目錄
一、網頁基礎
1.1 網頁的組成
1.2 網頁的結構
1.3 節點樹及節點間的關系
1.4 選擇器
二、爬蟲的基本原理
2.1 爬蟲概述
2.2 能抓怎樣的數據
2.3 JavaScript 渲染頁面
一、網頁基礎
????????使用瀏覽器訪問網站時,我們會看到各式各樣的頁面。你是否思考過,網頁為何會呈現出這樣的形態呢?在本節中,我們將深入了解網頁的基本組成、結構以及節點等方面的內容。
1.1 網頁的組成
??????? 網頁一般由HTML、CSS和JavaScript這三部分組成。打個比方,如果把網頁看作人,HTML就相當于人的骨架,CSS如同皮膚,JavaScript則類似肌肉。只有這三部分協同工作,才能打造出一個完整的網頁。下面,我們來分別講講這三部分各自的功能。
(1)HTML
????????HTML,全稱Hyper Text Markup Language,也就是超文本標記語言,專門用來描述網頁。網頁里有文字、按鈕、圖片、視頻等各種復雜的元素,而HTML就是這些元素的基礎架構。不同的元素用不同的標簽來表示,像圖片用img標簽,視頻用video標簽,段落用p標簽。為了安排這些元素的位置,常使用div標簽進行嵌套組合。各種標簽通過不同的排列和嵌套,最終搭建成網頁的框架。
????????以Chrome瀏覽器為例,打開百度后,右鍵點擊頁面,選擇“檢查”選項(也可以直接按F12鍵),就能打開開發者模式。在Elements選項卡中,我們可以看到網頁的源代碼。網頁就是由各種各樣的標簽嵌套組合而成,這些標簽所定義的節點元素相互嵌套,層層組合,形成復雜的層級關系,從而構建出網頁架構。

(2)CSS
??????? HTML確定了網頁的結構,但是光有HTML,頁面布局會很單調,只是簡單地排列節點元素,不夠美觀。為了讓網頁更好看,就需要用到CSS。
????????CSS的全稱是Cascading Style Sheets,即層疊樣式表。所謂“層疊”,就是當HTML引用多個樣式文件,且這些樣式出現沖突時,瀏覽器會按照特定順序來處理。而“樣式”指的是網頁中文字的大小、顏色,元素之間的間距、排列方式等格式。
????????CSS是目前網頁排版唯一的樣式標準,借助它,網頁會變得更加美觀。比如這段代碼“#head wrapper.s-ps-islite.s-p-top{position: absolute;bottom:40px;width:100%;height: 181px;}”,大括號前面的部分是CSS選擇器,它的作用是先找到id為head wrapper且class為s-ps-islite的節點,再從這個節點里找到class為s-p-top的節點。大括號里面的內容是樣式規則,像position規定元素采用絕對布局,bottom設定元素的下邊距為40像素,width讓元素寬度占滿父元素,height指定元素的高度。通常,我們會把整個網頁的樣式規則統一寫在后綴為.css的CSS文件里。在HTML文件中,只要用link標簽引入這個CSS文件,網頁就能變得美觀又優雅。
(3)JavaScript
??????? JavaScript簡稱JS,是一種腳本語言。HTML和CSS配合,只能給用戶展示靜態信息,缺乏互動性。而網頁上的下載進度條、提示框、輪播圖等具有交互性和動畫效果的部分,通常都是JavaScript的功勞。JavaScript的出現,改變了用戶與網頁信息的關系,不再只是單純的瀏覽和顯示,而是實現了實時、動態且可交互的頁面功能。
????????JavaScript一般保存在后綴為.js的單獨文件里。在HTML文件中,通過script標簽就可以引入JavaScript文件,比如“<script src="jquery-2.1.0.js"></script>”。
總的來說,HTML決定了網頁的內容和結構,CSS負責網頁的布局,JavaScript則定義了網頁的行為。
1.2 網頁的結構
????????我們先通過一個例子來感受 HTML 的基本結構。新建一個后綴為.html 的文本文件(名稱可自行設定),內容如下:
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><title>This is a Demo</title>
</head>
<body><div id="container"><div class="wrapper"><h2 class="title">Hello World</h2><p class="text">Hello,this is a paragraph.</p></div></div>
</body>
</html>??????? 上面是一個最簡單的HTML示例。代碼最開始的DOCTYPE聲明確定了文檔的類型,整個代碼最外面用html標簽包裹,并且有對應的結束標簽來表示代碼塊的結束。在html標簽里面,有head標簽和body標簽,它們分別對應網頁的頭部和主體部分,這兩個標簽也都有各自的結束標簽。
????????在head標簽里,定義了一些頁面的設置和引用內容。例如,“<meta charset="UTF-8">”把網頁的編碼設置成了UTF - 8;title標簽定義的標題會顯示在瀏覽器的選項卡上,不會在網頁正文中顯示。
????????body標簽里的內容會顯示在網頁的正文中。div標簽用于劃分網頁中的區域,其中有一個div的id屬性是container,id屬性在網頁里是唯一的,通過這個id能定位到對應的區域。在這個id為container的div里面,還有一個class屬性為wrapper的div標簽,class屬性也是常用的,經常和CSS一起使用來設置樣式。除此之外,代碼里還有代表二級標題的h2標簽和代表段落的p標簽,它們也都有各自的class屬性。
????????把這段代碼保存為文件后,在瀏覽器里打開它,你會發現瀏覽器的選項卡上顯示著“This is a Demo”,這是head標簽里title標簽定義的內容。而網頁的正文是由body標簽內的各個元素生成的,頁面上會顯示出二級標題和段落。
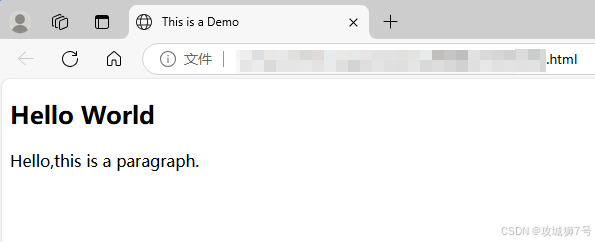
????????這個示例展示了網頁的常見結構,也就是說,標準的網頁結構是在html標簽里嵌套head標簽和body標簽,head標簽用來定義網頁的設置和引用,body標簽用來定義網頁的正文內容。
1.3 節點樹及節點間的關系
????????在 HTML 中,所有由標簽定義的內容都是節點,它們共同構成了一個 HTML DOM 樹。
DOM 是 W3C(萬維網聯盟)的標準,英文全稱是 Document Object Model,即文檔對象模型,它定義了訪問 HTML 和 XML 文檔的標準:W3C 文檔對象模型(DOM)是中立于平臺和語言的接口,允許程序和腳本動態地訪問和更新文檔的內容、結構和樣式。
W3C DOM 標準分為 3 個不同部分:
????????- 核心 DOM:針對任何結構化文檔的標準模型。
????????- XML DOM:針對 XML 文檔的標準模型。
????????- HTML DOM:針對 HTML 文檔的標準模型。
根據 W3C 的 HTML DOM 標準,HTML 文檔中的所有內容都是節點:
????????- 整個文檔是一個文檔節點。
????????- 每個 HTML 元素是元素節點。
????????- HTML 元素內的文本是文本節點。
????????- 每個 HTML 屬性是屬性節點。
????????- 注釋是注釋節點。
????????HTML DOM 將 HTML 文檔視為樹結構,這種結構稱為節點樹。通過 HTML DOM,樹中的所有節點都可以通過 JavaScript 訪問,所有 HTML 節點元素都可以被修改、創建或刪除。
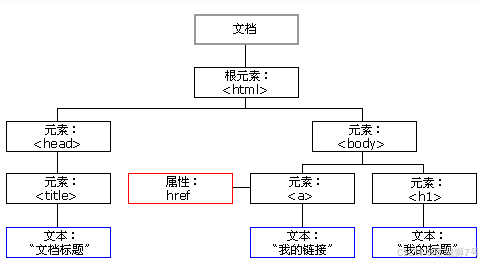
????????節點樹中的節點之間存在層級關系,我們常用父(parent)、子(child)和兄弟(sibling)等術語來描述這些關系。父節點擁有子節點,同級的子節點被稱為兄弟節點。在節點樹中,頂端節點是根(root)。除根節點外,每個節點都有父節點,同時可以擁有任意數量的子節點或兄弟節點。

1.4 選擇器
????????我們都清楚,網頁是由一個個節點構成的。CSS選擇器能夠依據不同節點設置不同的樣式規則,那要怎么找到這些節點呢?
????????在CSS里,我們借助CSS選擇器來定位節點。舉個例子,如果一個div節點的id是container,就可以寫成#container,這里“#”開頭就表示按id來選,后面跟著的就是id的名字;要是想選class為wrapper的節點,就用.wrapper,“.”開頭代表按class選,后面跟著的是class的名字;也能按照標簽名來篩選,比如選二級標題就用h2。這是最常用的三種選法,分別是按id、class、標簽名來選,得記住它們的寫法。
????????CSS選擇器還能進行嵌套選擇。選擇器之間用空格隔開,就表示有嵌套關系。比如#container.wrapper p,意思就是先選id為container的節點,再從里面選class為wrapper的節點,最后從這個節點里選p節點;要是選擇器之間沒加空格,就表示是并列關系。像div#container.wrapper p.text,就是先選id為container的div節點,接著從里面選class為wrapper的節點,再從這個節點里選class為text的p節點。
????????CSS 選擇器的篩選功能十分強大,此外,它還有一些其他語法規則,具體如下表所示:


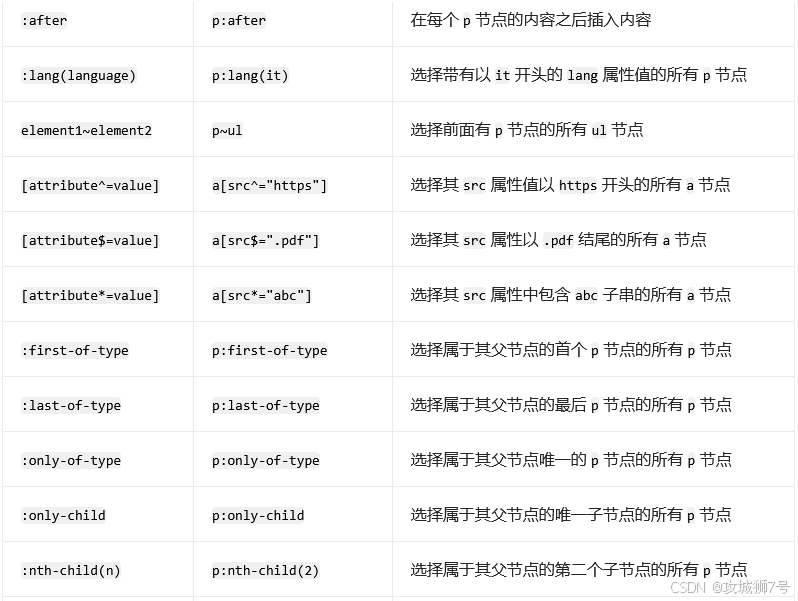
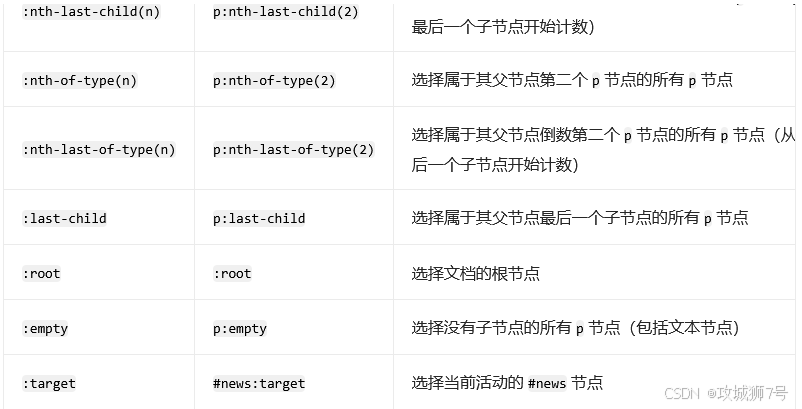

? 完整的選擇器參考表:
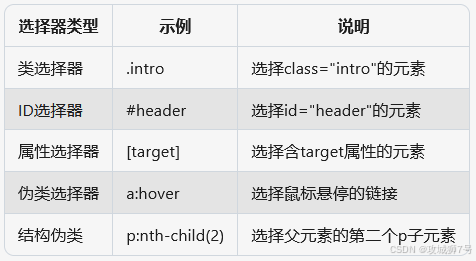
?????????此外,XPath 也是一種常用的選擇器,后面會詳細介紹。本節介紹了網頁的基本結構和節點間的關系,這些知識有助于我們更清晰地解析和提取網頁內容。
二、爬蟲的基本原理
????????咱們可以把互聯網當作一張巨大的網,而爬蟲,也就是網絡爬蟲,就像是在這張網上爬來爬去的蜘蛛。把網上的一個個節點當作網頁,當爬蟲訪問一個網頁時,就如同蜘蛛爬到了對應的節點,進而獲取網頁的信息。節點之間的連線,就好比網頁與網頁之間的鏈接。蜘蛛爬到一個節點后,能順著連線爬到下一個節點。同樣,爬蟲通過一個網頁,就能獲取到后續的網頁,如此一來,便能爬遍整個網上的節點,抓取網站的數據。
2.1 爬蟲概述
????????簡單來說,爬蟲是一種自動化程序,專門用來獲取網頁信息,再對信息進行提取和保存。下面為你簡單介紹一下:
(1)獲取網頁
????????爬蟲要做的第一件事,就是獲取網頁,確切地說是獲取網頁的源代碼。因為源代碼里包含著網頁的一些有用信息,拿到源代碼后,就能從中提取出我們需要的信息。
????????之前我們講過請求和響應的概念,向網站服務器發送請求,服務器返回的響應體就是網頁的源代碼。這里的關鍵,是要構造好請求,發送給服務器,然后接收響應并進行解析。當然,沒人會手動去截取網頁源碼,Python提供了urllib、requests等庫,來幫我們完成這項工作。使用這些庫,就能發起HTTP請求,請求和響應都能用庫中提供的數據結構來表示。得到響應后,解析數據結構里的Body部分,就能獲取網頁源代碼,這樣就通過程序實現了獲取網頁的過程。
(2)提取信息
????????拿到網頁源代碼后,接下來就要對源代碼進行分析,從中提取出我們需要的數據。最常用的方法是用正則表達式提取,但編寫正則表達式比較復雜,還容易出錯。由于網頁結構有一定的規律,我們還可以借助一些基于網頁節點屬性、CSS選擇器或XPath的庫,比如BeautifulSoup、pyquery、lxml等。這些庫能快速、高效地提取網頁信息,像節點的屬性、文本值等。提取信息是爬蟲很重要的一個環節,它能讓雜亂無章的數據變得有條理,方便我們后續對數據進行處理和分析。
(3)保存數據
????????提取完信息后,一般要把數據保存起來,方便后續使用。保存數據的方式有很多種,可以保存為TXT文本或者JSON文本,也能保存到數據庫里,比如MySQL和MongoDB。還能借助SFTP,把數據保存到遠程服務器上。
(4)自動化程序
????????爬蟲是自動化程序,能代替人完成很多操作。雖說手工也能提取信息,但要是數據量很大,或者需要快速獲取大量數據,那就得借助程序了。爬蟲在抓取數據的過程中,能進行異常處理、錯誤重試等操作,保證爬取工作持續、高效地進行。
2.2 能抓怎樣的數據
????????在網頁上,我們能看到各種各樣的信息。最常見的就是常規網頁,這類網頁對應的是HTML代碼,所以HTML源代碼是我們最常抓取的內容。另外,有些網頁返回的不是HTML代碼,而是JSON字符串,很多API接口就是這樣。這種格式的數據傳輸和解析都很方便,同樣可以抓取,而且提取數據也更輕松。網頁上還有圖片、視頻、音頻等二進制數據,利用爬蟲,能把這些數據抓取下來,并保存成對應的文件名。此外,像CSS、JavaScript和配置文件等各種擴展名的文件,只要在瀏覽器中能訪問到,爬蟲也能抓取。上面提到的這些內容,都有各自對應的URL,并且基于HTTP或HTTPS協議,只要是這類數據,爬蟲都能抓取。
2.3 JavaScript 渲染頁面
????????有時,使用 urllib 或 requests 抓取網頁時,得到的源代碼與瀏覽器中看到的不一致,這是常見問題。如今,網頁越來越多地采用 Ajax、前端模塊化工具構建,很多網頁由 JavaScript 渲染而成,原始的 HTML 代碼可能只是一個空殼。例如:
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><title>This is a Demo</title>
</head>
<body><div id="container"></div>
</body>
<script src="app.js"></script>
</html>????????在這個HTML頁面里,body節點下僅有一個id為container的節點。但值得留意的是,在body節點后面引入了app.js文件,整個網站頁面的渲染工作都由它負責。
????????當我們在瀏覽器中打開這個頁面時,瀏覽器首先會加載HTML內容。隨后,瀏覽器檢測到頁面引入了app.js文件,便會向服務器發起對該文件的請求。獲取到app.js文件后,瀏覽器就會執行其中的JavaScript代碼。這些代碼會對HTML中的節點進行修改,添加相應內容,經過這一系列操作,最終形成我們看到的完整頁面。
????????然而,當我們使用urllib或requests等庫向服務器請求頁面時,這些庫僅僅能獲取到HTML代碼,并不會自動加載JavaScript文件。這就導致我們無法看到和瀏覽器中一樣的頁面內容,也就解釋了為什么通過這些庫獲取的源代碼,和瀏覽器中實際顯示的不一樣。
????????由此可見,使用常規的HTTP請求庫獲取的源代碼,可能與瀏覽器顯示的頁面源代碼存在差異。針對這種情況,我們有兩種解決辦法。一是分析網站的后臺Ajax接口;二是借助Selenium、Splash等庫,模擬JavaScript在瀏覽器中的渲染過程。后續,我們會對采集JavaScript渲染網頁的方法展開詳細介紹。
????????在本節中,我們了解了爬蟲的部分基本原理,掌握這些知識,能幫助我們在后續編寫爬蟲程序時,進展得更加順利 。
參考學習書籍:Python 3網絡爬蟲開發實戰


)


與等距圓柱投影(Equirectangular projection))










)


)