論文主要處理Vision Transformer中的性能問題,采用推理速度不同的級聯模型進行速度優化,搭配層級間的特征復用和自注意力關系復用來提升準確率。從實驗結果來看,性能提升不錯
來源:曉飛的算法工程筆記 公眾號
論文: Not All Images are Worth 16x16 Words: Dynamic Transformers for Efficient Image Recognition

- 論文地址:https://arxiv.org/abs/2105.15075
- 論文代碼:https://github.com/blackfeather-wang/Dynamic-Vision-Transformer
Introduction
? Transformers是自然語言處理 (NLP) 中占主導地位的自注意的模型,最近很多研究將其成功適配到圖像識別任務。這類模型不僅在ImageNet上取得了SOTA,而且性能還能隨著數據集規模的增長而不斷增長。這類模型一般都先將圖像拆分為固定數量的圖像塊,然后轉換為1D token作為輸入,拆分更多的token有助于提高預測的準確性,但也會帶來巨額的計算成本(與token數成二次增長)。為了權衡性能和準確率,現有的這類模型都采用14x14或16x16的token數量。
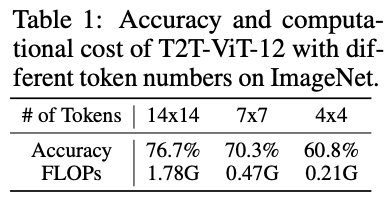
? 論文認為不同圖片之間存在相當大的差異,使用相同數量的token處理所有圖片并不是最優的。最理想的做法應為每個輸入專門配置token數量,這也是模型計算效率的關鍵。以T2T-ViT-12為例,官方推薦的14x14 token數僅比4x4 token數增加了15.9%(76.7% 對 60.8%)的準確率,卻增加了8.5倍的計算成本(1.78G 對 0.21G)。也就是說,對“簡單”圖片使用14x14 token數配置浪費了大量計算資源,使用4x4 token數配置就足夠了。

? 受此啟發,論文提出了一種動態Vision Transformer(DVT)框架,能夠根據每個圖片自動配置合適的token數,實現高效計算。訓練時使用逐漸增多的token數訓練級聯Transformer,測試時從較少的token數開始依次推理,得到置信度足夠的預測即終止推理過程。通過自動調整token數,“簡單”樣本和“困難”樣本的計算消耗將會不一樣,從而顯著提高效率。
? 另外,論文還設計了基于特征和基于關系的兩種復用機制,減少冗余的計算。前者允許下游模型在先前提取的深度特征上進行訓練,而后者允許利用上游模型中的自注意力關系來學習更準確的注意力圖。
? DVT是一個通用框架,可集成到大多數圖像識別的Transformer模型中。而且可以通過簡單地調整提前終止標準,在線調整整體計算成本,適用于計算資源動態波動或需要以最小功耗來實現特定性能的情況。從ImageNet和CIFAR的實驗結果來看,在精度相同的情況下,DVT能將T2T-ViT的計算成本降低1.6-3.6倍,而在NVIDIA 2080Ti上的真實推理速度也與理論結果一致。
Dynamic Vision Transformer
Overview

? DVT的推理過程如圖2所示。對于每張測試圖片,先使用少量1D token序列對其進行粗略表示,可通過直接使用分割圖像塊或利用如tokens-to-token模塊之類的技術來實現,然后通過Vision Transformer對這些token進行快速預測。由于Transformer的計算消耗與token數量成二次增長,所以這個過程很快。最后基于預設的終止標準對預測結果進行快速評估,確定是否足夠可靠。
? 如果預測未能滿足終止標準,原始輸入圖像將被拆分為更多token,再進行更準確、計算成本更高的推理。每個token embedding的維度保持不變,只增加token數量,從而實現更細粒度的表示。此時推理使用的Vision Transformer與上一級具有相同架構,但參數是不同的。根據設計,此階段在某些“困難”測試圖片上權衡計算量以獲得更高的準確性。為了提高效率,新模型可以復用之前學習的特征和關系。在獲得新的預測結果后,同樣根據終止標準進行判斷,不符合則繼續上述過程,直到結果符合標準或已使用最終的Vision Transformer。
? 訓練時,需保證DVT中所有級聯Vision Transformer輸出正確的預測結果,其優化目標為:
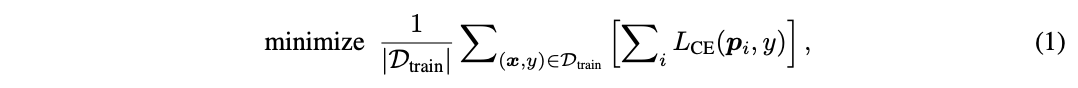
? 其中, ( x , y ) (x, y) (x,y)為訓練集 D t r a i n D_{train} Dtrain?中的一個樣本及其對應的標簽,采用標準的交叉熵損失函數 L C E ( ? ) L_{CE}(·) LCE?(?),而 p i p_i pi?表示第 i i i個模型輸出的softmax預測概率。
? DVT是一個通用且靈活的框架,可以嵌入到大多數現有的Vision Transformer模型(如ViT、DeiT和T2T-ViT)之中,提高其性能。
Feature and Relationship Reuse
? DVT的一個重要挑戰是如何進行計算的復用。在使用的具有更多token的下游Vision Transformer時,直接忽略之前模型中的計算結果顯然是低效的。雖然上游模型的token數量較少,但也提取了對預測有價值的信息。因此,論文提出了兩種機制來復用學習到的深度特征和自注意力關系,僅增加少量的額外計算成本就能顯著提高準確率。
? 介紹前,先重溫一下Vision Transformer的基本公式。Transformer encoder由交替堆疊的多頭自注意力(MSA)和多層感知器 (MLP)塊組成,每個塊的之前和之后分別添加了層歸一化(LN)和殘差連接。定義 z l ∈ R N × D z_l\in R^{N\times D} zl?∈RN×D表示第 l l l層的輸出,其中 N N N是樣本的token數, D D D是token的維度。需要注意的是, N = H W + 1 N=HW+1 N=HW+1,對應 H × W H\times W H×W圖像塊和可學習的分類token。假設Transformer共 L L L層,則整個模型的計算可表示為:
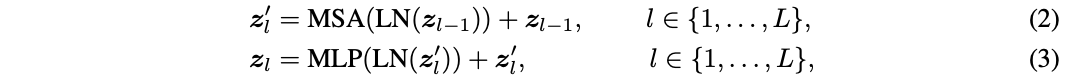
? 得到最終的結果 z L z_L zL?后,取其中的分類token通過LN層+全連接層進行最終預測。這里省略了position embedding的細節,論文沒有對其進行修改。
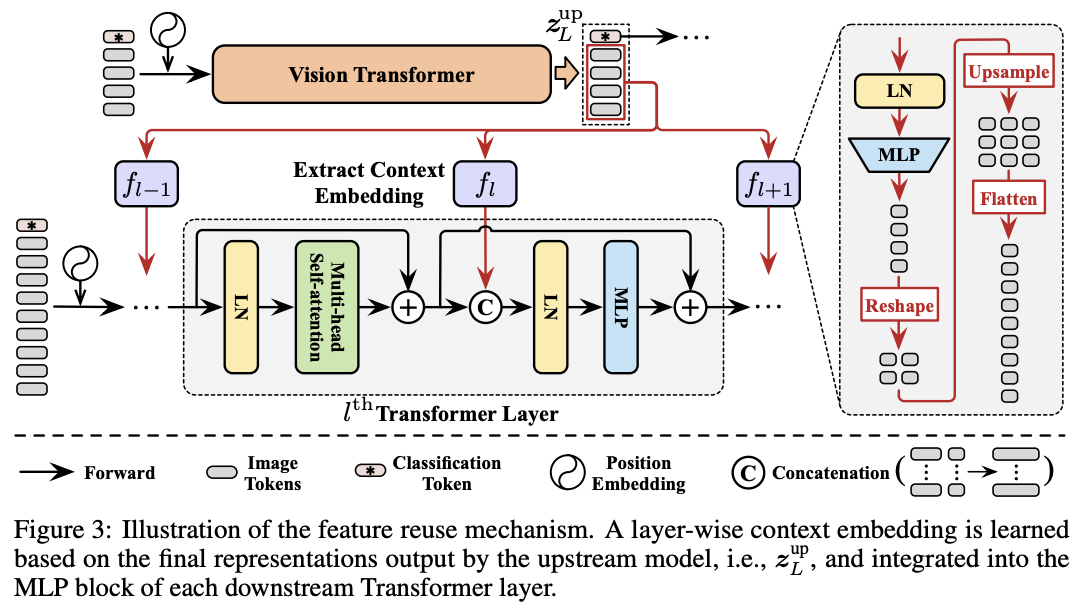
? DVT中的所有Transformer都具有相同的目標,即提取關鍵特征進行準確識別。 因此,下游模型應該在上游模型計算的深度特征的基礎上學習才是最高效的,而不是從頭開始提取特征。為此,論文提出了圖3的特征復用機制,利用上游Transformer最后輸出的結果 z L u p z^{up}_L zLup?來生成下游模型每層的輔助embedding輸入 E l E_l El?:
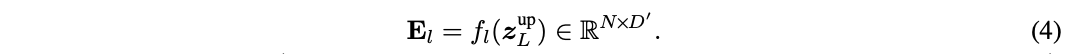
? f l : R N × D → R N × D ′ f_l:\mathbb{R}^{N\times D}\to \mathbb{R}^{N\times D^{'}} fl?:RN×D→RN×D′ 由LN+MLP( R D → R D ′ \mathbb{R}^{D}\to \mathbb{R}^{D^{'}} RD→RD′)開頭,對上游模型輸出進行非線性轉換。轉換后將結果reshape到原始圖像中的相應位置,然后上采樣并展平來匹配下游模型的token數量。一般情況下,使用較小的 D ′ D^{'} D′以便快速生成 f l f_l fl?。
? 之后將 E l E_l El?拼接到下游模型對應層的中間特征作為預測的先驗知識,也就是將公式3替換為:
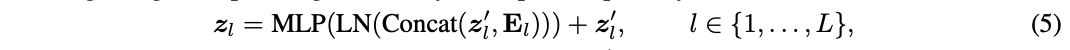
? E l E_l El?與中間特征 z l ′ z^{'}_l zl′?拼接,LN 的維度和MLP的第一層從 D D D增加到 D + D ′ D+D^{'} D+D′。 由于 E l E_l El?是基于上游輸出 z L u p z^{up}_L zLup?生成的,token數少于 z l ′ z^{'}_l zl′?,它實際上為 z l ′ z^{'}_l zl′?中的每個token總結了輸入圖像的上下文信息。 因此,將 E l E_l El?命名為上下文embedding。此外,論文發現不復用分類token對性能有提升,因此在公式5中將其填充零。
? 公式4和5允許下游模型在每層靈活地利用 z L u p z^{up}_L zLup?內的信息,從而最小化最終識別損失,這種特征重用方式也可以認為隱式地擴大了模型深度。
? Vision Transformer的關鍵在于自注意力模塊能夠整合整個圖像的信息,從而有效地模擬圖像中的長距離關系。通常情況下,模型需要在每一層學習一組注意力圖來描述token之間的關系。除了上面提到的特征復用,論文認為下游模型還可以復用上游模型產生的自注意力圖來進行優化。
? 定義輸入特征 z l z_l zl?,自注意力模塊先通過線性變換得到query矩陣 Q l Q_l Ql?、key矩陣 K l K_l Kl?和value矩陣 V l V_l Vl?:

? 其中, W l Q W^Q_l WlQ?、 W l K W^K_l WlK?和 W l V W^V_l WlV?為權重矩陣。然后通過一個帶有softmax的縮放點乘矩陣運算得到注意力圖,最后根據注意力圖來計算所有token的值:
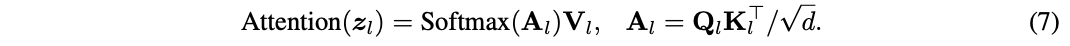
? 其中, d d d是 Q Q Q或 K K K的點積結果維度, A l ∈ R N × N A_l\in \mathbb{R}^{N\times N} Al?∈RN×N為注意力圖。為了清楚起見,這省略了多頭注意力機制的細節,多頭情況下 A l A_l Al?包含多個注意力圖。
? 對于關系復用,先將上游模型所有層產生的注意力圖(即 A l u p , l ∈ { 1 , ? , L } A^{up}_l, l\in \{1,\cdots , L\} Alup?,l∈{1,?,L})拼接起來:

? 其中, N u p N^{up} Nup和 N u p A t t N^{Att}_{up} NupAtt? 分別為上游模型中的toekn數和注意力圖數,通常 N u p A t t = N H L N^{Att}_{up} = N^H L NupAtt?=NHL, N H N^H NH是多頭注意力的head數, L L L是層數。
? 下游的模型同時利用自己的token和 A u p A^{up} Aup來構成注意力圖,也就是將公式7替換為:
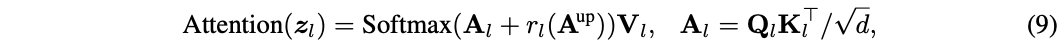
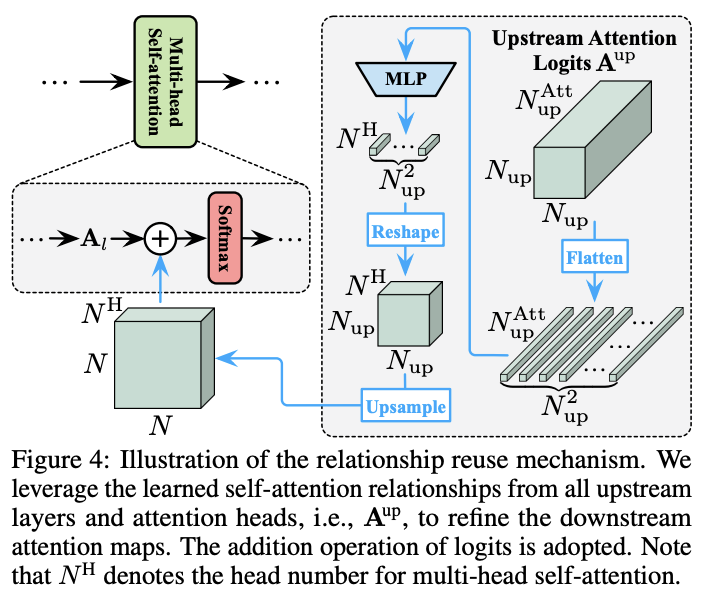
? 其中 r l ( ? ) r_l(\cdot) rl?(?)是一個轉換網絡,整合 A u p A^{up} Aup提供的信息來細化下游注意力圖 A l A_l Al?。 r l ( ? ) r_l(\cdot) rl?(?)的架構如圖5所示,先進行非線性MLP轉換,然后上采樣匹配下游模型的注意力圖大小。
? 公式9雖然很簡單,但很靈活。有兩個可以魔改的地方:
- 由于下游模型中的每個自注意力模塊可以訪問上游模型的所有淺層和深層的注意力頭,可以嘗試通過可學習的方式來對多層的注意力信息進行加權整合。
- 新生成的注意力圖和復用注意力圖直接相加,可以嘗試通過可學習的方式來對兩者加權。
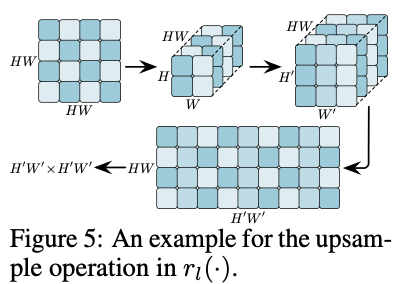
? 還需要注意的是, r l ( ? ) r_l(\cdot) rl?(?)不能直接使用常規上采樣操作。如圖5所示,假設需要將 H W × H W HW\times HW HW×HW( H = W = 2 H =W = 2 H=W=2)的注意力圖映射上采樣到 H ′ W ′ × H ′ W ′ H^{'}W^{'}\times H^{'}W^{'} H′W′×H′W′( H ′ = W ′ = 3 H^{'} =W^{'} = 3 H′=W′=3)的大小。由于每一行對應單個token與其他 H × W H\times W H×W個token的關系,直接對注意力圖上采樣會引入混亂的數據。因此,需要先將行reshape為 H × W H\times W H×W,然后再縮放到 H ′ W ′ × H ′ W ′ H^{'}W^{'}\times H^{'}W^{'} H′W′×H′W′,最后再展平為 H ′ W ′ H^{'}W^{'} H′W′向量。
? 如前面所述,DVT框架逐漸增加測試樣本的token數量并執行提前終止,“簡單”和“困難”圖像可以使用不同的token數來處理,從而提高了整體效率。對于第 i i i個模型產生的softmax預測 p i p_i pi?,將 p i p_i pi?的最大項 m a x j p i j max_j p_{ij} maxj?pij?與閾值 μ i {\mu}_{i} μi?進行比較。如果 m a x j p i j ≥ μ i max_j p_{ij}\ge {\mu}_{i} maxj?pij?≥μi?,則停止并采用 p i p_i pi?作為輸出。否則,將使用更多token數更多的下游模型繼續預測直到最后一個模型。
? 閾值 { μ 1 , μ 2 , ? } \{\mu_1, \mu_2, \cdots\} {μ1?,μ2?,?}需要在驗證集上求解。假設一個計算資源有限的批量數據分類場景,DVT需要在給定的計算預算 B > 0 B > 0 B>0內識別一組樣本 D v a l D_{val} Dval?。定義 A c c ( D v a l , { μ 1 , μ 2 , ? } ) Acc(D_{val}, \{\mu_1, \mu_2, \cdots\}) Acc(Dval?,{μ1?,μ2?,?})和 F L O P s ( D v a l , { μ 1 , μ 2 , ? } ) FLOPs(D_{val}, \{\mu_1, \mu_2, \cdots\}) FLOPs(Dval?,{μ1?,μ2?,?})為數據集 D v a l D_{val} Dval?上使用閾值 { μ 1 , μ 2 , ? } \{\mu_1, \mu_2, \cdots\} {μ1?,μ2?,?}時的準確度和計算成本,最優閾值可以通過求解以下優化問題得到:
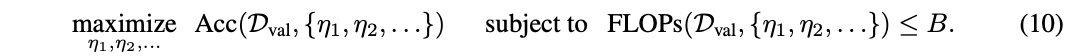
? 由于公式10是不可微的,論文使用遺傳算法解決了這個問題。
Experiment
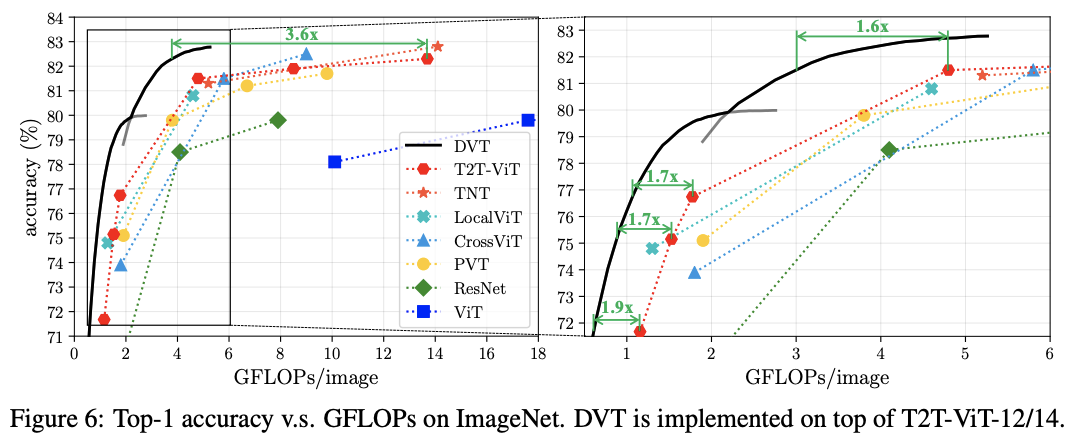
? ImageNet上的性能對比。

? 推理性能對比。

? CIFAR上對比DVT在不同模型規模的性能。
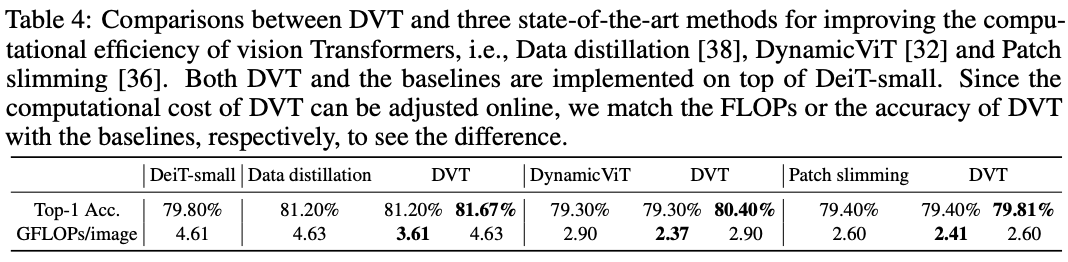
? 在ImageNet上與SOTA vision transformer提升方法的性能對比。
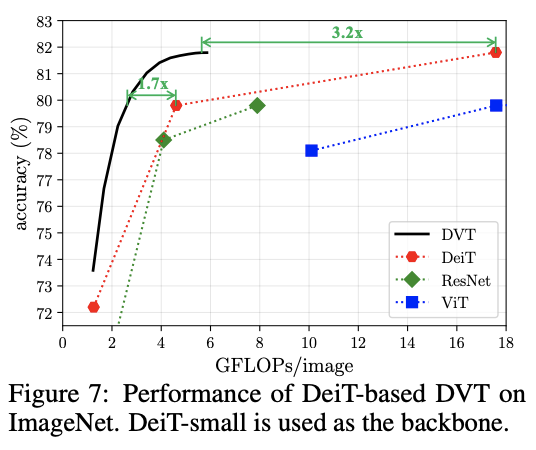
? 基于DeiT的DVT性能對比。
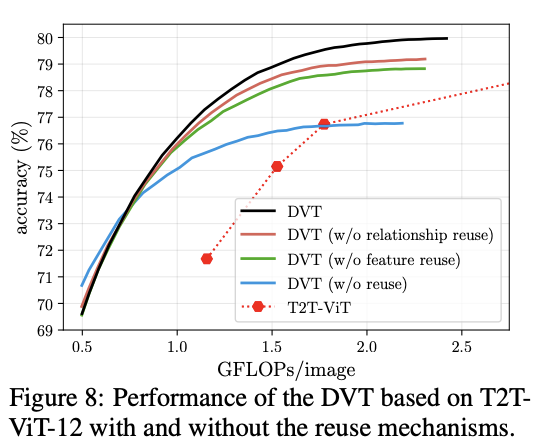
? 復用機制的對比實驗。
? 與類似的提前退出方法的性能對比。
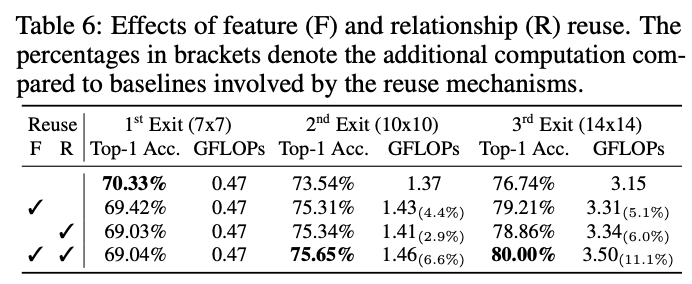
? 復用機制提升的性能與計算量。
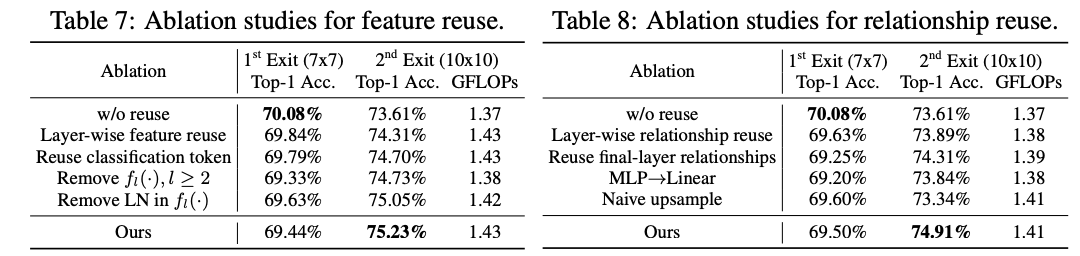
? 復用機制實現細節的對比實驗。

? 難易樣本的例子以及數量分布。

? 不同終止標準的性能對比。
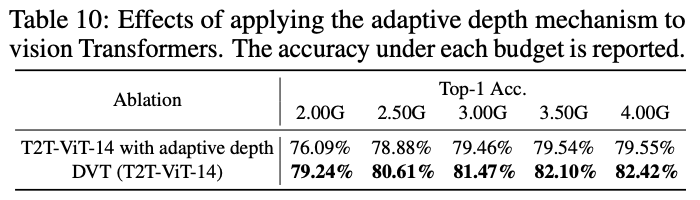
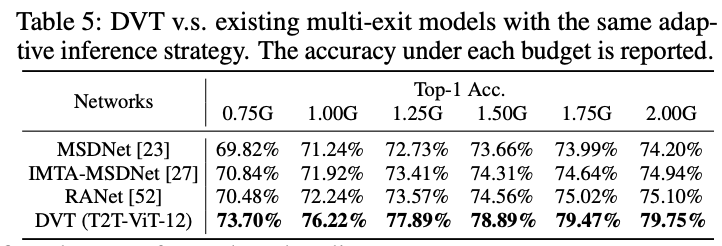
? 與自適應深度方法進行性能對比,自適應方法是在模型的不同位置插入分類器。
Conclusion
? 論文主要處理Vision Transformer中的性能問題,采用推理速度不同的級聯模型進行速度優化,搭配層級間的特征復用和自注意力關系復用來提升準確率。從實驗結果來看,性能提升不錯。
?
?
?
?
如果本文對你有幫助,麻煩點個贊或在看唄~
更多內容請關注 微信公眾號【曉飛的算法工程筆記】





含代碼復現)

)
——指針與數組及字符串)

)







)

