自從徹底搞懂Self_Attention機制之后,筆者對Transformer模型的理解直接從地下一層上升到大氣層,瞬間打通任督二脈。夜夜入睡之前,那句柔情百轉的"Attention is all you need"時常在耳畔環繞,情到深處不禁拍床叫好。于是在腎上腺素的驅使下,筆者熬了一個晚上,終于實現了Transformer模型。
對于 Self_Attention 機制一知半解的讀者,強烈推薦我的上一篇文章,沒有繁復的公式,將 Self_Attention 的本質思想講給你聽。
關于 Transformer的理論講解,請參考這篇文章。
1. 模型總覽
代碼講解之前,首先放出這張經典的模型架構圖。下面的內容中,我會將每個模塊的實現思路以及筆者在Coding過程中的感悟知無不答。沒有代碼基礎的讀者不要慌張,筆者也是最近才入門的,所寫Pytorch代碼沒有花里胡哨,所用變量名詞盡量保持與論文一致,對新手十分友好。
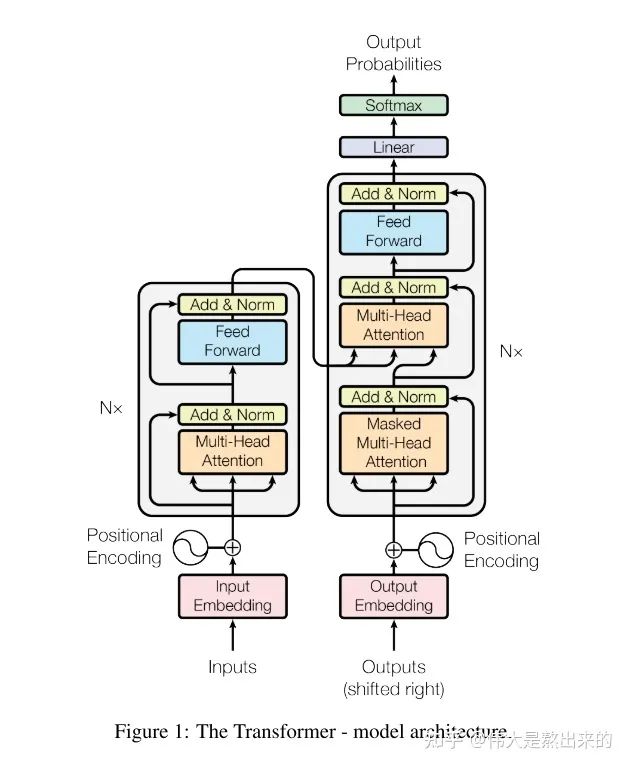
我們觀察模型的結構圖,Transformer模型包含哪些模塊?筆者將其分為以下幾個部分:
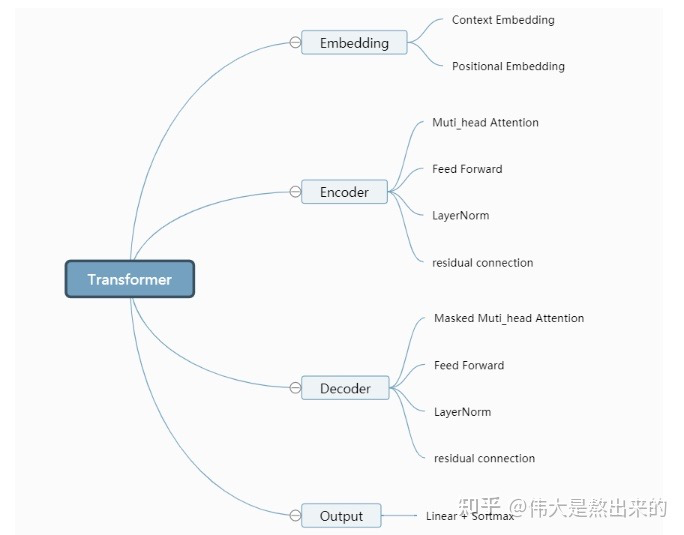
接下來我們首先逐個講解,最后將其拼接完成模型的復現。
2. config
下面是這個Demo所用的庫文件以及一些超參的信息。單獨實現一個Config類保存的原因是,方便日后復用。直接將模型部分復制,所用超參保存在新項目的Config類中即可。這里不過多贅述。

3. Embedding
Embedding部分接受原始的文本輸入(batch_size*seq_len,例:[[1,3,10,5],[3,4,5],[5,3,1,1]]),疊加一個普通的Embedding層以及一個Positional Embedding層,輸出最后結果。
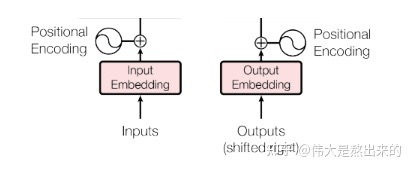
在這一層中,輸入的是一個list: [batch_size * seq_len],輸出的是一個tensor:[batch_size * seq_len * d_model]
普通的 Embedding 層想說兩點:
- 采用
torch.nn.Embedding實現embedding操作。需要關注的一點是論文中提到的Mask機制,包括padding_mask以及sequence_mask(具體請見文章開頭給出的理論講解那篇文章)。在文本輸入之前,我們需要進行padding統一長度,padding_mask的實現可以借助torch.nn.Embedding中的padding_idx參數。 - 在padding過程中,短補長截
class Embedding(nn.Module):def __init__(self,vocab_size): super(Embedding, self).__init__() # 一個普通的 embedding層,我們可以通過設置padding_idx=config.PAD 來實現論文中的 padding_mask self.embedding = nn.Embedding(vocab_size,config.d_model,padding_idx=config.PAD) def forward(self,x): # 根據每個句子的長度,進行padding,短補長截 for i in range(len(x)): if len(x[i]) < config.padding_size: x[i].extend([config.UNK] * (config.padding_size - len(x[i]))) # 注意 UNK是你詞表中用來表示oov的token索引,這里進行了簡化,直接假設為6 else: x[i] = x[i][:config.padding_size] x = self.embedding(torch.tensor(x)) # batch_size * seq_len * d_model return x
關于Positional Embedding,我們需要參考論文給出的公式。說一句題外話,在作者的實驗中對比了Positional Embedding與單獨采用一個Embedding訓練模型對位置的感知兩種方式,模型效果相差無幾。
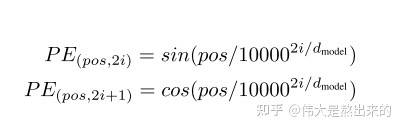

class Positional_Encoding(nn.Module):def __init__(self,d_model): super(Positional_Encoding,self).__init__() self.d_model = d_model def forward(self,seq_len,embedding_dim): positional_encoding = np.zeros((seq_len,embedding_dim)) for pos in range(positional_encoding.shape[0]): for i in range(positional_encoding.shape[1]): positional_encoding[pos][i] = math.sin(pos/(10000**(2*i/self.d_model))) if i % 2 == 0 else math.cos(pos/(10000**(2*i/self.d_model))) return torch.from_numpy(positional_encoding)
4. Encoder

Muti_head_Attention
這一部分是模型的核心內容,理論部分就不過多講解了,讀者可以參考文章開頭的第一個傳送門,文中有基礎的代碼實現。
Encoder 中的 Muti_head_Attention 不需要Mask,因此與我們上一篇文章中的實現方式相同。
為了避免模型信息泄露的問題,Decoder 中的 Muti_head_Attention 需要Mask。這一節中我們重點講解Muti_head_Attention中Mask機制的實現。
如果讀者閱讀了我們的上一篇文章,可以發現下面的代碼有一點小小的不同,主要體現在 forward 函數的參數。
forward函數的參數從 x 變為 x,y:請讀者觀察模型架構,Decoder需要接受Encoder的輸入作為公式中的V,即我們參數中的y。在普通的自注意力機制中,我們在調用中設置y=x即可。- requires_mask:是否采用Mask機制,在Decoder中設置為True
class Mutihead_Attention(nn.Module):def __init__(self,d_model,dim_k,dim_v,n_heads): super(Mutihead_Attention, self).__init__() self.dim_v = dim_v self.dim_k = dim_k self.n_heads = n_heads self.q = nn.Linear(d_model,dim_k) self.k = nn.Linear(d_model,dim_k) self.v = nn.Linear(d_model,dim_v) self.o = nn.Linear(dim_v,d_model) self.norm_fact = 1 / math.sqrt(d_model) def generate_mask(self,dim): # 此處是 sequence mask ,防止 decoder窺視后面時間步的信息。 # padding mask 在數據輸入模型之前完成。 matirx = np.ones((dim,dim)) mask = torch.Tensor(np.tril(matirx)) return mask==1 def forward(self,x,y,requires_mask=False): assert self.dim_k % self.n_heads == 0 and self.dim_v % self.n_heads == 0 # size of x : [batch_size * seq_len * batch_size] # 對 x 進行自注意力 Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k V = self.v(y).reshape(-1,y.shape[0],y.shape[1],self.dim_v // self.n_heads) # n_heads * batch_size * seq_len * dim_v # print("Attention V shape : {}".format(V.shape)) attention_score = torch.matmul(Q,K.permute(0,1,3,2)) * self.norm_fact if requires_mask: mask = self.generate_mask(x.shape[1]) attention_score.masked_fill(mask,value=float("-inf")) # 注意這里的小Trick,不需要將Q,K,V 分別MASK,只MASKSoftmax之前的結果就好了 output = torch.matmul(attention_score,V).reshape(y.shape[0],y.shape[1],-1) # print("Attention output shape : {}".format(output.shape)) output = self.o(output) return output
Feed Forward

這一部分實現很簡單,兩個Linear中連接Relu即可,目的是為模型增添非線性信息,提高模型的擬合能力。

Add & LayerNorm
這一節我們實現論文中提出的殘差連接以及LayerNorm。
論文中關于這部分給出公式:

代碼中的dropout,在論文中也有所解釋,對輸入layer_norm的tensor進行dropout,對模型的性能影響還是蠻大的。
代碼中的參數sub_layer ,可以是Feed Forward,也可以是Muti_head_Attention。

OK,Encoder中所有模塊我們已經講解完畢,接下來我們將其拼接作為Encoder
class Encoder(nn.Module):def __init__(self): super(Encoder, self).__init__() self.positional_encoding = Positional_Encoding(config.d_model) self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads) self.feed_forward = Feed_Forward(config.d_model) self.add_norm = Add_Norm() def forward(self,x): # batch_size * seq_len 并且 x 的類型不是tensor,是普通list x += self.positional_encoding(x.shape[1],config.d_model) # print("After positional_encoding: {}".format(x.size())) output = self.add_norm(x,self.muti_atten,y=x) output = self.add_norm(output,self.feed_forward) return output
5.Decoder
在 Encoder 部分的講解中,我們已經實現了大部分Decoder的模塊。Decoder的Muti_head_Attention引入了Mask機制,Decoder與Encoder 中模塊的拼接方式不同。以上兩點讀者在Coding的時候需要注意。
class Decoder(nn.Module):def __init__(self): super(Decoder, self).__init__() self.positional_encoding = Positional_Encoding(config.d_model) self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads) self.feed_forward = Feed_Forward(config.d_model) self.add_norm = Add_Norm() def forward(self,x,encoder_output): # batch_size * seq_len 并且 x 的類型不是tensor,是普通list # print(x.size()) x += self.positional_encoding(x.shape[1],config.d_model) # print(x.size()) # 第一個 sub_layer output = self.add_norm(x,self.muti_atten,y=x,requires_mask=True) # 第二個 sub_layer output = self.add_norm(output,self.muti_atten,y=encoder_output,requires_mask=True) # 第三個 sub_layer output = self.add_norm(output,self.feed_forward) return output
6.Transformer
至此,所有內容已經鋪墊完畢,我們開始組裝Transformer模型。論文中提到,Transformer中堆疊了6個我們上文中實現的Encoder 和 Decoder。這里筆者采用nn.Sequential實現了堆疊操作。
Output模塊的 Linear 和 Softmax 的實現也包含在下面的代碼中

完整代碼
# @Author:Yifx
# @Contact: Xxuyifan1999@163.com
# @Time:2021/9/16 20:02
# @Software: PyCharm"""
文件說明:
"""import torch
import torch.nn as nn
import numpy as np
import mathclass Config(object):def __init__(self): self.vocab_size = 6 self.d_model = 20 self.n_heads = 2 assert self.d_model % self.n_heads == 0 dim_k = self.d_model // self.n_heads dim_v = self.d_model // self.n_heads self.padding_size = 30 self.UNK = 5 self.PAD = 4 self.N = 6 self.p = 0.1
config = Config()class Embedding(nn.Module):def __init__(self,vocab_size): super(Embedding, self).__init__() # 一個普通的 embedding層,我們可以通過設置padding_idx=config.PAD 來實現論文中的 padding_mask self.embedding = nn.Embedding(vocab_size,config.d_model,padding_idx=config.PAD) def forward(self,x):# 根據每個句子的長度,進行padding,短補長截 for i in range(len(x)): if len(x[i]) < config.padding_size: x[i].extend([config.UNK] * (config.padding_size - len(x[i]))) # 注意 UNK是你詞表中用來表示oov的token索引,這里進行了簡化,直接假設為6 else: x[i] = x[i][:config.padding_size] x = self.embedding(torch.tensor(x)) # batch_size * seq_len * d_model return xclass Positional_Encoding(nn.Module):def __init__(self,d_model): super(Positional_Encoding,self).__init__() self.d_model = d_model def forward(self,seq_len,embedding_dim): positional_encoding = np.zeros((seq_len,embedding_dim)) for pos in range(positional_encoding.shape[0]): for i in range(positional_encoding.shape[1]): positional_encoding[pos][i] = math.sin(pos/(10000**(2*i/self.d_model))) if i % 2 == 0 else math.cos(pos/(10000**(2*i/self.d_model))) return torch.from_numpy(positional_encoding)class Mutihead_Attention(nn.Module):def __init__(self,d_model,dim_k,dim_v,n_heads): super(Mutihead_Attention, self).__init__() self.dim_v = dim_v self.dim_k = dim_k self.n_heads = n_heads self.q = nn.Linear(d_model,dim_k) self.k = nn.Linear(d_model,dim_k) self.v = nn.Linear(d_model,dim_v) self.o = nn.Linear(dim_v,d_model) self.norm_fact = 1 / math.sqrt(d_model) def generate_mask(self,dim): # 此處是 sequence mask ,防止 decoder窺視后面時間步的信息。 # padding mask 在數據輸入模型之前完成。 matirx = np.ones((dim,dim)) mask = torch.Tensor(np.tril(matirx)) return mask==1 def forward(self,x,y,requires_mask=False): assert self.dim_k % self.n_heads == 0 and self.dim_v % self.n_heads == 0 # size of x : [batch_size * seq_len * batch_size] # 對 x 進行自注意力 Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k V = self.v(y).reshape(-1,y.shape[0],y.shape[1],self.dim_v // self.n_heads) # n_heads * batch_size * seq_len * dim_v # print("Attention V shape : {}".format(V.shape)) attention_score = torch.matmul(Q,K.permute(0,1,3,2)) * self.norm_fact if requires_mask: mask = self.generate_mask(x.shape[1]) # masked_fill 函數中,對Mask位置為True的部分進行Mask attention_score.masked_fill(mask,value=float("-inf")) # 注意這里的小Trick,不需要將Q,K,V 分別MASK,只MASKSoftmax之前的結果就好了 output = torch.matmul(attention_score,V).reshape(y.shape[0],y.shape[1],-1) # print("Attention output shape : {}".format(output.shape)) output = self.o(output) return outputclass Feed_Forward(nn.Module):def __init__(self,input_dim,hidden_dim=2048): super(Feed_Forward, self).__init__() self.L1 = nn.Linear(input_dim,hidden_dim) self.L2 = nn.Linear(hidden_dim,input_dim) def forward(self,x): output = nn.ReLU()(self.L1(x)) output = self.L2(output) return outputclass Add_Norm(nn.Module):def __init__(self): self.dropout = nn.Dropout(config.p) super(Add_Norm, self).__init__() def forward(self,x,sub_layer,**kwargs): sub_output = sub_layer(x,**kwargs) # print("{} output : {}".format(sub_layer,sub_output.size())) x = self.dropout(x + sub_output) layer_norm = nn.LayerNorm(x.size()[1:]) out = layer_norm(x) return outclass Encoder(nn.Module):def __init__(self): super(Encoder, self).__init__() self.positional_encoding = Positional_Encoding(config.d_model) self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads) self.feed_forward = Feed_Forward(config.d_model) self.add_norm = Add_Norm() def forward(self,x): # batch_size * seq_len 并且 x 的類型不是tensor,是普通list x += self.positional_encoding(x.shape[1],config.d_model) # print("After positional_encoding: {}".format(x.size())) output = self.add_norm(x,self.muti_atten,y=x) output = self.add_norm(output,self.feed_forward) return output# 在 Decoder 中,Encoder的輸出作為Query和KEy輸出的那個東西。即 Decoder的Input作為V。此時是可行的
# 因為在輸入過程中,我們有一個padding操作,將Inputs和Outputs的seq_len這個維度都拉成一樣的了
# 我們知道,QK那個過程得到的結果是 batch_size * seq_len * seq_len .既然 seq_len 一樣,那么我們可以這樣操作
# 這樣操作的意義是,Outputs 中的 token 分別對于 Inputs 中的每個token作注意力class Decoder(nn.Module):def __init__(self): super(Decoder, self).__init__() self.positional_encoding = Positional_Encoding(config.d_model) self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads) self.feed_forward = Feed_Forward(config.d_model) self.add_norm = Add_Norm() def forward(self,x,encoder_output): # batch_size * seq_len 并且 x 的類型不是tensor,是普通list # print(x.size()) x += self.positional_encoding(x.shape[1],config.d_model) # print(x.size()) # 第一個 sub_layer output = self.add_norm(x,self.muti_atten,y=x,requires_mask=True) # 第二個 sub_layer output = self.add_norm(x,self.muti_atten,y=encoder_output,requires_mask=True) # 第三個 sub_layer output = self.add_norm(output,self.feed_forward) return outputclass Transformer_layer(nn.Module):def __init__(self): super(Transformer_layer, self).__init__() self.encoder = Encoder() self.decoder = Decoder() def forward(self,x): x_input,x_output = x encoder_output = self.encoder(x_input) decoder_output = self.decoder(x_output,encoder_output) return (encoder_output,decoder_output)class Transformer(nn.Module):def __init__(self,N,vocab_size,output_dim): super(Transformer, self).__init__() self.embedding_input = Embedding(vocab_size=vocab_size) self.embedding_output = Embedding(vocab_size=vocab_size) self.output_dim = output_dim self.linear = nn.Linear(config.d_model,output_dim) self.softmax = nn.Softmax(dim=-1) self.model = nn.Sequential(*[Transformer_layer() for _ in range(N)]) def forward(self,x): x_input , x_output = x x_input = self.embedding_input(x_input) x_output = self.embedding_output(x_output) _ , output = self.model((x_input,x_output)) output = self.linear(output) output = self.softmax(output) return output
覺得本文內容不錯的讀者記得點贊呀,感謝~~
如何學習大模型 AI ?
由于新崗位的生產效率,要優于被取代崗位的生產效率,所以實際上整個社會的生產效率是提升的。
但是具體到個人,只能說是:
“最先掌握AI的人,將會比較晚掌握AI的人有競爭優勢”。
這句話,放在計算機、互聯網、移動互聯網的開局時期,都是一樣的道理。
我在一線互聯網企業工作十余年里,指導過不少同行后輩。幫助很多人得到了學習和成長。
我意識到有很多經驗和知識值得分享給大家,也可以通過我們的能力和經驗解答大家在人工智能學習中的很多困惑,所以在工作繁忙的情況下還是堅持各種整理和分享。但苦于知識傳播途徑有限,很多互聯網行業朋友無法獲得正確的資料得到學習提升,故此將并將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。

第一階段(10天):初階應用
該階段讓大家對大模型 AI有一個最前沿的認識,對大模型 AI 的理解超過 95% 的人,可以在相關討論時發表高級、不跟風、又接地氣的見解,別人只會和 AI 聊天,而你能調教 AI,并能用代碼將大模型和業務銜接。
- 大模型 AI 能干什么?
- 大模型是怎樣獲得「智能」的?
- 用好 AI 的核心心法
- 大模型應用業務架構
- 大模型應用技術架構
- 代碼示例:向 GPT-3.5 灌入新知識
- 提示工程的意義和核心思想
- Prompt 典型構成
- 指令調優方法論
- 思維鏈和思維樹
- Prompt 攻擊和防范
- …
第二階段(30天):高階應用
該階段我們正式進入大模型 AI 進階實戰學習,學會構造私有知識庫,擴展 AI 的能力。快速開發一個完整的基于 agent 對話機器人。掌握功能最強的大模型開發框架,抓住最新的技術進展,適合 Python 和 JavaScript 程序員。
- 為什么要做 RAG
- 搭建一個簡單的 ChatPDF
- 檢索的基礎概念
- 什么是向量表示(Embeddings)
- 向量數據庫與向量檢索
- 基于向量檢索的 RAG
- 搭建 RAG 系統的擴展知識
- 混合檢索與 RAG-Fusion 簡介
- 向量模型本地部署
- …
第三階段(30天):模型訓練
恭喜你,如果學到這里,你基本可以找到一份大模型 AI相關的工作,自己也能訓練 GPT 了!通過微調,訓練自己的垂直大模型,能獨立訓練開源多模態大模型,掌握更多技術方案。
到此為止,大概2個月的時間。你已經成為了一名“AI小子”。那么你還想往下探索嗎?
- 為什么要做 RAG
- 什么是模型
- 什么是模型訓練
- 求解器 & 損失函數簡介
- 小實驗2:手寫一個簡單的神經網絡并訓練它
- 什么是訓練/預訓練/微調/輕量化微調
- Transformer結構簡介
- 輕量化微調
- 實驗數據集的構建
- …
第四階段(20天):商業閉環
對全球大模型從性能、吞吐量、成本等方面有一定的認知,可以在云端和本地等多種環境下部署大模型,找到適合自己的項目/創業方向,做一名被 AI 武裝的產品經理。
- 硬件選型
- 帶你了解全球大模型
- 使用國產大模型服務
- 搭建 OpenAI 代理
- 熱身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地計算機運行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何優雅地在阿里云私有部署開源大模型
- 部署一套開源 LLM 項目
- 內容安全
- 互聯網信息服務算法備案
- …
學習是一個過程,只要學習就會有挑戰。天道酬勤,你越努力,就會成為越優秀的自己。
如果你能在15天內完成所有的任務,那你堪稱天才。然而,如果你能完成 60-70% 的內容,你就已經開始具備成為一名大模型 AI 的正確特征了。
這份完整版的大模型 AI 學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】


)
C/C++版本)
函數解析)


的全同態加密方案)












