一、RAG(檢索增強生成)
1. RAG 的定義與核心思想
RAG(Retrieval-Augmented Generation,檢索增強生成) 是一種結合 信息檢索(Retrieval) 和 文本生成(Generation) 的技術,旨在通過引入外部知識庫增強大語言模型(LLM)的能力。其核心思想是:在生成答案前,先從外部數據源檢索與問題相關的信息,并將這些信息作為上下文輸入生成模型,從而提升生成結果的準確性、實時性和可解釋性。
傳統大模型的局限性
- 靜態知識:LLM 的訓練數據固定,無法實時更新(如 ChatGPT 的知識截止到 2023年)。
- 幻覺問題:模型可能生成看似合理但實際錯誤的內容(如虛構事實)。
- 缺乏可解釋性:生成結果依賴模型內部參數,難以追溯依據。
RAG 的解決方案
通過動態檢索外部知識庫,將最新、可信的數據與模型自身知識結合,生成更可靠的結果。
2. RAG 的架構與工作流程
RAG 的架構通常分為三個階段:索引構建(Indexing)、檢索(Retrieval) 和 生成(Generation)。
2.1 索引構建(Indexing)
- 數據預處理:將文檔切分為塊(Chunk),以適應模型輸入長度限制。
- 向量化:使用嵌入模型(如 BERT、Sentence-BERT)將文本轉換為向量,存入向量數據庫(如 FAISS、Milvus)。
- 元數據關聯:附加來源、時間戳等元數據,便于后續篩選。
2.2 檢索(Retrieval)
- 用戶提問向量化:將用戶問題轉換為向量。
- 相似性匹配:在向量數據庫中查找與問題向量最相似的 Top-K 文檔塊。
- 重排序(可選):根據相關性對結果二次排序,提升精度。
優化技術:
- HyDE(假設性文檔嵌入):讓模型生成假設性答案,基于此檢索更相關文檔。
- 多路召回:結合關鍵詞檢索與向量檢索,平衡相關性與多樣性。
2.3 生成(Generation)
- 上下文構造:將檢索到的文檔塊與用戶問題拼接為提示詞(Prompt)。
- 生成答案:大模型基于上下文生成最終回答,引用來源提高可信度。
3. RAG 的優勢與挑戰
3.1 優勢
| 維度 | 說明 |
|---|---|
| 數據實時性 | 動態檢索外部數據,解決模型知識陳舊問題。 |
| 可解釋性 | 提供檢索到的文檔作為依據,增強結果可信度。 |
| 可控性 | 通過限制檢索范圍(如內部知識庫)避免生成無關內容。 |
| 低成本 | 無需重新訓練模型,通過更新外部數據即可擴展能力。 |
3.2 挑戰與解決方案
| 挑戰 | 解決方案 |
|---|---|
| 檢索質量不足 | 優化分塊策略(按語義切分)、結合多路檢索、引入重排序模型。 |
| 生成結果冗余 | 在 Prompt 中明確要求簡潔回答,或對生成內容后處理。 |
| 多模態支持 | 擴展檢索庫至圖像、視頻(如 CLIP 模型跨模態檢索)。 |
| 延遲問題 | 使用高效向量數據庫、緩存高頻查詢結果、異步檢索。 |
4. 應用場景
4.1 智能客服
- 場景:用戶咨詢產品故障處理步驟。
- RAG 作用:檢索產品手冊和最新工單記錄,生成準確解決方案,并附上操作鏈接。
4.2 教育領域
- 場景:學生提問“量子力學的基本原理”。
- RAG 作用:從教材、論文中檢索核心概念,生成適合學生水平的解釋,推薦相關學習資源。
4.3 醫療輔助
- 場景:醫生查詢某種藥物的禁忌癥。
- RAG 作用:檢索最新醫學指南和病例報告,提醒注意患者過敏史。
4.4 金融分析
- 場景:分析師詢問“當前美聯儲利率政策”。
- RAG 作用:從財經新聞、央行報告中提取關鍵數據,生成摘要并附上趨勢圖表。
5. 未來發展方向
-
多模態 RAG
支持檢索圖像、音頻、視頻等多模態數據,生成富媒體回答(如用圖表解釋經濟趨勢)。 -
端到端優化
聯合訓練檢索器與生成器,提升二者協同效率(如 Google 的 REALM 模型)。 -
個性化交互
結合用戶歷史行為調整檢索策略,提供定制化內容(如根據醫生專業領域推薦文獻)。 -
實時性增強
開發流式數據處理管道,實現分鐘級知識庫更新(適用于金融、新聞等場景)。
6. 總結
RAG 通過“檢索+生成”的架構,有效彌補了大語言模型在實時性、準確性和可解釋性上的不足。隨著向量數據庫和嵌入模型的進步,RAG 正在成為企業構建知識智能系統的核心技術。未來,與多模態、個性化需求的結合將進一步拓展其應用邊界,推動 AI 從“通用助手”向“領域專家”演進。
二、RAGFlow
官網鏈接
GitHub 中文文檔
1.RAGFlow 是什么?
RAGFlow 是一款基于深度文檔理解的開源 RAG(檢索增強生成) 引擎。它為企業提供簡化的 RAG 全流程解決方案,通過結合大語言模型(LLM)實現高可信的問答能力,并基于復雜格式數據生成可靠引用,有效降低 LLM 的幻覺風險。
2. 核心特點
2.1 數據質量決定結果精度(“Quality in, quality out”)
- 基于深度文檔理解,能夠從各類復雜格式的非結構化數據中提取真知灼見。
- 真正在無限上下文(token)的場景下快速完成大海撈針測試。
2.2 基于模板的文本切片
- 不僅僅是智能,更重要的是可控可解釋。
- 多種文本模板可供選擇
2.3 有理有據、最大程度降低幻覺(hallucination)
- 文本切片過程可視化,支持手動調整。
- 有理有據:答案提供關鍵引用的快照并支持追根溯源。
2.4 兼容各類異構數據源
- 支持豐富的文件類型,包括 Word 文檔、PPT、excel 表格、txt 文件、圖片、PDF、影印件、復印件、結構化數據、網頁等。
2.5 全程無憂、自動化的 RAG 工作流
- 全面優化的 RAG 工作流可以支持從個人應用乃至超大型企業的各類生態系統。
- 大語言模型 LLM 以及向量模型均支持配置。
- 基于多路召回、融合重排序。
- 提供易用的 API,可以輕松集成到各類企業系統。
在這里插入圖片描述
3. 系統架構
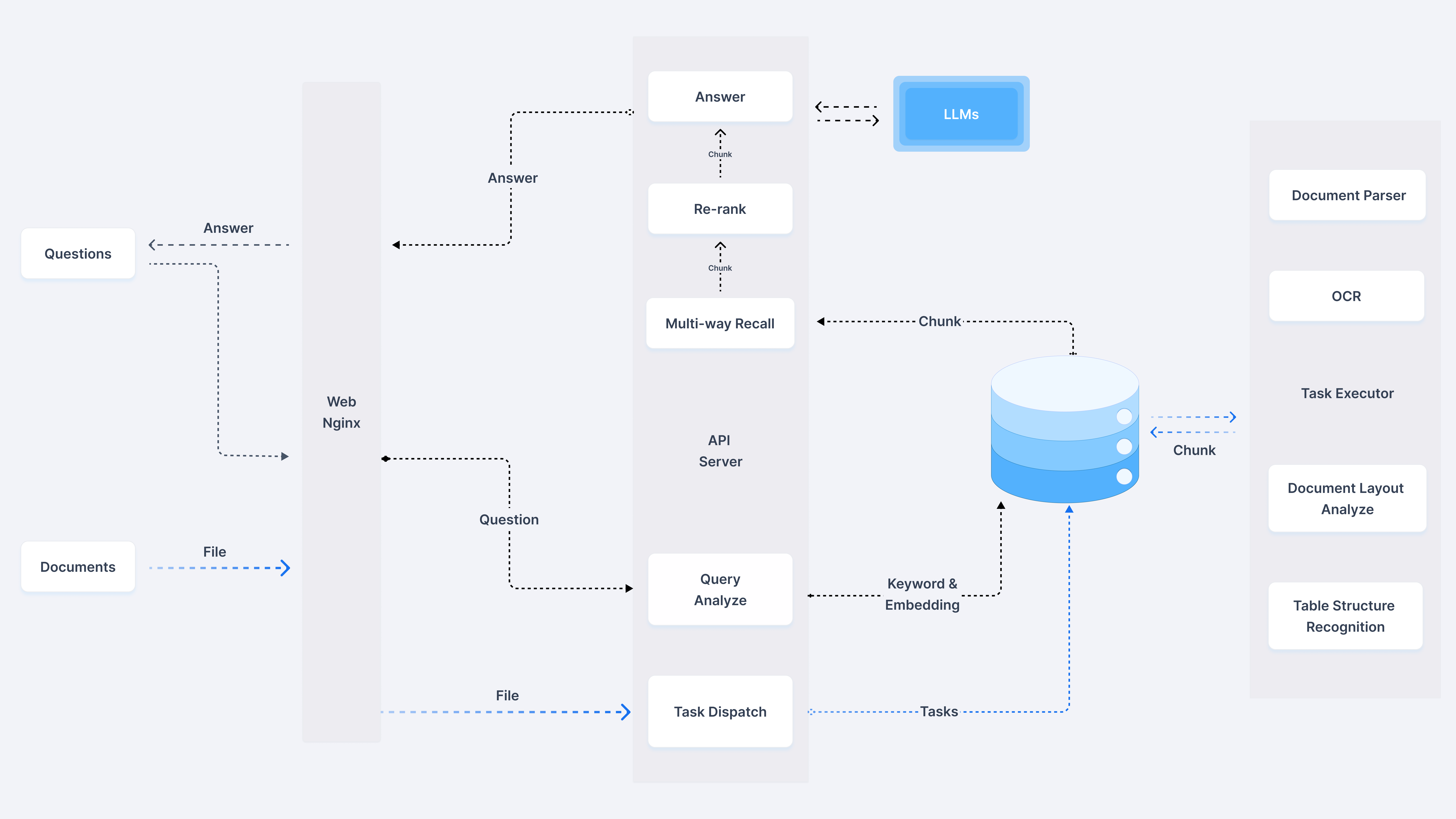
4. 為什么選擇 RAGFlow?
4.1 對比開源方案
| 功能維度 | LangChain | LlamaIndex | RAGFlow |
|---|---|---|---|
| 復雜PDF解析 | 依賴外部工具 | 僅基礎文本提取 | 原生支持表格/公式/OCR |
| 權限管理 | 無 | 基礎API密鑰控制 | 企業級RBAC + 審計日志 |
| 部署復雜度 | 需自行整合組件 | 中等 | Docker 一鍵部署 |
4.2 企業級特性
- 數據隔離:支持多租戶架構,不同部門數據完全隔離
- 合規審計:記錄所有文檔操作(上傳/檢索/刪除)并生成報表
- ?國產化適配:計劃支持國產芯片與操作系統(需參考官方路線圖確認)
5. 總結與展望
核心價值
RAGFlow 通過 多模態解析、動態分塊 和 可信生成 的三重創新,解決了企業級 RAG 落地中的三大難題:
- 復雜文檔利用率低 → 結構化提取表格/代碼/公式
- 檢索精度不足 → 混合檢索 + HyDE 增強
- 合規風險高 → 溯源標注 + 權限控制
未來演進
- ?實時流處理:探索音視頻數據的實時處理能力
- 低代碼配置:可視化界面定義分塊規則/檢索策略
- 領域增強包:推出醫療、法律等垂直領域的預訓練解析模型
對于需處理非結構化數據且重視數據主權的中大型組織,RAGFlow 提供了從文檔智能到決策支持的完整技術棧,是構建企業知識大腦的理想基座。





)



![[Linux系統編程]進程間通信—system V](http://pic.xiahunao.cn/[Linux系統編程]進程間通信—system V)



用于將笛卡爾坐標(x, y)轉換為極坐標(magnitude, angle)函數cartToPolar())

)



