摘要:本文整理自Apache Yarn && Flink Contributor,阿里巴巴智能引擎事業部技術專家王偉駿(鴻歷)老師在 5月16日 Streaming Lakehouse Meetup · Online 上的分享。內容主要分為以下三個部分:
一、 阿里智能引擎 AI 業務背景介紹
二、 引入 Paimon 原因、場景及預期收益
三、 遇到的問題及解法
一、阿里智能引擎 AI 業務背景介紹
首先介紹一下阿里智能引擎事業部中AI相關的業務背景。
1、 業務場景及特點
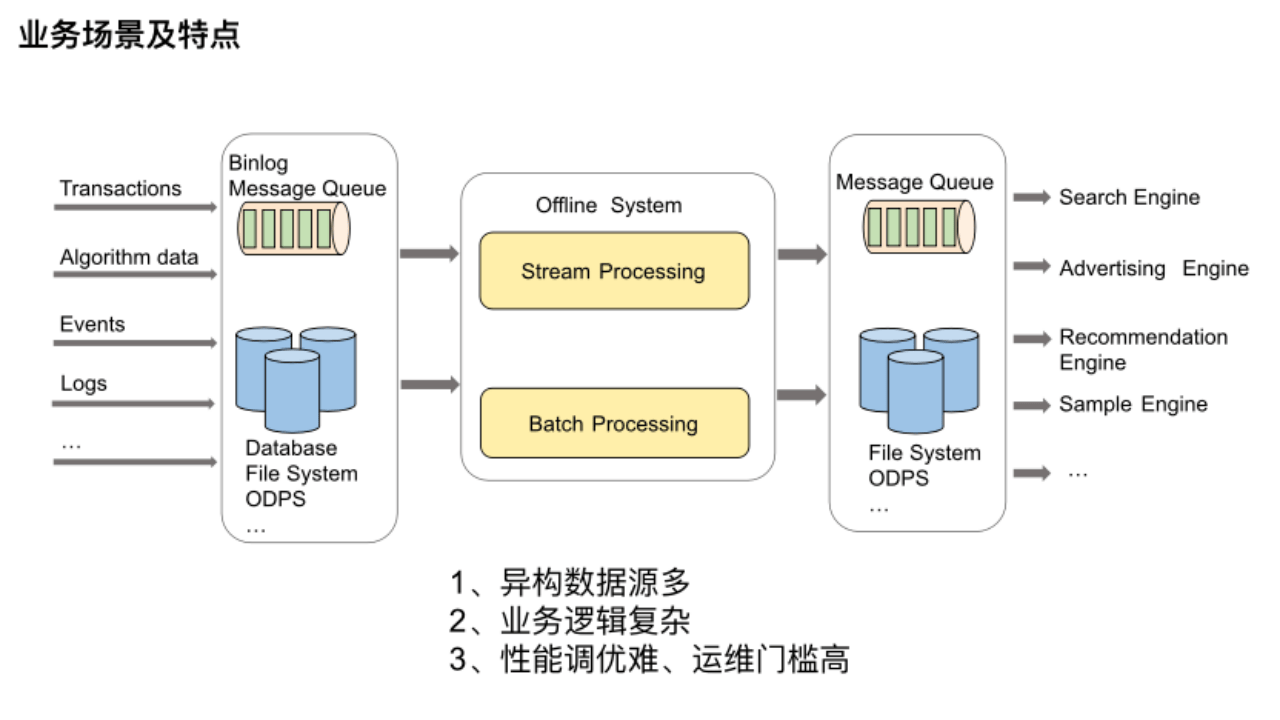 我們平臺支持多種大數據離線處理鏈路,比如說搜推廣鏈路、算法工程鏈路、模型推理鏈路等,這些數據處理鏈路的業務場景基本可以涵蓋為上述圖示流程。
我們平臺支持多種大數據離線處理鏈路,比如說搜推廣鏈路、算法工程鏈路、模型推理鏈路等,這些數據處理鏈路的業務場景基本可以涵蓋為上述圖示流程。
最左邊是各種搜推廣等引擎依賴的原始數據,主要來源于業務的事務數據、算法數據以及用戶的點擊事件日志等等,它們分布在不同的存儲系統中。最右邊的引擎想利用這些數據就需要一個離線系統,將不同維度的數據聚合到一起,以提供給不同的引擎使用。可以設想一下要開發這樣一個離線系統,需要面臨哪些痛點及難點。
(1) 異構數據源多:數據源來源于眾多異構數據源,所以我們需要對接各類存儲引擎,以此橫向擴展平臺的功能。
(2) 業務邏輯復雜:業務邏輯非常復雜,所以流批很難一體,很難做到多個批流作業之間的無縫完美銜接。
(3) 性能調優難、運維門檻高:在性能和運維方面由于涉及大數據組件非常多,需要了解很多計算引擎及存儲系統的內部實現細節,所以運維排查問題困難,作業性能調優要考慮的因素也很多。
2、 產品介紹及成果
為了降低業務離線開發和運維的門檻,減少業務接入的成本和提高業務迭代的效率,我們研發和建設了大數據離線處理平臺,提供 AI 領域端到端的 ETL 數據處理解決方案。
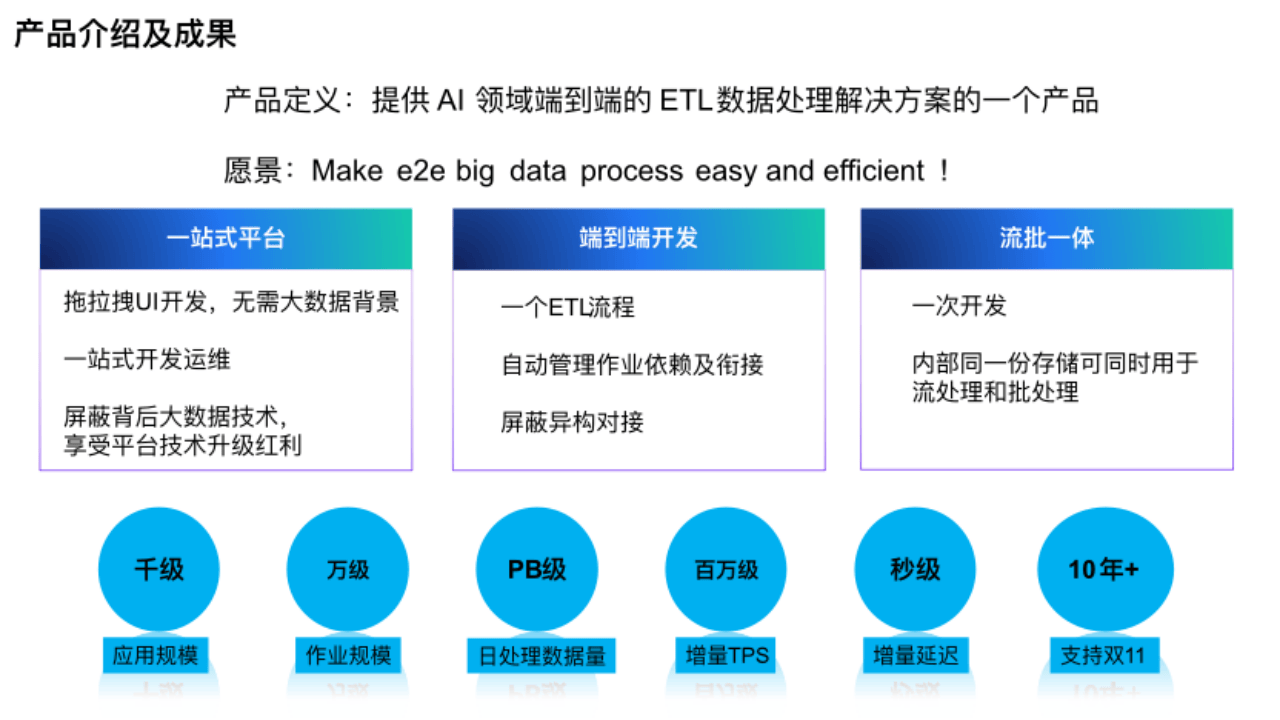
(1)一站式平臺
本平臺是從開發到運維的一站式平臺,用戶可以通過拖拉拽 UI 方式開發,沒有大數據背景的人也能使用。平臺屏蔽了背后的大數據技術,進一步降低用戶使用門檻。
(2) 端到端開發
在開發上,從數據源到引擎,平臺會把一個 ETL 流程轉換成多個流批作業,平臺管理背后所有作業依賴和存儲的對接。
(3) 流批一體
在流批一體方面用戶只需一次開發就能實現流批一體,內部同一份存儲可同時用于流處理和批處理。
目前平臺應用規模、作業規模、日數據處理量都很大,在增量 Tps 達到百萬級的情況下能給用戶帶來秒級延時的體驗,已經連續支持雙 11 多年。
3、 產品技術架構

(1) 依賴組件
①計算
從下往上看,首先在平臺的 Runtime 層的計算維度,依賴支持 K8S 協議的統一資源池來提供計算資源。目前主要是通過企業版 Flink 即 VVR 以流批一體的方式,將各種數據源的數據經過大量復雜計算,最終寫入不同的存儲介質中供下游使用。另外一種業界大家熟知的計算引擎 Spark目前正在接入中,平臺很快就會呈現出支持多引擎的狀況。由于Spark 的接入,所以我們正在借鑒 Seatunnel 來重構 Connector 模塊,統一計算引擎 API 接口,以此在 Connector 層面實現支持多引擎的目的。同樣,由于多引擎的接入,我們重新設計 UDxF 組件,用戶只需寫一套 UDxF 的代碼提供給平臺,我們自動將其 Translator 成不同計算引擎的 UDxF。通過 VVP 的 JAVA SDK 來統一提交作業,按需在頁面上對作業進行更進一步的運維及開發。
②存儲
依賴阿里內部自研的 Pangu 和 Swift,作為底層分布式文件系統和消息隊列,用 Hologres 來滿足業務對于高性能的數據掃描和點查等需求。數據湖格式選用的是Paimon,湖表存儲優化服務是我們正在調研的,主要是對大量 Paimon 表做 dedicated-compaction 以及對多種存儲引擎底層 SST 文件的存儲優化,進而提升大表讀寫吞吐性能。上面是統一的 Catalog 元數據服務,它集成了各種表的資源創建,資源回收、Meta、版本、訂閱及血緣管理的功能。
③調度
平臺的依賴 Airflow實現多作業的調度編排,流批作業的銜接等,依賴 Hippo申請集群資源。
(2) 核心功能
通過這些依賴的底層組件我們平臺向上提供了很多大數據處理相關功能,比如數據集成,支持用戶自定義插件的流批一體計算,樣本處理,OLAP 等核心能力。
(3) 產品端
通過核心能力,在產品端就能結合各種業務場景來提供多種端到端的大數據處理解決方案。比如在收推場景下的收推平臺、樣本場景下的樣本處理平臺等。
(4) 支持業務
有了解決方案,平臺目前支持的圖中最上方所示阿里內部幾乎所有業務線的各種數據處理的需求。
綜上所述,平臺的核心能力來源于底層依賴的各種計算、存儲、調度的組件,它們是給平臺上層業務賦能的動力源泉。為了更好的支持各種業務源源不斷的復雜新需求,我們必須持續更新迭代底層的計算存儲組件,所以我們今年開始引入了 Paimon。
二、引入 Paimon 原因、場景及預期收益
以上是一些關于平臺背景的相關內容,下面重點說下平臺引入 Paimon 的原因、場景及預期收益。

1、 引入Paimon 原因
引入 Paimon的原因主要是四個方面。
(1) **公司戰略 **
公司要建立集團數據湖生態,湖倉協同,促進集團數據資產集中存儲,高效使用。
(2) **成本 **
存儲成本居高不下,很多實效性要求不高的場景,其實沒必要用成本較高的分布式存儲服務來支持。
(3) **解決 Lambda 架構缺點 **
Lambda架構開發維護復雜存在資源浪費情況,我們這邊也有類似的現象,所以考慮引入Paimon。
(4)優化
我們調用發現數據湖在某些場景下可以解決業務性能瓶頸。
基于以上幾個原因,我們深度對比了業界幾大數據湖產品(Paimon、Iceberg、Hudi)后,結合業務需求及社區發展情況等因素綜合考慮,最終選擇了 Apache Paimon 作為我們數據湖的湖格式。
2、探索場景及預期收益一、樣本生成鏈路
以下是樣本生成鏈路的大致處理邏輯,也是要介紹的第一個場景——樣本生成鏈路。

這條鏈路的特點主要有:第一,時效性要求不高,5 分鐘左右;第二、數據量大,所以目前依賴的存儲成本很高;第三、計算邏輯相當復雜。
簡述:在樣本生成過程中,會分別消費用戶點擊日志和一些Odps表數據,進行寬表加工,及大量 JOIN 操作和復雜的 ETL 等計算邏輯,生成樣本特征及label。最終會將生成的樣本數據進行持久化,寫入到不同的目標系統中。當然實際處理邏輯遠比這里要復雜的多。
這條數據處理鏈路中,流批是完全分開的兩條鏈路,計算存儲均沒做到統一,開發維護成本偏高。更重要的是,這條時效性要求不高的鏈路的存儲成本卻一直居高不下,所以我們目前正在探索、嘗試將 Paimon 引入進來。

以上便是我們目前正在探索和嘗試的新架構。全鏈路不再有分布式 KV 存儲服務,而是用 Paimon 作為數據鏡像及 DimJoin 維表等來實現樣本處理過程中的數據存儲需求。
預期達到的收益:
(1) 做到真正的流批一體,流批計算引擎統一為 Flink,存儲統一為 Paimon,同一份存儲,既可以被用于流處理,也可以被用于批處理。明顯可以降低業務開發維護的成本。
(2) 可根據業務邏輯來決定是否共享部分存儲資源,如圖中間的paimon 表。
(3) 在某些情況下用 DimJoin 替換以前的 SortMergeJoin,提升性能。
(4) 由于沒有了分布式 KV 存儲服務,可以減少很多存儲服務的成本。
3、 探索場景及預期收益二、批樣本存儲鏈路
這是第二個場景——批樣本存儲鏈路,該鏈路是將樣本平臺產出的批樣本發往消息隊列給索引平臺 Build 成在線檢索引擎所需的 ORC 格式文件,以共用戶分析使用。

該鏈路有明顯的幾個缺點:
第一,索引平臺讀取消息隊列中的樣本數據 Build 索引的過程會有長尾,導致產出延遲。
第二,依賴組件多,整體鏈路太繞,導致運維成本高,可控性差。
所以我們探索是否能讓在線檢索引擎支持識別 Paimon 這種湖格式,樣本平臺就可以直接將樣本數據寫入 Paimon 中。如果實現,那依賴組件減少,產出延遲也就可控,運維及費用成本均可降低。
4、 探索場景及預期收益三、圖片特征計算鏈路
這是探索的第三個場景——圖片特征計算鏈路。在圖片特征計算場景下,該鏈路的時效性要求不高,主要是計算圖片的特征。但是由于圖片數量多,達到百億級,所以通過 TFS / OSS 拉取圖片經常導致服務端壓力過高,甚至雪崩、限流也經常發生,所以我們引入了 KV系統作為 Cache。該鏈路是利用Flink作業動態分析圖片的計算特征,當 Flink Batch Job 查詢該服務發現圖片不存在時,則會通過 HTTP 向 TFS 也就是圖片中心服務請求圖片,然后發往消息隊列中來更新 Cache。
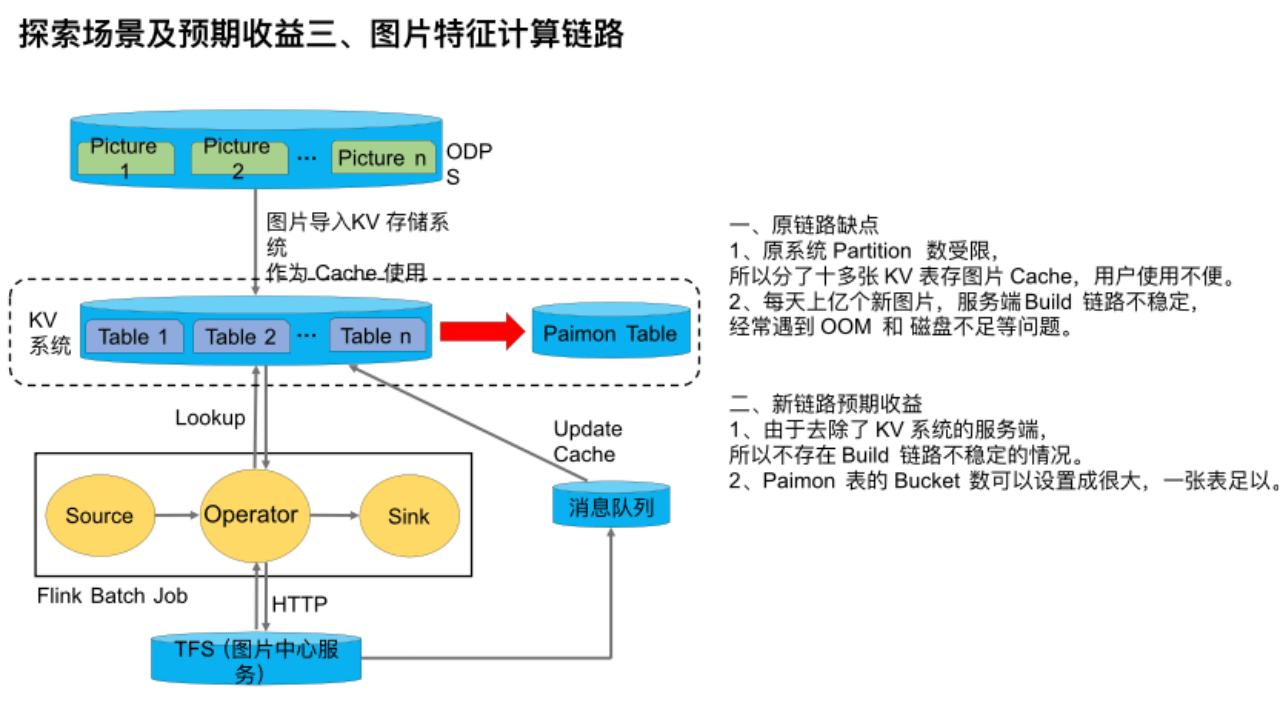
該鏈路有幾個缺點:
第一,原系統 Partition 數受限,所以我們分了十多張 KV 表存圖片 Cache,用戶使用不便。
第二,每天上億個新圖片,服務端 Build 鏈路不穩定,經常遇到 OOM 和 磁盤不足等問題。
由于 Paimon 支持作為維表被點查的,所以我們目前正在嘗試將 Paimon 引入進來當 Cache,替換原 KV 系統。
如果能實現,則預期收益是:
第一,由于去除了 KV 系統的服務端,所以不存在 Build 鏈路不穩定的情況,成本也能相應下降。
第二,Paimon 表的 Bucket 數可以設置成很大,一張表足以,方便用戶使用。
5、 探索場景及預期收益四、搜索離線鏈路
該鏈路是搜索平臺較典型離線處理鏈路。
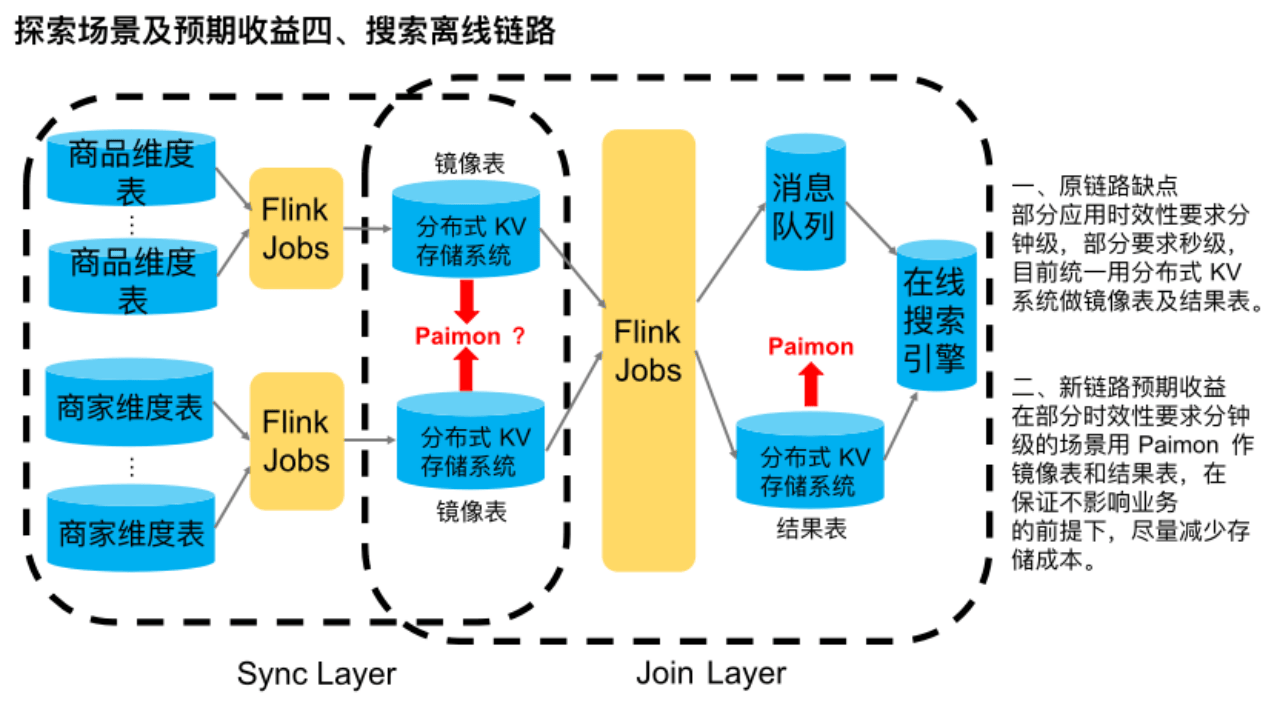
簡單介紹下,首先在同步層,多個商品維度源表與多個商家維度源表分別通過 Flink 流批作業全增量同步到分布式 KV 存儲系統中,作鏡像表使用。在 Join 層,通過一些 Flink 流批作業將各維度的鏡像表數據合并在一起做打寬處理,最終得到淘寶一件商品的完整數據信息。然后全增量分別寫到分布式 KV 存儲系統和消息隊列中,供下游的在線搜索引擎消費建索引等。該鏈路主要是用于時效性要求很高的場景,業務要求在源頭觸發增量以后,能在下游搜索引擎立馬查到最新的商品信息。
這條鏈路目前的主要缺點是,所有應用不管時效性是分鐘級還是秒級,都統一用分布式 KV 系統做鏡像表及結果表,存儲成本偏高。
我們調研到,由于 Paimon 支持流讀流寫、批讀批寫、以及作為維表被點查,所以我們目前正在探索是否能用 Paimon 來替換該鏈路中的分布式 KV 存儲系統,來滿足一些時效性要求在分鐘級別以上的業務需求,以此來實現成本的下降。目前結果表正在落地過程中,而鏡像表則還在探索調研中,屬于未來規劃。
6、 探索場景及預期收益五、搜索全量拉庫鏈路

最后一個場景來源于剛剛那個場景的源頭。也就是用戶在做大全量時,需要去拉分庫分表的Mysql數據,目前是各應用都去拉,很明顯有幾個缺點:
第一,拉取分庫分表Mysql時,并發有上限限制,吞吐受限,而盲目加并發有拉掛庫的風險。
第二,公司有些核心庫只允許晚上拉取,這直接影響到業務迭代。
第三,每個應用都要分別去拉取 Mysql 表,無法做到共享。
我們調研引入 Paimon 來解決該場景下的性能瓶頸問題,先將 mysql 表數據全增量同步到一張 Paimon 表中,然后下游全量來拉取這張 Paimon 表,增量可以根據時效性要求高低而決定選擇是走 DRC 原鏈路,還是消費 Paimon 的 changelog。目前正在落地過程中,預期收益其實很明顯,未來并發無上限了,釋放了吞吐和加快全量速度,全天24小時均可拉取,且能做到各應用共享 Paimon 表。
三、遇到的問題及解法
最后介紹下在落地過程中遇到的問題及解法。
1、 問題一及解法、Snapshot Expire 導致批作業運行失敗

Snapshot用戶去拉取時,會存在過期的可能,且在過程中發現會有非常多的錯誤,原因很簡單,就是全用戶全量拉過期的Paimon表,文件被刪,導致作業全量失敗。
有以下三種解法:第一,將 Consume-id 從流場景擴展到批場景,但調研詳細代碼的實現后,發現consumer ID有局限性。第二,統一加大 Snapshot Expire 時間,這樣,所有應用去拉Paimon表時都不會過期,但這樣有一個缺點就如圖中左邊所示,不同APP業務的邏輯不同,導致用戶每個作業的運行時長不同,有些作業只需讀Paimon表,中間沒有任何計算邏輯,直接落到KV存儲中,有些任務可能有DimJoin、UDTF等復雜的算法邏輯,算特征、算label等等。線上的作業實踐下來,發現同一張mysql表,快則十多分鐘拉完,慢則好幾個小時。第三,各 App 分別創建 Tag,作業結束后,每個應用負責刪除自己創建的Tag。因為平臺目前支持的上千個業務,每個業務都通過air flow去調度,用戶經常自己操作air flow,直接停止調度或重新clear調度節點,這樣會導致tag殘留,平臺無法保證用戶自己手工操作而產生的一些錯誤的運維手段。
最后,和社區一起討論,最后討論的解法如下:首先 Tag 支持精細化 TTL,然后 App 不再 Scan Snapshot,而是 Scan Tag With TTL。其次,每個業務知道自己的業務邏輯,所以可以設置自己需要的 TTL。同時,該方法也可以給平臺兜底,防止漏刪 Tag 的情況發生。另外,我們對老版本 Tag 及 Snapshot 都做了兼容。具體的實現是新建Class Tag extends Snapshot,詳細的開發的代碼及邏輯,可看下面的PIP。
2、 問題二及解法、Schema Evolution

遇到的第二個問題是Schema Evolution, 這是DRC數據,即集團內解析Binlog,吐出增量的組件。我們把它寫作Paimon表時,希望用戶的源頭數據變更可以動態的讓Paimon表生效。目前這個功能我們調研到社區以及公司的做法,決定用克隆表的方式來做。
(1) 不依賴 Flink-CDC 來實現 Schema Evloution 的原因
①Flink-CDC 不支持集團 TDDL (基于 Java 語言的分布式數據庫系統,提供分表分庫等功能)
②Debezium 不支持集團用的 Mysql 版本
(2)沒采用 Paimon 官網的 RichCdcSinkBuilder API 實現 Schema Evloution 的原因:
平臺全部作業統一用 Flink SQL,暫無支持 DataStream 的計劃。
所以我們另辟蹊徑,用 Clone Table 來支持 Schema Evloution。簡述是源頭DRC的增量會同步到Paimon表。此時用戶有了Schema Evloution需求,然后調用社區的Clone Table將Paimon表1克隆到Paimon表2,克隆最后一個snapshot,這個Paimon表會執行Alter Schema操作。執行完后,再拉全量同步mysql表新加的字段,只需d字段,再回溯增量,把a、b、c、d,4個字段回溯寫入Paimon表2。以此支持用戶Schema Evloution。目前這個方法也在嘗試落地中。
3、問題三及解法、Data Migration

第三個問題是數據遷移的情況,即業務遇到 DFS 集群裁撤,需要數據從 DFS 集群 A 遷移到 DFS 集群 B。還有是由于阿里云降價,所以有云上用戶想將數據從別的云廠商的云遷移到 AliYun 上。針對這種數據遷移的場景,不可能重新把業務全量掃描。針對以上兩種情況的解法:第一,我們決定去社區開發克隆表這種數據遷移工具,提供 Clone Table 這種 Data Migration 工具。第二,支持 Catalog、Database、Table、Snapshot、Tag 等 CloneType。
4、Clone Table 實現方法
最后詳細介紹一下Clone Table 實現方法。
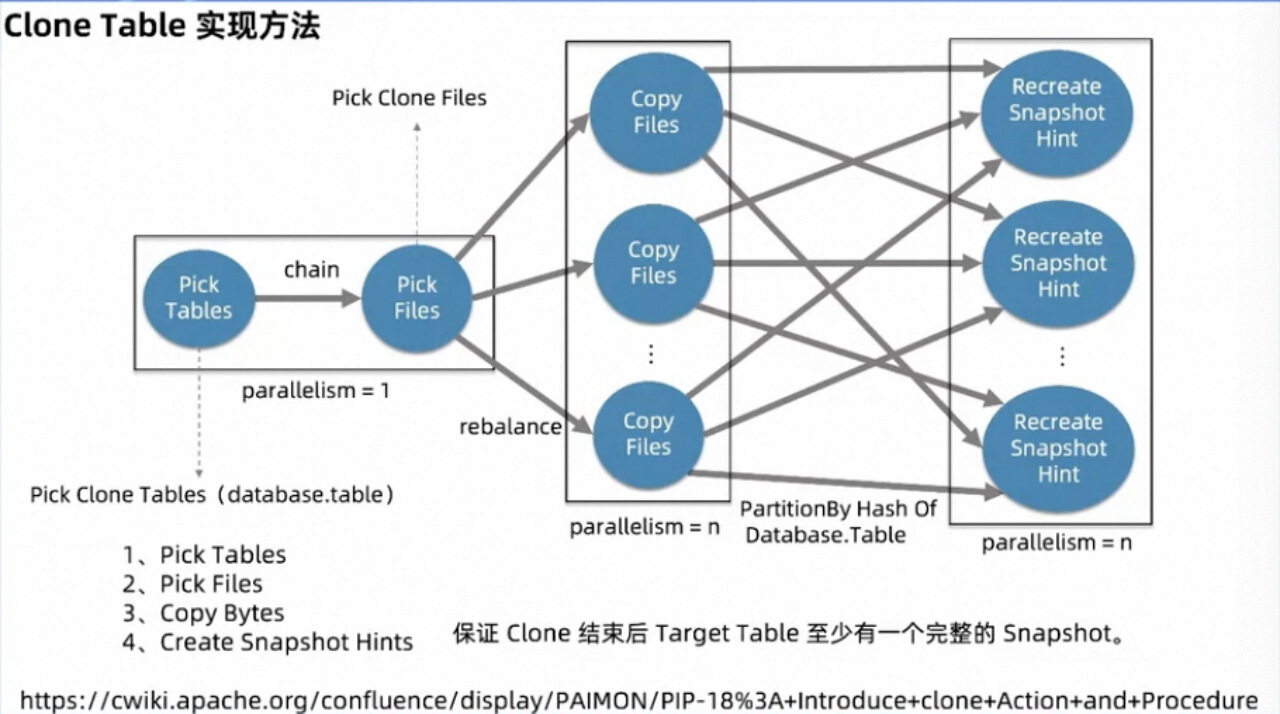
具體實現上來看,由于要 copy 的文件有可能很多,所以我們沒有在客戶端單點執行 copy File,而是起分布式任務來執行。
作業拓撲大致分為四個 Operator:
第一個 Operator,用來根據用戶傳遞的參數查詢要 copy 的表,封裝為 Record 發給第二個 Operator, 這個節點的設置主要是為了方便用戶一鍵 copy 多個表,整個 db或整個 catalog 下的所有表,而不是每 copy 一個表就要起一個作業。
第二個 Operator 在收到第一個節點的 Record 之后,會訪問該表最后一個 Snapshot 對應的 Manifest 等相關元數據文件,進而 pick 出相關數據、Schema 等文件。最后將文件信息 Rebalance 給第三個節點。
第三個 Operator,負責分布式執行文件復制,主要是通過 InputStream + OutputStream 的方式對文件進行逐字節 Copy。然后對 Database 和 Table 求 MurmurHash 來重新 Partition 發往下游最后一個節點。
最后一個 Operator,主要是負責一個表的文件復制完以后創建 snapshot 的 Hint 文件,代表著該 Snapshot 可供下游使用了。
由于用戶可能將Snapshot過去時間設置的時間很短,導致在執行Clone作業的過程中,Snapshot可能過期刪除, 導致Clone作業失敗。
因此為解決這個問題,我們會通過作業失敗的重啟后,來比較文件的size和文件名,這樣就會過濾掉已經copy的文件,以此加速作業整體執行速度。從而第二次的Clone job就能順利完成,生產實踐后發現這種方法是完全可用的。對于該功能詳細的邏輯以及代碼,可參考這個pip(https://cwiki.apache.org/confluence/display/PAIMON/PIP-18%3A+Introduce+clone+Action+and+Procedure)。


)









工具【了解安裝使用詳細】)




)
)
