Spark中常見的兩種數據傾斜現象如下
- stage部分task執行特別慢

一般情況下是某個task處理的數據量遠大于其他task處理的數據量,當然也不排除是程序代碼沒有冗余,異常數據導致程序運行異常。
- 作業重試多次某幾個task總會失敗

常見的退出碼143、53、137、52以及heartbeat timed out異常,通常可認為是executor內存被打滿。
RDD調優方法
- 查看數據分布
Spark Core中shuffle算子出現數據傾斜時,可在Spark作業中加入查看key分布的代碼,也可以將代碼拆解出來使用spark-shell做測試
val rdd = sc.parallelize(Array("hello", "hello", "hello", "hi")).map((_,1))// 數據量較少
rdd.reduceByKey(_ + _)
.sortBy(_._2, false)
.take(20)
// 數據量較大, 用sample采樣后在統計
rdd.sample(false, 0.1)
.reduceByKey(_+_)
.sortBy(_._2, false)
.take(20)
- 調整shuffle并行度
原理:Spark在做shuffle時,默認使用HashPartitioner(非Hash Shuffle)對數據進行分區。如果并行度設置的不合適如比較小,可能造成大量不相同的key對應的數據被分配到了同一個task上,造成該task所處理的數據遠大于其它task,從而造成數據傾斜
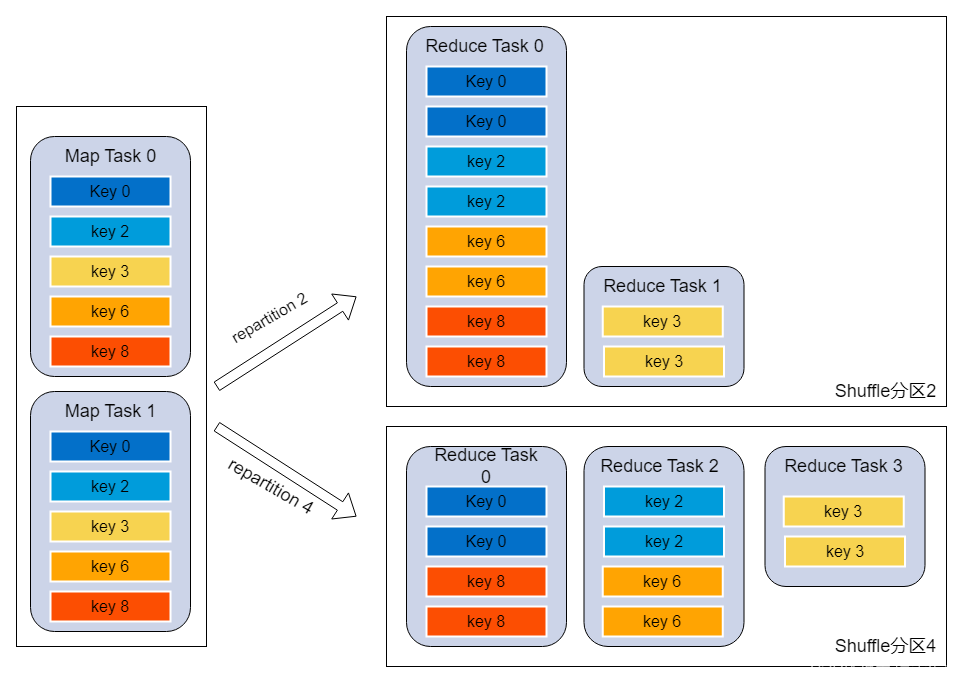
調優建議:
- 使用spark.default.parallelism調整分區數,默認值200建議500或更大
- 在shuffle的算子上直接設置分區數,如:a.join(b, 500)、rdd.reduceByKey(_ + _, 500)
- reduce join轉map join
原理:不使用join算子直接進行連接操作,而使用broadcast變量與map類算子實現join操作,進而完全規避掉shuffle類的操作,徹底避免數據傾斜的出現
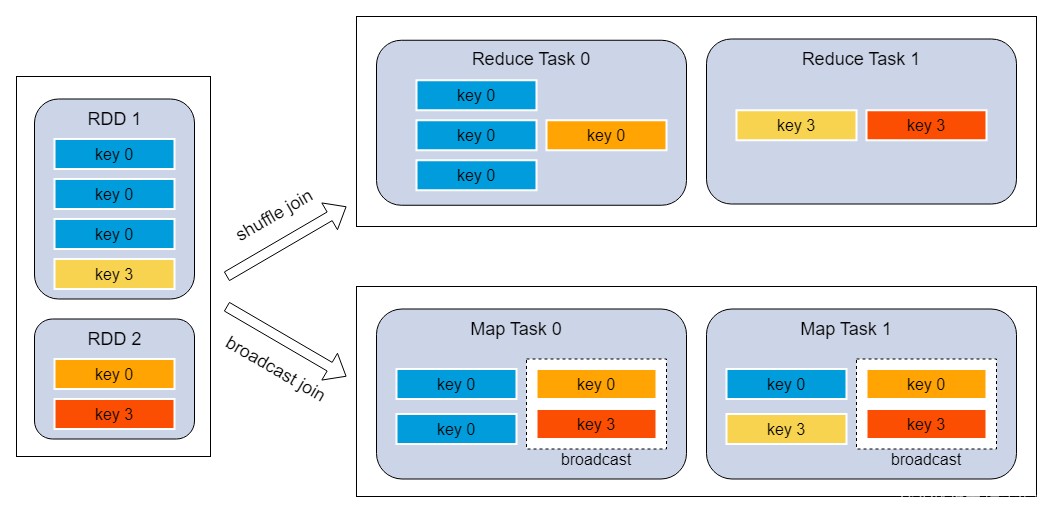
調優建議:
- broadcast的數據量不要超過500M, 過大driver/executor可能會oom
// 1.broadcast小表
val rdd1Broadcast = sc.broadcast(rdd1.collect())
// 2.map join
rdd2.map { x =>val rdd1DataMap = rdd1Broadcast.value.toMaprdd1DataMap.get(x._1) match {case Some(v) => (x._1, (x._2, v))case None => (x._1, (x._2, null))}
}
// 2.或者直接
rdd2.join(rdd1Broadcast)
- 分拆join在union
原理:將有數據傾斜的RDD1中傾斜key對應的數據集單獨抽取出來加鹽(隨機前綴),另外一個RDD2每條數據分別與所有的隨機前綴結合形成新的RDD(相當于將其數據增到到原來的N倍,N即為隨機前綴的總個數),然后將二者join之后去掉前綴;然后將不包含傾斜key的剩余數據進行join;最后將兩次join的結果集通過union合并,即可得到全部join結果。
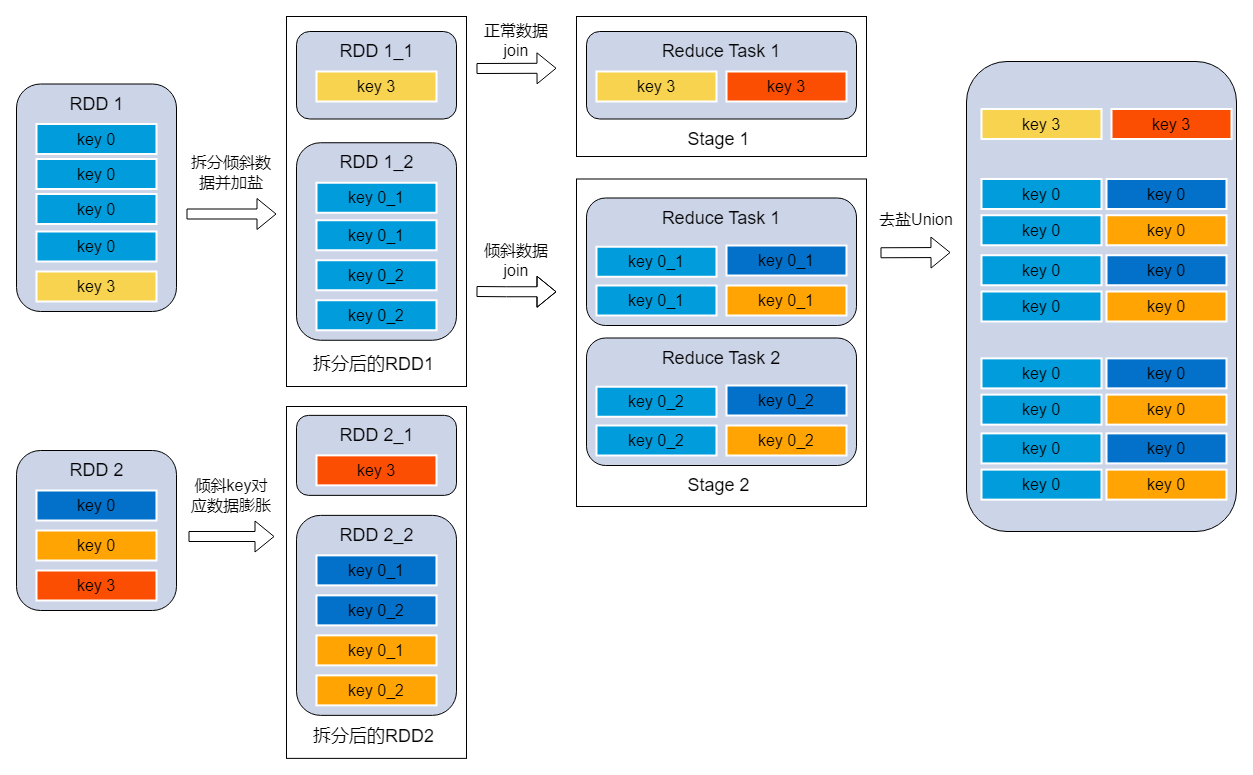
調優建議:
// 1.統計數量最大的key
val skewedKeySet = rdd1.sample(false, 0.2).reduceByKey(_ + _).sortBy(_._2, false).take(10).map(x => x._1).toSet// 2.拆分異常的rdd, 傾斜key加上隨機數
val rdd1_1 = rdd1.filter(x => skewedKeySet.contains(x._1)).map { x =>val prefix = scala.util.Random.nextInt(10).toString(s"${prefix}_${x._1}", x._2)
}
val rdd1_2 = rdd1.filter(x => !skewedKeySet.contains(x._1))// 3.正常rdd存在傾斜key的部分進行膨脹
val rdd2_1 = rdd2.filter(x => skewedKeySet.contains(x._1)).flatMap { x =>val list = 0 until 10list.map(i => (s"${i}_${x._1}", x._2))}val rdd2_2 = rdd2.filter(x => !skewedKeySet.contains(x._1))// 4.傾斜key的rdd進行join
val skewedRDD = rdd1_1.join(rdd2_1).map(x => (x._1.split("_")(1), x._2))
// 5.普通key的rdd進行join
val sampleRDD = rdd1_2.join(rdd2_2)
// 6.結果union
skewedRDD.union(sampleRDD)
SQL調優方法
- 查看數據分布
統計某個查詢結果或表中出現次數超過200次的key
WITH a AS (${query})
SELECT k,s
FROM (SELECT ${key} AS k,count(*) AS sFROM aGROUP BY ${key}
)
WHERE s > 200
- 自動調整shuffle并行度
原理:自適應執行開啟的前提下(AQE),假設我們設置的shuffle partition個數為5,在map stage結束之后,我們知道每一個partition的大小分別是70MB,30MB,20MB,10MB和50MB。假設我們設置每一個reducer處理的目標數據量是64MB,那么在運行時,我們可以實際使用3個reducer。第一個reducer處理partition 0 (70MB),第二個reducer處理連續的partition 1 到3,共60MB,第三個reducer處理partition 4 (50MB)
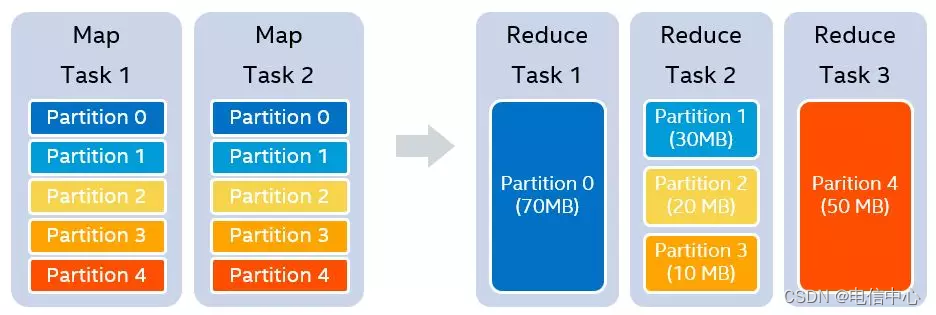
Spark參數:
| 參數 | 說明 | 推薦值 |
|---|---|---|
| spark.sql.adaptive.enabled | 開啟自適應執行 | 線上默認值true |
| spark.sql.adaptive.coalescePartitions.minPartitionNum | 自適應執行中使用的最小shuffle后分區數,默認值executor*core數 | 無 |
| spark.sql.adaptive.coalescePartitions.initialPartitionNum | 合并前的初始shuffle分區數量,默認值spark.sql.shuffle.partitions | 無 |
| spark.sql.adaptive.advisoryPartitionSizeInBytes | 合并小分區到建議的目標值, 默認256m | 無 |
| spark.sql.shuffle.partitions | join等操作分區數,默認值200 | 推薦500或更大 |
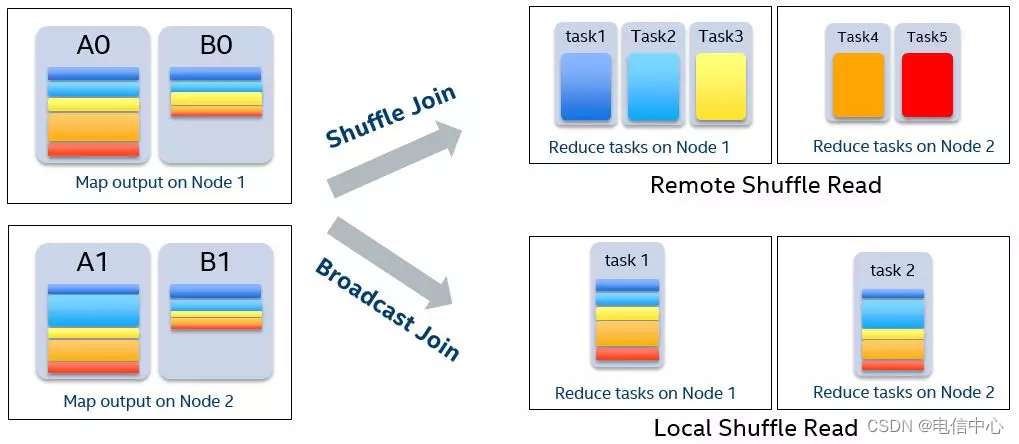
- 自動優化Join
原理:自適應執行開啟的前提下(AQE),我們可以獲得SortMergeJoin兩個子stage的數據量,在滿足條件的情況下,即一張表小于broadcast閾值,可以將SortMergeJoin轉化成BroadcastHashJoin
| 參數 | 說明 | 推薦值 |
|---|---|---|
| spark.sql.adaptive.enabled | 開啟自適應執行 | 線上默認值true |
| spark.sql.autoBroadcastJoinThreshold | 默認10M,設置為-1可以禁用廣播;實際根據hive表存儲的統計信息或文件預估大小與此值做判斷看是否做broadcast,由于文件是壓縮格式一般情況下此參數并不可靠 | 建議膨脹系數spark.sql.sources.fileCompressionFactor=10推薦此參數保持默認,調整自適應的broadcast參數 |
| spark.sql.adaptive.autoBroadcastJoinThreshold | 此參數僅影響自適應執行階段join優化時broadcast閾值;設置為-1可以禁用廣播;默認值spark.sql.autoBroadcastJoinThreshold | 自適應執行得到的數據比較準確,driver內存足夠的前提下可以將此值調大如200M |
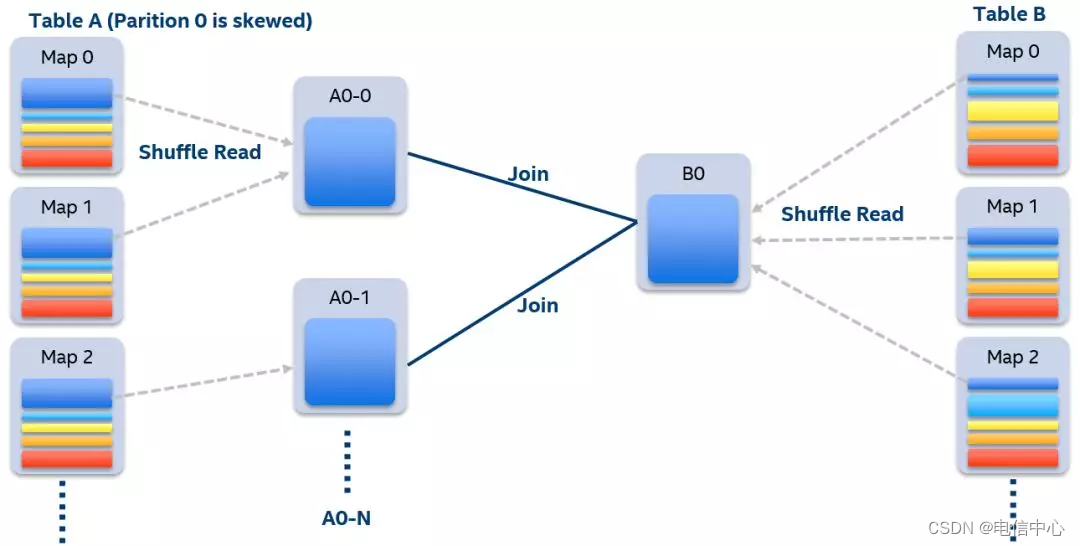
- 自動處理數據傾斜
原理:自適應執行開啟的前提下(AQE),我們可以在運行時很容易地檢測出有數據傾斜的partition。當執行某個stage時,我們收集該stage每個mapper 的shuffle數據大小和記錄條數。如果某一個partition的數據量或者記錄條數超過中位數的N倍,并且大于某個預先配置的閾值,我們就認為這是一個數據傾斜的partition,需要進行特殊的處理
| 參數 | 說明 | 推薦值 |
|---|---|---|
| spark.sql.adaptive.enabled | 開啟自適應執行 | 線上默認值true |
| spark.sql.adaptive.skewJoin.enabled | 開啟自動解決數據傾斜,默認值true | 無 |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 影響因子,某分區數據大小超過所有分區中位數與影響因子乘積,才會被認為發生了數據傾斜 | 無 |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes | 視為傾斜分區的分區數據最小值 | 無 |

 下String的內存釋放)

 線程的實現(上) 線程的創建方式 線程內存模型 線程安全)






: 基于FT2232HL實現的jtag下載器硬件+jtag的通信引腳說明)
)

 | 服務端請求偽造 SSRF)

2024.6.24~2024.6.30)
)


