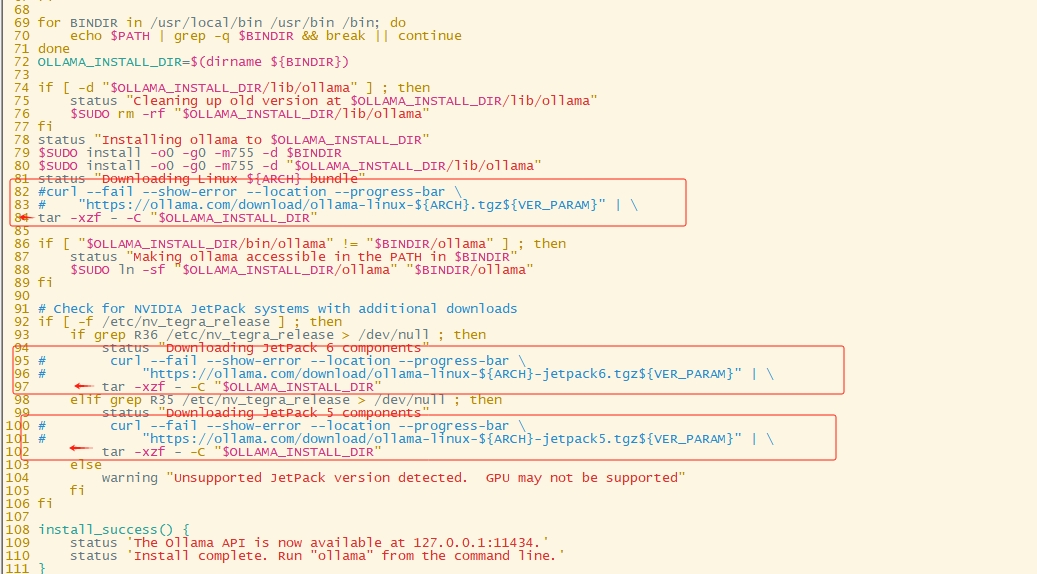
如果擔心腳本改錯,可以直接復制下面已經改好的腳本內容
#!/bin/sh
# This script installs Ollama on Linux.
# It detects the current operating system architecture and installs the appropriate version of Ollama.set -eured="$( (/usr/bin/tput bold || :; /usr/bin/tput setaf 1 || :) 2>&-)"
plain="$( (/usr/bin/tput sgr0 || :) 2>&-)"status() { echo ">>> $*" >&2; }
error() { echo "${red}ERROR:${plain} $*"; exit 1; }
warning() { echo "${red}WARNING:${plain} $*"; }TEMP_DIR=$(mktemp -d)
cleanup() { rm -rf $TEMP_DIR; }
trap cleanup EXITavailable() { command -v $1 >/dev/null; }
require() {local MISSING=''for TOOL in $*; doif ! available $TOOL; thenMISSING="$MISSING $TOOL"fidoneecho $MISSING
}[ "$(uname -s)" = "Linux" ] || error 'This script is intended to run on Linux only.'ARCH=$(uname -m)
case "$ARCH" inx86_64) ARCH="amd64" ;;aarch64|arm64) ARCH="arm64" ;;*) error "Unsupported architecture: $ARCH" ;;
esacIS_WSL2=falseKERN=$(uname -r)
case "$KERN" in*icrosoft*WSL2 | *icrosoft*wsl2) IS_WSL2=true;;*icrosoft) error "Microsoft WSL1 is not currently supported. Please use WSL2 with 'wsl --set-version <distro> 2'" ;;*) ;;
esacVER_PARAM="${OLLAMA_VERSION:+?version=$OLLAMA_VERSION}"SUDO=
if [ "$(id -u)" -ne 0 ]; then# Running as root, no need for sudoif ! available sudo; thenerror "This script requires superuser permissions. Please re-run as root."fiSUDO="sudo"
fiNEEDS=$(require curl awk grep sed tee xargs)
if [ -n "$NEEDS" ]; thenstatus "ERROR: The following tools are required but missing:"for NEED in $NEEDS; doecho " - $NEED"doneexit 1
fifor BINDIR in /usr/local/bin /usr/bin /bin; doecho $PATH | grep -q $BINDIR && break || continue
done
OLLAMA_INSTALL_DIR=$(dirname ${BINDIR})if [ -d "$OLLAMA_INSTALL_DIR/lib/ollama" ] ; thenstatus "Cleaning up old version at $OLLAMA_INSTALL_DIR/lib/ollama"$SUDO rm -rf "$OLLAMA_INSTALL_DIR/lib/ollama"
fi
status "Installing ollama to $OLLAMA_INSTALL_DIR"
$SUDO install -o0 -g0 -m755 -d $BINDIR
$SUDO install -o0 -g0 -m755 -d "$OLLAMA_INSTALL_DIR/lib/ollama"
status "Downloading Linux ${ARCH} bundle"
#curl --fail --show-error --location --progress-bar \
# "https://ollama.com/download/ollama-linux-${ARCH}.tgz${VER_PARAM}" | \
tar -xzf /root/ollama/ollama-linux-amd64.tgz -C "$OLLAMA_INSTALL_DIR"if [ "$OLLAMA_INSTALL_DIR/bin/ollama" != "$BINDIR/ollama" ] ; thenstatus "Making ollama accessible in the PATH in $BINDIR"$SUDO ln -sf "$OLLAMA_INSTALL_DIR/ollama" "$BINDIR/ollama"
fi# Check for NVIDIA JetPack systems with additional downloads
if [ -f /etc/nv_tegra_release ] ; thenif grep R36 /etc/nv_tegra_release > /dev/null ; thenstatus "Downloading JetPack 6 components"#curl --fail --show-error --location --progress-bar \# "https://ollama.com/download/ollama-linux-${ARCH}-jetpack6.tgz${VER_PARAM}" | \tar -xzf /root/ollama/ollama-linux-amd64.tgz -C "$OLLAMA_INSTALL_DIR"elif grep R35 /etc/nv_tegra_release > /dev/null ; thenstatus "Downloading JetPack 5 components"#curl --fail --show-error --location --progress-bar \# "https://ollama.com/download/ollama-linux-${ARCH}-jetpack5.tgz${VER_PARAM}" | \tar -xzf /root/ollama/ollama-linux-amd64.tgz -C "$OLLAMA_INSTALL_DIR"elsewarning "Unsupported JetPack version detected. GPU may not be supported"fi
fiinstall_success() {status 'The Ollama API is now available at 127.0.0.1:11434.'status 'Install complete. Run "ollama" from the command line.'
}
trap install_success EXIT# Everything from this point onwards is optional.configure_systemd() {if ! id ollama >/dev/null 2>&1; thenstatus "Creating ollama user..."$SUDO useradd -r -s /bin/false -U -m -d /usr/share/ollama ollamafiif getent group render >/dev/null 2>&1; thenstatus "Adding ollama user to render group..."$SUDO usermod -a -G render ollamafiif getent group video >/dev/null 2>&1; thenstatus "Adding ollama user to video group..."$SUDO usermod -a -G video ollamafistatus "Adding current user to ollama group..."$SUDO usermod -a -G ollama $(whoami)status "Creating ollama systemd service..."cat <<EOF | $SUDO tee /etc/systemd/system/ollama.service >/dev/null
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=$BINDIR/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"[Install]
WantedBy=default.target
EOFSYSTEMCTL_RUNNING="$(systemctl is-system-running || true)"case $SYSTEMCTL_RUNNING inrunning|degraded)status "Enabling and starting ollama service..."$SUDO systemctl daemon-reload$SUDO systemctl enable ollamastart_service() { $SUDO systemctl restart ollama; }trap start_service EXIT;;*)warning "systemd is not running"if [ "$IS_WSL2" = true ]; thenwarning "see https://learn.microsoft.com/en-us/windows/wsl/systemd#how-to-enable-systemd to enable it"fi;;esac
}if available systemctl; thenconfigure_systemd
fi# WSL2 only supports GPUs via nvidia passthrough
# so check for nvidia-smi to determine if GPU is available
if [ "$IS_WSL2" = true ]; thenif available nvidia-smi && [ -n "$(nvidia-smi | grep -o "CUDA Version: [0-9]*\.[0-9]*")" ]; thenstatus "Nvidia GPU detected."fiinstall_successexit 0
fi# Don't attempt to install drivers on Jetson systems
if [ -f /etc/nv_tegra_release ] ; thenstatus "NVIDIA JetPack ready."install_successexit 0
fi# Install GPU dependencies on Linux
if ! available lspci && ! available lshw; thenwarning "Unable to detect NVIDIA/AMD GPU. Install lspci or lshw to automatically detect and install GPU dependencies."exit 0
ficheck_gpu() {# Look for devices based on vendor ID for NVIDIA and AMDcase $1 inlspci)case $2 innvidia) available lspci && lspci -d '10de:' | grep -q 'NVIDIA' || return 1 ;;amdgpu) available lspci && lspci -d '1002:' | grep -q 'AMD' || return 1 ;;esac ;;lshw)case $2 innvidia) available lshw && $SUDO lshw -c display -numeric -disable network | grep -q 'vendor: .* \[10DE\]' || return 1 ;;amdgpu) available lshw && $SUDO lshw -c display -numeric -disable network | grep -q 'vendor: .* \[1002\]' || return 1 ;;esac ;;nvidia-smi) available nvidia-smi || return 1 ;;esac
}if check_gpu nvidia-smi; thenstatus "NVIDIA GPU installed."exit 0
fiif ! check_gpu lspci nvidia && ! check_gpu lshw nvidia && ! check_gpu lspci amdgpu && ! check_gpu lshw amdgpu; theninstall_successwarning "No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode."exit 0
fiif check_gpu lspci amdgpu || check_gpu lshw amdgpu; thenstatus "Downloading Linux ROCm ${ARCH} bundle"#curl --fail --show-error --location --progress-bar \# "https://ollama.com/download/ollama-linux-${ARCH}-rocm.tgz${VER_PARAM}" | \tar -xzf /root/ollama/ollama-linux-amd64.tgz -C "$OLLAMA_INSTALL_DIR"install_successstatus "AMD GPU ready."exit 0
fiCUDA_REPO_ERR_MSG="NVIDIA GPU detected, but your OS and Architecture are not supported by NVIDIA. Please install the CUDA driver manually https://docs.nvidia.com/cuda/cuda-installation-guide-linux/"
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#rhel-7-centos-7
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#rhel-8-rocky-8
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#rhel-9-rocky-9
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#fedora
install_cuda_driver_yum() {status 'Installing NVIDIA repository...'case $PACKAGE_MANAGER inyum)$SUDO $PACKAGE_MANAGER -y install yum-utilsif curl -I --silent --fail --location "https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repo" >/dev/null ; then$SUDO $PACKAGE_MANAGER-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repoelseerror $CUDA_REPO_ERR_MSGfi;;dnf)if curl -I --silent --fail --location "https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repo" >/dev/null ; then$SUDO $PACKAGE_MANAGER config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repoelseerror $CUDA_REPO_ERR_MSGfi;;esaccase $1 inrhel)status 'Installing EPEL repository...'# EPEL is required for third-party dependencies such as dkms and libvdpau$SUDO $PACKAGE_MANAGER -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-$2.noarch.rpm || true;;esacstatus 'Installing CUDA driver...'if [ "$1" = 'centos' ] || [ "$1$2" = 'rhel7' ]; then$SUDO $PACKAGE_MANAGER -y install nvidia-driver-latest-dkmsfi$SUDO $PACKAGE_MANAGER -y install cuda-drivers
}# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#ubuntu
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#debian
install_cuda_driver_apt() {status 'Installing NVIDIA repository...'if curl -I --silent --fail --location "https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-keyring_1.1-1_all.deb" >/dev/null ; thencurl -fsSL -o $TEMP_DIR/cuda-keyring.deb https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-keyring_1.1-1_all.debelseerror $CUDA_REPO_ERR_MSGficase $1 indebian)status 'Enabling contrib sources...'$SUDO sed 's/main/contrib/' < /etc/apt/sources.list | $SUDO tee /etc/apt/sources.list.d/contrib.list > /dev/nullif [ -f "/etc/apt/sources.list.d/debian.sources" ]; then$SUDO sed 's/main/contrib/' < /etc/apt/sources.list.d/debian.sources | $SUDO tee /etc/apt/sources.list.d/contrib.sources > /dev/nullfi;;esacstatus 'Installing CUDA driver...'$SUDO dpkg -i $TEMP_DIR/cuda-keyring.deb$SUDO apt-get update[ -n "$SUDO" ] && SUDO_E="$SUDO -E" || SUDO_E=DEBIAN_FRONTEND=noninteractive $SUDO_E apt-get -y install cuda-drivers -q
}if [ ! -f "/etc/os-release" ]; thenerror "Unknown distribution. Skipping CUDA installation."
fi. /etc/os-releaseOS_NAME=$ID
OS_VERSION=$VERSION_IDPACKAGE_MANAGER=
for PACKAGE_MANAGER in dnf yum apt-get; doif available $PACKAGE_MANAGER; thenbreakfi
doneif [ -z "$PACKAGE_MANAGER" ]; thenerror "Unknown package manager. Skipping CUDA installation."
fiif ! check_gpu nvidia-smi || [ -z "$(nvidia-smi | grep -o "CUDA Version: [0-9]*\.[0-9]*")" ]; thencase $OS_NAME incentos|rhel) install_cuda_driver_yum 'rhel' $(echo $OS_VERSION | cut -d '.' -f 1) ;;rocky) install_cuda_driver_yum 'rhel' $(echo $OS_VERSION | cut -c1) ;;fedora) [ $OS_VERSION -lt '39' ] && install_cuda_driver_yum $OS_NAME $OS_VERSION || install_cuda_driver_yum $OS_NAME '39';;amzn) install_cuda_driver_yum 'fedora' '37' ;;debian) install_cuda_driver_apt $OS_NAME $OS_VERSION ;;ubuntu) install_cuda_driver_apt $OS_NAME $(echo $OS_VERSION | sed 's/\.//') ;;*) exit ;;esac
fiif ! lsmod | grep -q nvidia || ! lsmod | grep -q nvidia_uvm; thenKERNEL_RELEASE="$(uname -r)"case $OS_NAME inrocky) $SUDO $PACKAGE_MANAGER -y install kernel-devel kernel-headers ;;centos|rhel|amzn) $SUDO $PACKAGE_MANAGER -y install kernel-devel-$KERNEL_RELEASE kernel-headers-$KERNEL_RELEASE ;;fedora) $SUDO $PACKAGE_MANAGER -y install kernel-devel-$KERNEL_RELEASE ;;debian|ubuntu) $SUDO apt-get -y install linux-headers-$KERNEL_RELEASE ;;*) exit ;;esacNVIDIA_CUDA_VERSION=$($SUDO dkms status | awk -F: '/added/ { print $1 }')if [ -n "$NVIDIA_CUDA_VERSION" ]; then$SUDO dkms install $NVIDIA_CUDA_VERSIONfiif lsmod | grep -q nouveau; thenstatus 'Reboot to complete NVIDIA CUDA driver install.'exit 0fi$SUDO modprobe nvidia$SUDO modprobe nvidia_uvm
fi# make sure the NVIDIA modules are loaded on boot with nvidia-persistenced
if available nvidia-persistenced; then$SUDO touch /etc/modules-load.d/nvidia.confMODULES="nvidia nvidia-uvm"for MODULE in $MODULES; doif ! grep -qxF "$MODULE" /etc/modules-load.d/nvidia.conf; thenecho "$MODULE" | $SUDO tee -a /etc/modules-load.d/nvidia.conf > /dev/nullfidone
fistatus "NVIDIA GPU ready."
install_success
保存并執行安裝腳本
(py38) root@wangt:~/ollama# bash install.sh
# 等待安裝結束(py38) root@wangt:~/ollama# vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/cuda-11.8/bin:/root/miniconda3/envs/py38/bin:/root/miniconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"
Environment="OLLAMA_HOST=0.0.0.0:8890"[Install]
WantedBy=default.target(py38) root@wangt:~/ollama# systemctl daemon-reload
(py38) root@wangt:~/ollama# systemctl restart ollama
(py38) root@wangt:~/ollama# netstat -tnlpu|grep 8890
tcp6 0 0 :::8890 :::* LISTEN 3073/ollama
2.3. 其它容器安裝方式(備選項)
實驗環境也可以考慮使用docker安裝,不會干擾本地環境,但使用異常排查問題時相對麻煩一些,docker運行需要有NVIDIA顯卡支持,需要配置
拉取 Ollama 鏡像
docker pull ollama/ollama:latest啟動 Ollama 容器
docker run -d --name ollama -p 11434:11434 ollama/ollama:latest驗證安裝
curl http://localhost:11434/
3. 使用和維護Ollama
3.1 基礎維護命令
-
啟動服務
systemctl start ollama -
停止服務
systemctl stop ollama -
查看服務狀態
systemctl status ollama(py38) root@wangt:~/ollama# curl 127.0.0.1:8890 Ollama is running -
查看版本信息
root@wangt:~/ollama# ollama --version
ollama version is 0.6.2
- 模型存儲路徑
root@wangt:~# ll /usr/share/ollama/.ollama/models/
total 16
drwxr-xr-x 4 ollama ollama 4096 Apr 1 03:17 ./
drwxr-xr-x 3 ollama ollama 4096 Apr 1 02:58 ../
drwxr-xr-x 2 ollama ollama 4096 Apr 1 04:40 blobs/
drwxr-xr-x 3 ollama ollama 4096 Apr 1 03:17 manifests/
3.2 模型管理命令
ollama官方模型倉庫地址:https://ollama.com/library
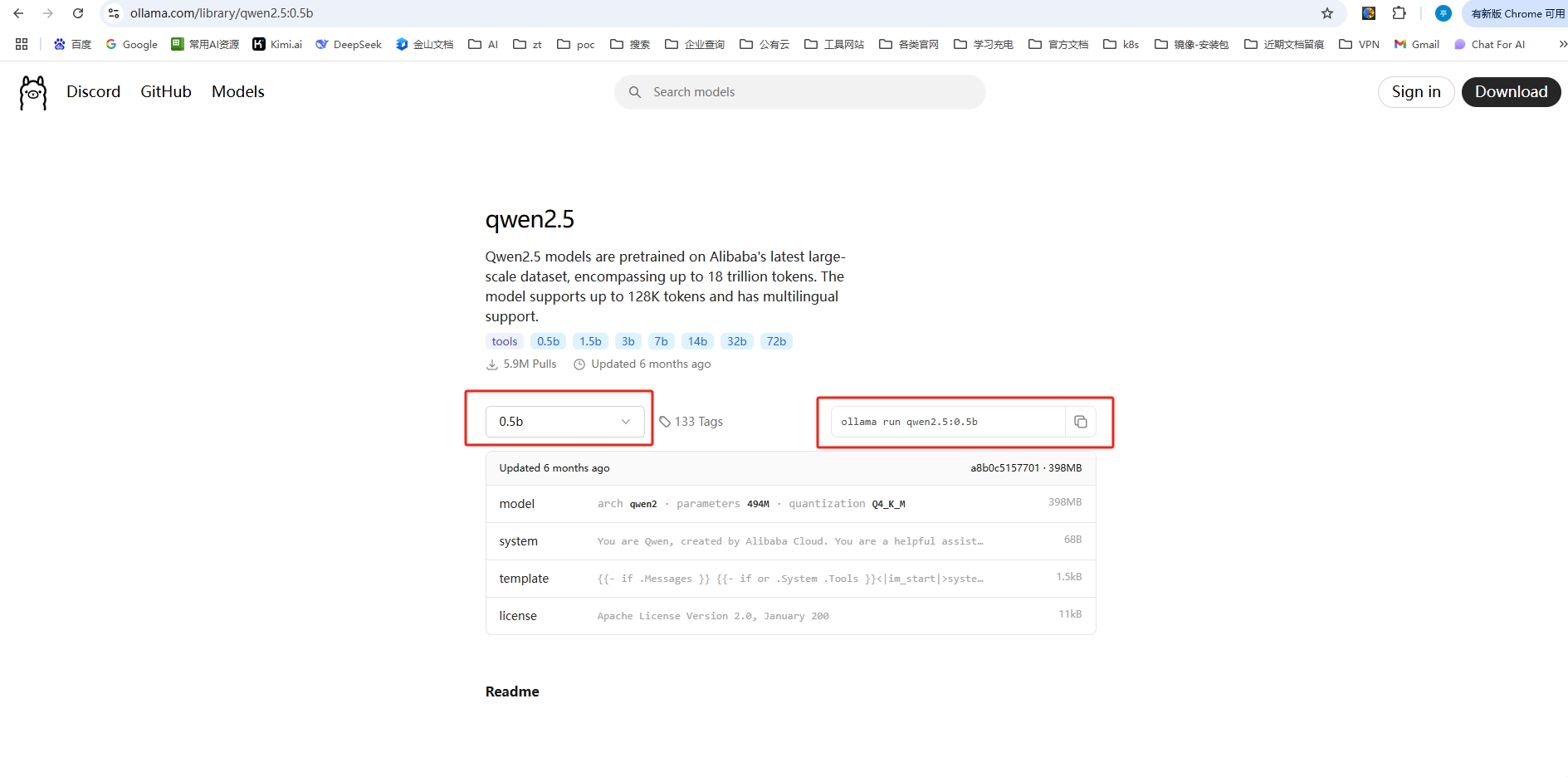
3.2.1 運行模型
在官方模型倉庫,找到自己想要的模型進入,根據自己用途情況,選擇參數量后,復制右邊的運行命令即可,類似于docker的使用方式
root@wangt:~/ollama# OLLAMA_HOST=127.0.0.1:8890 ollama run qwen2.5:0.5b
pulling manifest
pulling c5396e06af29... 100%
verifying sha256 digest
writing manifest
success # 嘗試體驗,問出問題
>>> 現在股票市場,創業板一共有多少家上市公司?
目前,創業板在A股市場上共設有50家公司。這個數目已經隨著市場的變動而有所調整。如果您需要最新的資訊和詳細信息,請留意財經新聞、官方網站或其他官方渠道以獲取最準確的信息。不過,一般來說,創業板的規模較大,通常與市值相對較高的公司有關,其上市公司的數量較多,
因為它們往往是具有較高知名度和技術實力的企業。>>> Send a message (/? for help)
安裝完成會進入到模型交互界面,直接可以和離線模型進行交互提問,使用命令
/?,可以查看操作清單>>> /? Available Commands:/set Set session variables/show Show model information/load <model> Load a session or model/save <model> Save your current session/clear Clear session context/bye Exit/?, /help Help for a command/? shortcuts Help for keyboard shortcutsUse """ to begin a multi-line message.>>> /bye root@wangt:~/ollama#
根據自己需要,可以去下載多個需要使用到的模型,例如再下載安裝一個deepseek-r1
當
ollama run運行的模型,會先檢查本地model,本地已經存在時,不會重新拉取,直接運行root@wangt:~/ollama# OLLAMA_HOST=127.0.0.1:8890 ollama run deepseek-r1:7b pulling manifest pulling 96c415656d37... 100% verifying sha256 digest writing manifest success >>> 你是什么模型?我是一個AI助手,由中國的深度求索(DeepSeek)公司獨立開發,我清楚自己的身份與局限,會始終秉持專業和誠實的態度幫助用戶。 >>> /bye
3.2.2 列出可用模型
root@wangt:~/ollama# OLLAMA_HOST=127.0.0.1:8890 ollama list
NAME ID SIZE MODIFIED
deepseek-r1:7b 0a8c26691023 4.7 GB 2 minutes ago
qwen2.5:0.5b a8b0c5157701 397 MB 21 minutes ago
也可以通過接口的方式查看:
root@wangt:~/ollama# curl http://localhost:8890/api/tags {"models": [{"name": "deepseek-r1:7b","model": "deepseek-r1:7b","modified_at": "2025-04-01T03:35:42.956003391Z","size": 4683075271,"digest": "0a8c266910232fd3291e71e5ba1e058cc5af9d411192cf88b6d30e92b6e73163","details": {"parent_model": "","format": "gguf","family": "qwen2","families": ["qwen2"],"parameter_size": "7.6B","quantization_level": "Q4_K_M"}},{"name": "qwen2.5:0.5b","model": "qwen2.5:0.5b","modified_at": "2025-04-01T03:17:35.053991433Z","size": 397821319,"digest": "a8b0c51577010a279d933d14c2a8ab4b268079d44c5c8830c0a93900f1827c67","details": {"parent_model": "","format": "gguf","family": "qwen2","families": ["qwen2"],"parameter_size": "494.03M","quantization_level": "Q4_K_M"}}] }
3.2.3 模型管理
- 查看模型信息
root@wangt:~/ollama# OLLAMA_HOST=127.0.0.1:8890 ollama show qwen2.5:0.5bModelarchitecture qwen2 parameters 494.03M context length 32768 embedding length 896 quantization Q4_K_M SystemYou are Qwen, created by Alibaba Cloud. You are a helpful assistant. LicenseApache License Version 2.0, January 2004
- 下載模型
root@wangt:~/ollama# OLLAMA_HOST=127.0.0.1:8890 ollama pull deepseek-r1:14b
使用到這里,命令總是加OLLAMA_HOST參數并不是很方便,我們可以增加
alias,來簡化命令root@wangt:~/ollama# alias ollama='OLLAMA_HOST=127.0.0.1:8890 ollama'
root@wangt:~/ollama# ollama list
NAME ID SIZE MODIFIED
deepseek-r1:14b ea35dfe18182 9.0 GB 25 minutes ago
deepseek-r1:7b 0a8c26691023 4.7 GB 58 minutes ago
qwen2.5:0.5b a8b0c5157701 397 MB About an hour ago
- 刪除模型
root@wangt:~/ollama# ollama rm qwen2.5:0.5b
deleted 'qwen2.5:0.5b'
root@wangt:~/ollama# ollama list
NAME ID SIZE MODIFIED
deepseek-r1:14b ea35dfe18182 9.0 GB 32 minutes ago
deepseek-r1:7b 0a8c26691023 4.7 GB About an hour ago
- 模型復制拷貝
root@wangt:~/ollama# ollama cp deepseek-r1:14b deepseek-r1_bak20250401:14b
copied 'deepseek-r1:14b' to 'deepseek-r1_bak20250401:14b'
root@wangt:~/ollama# ollama list
NAME ID SIZE MODIFIED
deepseek-r1_bak20250401:14b ea35dfe18182 9.0 GB 5 seconds ago
deepseek-r1:14b ea35dfe18182 9.0 GB 37 minutes ago
deepseek-r1:7b 0a8c26691023 4.7 GB About an hour ago
- 列出正在運行的模型
# 運行一個model
root@wangt:~# ollama run deepseek-r1:14b
>>> Send a message (/? for help)# 另起一個會話窗口查看
root@wangt:~# ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:14b ea35dfe18182 11 GB 100% GPU 3 minutes from now
- 非交互式查詢大模型
root@wangt:~/ollama# echo "上海的土地面積是多大?" | ollama run deepseek-r1:14b上海市的市域總面積約為6340平方公里。
root@wangt:~/ollama#
3.2.4 通過調接口方式查詢ollama大模型
# 格式如下
curl -X POST http://localhost:8890/api/generate -d '{"model": "deepseek-r1:14b","prompt": "上海的土地面積是多大?","stream": false
}'# 返回
{"model":"deepseek-r1:14b","created_at":"2025-04-01T06:14:56.00815753Z","response":"\u003cthink\u003e\n\n\u003c/think\u003e\n\n截至2023年,上海市的**土地總面積**約為**6,340平方公里**。這一數據包括了市轄區、郊縣等區域的土地面積。具體來說:\n\n- **市區**(包括黃浦、靜安、長寧、徐匯、楊浦、虹口、普陀、閘北、浦東新區等區)面積較小,約為**500平方公里**。\n- **郊區和遠郊地區**面積較大,約占總面積的絕大部分。\n\n需要注意的是,上海市的土地利用情況復雜,包括建設用地、農用地、生態保護區等多種類型。如果您需要更詳細的數據或具體區域的面積信息,可以參考當地統計局或自然資源部門發布的官方資料。","done":true,"done_reason":"stop","context":[151644,100633,109633,100210,20412,42140,26288,11319,151645,151648,271,151649,271,102219,17,15,17,18,7948,3837,105425,9370,334,101962,111603,334,107679,334,21,11,18,19,15,107231,334,1773,100147,20074,100630,34187,22697,103022,5373,103074,24342,49567,101065,109633,100210,1773,100398,99883,48443,12,3070,105587,334,9909,100630,99789,101465,5373,99541,50285,5373,45861,99503,5373,101957,99833,5373,101058,101465,5373,101522,39426,5373,99537,103441,5373,107964,48309,5373,112407,104879,49567,23836,7552,100210,109413,3837,107679,334,20,15,15,107231,334,8997,12,3070,117074,33108,99427,103074,100361,334,100210,104590,3837,115085,111603,9370,113604,3407,107916,100146,3837,105425,109633,100152,99559,102181,3837,100630,115138,5373,99288,102763,5373,100171,113891,107860,31905,1773,106870,85106,33126,100700,105918,57191,100398,101065,9370,100210,27369,3837,73670,101275,100198,112997,57191,110130,99667,105645,100777,101111,1773],"total_duration":2058396882,"load_duration":16299691,"prompt_eval_count":10,"prompt_eval_duration":13808729,"eval_count":150,"eval_duration":2027756646}
3.3 加載自定義模型(按需使用場景)
如果有需要加載一些自定義的模型,操作方式如下
-
其它途徑下載的模型文件
將模型文件(如.bin或.gguf格式)下載到本地。 -
加載模型
ollama create <model_name> --file <model_file>
4. 界面化操作-Ollama WebUI
4.1 安裝Open WebUI
(原 Ollama WebUI)
- docker方式部署
docker run -d -p 8891:8080 -e OLLAMA_BASE_URL=http://140.210.92.250:8890 -v open-webui:/app/backend/data --name ollama-web --restart always ghcr.io/open-webui/open-webui:main
注意:
-p 8891:8080,表示web-ui通過8891端口進行訪問,本容器則表示ui地址:http://140.210.92.250:8891OLLAMA_API_BASE_URL=http://140.210.92.250:8890,這里需要改成自己的ollama服務地址
4.2 使用Open WebUI
第一次登錄,需要注冊,且這個注冊賬號為管理員,注冊完成后登錄即可
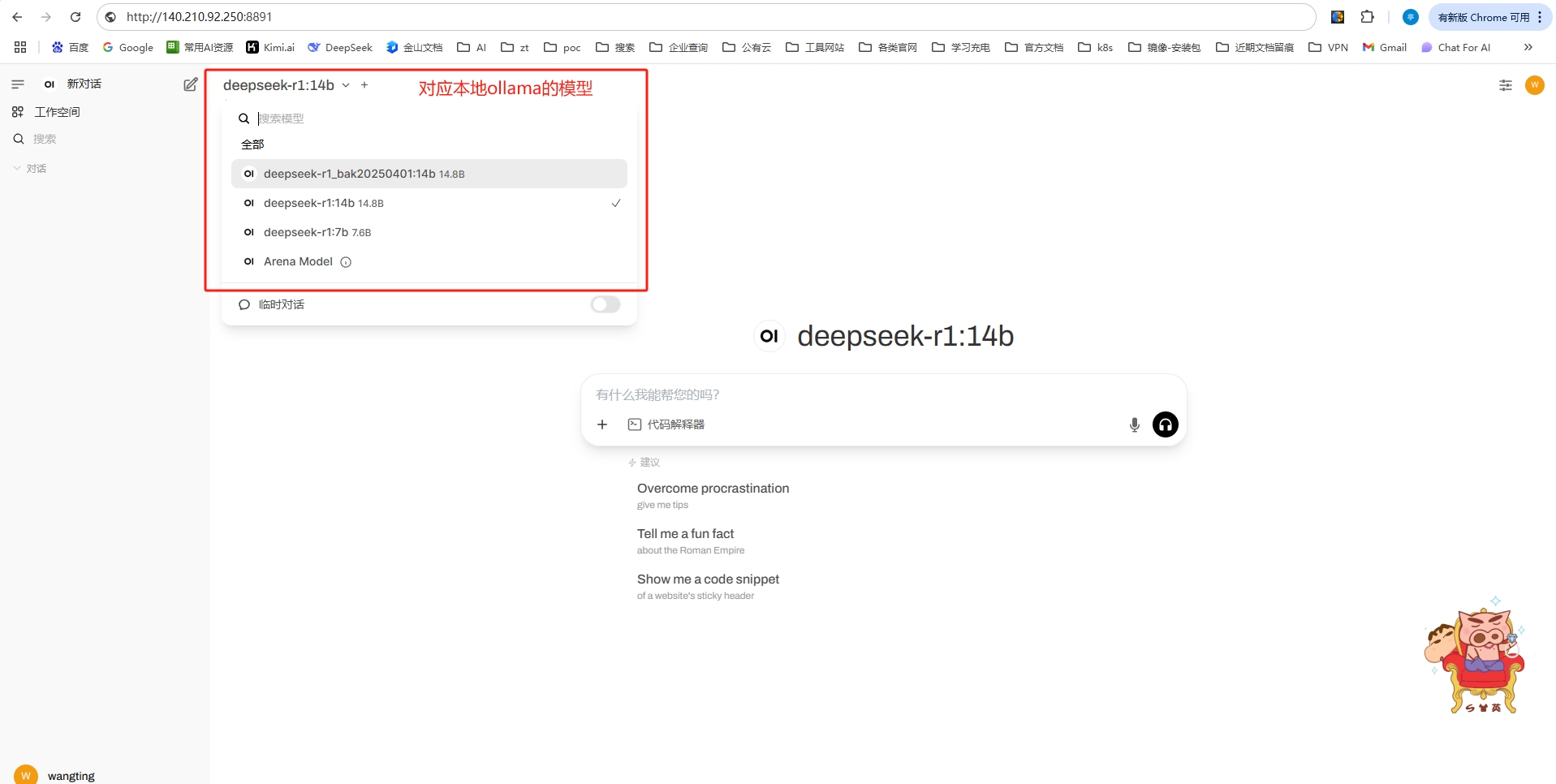
截止到這里,相當于一個離線的大模型+web-ui查詢的整個環境就算完成了,選擇一個模型,嘗試使用一下。
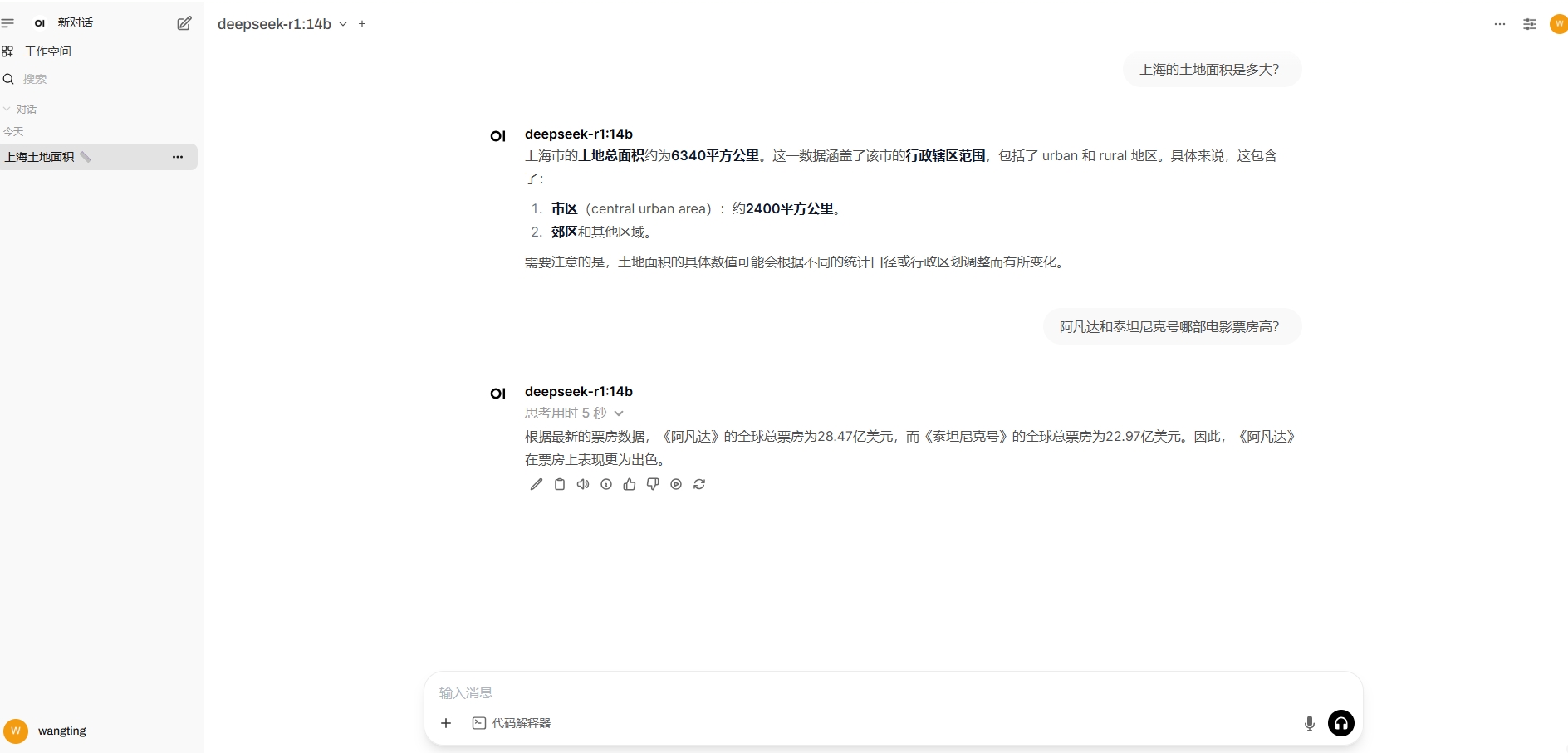
只要本地資源充足,可以通過ollama下載更大的模型進行使用







)


)






)

