現在來聊一聊訓練和渲染是如何進行的
training
train.py
line 31
def training(dataset, opt, pipe, testing_iterations, saving_iterations, checkpoint_iterations, checkpoint, debug_from):# 初始化第一次迭代的索引為0first_iter = 0# 準備輸出和日志記錄器tb_writer = prepare_output_and_logger(dataset)# 初始化高斯模型,參數為數據集的球諧函數(SH)級別gaussians = GaussianModel(dataset.sh_degree)# 創建場景對象,包含數據集和高斯模型scene = Scene(dataset, gaussians)# 設置高斯模型的訓練配置gaussians.training_setup(opt)# 加載檢查點(如果有),恢復模型參數和設置起始迭代次數if checkpoint:(model_params, first_iter) = torch.load(checkpoint)gaussians.restore(model_params, opt)# 設置背景顏色,如果數據集背景為白色,則設置為白色([1, 1, 1]),否則為黑色([0, 0, 0])bg_color = [1, 1, 1] if dataset.white_background else [0, 0, 0]# 將背景顏色轉換為CUDA張量,以便在GPU上使用background = torch.tensor(bg_color, dtype=torch.float32, device="cuda")# 創建兩個CUDA事件,用于記錄迭代開始和結束的時間iter_start = torch.cuda.Event(enable_timing=True)iter_end = torch.cuda.Event(enable_timing=True)# 初始化視點堆棧為空viewpoint_stack = None# 用于記錄指數移動平均損失的變量,初始值為0.0ema_loss_for_log = 0.0# 創建進度條,用于顯示訓練進度,從起始迭代數到總迭代數progress_bar = tqdm(range(first_iter, opt.iterations), desc="Training progress")# 增加起始迭代數,以便從下一次迭代開始first_iter += 1for iteration in range(first_iter, opt.iterations + 1):# 嘗試連接網絡GUI,如果當前沒有連接if network_gui.conn == None:network_gui.try_connect()# 如果已經連接網絡GUI,處理接收和發送數據while network_gui.conn != None:try:# 初始化網絡圖像字節為Nonenet_image_bytes = None# 從網絡GUI接收數據custom_cam, do_training, pipe.convert_SHs_python, pipe.compute_cov3D_python, keep_alive, scaling_modifer = network_gui.receive()# 如果接收到自定義相機數據,則進行渲染if custom_cam != None:# 使用自定義相機數據、當前的高斯模型、管道和背景顏色進行渲染net_image = render(custom_cam, gaussians, pipe, background, scaling_modifer)["render"]# 將渲染結果轉為字節格式,并轉換為內存視圖net_image_bytes = memoryview((torch.clamp(net_image, min=0, max=1.0) * 255).byte().permute(1, 2, 0).contiguous().cpu().numpy())# 發送渲染結果到網絡GUI,并附帶數據集的源路徑network_gui.send(net_image_bytes, dataset.source_path)# 如果需要進行訓練,并且當前迭代次數小于總迭代次數,或不需要保持連接,則退出循環if do_training and ((iteration < int(opt.iterations)) or not keep_alive):breakexcept Exception as e:# 如果出現異常,斷開網絡連接network_gui.conn = None# 記錄當前迭代的開始時間,用于計算每次迭代的持續時間iter_start.record()# 更新學習率gaussians.update_learning_rate(iteration)# 每1000次迭代增加一次SH級別,直到達到最大度if iteration % 1000 == 0:gaussians.oneupSHdegree()# 隨機選擇一個相機視角if not viewpoint_stack:viewpoint_stack = scene.getTrainCameras().copy()# 從相機視角堆棧中隨機彈出一個相機視角viewpoint_cam = viewpoint_stack.pop(randint(0, len(viewpoint_stack) - 1))# 渲染if (iteration - 1) == debug_from:pipe.debug = True# 如果設置了隨機背景顏色,則生成一個隨機背景顏色,否則使用預定義的背景顏色bg = torch.rand((3), device="cuda") if opt.random_background else background# 使用選定的相機視角、高斯模型、渲染管道和背景顏色進行渲染render_pkg = render(viewpoint_cam, gaussians, pipe, bg)# 提取渲染結果、視點空間點張量、可見性過濾器和半徑image, viewspace_point_tensor, visibility_filter, radii = render_pkg["render"], render_pkg["viewspace_points"], render_pkg["visibility_filter"], render_pkg["radii"]# 計算損失gt_image = viewpoint_cam.original_image.cuda() # 獲取地面真實圖像Ll1 = l1_loss(image, gt_image) # 計算L1損失# 計算總損失,結合L1損失和結構相似性損失(SSIM)loss = (1.0 - opt.lambda_dssim) * Ll1 + opt.lambda_dssim * (1.0 - ssim(image, gt_image))loss.backward() # 反向傳播計算梯度# 記錄當前迭代的結束時間,用于計算每次迭代的持續時間iter_end.record()# 在不需要計算梯度的上下文中進行操作with torch.no_grad():# 更新進度條和日志ema_loss_for_log = 0.4 * loss.item() + 0.6 * ema_loss_for_log # 更新指數移動平均損失if iteration % 10 == 0:# 每10次迭代更新一次進度條progress_bar.set_postfix({"Loss": f"{ema_loss_for_log:.{7}f}"})progress_bar.update(10)if iteration == opt.iterations:progress_bar.close()# 記錄訓練報告并保存training_report(tb_writer, iteration, Ll1, loss, l1_loss, iter_start.elapsed_time(iter_end), testing_iterations, scene, render, (pipe, background))if iteration in saving_iterations:# 在指定的迭代次數保存高斯模型print("\n[ITER {}] Saving Gaussians".format(iteration))scene.save(iteration)# 密集化操作if iteration < opt.densify_until_iter:# 跟蹤圖像空間中的最大半徑,用于修剪gaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter], radii[visibility_filter])gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter)# 在指定的迭代范圍和間隔內進行密集化和修剪if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0:size_threshold = 20 if iteration > opt.opacity_reset_interval else Nonegaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold)# 在指定的間隔內或滿足特定條件時重置不透明度if iteration % opt.opacity_reset_interval == 0 or (dataset.white_background and iteration == opt.densify_from_iter):gaussians.reset_opacity()# 優化器步驟if iteration < opt.iterations:gaussians.optimizer.step() # 更新模型參數gaussians.optimizer.zero_grad(set_to_none=True) # 清空梯度# 保存檢查點if iteration in checkpoint_iterations:print("\n[ITER {}] Saving Checkpoint".format(iteration))torch.save((gaussians.capture(), iteration), scene.model_path + "/chkpnt" + str(iteration) + ".pth")render
現在是渲染的這個文件進行方式,首先是主文件里單張圖片的渲染和整個數據集的渲染方法:
render.py
line 24
# 渲染一組視角并保存渲染結果和對應的真實圖像
def render_set(model_path, name, iteration, views, gaussians, pipeline, background):# 定義渲染結果和真實圖像的保存路徑render_path = os.path.join(model_path, name, "ours_{}".format(iteration), "renders")gts_path = os.path.join(model_path, name, "ours_{}".format(iteration), "gt")# 創建保存路徑,如果路徑不存在makedirs(render_path, exist_ok=True)makedirs(gts_path, exist_ok=True)# 遍歷每個視角進行渲染for idx, view in enumerate(tqdm(views, desc="Rendering progress")):# 渲染圖像rendering = render(view, gaussians, pipeline, background)["render"]# 獲取對應的真實圖像gt = view.original_image[0:3, :, :]# 保存渲染結果和真實圖像到指定路徑torchvision.utils.save_image(rendering, os.path.join(render_path, '{0:05d}'.format(idx) + ".png"))torchvision.utils.save_image(gt, os.path.join(gts_path, '{0:05d}'.format(idx) + ".png"))# 渲染訓練集和測試集的圖像,并保存結果
def render_sets(dataset: ModelParams, iteration: int, pipeline: PipelineParams, skip_train: bool, skip_test: bool):with torch.no_grad():# 初始化高斯模型和場景gaussians = GaussianModel(dataset.sh_degree)scene = Scene(dataset, gaussians, load_iteration=iteration, shuffle=False)# 設置背景顏色bg_color = [1, 1, 1] if dataset.white_background else [0, 0, 0]background = torch.tensor(bg_color, dtype=torch.float32, device="cuda")# 如果不跳過訓練集渲染,則渲染訓練集的圖像if not skip_train:render_set(dataset.model_path, "train", scene.loaded_iter, scene.getTrainCameras(), gaussians, pipeline, background)# 如果不跳過測試集渲染,則渲染測試集的圖像if not skip_test:render_set(dataset.model_path, "test", scene.loaded_iter, scene.getTestCameras(), gaussians, pipeline, background)但是這兩個方法都是外層函數,并沒有展示渲染如何進行參數傳遞和具體操作,在以下代碼中才是最關鍵的內容:
gaussian_renderer\__init__.py
line 18
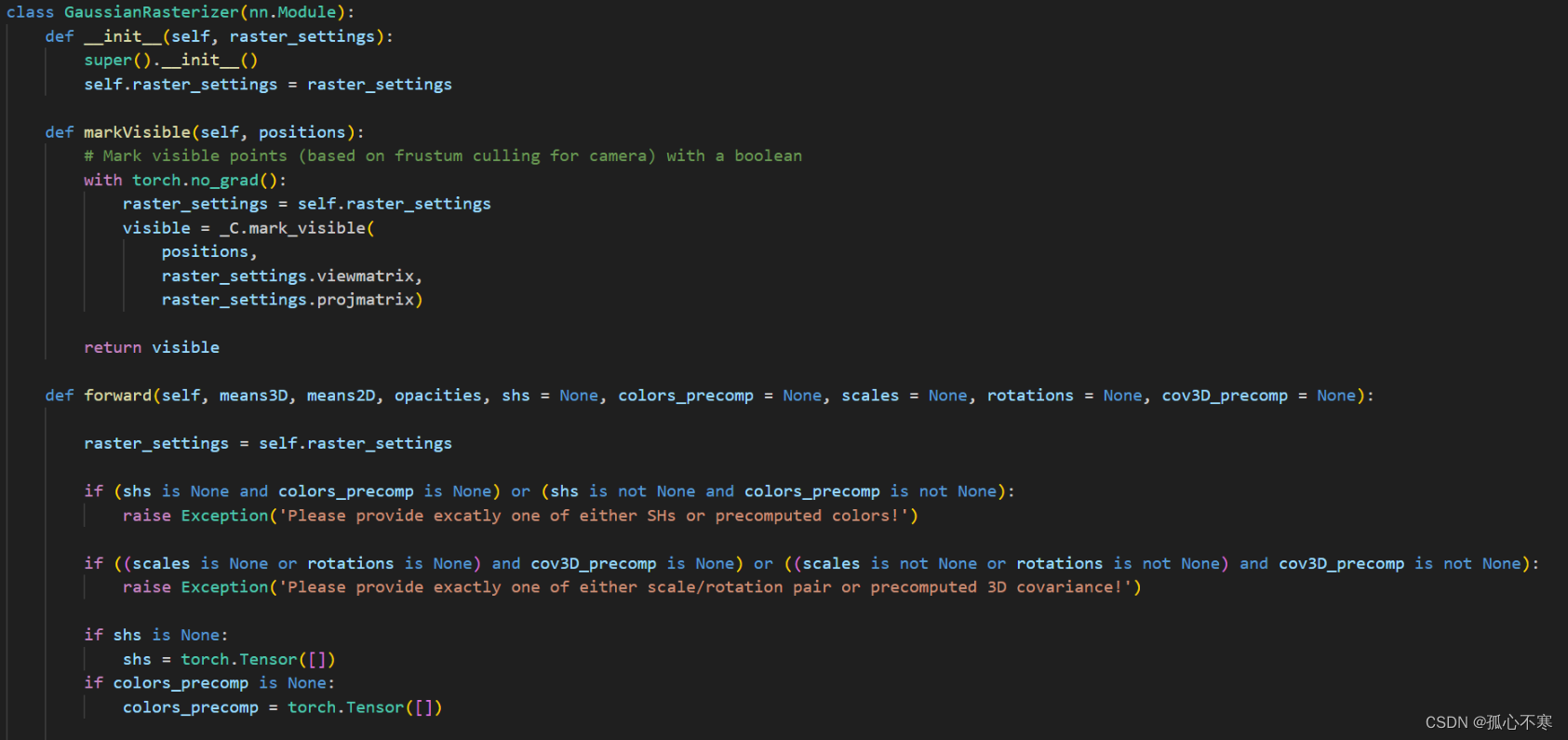
def render(viewpoint_camera, pc: GaussianModel, pipe, bg_color: torch.Tensor, scaling_modifier=1.0, override_color=None):"""渲染場景。參數:viewpoint_camera - 攝像機視角pc - 高斯模型pipe - 管道參數bg_color - 背景顏色張量,必須在GPU上scaling_modifier - 縮放修飾符,默認為1.0override_color - 覆蓋顏色,默認為None"""# 創建一個全零張量,用于使PyTorch返回2D(屏幕空間)均值的梯度screenspace_points = torch.zeros_like(pc.get_xyz, dtype=pc.get_xyz.dtype, requires_grad=True, device="cuda") + 0try:screenspace_points.retain_grad() # 保留梯度信息except:pass# 設置光柵化配置tanfovx = math.tan(viewpoint_camera.FoVx * 0.5) # 計算視角的X軸正切tanfovy = math.tan(viewpoint_camera.FoVy * 0.5) # 計算視角的Y軸正切raster_settings = GaussianRasterizationSettings(image_height=int(viewpoint_camera.image_height), # 圖像高度image_width=int(viewpoint_camera.image_width), # 圖像寬度tanfovx=tanfovx, # 視角X軸正切tanfovy=tanfovy, # 視角Y軸正切bg=bg_color, # 背景顏色scale_modifier=scaling_modifier, # 縮放修飾符viewmatrix=viewpoint_camera.world_view_transform, # 世界視圖變換矩陣projmatrix=viewpoint_camera.full_proj_transform, # 投影變換矩陣sh_degree=pc.active_sh_degree, # 球諧函數度數campos=viewpoint_camera.camera_center, # 攝像機中心prefiltered=False, # 預過濾debug=pipe.debug # 調試模式)rasterizer = GaussianRasterizer(raster_settings=raster_settings) # 初始化光柵化器means3D = pc.get_xyz # 獲取3D均值means2D = screenspace_points # 獲取2D均值opacity = pc.get_opacity # 獲取不透明度# 如果提供了預計算的3D協方差,則使用它。如果沒有,則從光柵化器的縮放/旋轉中計算。scales = Nonerotations = Nonecov3D_precomp = Noneif pipe.compute_cov3D_python:cov3D_precomp = pc.get_covariance(scaling_modifier) # 計算3D協方差else:scales = pc.get_scaling # 獲取縮放rotations = pc.get_rotation # 獲取旋轉# 如果提供了預計算的顏色,則使用它們。否則,如果需要在Python中預計算SH到顏色的轉換,則進行轉換。shs = Nonecolors_precomp = Noneif override_color is None:if pipe.convert_SHs_python:shs_view = pc.get_features.transpose(1, 2).view(-1, 3, (pc.max_sh_degree + 1) ** 2)dir_pp = (pc.get_xyz - viewpoint_camera.camera_center.repeat(pc.get_features.shape[0], 1))dir_pp_normalized = dir_pp / dir_pp.norm(dim=1, keepdim=True)sh2rgb = eval_sh(pc.active_sh_degree, shs_view, dir_pp_normalized)colors_precomp = torch.clamp_min(sh2rgb + 0.5, 0.0) # 計算顏色else:shs = pc.get_features # 獲取球諧函數特征else:colors_precomp = override_color # 覆蓋顏色# 將可見的高斯體光柵化為圖像,并獲取它們在屏幕上的半徑。rendered_image, radii = rasterizer(means3D=means3D,means2D=means2D,shs=shs,colors_precomp=colors_precomp,opacities=opacity,scales=scales,rotations=rotations,cov3D_precomp=cov3D_precomp)# 那些被視錐剔除或半徑為0的高斯體是不可見的。# 它們將被排除在用于分裂標準的值更新之外。return {"render": rendered_image, # 渲染圖像"viewspace_points": screenspace_points, # 視圖空間點"visibility_filter": radii > 0, # 可見性過濾器"radii": radii # 半徑}最值得關注的光柵化器,如果轉到定義去查看,其實會發現它就是第二期里講forward的代碼,只是這里面用python寫了變量的調用,實際的操作方式還是在cu文件里面。所以在此就不多做贅述,可以看上一期博客里面對forward的解讀。





)






含代碼復現)

)
——指針與數組及字符串)

)

