🧠 向所有學習者致敬!
“學習不是裝滿一桶水,而是點燃一把火。” —— 葉芝
我的博客主頁: https://lizheng.blog.csdn.net
🌐 歡迎點擊加入AI人工智能社區!
🚀 讓我們一起努力,共創AI未來! 🚀
現在大家都在采用向量搜索來適應用戶需求。顧名思義,向量搜索是通過一種稱為向量的概念來查找和比較對象的技術。簡單來說,它幫你發現對象之間的相似性,讓你能在數據中找到復雜且符合上下文的關聯。這項技術是AI搜索類應用的幕后功臣。
向量搜索是現代數據平臺(如向量數據庫)中的一項AI驅動的搜索功能,幫助用戶構建更靈活的應用。你不再局限于基礎的關鍵詞搜索,而是能跨越任何數字媒體類型,找到語義相似的信息。
它的核心是眾多機器學習系統之一,由各種規模和復雜度的大語言模型LLM驅動。這些模型可以通過數據庫和傳統平臺獲取,甚至被推送到邊緣設備,在移動端運行。
本文將介紹向量搜索、相關術語、功能及其在現代數據庫技術和人工智能AI創新中的應用。
什么是向量?
向量是一種數據結構,存儲了一組數字。在這里,它指的是保存了數據集數字摘要的向量,可以看作是數據的指紋或摘要,正式名稱叫嵌入。以下是一個簡單的例子:
| "紅蘋果": [-0.02511234? 0.05473123 -0.01234567 ...? 0.00456789? 0.03345678 -0.00789012] |
向量搜索的好處
向量搜索為數據庫及其應用帶來了一系列新能力。簡而言之,它幫助用戶在海量信息(即語料庫)中找到更符合上下文的匹配結果。接近度的概念很重要——向量搜索通過統計方法將項目分組,展示它們的相似性或相關性。這不僅適用于文本,還適用于更多類型的數據,盡管我們的例子多為文本,以便與傳統搜索系統對比。
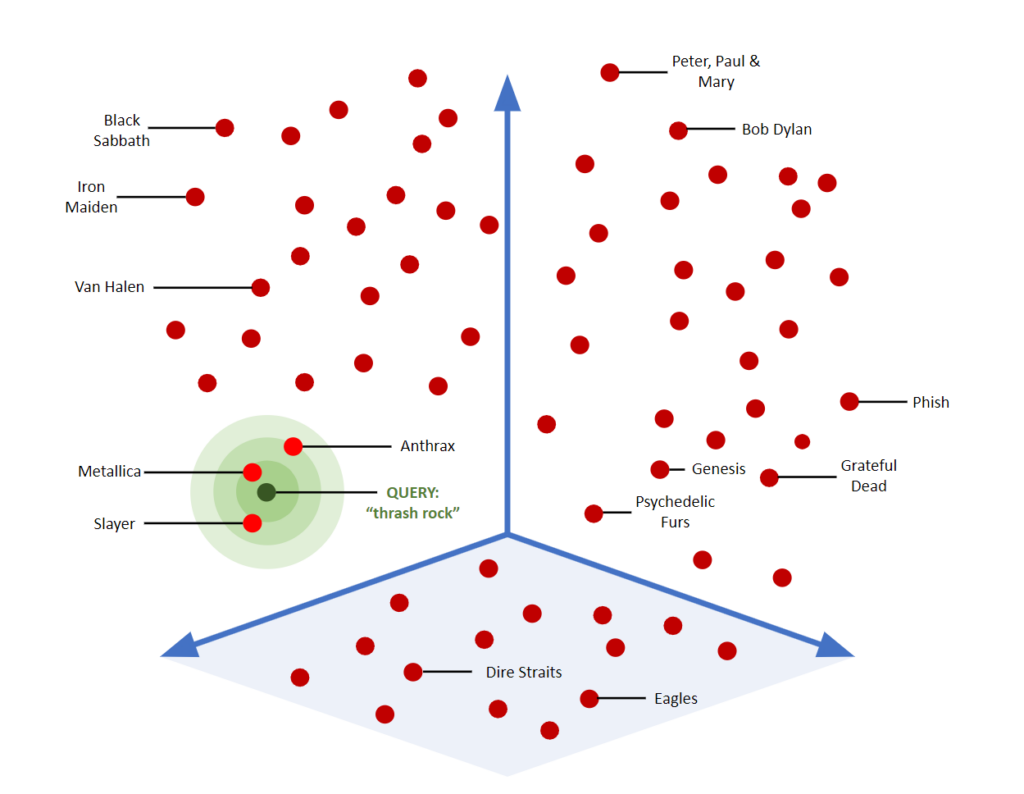
這張圖展示了向量搜索如何在3D空間中映射、查找和分組“相似”對象的可視化示例。
獲取海量通用知識
向量搜索也是將AI工具引入應用的好方法,提供了傳統搜索工具無法實現的靈活適應性。由于有許多公開的大語言模型(LLM),任何公司都可以采用它們作為應用搜索的基礎。LLM存儲了大量信息,搜索它們的結果能為你的應用帶來指數級價值,而無需編寫復雜代碼。這是許多應用通過新功能升級的方式之一。
超級搜索 vs. 傳統搜索
幸運的是,在更復雜的場景中,向量搜索也是一種更快的搜索方法。傳統的關鍵詞搜索系統可以優化以在文檔中查找匹配文本,但一旦需要應用復雜的模糊匹配算法或極端的布爾謂詞變通方案(比如多個WHERE子句),搜索就會變慢且更復雜。
在復雜環境中成功搜索所需的各種權衡,可以通過向量搜索避免。不過,這需要一個服務級API(如OpenAI)和足夠的資源來連接應用和LLM。根據你選擇的LLM,你會有不同的選擇和限制。
傳統搜索與向量搜索的區別
上述好處與兩種搜索方法的技術差異有所重疊。本節我們將深入探討這些差異的核心。
上下文與語義搜索
許多搜索系統使用關鍵詞或短語搜索,優化為查找精確的文本匹配或使用關鍵詞頻率最高的文檔。但問題是,這些方法可能缺乏上下文和靈活性。例如,搜索“樹”可能永遠無法匹配實際樹種名稱的數據,盡管這些數據非常相關。這種上下文匹配是語義搜索的一種形式——單詞之間的上下文和關系很重要。
相似性
向量搜索不僅關乎語義關系。例如,在文本應用中,它超越了使用單詞和短語,還能通過輸入單詞、句子、段落等,在更深層次上匹配語義和上下文,找到相似的文檔。
相似性搜索也適用于圖像。如果你要寫一個比較兩張圖像的應用,你會怎么做?如果只是逐個像素比較,你只能找到顏色、分辨率、編碼等完全相同的圖像。但如果你能分析圖像并生成內容向量嵌入,就可以比較它們并找到匹配項。在圖像例子中,向量嵌入描述了每張圖像的內容,然后讓你比較它們——這是一種更強大的比較和發現“接近度”的方法。
向量搜索的工作原理
向量搜索通過創建和比較向量嵌入來工作。其原理是數據可以轉換為數字向量表示(嵌入),并與其他以類似數字表示(使用LLM)編目的數據進行比較。
它將不同類型的數字內容(文本、音頻、視頻等)索引為神經網絡能理解的通用語言。
LLM創建的模型保存了代表訓練數據的向量。例如,維基百科的每個段落都可以被摘要并索引為向量。然后,用戶可以提交自己的數據向量(通常通過嵌入過程生成)到向量搜索系統,以找到相似的段落。
雖然背后有很多復雜的工作,但這就是其核心。
構建向量搜索應用的三個步驟
構建或使用向量搜索應用包括三個階段:
- 為自定義數據或查詢創建嵌入
- 使用基于大語言模型(LLM)訓練的向量引擎比較結果,找到與模型中數據語料庫最匹配的語義數據
- 將LLM結果與自定義應用數據或數據庫進行比較,找到更相關的匹配
第一步——為請求創建嵌入
嵌入在向量應用中就像數據的指紋,類似于稍后可以在索引中使用的鍵。一段數據(文本、圖像、視頻等)被發送到向量嵌入應用,轉換為數字表示(向量)。這個向量嵌入代表了輸入到嵌入應用的對象。幕后,一個大語言模型(LLM)引擎被用來創建嵌入,以便在下一步中從同一LLM中檢索匹配項。
在數據庫領域,表列中的文本可以通過嵌入引擎處理,向量對象可以保存在該行或JSON對象的屬性中。每個文檔或記錄的嵌入被索引,以便在搜索請求期間進行內部比較。
假設有一個零售目錄的網頁應用,用戶可以輸入描述服裝類型和顏色的文本來搜索庫存。應用將用戶請求發送到LLM進行向量嵌入處理。LLM用于計算向量表示以供下一步使用。“紅蘋果”可能變成如下所示的高維數組向量,以JSON存儲:
| { "word": "紅蘋果", "embedding": [0.72, -0.45, 0.88, 0.12, -0.65, 0.31, 0.55, 0.76] } |
這是一個過度簡化的例子,但本質上,向量嵌入只是通過特定機器學習過程分析數據后生成的多維數組。嵌入有不同的類型和大小,基于各種LLM,但這超出了本文的范圍。
第二步——從LLM中查找匹配項
假設LLM已經為其構建數據的所有部分創建了嵌入。如果LLM是用維基百科訓練的,那么每個段落可能都有自己的嵌入。大量的嵌入!
搜索階段是找到最接近匹配的嵌入的過程。向量搜索引擎可以接受現有嵌入,或從搜索查詢動態創建一個。例如,它可以接受應用中的用戶文本輸入或數據庫查詢,并使用LLM查找模型中的相關內容。然后,它將最相關的匹配返回給應用。
繼續零售例子,“藍色T恤”的向量嵌入可以作為查找相似數據的鍵。應用將該向量發送到中央LLM,根據構建LLM時分析的文本描述或圖像,找到最相似和語義相關的內容。
例如,你可能會得到一個包含五個文檔的列表,它們的向量嵌入在相似性上匹配。如下所示,每個文檔都有自己的向量表示。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | { "embeddings": [ { "word": "紅蘋果", "embedding": [0.72, -0.45, 0.88, 0.12, -0.65, 0.31, 0.55, 0.76] }, { "word": "爛蘋果", "embedding": [0.71, -0.42, 0.85, 0.15, -0.68, 0.29, 0.53, 0.78] }, { "word": "小柯基", "embedding": [0.73, -0.46, 0.87, 0.11, -0.64, 0.33, 0.56, 0.74] }, { "word": "大別野", "embedding": [0.75, -0.41, 0.89, 0.14, -0.67, 0.28, 0.54, 0.77] }, { "word": "云南滇紅", "embedding": [0.72, -0.44, 0.86, 0.13, -0.66, 0.30, 0.55, 0.76] }, { "word": "牛仔褲", "embedding": [0.70, -0.43, 0.84, 0.16, -0.69, 0.27, 0.52, 0.79] } ] } |
第三步——查找與自定義數據的匹配項
如果你只需要查找LLM中存儲的信息匹配項,那么工作就完成了。但真正自適應的應用會希望從內部數據源(如企業數據庫)中提取匹配和信息。
假設數據庫中的文檔或記錄已經保存了向量嵌入,并且你從LLM中獲得了匹配項。現在,你可以將這些匹配項發送到數據庫的向量搜索功能中,找到相關的數據庫文檔。操作上,它就像另一個索引字段,但會給搜索結果帶來更定性的感覺。
向量搜索如何找到匹配項?
向量搜索結合了三個概念:用戶生成的數據(請求)、包含代表數據源模型的LLM語料庫(模型),以及數據庫中的自定義數據(自定義匹配)。向量搜索讓這三個因素協同工作。
向量搜索支持什么?
只要能為任何類型的數據創建嵌入,并以相同方式(來自同一LLM)與其他嵌入進行比較,向量搜索就能找到相似性。
根據使用的LLM,結果可能會有很大差異,因為LLM的訓練數據來源不同。例如,如果你想搜索相似的圖像,但使用的LLM只包含古典文學,那么你會得到無法使用的結果(盡管如果是古典作家的圖片,可能還有點希望)。
同樣,如果你正在構建一個法律案例,而你的LLM只在Reddit數據上訓練,那么你可能會陷入一個獨特的場景,或許有一天能拍成一部好電影(當然,是在你被取消律師資格之后)。
這就是為什么確保支持你體驗的LLM針對正確的向量搜索用例和你所需的信息非常重要。非常通用的LLM會有更多上下文,但針對你行業的專業LLM會為你的業務提供更準確和細致的信息。
大規模進行向量搜索
任何執行向量搜索的企業系統在生產環境中都必須能夠擴展(參見我們的云數據復制指南)。這使得能夠復制和分片索引的向量搜索系統尤為關鍵。
當系統需要搜索索引以查找匹配項時,工作負載可以分布在多個節點上。
同樣,創建新嵌入并為其建立索引也將受益于資源隔離,這樣其他應用功能不會受到影響。資源隔離意味著向量搜索相關功能擁有自己的內存、CPU和存儲資源。
在數據庫環境中,確保所有服務都正確分配資源非常重要,這樣服務之間不會競爭。例如,表查詢、實時分析、日志記錄和數據存儲服務都需要自己的空間,向量搜索服務也是如此。
分布式LLM訪問API也很重要。由于許多其他服務可能調用嵌入,生成嵌入的API和系統也必須能夠隨著流量增長而擴展。對于基于云的LLM服務,確保在開始原型設計之前,它們的服務級別協議能夠滿足你的生產需求。
外部服務通常可以快速高效地擴展,但隨著規模擴大,需要額外資金。在評估選項時,確保清楚了解價格滑動比例。
向量搜索的未來
大多數應用開發將由混合搜索場景驅動。單一的搜索或查詢方法將無法滿足未來的靈活性需求。混合搜索能力意味著你可以使用向量搜索獲取語義匹配,同時使用基礎SQL謂詞甚至地理空間索引縮小結果范圍。
將這些功能結合到單一的混合搜索體驗中,將使開發者更容易從應用中提取最大靈活性。這包括將所有向量搜索功能擴展到邊緣移動設備以及在云端和本地。
檢索增強生成(RAG)將允許開發者在LLM之上添加更多自定義上下文感知。這將減少重新訓練LLM的需求,同時為開發者提供保持嵌入和匹配最新的靈活性。
向量搜索還將通過一種可插拔知識模塊定義,允許企業基于來自不同來源的LLM引入廣泛的信息。想象一個維護電線桿的移動現場應用。語義圖像搜索可能幫助識別電線桿物理結構的等等問題。
向量搜索常見問題
為什么向量搜索很重要?
向量搜索很重要,因為它提供了一種新穎的方法,利用最新的機器學習和AI技術,在數字數據之間找到相似性和上下文。
什么是向量搜索嵌入?
向量嵌入是保存了分析數據獨特數字表示的向量。機器學習(ML)工具使用大語言模型(LLM)分析輸入數據并生成描述數據的向量嵌入。然后,向量嵌入被保存在數據庫或文件中供后續使用。
傳統搜索和向量搜索有什么區別?
主要區別在于傳統搜索優化為查找精確的關鍵詞或短語匹配,而向量搜索旨在在更明確的語義上下文中找到相似概念。
向量搜索面臨哪些挑戰?
主要挑戰是應用必須依賴大語言模型(LLM)來幫助創建嵌入和查找上下文匹配。
)





 | 零基礎入門STM32第九十二步)




(信號保存與信號捕捉))







