參考資料:學習R
? ? ? ? 數據的來源可以由很多。R內置有許多數據集,而在其他的附件包中能找到更多的數據。R能從各式各樣的來源中讀取,且支持大量的文件格式。
1、內置的數據集
? ? ? ? R的基本分發包有一個datasets,里面全是示例數據集。很多其他包也含有數據集。使用data函數可以查看所有我們已成功加載了的包的數據集:

? ? ? ? 如果需要更完整的列表,包括已安裝的所有包的數據,可以使用
data(package=.packages(TRUE))

? ? ? ? 如果我們想訪問任意數據集里的數據,只需調用data函數,傳入數據集的名稱及其所在的包名(如果此包已經加載,可省略這個packages參數)
data("kidney",package="survival")
2、讀取文本文件
? ? ? ? 有眾多的格式和文本文件標準可用于存儲數據。用于存儲數據的通用格式為分隔符(即CSV或制表符分隔文件)、可擴展標記語言(XML)、JavaScript對象表示法(JSON)和YAML。
? ? ? ? 將數據存儲在文本文件中的主要優點是:它們可被幾乎所有的其他數據分析軟件讀取。
(1)CSV和制表符分隔(Tab-Delimited)文件
????????矩形(類似電子表格的) 數據通常存儲在帶有分隔符的文件中, 特別是逗號分隔值(CSV)和制表符分隔值文件。read.table函數將讀取這些分隔符文件,并將結果存儲在一個數據框中。
????????RedDeerEndocranialVolume.dlm 是一個以空格符分隔的文件, 它包含了一些使用不同技術
測量得到的馬鹿的顱容積數據。數據文件可以在 learningr 包的extdata文件夾中找到。該數據有標題行,所以我們需要給read.table傳遞參數header=TRUE。因為并不是每次都會進行二次測量,所以不是所有行都是完整的。給read.table傳遞參數fill=TRUE會使用NA值來代替那些缺失的域。下例中的system.file函數用于定位包中的文件。
install.packages("learningr")
library(learningr)
deer_file<-system.file("extdata","RedDeerEndocranialVolume.dlm",package="learningr"
)
deer_data<-read.table(deer_file,header=TRUE,fill=TRUE)
str(deer_data,vec.len=1)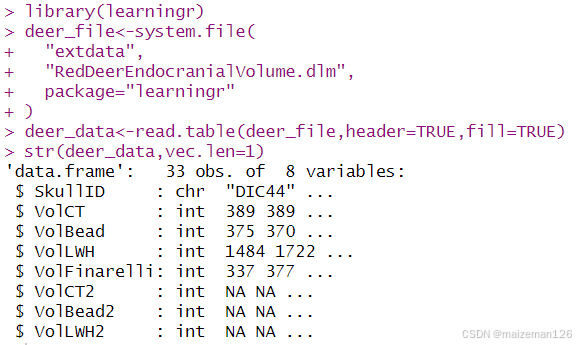
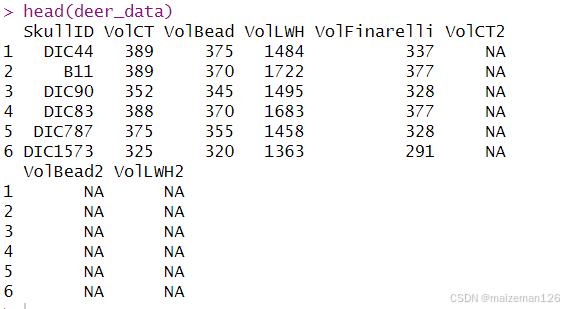
????????注意, 每個列的類已自動確定, 行和列的名字也已自動分配。 列名( 默認情況下) 必須是有效的變量名(通過使用 make.names), 如果不提供行名那么行將就會按 1、 2、 3 編號,以此類推。
? ? ? ? 有很多參數可以用來指定如何讀取該文件,其中最重要的是sep參數,它決定了使用哪個字符作為字段之間的分隔符。nrow可以指定讀取數據的行數,而skip決定跳過文件開始的多少行。更多高級選項包括:覆蓋默認的行名、列名和類,指定輸入文字的字符編碼,以及輸入的字符串格式的列如何聲明。
? ? ? ? 有幾個read.table的包裝函數使用起來比較方便。read.csv分隔符默認設置為逗號,并假設數據有標題行。read.csv2使用逗號作為小數位,并用分號作為分隔符。read.delim和read.delim2將分別使用句號和逗號作為小數位來導入制表符分隔的文件。
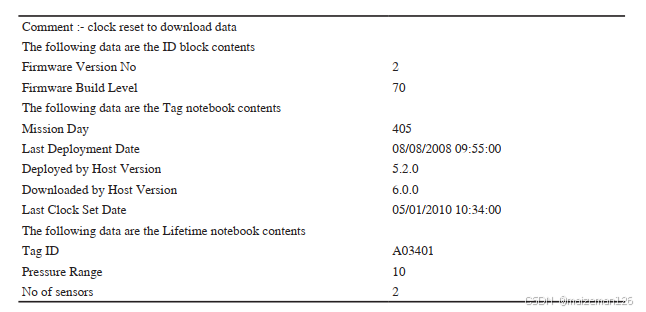
? ? ? ? 在上圖這種情況,我們不能僅調用read.csv就把所有東西都讀出來,因為不同的數據塊中所含有的字段數量不同,而且每個字段也確實不同。我們需要使用read.csv中的skip和nrow參數指定要讀取文件中的哪些位置:
crab_file<-system.file("extdata","crabtag.csv",package="learningr"
)
crab_id_block<-read.csv(crab_file,header=FALSE,skip=3,nrow=2
)
print(crab_id_block)
crab_lifetiem_notebook<-read.csv(crab_file,header=FALSE,skip=8,nrow=5
)
print(crab_lifetiem_notebook)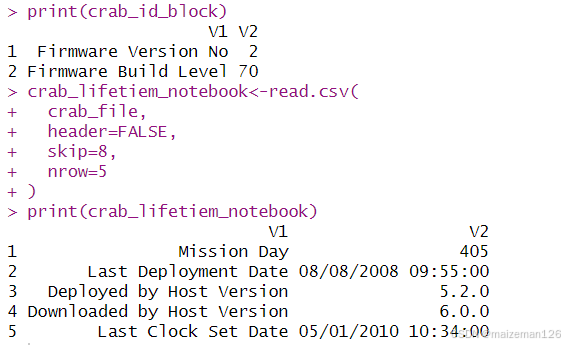
? ? ? ?如果我們的數據是從另一種語言中導入的,那么可能需要把na.strings參數傳遞給read.table。對于SQL導出的數據,則使用na.string="NULL"。對于SAS或Stata導出的數據,則需要使用na.strings="."。從Excel中導出的數據,使用na.string=c("","#N/A","#DIV/0!","#NUM")。
? ? ? ? 寫入文件通常比讀取文件要簡單,因為我們無需擔心讀取文件時出現各種問題。很顯然,write.table和write.csv分別對應著read.table和read.csv的讀操作。這兩個函數都需要一個數據框和寫入文件的路徑作為參數。
write.csv(crab_id_block,"Data/Cleaned/id_block_data.csv",row.names=FALSE,fileEncoding = "utf8"
)(2)非結構化文本文件
? ? ? ? 不是所有的文本文件都像都像定界符文件那樣有一個定義良好的而結構。如果文件的結構松散,更簡單的做法是:先讀入文件中的所有文本行,再對其內容進行分析或操作。readLines就提供了這種方法。它接受一個文件路徑(或文件連接)和一個可選的最大行數作為參數來讀取文件。
text_file<-system.file("extdata","Shakespeare's The Tempest, from Project Gutenberg pg2235.txt",package="learningr"
)
the_tempest<-readLines(text_file)
the_tempest[19:20]
help(readLines)? ? ? ? writeLines用于執行與readLines相反的操作。它寫入文件時需要一個字符向量和文件作為輸入參數:
writeLines(rev(text_file), # rev執行向量的反操作"name.txt"
)(3)XML和HTML文件
? ? ? ? 當我們導入一個XML文件時,XML包(需安裝并加載)將提供兩種選擇以存儲結果:利用內部節點,或使用R節點。通常,我們應該使用內部節點來存儲,因為這樣我們能使用XPath來查詢節點樹。
? ? ? ? 有幾個函數可以用于導入XML數據,如xmlParse:
library(XML)
xml_file<-system.file("extdata","options.xml",package="learningr"
)
r_options<-xmlParse(xml_file)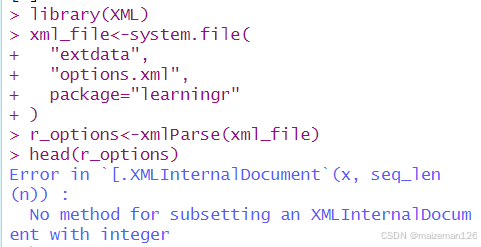
? ? ? ? 如上圖所示,使用內部節點的問題是:str和head等匯總函數不能和它們一起使用。要使用R級的節點,需設置useInternalNodes=FALSE(或使用xmlTreeParse,它會默認設置此項屬性)
xmlParse(xml_file,useInternalNodes = FALSE)
xmlTreeParse(xml_file)
? ? ? ? XPath是一種用于查詢XML文檔的語言,它能基于某些過濾規則尋找相應的節點。下例中,我們將在文檔//中尋找命名為variable的節點,此節點[]的name屬性@包含contains了warn字符串。
library(XML)
xml_file<-system.file("extdata","options.xml",package="learningr"
)
r_options<-xmlParse(xml_file)
xpathSApply(r_options,"//variable[contains(@name,'warn')]")

? ? ? ? 這種查詢在提取網頁數據中非常有用。htmlParse和htmlTreeParse是用于HTML頁面導入的函數。
(4)JSON和YAML文件
????????XML 的主要問題是它太冗長了,且你需要顯式地指定數據的類型(它在默認情況下不能區分字符串和數字),這就使得它更冗長了。如果文件大小很重要(例如,當你要在網絡上傳輸大量數據集時),信息過于冗余就成了問題。于是,有人發明了YAML和它的子集JSON來解決這些問題。它們特別適合于通過網絡傳輸大量數據集,尤其是數字數據和數組。JSON是Web應用程序彼此之間傳遞數據的事實標準。
????????有兩個包可用于處理JSON數據:RJSONIO和rjson。在讀入不正確的JSON時,RJSONIO一般比rjson更寬容。在這兩個包中讀取和寫入JSON數據的函數名基本相同,所以很容易在它們之間
換。在下例中,雙冒號 :: 用于把相同名字的函數從不同的包中分別出來(如果只加載兩個包中的一個, 就不需要雙冒號)。
install.packages(c("RJSONIO","rjson"))
library(RJSONIO)
library(rjson)
jamaican_city_file<-system.file("extdata","Jamaican Cities.json",package="learningr"
)
jamaican_ctiy_RJSONIO<-rjson::fromJSON(jamaican_city_file)
print(jamaican_ctiy_RJSONIO)????????JSON的規范不允許無窮值或 NaN 值,而且它對缺失數的定義比較模糊。這兩個包處理這些值的方式有所不同:RJSONIO 把 NaN 和 NA 映射為 JSON 的 null,但保留正負無窮;而 rjson 會把所有這些值都轉換為字符串。
special_numbers<-c(NaN,NA,Inf,-Inf)
RJSONIO::toJSON(special_numbers)
rjson::toJSON(special_numbers)
????????因為這兩種方法都用于處理備受限制的JSON規范,所以如果你發現需要大量地處理這些特殊數字類型(或想在你的數據對象中加些評論),那么最好還是使用YAML。在yaml包中有兩個函數能導入YAML數據:yaml.load接受一個YAML的字符串,并將其轉換為一個R對象;yaml.load_file 也一樣,不過它把輸入的字符串作為包含 YAML 文件的路徑處理。這里不再展示。


用于將笛卡爾坐標(x, y)轉換為極坐標(magnitude, angle)函數cartToPolar())

)





 | 零基礎入門STM32第九十二步)




(信號保存與信號捕捉))



