如果你希望您的內容出現在 AI Overviews、ChatGPT 和 Gemini 中?以下是設置 GEO 廣告系列的方法。
任何好的 GEO 活動的第一步是創造一些東西實際上想要鏈接到或引用。
GEO 策略組件
想象一些你合理預期不會直接在 ChatGPT 或類似系統中找到的體驗:
- 例如盧浮宮的 3D 導覽或虛擬現實音樂會。
- 實時數據如價格、航班延誤、可用酒店房間等。雖然大型語言模型(LLMs)可通過 API 集成此類數據,但我認為目前存在機會捕獲部分此類流量。
- 需要 EEAT(經驗、專業知識、權威性、可信度)的主題。
LLMs 無法擁有第一手經驗。但用戶希望獲得。LLMs 有動力引用提供第一手經驗的來源。這是需要記住的一點,但還有其他什么呢?
我們需要區分兩種方法:影響基礎模型與通過錨定影響LLM答案。前者對大多數創作者而言難以實現,而后者則提供了切實可行的機會。
影響基礎模型
基礎模型是在固定數據集上訓練的,訓練完成后無法學習新信息。對于當前的模型如GPT-4而言,已經為時已晚——它們已經完成訓練。
但這對于未來至關重要:想象一臺智能冰箱使用 2025 年的 o4-mini 系統,它可能——假設性地——更傾向于可口可樂而非百事可樂。這種偏見可能在未來數年內影響購買決策!
優化RAG/地面校準
當大型語言模型(LLMs)僅憑訓練數據無法回答問題時,它們會使用檢索增強生成(RAG)技術——從當前信息中提取內容以輔助生成答案。AI Overviews 和 ChatGPT 的網頁搜索功能便是通過這種方式實現的。
作為 SEO 專業人士,我們希望實現以下三點:
- 我們的內容被選為信息來源。
- 我們的內容在這些來源中被引用最多。
- 其他被選中的來源支持我們的預期結果。
成功運用 GEO 的具體步驟
別擔心,優化內容和品牌提及以適應大型語言模型(LLMs)并不需要高深的知識。實際上,許多傳統的 SEO 方法仍然適用,其中一些可以融入你的工作流程。
步驟1:確保可爬取
聽起來簡單,但實際上這是非常重要的一步。如果你希望 LLMs 能夠爬取你的網站,就必須允許它們這樣做。OpenAI、Anthropic 等公司提供了多種 LLM 爬蟲工具。
其中部分爬蟲行為異常,可能觸發反爬蟲和 DDoS 防護機制。若您自動攔截了攻擊性機器人,請與IT團隊溝通,確保不會誤攔截您關注的 LLM 爬蟲。
若使用 CDN 服務(如:Fastly 或 Cloudflare),請確認LLM爬蟲未被默認設置攔截。
步驟 2:繼續提升傳統排名
最關鍵的 GEO 策略其實非常簡單。做好傳統 SEO。在 Google(針對 Gemini 和 AI Overviews)、Bing(針對 ChatGPT 和 Copilot)、Brave(針對 Claude)以及百度(針對 DeepSeek)上獲得良好的排名。
步驟 3:目標查詢分支
當前一代的語言模型實際上比簡單的 RAG 做了更多事情。它們會生成多個查詢。這被稱為查詢分支。
例如,當我最近詢問 ChatGPT “SEO 們討論的最新 Google 專利是什么?”時,它進行了兩次網絡搜索,分別是 “SEO 們討論的最新 Google 專利 2025 SEO 論壇” 和 “SEO 們討論的最新 Google 專利 2025”。
建議:檢查提示詞的典型查詢分支,并嘗試為這些關鍵詞進行排名。
我在 ChatGPT 中看到的典型扇出模式包括:當詢問人們在討論什么時,會附加“論壇”一詞;當詢問與某人相關的問題時,會附加“采訪”一詞。當前年份(2025)也常被添加。
注意:不同 LLM 的扇出模式存在差異,且隨時間變化。我們今天看到的模式可能在12個月后不再適用。
步驟 4:確保品牌提及的一致性
這是每個人都應做到的簡單事情——無論是作為個人還是企業。確保您在網上被一致地描述。在 X、LinkedIn、您自己的網站、Crunchbase、Github 等平臺上,始終以相同的方式描述自己。
如果你在 X 和 LinkedIn 上的個人資料中稱自己為“中小企業地理信息系統(GIS)顧問”,就不要在 Github 上改成“人工智能(AI)專家”,也不要在新聞稿中稱自己為“機器學習(ML)自由職業者”。
我曾看到有人僅通過在網上保持一致的自我描述,就在 ChatGPT 和 Google AI Overviews 上取得了積極成果。這一點也適用于公關報道——你為品牌獲得的報道越多且質量越高,LLMs 就越有可能將這些內容原封不動地反饋給用戶。
步驟 5:避免使用 JavaScript
作為 SEO,我總是要求盡可能少地使用 JavaScript。作為 GEO,我堅決要求!
大多數 LLM 爬蟲無法渲染 JavaScript。如果您的主要內容隱藏在 JavaScript 之后,您就出局了。
步驟 6:擁抱社交媒體與用戶生成內容(UGC)
毫不意外,大型語言模型(LLMs)似乎非常依賴 Reddit 和維基百科。這兩個平臺幾乎涵蓋了所有主題的用戶生成內容。得益于多層社區驅動的審核機制,大量垃圾信息和垃圾郵件已被過濾掉。
盡管兩者均可被濫用,但其內容的平均可靠性仍遠高于互聯網整體水平。兩者均會定期更新。
Reddit 還為 LLM 實驗室提供了關于人們如何在線討論話題、使用何種語言描述不同概念以及對冷門小眾話題的知識等數據。
我們可以合理假設,在 Reddit、維基百科、Quora 和 Stack Overflow 等平臺上經過審核的用戶生成內容(UGC)將對 LLM 保持相關性。
我并不主張在這些平臺上進行垃圾信息轟炸。然而,如果你能影響自己和競爭對手在這些平臺上的展示方式,你可能希望這樣做。
步驟 7:為機器可讀性和可引用性創建內容
編寫 LLMs 能理解并愿意引用的內容。目前還沒有人完美地解決這個問題,但以下方法似乎有效:
- 使用陳述性和事實性語言。例如,不要寫“我們覺得這雙鞋對顧客來說不錯”,而是寫“96% 的買家表示對這雙鞋感到滿意”。
- 添加結構化數據標記(Schema)。這一話題曾多次被討論。最近,必應(Bing)首席產品經理 Fabrice Canel 確認,結構化數據標記有助于 LLM 理解您的內容。
- 如果您希望內容被現有 AI Overviews 引用,請確保內容長度與現有內容相當。雖然不應直接復制現有 AI Overviews,但高余弦相似度有助于提升引用概率。對于技術控:是的,考慮到歸一化,當然可以使用點積代替余弦相似度。
- 如果你在內容中使用了專業術語,請進行解釋。最好用一句簡單的話說明。
- 為長段落文本、評論列表、表格、視頻及其他難以引用的內容格式添加摘要。
步驟8:優化你的內容

如果我們參考《GEO: Generative Engine Optimization》(arXiv:2311.09735)、《What Evidence Do Language Models Find Convincing? 》(arXiv:2402.11782v1)以及類似的科學研究,答案是明確的。這取決于具體情況!
要在某些 LLM 中被引用,以下幾點有助于提升效果:
- 添加獨特詞匯
- 包含利弊分析
- 收集用戶評價
- 引用專家觀點
- 包含定量數據并注明來源
- 使用通俗易懂的語言
- 以積極的語氣撰寫
- 添加低困惑度(可預測且結構清晰)的產品文本
- 包含更多列表(如本段所示!)
然而,對于其他主題與LLM的組合,這些措施可能適得其反。
在廣泛認可的最佳實踐形成之前,我能給出的唯一建議是:以用戶利益為先并進行實驗。
步驟 9:堅持事實
十多年來,算法一直從文本中提取知識,將其表示為三元組(主體、謂詞、對象)——例如,(自由女神像,位置,紐約)。與已知事實相矛盾的文本可能顯得不可信。與共識一致但添加獨特事實的文本是大型語言模型(LLMs)和知識圖譜的理想選擇。
因此,請堅持已確立的事實,并添加獨特信息。
步驟 10:投資于數字公關
這里討論的所有內容不僅適用于您自己的網站,也適用于其他網站上的內容。影響它的最佳方式是什么?數字公關!
您為品牌獲得的覆蓋范圍越廣、質量越高,大型語言模型(LLMs)就越有可能將這些內容原封不動地反饋給用戶。
我甚至見過廣告軟文被用作信息來源的案例!
要嘗試的具體 GEO 工作流程
在加入Peec AI之前,我曾是該平臺的用戶。以下是我使用該工具的方式,以及我建議我們的客戶如何使用它。
了解您的競爭對手是誰
與傳統 SEO 類似,使用一個好的地理定位工具(GEO 工具)往往能揭示出意想不到的競爭對手。定期查看自動識別出的競爭對手列表。對于那些讓你感到意外的競爭對手,查看他們在哪些提示中被提及。然后檢查導致他們被納入的來源。你在這些來源中是否得到了恰當的呈現?如果沒有,立即采取行動!
如果競爭對手是因為他們的 PeerSpot 個人資料而被提及,但你在那里沒有評論,那就請客戶留下評論。
你的競爭對手的 CEO 是否被一位 Youtuber 采訪過?嘗試也上那個節目。或者發布你自己的視頻,針對類似的關鍵詞。
你的競爭對手是否經常出現在前十名列表中,而你從未進入前五名?向創建該列表的發布者提供一個他們無法拒絕的聯盟協議。在下一次內容更新時,你幾乎可以肯定會成為新的第一名。
了解來源
在執行搜索基礎時,LLM 依賴于來源。
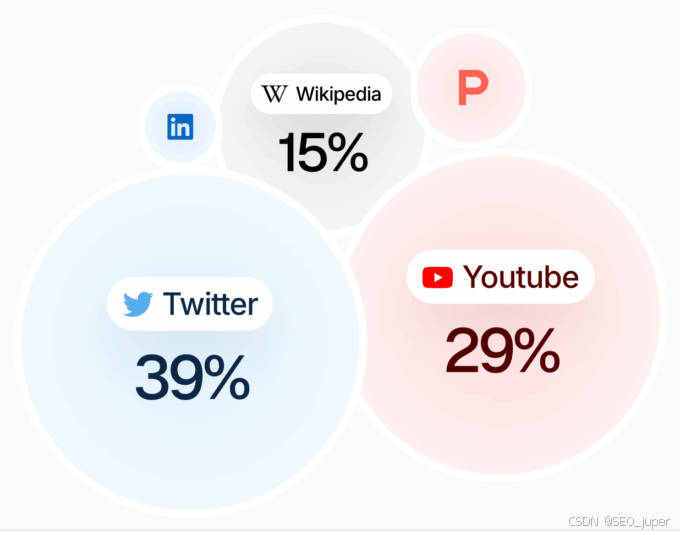
查看大量相關提示的頂級來源。暫時忽略你的網站和競爭對手。你可能會發現以下內容:
- 一個像 Reddit 或 X 這樣的社區。加入社區并參與討論。X 是你在 Grok 上影響結果的最佳選擇。
- 一個由影響者驅動的網站,如:YouTube 或 TikTok。雇傭影響者制作視頻。確保指導他們針對正確的關鍵詞。
- 聯盟發布商。通過支付更高傭金來提升排名。
- 新聞與媒體發布商。購買廣告軟文并/或通過公關活動針對他們。在某些情況下,你可能需要聯系他們的商業內容部門。
你還可以查看這個。
目標查詢扇出
一旦您觀察到哪些搜索是由查詢扇出觸發的,針對這些搜索創建內容。
在您自己的網站上。通過在 Medium 和 LinkedIn 上發布文章。通過新聞稿。或者通過付費文章投放。如果它在搜索引擎中排名靠前,就有機會被基于 LLM 的回答引擎引用。
最后
生成式引擎優化已不再是可選項——它是自然增長的新前沿。在 Peec AI,我們正在構建工具,以追蹤、影響并在這片新生態系統中取得勝利。
生成式引擎優化已不再是可選項——它是有機增長的新前沿。目前,我們看到客戶的 LLM 流量每 2 到 3 個月就能增長 100%。有時,其轉化率甚至能達到傳統SEO流量的20倍!
無論您是正在塑造 AI 答案、監控品牌提及,還是推動內容可見性,現在正是采取行動的時機。
商品管理)













Milvus可視化工具)

)


