人工智能-NLP簡單知識匯總01
1.1自然語言處理的基本概念
自然語言處理難點:
- 語音歧義
- 句子切分歧義
- 詞義歧義
- 結構歧義
- 代指歧義
- 省略歧義
- 語用歧義
總而言之:!!語言無處不歧義
1.2自然語言處理的基本范式
1.2.1基于規則的方法
通過詞匯、形式文法等制定的規則引入語言學知識,從而完成相應的自然語言處理任務
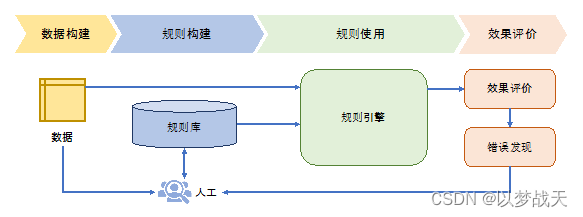
對于機器翻譯任務可以構造如下規則庫:
if 漢語主語=我 then 英語主語 = I
if 英語主語=I then 英語 be動詞 = am/was
if 漢語 = 蘋果 and 沒有修飾量詞 then 英語 = apples
就是基于固定規則,優缺點顯而易見
1.2.2基于機器學習的方法
將自然語言處理任務轉化為某種分類任務
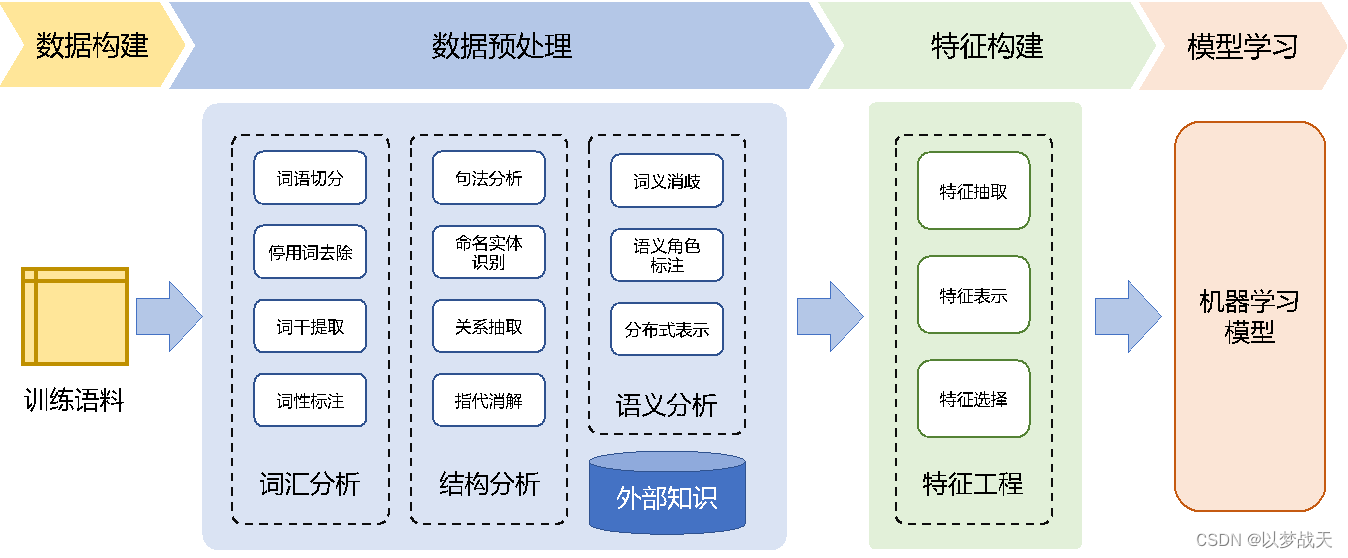
-
數據構建既是構建語料庫(Corpus)
-
數據預處理既是簡單的數據處理劃分。
-
特征構建階段是提取對于機器學習模型有用的特征。
-
模型學習階段既是選擇合適的機器學習模型,確定學習準則,訓練模型參數。
需要人工處理的特別多
1.2.3基于深度學習的方法
將特征學習和預測模型融合,通過優化算法使得模型自動地學習出好的特征表示,并基于此進行結果預測
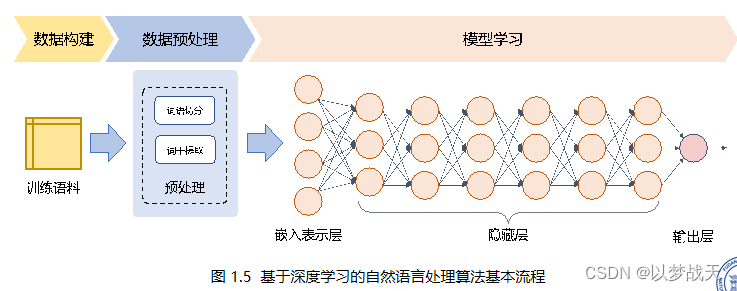
- 數據預處理簡單
- 通過多層特征轉換,將原始數據轉換為更加抽象的表示。可以在一定程度上完全代替人工設計的特征。也稱為:表示學習。
- 利用自監督任務進行預處理,通過海量的數據得到更加通用語言表示,根據下游任務進行網絡調整。
1.2.4基于大模型的方法
將大量各類型自然語言處理任務,統一為生成式自然語言理解框架
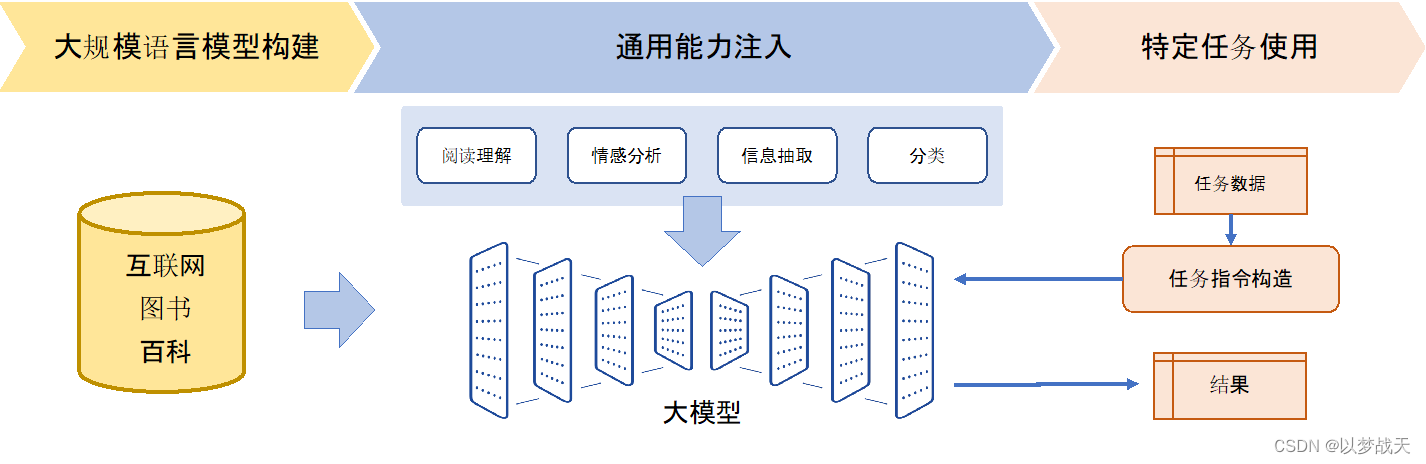
- 在大規模語言模型構建階段,通過大量的文本內容,訓練模型長文本的建模能力,使得模型具有語言生成能力,并使得模型獲得隱式的世界知識。
- 在通用能力注入階段,利用包括閱讀理解、情感分析、信息抽取等現有任務的標注數據,結合人工設計的指令詞對模型進行多任務訓練,從而使得模型具有很好的任務泛化能力。
- 特定任務使用階段則變得非常簡單,由于模型具備了通用任務能力,只需要根據任務需求設計任務指令,將任務中所需處理的文本內容與指令結合,然后就可以利用大模型得到所需結果。
![[DataWhale大模型應用開發]學習筆記1-嘗試搭建向量數據庫](http://pic.xiahunao.cn/[DataWhale大模型應用開發]學習筆記1-嘗試搭建向量數據庫)










)

)

)



