一、 Stable Diffusion簡介
2022年作為AIGC(Artificial Intelligence GeneratedContent)時代的元年,各個領域的AIGC技術都有一個迅猛的發展,給工業界、學術界、投資界甚至競賽界都注入了新的“[AI(https://so.csdn.net/so/search?q=AI&spm=1001.2101.3001.7020)活力”與“AI勢能”。
其中在AI繪畫領域,StableDiffusion當仁不讓地成為了開源社區中持續繁榮的AI繪畫核心模型,并且快速破圈,讓AIGC的ToC可能性比肩移動互聯網時代的產品,每個人都能感受到AI帶來的力量與影響。StableDiffusion由CompVis研究人員創建的主要用于文本生成圖像的深度學習模型,與初創公司StabilityAI、Runway合作開發,并得到EleutherAI和LAION的支持,它主要用于根據文本的描述產生詳細圖像,也就是常說的txt2img
的應用場景中:通過給定文本提示詞(text prompt),該模型會輸出一張匹配提示詞的圖片。例如輸入文本提示詞:A cute cat,StableDiffusion會輸出一張帶有可愛貓咪的圖片(如下圖)。
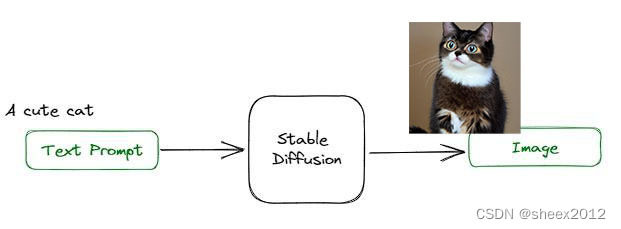
Stable Diffusion(簡稱SD)是AI繪畫領域的一個核心模型,與Midjourney不同的是,Stable
Diffusion是一個完全開源的項目(模型、代碼、訓練數據、論文、生態等全部開源),可拓展性強、 出圖效率高、
數據安全保障,這使得其能快速構建強大繁榮的上下游生態,并且吸引了越來越多的AI繪畫愛好者加入其中,與AI行業從業者一起推動AIGC領域的發展與普惠。可以說,AI繪畫的ToC普惠在AIGC時代的早期就已經顯現,這是之前的傳統深度學習時代從未有過的。
Stable
Diffusion模型基于一個擴散過程,逐步從噪聲中恢復出圖像信息。在訓練階段,模型會學習如何逐步將噪聲轉化為真實的圖像數據;而在生成階段,模型則可以從隨機噪聲出發,通過反向的擴散過程,生成出與訓練數據分布相似的圖像。Stable
Diffusion主要由變分自編碼器(VAE)、U-Net和一個文本編碼器三個部分組成。在前向擴散過程中,高斯噪聲被迭代地應用于壓縮的潛在表征。每個去噪步驟都由一個包含殘差神經網絡(ResNet)的U-
Net架構完成,通過從前向擴散往反方向去噪而獲得潛在表征。最后,VAE解碼器通過將表征轉換回像素空間來生成輸出圖像。

我們可以通過官方網站 Stability AI,以及Dream
Studio、Replicate、Playground
AI、Baseten等網站在線體驗Stable
Diffusion的巨大威力。但是,一方面國外的網站訪問畢竟還是不方便(經常需要科學上網,你懂的),另一方面也不想讓自己的一些“幼稚”想法被他們“竊取”。相比于集成在網絡平臺的SD或者其他AI繪畫平臺來說,自部署平臺沒有生成數量的限制,不用花錢,不用被NSFW約束,生成時間快,不用排隊,自由度高,而且功能完整,插件豐富,可以調試和個性化的地方也更多;更穩定,也更容易讓SD變成生產力或者商業化使用。既然這樣,那就自力更生,在本機上自己部署一個,可以隨心所欲地玩圖、玩圖…。
二、Stable Diffusion v2安裝
1. 安裝前的準備
現有深度學習訓練和部署環境在硬件上一般基于Nvidia
GPU,在底層需要顯卡驅動和CUDA工具包(需要包含配套版本的cuDNN),在應用軟件層面需要Python編譯和解釋器,以及基于Python的深度學習框架(如Pytorch、TensorFlow等)。同時,為了方便代碼自動下載和程序模塊化管理,通常還需要安裝git和conda軟件。筆者(Sheex2012)主機配備了RTX
4070Ti 12G顯卡,并事先安裝了CUDA 12.1,Python 3.11.6,git 2.44,Pytorch 2.1.2,能夠滿足Stable
Diffusion環境要求。本文重點聚焦Stable Diffusion推理程序的部署,硬件需求確認和基礎軟件的安裝這里不再贅述。
2. 下載和部署Stable Diffusion
我們從Stability.AI的github官方開源Stability.AI
Stablediffusion下載源碼:
git clone https://github.com/Stability-AI/stablediffusion.git* 1
當然,也可以從網頁上以下載源碼ZIP包,解壓縮到本地。
源碼下載完成后,接下來需要安裝項目的依賴項:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple * 1
然后從huggingface下載預訓練模型v2-1_768-ema-
pruned.ckpt,并存放到checkpoints文件夾中。
3. 運行Stable Diffusion
部署完成后,運行下述腳本,生成圖片:
python ./scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt ./checkpoints/v2-1_768-ema-pruned.ckpt --config ./configs/stable-diffusion/v2-inference-v.yaml --H 768 --W 768* 1
可是,報錯了:
No module named 'ldm'* 1
這個應該是目錄結構的問題,將ldm拷貝/移動到script文件夾,再來一次,不出意外,還是有點小意外,內存不夠了:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 9.49 GiB. GPU 0 has a total capacty of 11.99 GiB of which 0 bytes is free. Of the allocated memory 14.77 GiB is allocated by PyTorch, and 9.52 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF* 1
那就把圖像的尺寸調整成512x512,問題解決了。

這是生成的圖片(存放在outputs\txt2img-samples文件夾中):

三、 Stable Diffusion WebUI 安裝
Stable
Diffusion只是提供一個模型,提供基礎的文本分析、特征提取、圖片生成這些核心功能,但自身是沒有可視化UI的,用起來就是各種文件加命令行。原始的Stable
Diffusion程序(腳本)只能以命令行的方式進行,參數設置很不方便,而且每次調用時,需要事先加載預訓練模型,圖像生成完成后會釋放內存中的模型并結束進程,運行效率低,交互操作極其麻煩。
開源的 Stable Diffusion 社區受到了廣泛民間開發者大力支持,眾多為愛發電的程序員自告奮勇的為其制作方便操控的 GUI
圖形化界面。其中流傳最廣、功能最強也是被公認最為方便的,就是由越南超人 AUTOMATIC1111 開發的 WebUI,即大名鼎鼎的Stable
Diffusion WebUI。可以看到github上的start已經超過130k了,真是神一樣的存在。

PS,大神的頭像直接使用了越南盾中胡志明頭像。

Stable Diffusion WebUI集成了大量代碼層面的繁瑣應用,將 Stable Diffusion
的各項繪圖參數轉化成可視化的選項數值和操控按鈕,用戶可以直接通過 Web 頁面使用 Stable
Diffusion。如今各類開源社區里
90%以上的拓展應用都是基于它而研發的。
Stable Diffusion WebUI是一個最流行的開源 Stable Diffusion 整合程序,其核心功能是 文生圖 和 圖生圖,這也是
Stable Diffusion 的核心能力。Stable Diffusion WebUI
的其它功能,比如ControlNet、高清放大、模型訓練等等都是其它第三方開發的,有的已經內置到 WebUI 中,隨著 WebUI
的發布而發布,有的還需要用戶手動安裝。
當然,除了 WebUI 還有一些其他的 GUI 應用,比如 ComfyUI 和 Vlad Diffusion
等,不過它們的應用場景更為專業和小眾,感興趣的可以點擊下面的 GitHub 鏈接了解,這里就不再贅述了。
1. 手動安裝
我們先手動方式一步一步安裝,從中體驗一下其中的繁瑣(其實,這對于從事深度學習的相關技術人員來說是常規操作)。
首先,從github上下載源碼:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git* 1
其次,下載安裝Stable Diffusion WebUI的依賴項:
cd stable-diffusion-webui
pip install -r requirements_versions.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple * 1* 2* 3


依賴項成功安裝后,還是從huggingface下載v1-5-pruned-
emaonly.safetensors預訓練模型,放置到models\Stable-diffusion文件夾。
好了,開始魔法吧。
python webui.py* 1命令行窗口顯示了模型加載運行過程,這里一共花了49.2秒。* 1

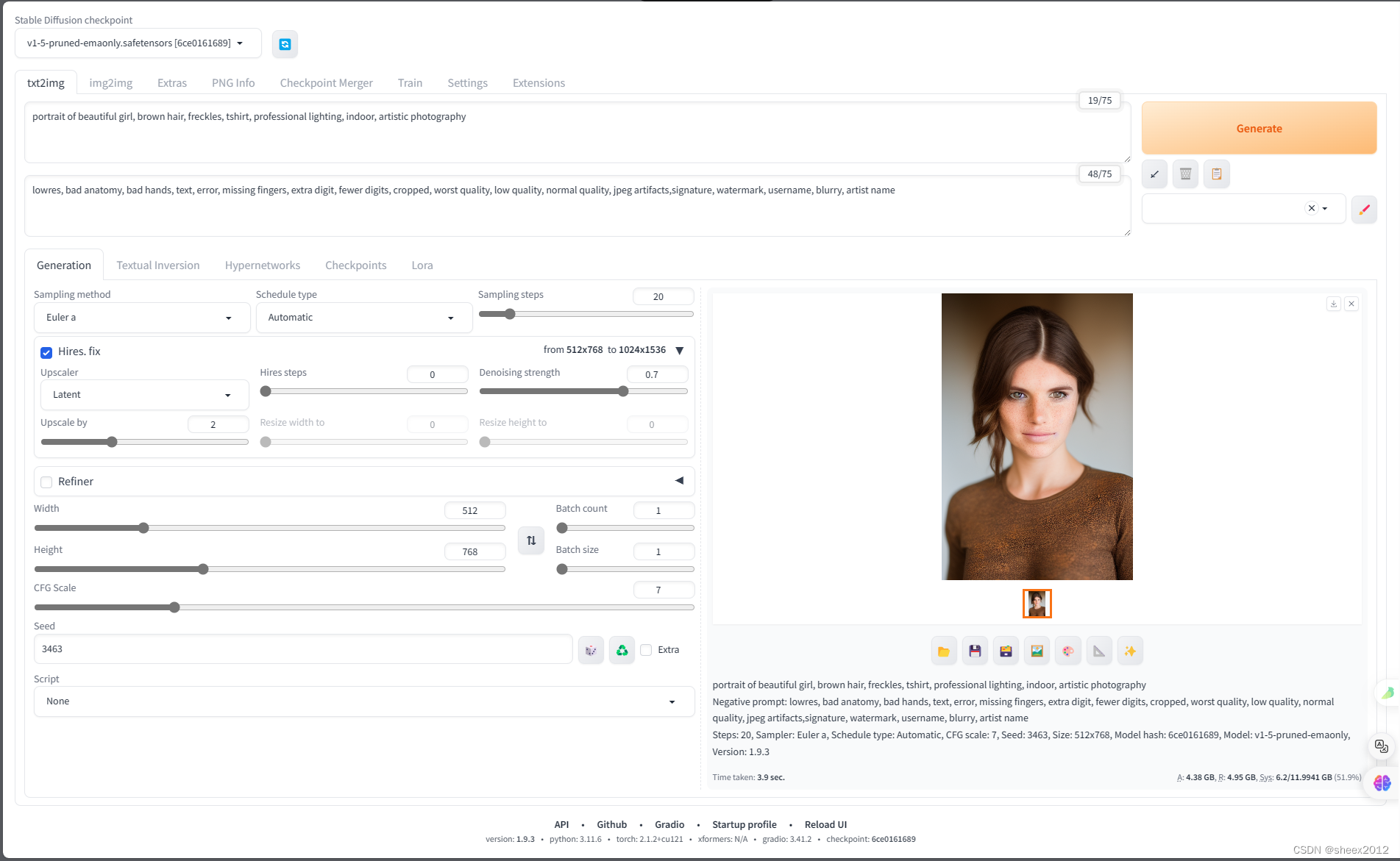
進入 http://127.0.0.1:7860網站,輸入提示詞:
portrait of beautiful girl, brown hair, freckles, tshirt, professional lighting, indoor, artistic photography* 1
反向提示詞:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name* 1
點擊,Generate按鈕,3.9秒后,生成一幅女孩肖像畫。GPU占用3.8G左右。

如果覺得全是英文的界面操作起來不夠方便,可以:
1)從[Stable-diffusion-webui 的漢化擴展](https://github.com/VinsonLaro/stable-
diffusion-webui-chinese “Stable-diffusion-webui
的漢化擴展”)下載漢化語言包,把"localizations"文件夾內的"Chinese-All.json"和"Chinese-
English.json"復制到"stable-diffusion-webui\localizations"目錄中;
2)點擊"Settings",左側點擊"User interface"界面,在界面里最下方的"Localization (requires
restart)“,選擇"Chinese-All"或者"Chinese-English”;
3)點擊界面最上方的黃色按鈕"Apply settings",再點擊右側的"Reload UI"即可完成漢化。

不過,個人覺得漢化后的文字有點擁擠。
2. 自動安裝
事實上,Stable Diffusion
WebUI官方網站中不再有手動安裝的步驟,我的理解是作者鼓勵大家采用自動安裝方式,而自動安裝的確非常方便的。當我們下載完成Stable Diffusion
WebUI源碼后,在確保已經安裝了Python 3.10.6和git后,雙擊批處理文件webui-user.bat即可。

從命令行窗口輸出,我們看到,批處理命令自動下載安裝了Pytorch等依賴項:

從github clone 并安裝Clip Open_Clip等依賴程序,而且,由于眾所周知的原因,從github clone 源碼會經常報錯:

沒關系,接著多運行幾遍即可。然后,再從 從huggingface下載預訓練模型v1-5-pruned-emaonly.safetensors(當然,還是會報錯):
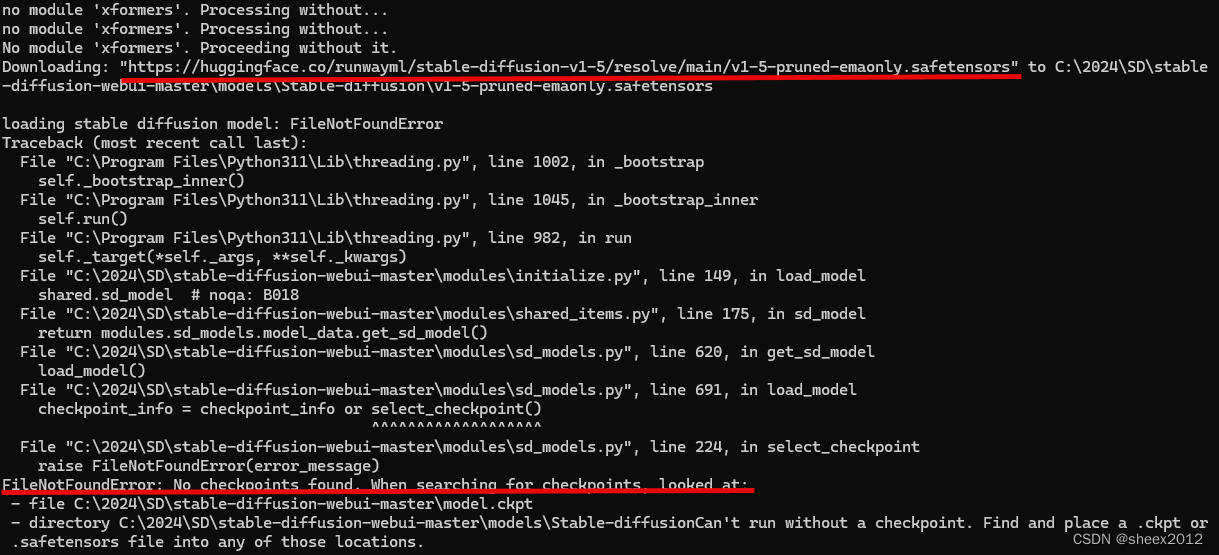
當所有的問題都解決之后,批處理文件webui-user.bat,將和前述的一樣,將開放http://127.0.0.1:7860網站,后續處理過程不再贅述。

- 自動安裝過程分析
1) webui-user.bat 分析
自動安裝和手動安裝在結果上是沒有區別的,都是下載源碼、下載安裝依賴項(包括二進制和github源碼)、下載預訓練模型,然后按照配置參數運行程序。自動安裝過程把上述過程全部放到批處理文件中webui-
user.bat,讓我們來看看它到底做了啥。
@echo offset PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=call webui.bat* 1* 2* 3* 4* 5* 6* 7* 8* 9
webui-user.bat只有短短幾行,首先將四個環境變量置空,然后調用webui.bat,所以webui.bat默默承擔了所有。
2) webui.bat 簡要分析
7. if not defined PYTHON (set PYTHON=python)
8. if defined GIT (set "GIT_PYTHON_GIT_EXECUTABLE=%GIT%")
9. if not defined VENV_DIR (set "VENV_DIR=%~dp0%venv")* 1* 2* 3
首先,webui.bat在7-9行設置了PYTHON、GIT、VENV_DIR 三個環境變量,其中VENV_DIR
在當前目錄中新建venv文件夾;其次,在16行測試調用Python程序;然后在第22行測試pip命令可用性。
16. %PYTHON% -c "" >tmp/stdout.txt 2>tmp/stderr.txt
17. if %ERRORLEVEL% == 0 goto :check_pip
18. echo Couldn't launch python
19. goto :show_stdout_stderr21. :check_pip
22. %PYTHON% -mpip --help >tmp/stdout.txt 2>tmp/stderr.txt
23. if %ERRORLEVEL% == 0 goto :start_venv* 1* 2* 3* 4* 5* 6* 7* 8
接下來的37-40行是創建虛擬環境的關鍵,37行獲得當前系統的缺省Python路徑,39行利用 -m
venv參數,運行此命令將創建目標目錄venv,并使用home鍵將pyvenv.cfg文件放置在其中,該文件指向運行該命令的 Python
安裝(目標目錄的通用名稱為.venv)。
37. for /f "delims=" %%i in ('CALL %PYTHON% -c "import sys; print(sys.executable)"') do set PYTHON_FULLNAME="%%i"
38. echo Creating venv in directory %VENV_DIR% using python %PYTHON_FULLNAME%
39. %PYTHON_FULLNAME% -m venv "%VENV_DIR%" >tmp/stdout.txt 2>tmp/stderr.txt
40. if %ERRORLEVEL% == 0 goto :activate_venv* 1* 2* 3* 4
基于venv的虛擬環境創建完成后,先激活該虛擬環境,再調用launch.py。至此,批處理文件的任務基本完成,并將控制權交給launch.py腳本。
44. :activate_venv
45. set PYTHON="%VENV_DIR%\Scripts\Python.exe"
46. echo venv %PYTHON%57. :launch
58. %PYTHON% launch.py %** 1* 2* 3* 4* 5* 6* 7
3) launch.py 腳本簡要分析
start = launch_utils.startdef main():if args.dump_sysinfo:filename = launch_utils.dump_sysinfo()print(f"Sysinfo saved as {filename}. Exiting...")exit(0)launch_utils.startup_timer.record("initial startup")with launch_utils.startup_timer.subcategory("prepare environment"):if not args.skip_prepare_environment:prepare_environment()if args.test_server:configure_for_tests()start()if __name__ == "__main__":main()* 1* 2* 3* 4* 5* 6* 7* 8* 9* 10* 11* 12* 13* 14* 15* 16* 17* 18* 19* 20* 21* 22* 23* 24* 25
可以看到,有個prepare_environment函數,顯然是它在負責環境初始化工作。
4) prepare_environment函數 分析
def prepare_environment():torch_index_url = os.environ.get('TORCH_INDEX_URL', "https://download.pytorch.org/whl/cu121")torch_command = os.environ.get('TORCH_COMMAND', f"pip install torch==2.1.2 torchvision==0.16.2 --extra-index-url {torch_index_url}")requirements_file = os.environ.get('REQS_FILE', "requirements_versions.txt")xformers_package = os.environ.get('XFORMERS_PACKAGE', 'xformers==0.0.23.post1')clip_package = os.environ.get('CLIP_PACKAGE', "https://github.com/openai/CLIP/archive/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1.zip")openclip_package = os.environ.get('OPENCLIP_PACKAGE', "https://github.com/mlfoundations/open_clip/archive/bb6e834e9c70d9c27d0dc3ecedeebeaeb1ffad6b.zip")assets_repo = os.environ.get('ASSETS_REPO', "https://github.com/AUTOMATIC1111/stable-diffusion-webui-assets.git")stable_diffusion_repo = os.environ.get('STABLE_DIFFUSION_REPO', "https://github.com/Stability-AI/stablediffusion.git")stable_diffusion_xl_repo = os.environ.get('STABLE_DIFFUSION_XL_REPO', "https://github.com/Stability-AI/generative-models.git")k_diffusion_repo = os.environ.get('K_DIFFUSION_REPO', 'https://github.com/crowsonkb/k-diffusion.git')blip_repo = os.environ.get('BLIP_REPO', 'https://github.com/salesforce/BLIP.git')# 安裝Pytorchif args.reinstall_torch or not is_installed("torch") or not is_installed("torchvision"):run(f'"{python}" -m {torch_command}', "Installing torch and torchvision", "Couldn't install torch", live=True)# 分別利用pip安裝clip、open_clip、xformers、ngrokif not is_installed("clip"):run_pip(f"install {clip_package}", "clip")if not is_installed("open_clip"):run_pip(f"install {openclip_package}", "open_clip")if (not is_installed("xformers") or args.reinstall_xformers) and args.xformers:run_pip(f"install -U -I --no-deps {xformers_package}", "xformers")if not is_installed("ngrok") and args.ngrok:run_pip("install ngrok", "ngrok")os.makedirs(os.path.join(script_path, dir_repos), exist_ok=True)# 分別利用git安裝assets、Stable Diffusion、Stable Diffusion XL、K-diffusion、BLIPgit_clone(assets_repo, repo_dir('stable-diffusion-webui-assets'), "assets", assets_commit_hash)git_clone(stable_diffusion_repo, repo_dir('stable-diffusion-stability-ai'), "Stable Diffusion", stable_diffusion_commit_hash)git_clone(stable_diffusion_xl_repo, repo_dir('generative-models'), "Stable Diffusion XL", stable_diffusion_xl_commit_hash)git_clone(k_diffusion_repo, repo_dir('k-diffusion'), "K-diffusion", k_diffusion_commit_hash)git_clone(blip_repo, repo_dir('BLIP'), "BLIP", blip_commit_hash)startup_timer.record("clone repositores")# 利用pip安裝requirements.txt文件指定的依賴項if not requirements_met(requirements_file):run_pip(f"install -r \"{requirements_file}\"", "requirements")* 1* 2* 3* 4* 5* 6* 7* 8* 9* 10* 11* 12* 13* 14* 15* 16* 17* 18* 19* 20* 21* 22* 23* 24* 25* 26* 27* 28* 29* 30* 31* 32* 33* 34* 35* 36* 37* 38* 39* 40* 41* 42* 43* 44* 45* 46* 47
prepare_environment函數(上述代碼是簡化后的核心代碼),基本上就是利用pip和git下載和安裝依賴項(作者一直強調事先需要部署好git的原因就在這兒),和手動安裝過程對應了起來。
四、 秋葉整合包安裝
Stable
Diffusion秋葉整合包是中國大神秋葉(bilibili@秋葉aaaki)基于Stable Diffusion
WebUI內核開發的整合包,內置了與電腦本身系統隔離的Python環境和Git(包含了第三部分需要下載和安裝的依賴項、github依賴包、預訓練模型以及相當多的插件)。可以忽略網絡需求和Python環境的門檻,讓更多人輕松地使用Stable
Diffusion WebUI。超簡單一鍵安裝,無任何使用門檻,完全免費使用,支持Nvdia全系列顯卡,近期發布了Stable
Diffusion整合包v4.8版本(整合包v4.8)。
1) 確認配置:
系統:Windows 10及以上系統
顯卡:建議在本機安裝Nvidia獨立顯卡,并且顯存要達到6G以上,6G只能出圖,如果要做訓練建議12G以上。
2)下載文件
下載到本地,最好不要有中文目錄,最新版下載鏈接: https://pan.quark.cn/s/2c832199b09b
3)點擊“A繪世啟動器”
4)點擊“一鍵啟動”

5)進入網站
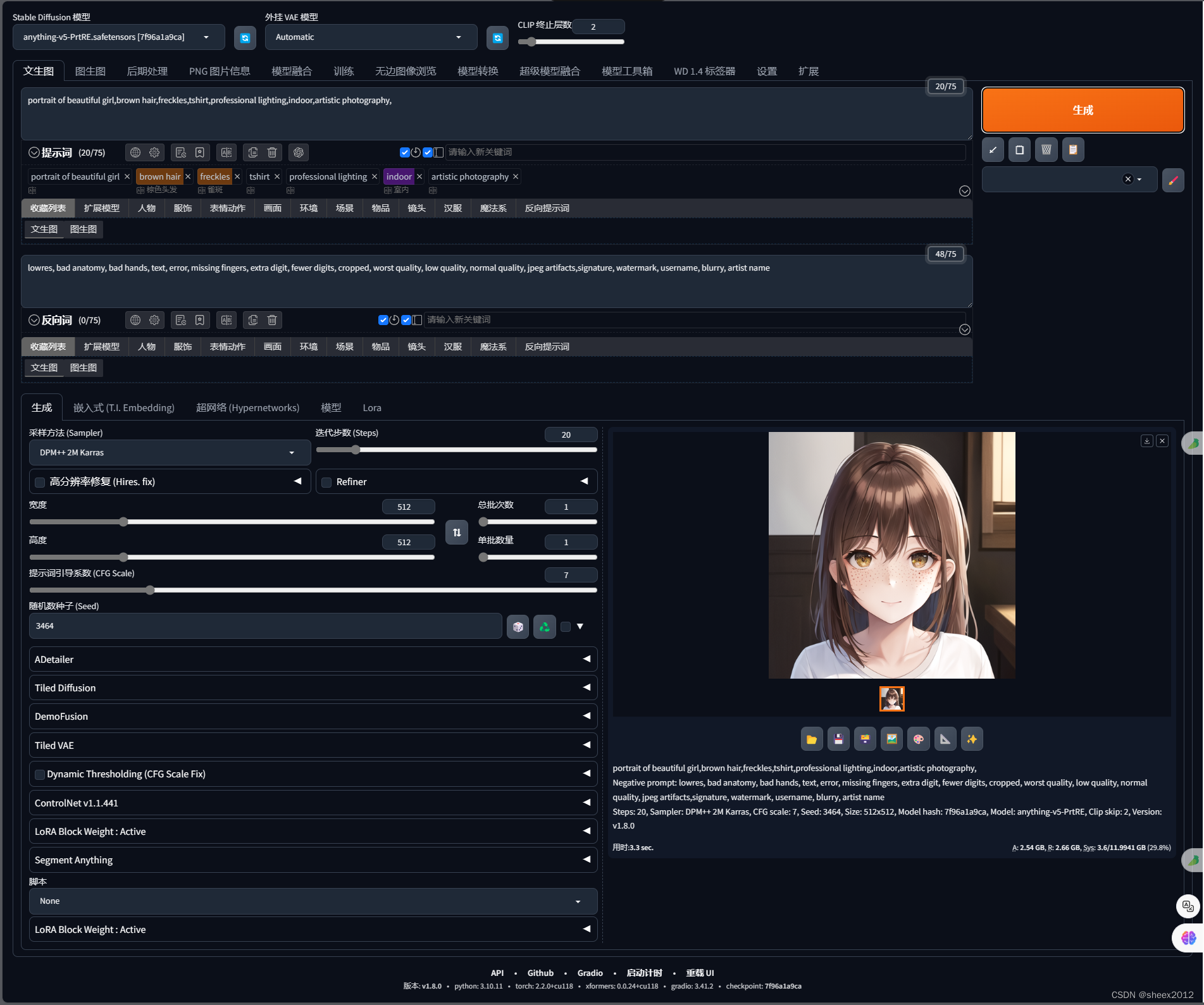
這個界面比原始的炫多了。我們看到了類似的命令行輸出:

五、推理程序安裝方式討論
1. 整合包需要做什么
Python+深度學習框架是當前基于深度學習的訓練和部署的主流模式,要在一臺新的主機上部署推理模型,一般而言必須安裝整套的軟件框架、輔助工具包和相關的底層驅動,這使得這個過程非常繁瑣。特別地,不同的(開源)軟件往往依賴不同版本的軟件包,而不同版本的軟件包之間往往存在接口不兼容的問題,給軟件運行帶來不可估量的隱患。因此,虛擬環境成為Python環境的一個重要手段,這使得不同的軟件版本可以互相隔離。* 1
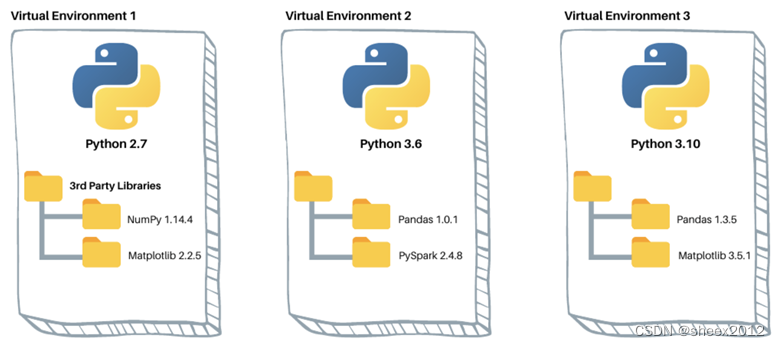
因此,要完整地安裝一套基于深度學習的應用程序,通常來講有虛擬環境創建、程序及依賴項下載安裝、預訓練模型等運行數據下載等重要步驟。對于一個從事深度學習的研究者來說,這些步驟不難,缺什么就補充安裝什么。但對于普通的愛好者來說,這個過程就太過于復雜了,因此自動安裝要把上述步驟全部在后臺一步步下載安裝和驗證,建立起一個獨立的虛擬運行環境;而整合包則更進一步,直接就是一個“綠色版”。
2. 為什么是Python3.10 ?
WebUI的作者AUTOMATIC1111在頁面中,強調了Python的版本,需采用3.10.6版本,給出的理由是擔心新版本的Python不支持Pytorch。

筆者的主機先前已經成功安裝了Python 3.11.6和Pytorch 2.1.2,覺得作者的擔心有點多余,就在主機環境中繼續安裝部署。

而且運行時,反正警告我們Python版本不兼容:

經過仔細比對,我們發現即便已經成功安裝了xformers包,系統還是提示no module ‘xformers’,讓我們頗感意外。

經分析,xformers依賴一個’triton’包:

而’triton’包沒有編譯好的適合于Windows的wheel,自然也就無法安裝。而有人針對Python
3.10編譯好好了一個版本,而這個包在Python 3.11版本下安裝時失敗的。我猜測,這可能是作者反復強調使用Python 3.10的原因。

六、小結
近年來,隨著AIGC技術的飛速發展,深度學習模型的本地化部署和應用技術也得到了充分重視,各種一鍵式安裝程序層出不窮,大大降低了模型的部署復雜性,進一步促進了AIGC的普惠應用。將虛擬環境創建、程序下載部署、數據下載部署等復雜過程一步步地串聯起來,并將常用運行環節和數據整合成一體,實現一鍵直達,方便“小白”使用,成為一種流行而有效的方法。
本文僅僅安裝部署了Stable Diffusion
WebUI的主要成分,SDXL,以及其豐富的插件尚未涉及,后續一要將各個插件系統用起來,二要深入Stable Diffusion原理,并與Stable
Diffusion使用結合,探索出更加有意思的東東。而對于具備極客精神的 AI 繪畫愛好者來說,使用 Stable Diffusion
過程中可以學到很多關于模型技術的知識,理解了 Stable Diffusion 等于就掌握了 AI
繪畫的精髓,可以更好的向下兼容其他任意一款低門檻的繪畫工具。
譯好的適合于Windows的wheel,自然也就無法安裝。而有人針對Python
3.10編譯好好了一個版本,而這個包在Python 3.11版本下安裝時失敗的。我猜測,這可能是作者反復強調使用Python 3.10的原因。
六、小結
近年來,隨著AIGC技術的飛速發展,深度學習模型的本地化部署和應用技術也得到了充分重視,各種一鍵式安裝程序層出不窮,大大降低了模型的部署復雜性,進一步促進了AIGC的普惠應用。將虛擬環境創建、程序下載部署、數據下載部署等復雜過程一步步地串聯起來,并將常用運行環節和數據整合成一體,實現一鍵直達,方便“小白”使用,成為一種流行而有效的方法。
本文僅僅安裝部署了Stable Diffusion
WebUI的主要成分,SDXL,以及其豐富的插件尚未涉及,后續一要將各個插件系統用起來,二要深入Stable Diffusion原理,并與Stable
Diffusion使用結合,探索出更加有意思的東東。而對于具備極客精神的 AI 繪畫愛好者來說,使用 Stable Diffusion
過程中可以學到很多關于模型技術的知識,理解了 Stable Diffusion 等于就掌握了 AI
繪畫的精髓,可以更好的向下兼容其他任意一款低門檻的繪畫工具。
寫在最后
感興趣的小伙伴,贈送全套AIGC學習資料,包含AI繪畫、AI人工智能等前沿科技教程和軟件工具,具體看這里。

AIGC技術的未來發展前景廣闊,隨著人工智能技術的不斷發展,AIGC技術也將不斷提高。未來,AIGC技術將在游戲和計算領域得到更廣泛的應用,使游戲和計算系統具有更高效、更智能、更靈活的特性。同時,AIGC技術也將與人工智能技術緊密結合,在更多的領域得到廣泛應用,對程序員來說影響至關重要。未來,AIGC技術將繼續得到提高,同時也將與人工智能技術緊密結合,在更多的領域得到廣泛應用。
?

一、AIGC所有方向的學習路線
AIGC所有方向的技術點做的整理,形成各個領域的知識點匯總,它的用處就在于,你可以按照下面的知識點去找對應的學習資源,保證自己學得較為全面。


二、AIGC必備工具
工具都幫大家整理好了,安裝就可直接上手!

三、最新AIGC學習筆記
當我學到一定基礎,有自己的理解能力的時候,會去閱讀一些前輩整理的書籍或者手寫的筆記資料,這些筆記詳細記載了他們對一些技術點的理解,這些理解是比較獨到,可以學到不一樣的思路。


四、AIGC視頻教程合集
觀看全面零基礎學習視頻,看視頻學習是最快捷也是最有效果的方式,跟著視頻中老師的思路,從基礎到深入,還是很容易入門的。

五、實戰案例
紙上得來終覺淺,要學會跟著視頻一起敲,要動手實操,才能將自己的所學運用到實際當中去,這時候可以搞點實戰案例來學習。

)



)
漢諾塔問題)




)

開發:從入門到實戰,構建萬物互聯新時代)





k-近鄰算法(k-Nearest Neighbors, KNN)cv::ml::KNearest類)
