前言
??在 RK3588 上部署大模型可以顯著提升計算效率、節能、加速推理過程,并實現本地化推理,適合各種邊緣計算應用,如智能設備、自動駕駛、工業機器人、健康監測等領域。此外,RK3588 配備了強大的 NPU(神經網絡處理單元),可以加速深度學習推理過程。通過在 RK3588 上部署大模型,NPU 能夠顯著提高模型推理速度,減少推理時間,尤其在進行實時推理時十分重要。
1.部署方式
現有我知道的部署方式有兩種,一是利用ollama去部署,二是使用rknn官方代碼庫去部署,前者使用cpu,后者使用npu,先說結論兩者token速度相差不大。
廢話少說,下面分享部署過程。
1.1 利用ollama部署
這里就不多說了,因為之前寫過一篇利用ollama部署deepseek的文章,這里就不贅述,直接甩命令:
# 下載并安裝ollama
curl -fsSL https://ollama.com/install.sh | sh# 下載deepseek-1.5b
ollama pull deepseek-r1:1.5b# 運行deepseek
ollama run deepseek-r1:1.5b
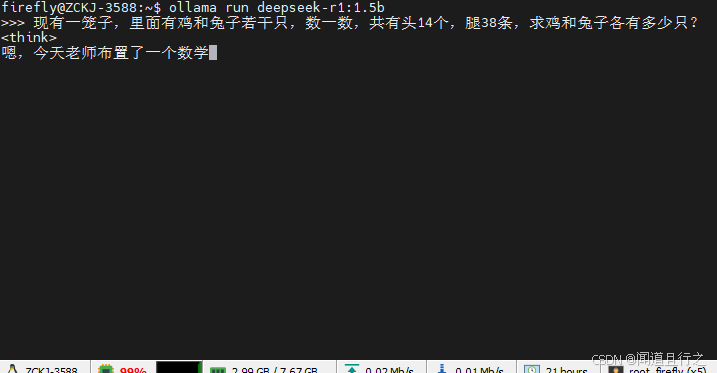
運行之后可以看到,cpu的占用幾乎滿了:
](https://i-blog.csdnimg.cn/direct/6f4497d465d14bab990f3809e521424c.png)
watch sudo cat /sys/kernel/debug/rknpu/load
查看一下npu的占用率,根本沒動:

1.2 官方代碼庫部署
1.2.1 安裝依賴(x86_64機器)
conda create -n rkllm python=3.10
conda activate rkllm
pip install rkllm_toolkit-1.1.4-cp310-cp310-linux_x86_64.whl
這里的rkllm_toolkit安裝包可以去這里下載:rknn-llm,如果嫌下載慢可以私信問我要。
1.2.2 下載模型及轉換模型(x86_64機器)
下載項目地址:rknn-llm
下載模型地址:
DeepSeek-R1-Distill-Qwen-1.5B
cd examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export/
python export_rkllm.py
轉換之前記得修改你的模型路徑:

轉換之后地模型后綴為rkllm。
1.2.3 編譯運行代碼(x86_64機器)(可選)
①先下載下載交叉編譯工具鏈 gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu
這里多說一句,交叉編譯工具鏈的作用是是為了在x86_64平臺下編譯arrch平臺下能夠執行的文件。
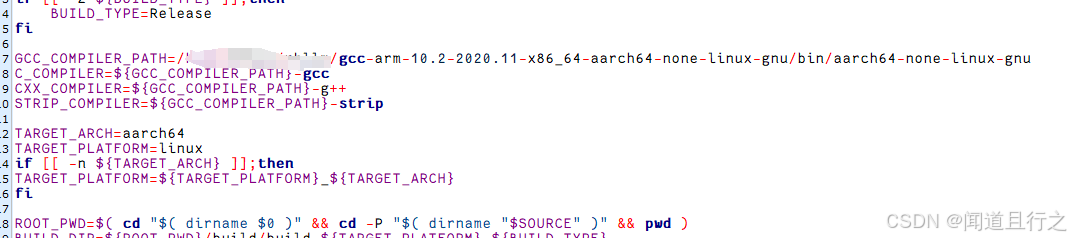
②修改examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/build-linux.sh中GCC_COMPILER_PATH的路徑:
③開始編譯:
cd examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/
bash build-linux.sh
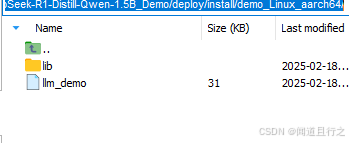
如圖所示,編譯之后所需庫和可執行文件在deploy/install/demo_Linux_aarch64/目錄下:
1.2.4 直接下載編譯好的代碼(x86_64機器)(可選)
如果不想自己編譯代碼,這里有編譯好的代碼:
git clone https://www.modelscope.cn/radxa/DeepSeek-R1-Distill-Qwen-1.5B_RKLLM.git
注:1.2.3和1.2.4必選其中一個
1.2.5 運行代碼(RK3588)
將轉化模型和代碼復制到rk3588后,執行以下命令:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./lib
export RKLLM_LOG_LEVEL=1
./llm_demo DeepSeek-R1-Distill-Qwen-1.5B.rkllm 10000 10000
這里可以看到,cpu的利用率下去了:
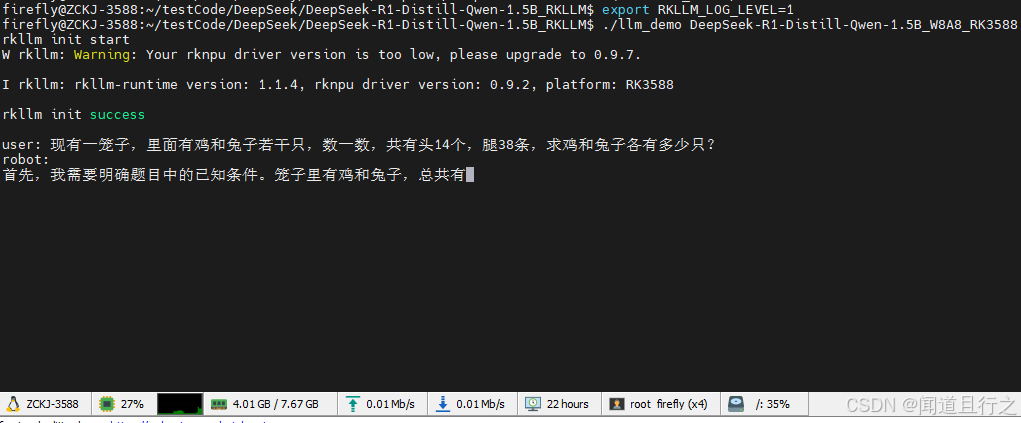
每個npu的占用率大概在30%-40%之間:

參考
RKLLM DeepSeek-R1
這里推薦一個網站,在Hugging Face下不下來的模型可以在這里下載!!魔搭社區
總結
??本文介紹了兩種在RK3588上部署deepseek-1.5b的方法,雖然兩種方法的token是差不多的,但是我還是推薦使用npu的方法去推理大模型,后續會繼續測試deepseek中更大參數體量的模型,測試一下rk3588的極限在哪里。



)






)


)
)



)
漢諾塔問題)