本文來源公眾號“江大白”,僅用于學術分享,侵權刪,干貨滿滿。
原文鏈接:何凱明入職 MIT,首次帶隊提出Diffusion Loss,擴散模型思想提升生成速度和效果 !
導讀
在圖像生成領域中,作者觀察到向量量化標記并不是自回歸建模的必要條件,并提出通過在連續值域上,操作的擴散過程來對每個標記的概率分布,進行建模。改進后的圖像生成器在生成速度與效果上,都取得了巨大的提升。

傳統觀點認為,用于圖像生成的自回歸模型通常伴隨著向量量化標記。作者觀察到,盡管離散值空間可以促進表示分類分布,但這并非自回歸建模的必要條件。
在這項工作中,作者提出使用擴散過程來建模每個標記的概率分布,這使得作者能夠在連續值空間中應用自回歸模型。作者不是使用分類交叉熵損失,而是定義了一個擴散損失函數來建模每個標記的概率。
這種方法消除了對離散值標記器的需求。作者在廣泛的情況下評估了其有效性,包括標準自回歸模型和廣義 Mask 自回歸(MAR)變體。
通過移除向量量化,作者的圖像生成器在享受序列建模速度優勢的同時,取得了強大的成果。
作者希望這項工作將激發在其他連續值領域和應用中使用自回歸生成的興趣。
論文鏈接:https://arxiv.org/pdf/2406.11838
1 Introduction
自回歸模型目前是自然語言處理中生成模型的實際解決方案。這些模型基于前面的詞作為輸入來預測序列中的下一個詞或標記。由于語言的離散性質,這些模型的輸入和輸出處于分類的、離散值的空間。這種普遍的方法導致人們普遍認為自回歸模型與離散表示固有地聯系在一起。
因此,將自回歸模型推廣到連續值域(尤其是圖像生成)的研究一直集中在數據離散化上[6; 13; 40]。通常采用的策略是訓練一個針對圖像的離散值分詞器,這涉及到通過向量量化(VQ)獲得的有限詞匯[51; 41]。
然后自回歸模型在離散值標記空間上操作,類似于它們的語言對應物。
在這項工作中,作者旨在回答以下問題:“自回歸模型與向量量化表示結合是必要的嗎?”作者注意到自回歸的特性,即“基于前面的標記預測下一個標記”,與值是離散的還是連續的無關。需要的是對每個標記的概率分布進行建模,這可以通過損失函數來衡量,并從中抽取樣本。離散值表示可以通過分類分布方便地建模,但這在概念上并非必要。如果提出每個標記概率分布的其他模型,自回歸模型可以在沒有向量量化的情況下處理。
基于這一觀察,作者提出通過在連續值域上操作的擴散過程來對每個標記的概率分布進行建模。作者的方法論利用了擴散模型[45; 24; 33; 10]的原理來表示任意的概率分布。具體來說,作者的方法自回歸地為每個標記預測一個向量z,該向量作為去噪網絡(如一個小型MLP)的條件。去噪擴散過程使作者能夠表示輸出x的潛在分布p(x|z)(圖1)。這個小型的去噪網絡與自回歸模型一起訓練,以連續值標記作為輸入和目標。從概念上講,這個應用于每個標記的小型預測頭就像一個用于衡量z質量的損失函數。作者將這個損失函數稱為“擴散損失”。

作者的方法消除了對離散值分詞器的需求。向量量化分詞器難以訓練,且對梯度近似策略敏感。它們的重建質量通常比連續值對應物差[42]。作者的方法允許自回歸模型享受高質量、非量化分詞器的優點。
為了擴大范圍,作者進一步將標準的自回歸(AR)模型[13]和 Mask 生成模型[4; 29]統一到一個廣義的自回歸框架中(圖3)。從概念上講, Mask 生成模型以隨機順序同時預測多個輸出標記,同時仍保持基于已知標記預測下一個標記的自回歸性質。這導致了一個可以與擴散損失無縫使用的“ Mask 自回歸”(MAR)模型。
作者通過實驗證明了擴散損失在各種情況下的有效性,包括AR和MAR模型。它消除了對向量量化分詞器的需求,并一致提高了生成質量。作者的損失函數可以靈活地應用于不同類型的分詞器。此外,作者的方法享有序列模型快速速度的優勢。作者的帶擴散損失的MAR模型在ImageNet 256x256上的生成速度小于0.3秒/張圖像,同時達到強大的FID小于2.0。作者最好的模型可以達到1.55 FID。
作者的方法的有效性揭示了一個在很大程度上尚未探索的圖像生成領域:通過自回歸建模標記的“相互依賴”,同時通過擴散對每個標記的分布進行建模。這與典型的潛在擴散模型[42; 37]形成對比,在后者中,擴散過程建模了所有標記的聯合分布。鑒于作者方法的效率、速度和靈活性,作者希望擴散損失能推進自回歸圖像生成,并在未來的研究中推廣到其他領域。
2 Related Work
圖像生成的序列模型。?在自回歸圖像模型方面的開創性工作是在像素序列上進行的。自回歸可以通過RNNs [50]、CNNs [49; 7] 來實現,最近最流行的是Transformers [36; 6]。受到語言模型的啟發,另一系列工作 [51; 41; 13; 40] 將圖像建模為離散值標記。自回歸 [13; 40] 和 Mask 生成模型 [4; 29] 可以在離散值標記空間上操作。但是離散標記器難以訓練,這最近引起了特別的關注 [27; 54; 32]。
與作者的工作相關的是,最近關于GIVT [48] 的工作也專注于序列模型中的連續值標記。GIVT 和作者的工作都揭示了這一方向的重要性和潛力。在GIVT中,標記分布由高斯混合模型表示。它使用預定義的混合數量,這可能限制了它可以表示的分布類型。相比之下,作者的方法利用擴散過程在建模任意分布方面的有效性。
表示學習的擴散過程。?去噪擴散過程已經被探索作為視覺自監督學習的準則。例如,DiffMAE [53] 用去噪擴散解碼器替換了原始 MAE [21] 中的 L2 損失;DARL [30] 使用去噪擴散塊解碼器訓練自回歸模型。這些努力主要集中在表示學習上,而不是圖像生成。在它們的場景中,生成?多樣化?的圖像并非目標;這些方法尚未展示從零開始生成新圖像的能力。策略學習的擴散。作者的工作與機器人領域的擴散策略 [8] 在概念上是相關的。在這些場景中,_采取行動_ 的分布被制定為機器人觀察到的去噪過程,可以是像素或潛在表示 [8; 34]。在圖像生成中,作者可以將生成一個標記視為“行動”。盡管存在這種概念上的聯系,但在機器人領域生成的樣本多樣性不如圖像生成核心考量。
注意:公式部分按照您的要求保持原始輸出,未翻譯。
3 Method
總之,作者的圖像生成方法是在標記化的潛在空間上操作的序列模型[6; 13; 40]。但與以往基于向量量化標記器的方法(例如,VQ-VAE的變體[51; 13])不同,作者旨在使用連續值標記器(例如,[42])。作者提出了擴散損失,這使得序列模型能夠與連續值標記兼容。
3.1 Rethinking Discrete-Valued Tokens

這種分析表明,離散值標記對自回歸模型來說_并非_必要。相反,建模一個分布是本質上的要求。離散值標記空間意味著一個分類分布,其損失函數和采樣器容易定義。作者實際上需要的是用于分布建模的損失函數及其相應的采樣器。
3.2 Diffusion Loss
去噪擴散模型[24]為建模任意分布提供了一個有效的框架。但與將擴散模型用于表示所有像素或所有 Token 的聯合分布的常見用法不同,在作者的案例中,擴散模型用于表示每個 Token 的分布。


3.3 Diffusion Loss for Autoregressive Models

3.4 Unifying Autoregressive and Masked Generative Models
作者展示了諸如MaskGIT [4]和MAGE?[29]之類的 Mask 生成模型可以在自回歸的廣泛概念下進行泛化,即下一個標記的預測。
雙向注意力可以執行自回歸。自回歸的概念與網絡架構正交:自回歸可以通過RNNs [50]、CNNs [49; 7]和Transformers [38; 36; 6]來完成。當使用Transformers時,盡管自回歸模型通常通過_因果_注意力來實現,但作者展示了它們也可以通過_雙向_注意力來完成。請見圖2。需要注意的是,自回歸的目標是給定前一個標記后_預測下一個標記_;它并不限制前一個標記如何與下一個標記進行通信。
作者可以采用如Masked Autoencoder (MAE) [21]中所示的雙向注意力實現。見圖2(b)。具體來說,作者首先在已知標記上應用MAE風格的編碼器1(帶有位置嵌入[52])。然后作者將編碼后的序列與 Mask 標記(再次加上位置嵌入)連接起來,并用MAE風格的解碼器映射這個序列。Mask 標記上的位置嵌入可以讓解碼器知道需要預測哪些位置。與因果注意力不同,這里的損失只在未知標記上計算[21]。利用MAE風格的技巧,作者允許_所有_已知標記相互看見,也允許所有未知標記看見所有已知標記。這種_全注意力_比因果注意力在標記之間的通信引入了更好的效果。在推理時,作者可以使用這種雙向公式生成標記(每步一個或多個),這是一種自回歸形式。作為一種妥協,作者無法使用因果注意力的鍵值(kv)緩存[44]來加速推理。但正如作者可以同時生成多個標記,作者可以減少生成步驟以加速推理。標記之間的全注意力可以顯著提高質量,并提供更好的速度/精度權衡。
隨機順序的自回歸模型。為了與 Mask 生成模型[4, 29]相聯系,作者考慮了一種隨機順序下的自回歸變體。模型接收到一個隨機排列的序列。這種隨機排列對于每個樣本都是不同的。見圖3(b)。在這種情況下,下一個待預測標記的位置需要模型能夠訪問。作者采用了與MAE[21]類似的策略:作者在解碼層中添加位置嵌入(與未Shuffle的位置相對應),這可以告訴模型預測哪些位置。這種策略適用于因果和雙向版本。
如圖3(b)(c)所示,隨機順序自回歸的行為像是一種特殊的 Mask 生成形式,一次生成一個標記。作者以下進行詳細闡述。

3.5 Diffusion Loss

3.6 Autoregressive and Masked Autoregressive Image Generation
分詞器。作者使用了LDM [42]提供的公開分詞器。作者的實驗將涉及它們的VQ-16和KL-16版本[42]。VQ-16是一個VQ-GAN[13],即帶有GAN損失[15]和感知損失[56]的VQ-VAE[51];KL-16是它的對應版本,通過Kullback-Leibler(KL)散度進行正則化,不進行向量量化。16表示分詞器的步長。
Transformer。作者的架構遵循ViT[11]中的Transformer[52]實現。給定一個來自分詞器的標記序列,作者添加位置嵌入[52]并在序列開頭附加類別標記[cls];然后通過Transformer處理該序列。默認情況下,作者的Transformer有32個塊和1024的寬度,作者稱之為大型(-L)(約400M個參數)。
**自回歸 Baseline **。因果注意力遵循GPT[38]的常見實踐(圖2(a))。輸入序列通過一個標記(此處為[cls])進行移位。三角 Mask [52]應用于注意力矩陣。在推理時,應用溫度(τ)采樣。作者使用kv-cache[44]進行高效推理。
** Mask 自回歸模型**。使用雙向注意力(圖2(b)),作者可以根據任意數量的已知標記預測任意數量的未知標記。在訓練時,作者在[0.7, 1.0]范圍內隨機采樣 Mask 比例[21, 4, 29]:例如,0.7意味著70%的標記是未知的。由于采樣的序列可能非常短,作者在編碼器序列的開始處始終填充64個[cls]標記,這提高了作者編碼的穩定性和容量。如圖2所示,在解碼器中引入 Mask 標記[m],并添加位置嵌入。為了簡單起見,與[21]不同,作者讓編碼器和解碼器具有相同的尺寸:每個都有所有塊的一半(例如,在MAR-L中為16)。
在推理時,MAR執行“下一組標記預測”。它按照余弦計劃逐步將 Mask 比例從1.0減少到0[4, 29]。默認情況下,作者在該計劃中使用64步。應用溫度(τ)采樣。與[4, 29]不同,MAR始終使用完全隨機順序。
4 Experiments
作者在ImageNet [9] 數據集上進行了實驗,分辨率為256×256。作者評估了FID [22] 和IS [43],并根據常見做法[10]提供了精確度和召回率作為參考。作者遵循了[10]提供的評估套件。
4.1 Properties of Diffusion Loss
擴散損失與交叉熵損失的比較。作者首先比較了使用擴散損失的連續值標記與使用交叉熵損失的標準離散值標記(表1)。為了公平比較,兩個分詞器("VQ-16" 和 "KL-16")均從LDM代碼庫[42]下載。這些分詞器被廣泛使用(例如[13, 42, 37])。
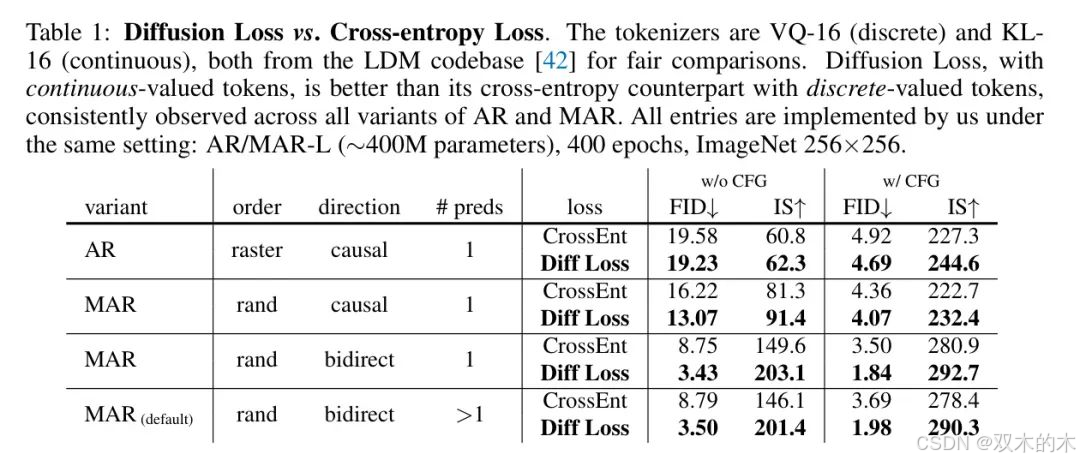
比較在AR/MAR的四種變體中進行。如表1所示,在所有情況下,擴散損失一致優于交叉熵損失。特別是,在MAR中(例如,默認設置),使用擴散損失可以相對減少約50%-60%的FID。這是因為連續值的KL-16比VQ-16(下面表2中討論)具有更小的壓縮損失,也因為擴散過程比分類過程更有效地建模分布。
在以下消融研究中,除非另有指定,作者遵循表1中“默認”MAR設置。
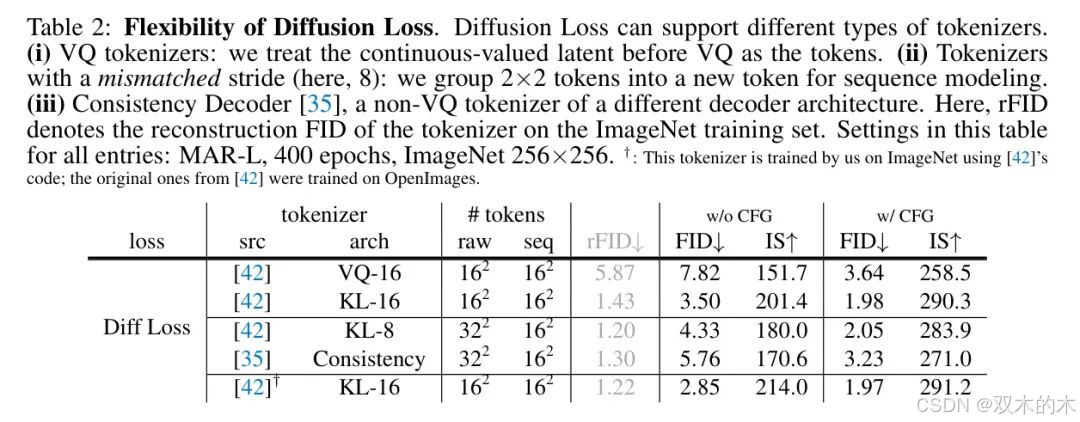
擴散損失的靈活性。擴散損失的一個顯著優勢是它適用于各種分詞器。作者在表2中比較了幾個公開可用的分詞器。
即使給定VQ分詞器,擴散損失也可以輕松使用。作者簡單地將VQ層之前的連續值潛在標記視為標記。這個變體使作者得到了7.82 FID(無CFG),與使用相同VQ分詞器的交叉熵損失的8.79 FID(表1)相比,表現良好。這表明擴散在建模分布方面具有更好的能力。
這個變體還使作者能夠在使用相同損失的情況下比較VQ-16和KL-16分詞器。如表2所示,VQ-16的重建FID(rFID)比KL-16差得多,這也導致了生成FID(例如,表2中的7.82 vs 3.50)差得多。
有趣的是,擴散損失還使作者能夠使用步長不匹配的分詞器。在表2中,作者研究了一個步長為8,輸出序列長度為32×32的KL-8分詞器。在沒有增加生成器序列長度的情況下,作者將2×2標記組合成一個新的標記。盡管步長不匹配,作者仍然能夠獲得不錯的結果,例如,KL-8給作者帶來了2.05 FID,而KL-16是1.98 FID。此外,這個特性允許作者研究其他分詞器,例如一致性解碼器[35],這是一種不同架構/步長的非VQ分詞器,專為不同目標設計。
為了全面性,作者還使用[42]的代碼在ImageNet上訓練了一個KL-16分詞器,注意到[42]中的原始KL-16是在OpenImages[28]上訓練的。比較在表2的最后一行。作者將在以下探索中使用這個分詞器。
擴散損失中的去噪MLP。作者在表3中研究了去噪MLP。即使是非常小的MLP(例如,2M)也能帶來有競爭力的結果。如預期的那樣,增加MLP的寬度有助于提高生成質量;作者還探索了增加深度并觀察到類似情況。請注意,作者的默認MLP大小(1024寬度,21M)僅為MAR-L模型增加了約5%的額外參數。在推理期間,擴散采樣器的整體運行時間成本適中,約為10%。在作者的實現中,增加MLP寬度幾乎沒有額外成本(表3),部分原因是因為主要開銷不是關于計算而是內存通信。
擴散損失的采樣步驟。作者的擴散過程遵循DDPM[24, 10]的常見做法:作者使用1000步噪聲計劃進行訓練,但使用更少的步驟進行推理。圖4顯示,在推理時使用100個擴散步驟就足以實現強烈的生成質量。
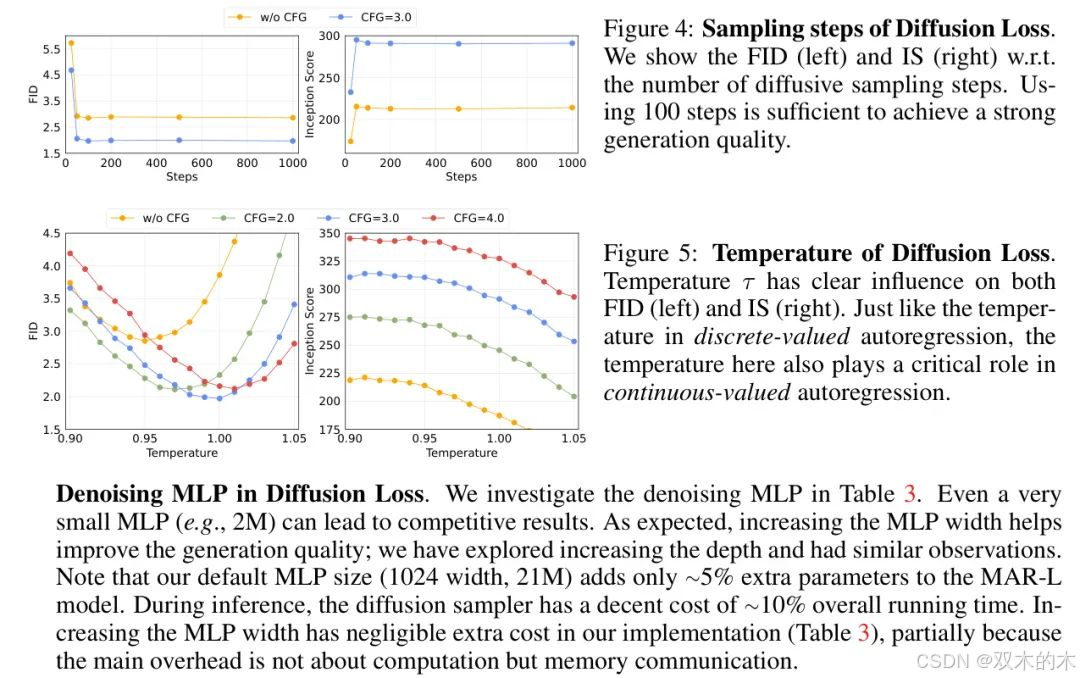
擴散損失的溫度。在交叉熵損失的情況下,溫度至關重要。擴散損失也為控制多樣性和保真度提供了一個溫度對應項。圖5顯示了推理時擴散采樣器中溫度τ的影響(見第3.2節)。溫度τ在作者的模型中發揮著重要作用,與基于交叉熵的對應項的觀察類似(注意表1中的交叉熵結果是它們最優溫度下的結果)。
4.2 Properties of Generalized Autoregressive Models
從AR到MAR。表1也是對AR/MAR變體的比較,作者接下來討論。首先,將AR中的光柵順序替換為_隨機_順序可以帶來顯著的增益,例如,在沒有CFG的情況下將FID從19.23降低到13.07。接下來,用雙向注意力替換因果注意力會導致另一個巨大的增益,例如,在沒有CFG的情況下將FID從13.07降低到3.43。
隨機順序、雙向的AR本質上是一種MAR形式,一次預測一個標記。在每一步預測_多個_標記('>1')可以有效地減少自回歸步驟的數量。在表1中,作者展示了進行64步的MAR變體略微犧牲了生成質量。接下來將討論更全面的權衡比較。
速度/精度權衡。遵循MaskGIT [4],作者的MAR具有一次預測多個標記的靈活性。這由推理時的自回歸步驟數量控制。圖6繪制了速度/精度權衡。與具有高效kv-cache的AR相比,MAR具有更好的權衡。
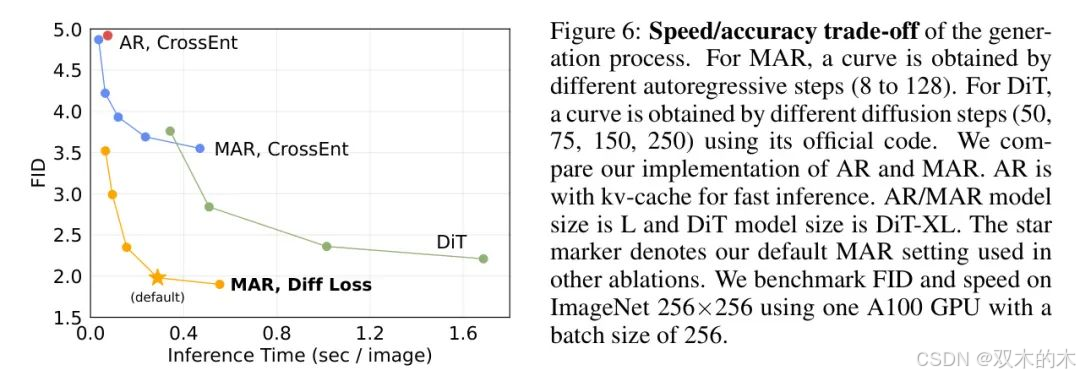
在擴散損失下,與近期流行的Diffusion Transformer (DiT) [37]相比,MAR也顯示出有利的權衡。作為一種潛在擴散模型,DiT通過擴散過程建模_所有_標記之間的相互依賴。DiT的速度/精度權衡主要由其擴散步驟控制。與作者對小型MLP的擴散過程不同,DiT的擴散過程涉及_整個_Transformer架構。作者的方法更準確且更快。值得注意的是,作者的方法可以在強FID(<2.0)下以每張圖像小于0.3秒的速度生成。
4.3 Benchmarking with Previous Systems
作者在表4中與最先進的系統進行了比較。作者探索了各種模型大小(見附錄B),并訓練了800個周期。類似于自回歸語言模型[3],作者觀察到了鼓舞人心的縮放行為。進一步研究縮放可能是有希望的。在指標方面,作者在沒有CFG的情況下報告了2.35的FID,大大優于其他基于標記的方法。作者最佳的成績是1.55的FID,并且與最先進的系統相比表現良好。圖7展示了定性結果。


5 Discussion and Conclusion
在各種自回歸模型上,擴散損失的有效性提出了新的可能性:通過自回歸建模標記之間的相互依賴,同時通過擴散建模每個標記的分布。這與常見的通過擴散建模所有標記的聯合分布的做法不同。
作者在圖像生成方面的強大結果表明,自回歸模型或其擴展是超越語言建模的強大工具。
這些模型不必受限于向量量化表示。
作者希望作者的工作將激勵研究界在其他領域探索具有連續值表示的序列模型。
6 參考
[1].Autoregressive Image Generation without Vector Quantization.
THE END !
文章結束,感謝閱讀。您的點贊,收藏,評論是我繼續更新的動力。大家有推薦的公眾號可以評論區留言,共同學習,一起進步。


)

pem, der, crt, cer, key等各類證書與密鑰文件后綴解析)










電路設計)



