目錄
1.初識Redis
1.1 Redis是什么?
1.2 Redis的特性
1.2.1 速度快
1.2.2 基于鍵值對的數據結構服務器
1.2.3 豐富的功能
1.2.4 簡單穩定
1.2.5?持久化
1.2.6 主從復制
1.2.7 高可用和分布式
1.3 Redis的使用場景
1.3.1 緩存
1.3.2 排行榜系統
1.3.3 計數器應用
1.3.4 社交網絡
1.3.5 消息隊列
2.Redis常見的數據類型
2.1 基本全局命令
2.1.1 KEYS
2.1.2 EXISTS
2.1.3 DEL
2.1.4 EXPIRE
2.1.5 TTL
2.1.6 TYPE
2.2 數據結構和內部編碼
1.初識Redis
1.1 Redis是什么?
Redis是一個在內存中存儲數據的中間件,用于作為數據庫,用于作為數據緩存,在分布式系統中有很大的用處,由于Redis將所有的數據存儲在內存中,所以Redis的讀寫性能非常高效
1.2 Redis的特性
1.2.1 速度快
1)Redis數據存儲在內存中,所以就比訪問硬盤的數據庫快很多
2)Redis的核心功能都是比較簡單的操作內存的數據結構
3)從網絡的角讀看,Redis使用了IO多路復用的方式,一個線程管理多個socket
4)Redis使用了單線程模型,減少了不必要的線程之間的競爭開銷
1.2.2 基于鍵值對的數據結構服務器
Redis是一種基于鍵值對的NoSQL數據庫,與很多鍵值對數據庫不同的是,Redis中的值可以是由String、hash、list、set、zset(有序集合)、Bitmaps(位圖)等多種數據結構和算法組成,因此Redis可以滿足很多的應用場景
1.2.3 豐富的功能
除了5中數據結構,Redis海提供了許多額外的功能:
1)提供了鍵過期功能,可以用來實現緩存
2)提供了發布訂閱功能,可以用來實現消息系統
3)支持Lua腳本功能,可以利用Lua創建出新的Redis命令
4)提供了簡單的事務功能,能在一定程度上保證事務特性
5)提供了流水線功能,客戶端能將一批命令一次性傳到Redis,減少了網絡的開銷
1.2.4 簡單穩定
Redis的簡單主要表現在三個方面,首先,Redis的源碼很少,相對于很多NoSQL數據庫來說代碼量相對要少很多。其次,Redis使用單線程模型,使得Redis服務端處理模型變得簡單。最后,Redis不需要依賴其他操作系統中的類庫,自己實現了事件處理的相關功能
1.2.5?持久化
通常看,將數據放在內存中不安全,一旦發生斷電,重要的數據可能就會丟失,因此Redis提供了兩種持久化的方式:RDB和AOF,使用兩種策略將內存的數據保存到硬盤中,這樣就保證了數據的可持久化
1.2.6 主從復制
Redis提供了復制功能,實現了多個相同的Redis副本,復制功能是分布式Redis的基礎
1.2.7 高可用和分布式
Redis提供了高可用實現的Redis哨兵(Redis Sentinel),能夠保證Redis結點的故障發現和故障自動轉移,也提供了Redis集群(Redis Cluster),是真正的分布式實現,提供了高可用、讀寫和容量的擴展性
1.3 Redis的使用場景
1.3.1 緩存
緩存機制幾乎在所有的網站都有使用,合理的使用緩存可以加速數據的訪問速度,Redis提供了鍵值對過期時間設置,并且也提供了靈活控制最大內存和內存溢出后的淘汰策略
1.3.2 排行榜系統
Redis提供了列表和有序集合的結構,合理地使用這些數據結構可以很方便地構建各種排行榜系統
1.3.3 計數器應用
在視頻網站中,每播放一次視頻播放量就加1,如果并發量很大對于傳統關系型數據的性能是?種挑戰,Redis天然支持計數功能而且計數的性能也非常好,可以說是計數器系統的重要選擇
1.3.4 社交網絡
由于社交網站訪問量通常比較大,而且傳統的關系型數據不太合適保存這種類型的數據,Redis提供的數據結構可以相對比較容易地實現這些功能
1.3.5 消息隊列
消息隊列系統可以說是一個大型網站的必備基礎組件,因為其具有業務解耦、非實時業務削峰等特性。Redis提供了發布訂閱功能和阻塞隊列的功能,對于一般的消息隊列功能基本可以滿足
2.Redis常見的數據類型
2.1 基本全局命令
Redis由5中數據結構,它們都是鍵值對中的值,對于鍵來說有一些通用的命令
2.1.1 KEYS
返回所有滿足樣式的key,例如
h?llo匹配hello,hallo和hxllo,?匹配任意一個字符
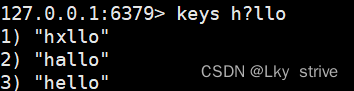
h*llo匹配hllo,hello,heeeello,*匹配0個或者多個任意字符
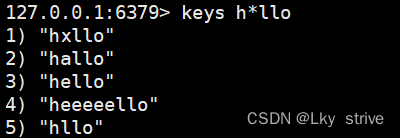
h[ae]llo匹配hello和hallo,[ae]只能匹配a和e

h[^e]匹配hallo,hxllo,[^e]排除e,其他都能匹配

h[a-b]llo匹配hallo和hbllo,只匹配a-b之間的范圍,包含兩側邊界
![]()
keys的時間復雜度是O(N),其中keys *(查詢redis中的所有key)
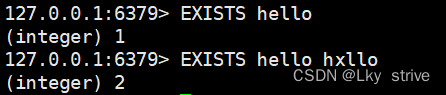
2.1.2 EXISTS
判斷某個key是否存在
時間復雜度:O(1)
返回值:key存在的個數
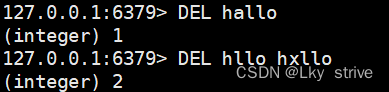
2.1.3 DEL
刪除指定的key
時間復雜度:O(1)
返回值:刪除掉key的個數
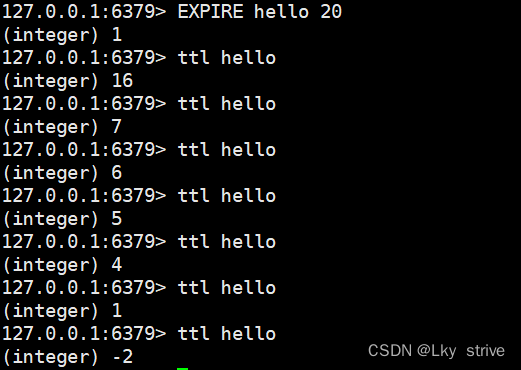
2.1.4 EXPIRE
為指定的key添加秒級的過期時間,key存活時間超過指定的值就會被自動刪除
時間復雜度:O(1)
返回值:1表示設置成功,0表示設置失敗
![]()

2.1.5 TTL
獲取指定key的過期時間,秒級
時間復雜度:O(1)
返回值:剩余時間。-1表示沒有關聯過期時間,-2表示key不存在
2.1.6 TYPE
返回key對應的數據類型,Redis的所有key都是String,key對應的value可能會存在多種類型
時間復雜度:O(1)
返回值:none,string,list,set,zset,hash,stream
![]()
總結:
keys:用來查看匹配規則的key
exists:用來判定指定key是否存在
del:刪除指定的key
expire:給key設置過期時間
ttl:查詢key的過期時間
type:查詢key對應的value的類型
2.2 數據結構和內部編碼
type命令實際返回的就是當前鍵的數據結構類型,它們分別是:String、list、hash、set、zest,這些只是Redis對外的數據結構
Redis數據結構和內部編碼
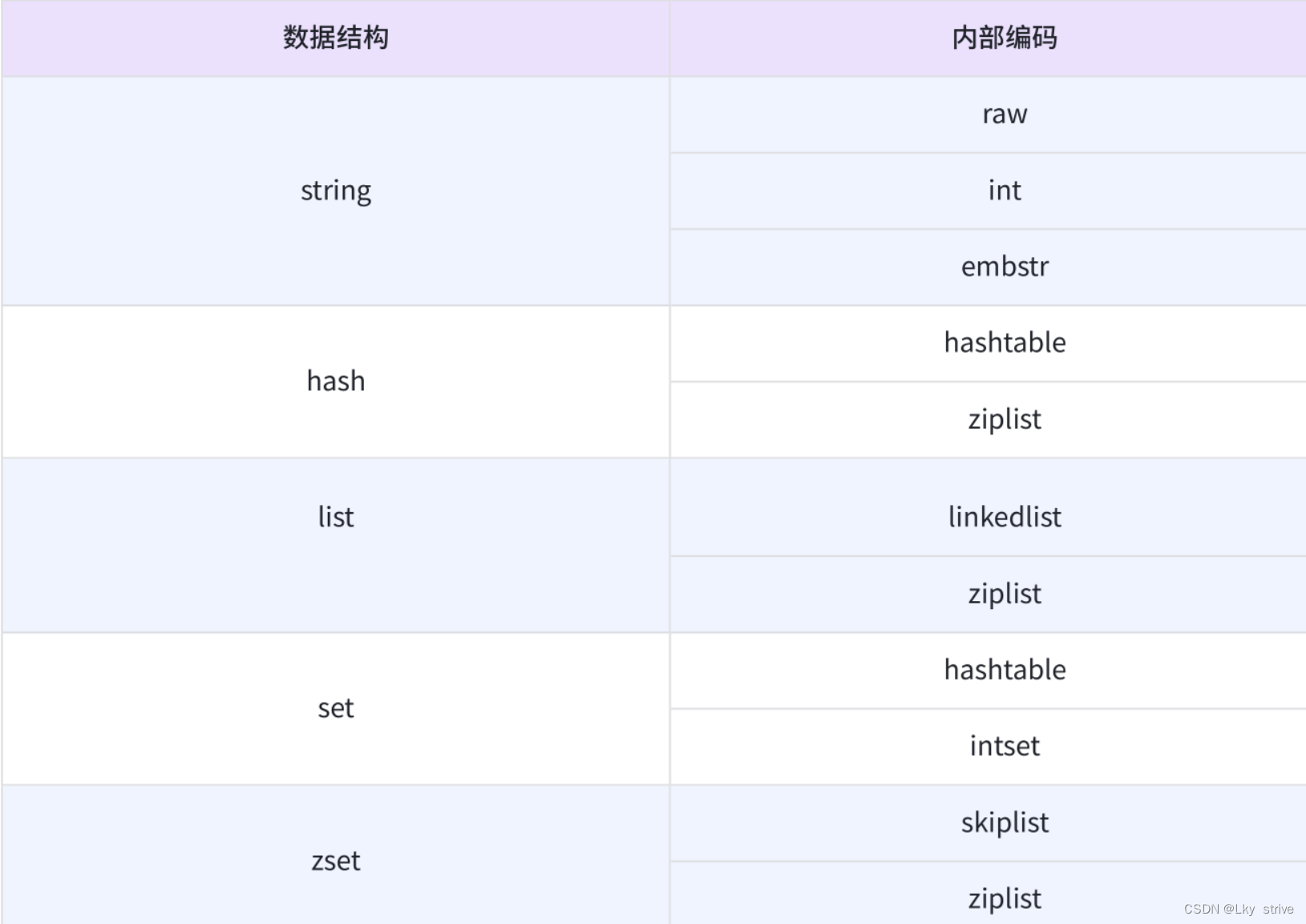
String
raw:最基本的字符串
int:redis通常也可以用來實現一些"計數"功能,當value是一個整數的時候,此時可能redis會直接使用int來保存
embstr:針對短字符串進行的特殊優化
hash
hashtable:最基本的哈希表
ziplist:壓縮列表,當哈希表里面的元素比較少時,可能就優化成ziplist,從而節省空間
list
linkedlist:鏈表
ziplist:壓縮列表
從Redis3.2開始,引入新的實現方式quicklist,它同時兼顧了linkedlist和ziplist的優點,其中quicklist就是一個鏈表,每個元素又是一個ziplist,兼顧到時間和空間
set
intset:集合中存的都是整數
zset
skiplist:跳表
上述每種數據結構都有至少兩種以上的內部編碼實現,其中可以通過object encoding命令來查詢內部編碼
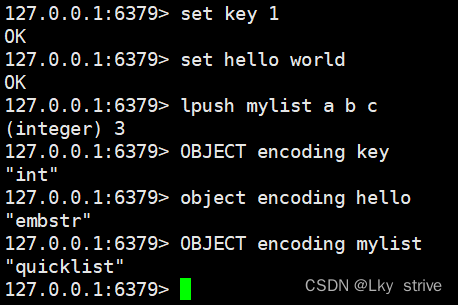
hello對應值的內部編碼時embstr,mylist對應值的內部編碼時ziplist
Redis這樣設計有兩個好處:
1)可以改進內部編碼,而對外的數據結構和命令沒有任何影響,因此一旦開發出更優秀的內部編碼,無需改動外部數據結構和命令,形成了高內聚低耦合,例如Redis3.2提供了quicklist,它是結合了ziplist和linkedlist兩者的優點,為列表類型提供了一種更為優秀的內部編碼實現,用戶是感知不到的
2)多種內部編碼實現可以在不同場景下發揮各自的優勢,例如ziplist比較節省內存,但是在列表元素比較多的情況下,性能會下降,這時候Redis會根據配置選項將列表類型的內部實現轉換為
linkedlist,整個過程用戶也感知不到
)
)
-->深度剖析(一))

)







】)



![[SAP ABAP] 數據字典](http://pic.xiahunao.cn/[SAP ABAP] 數據字典)


——策略模式)