目錄
10.3.4 Spark運行原理
?1.設計背景
?2.RDD概念
?3.RDD特性
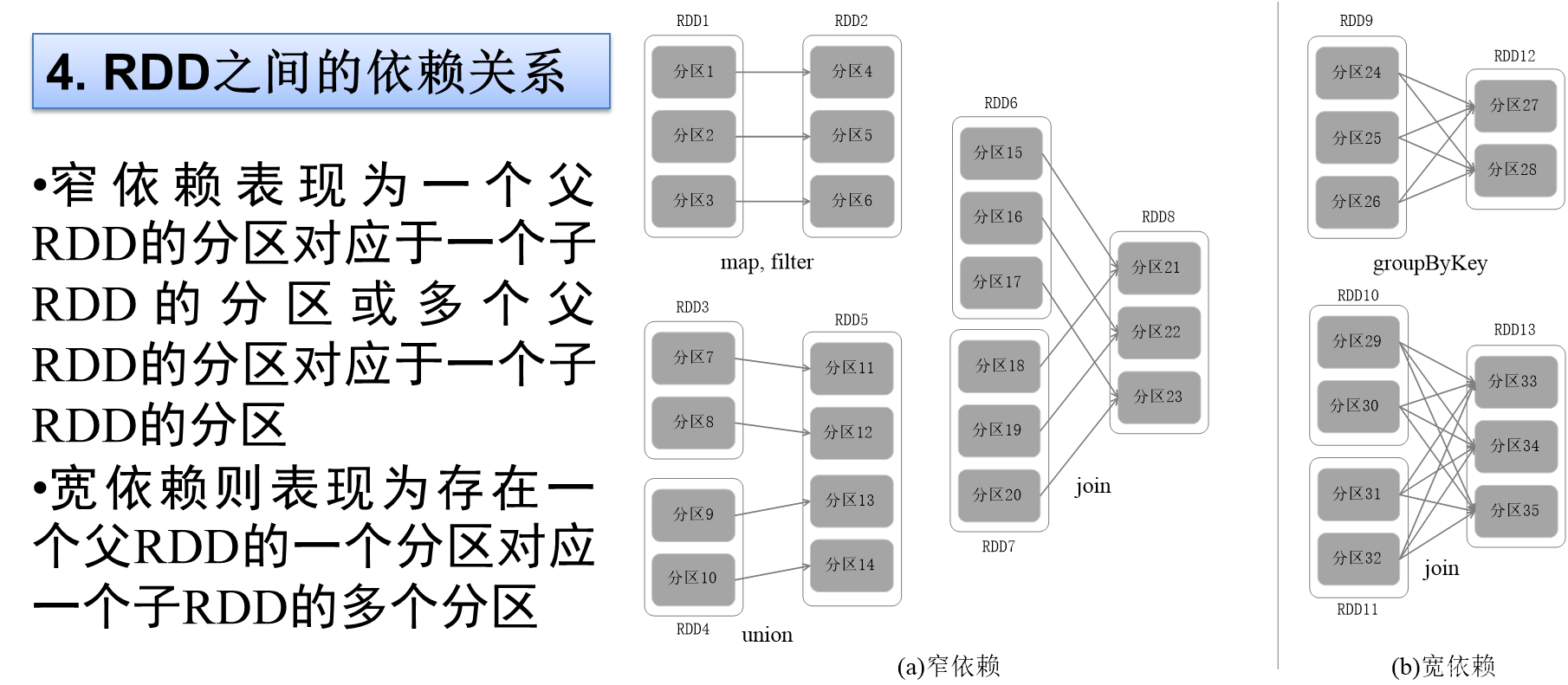
?4.RDD之間的依賴關系
?窄依賴和寬依賴
5.Stage的劃分
?Stage的類型包括兩種:ShuffleMapStage和ResultStage
?6.RDD運行過程
10.3.4 Spark運行原理
?1.設計背景
RDD就是為了滿足這種需求而出現的,它提供了一個抽象的數據架構,我們不必擔心底層數據的分布式特性,只需將具體的應用邏輯表達為一系列轉換處理,不同RDD之間的轉換操作形成依賴關系,可以實現管道化,避免中間數據存儲,大大降低了數據復制、磁盤IO和序列化開銷。
?2.RDD概念
一個RDD就是一個分布式對象集合,本質上是一個只讀的分區記錄集合,每個RDD可分成多個分區,每個分區就是一個數據集片段,并且一個RDD的不同分區可以被保存到集群中不同的節點上,從而可以在集群中的不同節點上進行并行計算
RDD提供了一種高度受限的共享內存模型,即RDD是只讀的記錄分區的集合,不能直接修改,只能基于穩定的物理存儲中的數據集創建RDD,或者通過在其他RDD上執行確定的轉換操作(如map、join和group by)而創建得到新的RDD
RDD采用了惰性調用:RDD的執行過程中,真正的計算發生在RDD的“行動”操作,對于行動之前的所有“轉換”操作,Spark只是會記錄下“轉換”操作應用的一些基礎數據集以及RDD生成的軌跡,即相互依賴關系,而不會觸發真正的計算。
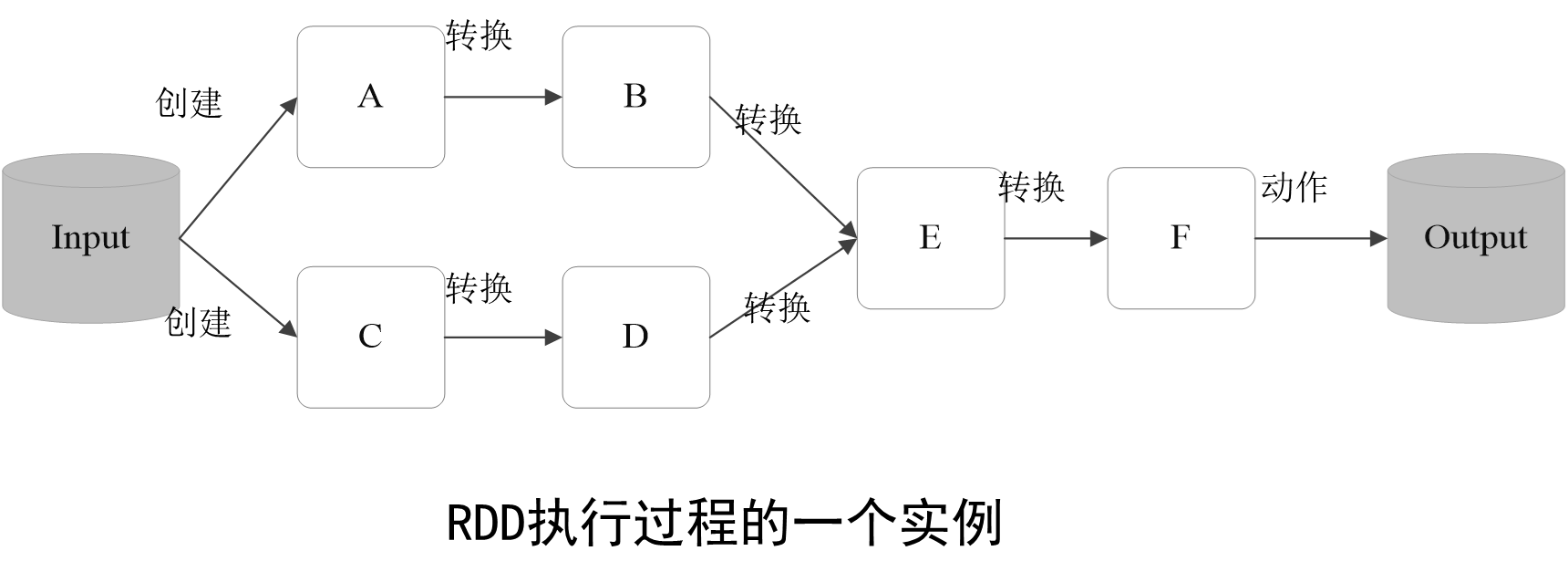
上述這一系列處理稱為一個“血緣關系(Lineage)”,即DAG拓撲排序的結果。采用惰性調用,通過血緣關系連接起來的一系列RDD操作就可以實現管道化(pipeline),避免了多次轉換操作之間數據同步的等待,而且不用擔心有過多的中間數據,因為這些具有血緣關系的操作都管道化了,一個操作得到的結果不需要保存為中間數據,而是直接管道式地流入到下一個操作進行處理。
同時,這種通過血緣關系把一系列操作進行管道化連接的設計方式,也使得管道中每次操作的計算變得相對簡單,保證了每個操作在處理邏輯上的單一性;相反,在MapReduce的設計中,為了盡可能地減少MapReduce過程,在單個MapReduce中會寫入過多復雜的邏輯。
一個Spark的“Hello World”程序:以一個“Hello World”入門級Spark程序來解釋RDD執行過程,這個程序的功能是讀取一個HDFS文件,計算出包含字符串“Hello World”的行數。





3.RDD特性
Spark采用RDD以后能夠實現高效計算的原因主要在于:
(1)高效的容錯性
現有容錯機制:數據復制或者記錄日志
RDD:血緣關系、重新計算丟失分區、無需回滾系統、重算過程在不同節點之間并行、只記錄粗粒度的操作
(2)中間結果持久化到內存,數據在內存中的多個RDD操作之間進行傳遞,避免了不必要的讀寫磁盤開銷
(3)存放的數據可以是Java對象,避免了不必要的對象序列化和反序列化
?4.RDD之間的依賴關系
RDD不同操作,會使得RDD分區之間產生不同的依賴關系,DAG調度器根據RDD之間的依賴關系,把DAG劃分為若干個階段,依賴關系分為窄依賴和寬依賴,二者主要區別:是否包含Shuffle操作。
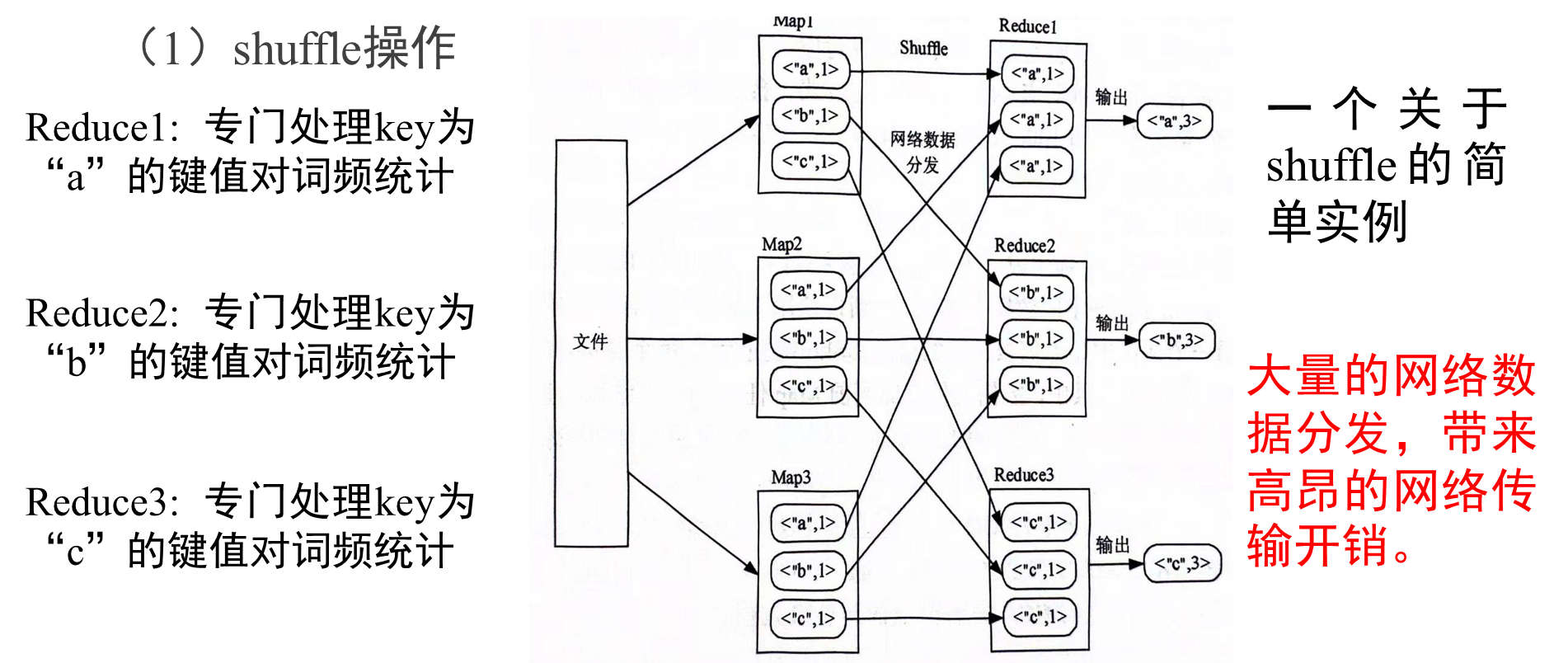
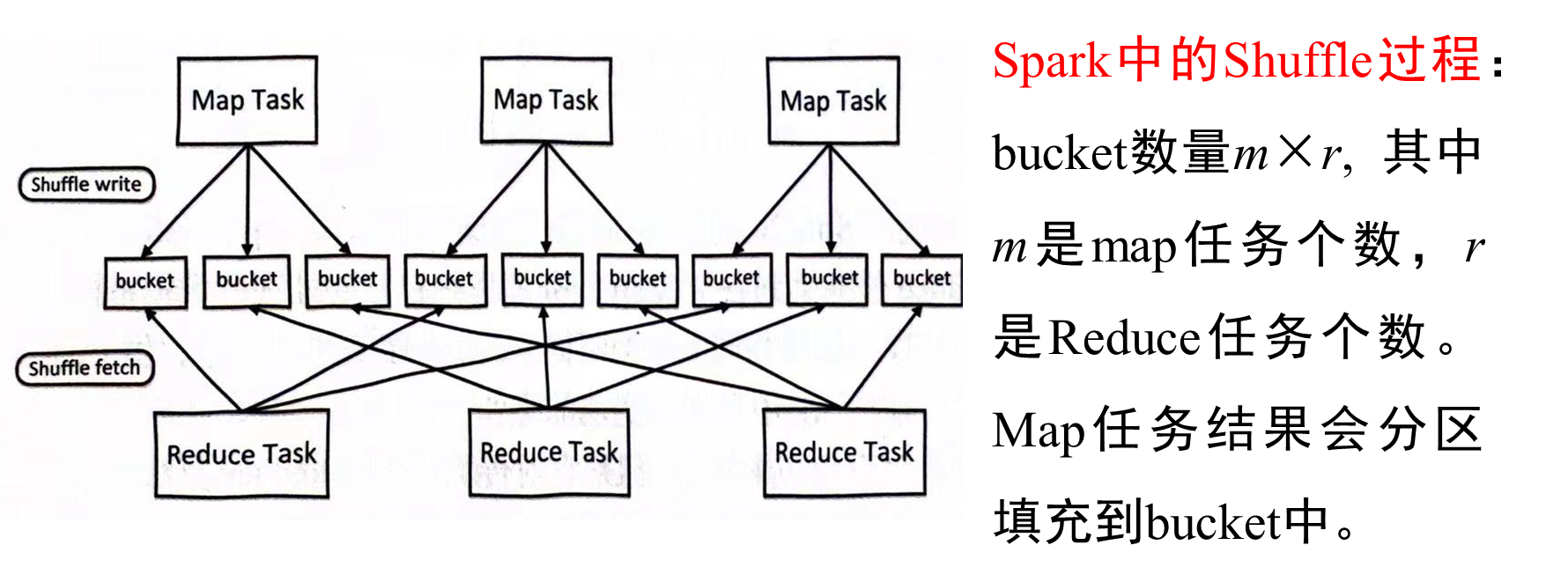
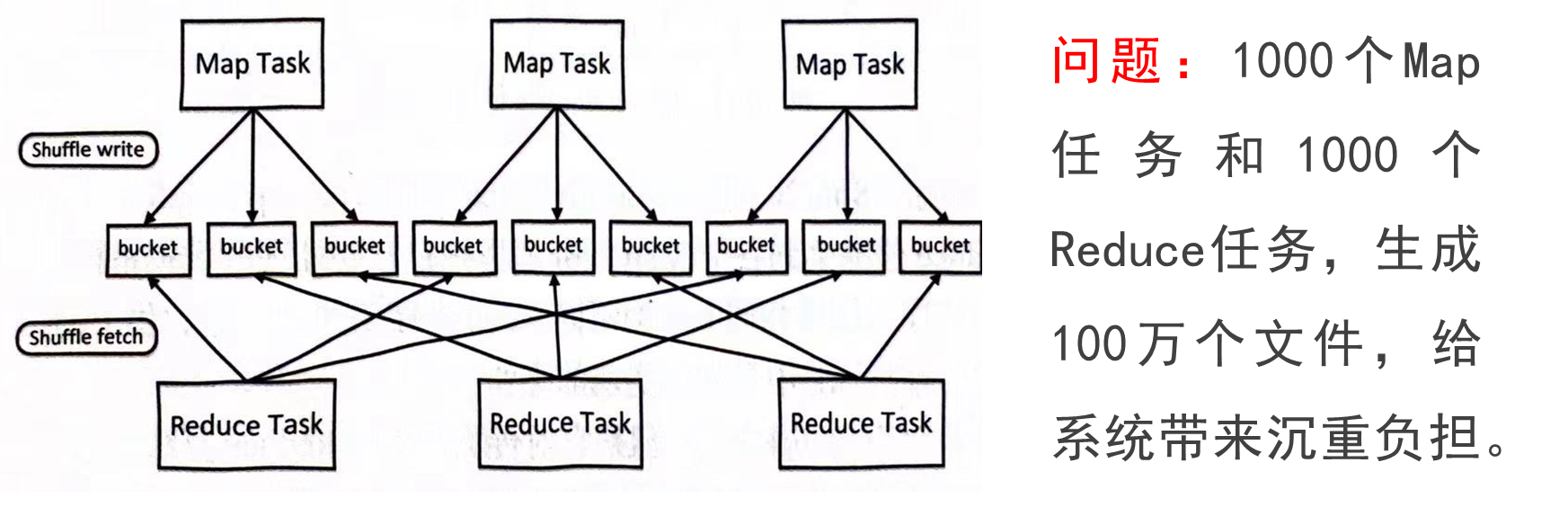
窄依賴和寬依賴
5.Stage的劃分
Spark通過分析各個RDD的依賴關系生成了DAG,再通過分析各個RDD中的分區之間的依賴關系來決定如何劃分Stage,具體劃分方法是:
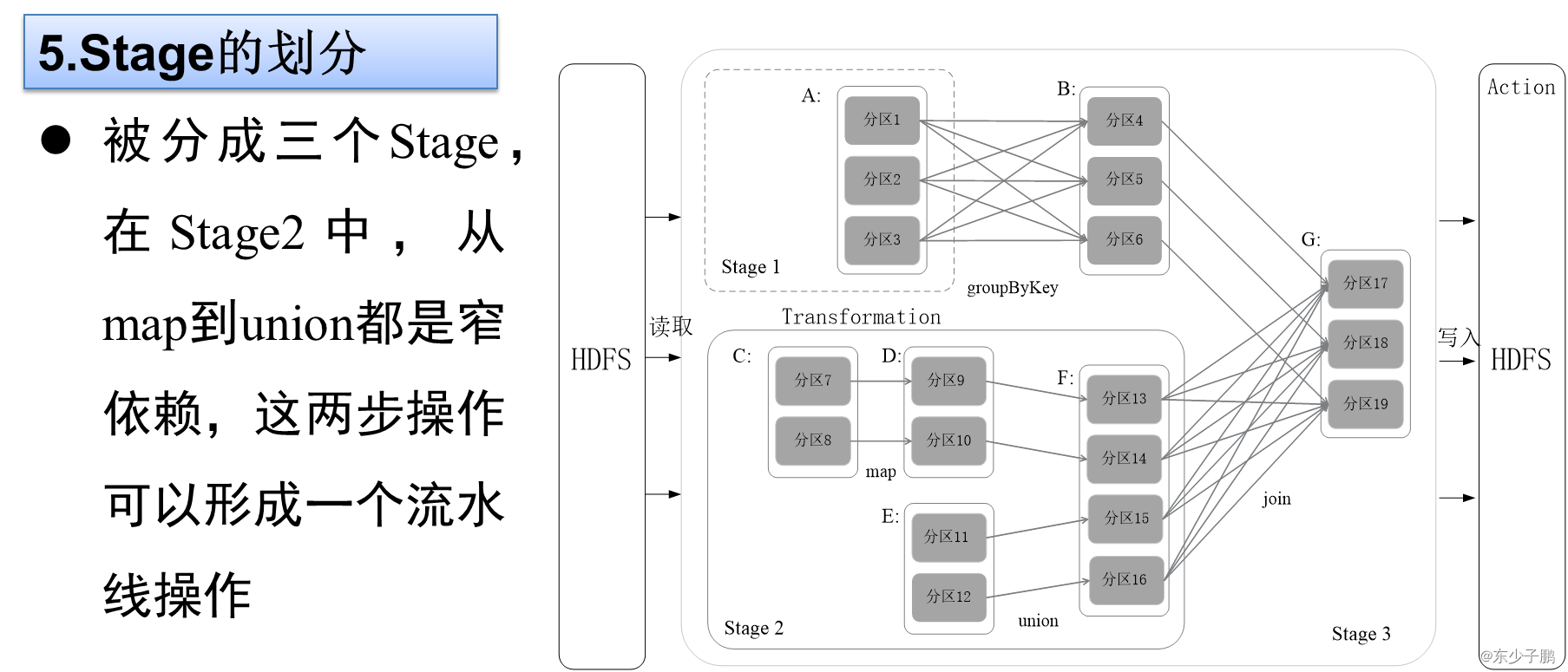
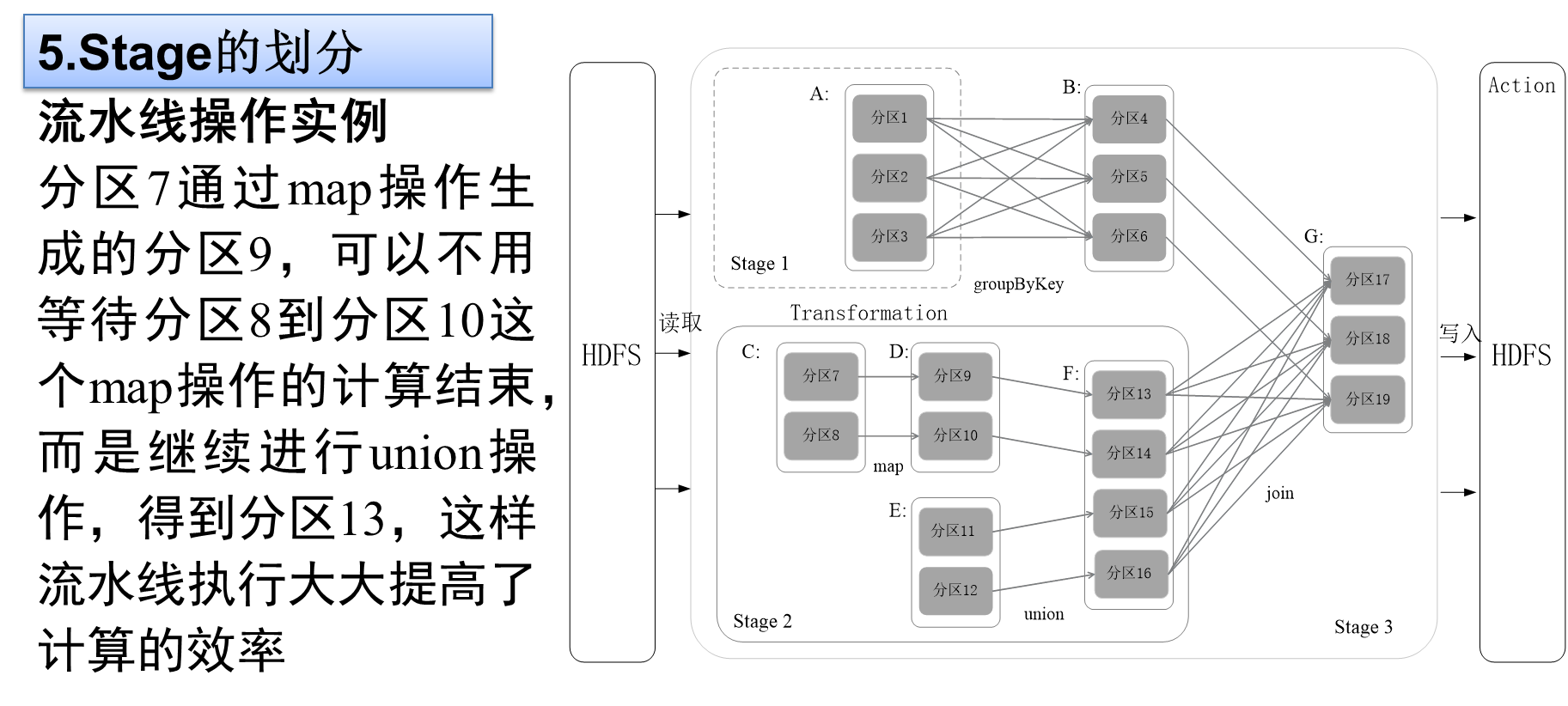
?Stage的類型包括兩種:ShuffleMapStage和ResultStage
(2)ResultStage:最終的Stage,沒有輸出,而是直接產生結果或存儲。這種Stage是直接輸出結果,其輸入邊界可以是從外部獲取數據,也可以是另一個ShuffleMapStage的輸出。在一個Job里必定有該類型Stage。
因此,一個Job含有一個或多個Stage,其中至少含有一個ResultStage。
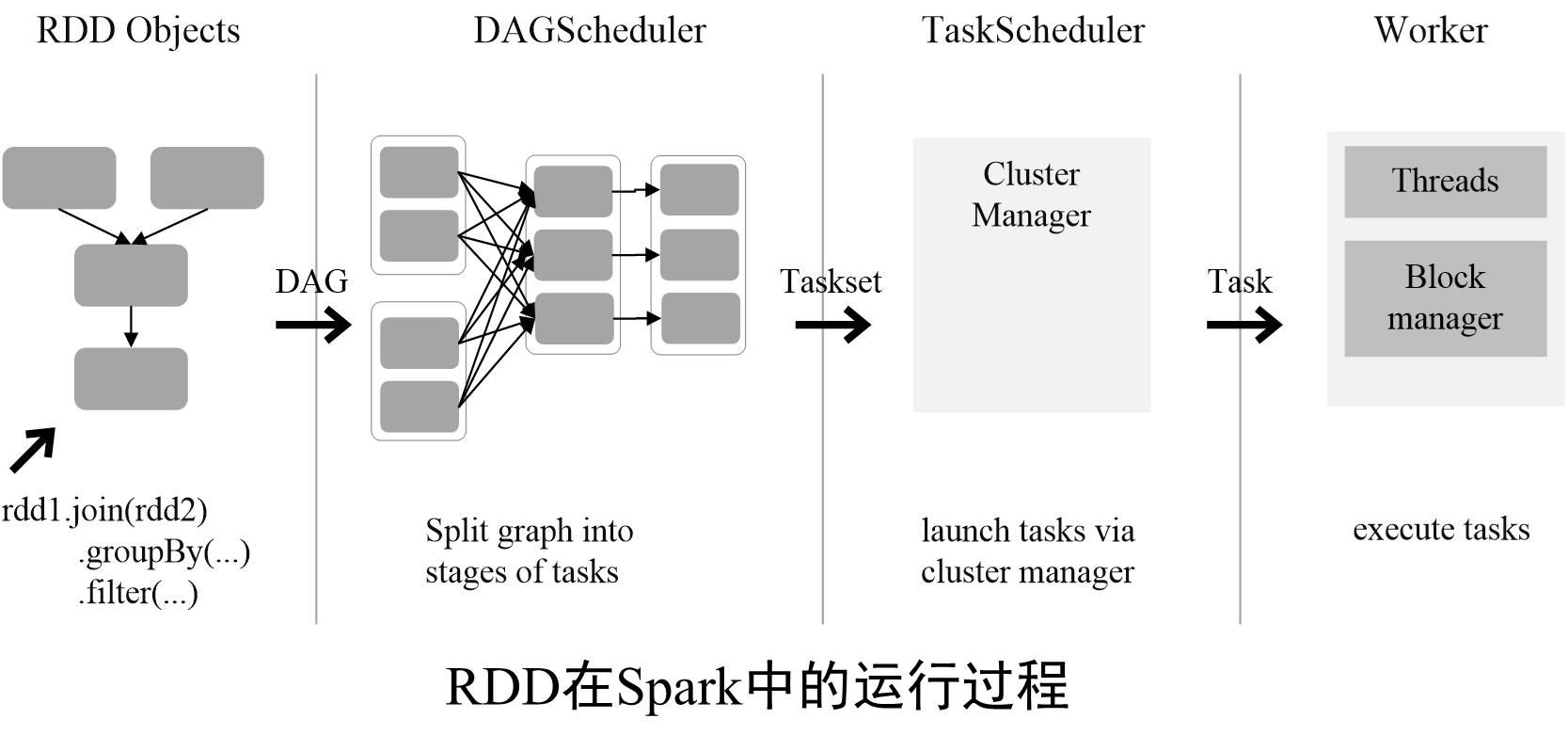
?6.RDD運行過程
通過上述對RDD概念、依賴關系和Stage劃分的介紹,結合之前介紹的Spark運行基本流程,再總結一下RDD在Spark架構中的運行過程:
(1)創建RDD對象;
(2)SparkContext負責計算RDD之間的依賴關系,構建DAG;
(3)DAGScheduler負責把DAG圖分解成多個Stage,每個Stage中包含了多個Task,每個Task會被TaskScheduler分發給各個WorkerNode上的Executor去執行。









電路設計)









