目錄
一、Introduction
1 Motivation
2 Contribution
二、原理分析
1 Network Architecture
1)Shallow feature extraction
2) deep feature extraction
3) image reconsruction modules
4) loss function
2 Residual Swin Transformer Block
三、實驗結果
1 經典圖像超分辨率(Classical image SR)
2 輕量級圖像超分辨率(Lightweight image SR)
3 Real-world image SR
四、小結
五、鏈接及代碼
一、Introduction
1 Motivation
在圖像超分辨率、圖像去噪、壓縮等圖像修復(Image restoration)任務中,卷積神經網絡目前仍然是主流。但卷積神經網絡有以下缺陷:
(1)圖像和卷積核之間的交互是與內容無關的;
(2)在局部處理的原則下,卷積對于長距離依賴建模是無效的。
作為卷積的一個替代操作,Transformer設計了自注意力機制來捕捉全局信息,但視覺Transformer因為需要劃分patch,因此具有以下兩個缺點:
(1)邊界像素不能利用patch之外的鄰近像素進行圖像恢復;
(2)恢復后的圖像可能會在每個patch周圍引入邊界偽影,這個問題能夠通過patch overlapping緩解,但會增加計算量。
Swin Transformer結合了卷積和Transformer的優勢,因此本文基于Swin Transformer提出了一種圖像修復模型SwinIR。
2 Contribution
和現有的模型相比,SwinIR具有更少的參數,且取得了更好的效果。
Recently, Swin Transformer [56] has shown great promise as it integrates the advantages of both CNN and Transformer. On the one hand, it has the advantage of CNN to process image with large size due to the local attention mechanism. On the other hand, it has the advantage of Transformer to model long-range dependency with the shifted window scheme.
二、原理分析
1 Network Architecture
SwinIR的整體結構如下圖所示,可以分為3個部分:shallow feature extraction、deep feature extraction、highquality (HQ) image reconstruction modules。對所有的復原任務采用相同的feature extraction modules,針對不同的任務采用不同的reconstruction modules。
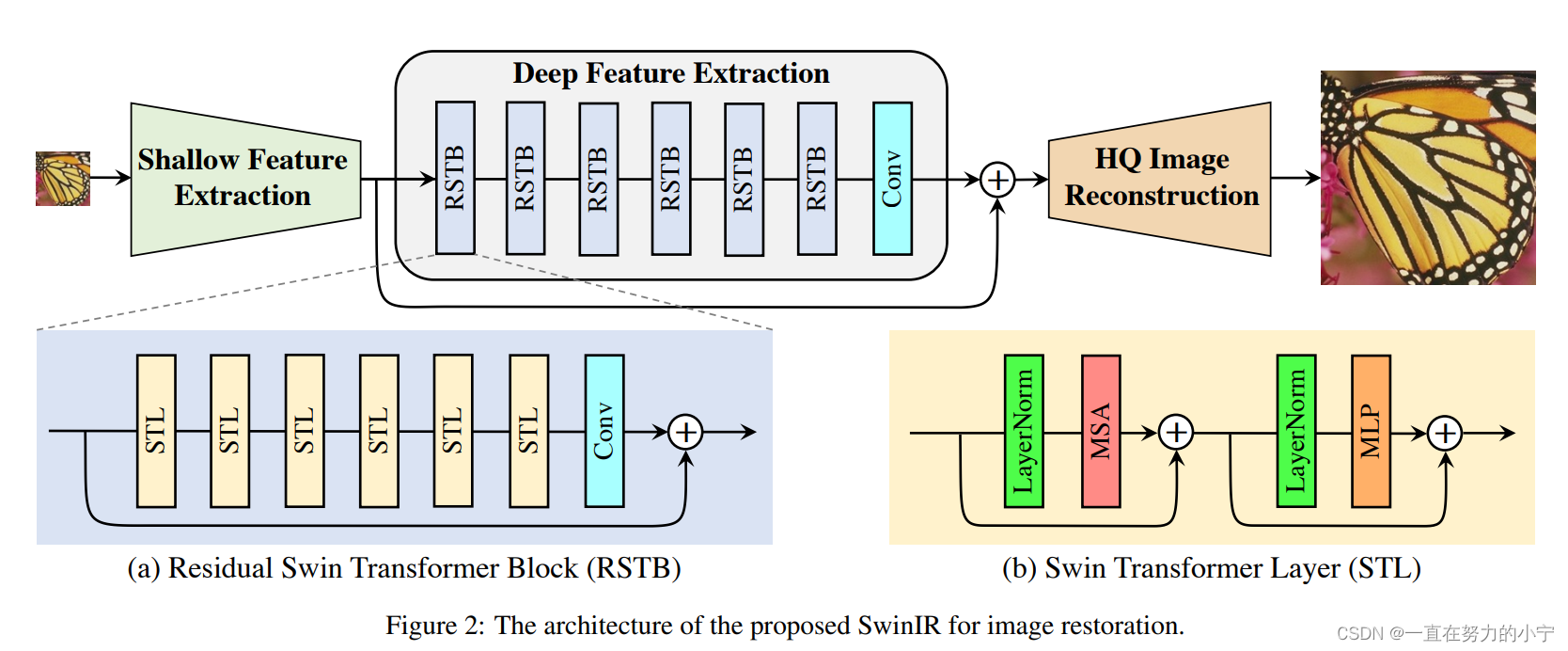
1)Shallow feature extraction
首先用一個3x3卷積HSF提取淺層特征F0

將提取到的淺層特征F0,使用深層特征提取模塊HDF進一步提取特征。深層特征提取模塊由K個residual Swin Transformer blocks(RSTB)和一個3×3卷積構成。

2) deep feature extraction
每個RSTB的輸出F1,F2,FK,以及輸出的深層特征FDK如式(3)所示,式中HRSTBi表示第i個RSTB模塊,HCONV表示最終的卷積層。卷積層能夠將卷積的歸納偏置(inductive bias)引入基于Transformer的網絡,為后續淺層、深層特征的融合奠定基礎。
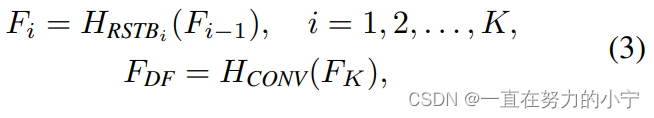
3) image reconsruction modules
以圖像超分辨率為例,通過融合淺層特征F0和深層特征FDK來重建高質量圖片IRHQ,式中HREC為重建模塊。
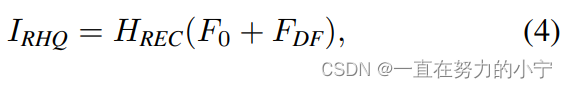
淺層特征F0主要包含低頻信息,而深層特征則專注于恢復丟失的高頻信息。SwinIR采用一個長距離連接,將低頻信息直接傳輸給重建模塊,可以幫助深度特征提取模塊專注于高頻信息,穩定訓練。在圖像超分辨率任務中,通過sub-pixel convolution layer將特征上采樣,實現重建。在其他任務中,則是采用一個帶有殘差的卷積操作,如公式(5)所示。
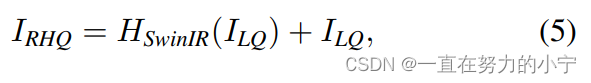
4) loss function
圖像超分辨率任務采用L1損失,通過優化SwinIR生成的高質量圖像IRHQ及其對應的標簽IHQ的來優化模型。
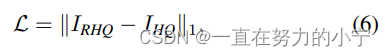
圖像去噪任務和壓縮任務采用Charbonnier loss,式中?通常設置為10-3。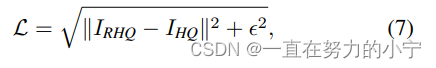
2 Residual Swin Transformer Block
如下圖所示,residual Swin Transformer block (RSTB)由殘差塊、Swin Transformer layers (STL)、卷積層構成。卷積操作有利于增強平移不變性,殘差連接則有利于模型融合不同層級的特征。
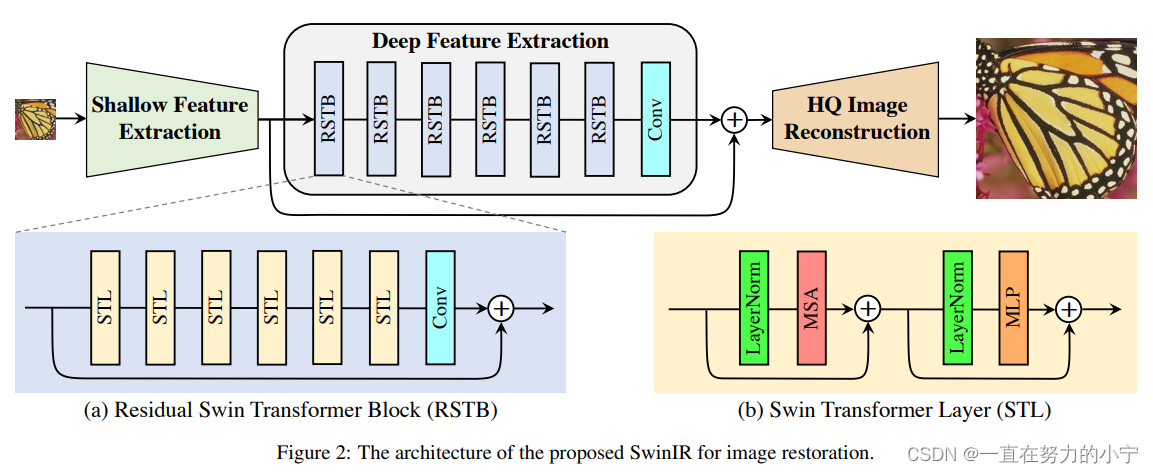
Swin Transformer layer (STL)取自論文:Swin transformer: Hierarchical vision transformer using shifted windows,和原版Transformer中multi-head self-attention的不同之處主要有局部注意力(local attention)和滑動窗口機制(shifted window mechanism)。首先,將大小為H×W×C的輸入特征reshape為(HW/M2)×M2×C,即將其劃分為HW/M2個M×M的local windows,然后對每個windows計算自注意力,具體如式(10)、(12)所示。第一個式子表示Query、Key、Value的計算過程,三個權重在不同的window間共享參數;第二個式子表示multi-head self-attention以及add and norm;第三個式子表示feed forward network以及add and norm。
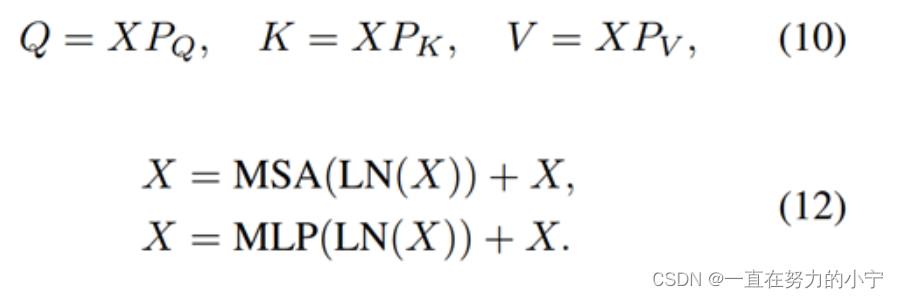
由于在local windows之間沒有信息交互,因此本文交替使用常規窗口劃分和滑動窗口劃分來實現window間的信息交互。
三、實驗結果
部分實驗結果如下所示(僅選取了圖像超分辨率相關的實驗結果),包括經典圖像超分辨率(Classical image SR)、輕量級圖像超分辨率(Lightweight image SR)、真實世界圖像超分辨率(Real-world image SR)。
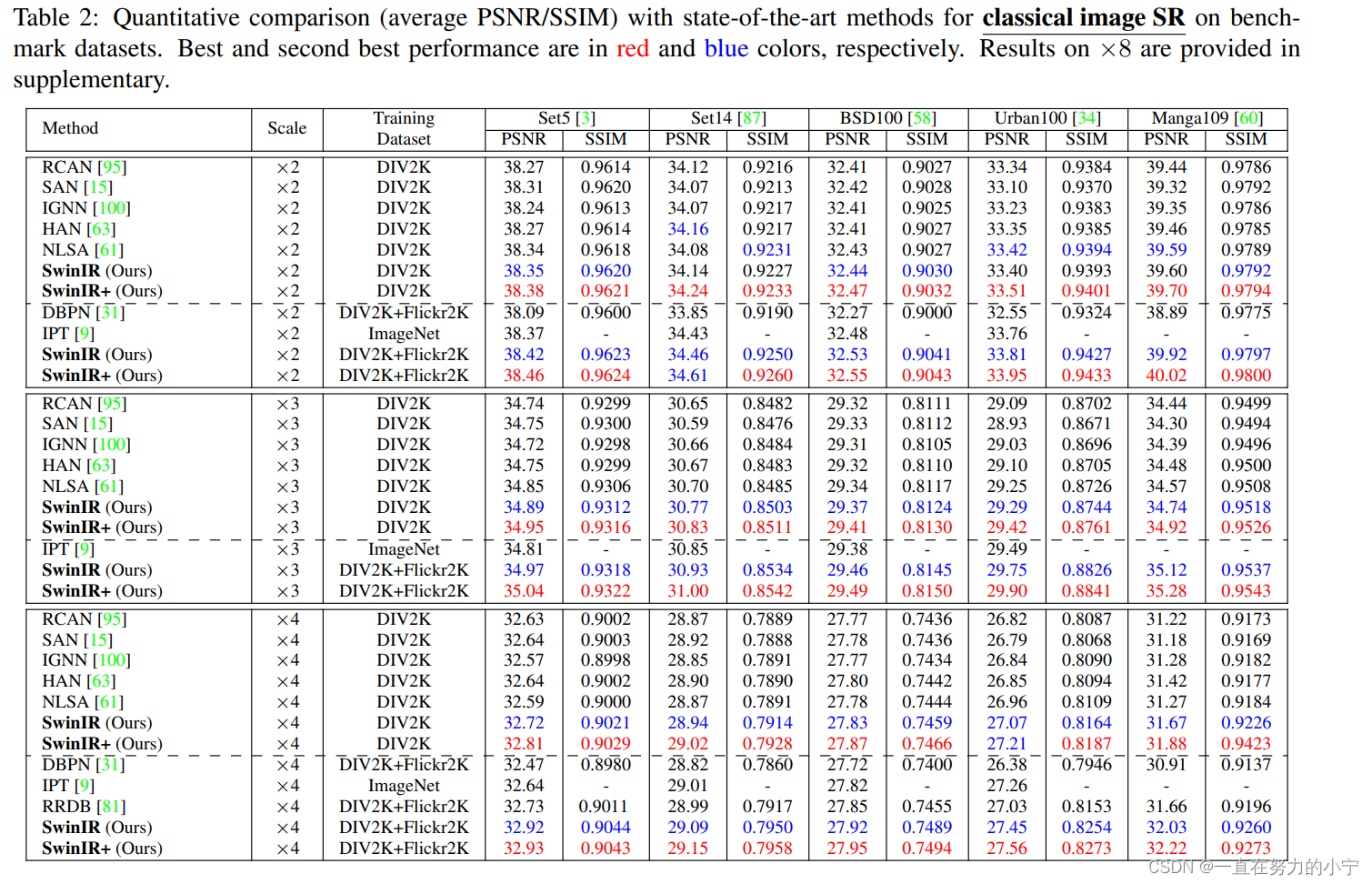
1 經典圖像超分辨率(Classical image SR)
作者對比了基于卷積神經網絡的模型(DBPN、RCAN、RRDB、SAN、IGNN、HAN、NLSA IPT)和最新的基于transformer的模型(IPT)。得益于局部窗口自注意力機制和卷積操作的歸納偏置,SwinIR的參數量減少至11.8M,明顯少于IPT的115.5M,甚至少于部分基于卷積神經網絡的模型;模型的訓練難度也隨之減少,不再需要ImageNet那樣的大數據集來訓練模型。僅使用DIV2K數據集訓練時,SwinIR的精度就超過了卷積神經網絡模型;再加上Flickr2K數據集后,精度就超越了使用ImageNet訓練、115.5M參數的IPT模型。
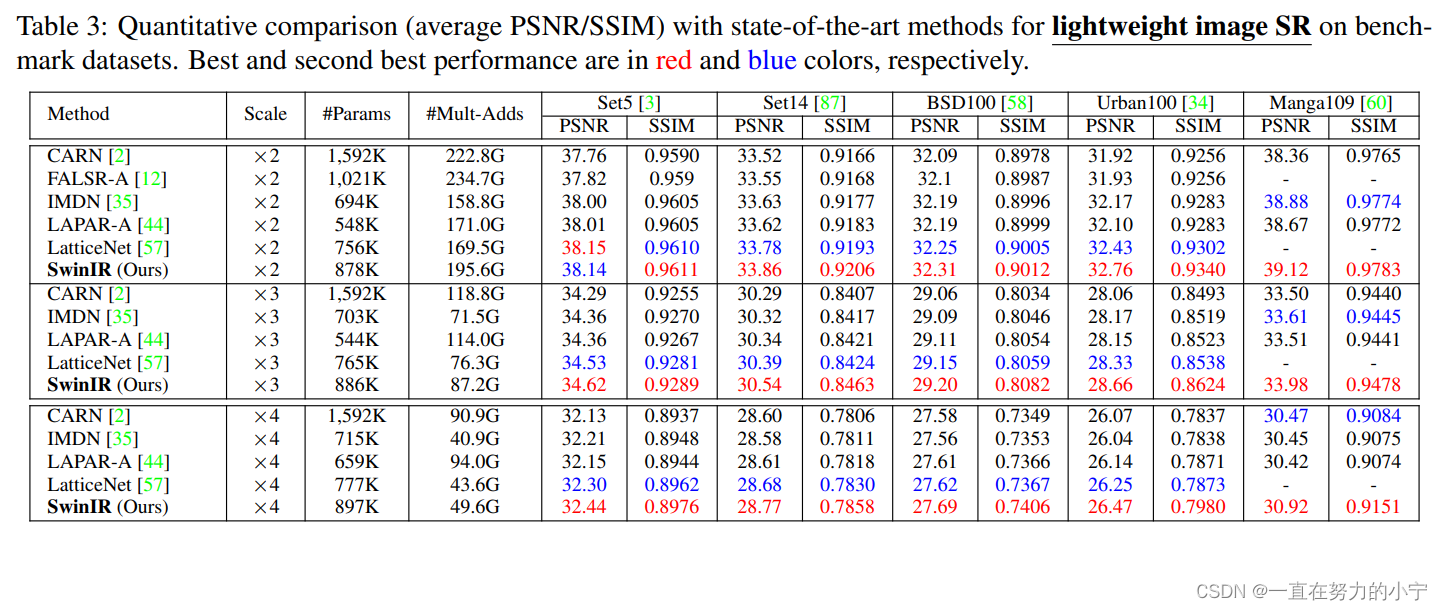
2 輕量級圖像超分辨率(Lightweight image SR)
作者對比了幾個輕量級的圖像超分模型(CARN、FALSR-A、IMDN、LAPAR-A、LatticeNet),如下圖所示,在相似的計算量和參數量的前提下,SwinIR超越了諸多輕量級超分模型,顯然SwinIR更加高效。
3 Real-world image SR
圖像超分辨率的最終目的是應用于真實世界。由于真實世界圖像超分任務沒有GT圖像,因此作者對比了幾種真實世界圖像超分模型的可視化結果(ESRGAN、RealSR、BSRGAN、Real-ESRGAN)。SwinIR能夠產生銳度高的清晰圖像。

四、小結
Transformer在視覺領域魔改至今,Swin Transformer當屬其中最優、運用最多的變體。因此SwinIR進一步把Swin Transformer中的block搬到了圖像處理任務里,模型則仍然遵循目前超分網絡中head+body+tail的通用結構,改進相對比較小。
另一方面,Swin Transforme把卷積神經網絡中常用的多尺度結構用在了基于Transforme的模型中,但圖像超分辨率中一般不用多尺度結構,這或許就是SwinIR不如Swin Transforme效果好的原因。
五、鏈接及代碼
https://github.com/JingyunLiang/SwinIR?tab=readme-ov-file![]() https://github.com/JingyunLiang/SwinIR?tab=readme-ov-filehttps://arxiv.org/pdf/2108.10257
https://github.com/JingyunLiang/SwinIR?tab=readme-ov-filehttps://arxiv.org/pdf/2108.10257![]() https://arxiv.org/pdf/2108.10257
https://arxiv.org/pdf/2108.10257

)
——指針與數組及字符串)

)







)





:界面優化)
![[Go 微服務] Kratos 使用的簡單總結](http://pic.xiahunao.cn/[Go 微服務] Kratos 使用的簡單總結)