引言

提升機器學習模型的訓練速度是每位機器學習工程師的共同追求。訓練速度的提升意味著實驗周期的縮短,進而加速產品的迭代過程。同時,這也表示在進行單一模型訓練時,所需的資源將會減少。簡而言之,我們追求的是效率。
熟悉 PyTorch profiler
在進行任何優化之前,首先需要了解代碼中各個部分的執行時長。Pytorch profiler 是一款功能全面的訓練性能分析工具,能夠捕捉以下信息:
-
CPU 操作的耗時 -
CUDA 核心的運行時間 -
內存使用情況的歷史記錄
這些就是你需要關注的所有內容。而且,使用起來非常簡單!記錄這些事件的方法是,將訓練過程封裝在一個 profiler 的上下文環境中,操作方式如下:
import?torch.autograd.profiler?as?profiler
with?profiler.profile(
??activities=[ProfilerActivity.CPU,?ProfilerActivity.CUDA],
??on_trace_ready=torch.profiler.tensorboard_trace_handler('./logs'),
)?as?prof:
??train(args)
之后,您可以啟動張量板并查看分析跟蹤。Profiler 提供了眾多選項,但最關鍵的是 "activities" 和 "profile_memory" 這兩個功能。盡管你可以探索其他功能,但請記住一個基本原則:啟用的選項越少,性能開銷也就越低。
例如,如果你的目的是分析 CUDA 內核的執行時間,那么最好的做法是關閉 CPU 分析和其他所有功能。這樣,分析結果會更貼近實際的執行情況。
為了讓分析結果更易于理解,建議添加一些描述代碼關鍵部分的分析上下文。如果分析功能沒有被激活,這些上下文就不會產生任何影響。
with?profiler.record_function("forward_pass"):
??result?=?model(**batch)
with?profiler.record_function("train_step"):
??step(**result)
這樣,您使用的標簽將在跡線中可見。因此,識別代碼塊會更容易。或者更精細的內部模式的前進:
with?profiler.record_function("transformer_layer:self_attention"):
??data?=?self.self_attention(**data)
...
with?profiler.record_function("transformer_layer:encoder_attention"):
??data?=?self.encoder_attention(**data,?**encoder_data)
了解 PyTorch traces
收集traces后,在張量板中打開它們。 CPU + CUDA 配置文件如下所示:
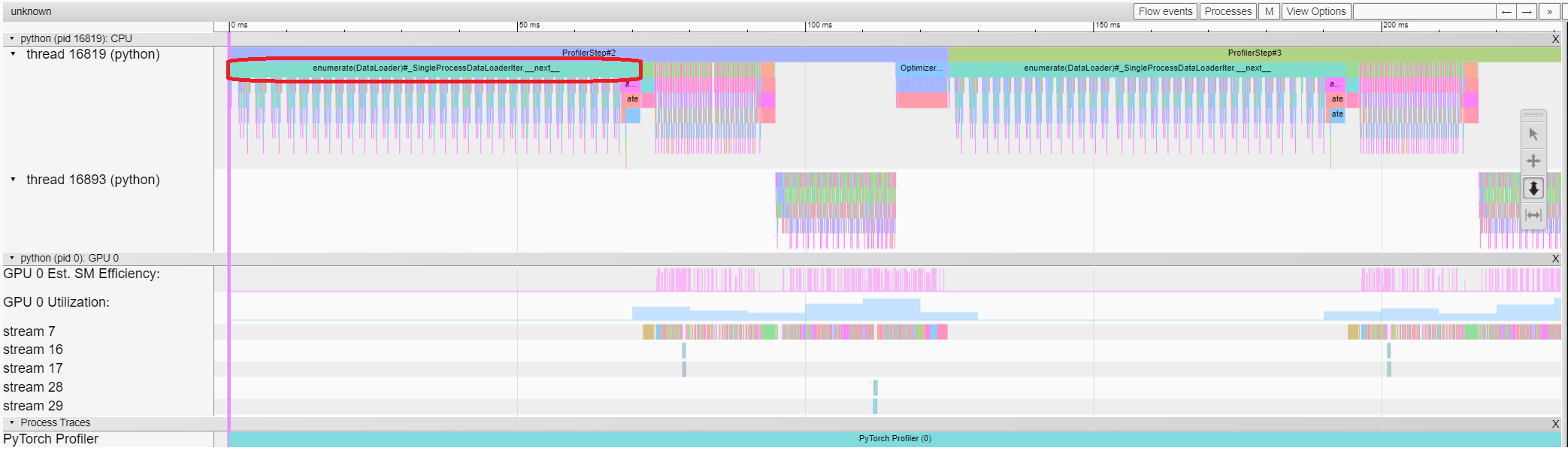
立刻識別出任何訓練過程中的關鍵環節:
-
數據加載 -
前向傳播 -
反向傳播
PyTorch 會在一個獨立線程中處理反向傳播(如上圖所示的線程 16893),這使得它很容易被識別出來。
數據加載
在數據加載方面,我們追求極致的效率,即幾乎不耗費時間。
原因在于,在數據加載的過程中,GPU 閑置不工作,這導致資源沒有得到充分利用。但是,由于數據處理和 GPU 計算是兩個獨立的部分,它們可以同時進行。
你可以通過查看分析器跟蹤中的 GPU 估計 SM 效率和 GPU 利用率來輕松識別 GPU 空閑的區域。那些活動量為零的區域就是我們需要注意的問題所在。在這些區域,GPU 并沒有參與任何工作。
解決這個問題的一個簡單方法是:
-
在后臺進程中進行數據處理,這樣不會受到全局解釋器鎖(GIL)的限制。 -
通過并行進程來同時執行數據增強和轉換操作。 如果你使用的是 PyTorch 的 DataLoader,通過設置 num_workers參數就可以輕松實現這一點。如果你使用的是 IterableDataset,情況會稍微復雜一些,因為數據可能會被重復處理。不過,通過使用get_worker_info()方法,你仍然可以解決這個問題——你需要調整迭代方式,確保每個工作進程處理的是互不重疊的不同數據行。
如果你需要更靈活的數據處理方式,你可以考慮使用 multiprocessing 模塊來自己實現多進程轉換功能。
內存分配器
使用 PyTorch 在 CUDA 設備上分配張量時,PyTorch 會利用緩存分配器來避免執行成本較高的 cudaMalloc 和 cudaFree 操作。PyTorch 的分配器會嘗試復用之前通過 cudaMalloc 分配的內存塊。如果分配器手頭有合適的內存塊,它將直接提供這塊內存,而無需再次調用 cudaMalloc,這樣 cudaMalloc 只在程序啟動時調用一次。
但是,如果你處理的是長度不一的數據,不同前向傳播過程可能需要不同大小的中間張量。這時,PyTorch 的分配器可能沒有合適的內存塊可用。在這種情況下,分配器會嘗試通過調用 cudaFree 釋放之前分配的內存塊,以便為新的內存分配騰出空間。
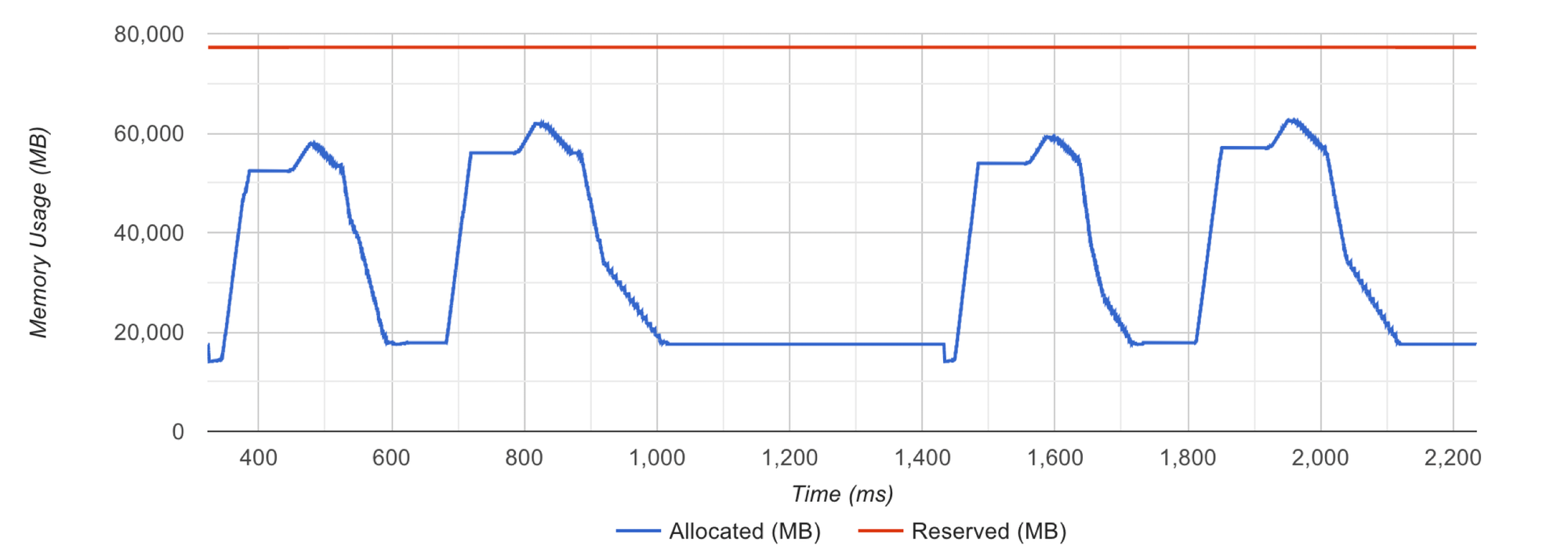
釋放內存后,分配器會重新開始構建其緩存,這將涉及到大量的 cudaMalloc 調用,這是一個資源消耗較大的操作。你可以通過觀察 tensorboard profiler viewer 的內存分析部分來識別這個問題。
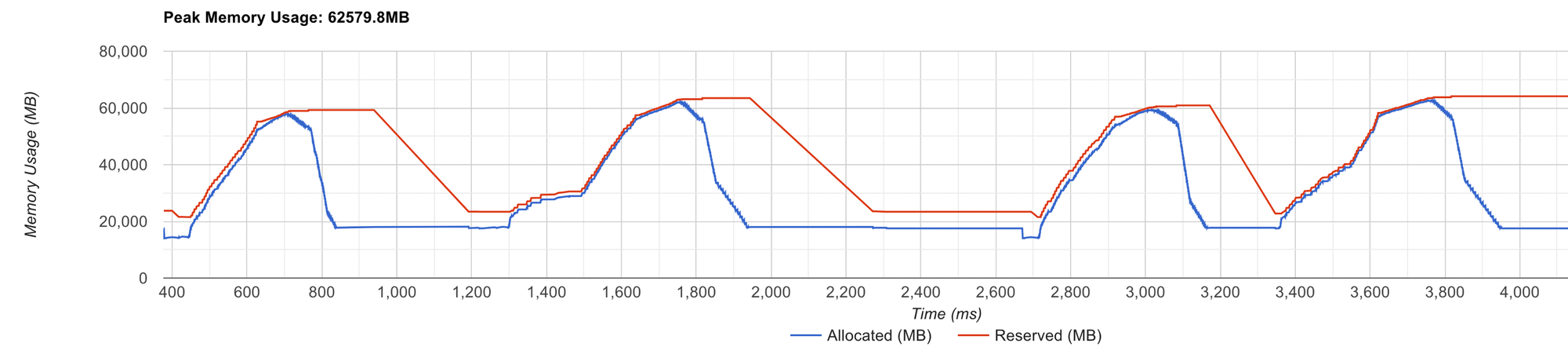
請注意,代表分配器預留內存的紅線持續波動。這表明 PyTorch 的內存分配器在處理內存請求時遇到了效率問題。
當內存分配在沒有觸發分配器緊急情況下順利進行時,你會看到紅線保持平穩。
本文由 mdnice 多平臺發布



--無監督學習(三)EM算法)





 控制DS18B20)







)

